 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Overprotective Training Environments Fall Short at Testing Time: Let Models Contribute to Their Own Training
Mar 30, 2021
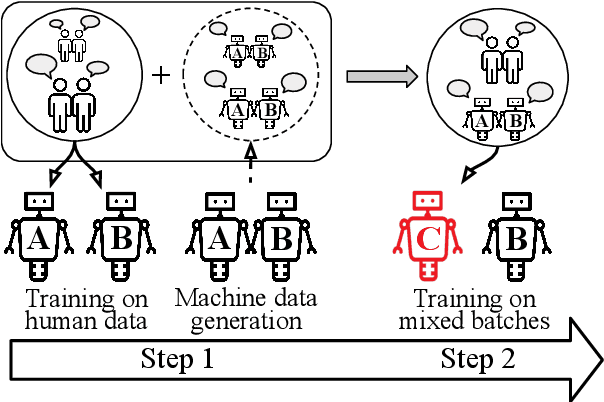
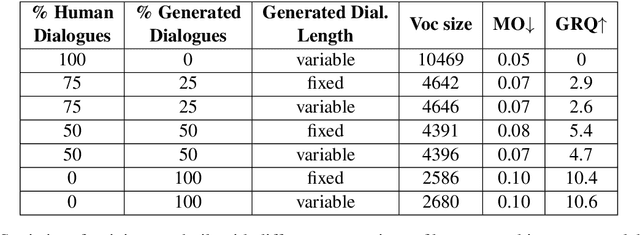

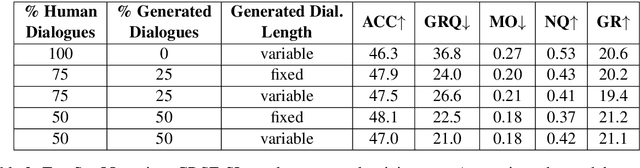
Despite important progress, conversational systems often generate dialogues that sound unnatural to humans. We conjecture that the reason lies in their different training and testing conditions: agents are trained in a controlled "lab" setting but tested in the "wild". During training, they learn to generate an utterance given the human dialogue history. On the other hand, during testing, they must interact with each other, and hence deal with noisy data. We propose to fill this gap by training the model with mixed batches containing both samples of human and machine-generated dialogues. We assess the validity of the proposed method on GuessWhat?!, a visual referential game.
Real-time and Large-scale Fleet Allocation of Autonomous Taxis: A Case Study in New York Manhattan Island
Sep 06, 2020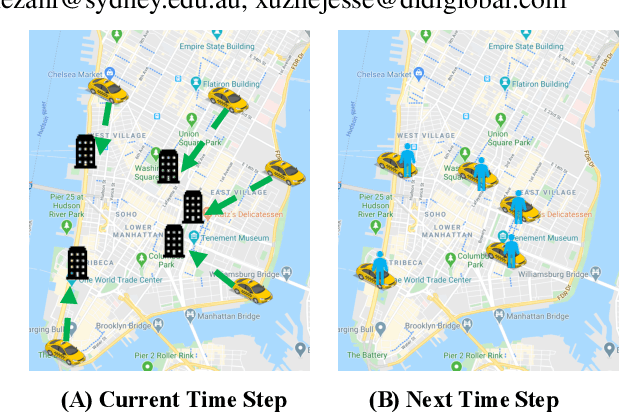

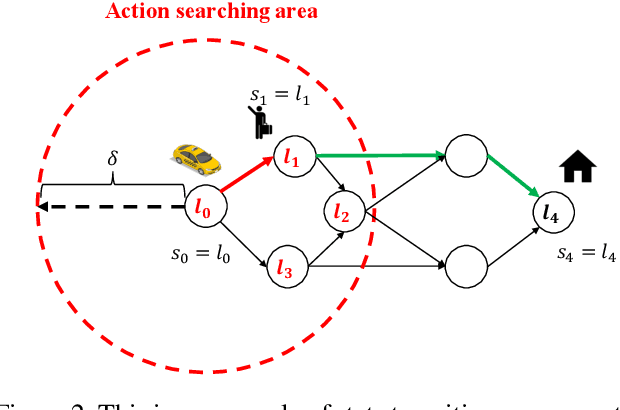
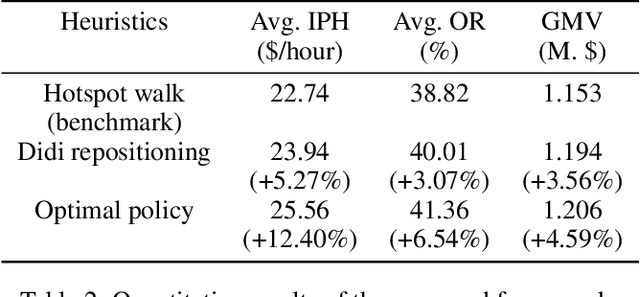
Nowadays, autonomous taxis become a highly promising transportation mode, which helps relieve traffic congestion and avoid road accidents. However, it hinders the wide implementation of this service that traditional models fail to efficiently allocate the available fleet to deal with the imbalance of supply (autonomous taxis) and demand (trips), the poor cooperation of taxis, hardly satisfied resource constraints, and on-line platform's requirements. To figure out such urgent problems from a global and more farsighted view, we employ a Constrained Multi-agent Markov Decision Processes (CMMDP) to model fleet allocation decisions, which can be easily split into sub-problems formulated as a 'Dynamic assignment problem' combining both immediate rewards and future gains. We also leverage a Column Generation algorithm to guarantee the efficiency and optimality in a large scale. Through extensive experiments, the proposed approach not only achieves remarkable improvements over the state-of-the-art benchmarks in terms of the individual's efficiency (arriving at 12.40%, 6.54% rise of income and utilization, respectively) and the platform's profit (reaching 4.59% promotion) but also reveals a time-varying fleet adjustment policy to minimize the operation cost of the platform.
A feasibility study of a hyperparameter tuning approach to automated inverse planning in radiotherapy
May 14, 2021
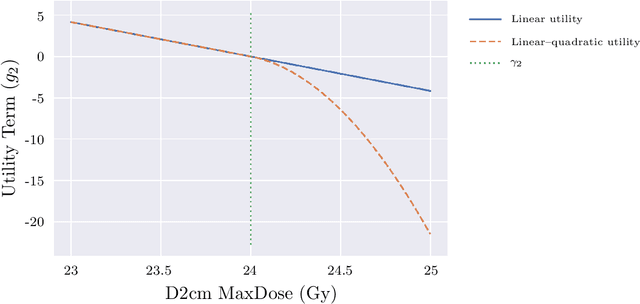
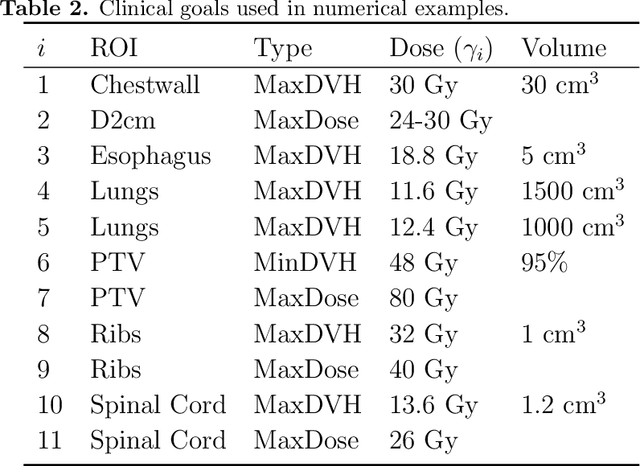
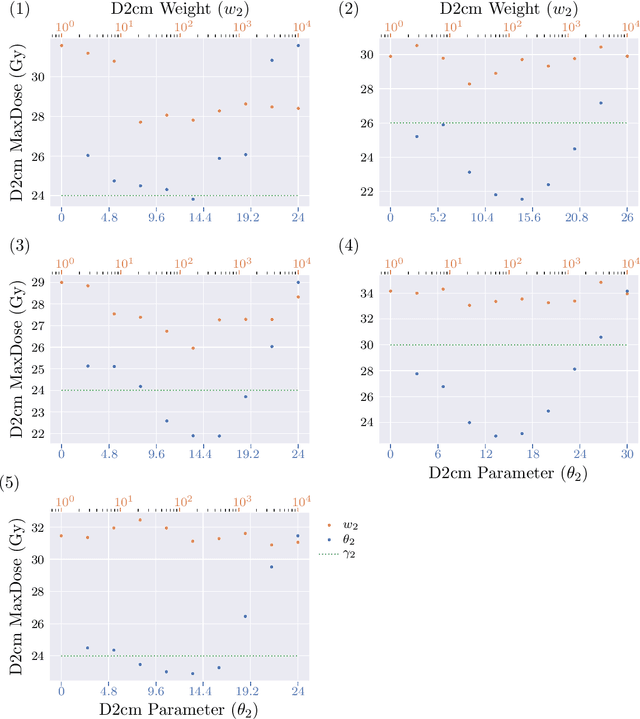
Radiotherapy inverse planning requires treatment planners to modify multiple parameters in the objective function to produce clinically acceptable plans. Due to manual steps in this process, plan quality can vary widely depending on planning time available and planner's skills. The purpose of this study is to automate the inverse planning process to reduce active planning time while maintaining plan quality. We propose a hyperparameter tuning approach for automated inverse planning, where a treatment plan utility is maximized with respect to the limit dose parameters and weights of each organ-at-risk (OAR) objective. Using 6 patient cases, we investigated the impact of the choice of dose parameters, random and Bayesian search methods, and utility function form on planning time and plan quality. For given parameters, the plan was optimized in RayStation, using the scripting interface to obtain the dose distributions deliverable. We normalized all plans to have the same target coverage and compared the OAR dose metrics in the automatically generated plans with those in the manually generated clinical plans. Using 100 samples was found to produce satisfactory plan quality, and the average planning time was 2.3 hours. The OAR doses in the automatically generated plans were lower than the clinical plans by up to 76.8%. When the OAR doses were larger than the clinical plans, they were still between 0.57% above and 98.9% below the limit doses, indicating they are clinically acceptable. For a challenging case, a dimensionality reduction strategy produced a 92.9% higher utility using only 38.5% of the time needed to optimize over the original problem. This study demonstrates our hyperparameter tuning framework for automated inverse planning can significantly reduce the treatment planner's planning time with plan quality that is similar to or better than manually generated plans.
Homogeneous Learning: Self-Attention Decentralized Deep Learning
Oct 11, 2021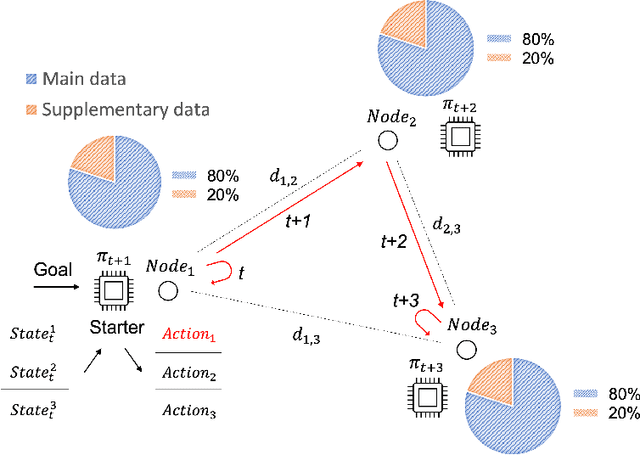
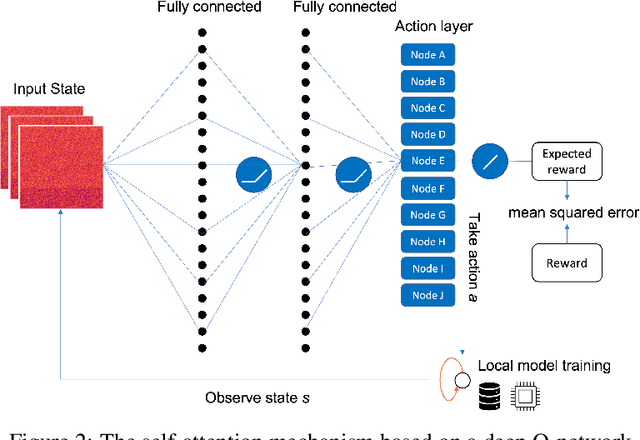
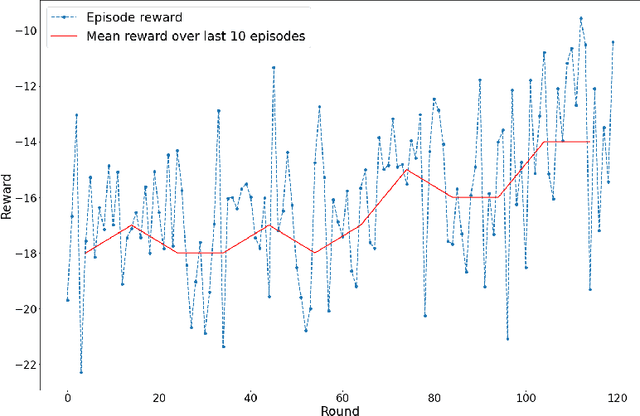
Federated learning (FL) has been facilitating privacy-preserving deep learning in many walks of life such as medical image classification, network intrusion detection, and so forth. Whereas it necessitates a central parameter server for model aggregation, which brings about delayed model communication and vulnerability to adversarial attacks. A fully decentralized architecture like Swarm Learning allows peer-to-peer communication among distributed nodes, without the central server. One of the most challenging issues in decentralized deep learning is that data owned by each node are usually non-independent and identically distributed (non-IID), causing time-consuming convergence of model training. To this end, we propose a decentralized learning model called Homogeneous Learning (HL) for tackling non-IID data with a self-attention mechanism. In HL, training performs on each round's selected node, and the trained model of a node is sent to the next selected node at the end of each round. Notably, for the selection, the self-attention mechanism leverages reinforcement learning to observe a node's inner state and its surrounding environment's state, and find out which node should be selected to optimize the training. We evaluate our method with various scenarios for an image classification task. The result suggests that HL can produce a better performance compared with standalone learning and greatly reduce both the total training rounds by 50.8% and the communication cost by 74.6% compared with random policy-based decentralized learning for training on non-IID data.
SlimYOLOv3: Narrower, Faster and Better for Real-Time UAV Applications
Jul 25, 2019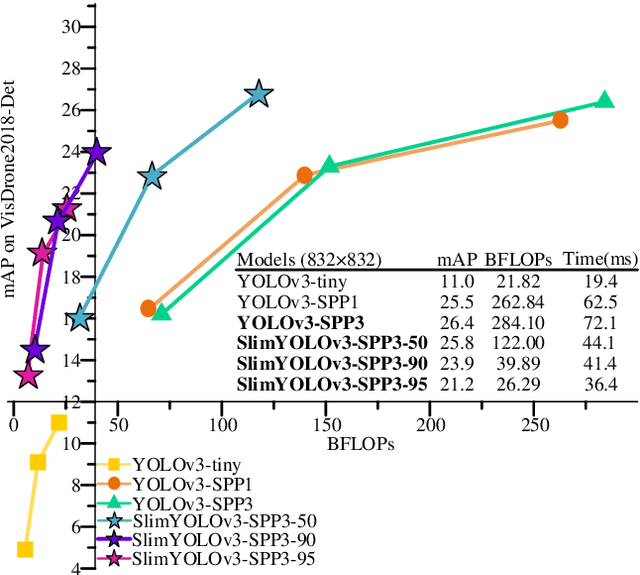
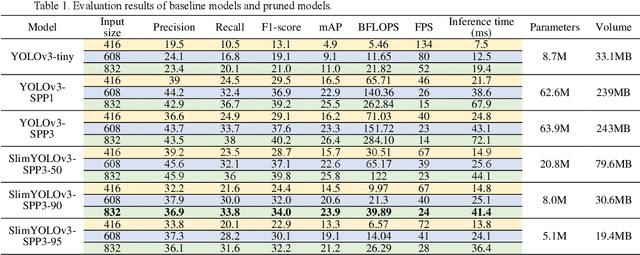
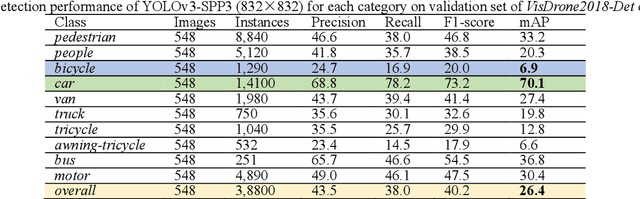
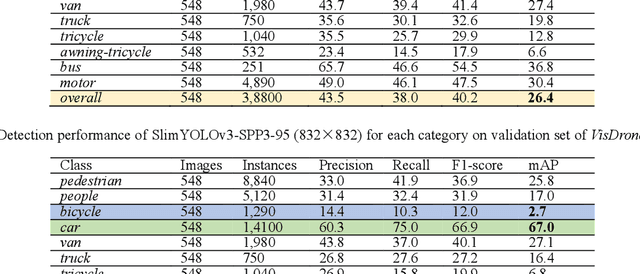
Drones or general Unmanned Aerial Vehicles (UAVs), endowed with computer vision function by on-board cameras and embedded systems, have become popular in a wide range of applications. However, real-time scene parsing through object detection running on a UAV platform is very challenging, due to limited memory and computing power of embedded devices. To deal with these challenges, in this paper we propose to learn efficient deep object detectors through channel pruning of convolutional layers. To this end, we enforce channel-level sparsity of convolutional layers by imposing L1 regularization on channel scaling factors and prune less informative feature channels to obtain "slim" object detectors. Based on such approach, we present SlimYOLOv3 with fewer trainable parameters and floating point operations (FLOPs) in comparison of original YOLOv3 (Joseph Redmon et al., 2018) as a promising solution for real-time object detection on UAVs. We evaluate SlimYOLOv3 on VisDrone2018-Det benchmark dataset; compelling results are achieved by SlimYOLOv3 in comparison of unpruned counterpart, including ~90.8% decrease of FLOPs, ~92.0% decline of parameter size, running ~2 times faster and comparable detection accuracy as YOLOv3. Experimental results with different pruning ratios consistently verify that proposed SlimYOLOv3 with narrower structure are more efficient, faster and better than YOLOv3, and thus are more suitable for real-time object detection on UAVs. Our codes are made publicly available at https://github.com/PengyiZhang/SlimYOLOv3.
No-Press Diplomacy from Scratch
Oct 06, 2021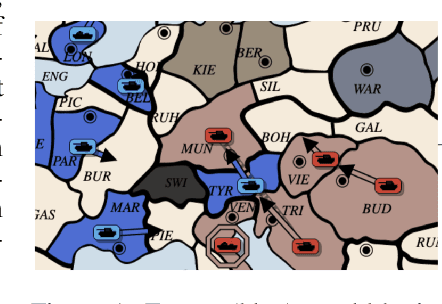


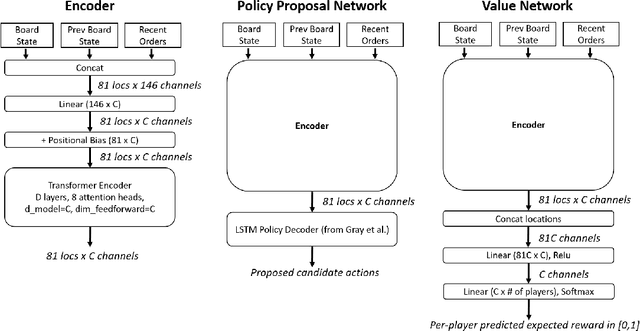
Prior AI successes in complex games have largely focused on settings with at most hundreds of actions at each decision point. In contrast, Diplomacy is a game with more than 10^20 possible actions per turn. Previous attempts to address games with large branching factors, such as Diplomacy, StarCraft, and Dota, used human data to bootstrap the policy or used handcrafted reward shaping. In this paper, we describe an algorithm for action exploration and equilibrium approximation in games with combinatorial action spaces. This algorithm simultaneously performs value iteration while learning a policy proposal network. A double oracle step is used to explore additional actions to add to the policy proposals. At each state, the target state value and policy for the model training are computed via an equilibrium search procedure. Using this algorithm, we train an agent, DORA, completely from scratch for a popular two-player variant of Diplomacy and show that it achieves superhuman performance. Additionally, we extend our methods to full-scale no-press Diplomacy and for the first time train an agent from scratch with no human data. We present evidence that this agent plays a strategy that is incompatible with human-data bootstrapped agents. This presents the first strong evidence of multiple equilibria in Diplomacy and suggests that self play alone may be insufficient for achieving superhuman performance in Diplomacy.
Deep Learning Statistical Arbitrage
Jun 08, 2021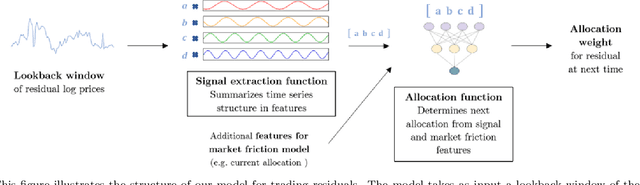
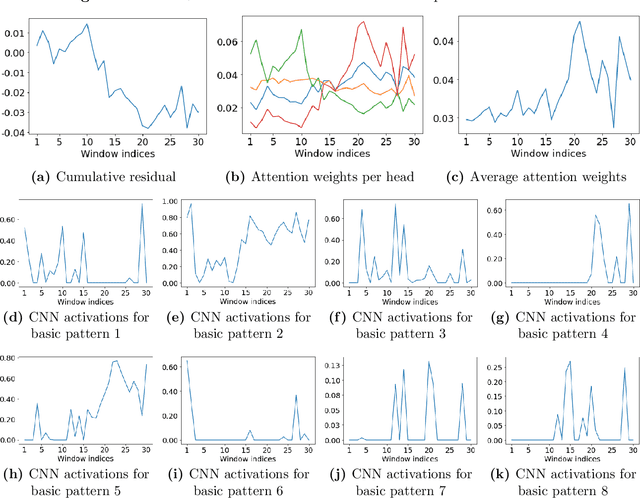
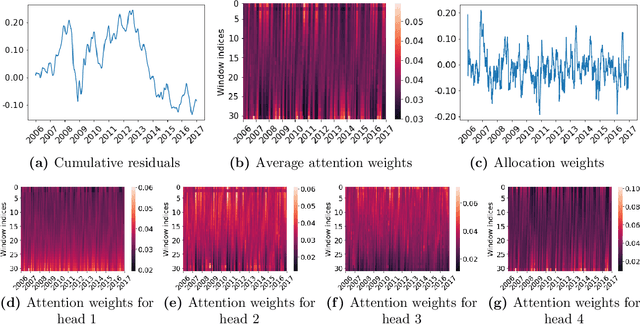
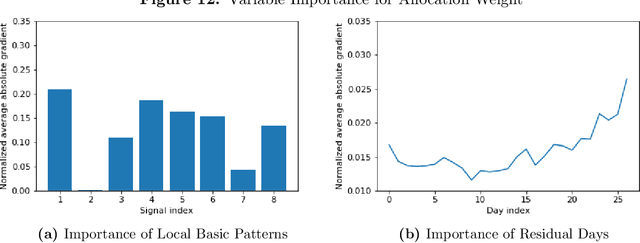
Statistical arbitrage identifies and exploits temporal price differences between similar assets. We propose a unifying conceptual framework for statistical arbitrage and develop a novel deep learning solution, which finds commonality and time-series patterns from large panels in a data-driven and flexible way. First, we construct arbitrage portfolios of similar assets as residual portfolios from conditional latent asset pricing factors. Second, we extract the time series signals of these residual portfolios with one of the most powerful machine learning time-series solutions, a convolutional transformer. Last, we use these signals to form an optimal trading policy, that maximizes risk-adjusted returns under constraints. We conduct a comprehensive empirical comparison study with daily large cap U.S. stocks. Our optimal trading strategy obtains a consistently high out-of-sample Sharpe ratio and substantially outperforms all benchmark approaches. It is orthogonal to common risk factors, and exploits asymmetric local trend and reversion patterns. Our strategies remain profitable after taking into account trading frictions and costs. Our findings suggest a high compensation for arbitrageurs to enforce the law of one price.
Mixed pooling of seasonality in time series pallet forecasting
Aug 14, 2019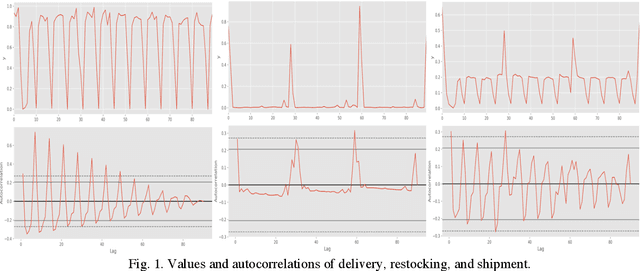
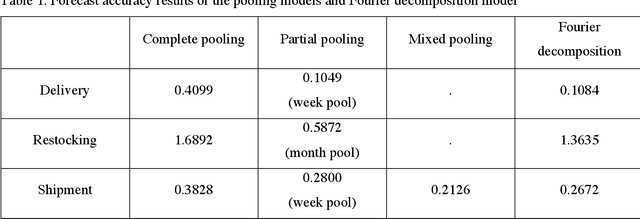
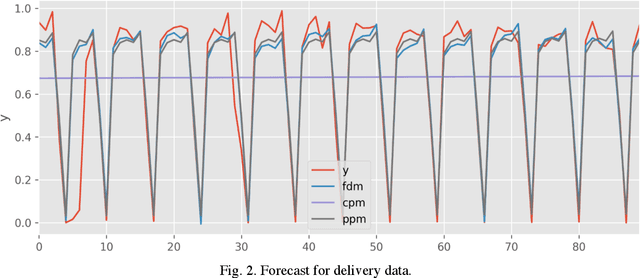
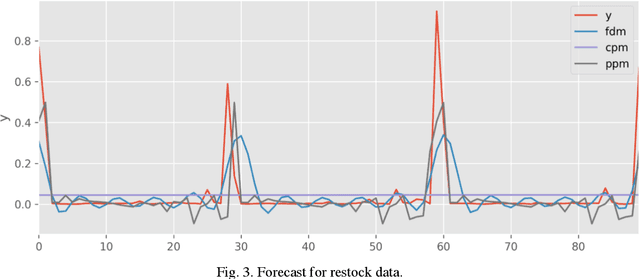
Multiple seasonal patterns play a key role in time series forecasting, especially for business time series where seasonal effects are often dramatic. Previous approaches including Fourier decomposition, exponential smoothing, and seasonal autoregressive integrated moving average (SARIMA) models do not reflect the distinct characteristics of each period in seasonal patterns, such as the unique behavior of specific days of the week in business data. We propose a multi-dimensional hierarchical model. Intermediate parameters for each seasonal period are first estimated, and a mixture of intermediate parameters is then taken, resulting in a model that successfully reflects the interactions between multiple seasonal patterns. Although this process reduces the data available for each parameter, a robust estimation can be obtained through a hierarchical Bayesian model implemented in Stan. Through this model, it becomes possible to consider both the characteristics of each seasonal period and the interactions among characteristics from multiple seasonal periods. Our new model achieved considerable improvements in prediction accuracy compared to previous models, including Fourier decomposition, which Prophet uses to model seasonality patterns. A comparison was performed on a real-world dataset of pallet transport from a national-scale logistic network.
Automatic Identification of the End-Diastolic and End-Systolic Cardiac Frames from Invasive Coronary Angiography Videos
Oct 06, 2021
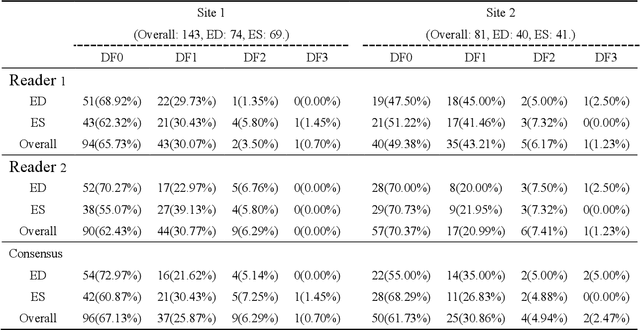
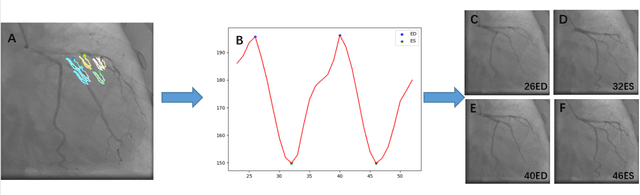
Automatic identification of proper image frames at the end-diastolic (ED) and end-systolic (ES) frames during the review of invasive coronary angiograms (ICA) is important to assess blood flow during a cardiac cycle, reconstruct the 3D arterial anatomy from bi-planar views, and generate the complementary fusion map with myocardial images. The current identification method primarily relies on visual interpretation, making it not only time-consuming but also less reproducible. In this paper, we propose a new method to automatically identify angiographic image frames associated with the ED and ES cardiac phases by using the trajectories of key vessel points (i.e. landmarks). More specifically, a detection algorithm is first used to detect the key points of coronary arteries, and then an optical flow method is employed to track the trajectories of the selected key points. The ED and ES frames are identified based on all these trajectories. Our method was tested with 62 ICA videos from two separate medical centers (22 and 9 patients in sites 1 and 2, respectively). Comparing consensus interpretations by two human expert readers, excellent agreement was achieved by the proposed algorithm: the agreement rates within a one-frame range were 92.99% and 92.73% for the automatic identification of the ED and ES image frames, respectively. In conclusion, the proposed automated method showed great potential for being an integral part of automated ICA image analysis.
Stochastic Transformer Networks with Linear Competing Units: Application to end-to-end SL Translation
Oct 01, 2021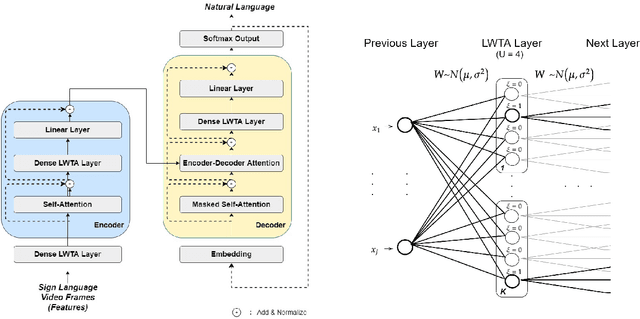
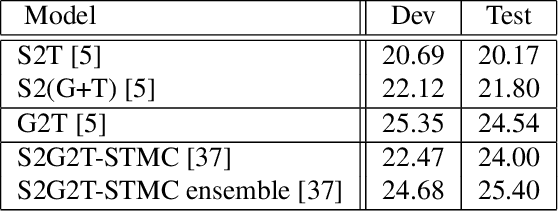


Automating sign language translation (SLT) is a challenging real world application. Despite its societal importance, though, research progress in the field remains rather poor. Crucially, existing methods that yield viable performance necessitate the availability of laborious to obtain gloss sequence groundtruth. In this paper, we attenuate this need, by introducing an end-to-end SLT model that does not entail explicit use of glosses; the model only needs text groundtruth. This is in stark contrast to existing end-to-end models that use gloss sequence groundtruth, either in the form of a modality that is recognized at an intermediate model stage, or in the form of a parallel output process, jointly trained with the SLT model. Our approach constitutes a Transformer network with a novel type of layers that combines: (i) local winner-takes-all (LWTA) layers with stochastic winner sampling, instead of conventional ReLU layers, (ii) stochastic weights with posterior distributions estimated via variational inference, and (iii) a weight compression technique at inference time that exploits estimated posterior variance to perform massive, almost lossless compression. We demonstrate that our approach can reach the currently best reported BLEU-4 score on the PHOENIX 2014T benchmark, but without making use of glosses for model training, and with a memory footprint reduced by more than 70%.