 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The interpretation of endobronchial ultrasound image using 3D convolutional neural network for differentiating malignant and benign mediastinal lesions
Aug 02, 2021
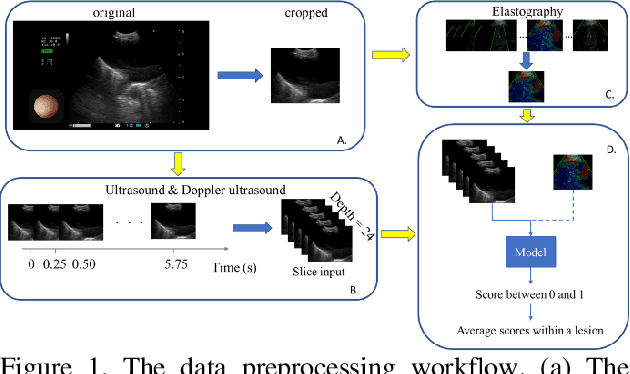
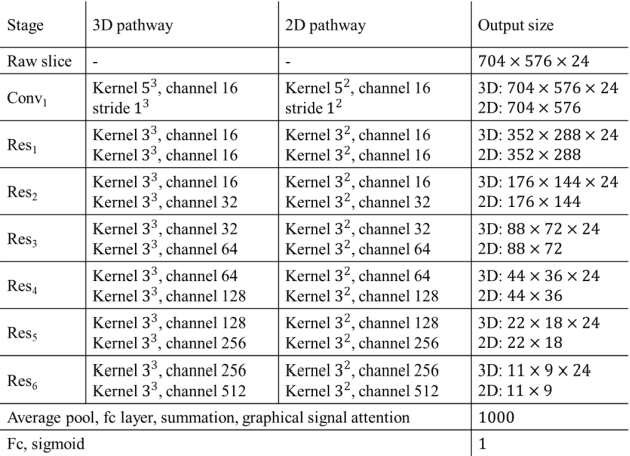
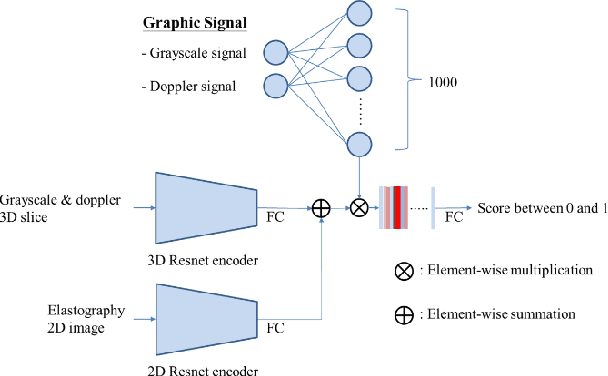
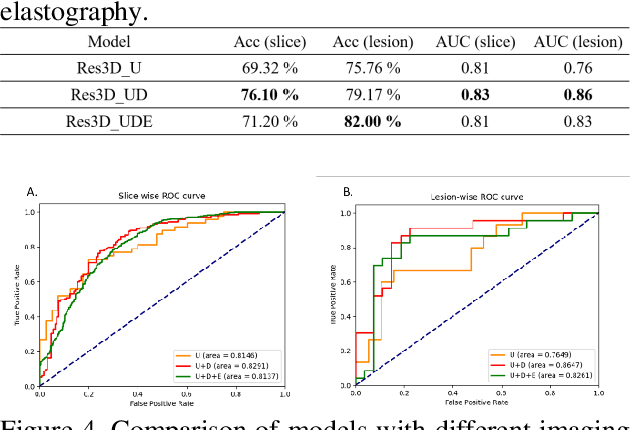
The purpose of this study is to differentiate malignant and benign mediastinal lesions by using the three-dimensional convolutional neural network through the endobronchial ultrasound (EBUS) image. Compared with previous study, our proposed model is robust to noise and able to fuse various imaging features and spatiotemporal features of EBUS videos. Endobronchial ultrasound-guided transbronchial needle aspiration (EBUS-TBNA) is a diagnostic tool for intrathoracic lymph nodes. Physician can observe the characteristics of the lesion using grayscale mode, doppler mode, and elastography during the procedure. To process the EBUS data in the form of a video and appropriately integrate the features of multiple imaging modes, we used a time-series three-dimensional convolutional neural network (3D CNN) to learn the spatiotemporal features and design a variety of architectures to fuse each imaging mode. Our model (Res3D_UDE) took grayscale mode, Doppler mode, and elastography as training data and achieved an accuracy of 82.00% and area under the curve (AUC) of 0.83 on the validation set. Compared with previous study, we directly used videos recorded during procedure as training and validation data, without additional manual selection, which might be easier for clinical application. In addition, model designed with 3D CNN can also effectively learn spatiotemporal features and improve accuracy. In the future, our model may be used to guide physicians to quickly and correctly find the target lesions for slice sampling during the inspection process, reduce the number of slices of benign lesions, and shorten the inspection time.
Concentration of Contractive Stochastic Approximation and Reinforcement Learning
Jun 27, 2021Using a martingale concentration inequality, concentration bounds `from time $n_0$ on' are derived for stochastic approximation algorithms with contractive maps and both martingale difference and Markov noises. These are applied to reinforcement learning algorithms, in particular to asynchronous Q-learning and TD(0).
Ousiometrics and Telegnomics: The essence of meaning conforms to a two-dimensional powerful-weak and dangerous-safe framework with diverse corpora presenting a safety bias
Oct 13, 2021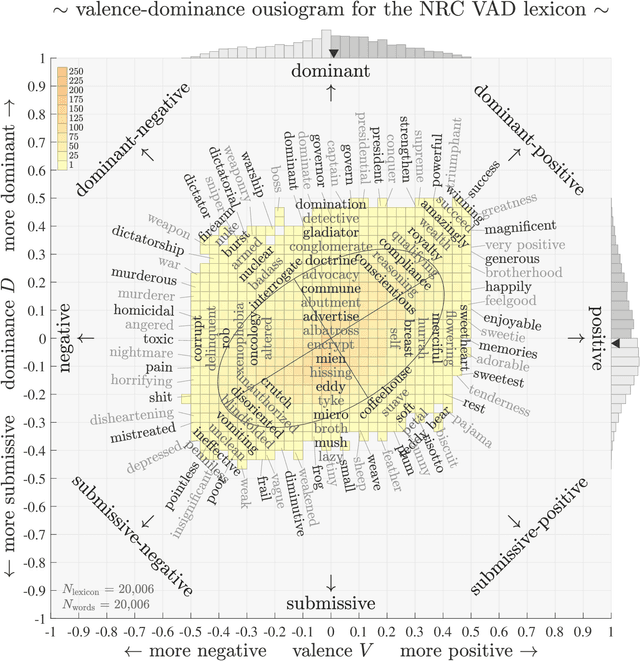
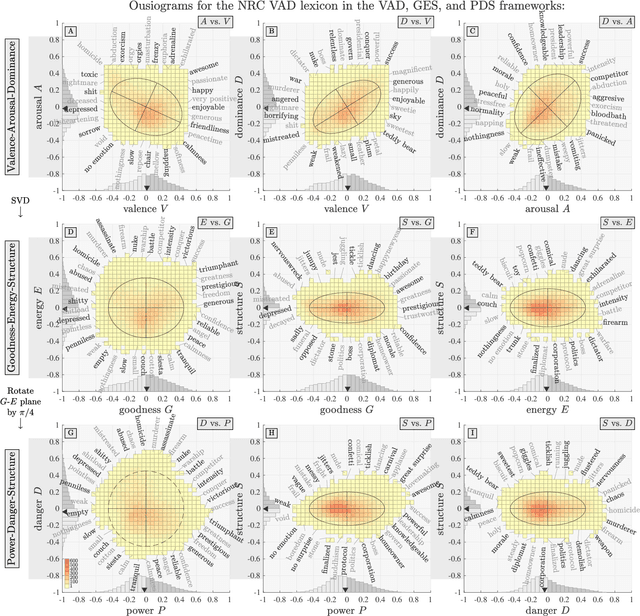
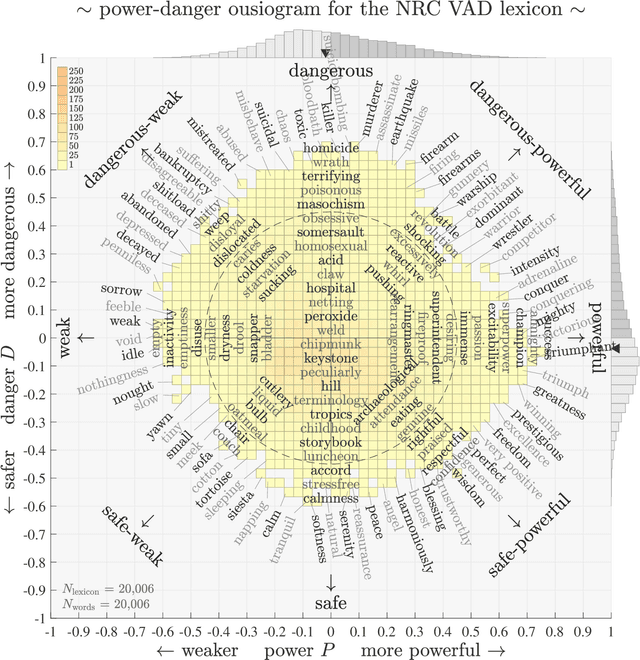
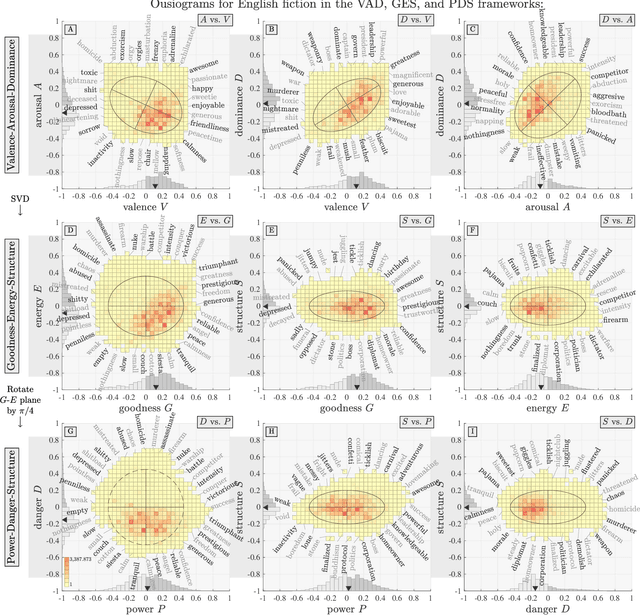
We define `ousiometrics' to be the study of essential meaning in whatever context that meaningful signals are communicated, and `telegnomics' as the study of remotely sensed knowledge. From work emerging through the middle of the 20th century, the essence of meaning has become generally accepted as being well captured by the three orthogonal dimensions of evaluation, potency, and activation (EPA). By re-examining first types and then tokens for the English language, and through the use of automatically annotated histograms -- `ousiograms' -- we find here that: 1. The essence of meaning conveyed by words is instead best described by a compass-like power-danger (PD) framework, and 2. Analysis of a disparate collection of large-scale English language corpora -- literature, news, Wikipedia, talk radio, and social media -- shows that natural language exhibits a systematic bias toward safe, low danger words -- a reinterpretation of the Pollyanna principle's positivity bias for written expression. To help justify our choice of dimension names and to help address the problems with representing observed ousiometric dimensions by bipolar adjective pairs, we introduce and explore `synousionyms' and `antousionyms' -- ousiometric counterparts of synonyms and antonyms. We further show that the PD framework revises the circumplex model of affect as a more general model of state of mind. Finally, we use our findings to construct and test a prototype `ousiometer', a telegnomic instrument that measures ousiometric time series for temporal corpora. We contend that our power-danger ousiometric framework provides a complement for entropy-based measurements, and may be of value for the study of a wide variety of communication across biological and artificial life.
Machine learning models show similar performance to Renewables.ninja for generation of long-term wind power time series even without location information
Dec 09, 2019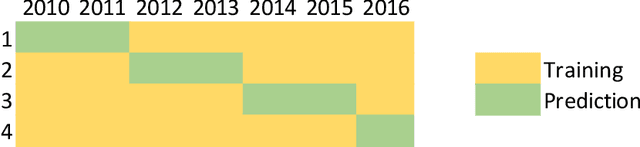
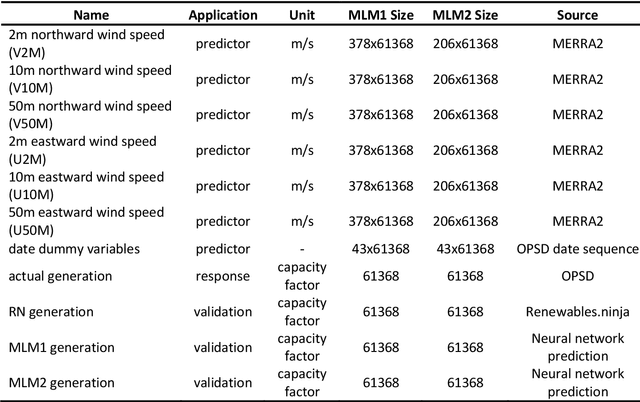
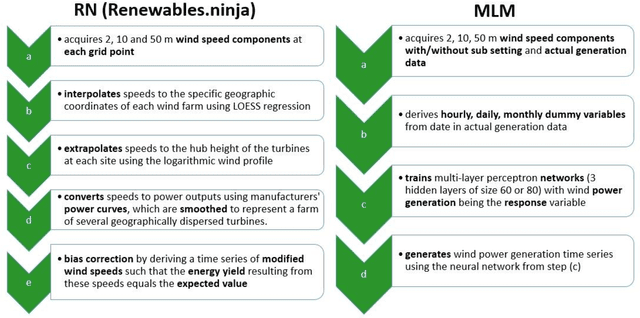
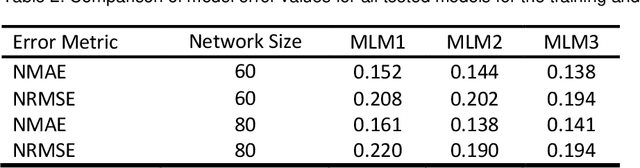
Driven by climatic processes, wind power generation is inherently variable. Long-term simulated wind power time series are therefore an essential component for understanding the temporal availability of wind power and its integration into future renewable energy systems. In the recent past, mainly power curve based models such as Renewables.ninja (RN) have been used for deriving synthetic time series for wind power generation despite their need for accurate location information as well as for bias correction, and their insufficient replication of extreme events and short-term power ramps. We assess how time series generated by machine learning models (MLM) compare to RN in terms of their ability to replicate the characteristics of observed nationally aggregated wind power generation for Germany. Hence, we apply neural networks to one MERRA2 reanalysis wind speed input dataset with no location information and one with basic location information. The resulting time series and the RN time series are compared with actual generation. Both MLM time series feature equal or even better time series quality than RN depending on the characteristics considered. We conclude that MLM models can, even when reducing information on turbine locations and turbine types, produce time series of at least equal quality to RN.
Learning in time-varying games
Sep 10, 2018In this paper, we examine the long-term behavior of regret-minimizing agents in time-varying games with continuous action spaces. In its most basic form, (external) regret minimization guarantees that an agent's cumulative payoff is no worse in the long run than that of the agent's best fixed action in hindsight. Going beyond this worst-case guarantee, we consider a dynamic regret variant that compares the agent's accrued rewards to those of any sequence of play. Specializing to a wide class of no-regret strategies based on mirror descent, we derive explicit rates of regret minimization relying only on imperfect gradient obvservations. We then leverage these results to show that players are able to stay close to Nash equilibrium in time-varying monotone games - and even converge to Nash equilibrium if the sequence of stage games admits a limit.
Robust High-Resolution Video Matting with Temporal Guidance
Aug 25, 2021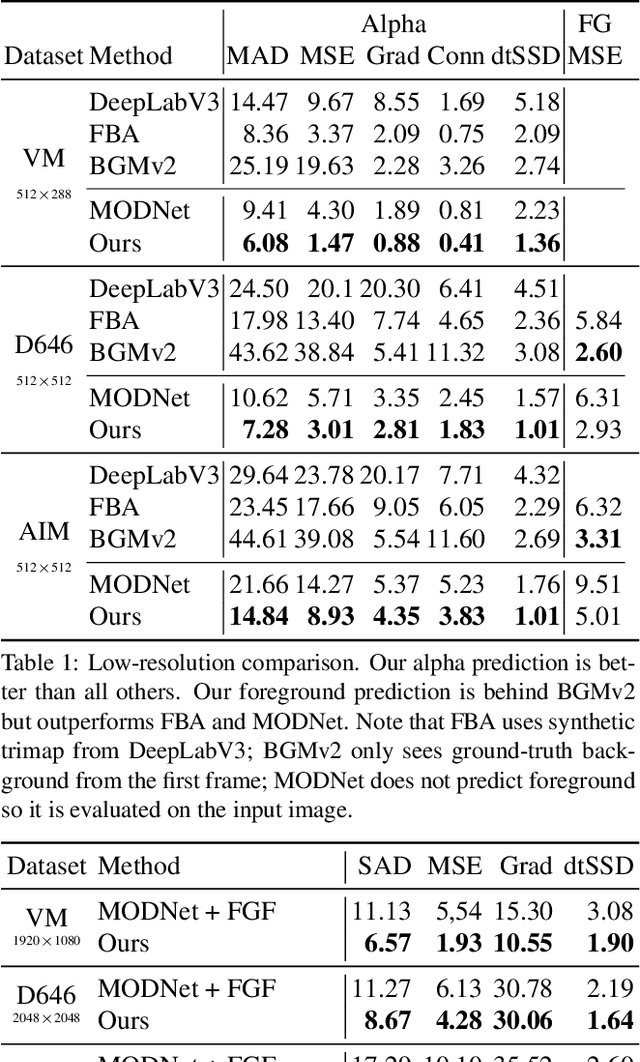
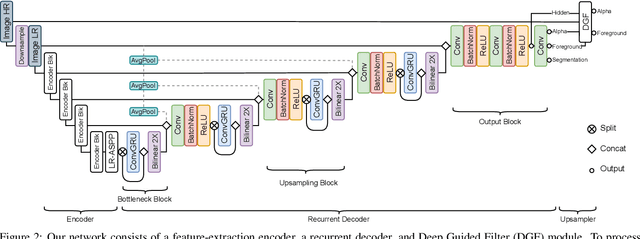
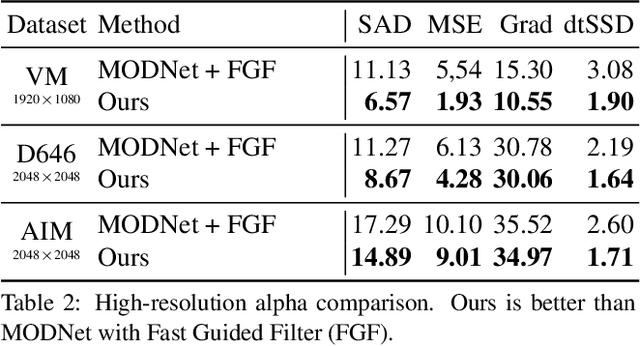
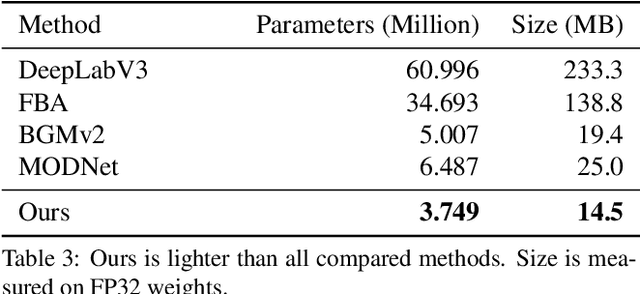
We introduce a robust, real-time, high-resolution human video matting method that achieves new state-of-the-art performance. Our method is much lighter than previous approaches and can process 4K at 76 FPS and HD at 104 FPS on an Nvidia GTX 1080Ti GPU. Unlike most existing methods that perform video matting frame-by-frame as independent images, our method uses a recurrent architecture to exploit temporal information in videos and achieves significant improvements in temporal coherence and matting quality. Furthermore, we propose a novel training strategy that enforces our network on both matting and segmentation objectives. This significantly improves our model's robustness. Our method does not require any auxiliary inputs such as a trimap or a pre-captured background image, so it can be widely applied to existing human matting applications.
Rethinking Trajectory Evaluation for SLAM: a Probabilistic, Continuous-Time Approach
Jun 10, 2019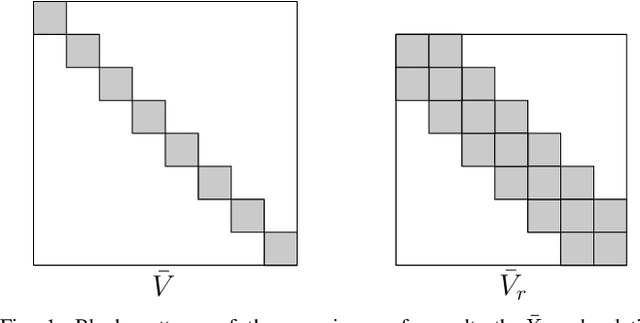
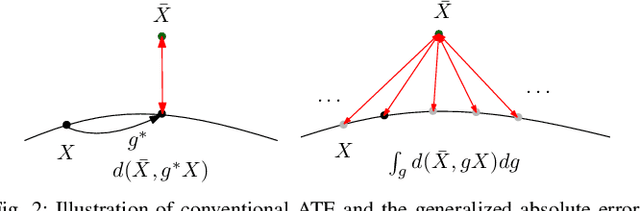
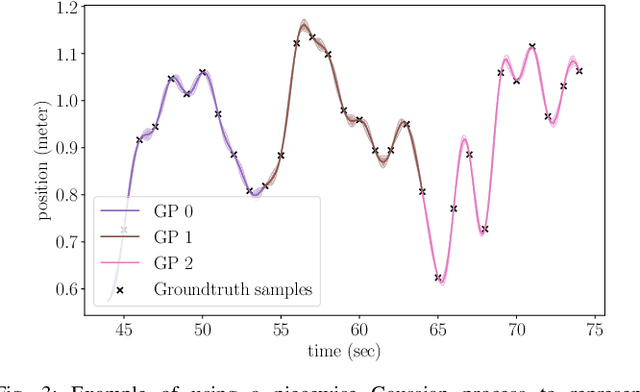
Despite the existence of different error metrics for trajectory evaluation in SLAM, their theoretical justifications and connections are rarely studied, and few methods handle temporal association properly. In this work, we propose to formulate the trajectory evaluation problem in a probabilistic, continuous-time framework. By modeling the groundtruth as random variables, the concepts of absolute and relative error are generalized to be likelihood. Moreover, the groundtruth is represented as a piecewise Gaussian Process in continuous-time. Within this framework, we are able to establish theoretical connections between relative and absolute error metrics and handle temporal association in a principled manner.
Toolbox Release: A WiFi-Based Relative Bearing Sensor for Robotics
Sep 24, 2021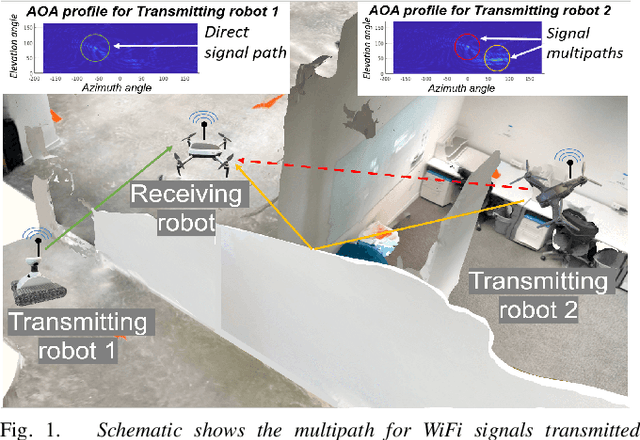
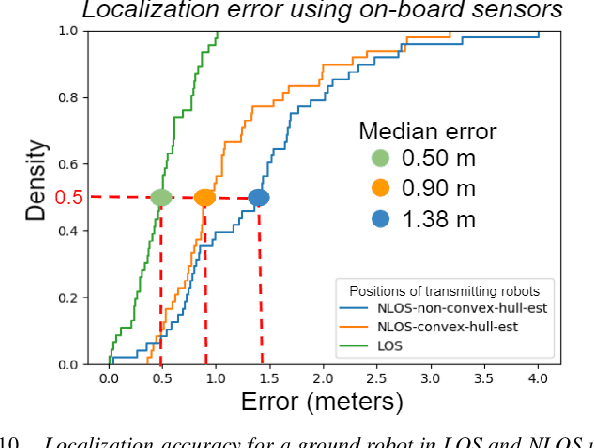
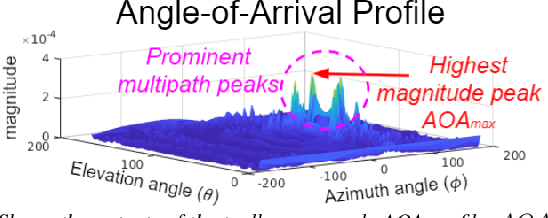
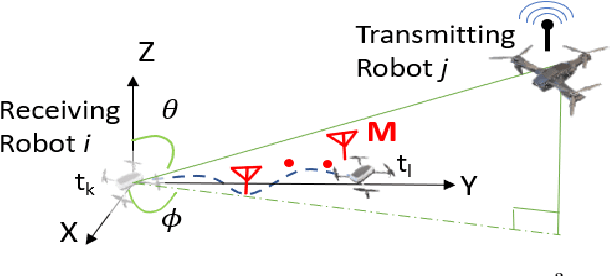
This paper presents the WiFi-Sensor-for-Robotics (WSR) toolbox, an open source C++ framework. It enables robots in a team to obtain relative bearing to each other, even in non-line-of-sight (NLOS) settings which is a very challenging problem in robotics. It does so by analyzing the phase of their communicated WiFi signals as the robots traverse the environment. This capability, based on the theory developed in our prior works, is made available for the first time as an opensource tool. It is motivated by the lack of easily deployable solutions that use robots' local resources (e.g WiFi) for sensing in NLOS. This has implications for localization, ad-hoc robot networks, and security in multi-robot teams, amongst others. The toolbox is designed for distributed and online deployment on robot platforms using commodity hardware and on-board sensors. We also release datasets demonstrating its performance in NLOS and line-of-sight (LOS) settings for a multi-robot localization usecase. Empirical results show that the bearing estimation from our toolbox achieves mean accuracy of 5.10 degrees. This leads to a median error of 0.5m and 0.9m for localization in LOS and NLOS settings respectively, in a hardware deployment in an indoor office environment.
Spectral Processing and Optimization of Static and Dynamic 3D Geometries
Jul 15, 2021Geometry processing of 3D objects is of primary interest in many areas of computer vision and graphics, including robot navigation, 3D object recognition, classification, feature extraction, etc. The recent introduction of cheap range sensors has created a great interest in many new areas, driving the need for developing efficient algorithms for 3D object processing. Previously, in order to capture a 3D object, expensive specialized sensors were used, such as lasers or dedicated range images, but now this limitation has changed. The current approaches of 3D object processing require a significant amount of manual intervention and they are still time-consuming making them unavailable for use in real-time applications. The aim of this thesis is to present algorithms, mainly inspired by the spectral analysis, subspace tracking, etc, that can be used and facilitate many areas of low-level 3D geometry processing (i.e., reconstruction, outliers removal, denoising, compression), pattern recognition tasks (i.e., significant features extraction) and high-level applications (i.e., registration and identification of 3D objects in partially scanned and cluttered scenes), taking into consideration different types of 3D models (i.e., static and dynamic point clouds, static and dynamic 3D meshes).
SIMONe: View-Invariant, Temporally-Abstracted Object Representations via Unsupervised Video Decomposition
Jun 07, 2021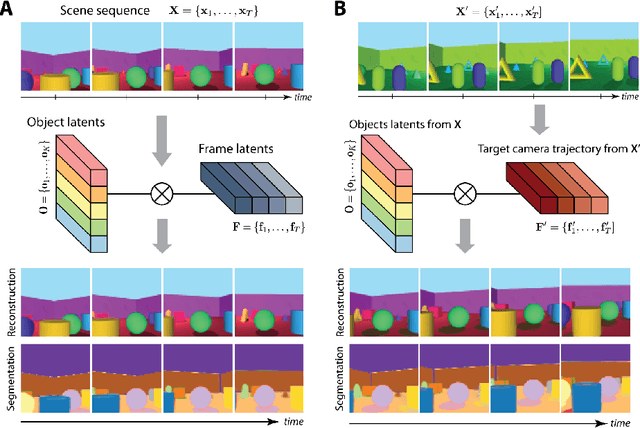
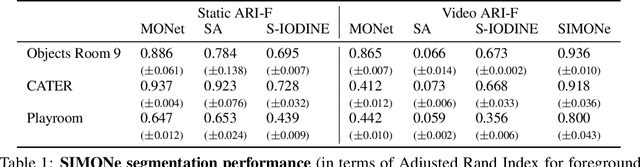
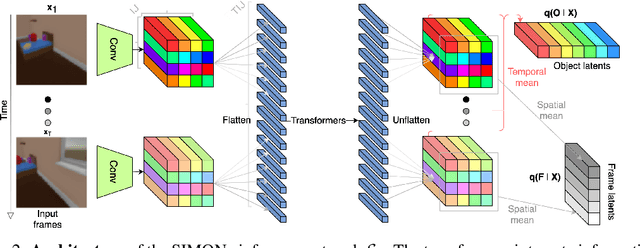

To help agents reason about scenes in terms of their building blocks, we wish to extract the compositional structure of any given scene (in particular, the configuration and characteristics of objects comprising the scene). This problem is especially difficult when scene structure needs to be inferred while also estimating the agent's location/viewpoint, as the two variables jointly give rise to the agent's observations. We present an unsupervised variational approach to this problem. Leveraging the shared structure that exists across different scenes, our model learns to infer two sets of latent representations from RGB video input alone: a set of "object" latents, corresponding to the time-invariant, object-level contents of the scene, as well as a set of "frame" latents, corresponding to global time-varying elements such as viewpoint. This factorization of latents allows our model, SIMONe, to represent object attributes in an allocentric manner which does not depend on viewpoint. Moreover, it allows us to disentangle object dynamics and summarize their trajectories as time-abstracted, view-invariant, per-object properties. We demonstrate these capabilities, as well as the model's performance in terms of view synthesis and instance segmentation, across three procedurally generated video datasets.