 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Stochastic Transformer Networks with Linear Competing Units: Application to end-to-end SL Translation
Oct 01, 2021
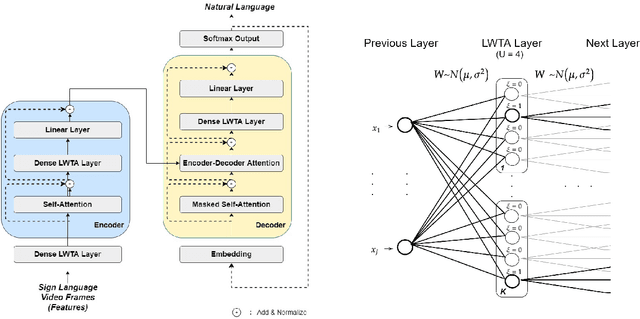
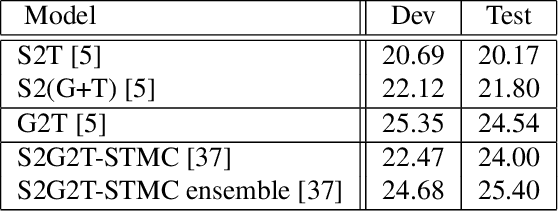


Automating sign language translation (SLT) is a challenging real world application. Despite its societal importance, though, research progress in the field remains rather poor. Crucially, existing methods that yield viable performance necessitate the availability of laborious to obtain gloss sequence groundtruth. In this paper, we attenuate this need, by introducing an end-to-end SLT model that does not entail explicit use of glosses; the model only needs text groundtruth. This is in stark contrast to existing end-to-end models that use gloss sequence groundtruth, either in the form of a modality that is recognized at an intermediate model stage, or in the form of a parallel output process, jointly trained with the SLT model. Our approach constitutes a Transformer network with a novel type of layers that combines: (i) local winner-takes-all (LWTA) layers with stochastic winner sampling, instead of conventional ReLU layers, (ii) stochastic weights with posterior distributions estimated via variational inference, and (iii) a weight compression technique at inference time that exploits estimated posterior variance to perform massive, almost lossless compression. We demonstrate that our approach can reach the currently best reported BLEU-4 score on the PHOENIX 2014T benchmark, but without making use of glosses for model training, and with a memory footprint reduced by more than 70%.
Incentivizing Compliance with Algorithmic Instruments
Jul 28, 2021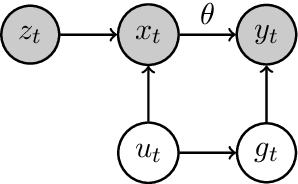
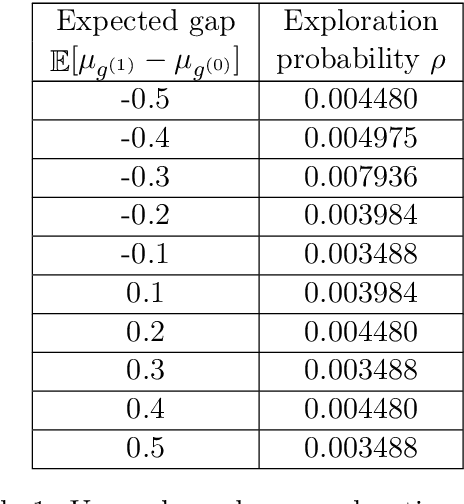
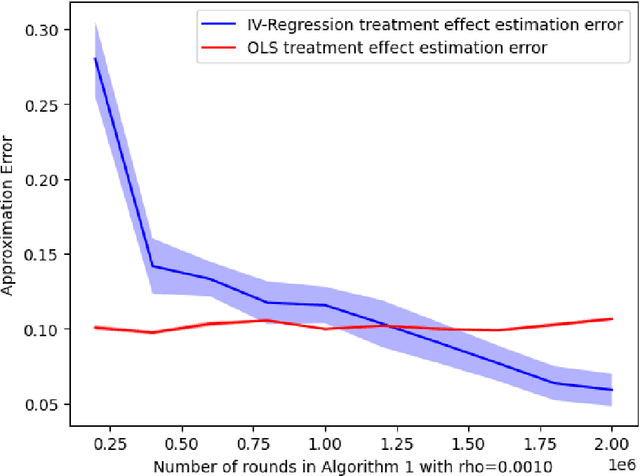
Randomized experiments can be susceptible to selection bias due to potential non-compliance by the participants. While much of the existing work has studied compliance as a static behavior, we propose a game-theoretic model to study compliance as dynamic behavior that may change over time. In rounds, a social planner interacts with a sequence of heterogeneous agents who arrive with their unobserved private type that determines both their prior preferences across the actions (e.g., control and treatment) and their baseline rewards without taking any treatment. The planner provides each agent with a randomized recommendation that may alter their beliefs and their action selection. We develop a novel recommendation mechanism that views the planner's recommendation as a form of instrumental variable (IV) that only affects an agents' action selection, but not the observed rewards. We construct such IVs by carefully mapping the history -- the interactions between the planner and the previous agents -- to a random recommendation. Even though the initial agents may be completely non-compliant, our mechanism can incentivize compliance over time, thereby enabling the estimation of the treatment effect of each treatment, and minimizing the cumulative regret of the planner whose goal is to identify the optimal treatment.
Double-RIS Versus Single-RIS Aided Systems: Tensor-Based MIMO Channel Estimation and Design Perspectives
Sep 19, 2021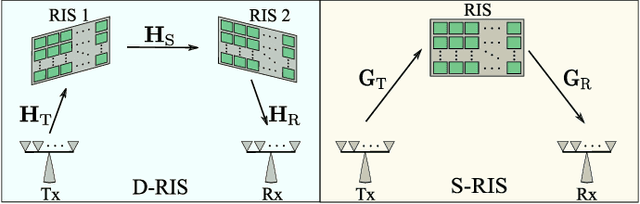
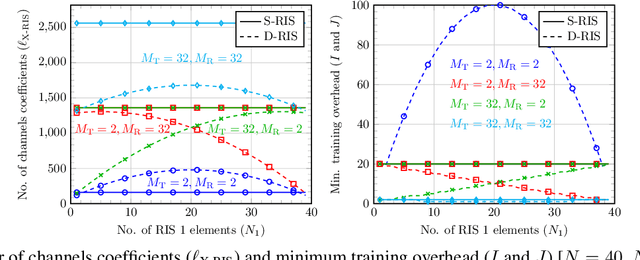
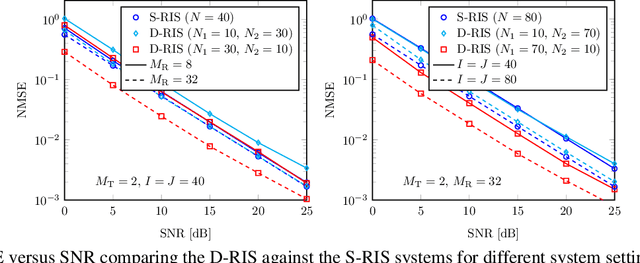
Reconfigurable intelligent surfaces (RISs) have been proposed recently as new technology to tune the wireless propagation channels in real-time. However, most of the current works assume single-RIS (S-RIS)-aided systems, which can be limited in some application scenarios where a transmitter might need a multi-RIS-aided channel to communicate with a receiver. In this paper, we consider a double-RIS (D-RIS)-aided MIMO system and propose an alternating least-squared-based channel estimation method by exploiting the Tucker2 tensor structure of the received signals. Using the proposed method, the cascaded MIMO channel parts can be estimated separately, up to trivial scaling factors. Compared with the S-RIS systems, we show that if the RIS elements of a S-RIS system are distributed carefully between the two RISs in a D-RIS system, the training overhead can be reduced and the estimation accuracy can also be increased. Therefore, D-RIS systems can be seen as an appealing approach to further increase the coverage, capacity, and efficiency of future wireless networks compared to S-RIS systems.
Learning to be safe, in finite time
Oct 01, 2020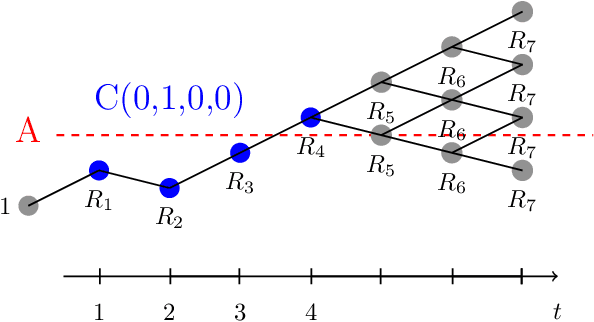
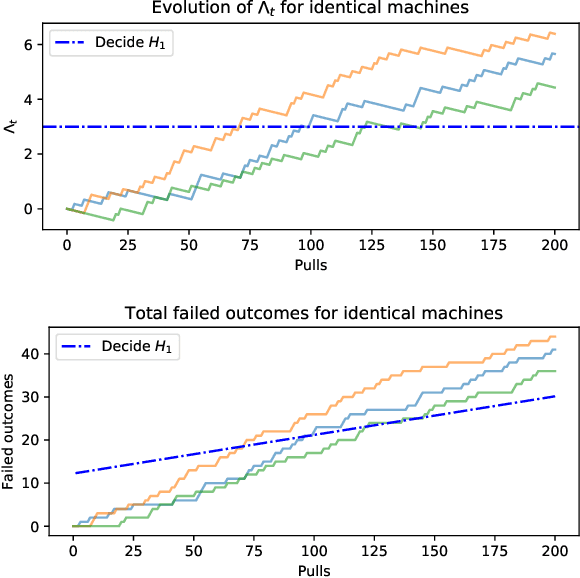
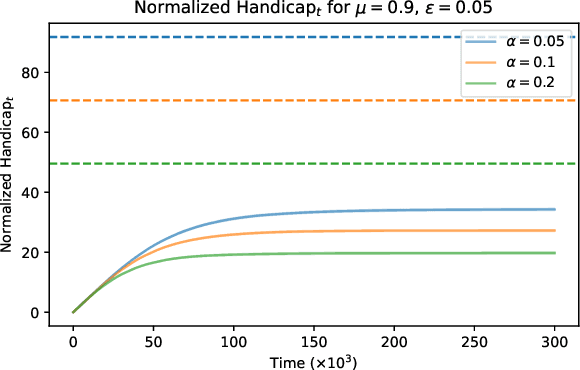
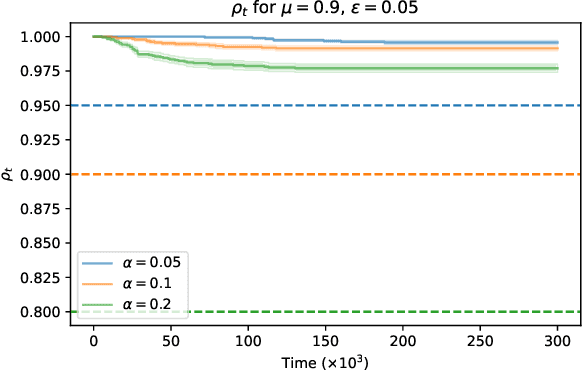
This paper aims to put forward the concept that learning to take safe actions in unknown environments, even with probability one guarantees, can be achieved without the need for an unbounded number of exploratory trials, provided that one is willing to relax its optimality requirements mildly. We focus on the canonical multi-armed bandit problem and seek to study the exploration-preservation trade-off intrinsic within safe learning. More precisely, by defining a handicap metric that counts the number of unsafe actions, we provide an algorithm for discarding unsafe machines (or actions), with probability one, that achieves constant handicap. Our algorithm is rooted in the classical sequential probability ratio test, redefined here for continuing tasks. Under standard assumptions on sufficient exploration, our rule provably detects all unsafe machines in an (expected) finite number of rounds. The analysis also unveils a trade-off between the number of rounds needed to secure the environment and the probability of discarding safe machines. Our decision rule can wrap around any other algorithm to optimize a specific auxiliary goal since it provides a safe environment to search for (approximately) optimal policies. Simulations corroborate our theoretical findings and further illustrate the aforementioned trade-offs.
Multiple Myeloma Cancer Cell Instance Segmentation
Sep 19, 2021
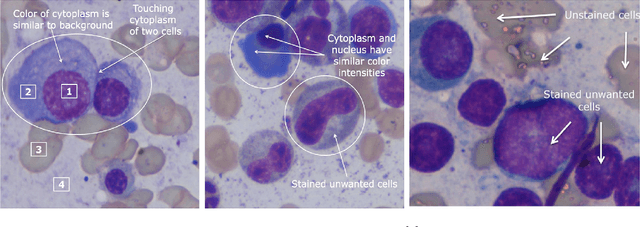
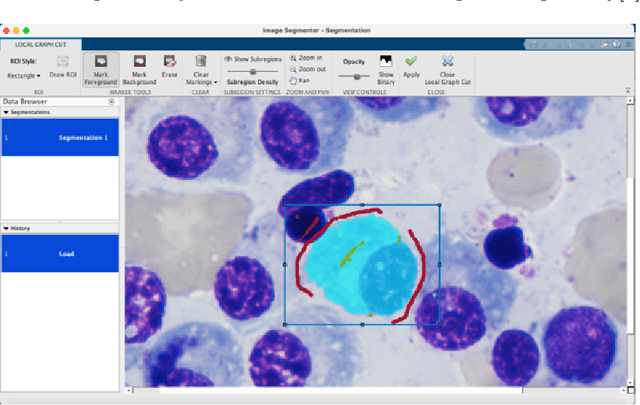

Images remain the largest data source in the field of healthcare. But at the same time, they are the most difficult to analyze. More than often, these images are analyzed by human experts such as pathologists and physicians. But due to considerable variation in pathology and the potential fatigue of human experts, an automated solution is much needed. The recent advancement in Deep learning could help us achieve an efficient and economical solution for the same. In this research project, we focus on developing a Deep Learning-based solution for detecting Multiple Myeloma cancer cells using an Object Detection and Instance Segmentation System. We explore multiple existing solutions and architectures for the task of Object Detection and Instance Segmentation and try to leverage them and come up with a novel architecture to achieve comparable and competitive performance on the required task. To train our model to detect and segment Multiple Myeloma cancer cells, we utilize a dataset curated by us using microscopic images of cell slides provided by Dr.Ritu Gupta(Prof., Dept. of Oncology AIIMS).
Architecture Aware Latency Constrained Sparse Neural Networks
Sep 01, 2021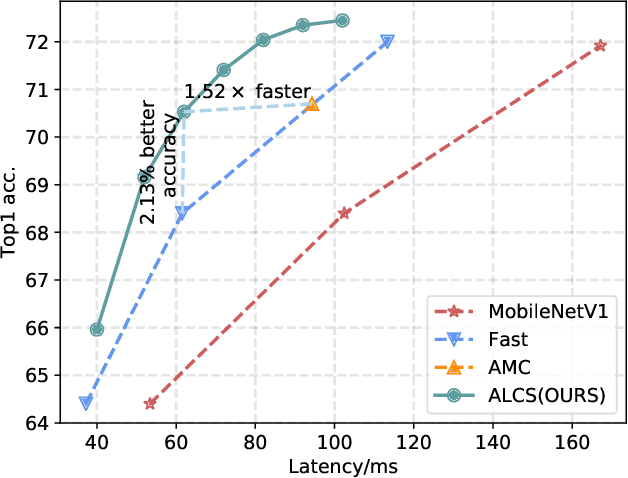
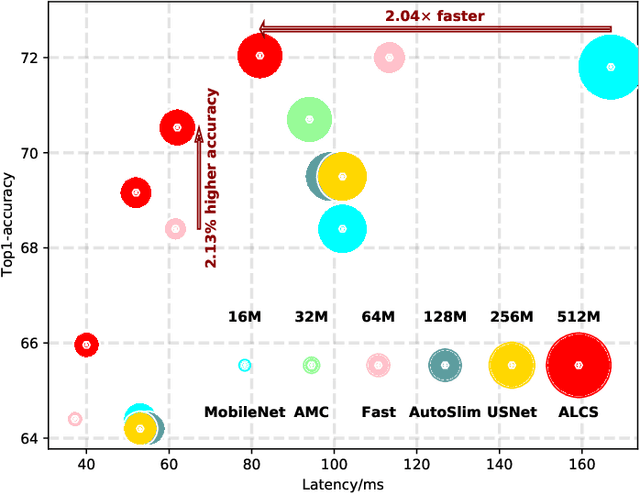
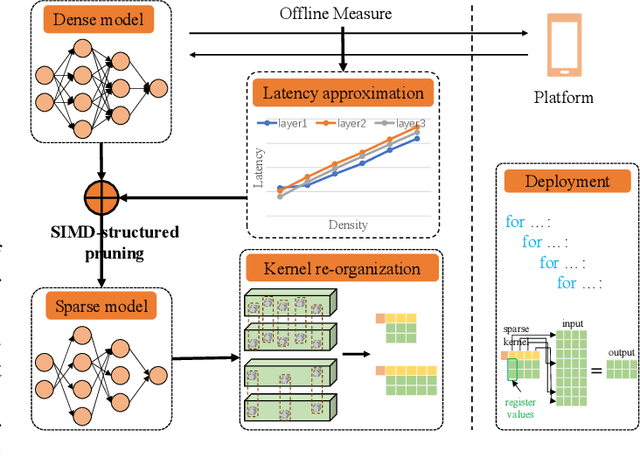
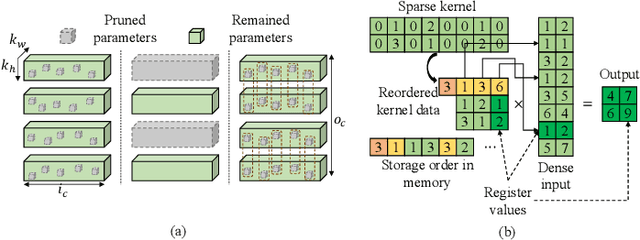
Acceleration of deep neural networks to meet a specific latency constraint is essential for their deployment on mobile devices. In this paper, we design an architecture aware latency constrained sparse (ALCS) framework to prune and accelerate CNN models. Taking modern mobile computation architectures into consideration, we propose Single Instruction Multiple Data (SIMD)-structured pruning, along with a novel sparse convolution algorithm for efficient computation. Besides, we propose to estimate the run time of sparse models with piece-wise linear interpolation. The whole latency constrained pruning task is formulated as a constrained optimization problem that can be efficiently solved with Alternating Direction Method of Multipliers (ADMM). Extensive experiments show that our system-algorithm co-design framework can achieve much better Pareto frontier among network accuracy and latency on resource-constrained mobile devices.
Collision Avoidance Using Spherical Harmonics
Jul 15, 2021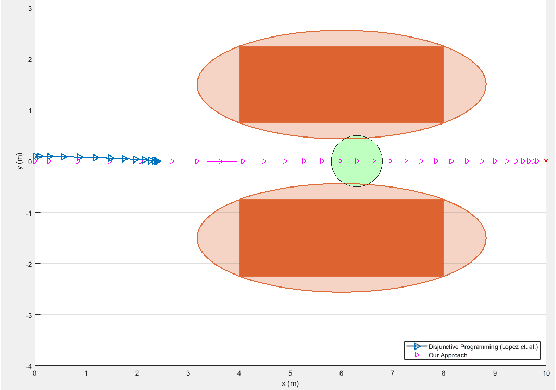
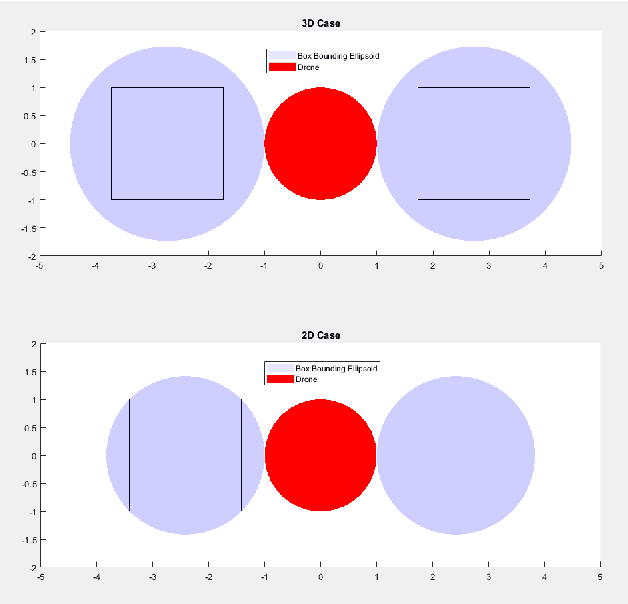
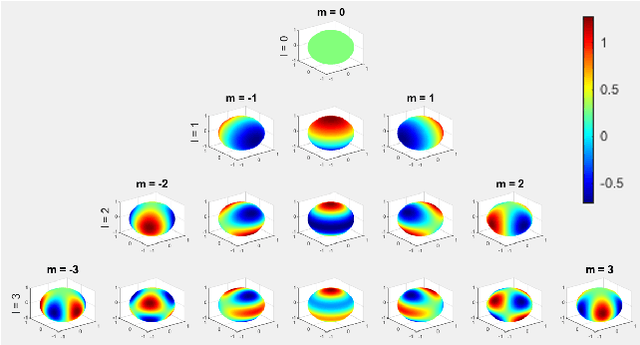
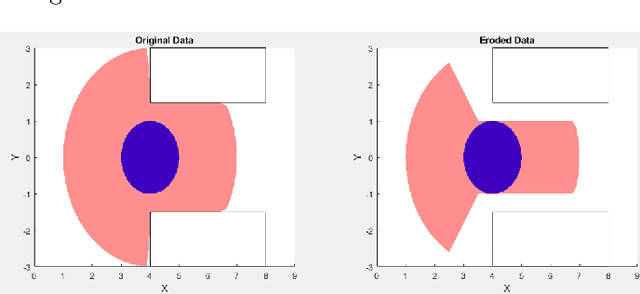
In this paper, we propose a novel optimization-based trajectory planner that utilizes spherical harmonics to estimate the collision-free solution space around an agent. The space is estimated using a constrained over-determined least-squares estimator to determine the parameters that define a spherical harmonic approximation at a given time step. Since spherical harmonics produce star-convex shapes, the planner can consider all paths that are in line-of-sight for the agent within a given radius. This contrasts with other state-of-the-art planners that generate trajectories by estimating obstacle boundaries with rough approximations and using heuristic rules to prune a solution space into one that can be easily explored. Those methods cause the trajectory planner to be overly conservative in environments where an agent must get close to obstacles to accomplish a goal. Our method is shown to perform on-par with other path planners and surpass these planners in certain environments. It generates feasible trajectories while still running in real-time and guaranteeing safety when a valid solution exists.
Universal time-series forecasting with mixture predictors
Oct 01, 2020This book is devoted to the problem of sequential probability forecasting, that is, predicting the probabilities of the next outcome of a growing sequence of observations given the past. This problem is considered in a very general setting that unifies commonly used probabilistic and non-probabilistic settings, trying to make as few as possible assumptions on the mechanism generating the observations. A common form that arises in various formulations of this problem is that of mixture predictors, which are formed as a combination of a finite or infinite set of other predictors attempting to combine their predictive powers. The main subject of this book are such mixture predictors, and the main results demonstrate the universality of this method in a very general probabilistic setting, but also show some of its limitations. While the problems considered are motivated by practical applications, involving, for example, financial, biological or behavioural data, this motivation is left implicit and all the results exposed are theoretical. The book targets graduate students and researchers interested in the problem of sequential prediction, and, more generally, in theoretical analysis of problems in machine learning and non-parametric statistics, as well as mathematical and philosophical foundations of these fields. The material in this volume is presented in a way that presumes familiarity with basic concepts of probability and statistics, up to and including probability distributions over spaces of infinite sequences. Familiarity with the literature on learning or stochastic processes is not required.
Assessing domain adaptation techniques for mitosis detection in multi-scanner breast cancer histopathology images
Sep 25, 2021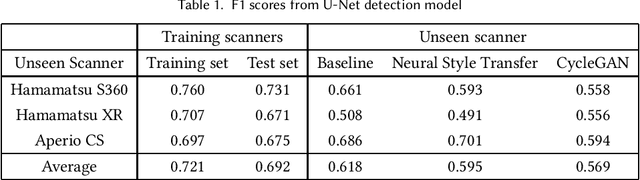
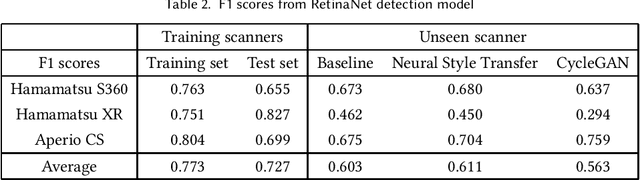
Breast cancer is the most prevalent cancer worldwide and is increasing in incidence, with over two million new cases now diagnosed each year. As part of diagnostic tumour grading, histopathologists manually count the number of dividing cells (mitotic figures) in a sample. Since the process is subjective and time-consuming, artificial intelligence (AI) methods have been developed to automate the process, however these methods often perform poorly when applied to data from outside of the original (training) domain, i.e. they do not generalise well to variations in histological background, staining protocols, or scanner types. Style transfer, a form of domain adaptation, provides the means to transform images from different domains to a shared visual appearance and have been adopted in various applications to mitigate the issue of domain shift. In this paper we train two mitosis detection models and two style transfer methods and evaluate the usefulness of the latter for improving mitosis detection performance in images digitised using different scanners. We found that the best of these models, U-Net without style transfer, achieved an F1-score of 0.693 on the MIDOG 2021 preliminary test set.
Changes in European Solidarity Before and During COVID-19: Evidence from a Large Crowd- and Expert-Annotated Twitter Dataset
Aug 02, 2021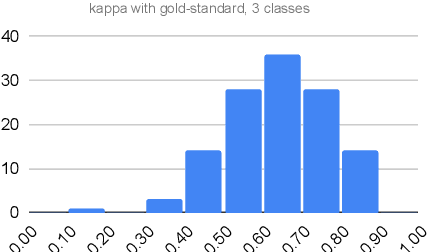

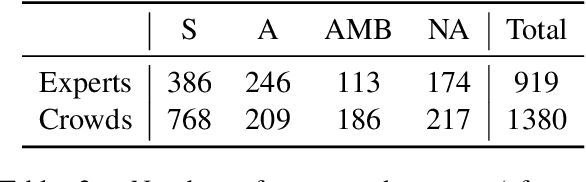

We introduce the well-established social scientific concept of social solidarity and its contestation, anti-solidarity, as a new problem setting to supervised machine learning in NLP to assess how European solidarity discourses changed before and after the COVID-19 outbreak was declared a global pandemic. To this end, we annotate 2.3k English and German tweets for (anti-)solidarity expressions, utilizing multiple human annotators and two annotation approaches (experts vs.\ crowds). We use these annotations to train a BERT model with multiple data augmentation strategies. Our augmented BERT model that combines both expert and crowd annotations outperforms the baseline BERT classifier trained with expert annotations only by over 25 points, from 58\% macro-F1 to almost 85\%. We use this high-quality model to automatically label over 270k tweets between September 2019 and December 2020. We then assess the automatically labeled data for how statements related to European (anti-)solidarity discourses developed over time and in relation to one another, before and during the COVID-19 crisis. Our results show that solidarity became increasingly salient and contested during the crisis. While the number of solidarity tweets remained on a higher level and dominated the discourse in the scrutinized time frame, anti-solidarity tweets initially spiked, then decreased to (almost) pre-COVID-19 values before rising to a stable higher level until the end of 2020.