 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Mass Segmentation in Automated 3-D Breast Ultrasound Using Dual-Path U-net
Sep 17, 2021
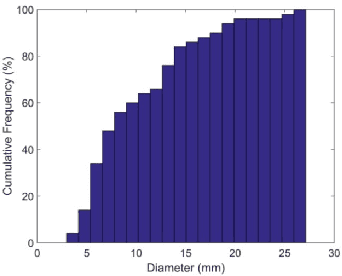

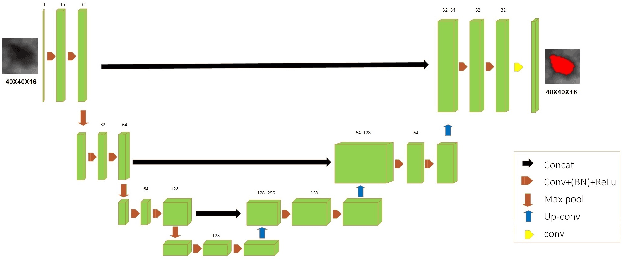
Automated 3-D breast ultrasound (ABUS) is a newfound system for breast screening that has been proposed as a supplementary modality to mammography for breast cancer detection. While ABUS has better performance in dense breasts, reading ABUS images is exhausting and time-consuming. So, a computer-aided detection system is necessary for interpretation of these images. Mass segmentation plays a vital role in the computer-aided detection systems and it affects the overall performance. Mass segmentation is a challenging task because of the large variety in size, shape, and texture of masses. Moreover, an imbalanced dataset makes segmentation harder. A novel mass segmentation approach based on deep learning is introduced in this paper. The deep network that is used in this study for image segmentation is inspired by U-net, which has been used broadly for dense segmentation in recent years. The system's performance was determined using a dataset of 50 masses including 38 malign and 12 benign lesions. The proposed segmentation method attained a mean Dice of 0.82 which outperformed a two-stage supervised edge-based method with a mean Dice of 0.74 and an adaptive region growing method with a mean Dice of 0.65.
26ms Inference Time for ResNet-50: Towards Real-Time Execution of all DNNs on Smartphone
May 02, 2019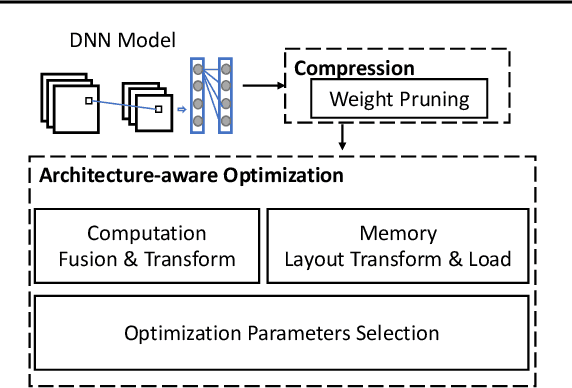

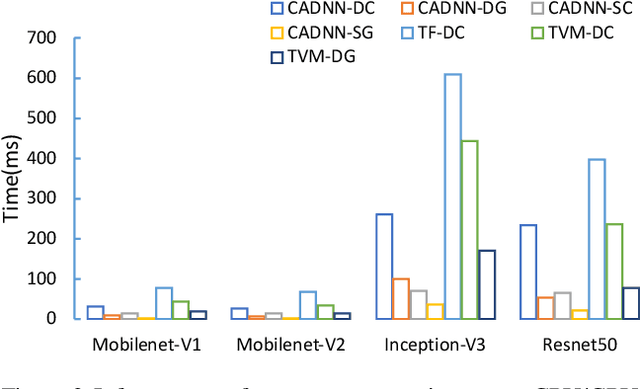
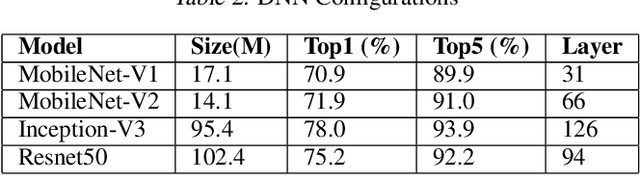
With the rapid emergence of a spectrum of high-end mobile devices, many applications that required desktop-level computation capability formerly can now run on these devices without any problem. However, without a careful optimization, executing Deep Neural Networks (a key building block of the real-time video stream processing that is the foundation of many popular applications) is still challenging, specifically, if an extremely low latency or high accuracy inference is needed. This work presents CADNN, a programming framework to efficiently execute DNN on mobile devices with the help of advanced model compression (sparsity) and a set of thorough architecture-aware optimization. The evaluation result demonstrates that CADNN outperforms all the state-of-the-art dense DNN execution frameworks like TensorFlow Lite and TVM.
Decision Tree Learning with Spatial Modal Logics
Sep 17, 2021
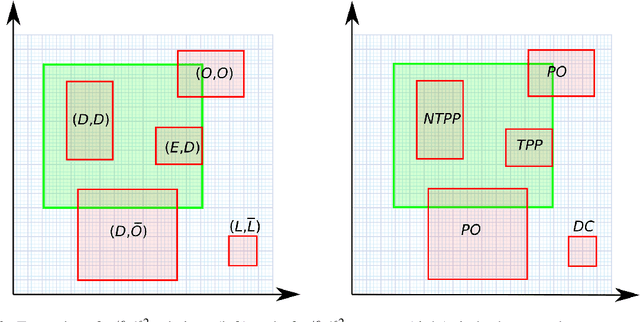
Symbolic learning represents the most straightforward approach to interpretable modeling, but its applications have been hampered by a single structural design choice: the adoption of propositional logic as the underlying language. Recently, more-than-propositional symbolic learning methods have started to appear, in particular for time-dependent data. These methods exploit the expressive power of modal temporal logics in powerful learning algorithms, such as temporal decision trees, whose classification capabilities are comparable with the best non-symbolic ones, while producing models with explicit knowledge representation. With the intent of following the same approach in the case of spatial data, in this paper we: i) present a theory of spatial decision tree learning; ii) describe a prototypical implementation of a spatial decision tree learning algorithm based, and strictly extending, the classical C4.5 algorithm; and iii) perform a series of experiments in which we compare the predicting power of spatial decision trees with that of classical propositional decision trees in several versions, for a multi-class image classification problem, on publicly available datasets. Our results are encouraging, showing clear improvements in the performances from the propositional to the spatial models, which in turn show higher levels of interpretability.
* In Proceedings GandALF 2021, arXiv:2109.07798. This is partially dedicated to Alice
The Multi-phase spatial meta-heuristic algorithm for public health emergency transportation
Jul 05, 2021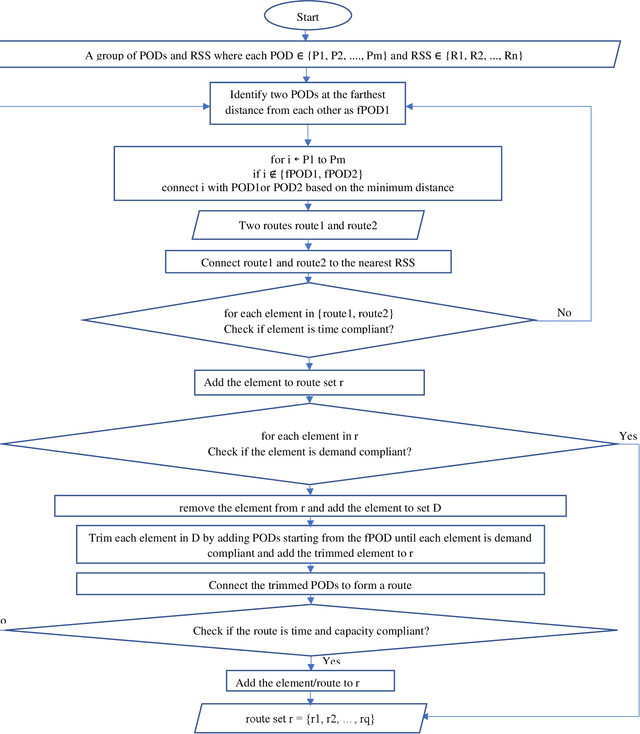
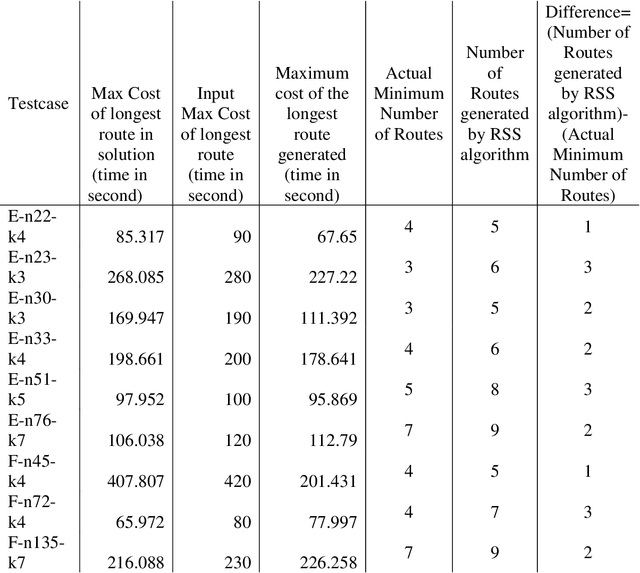
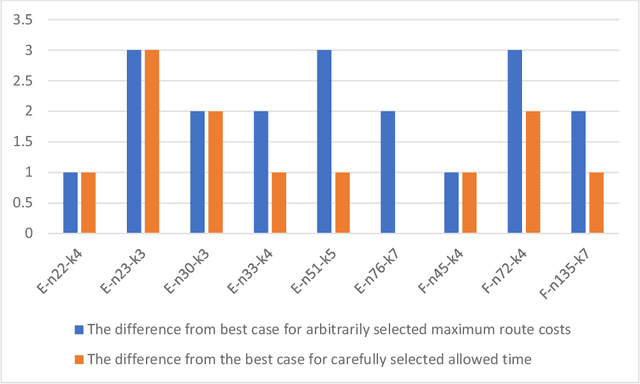
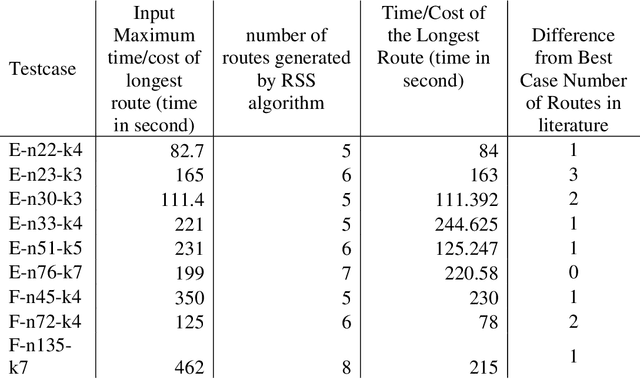
The delivery of Medical Countermeasures(MCMs) for mass prophylaxis in the case of a bio-terrorist attack is an active research topic that has interested the research community over the past decades. The objective of this study is to design an efficient algorithm for the Receive Reload and Store Problem(RSS) in which we aim to find feasible routes to deliver MCMs to a target population considering time, physical, and human resources, and capacity limitations. For doing this, we adapt the p-median problem to the POD-based emergency response planning procedures and propose an efficient algorithm solution to perform the p-median in reasonable computational time. We present RE-PLAN, the Response PLan Analyzer system that contains some RSS solutions developed at The Center for Computational Epidemiology and Response Analysis (CeCERA) at the University of North Texas. Finally, we analyze a study case where we show how the computational performance of the algorithm can impact the process of decision making and emergency planning in the short and long terms.
Automated Identification of Cell Populations in Flow Cytometry Data with Transformers
Aug 23, 2021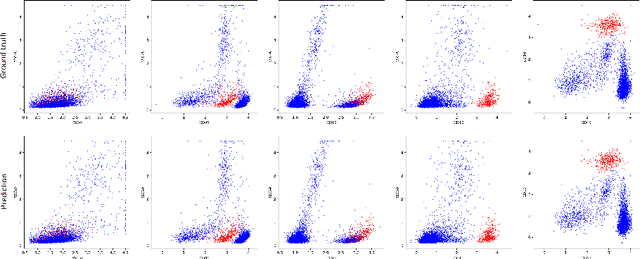
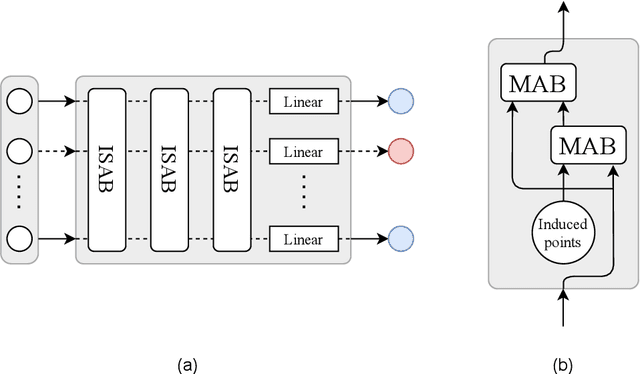
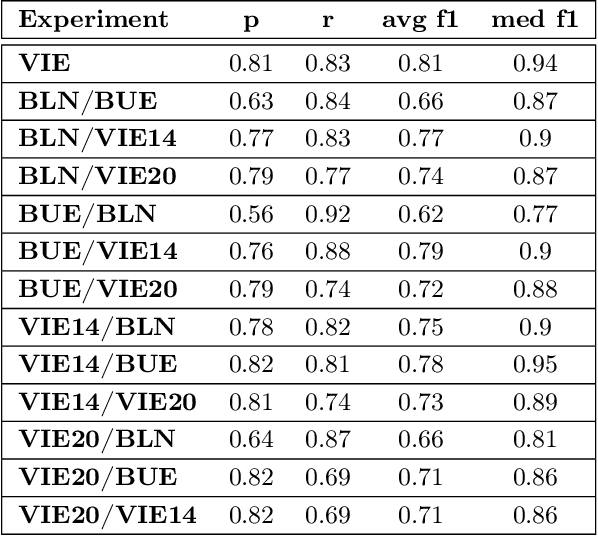
Acute Lymphoblastic Leukemia (ALL) is the most frequent hematologic malignancy in children and adolescents. A strong prognostic factor in ALL is given by the Minimal Residual Disease (MRD), which is a measure for the number of leukemic cells persistent in a patient. Manual MRD assessment from Multiparameter Flow Cytometry (FCM) data after treatment is time-consuming and subjective. In this work, we present an automated method to compute the MRD value directly from FCM data. We present a novel neural network approach based on the transformer architecture that learns to directly identify blast cells in a sample. We train our method in a supervised manner and evaluate it on publicly available ALL FCM data from three different clinical centers. Our method reaches a median f1 score of ~0.93 when tested on 200 B-ALL samples.
A relaxed technical assumption for posterior sampling-based reinforcement learning for control of unknown linear systems
Aug 19, 2021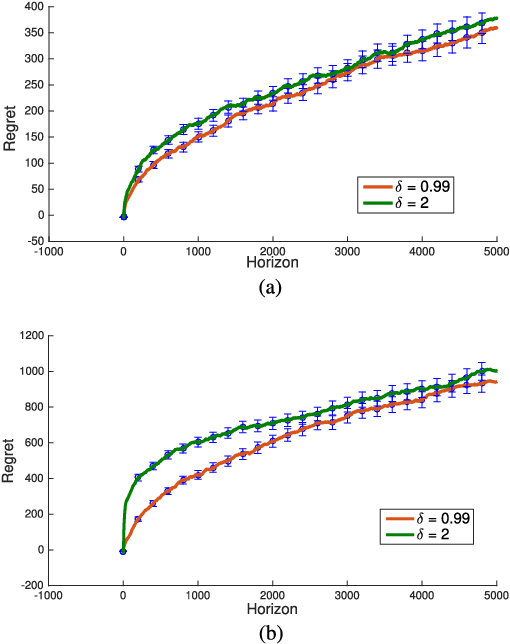
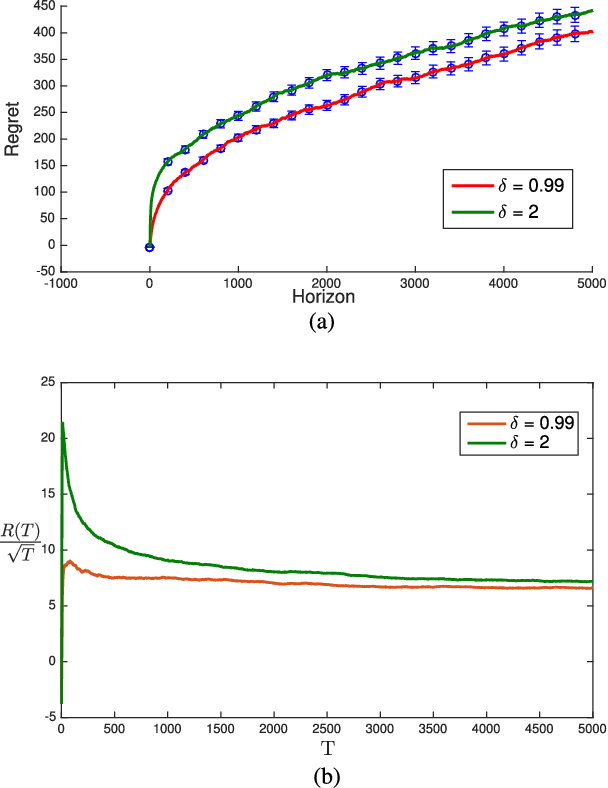
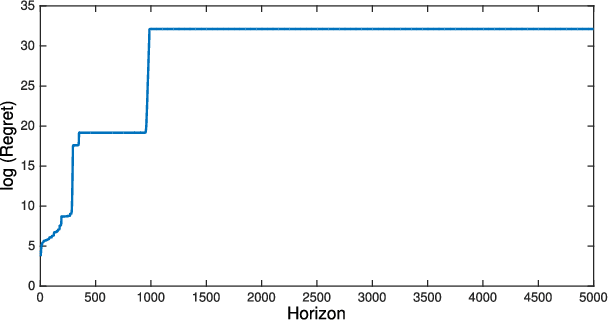
We revisit the Thompson sampling algorithm to control an unknown linear quadratic (LQ) system recently proposed by Ouyang et al (arXiv:1709.04047). The regret bound of the algorithm was derived under a technical assumption on the induced norm of the closed loop system. In this technical note, we show that by making a minor modification in the algorithm (in particular, ensuring that an episode does not end too soon), this technical assumption on the induced norm can be replaced by a milder assumption in terms of the spectral radius of the closed loop system. The modified algorithm has the same Bayesian regret of $\tilde{\mathcal{O}}(\sqrt{T})$, where $T$ is the time-horizon and the $\tilde{\mathcal{O}}(\cdot)$ notation hides logarithmic terms in~$T$.
Mitigating Membership Inference Attacks by Self-Distillation Through a Novel Ensemble Architecture
Oct 15, 2021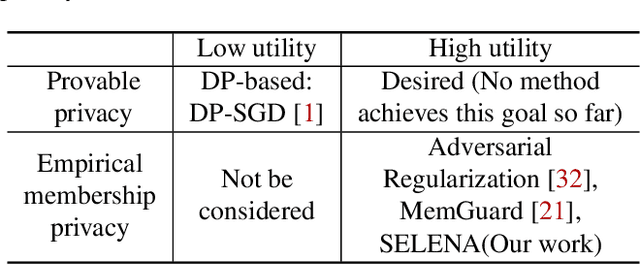

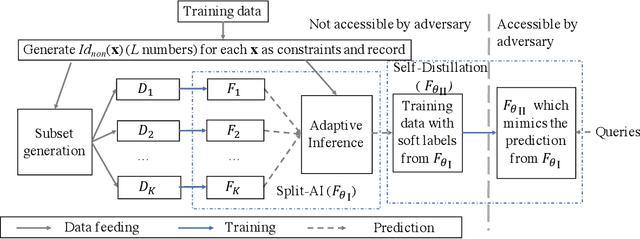
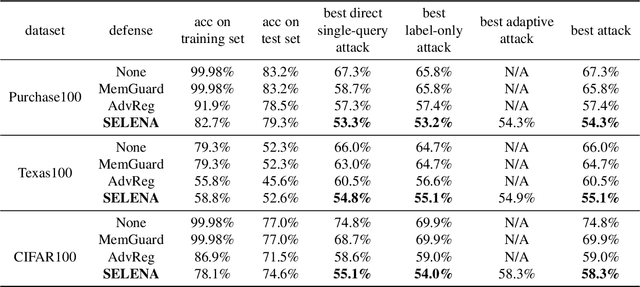
Membership inference attacks are a key measure to evaluate privacy leakage in machine learning (ML) models. These attacks aim to distinguish training members from non-members by exploiting differential behavior of the models on member and non-member inputs. The goal of this work is to train ML models that have high membership privacy while largely preserving their utility; we therefore aim for an empirical membership privacy guarantee as opposed to the provable privacy guarantees provided by techniques like differential privacy, as such techniques are shown to deteriorate model utility. Specifically, we propose a new framework to train privacy-preserving models that induces similar behavior on member and non-member inputs to mitigate membership inference attacks. Our framework, called SELENA, has two major components. The first component and the core of our defense is a novel ensemble architecture for training. This architecture, which we call Split-AI, splits the training data into random subsets, and trains a model on each subset of the data. We use an adaptive inference strategy at test time: our ensemble architecture aggregates the outputs of only those models that did not contain the input sample in their training data. We prove that our Split-AI architecture defends against a large family of membership inference attacks, however, it is susceptible to new adaptive attacks. Therefore, we use a second component in our framework called Self-Distillation to protect against such stronger attacks. The Self-Distillation component (self-)distills the training dataset through our Split-AI ensemble, without using any external public datasets. Through extensive experiments on major benchmark datasets we show that SELENA presents a superior trade-off between membership privacy and utility compared to the state of the art.
Multi-Robot Task Planning under Individual and Collaborative Temporal Logic Specifications
Aug 27, 2021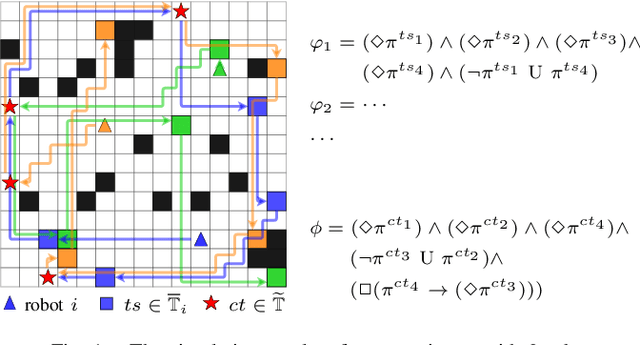
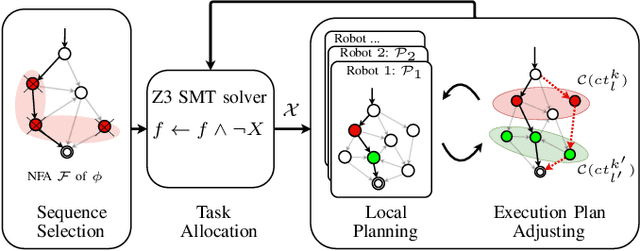
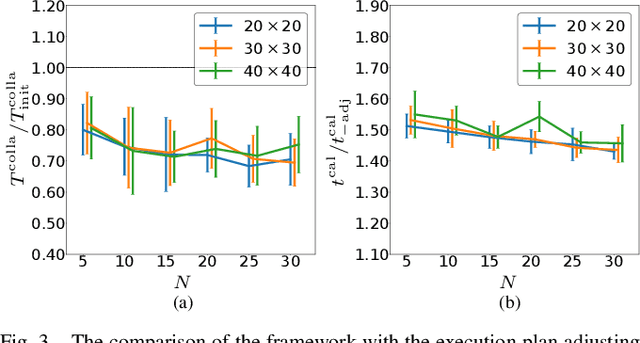
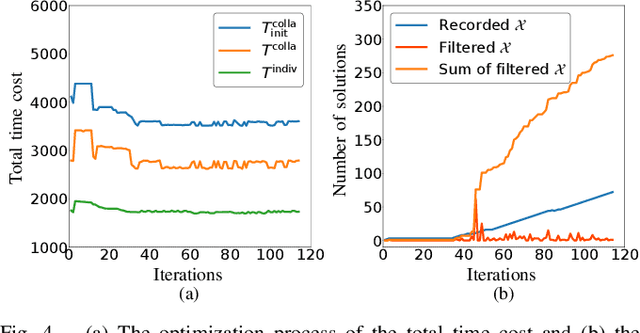
This paper investigates the task coordination of multi-robot where each robot has a private individual temporal logic task specification; and also has to jointly satisfy a globally given collaborative temporal logic task specification. To efficiently generate feasible and optimized task execution plans for the robots, we propose a hierarchical multi-robot temporal task planning framework, in which a central server allocates the collaborative tasks to the robots, and then individual robots can independently synthesize their task execution plans in a decentralized manner. Furthermore, we propose an execution plan adjusting mechanism that allows the robots to iteratively modify their execution plans via privacy-preserved inter-agent communication, to improve the expected actual execution performance by reducing waiting time in collaborations for the robots. The correctness and efficiency of the proposed method are analyzed and also verified by extensive simulation experiments.
Reliable and Fast Recurrent Neural Network Architecture Optimization
Jun 29, 2021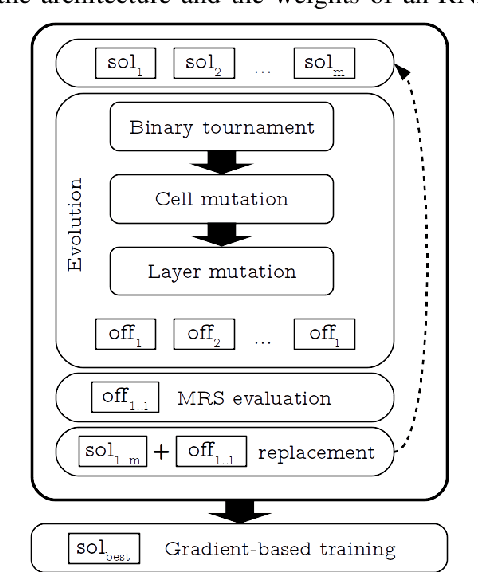
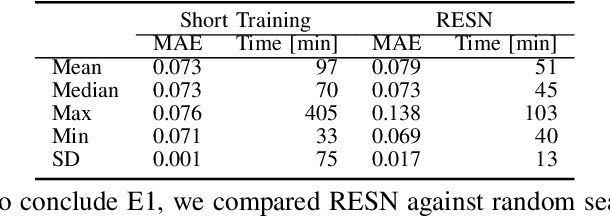
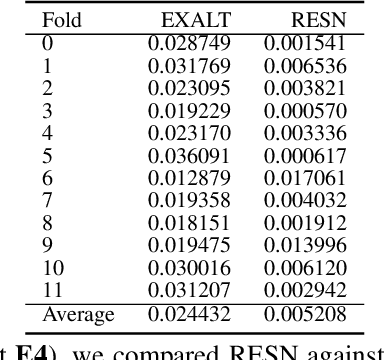

This article introduces Random Error Sampling-based Neuroevolution (RESN), a novel automatic method to optimize recurrent neural network architectures. RESN combines an evolutionary algorithm with a training-free evaluation approach. The results show that RESN achieves state-of-the-art error performance while reducing by half the computational time.
Few-Shot Bot: Prompt-Based Learning for Dialogue Systems
Oct 15, 2021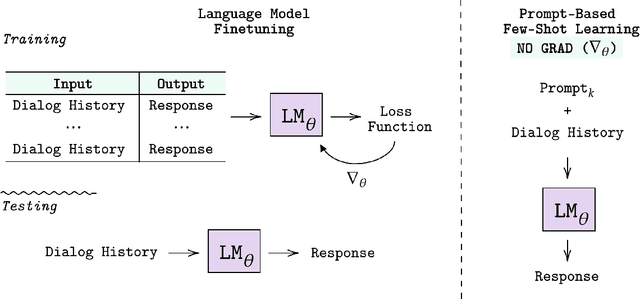
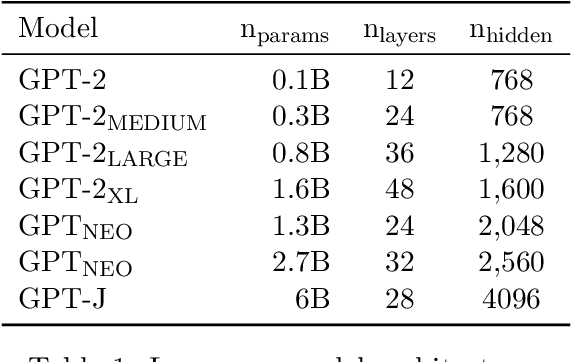
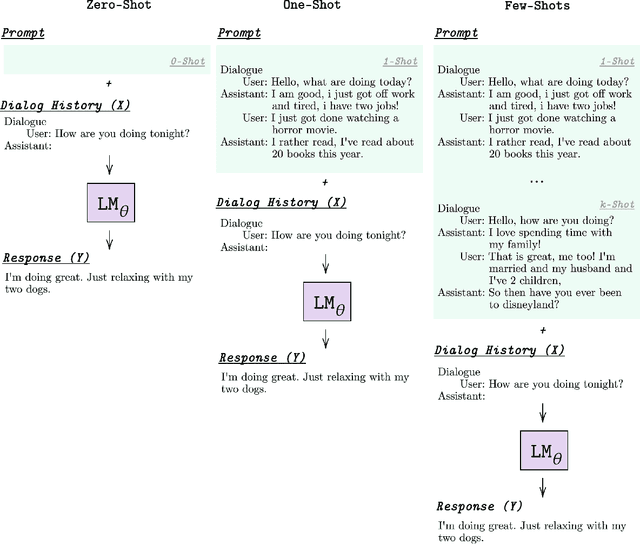
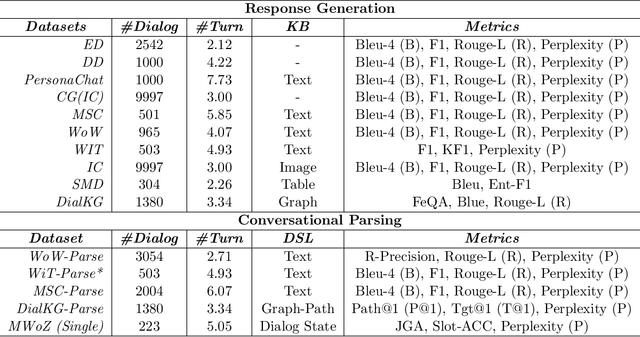
Learning to converse using only a few examples is a great challenge in conversational AI. The current best conversational models, which are either good chit-chatters (e.g., BlenderBot) or goal-oriented systems (e.g., MinTL), are language models (LMs) fine-tuned on large conversational datasets. Training these models is expensive, both in terms of computational resources and time, and it is hard to keep them up to date with new conversational skills. A simple yet unexplored solution is prompt-based few-shot learning (Brown et al. 2020) which does not require gradient-based fine-tuning but instead uses a few examples in the LM context as the only source of learning. In this paper, we explore prompt-based few-shot learning in dialogue tasks. We benchmark LMs of different sizes in nine response generation tasks, which include four knowledge-grounded tasks, a task-oriented generations task, three open-chat tasks, and controlled stylistic generation, and five conversational parsing tasks, which include dialogue state tracking, graph path generation, persona information extraction, document retrieval, and internet query generation. The current largest released LM (GPT-J-6B) using prompt-based few-shot learning, and thus requiring no training, achieves competitive performance to fully trained state-of-the-art models. Moreover, we propose a novel prompt-based few-shot classifier, that also does not require any fine-tuning, to select the most appropriate prompt given a dialogue history. Finally, by combining the power of prompt-based few-shot learning and a Skill Selector, we create an end-to-end chatbot named the Few-Shot Bot (FSB), which automatically selects the most appropriate conversational skill, queries different knowledge bases or the internet, and uses the retrieved knowledge to generate a human-like response, all using only few dialogue examples per skill.