 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-DoF Time Domain Passivity Approach Based Drift Compensation for Telemanipulation
Oct 10, 2019

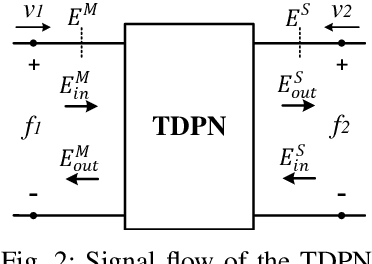
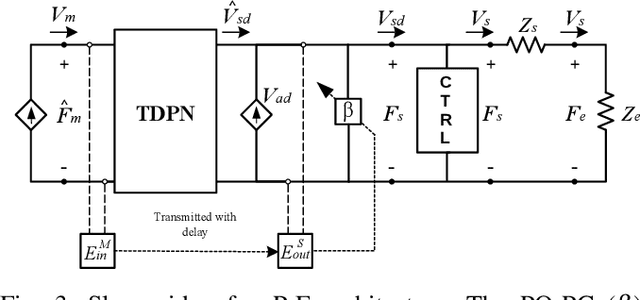
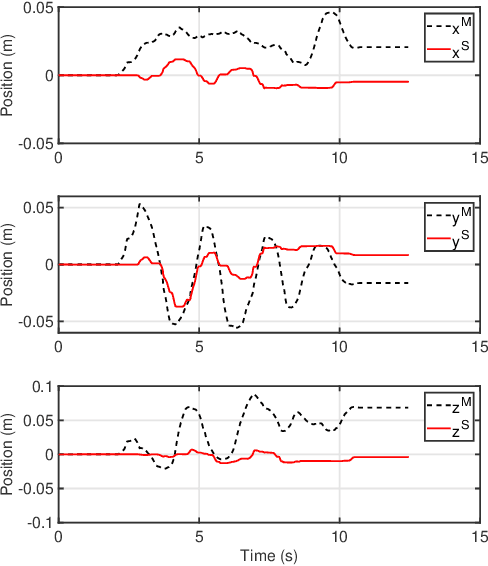
When, in addition to stability, position synchronization is also desired in bilateral teleoperation, Time Domain Passivity Approach (TDPA) alone might not be able to fulfill the desired objective. This is due to an undesired effect caused by admittance type passivity controllers, namely position drift. Previous works focused on developing TDPA-based drift compensation methods to solve this issue. It was shown that, in addition to reducing drift, one of the proposed methods was able to keep the force signals within their normal range, guaranteeing the safety of the task. However, no multi-DoF treatment of those approaches has been addressed. In that scope, this paper focuses on providing an extension of previous TDPA-based approaches to multi-DoF Cartesian-space teleoperation. An analysis of the convergence properties of the presented method is also provided. In addition, its applicability to multi-DoF devices is shown through hardware experiments and numerical simulation with round-trip time delays up to 700 ms.
Wake-Cough: cough spotting and cougher identification for personalised long-term cough monitoring
Oct 07, 2021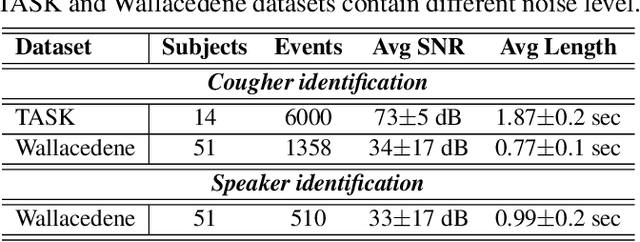

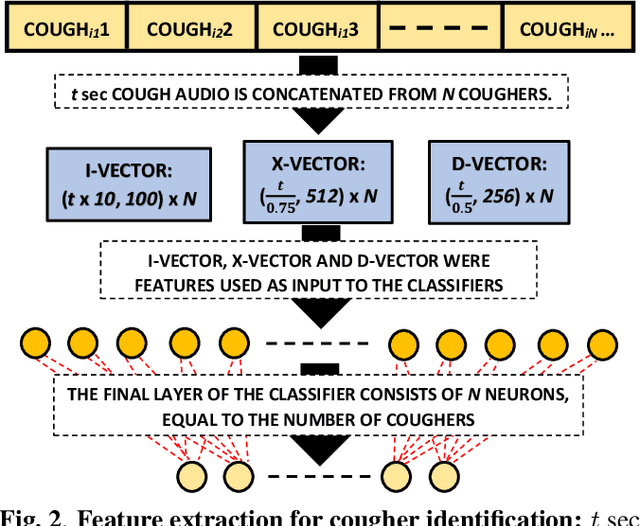
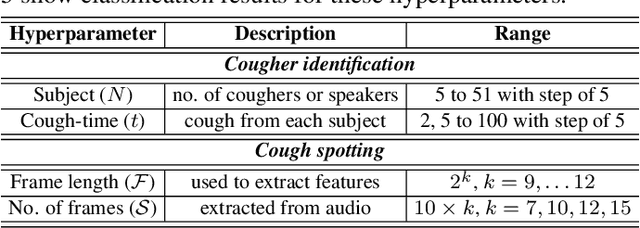
We present 'wake-cough', an application of wake-word spotting to coughs using Resnet50 and identifying coughers using i-vectors, for the purpose of a long-term, personalised cough monitoring system. Coughs, recorded in a quiet (73$\pm$5 dB) and noisy (34$\pm$17 dB) environment, were used to extract i-vectors, x-vectors and d-vectors, used as features to the classifiers. The system achieves 90.02\% accuracy from an MLP to discriminate 51 coughers using 2-sec long cough segments in the noisy environment. When discriminating between 5 and 14 coughers using longer (100 sec) segments in the quiet environment, this accuracy rises to 99.78\% and 98.39\% respectively. Unlike speech, i-vectors outperform x-vectors and d-vectors in identifying coughers. These coughs were added as an extra class in the Google Speech Commands dataset and features were extracted by preserving the end-to-end time-domain information in an event. The highest accuracy of 88.58\% is achieved in spotting coughs among 35 other trigger phrases using a Resnet50. Wake-cough represents a personalised, non-intrusive, cough monitoring system, which is power efficient as using wake-word detection method can keep a smartphone-based monitoring device mostly dormant. This makes wake-cough extremely attractive in multi-bed ward environments to monitor patient's long-term recovery from lung ailments such as tuberculosis and COVID-19.
Explanation as a process: user-centric construction of multi-level and multi-modal explanations
Oct 07, 2021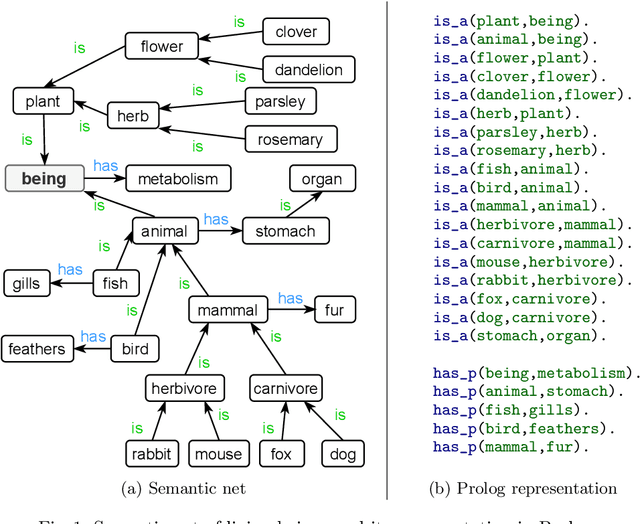


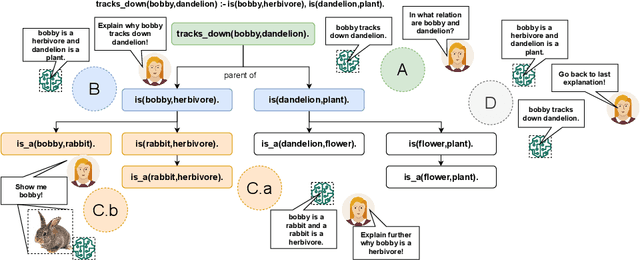
In the last years, XAI research has mainly been concerned with developing new technical approaches to explain deep learning models. Just recent research has started to acknowledge the need to tailor explanations to different contexts and requirements of stakeholders. Explanations must not only suit developers of models, but also domain experts as well as end users. Thus, in order to satisfy different stakeholders, explanation methods need to be combined. While multi-modal explanations have been used to make model predictions more transparent, less research has focused on treating explanation as a process, where users can ask for information according to the level of understanding gained at a certain point in time. Consequently, an opportunity to explore explanations on different levels of abstraction should be provided besides multi-modal explanations. We present a process-based approach that combines multi-level and multi-modal explanations. The user can ask for textual explanations or visualizations through conversational interaction in a drill-down manner. We use Inductive Logic Programming, an interpretable machine learning approach, to learn a comprehensible model. Further, we present an algorithm that creates an explanatory tree for each example for which a classifier decision is to be explained. The explanatory tree can be navigated by the user to get answers of different levels of detail. We provide a proof-of-concept implementation for concepts induced from a semantic net about living beings.
Predictive Maintenance for General Aviation Using Convolutional Transformers
Oct 07, 2021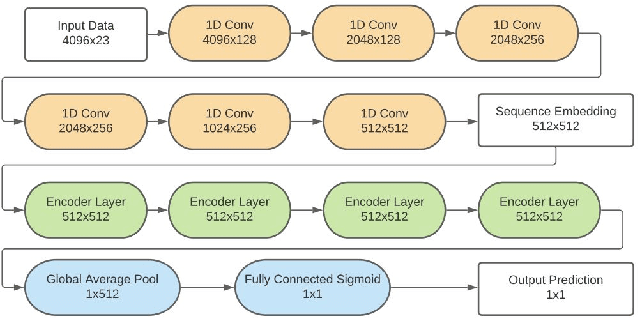
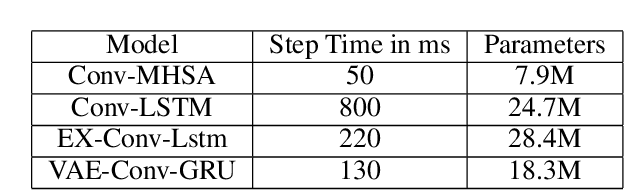
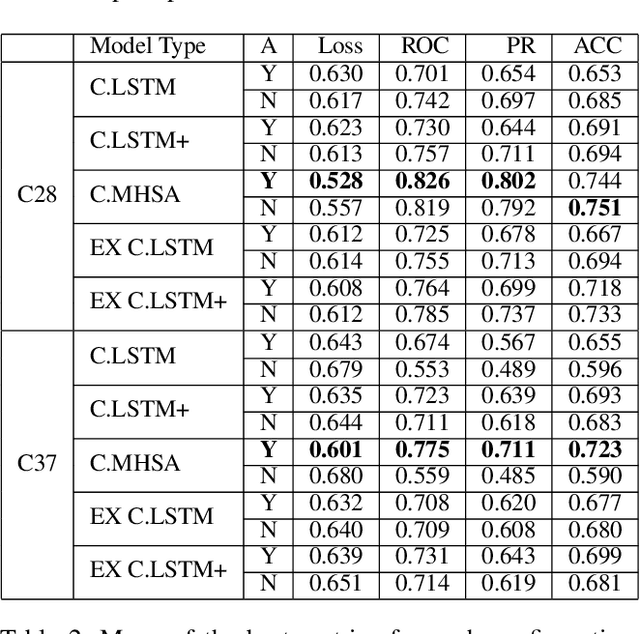
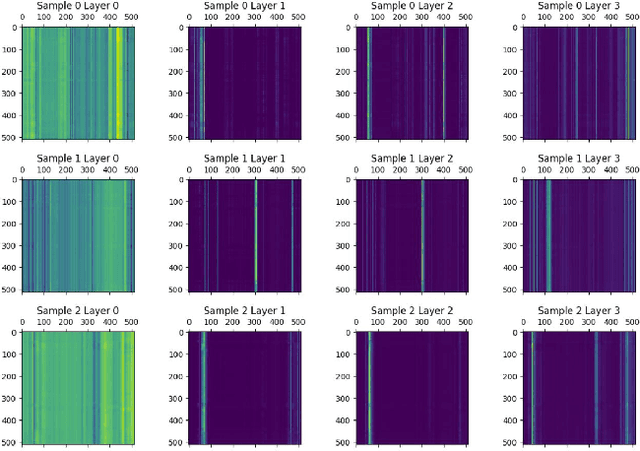
Predictive maintenance systems have the potential to significantly reduce costs for maintaining aircraft fleets as well as provide improved safety by detecting maintenance issues before they come severe. However, the development of such systems has been limited due to a lack of publicly labeled multivariate time series (MTS) sensor data. MTS classification has advanced greatly over the past decade, but there is a lack of sufficiently challenging benchmarks for new methods. This work introduces the NGAFID Maintenance Classification (NGAFID-MC) dataset as a novel benchmark in terms of difficulty, number of samples, and sequence length. NGAFID-MC consists of over 7,500 labeled flights, representing over 11,500 hours of per second flight data recorder readings of 23 sensor parameters. Using this benchmark, we demonstrate that Recurrent Neural Network (RNN) methods are not well suited for capturing temporally distant relationships and propose a new architecture called Convolutional Multiheaded Self Attention (Conv-MHSA) that achieves greater classification performance at greater computational efficiency. We also demonstrate that image inspired augmentations of cutout, mixup, and cutmix, can be used to reduce overfitting and improve generalization in MTS classification. Our best trained models have been incorporated back into the NGAFID to allow users to potentially detect flights that require maintenance as well as provide feedback to further expand and refine the NGAFID-MC dataset.
Can Q-learning solve Multi Armed Bantids?
Oct 21, 2021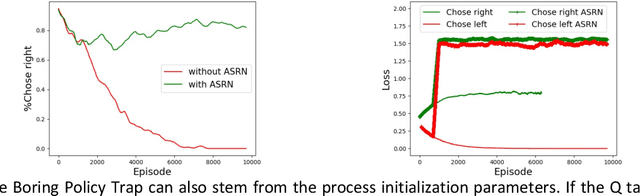
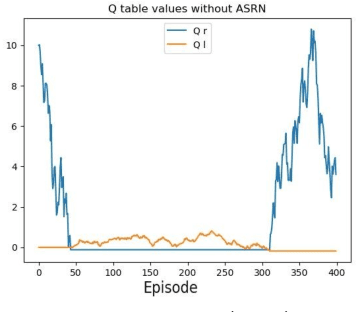
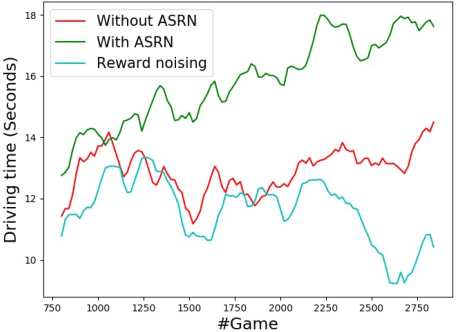
When a reinforcement learning (RL) method has to decide between several optional policies by solely looking at the received reward, it has to implicitly optimize a Multi-Armed-Bandit (MAB) problem. This arises the question: are current RL algorithms capable of solving MAB problems? We claim that the surprising answer is no. In our experiments we show that in some situations they fail to solve a basic MAB problem, and in many common situations they have a hard time: They suffer from regression in results during training, sensitivity to initialization and high sample complexity. We claim that this stems from variance differences between policies, which causes two problems: The first problem is the "Boring Policy Trap" where each policy have a different implicit exploration depends on its rewards variance, and leaving a boring, or low variance, policy is less likely due to its low implicit exploration. The second problem is the "Manipulative Consultant" problem, where value-estimation functions used in deep RL algorithms such as DQN or deep Actor Critic methods, maximize estimation precision rather than mean rewards, and have a better loss in low-variance policies, which cause the network to converge to a sub-optimal policy. Cognitive experiments on humans showed that noised reward signals may paradoxically improve performance. We explain this using the aforementioned problems, claiming that both humans and algorithms may share similar challenges in decision making. Inspired by this result, we propose the Adaptive Symmetric Reward Noising (ASRN) method, by which we mean equalizing the rewards variance across different policies, thus avoiding the two problems without affecting the environment's mean rewards behavior. We demonstrate that the ASRN scheme can dramatically improve the results.
Modeling and Reasoning in Event Calculus using Goal-Directed Constraint Answer Set Programming
Jun 28, 2021
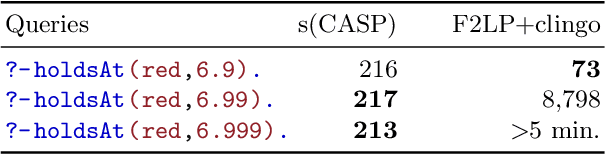


Automated commonsense reasoning is essential for building human-like AI systems featuring, for example, explainable AI. Event Calculus (EC) is a family of formalisms that model commonsense reasoning with a sound, logical basis. Previous attempts to mechanize reasoning using EC faced difficulties in the treatment of the continuous change in dense domains (e.g., time and other physical quantities), constraints among variables, default negation, and the uniform application of different inference methods, among others. We propose the use of s(CASP), a query-driven, top-down execution model for Predicate Answer Set Programming with Constraints, to model and reason using EC. We show how EC scenarios can be naturally and directly encoded in s(CASP) and how it enables deductive and abductive reasoning tasks in domains featuring constraints involving both dense time and dense fluents.
Impact of COVID-19 Policies and Misinformation on Social Unrest
Oct 07, 2021
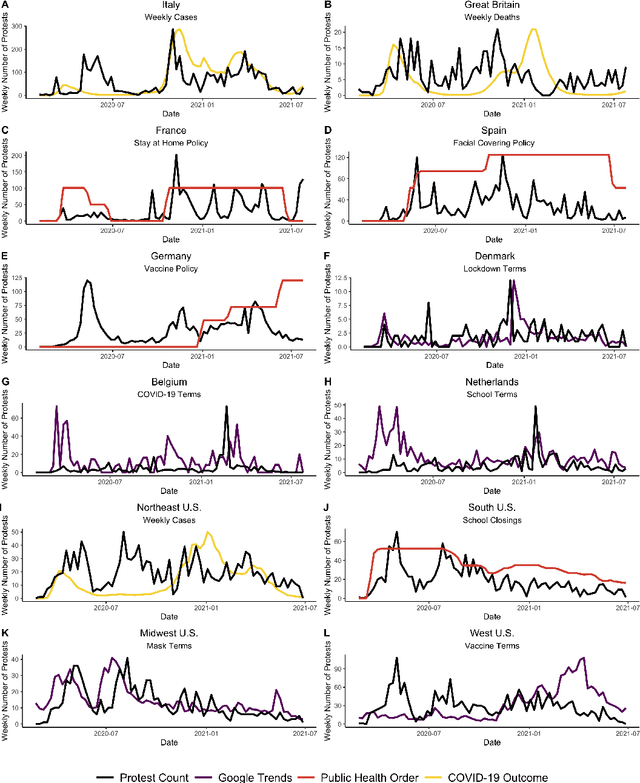
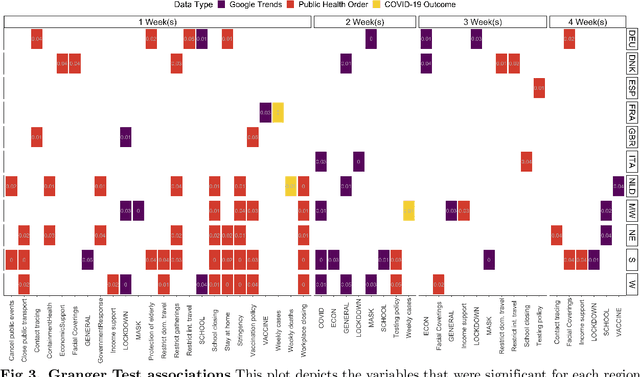
The novel coronavirus disease (COVID-19) pandemic has impacted every corner of earth, disrupting governments and leading to socioeconomic instability. This crisis has prompted questions surrounding how different sectors of society interact and influence each other during times of change and stress. Given the unprecedented economic and societal impacts of this pandemic, many new data sources have become available, allowing us to quantitatively explore these associations. Understanding these relationships can help us better prepare for future disasters and mitigate the impacts. Here, we focus on the interplay between social unrest (protests), health outcomes, public health orders, and misinformation in eight countries of Western Europe and four regions of the United States. We created 1-3 week forecasts of both a binary protest metric for identifying times of high protest activity and the overall protest counts over time. We found that for all regions, except Belgium, at least one feature from our various data streams was predictive of protests. However, the accuracy of the protest forecasts varied by country, that is, for roughly half of the countries analyzed, our forecasts outperform a na\"ive model. These mixed results demonstrate the potential of diverse data streams to predict a topic as volatile as protests as well as the difficulties of predicting a situation that is as rapidly evolving as a pandemic.
Mitigating Catastrophic Forgetting in Scheduled Sampling with Elastic Weight Consolidation in Neural Machine Translation
Sep 13, 2021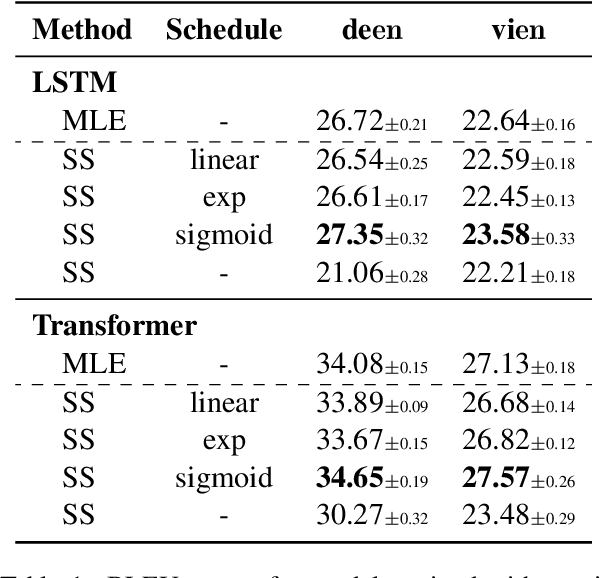
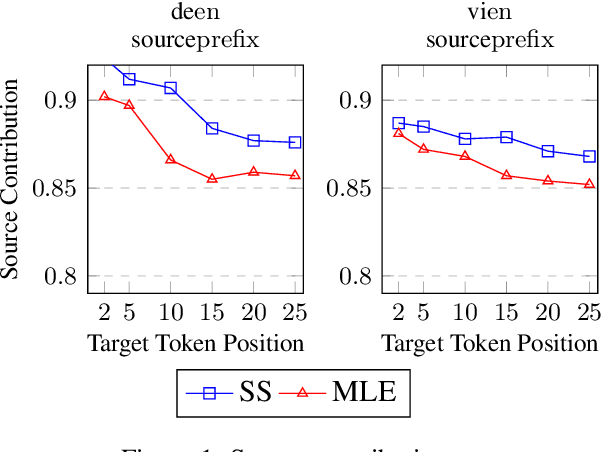
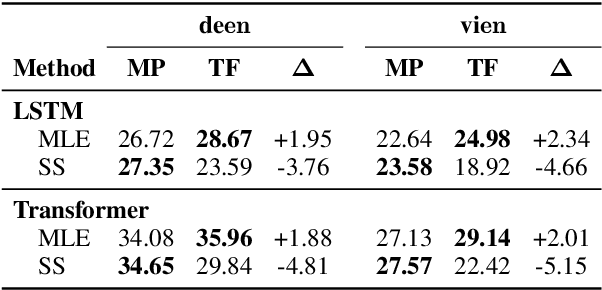
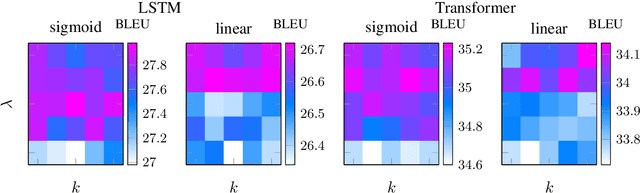
Despite strong performance in many sequence-to-sequence tasks, autoregressive models trained with maximum likelihood estimation suffer from exposure bias, i.e. a discrepancy between the ground-truth prefixes used during training and the model-generated prefixes used at inference time. Scheduled sampling is a simple and often empirically successful approach which addresses this issue by incorporating model-generated prefixes into the training process. However, it has been argued that it is an inconsistent training objective leading to models ignoring the prefixes altogether. In this paper, we conduct systematic experiments and find that it ameliorates exposure bias by increasing model reliance on the input sequence. We also observe that as a side-effect, it worsens performance when the model-generated prefix is correct, a form of catastrophic forgetting. We propose using Elastic Weight Consolidation as trade-off between mitigating exposure bias and retaining output quality. Experiments on two IWSLT'14 translation tasks demonstrate that our approach alleviates catastrophic forgetting and significantly improves BLEU compared to standard scheduled sampling.
Artificial Intelligence Hybrid Deep Learning Model for Groundwater Level Prediction Using MLP-ADAM
Jul 29, 2021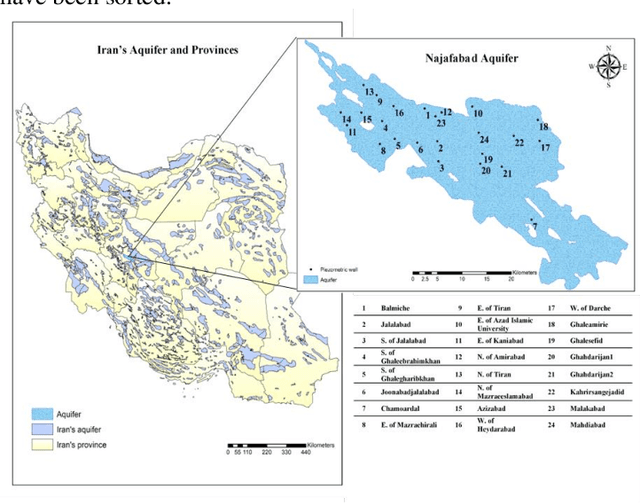
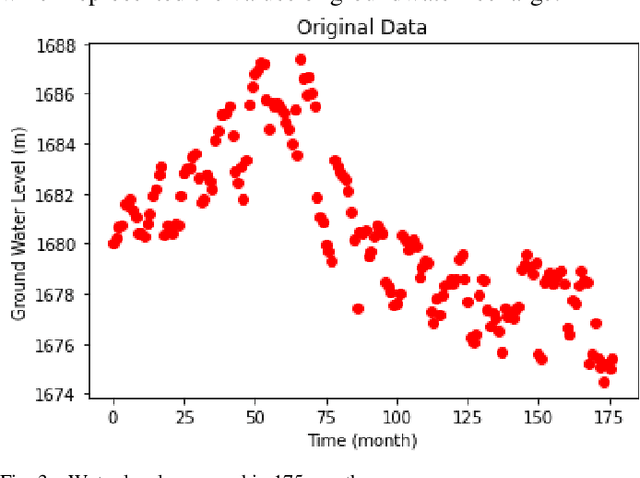
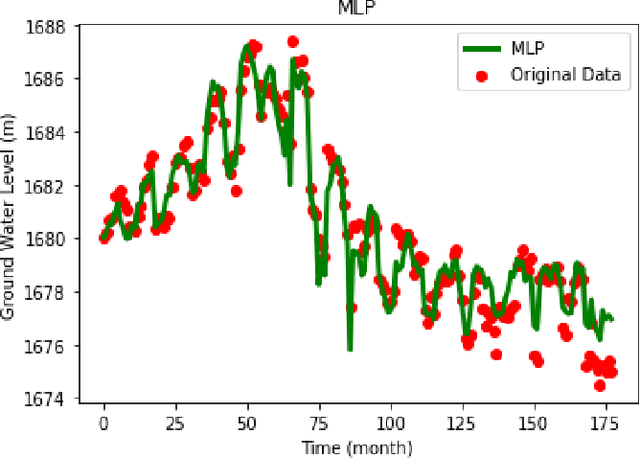
Groundwater is the largest storage of freshwater resources, which serves as the major inventory for most of the human consumption through agriculture, industrial, and domestic water supply. In the fields of hydrological, some researchers applied a neural network to forecast rainfall intensity in space-time and introduced the advantages of neural networks compared to numerical models. Then, many researches have been conducted applying data-driven models. Some of them extended an Artificial Neural Networks (ANNs) model to forecast groundwater level in semi-confined glacial sand and gravel aquifer under variable state, pumping extraction and climate conditions with significant accuracy. In this paper, a multi-layer perceptron is applied to simulate groundwater level. The adaptive moment estimation optimization algorithm is also used to this matter. The root mean squared error, mean absolute error, mean squared error and the coefficient of determination ( ) are used to evaluate the accuracy of the simulated groundwater level. Total value of and RMSE are 0.9458 and 0.7313 respectively which are obtained from the model output. Results indicate that deep learning algorithms can demonstrate a high accuracy prediction. Although the optimization of parameters is insignificant in numbers, but due to the value of time in modelling setup, it is highly recommended to apply an optimization algorithm in modelling.
A2Log: Attentive Augmented Log Anomaly Detection
Sep 20, 2021Anomaly detection becomes increasingly important for the dependability and serviceability of IT services. As log lines record events during the execution of IT services, they are a primary source for diagnostics. Thereby, unsupervised methods provide a significant benefit since not all anomalies can be known at training time. Existing unsupervised methods need anomaly examples to obtain a suitable decision boundary required for the anomaly detection task. This requirement poses practical limitations. Therefore, we develop A2Log, which is an unsupervised anomaly detection method consisting of two steps: Anomaly scoring and anomaly decision. First, we utilize a self-attention neural network to perform the scoring for each log message. Second, we set the decision boundary based on data augmentation of the available normal training data. The method is evaluated on three publicly available datasets and one industry dataset. We show that our approach outperforms existing methods. Furthermore, we utilize available anomaly examples to set optimal decision boundaries to acquire strong baselines. We show that our approach, which determines decision boundaries without utilizing anomaly examples, can reach scores of the strong baselines.