 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A stochastic metapopulation state-space approach to modeling and estimating Covid-19 spread
Jun 15, 2021
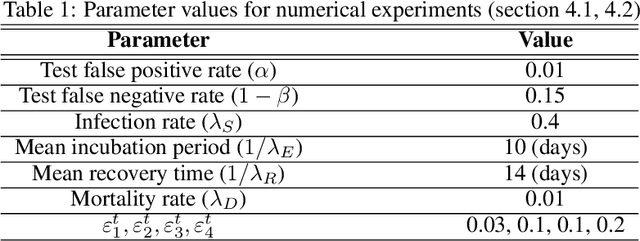
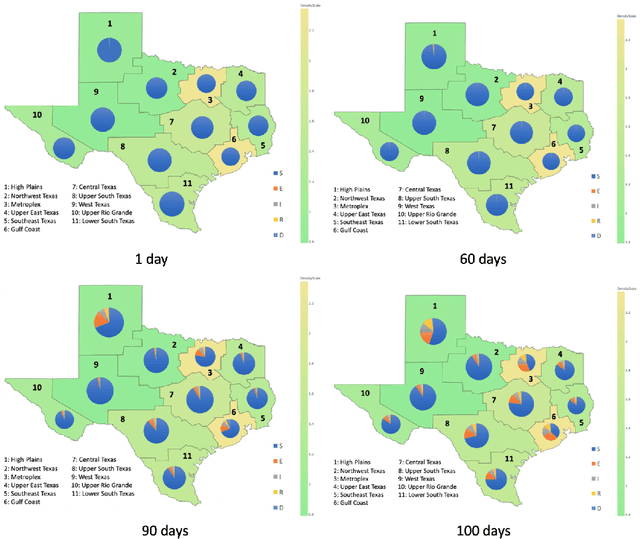

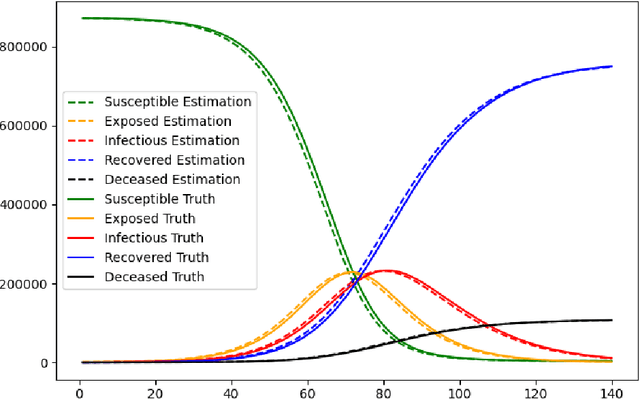
Mathematical models are widely recognized as an important tool for analyzing and understanding the dynamics of infectious disease outbreaks, predict their future trends, and evaluate public health intervention measures for disease control and elimination. We propose a novel stochastic metapopulation state-space model for COVID-19 transmission, based on a discrete-time spatio-temporal susceptible/exposed/infected/recovered/deceased (SEIRD) model. The proposed framework allows the hidden SEIRD states and unknown transmission parameters to be estimated from noisy, incomplete time series of reported epidemiological data, by application of unscented Kalman filtering (UKF), maximum-likelihood adaptive filtering, and metaheuristic optimization. Experiments using both synthetic data and real data from the Fall 2020 Covid-19 wave in the state of Texas demonstrate the effectiveness of the proposed model.
DeepStroke: An Efficient Stroke Screening Framework for Emergency Rooms with Multimodal Adversarial Deep Learning
Sep 24, 2021
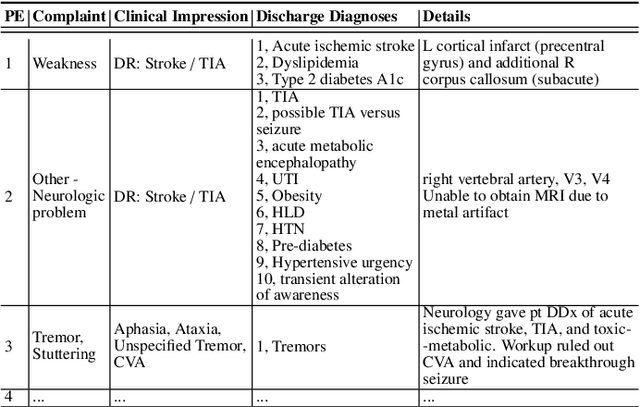
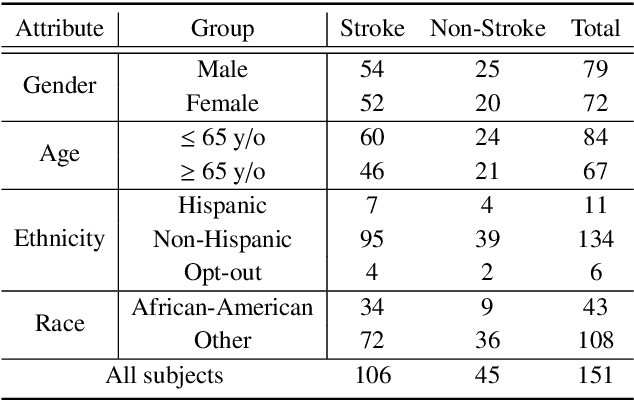
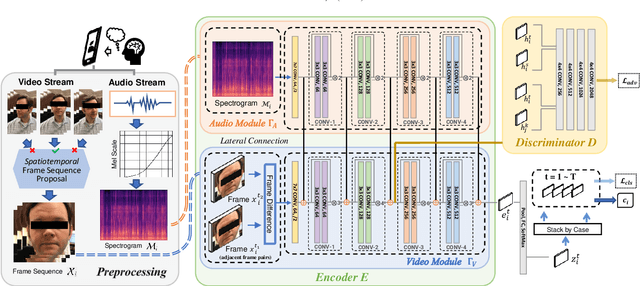
In an emergency room (ER) setting, the diagnosis of stroke is a common challenge. Due to excessive execution time and cost, an MRI scan is usually not available in the ER. Clinical tests are commonly referred to in stroke screening, but neurologists may not be immediately available. We propose a novel multimodal deep learning framework, DeepStroke, to achieve computer-aided stroke presence assessment by recognizing the patterns of facial motion incoordination and speech inability for patients with suspicion of stroke in an acute setting. Our proposed DeepStroke takes video data for local facial paralysis detection and audio data for global speech disorder analysis. It further leverages a multi-modal lateral fusion to combine the low- and high-level features and provides mutual regularization for joint training. A novel adversarial training loss is also introduced to obtain identity-independent and stroke-discriminative features. Experiments on our video-audio dataset with actual ER patients show that the proposed approach outperforms state-of-the-art models and achieves better performance than ER doctors, attaining a 6.60% higher sensitivity and maintaining 4.62% higher accuracy when specificity is aligned. Meanwhile, each assessment can be completed in less than 6 minutes, demonstrating the framework's great potential for clinical implementation.
A Time Series Analysis-Based Stock Price Prediction Using Machine Learning and Deep Learning Models
Apr 17, 2020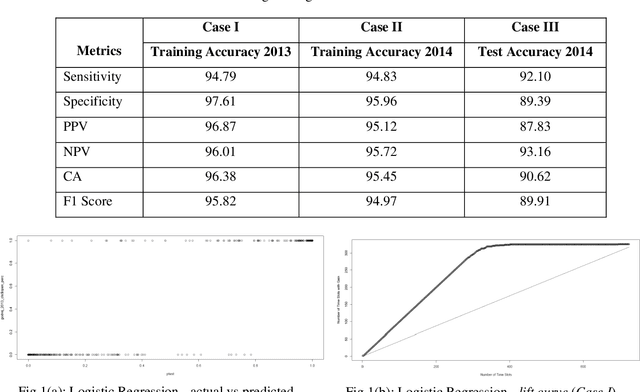
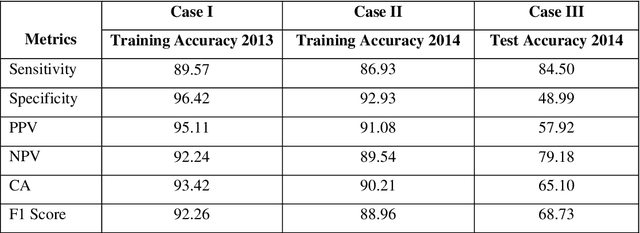
Prediction of future movement of stock prices has always been a challenging task for the researchers. While the advocates of the efficient market hypothesis (EMH) believe that it is impossible to design any predictive framework that can accurately predict the movement of stock prices, there are seminal work in the literature that have clearly demonstrated that the seemingly random movement patterns in the time series of a stock price can be predicted with a high level of accuracy. Design of such predictive models requires choice of appropriate variables, right transformation methods of the variables, and tuning of the parameters of the models. In this work, we present a very robust and accurate framework of stock price prediction that consists of an agglomeration of statistical, machine learning and deep learning models. We use the daily stock price data, collected at five minutes interval of time, of a very well known company that is listed in the National Stock Exchange (NSE) of India. The granular data is aggregated into three slots in a day, and the aggregated data is used for building and training the forecasting models. We contend that the agglomerative approach of model building that uses a combination of statistical, machine learning, and deep learning approaches, can very effectively learn from the volatile and random movement patterns in a stock price data. We build eight classification and eight regression models based on statistical and machine learning approaches. In addition to these models, a deep learning regression model using a long-and-short-term memory (LSTM) network is also built. Extensive results have been presented on the performance of these models, and the results are critically analyzed.
* 46 Pages, 36 Figures, 21 Tables
Unlocking the potential of deep learning for marine ecology: overview, applications, and outlook
Sep 29, 2021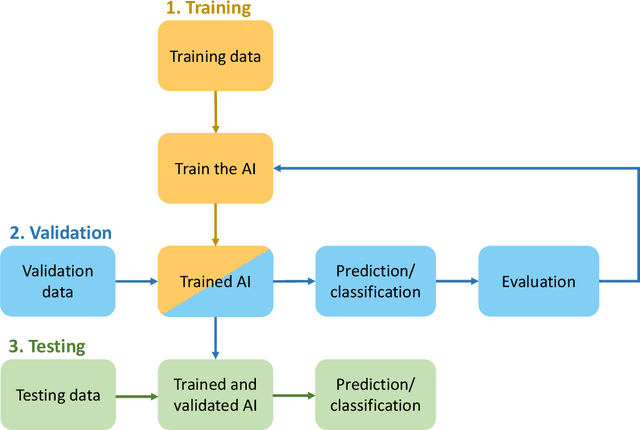

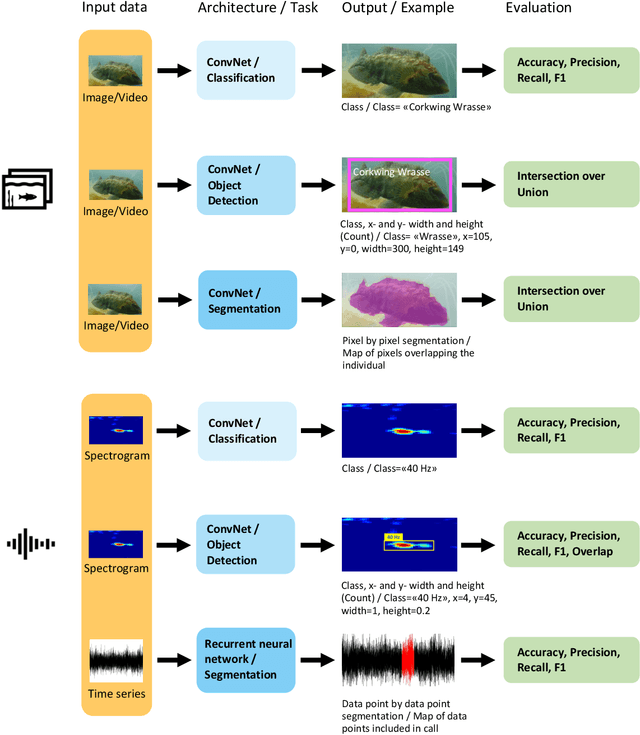
The deep learning revolution is touching all scientific disciplines and corners of our lives as a means of harnessing the power of big data. Marine ecology is no exception. These new methods provide analysis of data from sensors, cameras, and acoustic recorders, even in real time, in ways that are reproducible and rapid. Off-the-shelf algorithms can find, count, and classify species from digital images or video and detect cryptic patterns in noisy data. Using these opportunities requires collaboration across ecological and data science disciplines, which can be challenging to initiate. To facilitate these collaborations and promote the use of deep learning towards ecosystem-based management of the sea, this paper aims to bridge the gap between marine ecologists and computer scientists. We provide insight into popular deep learning approaches for ecological data analysis in plain language, focusing on the techniques of supervised learning with deep neural networks, and illustrate challenges and opportunities through established and emerging applications of deep learning to marine ecology. We use established and future-looking case studies on plankton, fishes, marine mammals, pollution, and nutrient cycling that involve object detection, classification, tracking, and segmentation of visualized data. We conclude with a broad outlook of the field's opportunities and challenges, including potential technological advances and issues with managing complex data sets.
Adversarial Representation Learning With Closed-Form Solvers
Sep 12, 2021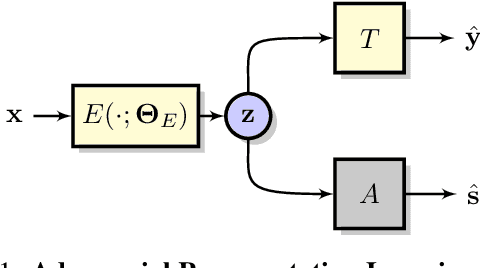
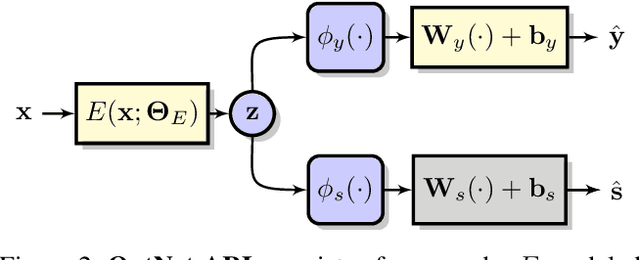
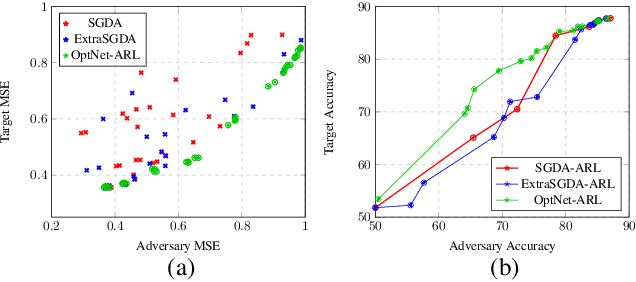
Adversarial representation learning aims to learn data representations for a target task while removing unwanted sensitive information at the same time. Existing methods learn model parameters iteratively through stochastic gradient descent-ascent, which is often unstable and unreliable in practice. To overcome this challenge, we adopt closed-form solvers for the adversary and target task. We model them as kernel ridge regressors and analytically determine an upper-bound on the optimal dimensionality of representation. Our solution, dubbed OptNet-ARL, reduces to a stable one one-shot optimization problem that can be solved reliably and efficiently. OptNet-ARL can be easily generalized to the case of multiple target tasks and sensitive attributes. Numerical experiments, on both small and large scale datasets, show that, from an optimization perspective, OptNet-ARL is stable and exhibits three to five times faster convergence. Performance wise, when the target and sensitive attributes are dependent, OptNet-ARL learns representations that offer a better trade-off front between (a) utility and bias for fair classification and (b) utility and privacy by mitigating leakage of private information than existing solutions.
Autoregressive-Model-Based Methods for Online Time Series Prediction with Missing Values: an Experimental Evaluation
Aug 27, 2019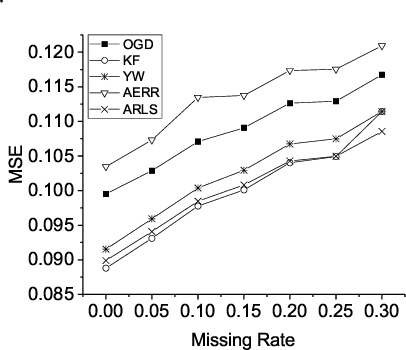
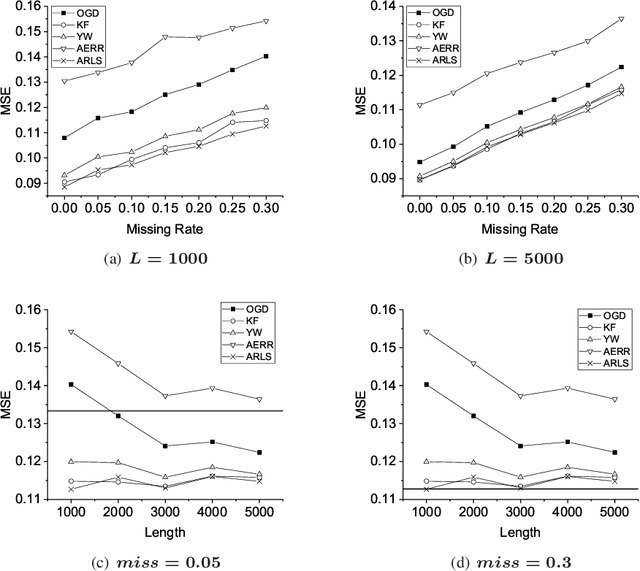
Time series prediction with missing values is an important problem of time series analysis since complete data is usually hard to obtain in many real-world applications. To model the generation of time series, autoregressive (AR) model is a basic and widely used one, which assumes that each observation in the time series is a noisy linear combination of some previous observations along with a constant shift. To tackle the problem of prediction with missing values, a number of methods were proposed based on various data models. For real application scenarios, how do these methods perform over different types of time series with different levels of data missing remains to be investigated. In this paper, we focus on online methods for AR-model-based time series prediction with missing values. We adapted five mainstream methods to fit in such a scenario. We make detailed discussion on each of them by introducing their core ideas about how to estimate the AR coefficients and their different strategies to deal with missing values. We also present algorithmic implementations for better understanding. In order to comprehensively evaluate these methods and do the comparison, we conduct experiments with various configurations of relative parameters over both synthetic and real data. From the experimental results, we derived several noteworthy conclusions and shows that imputation is a simple but reliable strategy to handle missing values in online prediction tasks.
Nowcasting-Nets: Deep Neural Network Structures for Precipitation Nowcasting Using IMERG
Aug 16, 2021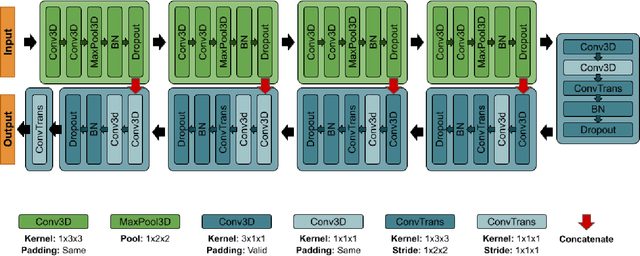
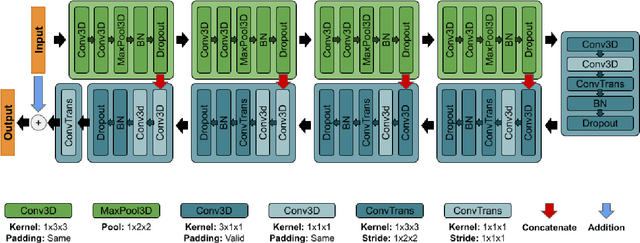
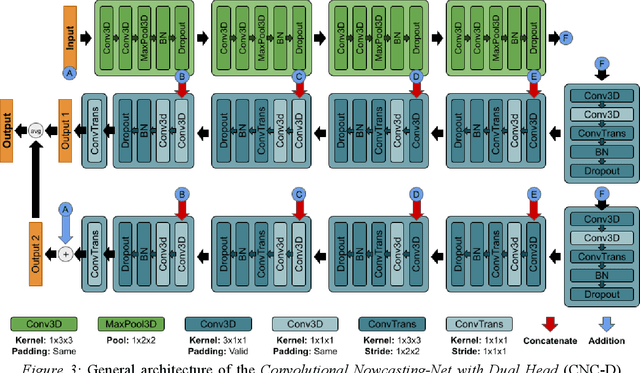
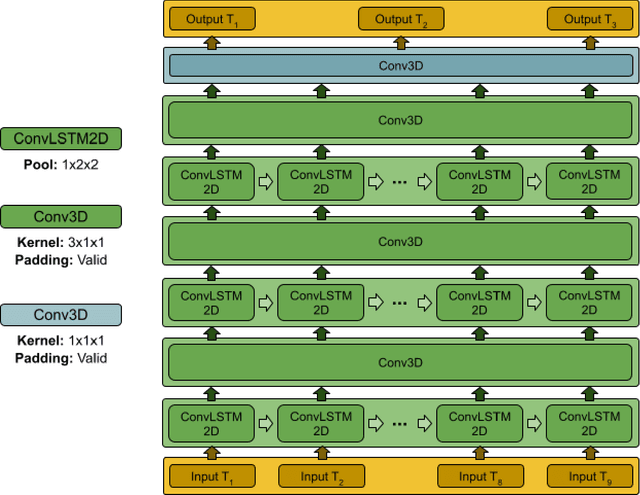
Accurate and timely estimation of precipitation is critical for issuing hazard warnings (e.g., for flash floods or landslides). Current remotely sensed precipitation products have a few hours of latency, associated with the acquisition and processing of satellite data. By applying a robust nowcasting system to these products, it is (in principle) possible to reduce this latency and improve their applicability, value, and impact. However, the development of such a system is complicated by the chaotic nature of the atmosphere, and the consequent rapid changes that can occur in the structures of precipitation systems In this work, we develop two approaches (hereafter referred to as Nowcasting-Nets) that use Recurrent and Convolutional deep neural network structures to address the challenge of precipitation nowcasting. A total of five models are trained using Global Precipitation Measurement (GPM) Integrated Multi-satellitE Retrievals for GPM (IMERG) precipitation data over the Eastern Contiguous United States (CONUS) and then tested against independent data for the Eastern and Western CONUS. The models were designed to provide forecasts with a lead time of up to 1.5 hours and, by using a feedback loop approach, the ability of the models to extend the forecast time to 4.5 hours was also investigated. Model performance was compared against the Random Forest (RF) and Linear Regression (LR) machine learning methods, and also against a persistence benchmark (BM) that used the most recent observation as the forecast. Independent IMERG observations were used as a reference, and experiments were conducted to examine both overall statistics and case studies involving specific precipitation events. Overall, the forecasts provided by the Nowcasting-Net models are superior, with the Convolutional Nowcasting Network with Residual Head (CNC-R) achieving 25%, 28%, and 46% improvement in the test ...
Extracting Event Temporal Relations via Hyperbolic Geometry
Sep 12, 2021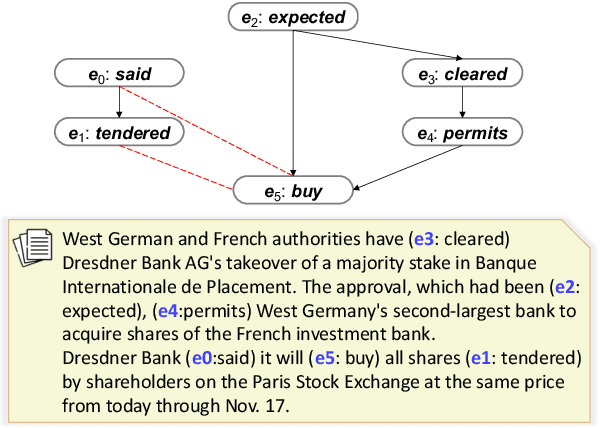
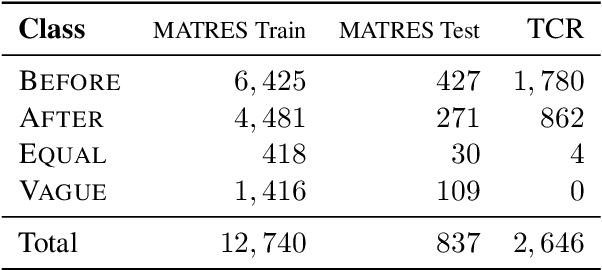

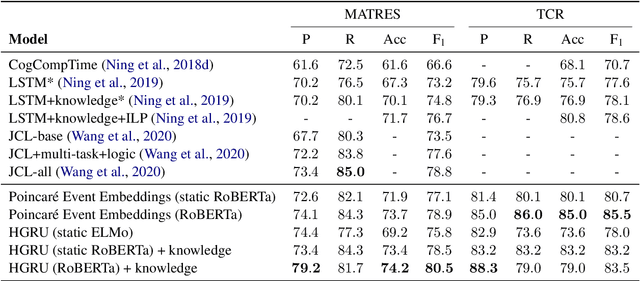
Detecting events and their evolution through time is a crucial task in natural language understanding. Recent neural approaches to event temporal relation extraction typically map events to embeddings in the Euclidean space and train a classifier to detect temporal relations between event pairs. However, embeddings in the Euclidean space cannot capture richer asymmetric relations such as event temporal relations. We thus propose to embed events into hyperbolic spaces, which are intrinsically oriented at modeling hierarchical structures. We introduce two approaches to encode events and their temporal relations in hyperbolic spaces. One approach leverages hyperbolic embeddings to directly infer event relations through simple geometrical operations. In the second one, we devise an end-to-end architecture composed of hyperbolic neural units tailored for the temporal relation extraction task. Thorough experimental assessments on widely used datasets have shown the benefits of revisiting the tasks on a different geometrical space, resulting in state-of-the-art performance on several standard metrics. Finally, the ablation study and several qualitative analyses highlighted the rich event semantics implicitly encoded into hyperbolic spaces.
Targeted Gradient Descent: A Novel Method for Convolutional Neural Networks Fine-tuning and Online-learning
Sep 29, 2021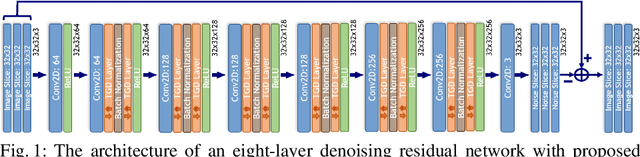
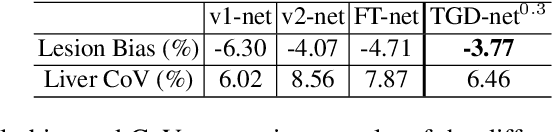
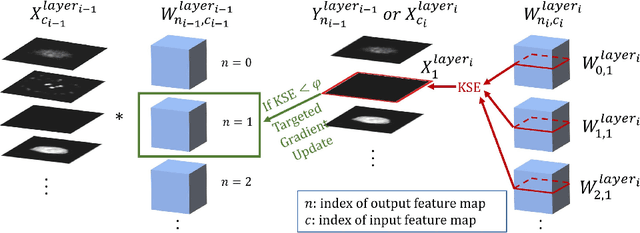

A convolutional neural network (ConvNet) is usually trained and then tested using images drawn from the same distribution. To generalize a ConvNet to various tasks often requires a complete training dataset that consists of images drawn from different tasks. In most scenarios, it is nearly impossible to collect every possible representative dataset as a priori. The new data may only become available after the ConvNet is deployed in clinical practice. ConvNet, however, may generate artifacts on out-of-distribution testing samples. In this study, we present Targeted Gradient Descent (TGD), a novel fine-tuning method that can extend a pre-trained network to a new task without revisiting data from the previous task while preserving the knowledge acquired from previous training. To a further extent, the proposed method also enables online learning of patient-specific data. The method is built on the idea of reusing a pre-trained ConvNet's redundant kernels to learn new knowledge. We compare the performance of TGD to several commonly used training approaches on the task of Positron emission tomography (PET) image denoising. Results from clinical images show that TGD generated results on par with training-from-scratch while significantly reducing data preparation and network training time. More importantly, it enables online learning on the testing study to enhance the network's generalization capability in real-world applications.
FLASHE: Additively Symmetric Homomorphic Encryption for Cross-Silo Federated Learning
Sep 02, 2021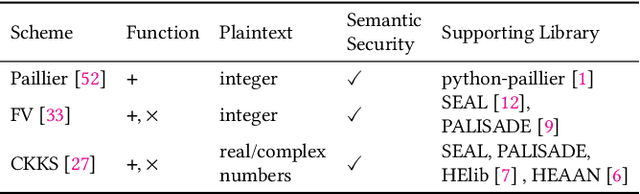
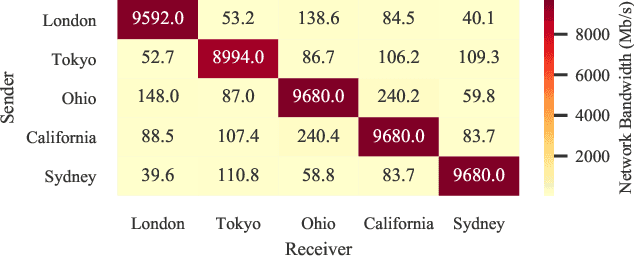
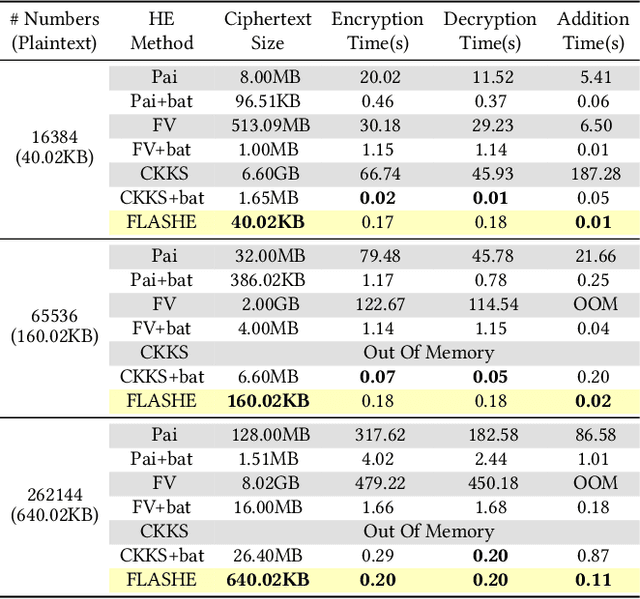
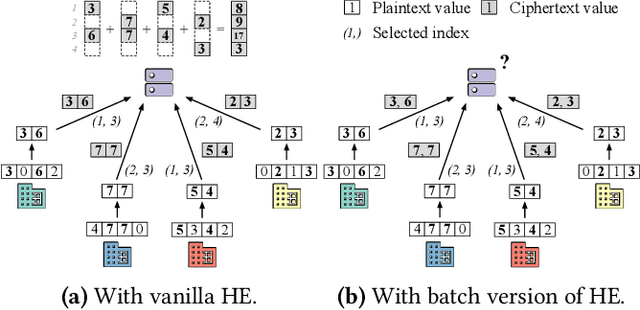
Homomorphic encryption (HE) is a promising privacy-preserving technique for cross-silo federated learning (FL), where organizations perform collaborative model training on decentralized data. Despite the strong privacy guarantee, general HE schemes result in significant computation and communication overhead. Prior works employ batch encryption to address this problem, but it is still suboptimal in mitigating communication overhead and is incompatible with sparsification techniques. In this paper, we propose FLASHE, an HE scheme tailored for cross-silo FL. To capture the minimum requirements of security and functionality, FLASHE drops the asymmetric-key design and only involves modular addition operations with random numbers. Depending on whether to accommodate sparsification techniques, FLASHE is optimized in computation efficiency with different approaches. We have implemented FLASHE as a pluggable module atop FATE, an industrial platform for cross-silo FL. Compared to plaintext training, FLASHE slightly increases the training time by $\leq6\%$, with no communication overhead.