 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On the Explanatory Power of Decision Trees
Aug 11, 2021
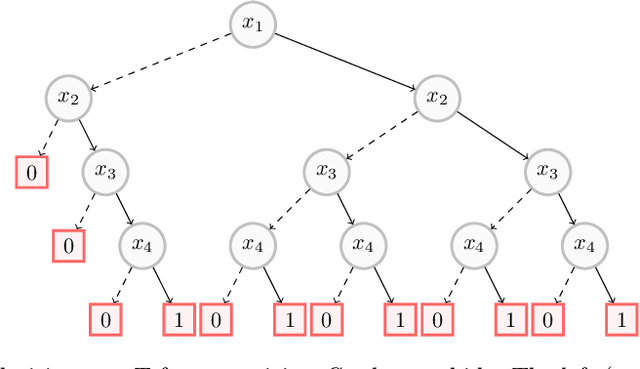
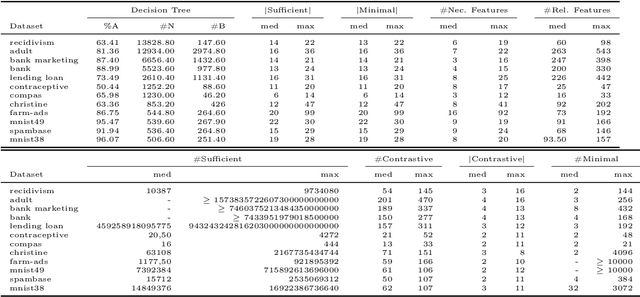
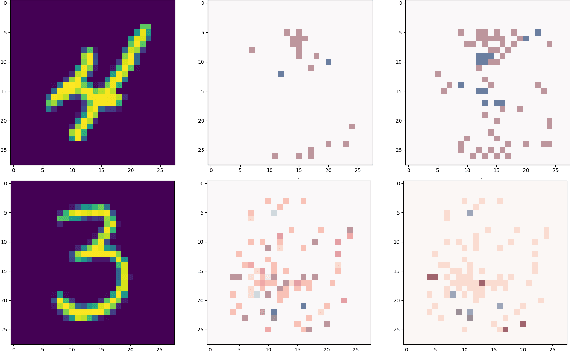
Decision trees have long been recognized as models of choice in sensitive applications where interpretability is of paramount importance. In this paper, we examine the computational ability of Boolean decision trees in deriving, minimizing, and counting sufficient reasons and contrastive explanations. We prove that the set of all sufficient reasons of minimal size for an instance given a decision tree can be exponentially larger than the size of the input (the instance and the decision tree). Therefore, generating the full set of sufficient reasons can be out of reach. In addition, computing a single sufficient reason does not prove enough in general; indeed, two sufficient reasons for the same instance may differ on many features. To deal with this issue and generate synthetic views of the set of all sufficient reasons, we introduce the notions of relevant features and of necessary features that characterize the (possibly negated) features appearing in at least one or in every sufficient reason, and we show that they can be computed in polynomial time. We also introduce the notion of explanatory importance, that indicates how frequent each (possibly negated) feature is in the set of all sufficient reasons. We show how the explanatory importance of a feature and the number of sufficient reasons can be obtained via a model counting operation, which turns out to be practical in many cases. We also explain how to enumerate sufficient reasons of minimal size. We finally show that, unlike sufficient reasons, the set of all contrastive explanations for an instance given a decision tree can be derived, minimized and counted in polynomial time.
Multi-modal Affect Analysis using standardized data within subjects in the Wild
Jul 08, 2021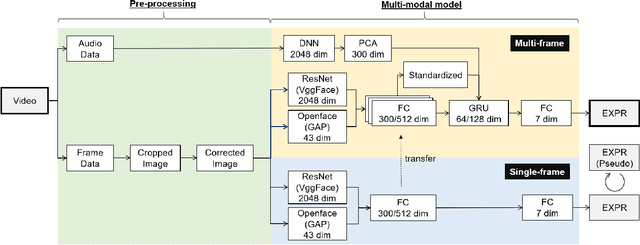


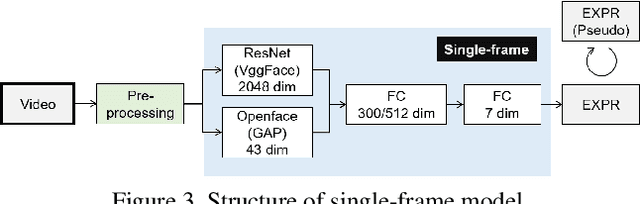
Human affective recognition is an important factor in human-computer interaction. However, the method development with in-the-wild data is not yet accurate enough for practical usage. In this paper, we introduce the affective recognition method focusing on facial expression (EXP) and valence-arousal calculation that was submitted to the Affective Behavior Analysis in-the-wild (ABAW) 2021 Contest. When annotating facial expressions from a video, we thought that it would be judged not only from the features common to all people, but also from the relative changes in the time series of individuals. Therefore, after learning the common features for each frame, we constructed a facial expression estimation model and valence-arousal model using time-series data after combining the common features and the standardized features for each video. Furthermore, the above features were learned using multi-modal data such as image features, AU, Head pose, and Gaze. In the validation set, our model achieved a facial expression score of 0.546. These verification results reveal that our proposed framework can improve estimation accuracy and robustness effectively.
Adversarial Auto-Encoding for Packet Loss Concealment
Jul 08, 2021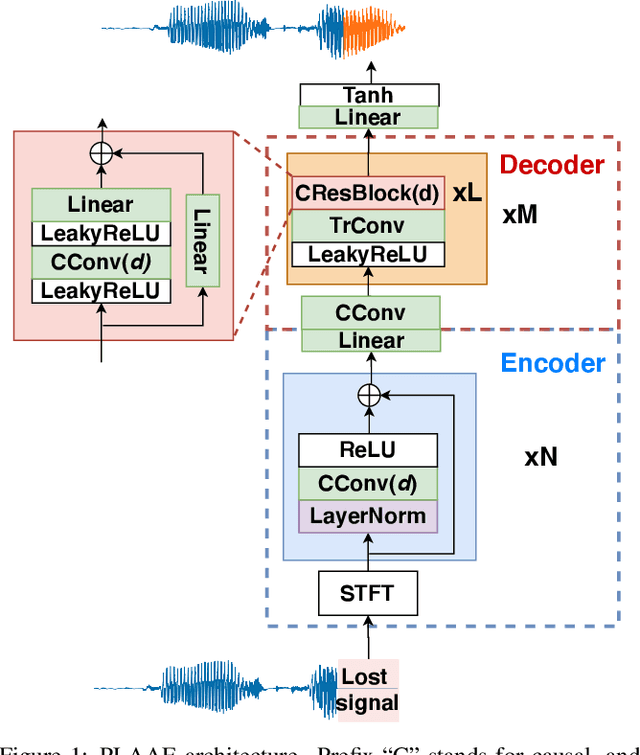
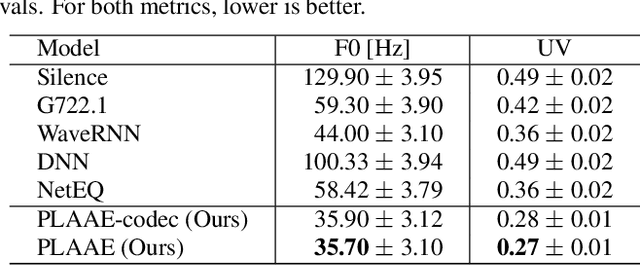
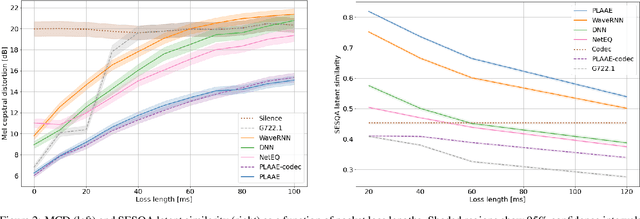
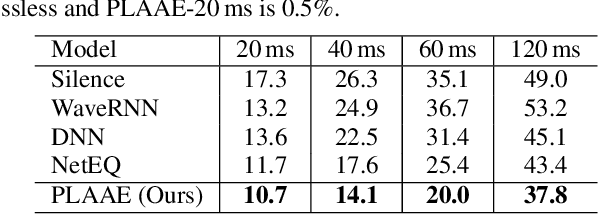
Communication technologies like voice over IP operate under constrained real-time conditions, with voice packets being subject to delays and losses from the network. In such cases, the packet loss concealment (PLC) algorithm reconstructs missing frames until a new real packet is received. Recently, autoregressive deep neural networks have been shown to surpass the quality of signal processing methods for PLC, specially for long-term predictions beyond 60 ms. In this work, we propose a non-autoregressive adversarial auto-encoder, named PLAAE, to perform real-time PLC in the waveform domain. PLAAE has a causal convolutional structure, and it learns in an auto-encoder fashion to reconstruct signals with gaps, with the help of an adversarial loss. During inference, it is able to predict smooth and coherent continuations of such gaps in a single feed-forward step, as opposed to autoregressive models. Our evaluation highlights the superiority of PLAAE over two classic PLCs and two deep autoregressive models in terms of spectral and intonation reconstruction, perceptual quality, and intelligibility.
FLASHE: Additively Symmetric Homomorphic Encryption for Cross-Silo Federated Learning
Sep 02, 2021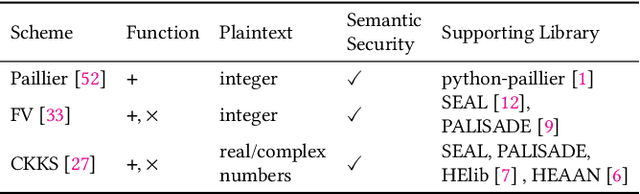
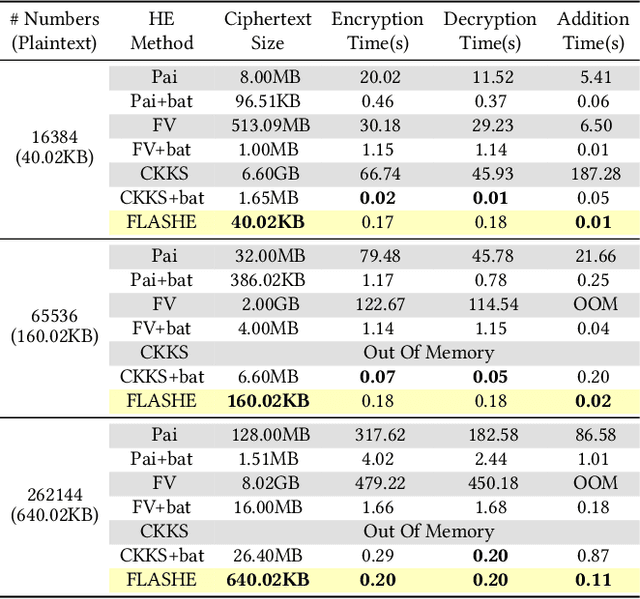
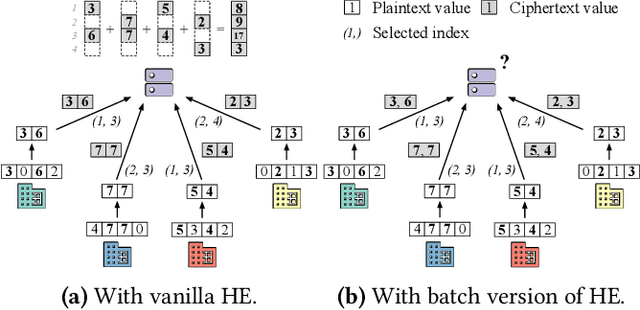
Homomorphic encryption (HE) is a promising privacy-preserving technique for cross-silo federated learning (FL), where organizations perform collaborative model training on decentralized data. Despite the strong privacy guarantee, general HE schemes result in significant computation and communication overhead. Prior works employ batch encryption to address this problem, but it is still suboptimal in mitigating communication overhead and is incompatible with sparsification techniques. In this paper, we propose FLASHE, an HE scheme tailored for cross-silo FL. To capture the minimum requirements of security and functionality, FLASHE drops the asymmetric-key design and only involves modular addition operations with random numbers. Depending on whether to accommodate sparsification techniques, FLASHE is optimized in computation efficiency with different approaches. We have implemented FLASHE as a pluggable module atop FATE, an industrial platform for cross-silo FL. Compared to plaintext training, FLASHE slightly increases the training time by $\leq6\%$, with no communication overhead.
An integrated light management system with real-time light measurement and human perception
Apr 17, 2020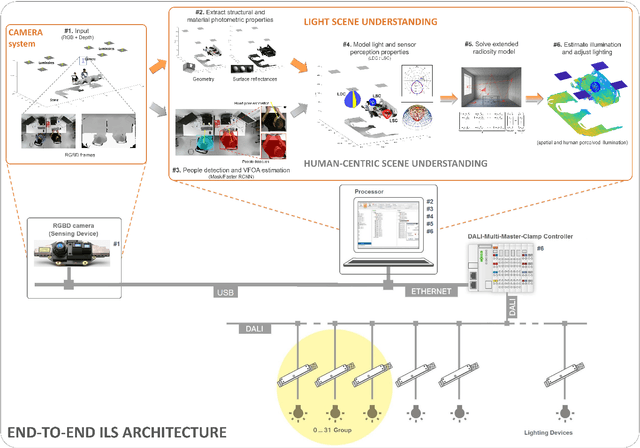
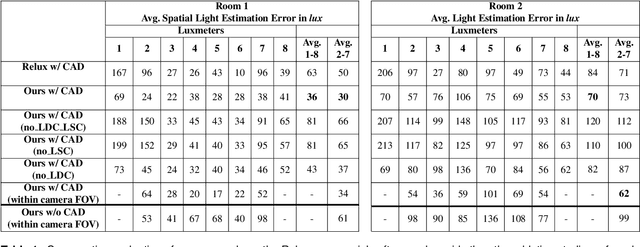

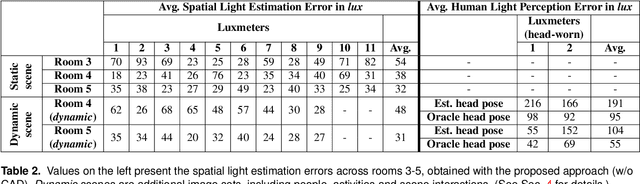
Illumination is important for well-being, productivity and safety across several environments, including offices, retail shops and industrial warehouses. Current techniques for setting up lighting require extensive and expert support and need to be repeated if the scene changes. Here we propose the first fully-automated light management system (LMS) which measures lighting in real-time, leveraging an RGBD sensor and a radiosity-based light propagation model. Thanks to the integration of light distribution and perception curves into the radiosity, we outperform a commercial software (Relux) on a newly introduced dataset. Furthermore, our proposed LMS is the first to estimate both the presence and the attention of the people in the environment, as well as their light perception. Our new LMS adapts therefore lighting to the scene and human activity and it is capable of saving up to 66%, as we experimentally quantify,without compromising the lighting quality.
Nowcasting-Nets: Deep Neural Network Structures for Precipitation Nowcasting Using IMERG
Aug 16, 2021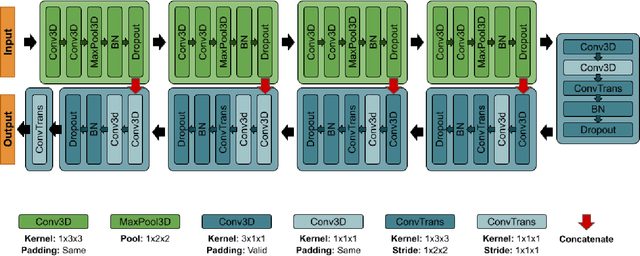
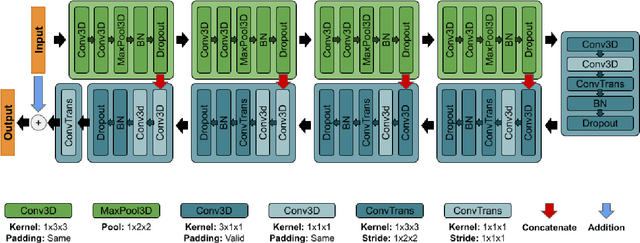
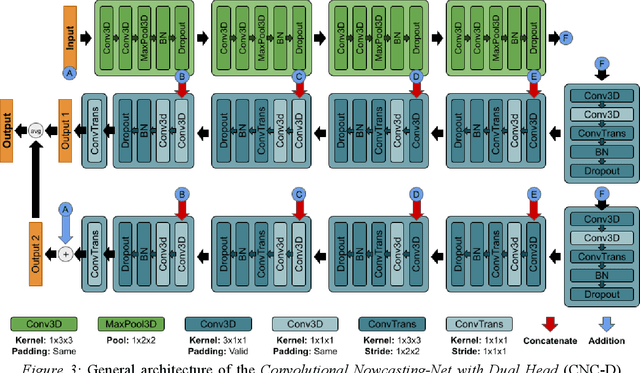
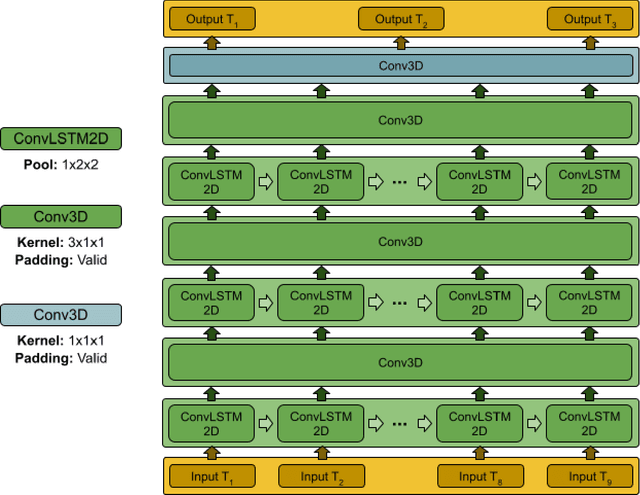
Accurate and timely estimation of precipitation is critical for issuing hazard warnings (e.g., for flash floods or landslides). Current remotely sensed precipitation products have a few hours of latency, associated with the acquisition and processing of satellite data. By applying a robust nowcasting system to these products, it is (in principle) possible to reduce this latency and improve their applicability, value, and impact. However, the development of such a system is complicated by the chaotic nature of the atmosphere, and the consequent rapid changes that can occur in the structures of precipitation systems In this work, we develop two approaches (hereafter referred to as Nowcasting-Nets) that use Recurrent and Convolutional deep neural network structures to address the challenge of precipitation nowcasting. A total of five models are trained using Global Precipitation Measurement (GPM) Integrated Multi-satellitE Retrievals for GPM (IMERG) precipitation data over the Eastern Contiguous United States (CONUS) and then tested against independent data for the Eastern and Western CONUS. The models were designed to provide forecasts with a lead time of up to 1.5 hours and, by using a feedback loop approach, the ability of the models to extend the forecast time to 4.5 hours was also investigated. Model performance was compared against the Random Forest (RF) and Linear Regression (LR) machine learning methods, and also against a persistence benchmark (BM) that used the most recent observation as the forecast. Independent IMERG observations were used as a reference, and experiments were conducted to examine both overall statistics and case studies involving specific precipitation events. Overall, the forecasts provided by the Nowcasting-Net models are superior, with the Convolutional Nowcasting Network with Residual Head (CNC-R) achieving 25%, 28%, and 46% improvement in the test ...
Complex Temporal Question Answering on Knowledge Graphs
Sep 18, 2021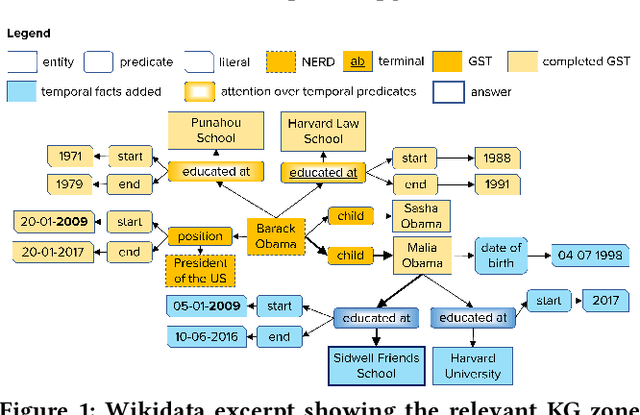

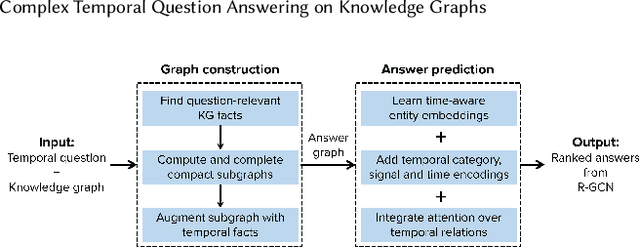
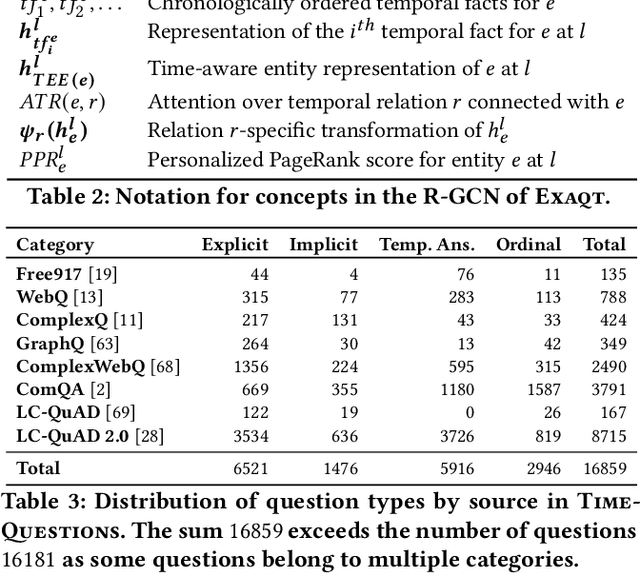
Question answering over knowledge graphs (KG-QA) is a vital topic in IR. Questions with temporal intent are a special class of practical importance, but have not received much attention in research. This work presents EXAQT, the first end-to-end system for answering complex temporal questions that have multiple entities and predicates, and associated temporal conditions. EXAQT answers natural language questions over KGs in two stages, one geared towards high recall, the other towards precision at top ranks. The first step computes question-relevant compact subgraphs within the KG, and judiciously enhances them with pertinent temporal facts, using Group Steiner Trees and fine-tuned BERT models. The second step constructs relational graph convolutional networks (R-GCNs) from the first step's output, and enhances the R-GCNs with time-aware entity embeddings and attention over temporal relations. We evaluate EXAQT on TimeQuestions, a large dataset of 16k temporal questions we compiled from a variety of general purpose KG-QA benchmarks. Results show that EXAQT outperforms three state-of-the-art systems for answering complex questions over KGs, thereby justifying specialized treatment of temporal QA.
Proof of Reference(PoR): A unified informetrics based consensus mechanism
Jul 01, 2021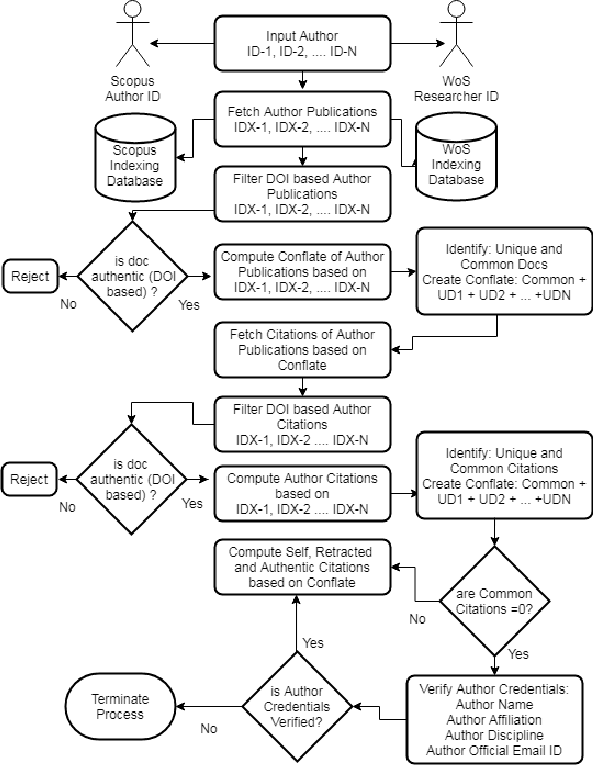
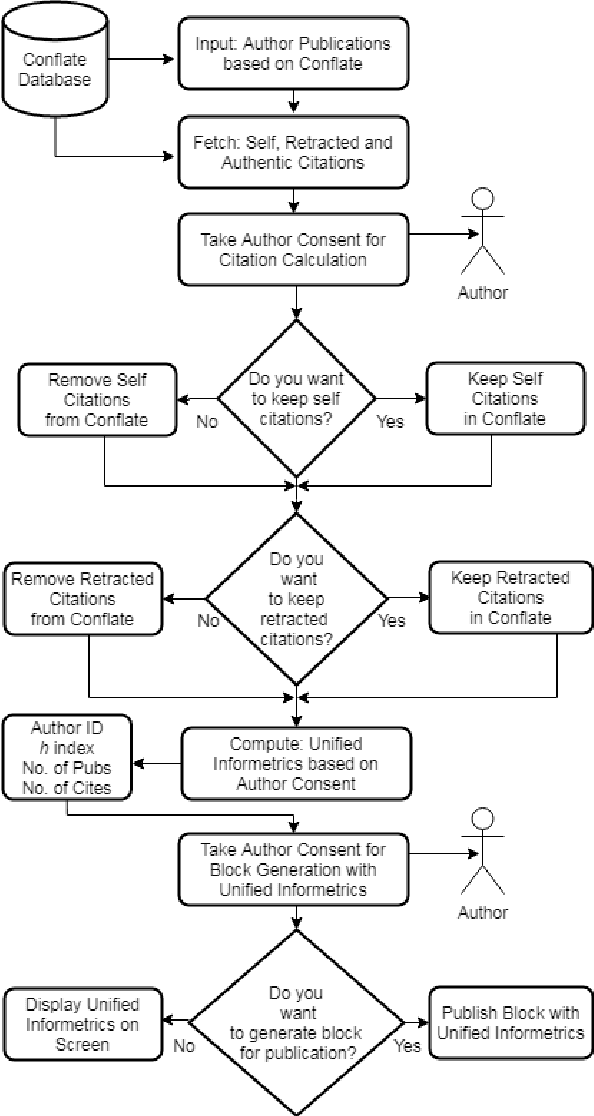

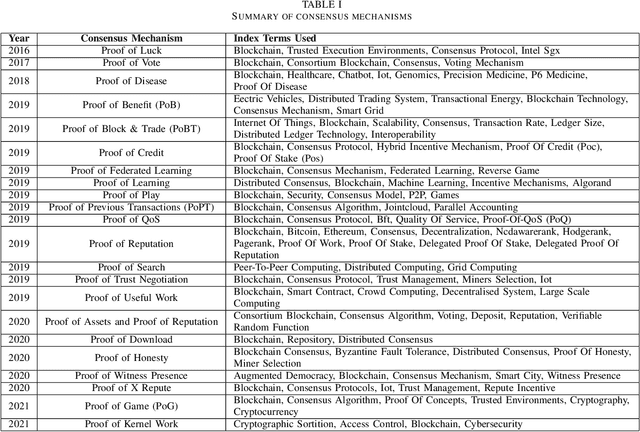
Bibliometrics is useful to analyze the research impact for measuring the research quality. Different bibliographic databases like Scopus, Web of Science, Google Scholar etc. are accessed for evaluating the trend of publications and citations from time to time. Some of these databases are free and some are subscription based. Its always debatable that which bibliographic database is better and in what terms. To provide an optimal solution to availability of multiple bibliographic databases, we have implemented a single authentic database named as ``conflate'' which can be used for fetching publication and citation trend of an author. To further strengthen the generated database and to provide the transparent system to the stakeholders, a consensus mechanism ``proof of reference (PoR)'' is proposed. Due to three consent based checks implemented in PoR, we feel that it could be considered as a authentic and honest citation data source for the calculation of unified informetrics for an author.
Pump and Dumps in the Bitcoin Era: Real Time Detection of Cryptocurrency Market Manipulations
May 04, 2020
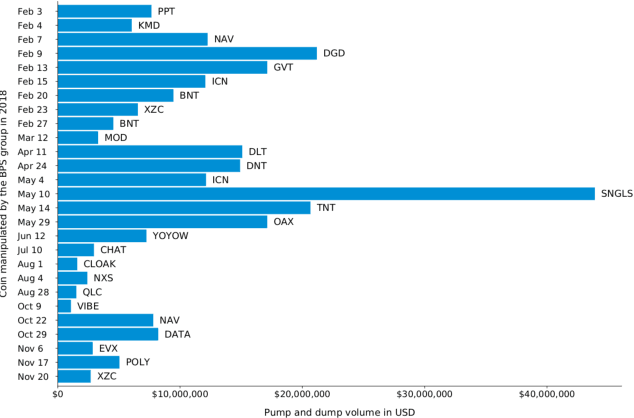
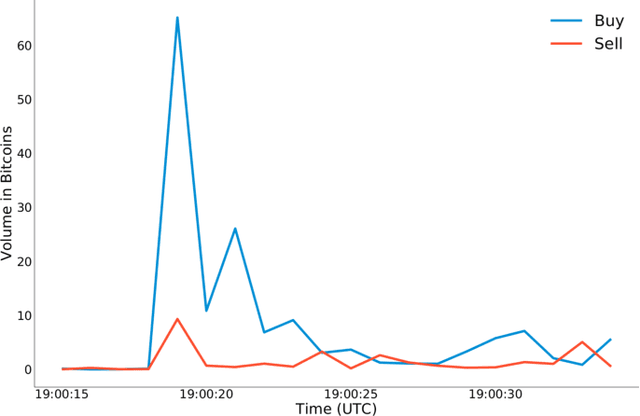
In the last years, cryptocurrencies are increasingly popular. Even people who are not experts have started to invest in these securities and nowadays cryptocurrency exchanges process transactions for over 100 billion US dollars per month. However, many cryptocurrencies have low liquidity and therefore they are highly prone to market manipulation schemes. In this paper, we perform an in-depth analysis of pump and dump schemes organized by communities over the Internet. We observe how these communities are organized and how they carry out the fraud. Then, we report on two case studies related to pump and dump groups. Lastly, we introduce an approach to detect the fraud in real time that outperforms the current state of the art, so to help investors stay out of the market when a pump and dump scheme is in action.
A Fast-Optimal Guaranteed Algorithm For Learning Sub-Interval Relationships in Time Series
Jun 03, 2019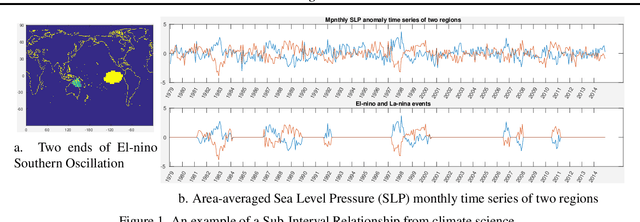
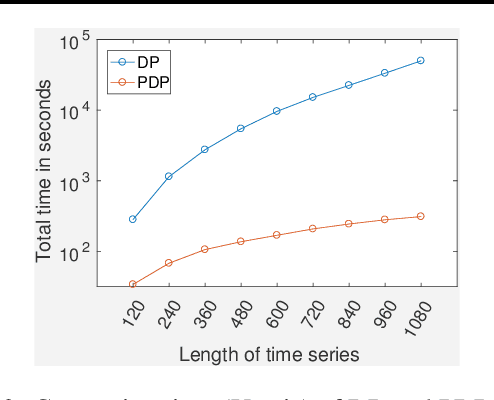
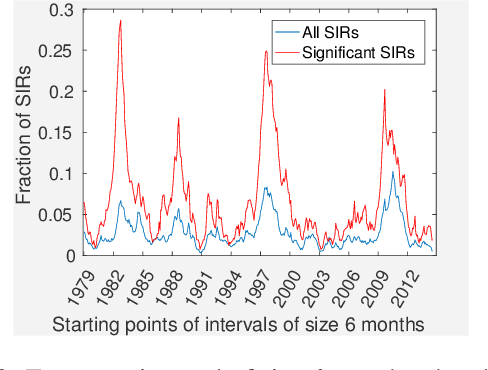
Traditional approaches focus on finding relationships between two entire time series, however, many interesting relationships exist in small sub-intervals of time and remain feeble during other sub-intervals. We define the notion of a sub-interval relationship (SIR) to capture such interactions that are prominent only in certain sub-intervals of time. To that end, we propose a fast-optimal guaranteed algorithm to find most interesting SIR relationship in a pair of time series. Lastly, we demonstrate the utility of our method in climate science domain based on a real-world dataset along with its scalability scope and obtain useful domain insights.