 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ST-MAML: A Stochastic-Task based Method for Task-Heterogeneous Meta-Learning
Sep 27, 2021
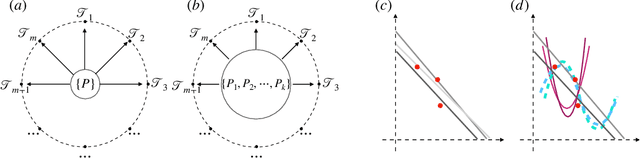
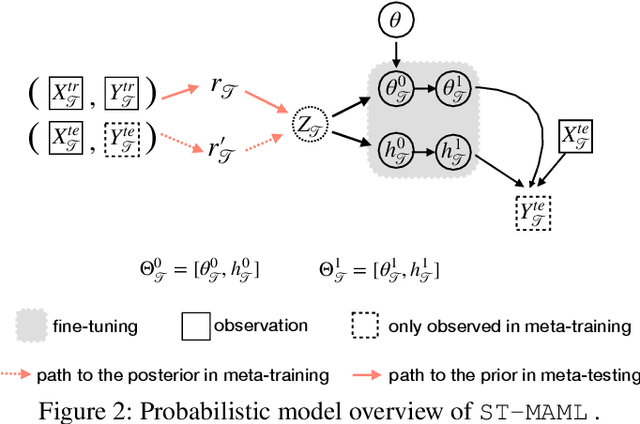

Optimization-based meta-learning typically assumes tasks are sampled from a single distribution - an assumption oversimplifies and limits the diversity of tasks that meta-learning can model. Handling tasks from multiple different distributions is challenging for meta-learning due to a so-called task ambiguity issue. This paper proposes a novel method, ST-MAML, that empowers model-agnostic meta-learning (MAML) to learn from multiple task distributions. ST-MAML encodes tasks using a stochastic neural network module, that summarizes every task with a stochastic representation. The proposed Stochastic Task (ST) strategy allows a meta-model to get tailored for the current task and enables us to learn a distribution of solutions for an ambiguous task. ST-MAML also propagates the task representation to revise the encoding of input variables. Empirically, we demonstrate that ST-MAML matches or outperforms the state-of-the-art on two few-shot image classification tasks, one curve regression benchmark, one image completion problem, and a real-world temperature prediction application. To the best of authors' knowledge, this is the first time optimization-based meta-learning method being applied on a large-scale real-world task.
OmniTrack: Real-time detection and tracking of objects, text and logos in video
Oct 14, 2019
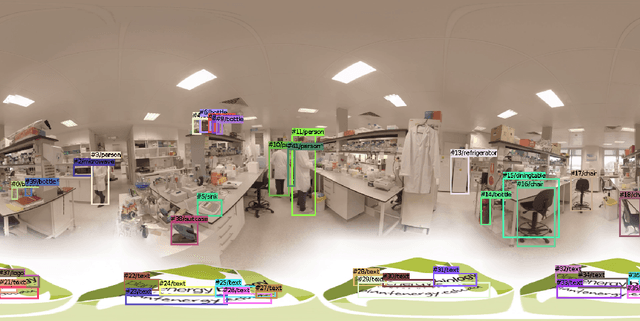
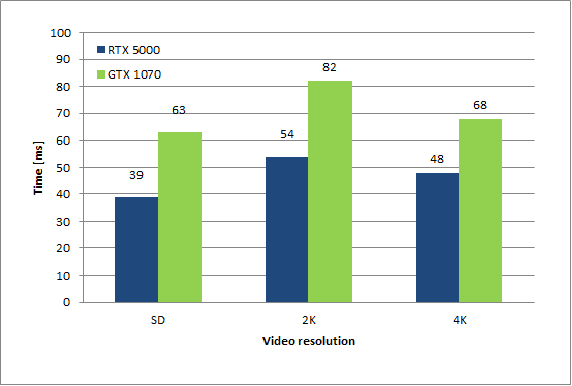
The automatic detection and tracking of general objects (like persons, animals or cars), text and logos in a video is crucial for many video understanding tasks, and usually real-time processing as required. We propose OmniTrack, an efficient and robust algorithm which is able to automatically detect and track objects, text as well as brand logos in real-time. It combines a powerful deep learning based object detector (YoloV3) with high-quality optical flow methods. Based on the reference YoloV3 C++ implementation, we did some important performance optimizations which will be described. The major steps in the training procedure for the combined detector for text and logo will be presented. We will describe then the OmniTrack algorithm, consisting of the phases preprocessing, feature calculation, prediction, matching and update. Several performance optimizations have been implemented there as well, like doing the object detection and optical flow calculation asynchronously. Experiments show that the proposed algorithm runs in real-time for standard definition ($720x576$) video on a PC with a Quadro RTX 5000 GPU.
Modeling Time to Open of Emails with a Latent State for User Engagement Level
Aug 18, 2019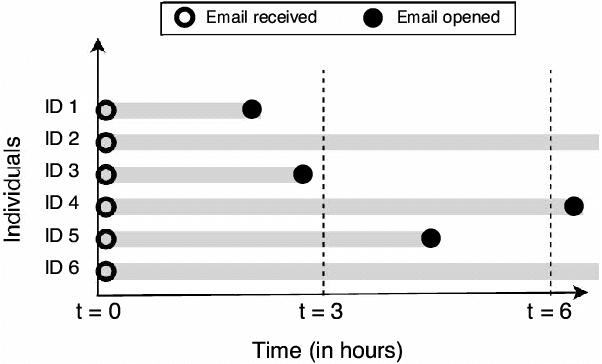
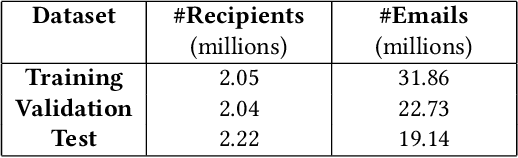
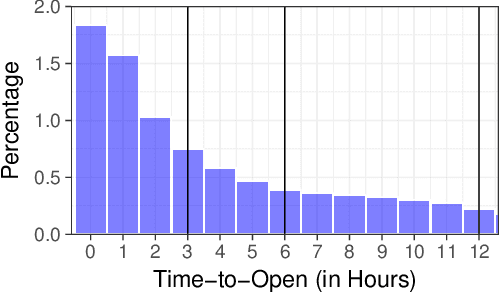

Email messages have been an important mode of communication, not only for work, but also for social interactions and marketing. When messages have time sensitive information, it becomes relevant for the sender to know what is the expected time within which the email will be read by the recipient. In this paper we use a survival analysis framework to predict the time to open an email once it has been received. We use the Cox Proportional Hazards (CoxPH) model that offers a way to combine various features that might affect the event of opening an email. As an extension, we also apply a mixture model (MM) approach to CoxPH that distinguishes between recipients, based on a latent state of how prone to opening the messages each individual is. We compare our approach with standard classification and regression models. While the classification model provides predictions on the likelihood of an email being opened, the regression model provides prediction of the real-valued time to open. The use of survival analysis based methods allows us to jointly model both the open event as well as the time-to-open. We experimented on a large real-world dataset of marketing emails sent in a 3-month time duration. The mixture model achieves the best accuracy on our data where a high proportion of email messages go unopened.
* 9 pages, 5 figures, WSDM'18, February 5-9, 2018, Marina Del Rey, CA, USA, https://dl.acm.org/citation.cfm?id=3159683
Fingerprint Matching using the Onion Peeling Approach and Turning Function
Oct 03, 2021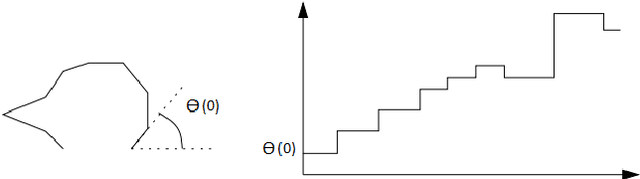
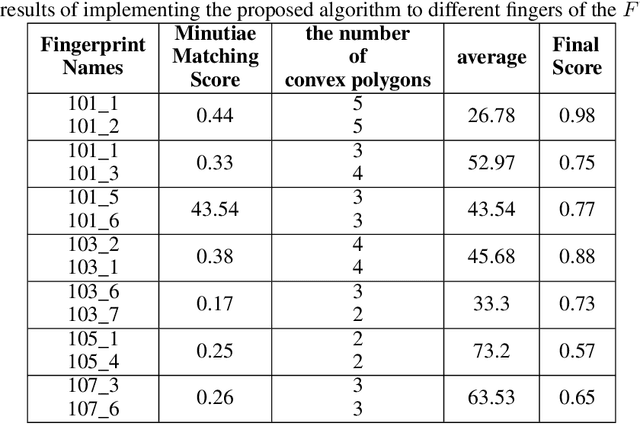
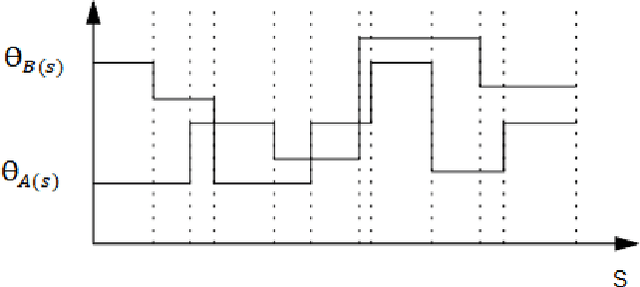
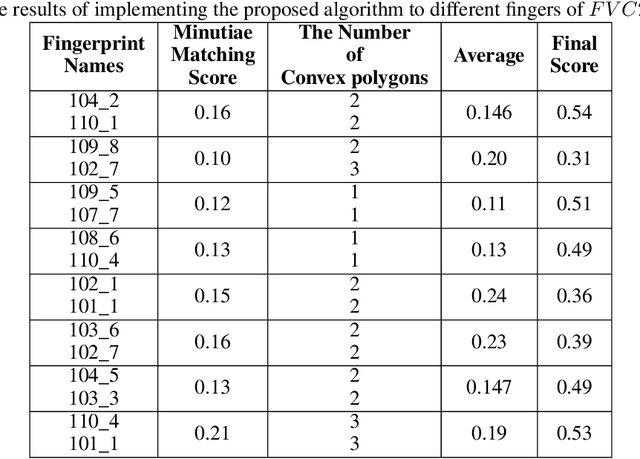
Fingerprint, as one of the most popular and robust biometric traits, can be used in automatic identification and verification systems to identify individuals. Fingerprint matching is a vital and challenging issue in fingerprint recognition systems. Most fingerprint matching algorithms are minutiae-based. The minutiae in fingerprints can be determined by their discontinuity. Ridge ending and ridge bifurcation are two frequently used minutiae in most fingerprint-based matching algorithms. This paper presents a new minutiae-based fingerprint matching using the onion peeling approach. In the proposed method, fingerprints are aligned to find the matched minutiae points. Then, the nested convex polygons of matched minutiae points are constructed and the comparison between peer-to-peer polygons is performed by the turning function distance. Simplicity, accuracy, and low time complexity of the Onion peeling approach are three important factors that make it a standard method for fingerprint matching purposes. The performance of the proposed algorithm is evaluated on the database $FVC2002$. The results show that fingerprints of the same fingers have higher scores than different fingers. Since the fingerprints that the difference between the number of their layers is more than $2$ and the minutiae matching score lower than 0.15 are ignored, the better results are obtained.
RAIL-KD: RAndom Intermediate Layer Mapping for Knowledge Distillation
Sep 21, 2021
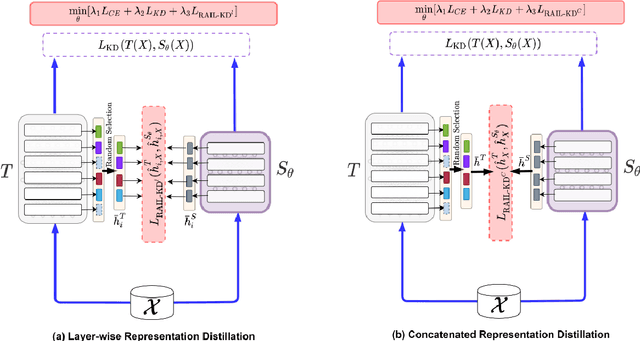
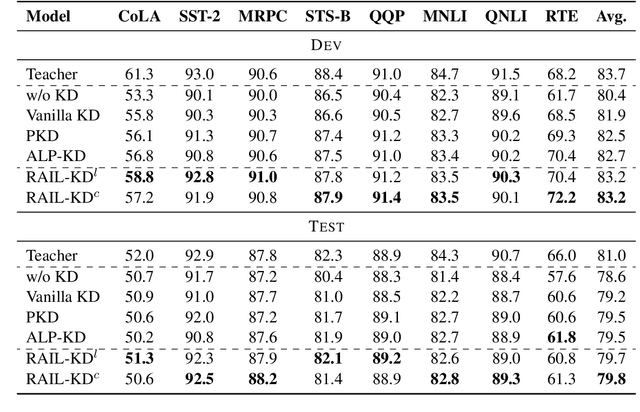
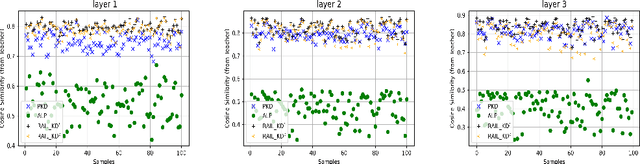
Intermediate layer knowledge distillation (KD) can improve the standard KD technique (which only targets the output of teacher and student models) especially over large pre-trained language models. However, intermediate layer distillation suffers from excessive computational burdens and engineering efforts required for setting up a proper layer mapping. To address these problems, we propose a RAndom Intermediate Layer Knowledge Distillation (RAIL-KD) approach in which, intermediate layers from the teacher model are selected randomly to be distilled into the intermediate layers of the student model. This randomized selection enforce that: all teacher layers are taken into account in the training process, while reducing the computational cost of intermediate layer distillation. Also, we show that it act as a regularizer for improving the generalizability of the student model. We perform extensive experiments on GLUE tasks as well as on out-of-domain test sets. We show that our proposed RAIL-KD approach outperforms other state-of-the-art intermediate layer KD methods considerably in both performance and training-time.
HydraSum -- Disentangling Stylistic Features in Text Summarization using Multi-Decoder Models
Oct 13, 2021
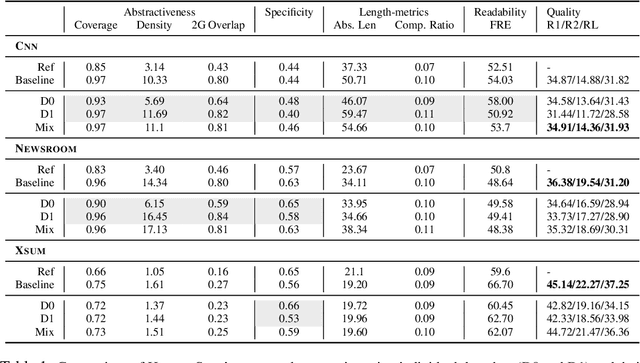
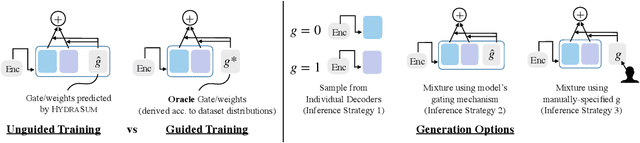

Existing abstractive summarization models lack explicit control mechanisms that would allow users to influence the stylistic features of the model outputs. This results in generating generic summaries that do not cater to the users needs or preferences. To address this issue we introduce HydraSum, a new summarization architecture that extends the single decoder framework of current models, e.g. BART, to a mixture-of-experts version consisting of multiple decoders. Our proposed model encourages each expert, i.e. decoder, to learn and generate stylistically-distinct summaries along dimensions such as abstractiveness, length, specificity, and others. At each time step, HydraSum employs a gating mechanism that decides the contribution of each individual decoder to the next token's output probability distribution. Through experiments on three summarization datasets (CNN, Newsroom, XSum), we demonstrate that this gating mechanism automatically learns to assign contrasting summary styles to different HydraSum decoders under the standard training objective without the need for additional supervision. We further show that a guided version of the training process can explicitly govern which summary style is partitioned between decoders, e.g. high abstractiveness vs. low abstractiveness or high specificity vs. low specificity, and also increase the stylistic-difference between individual decoders. Finally, our experiments demonstrate that our decoder framework is highly flexible: during inference, we can sample from individual decoders or mixtures of different subsets of the decoders to yield a diverse set of summaries and enforce single- and multi-style control over summary generation.
Keiki: Towards Realistic Danmaku Generation via Sequential GANs
Jul 07, 2021
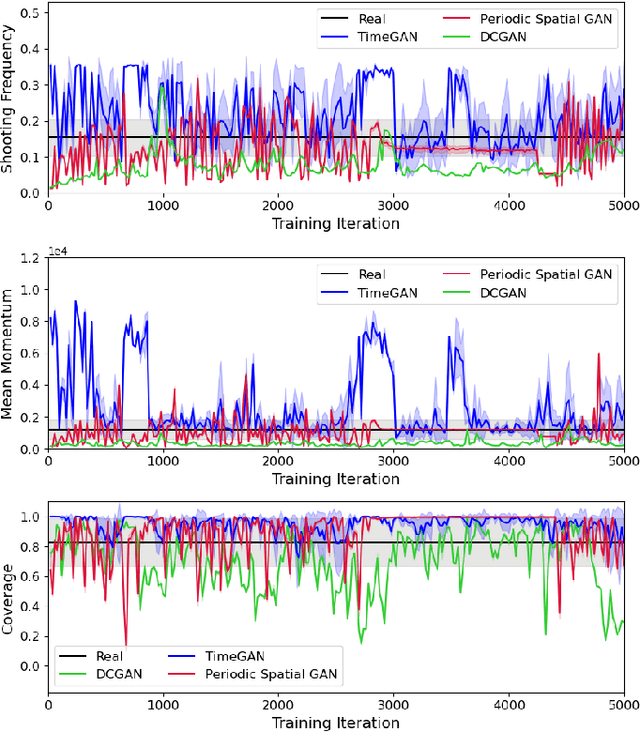
Search-based procedural content generation methods have recently been introduced for the autonomous creation of bullet hell games. Search-based methods, however, can hardly model patterns of danmakus -- the bullet hell shooting entity -- explicitly and the resulting levels often look non-realistic. In this paper, we present a novel bullet hell game platform named Keiki, which allows the representation of danmakus as a parametric sequence which, in turn, can model the sequential behaviours of danmakus. We employ three types of generative adversarial networks (GANs) and test Keiki across three metrics designed to quantify the quality of the generated danmakus. The time-series GAN and periodic spatial GAN show different yet competitive performance in terms of the evaluation metrics adopted, their deviation from human-designed danmakus, and the diversity of generated danmakus. The preliminary experimental studies presented here showcase that potential of time-series GANs for sequential content generation in games.
Real-Time, Environmentally-Robust 3D LiDAR Localization
Oct 28, 2019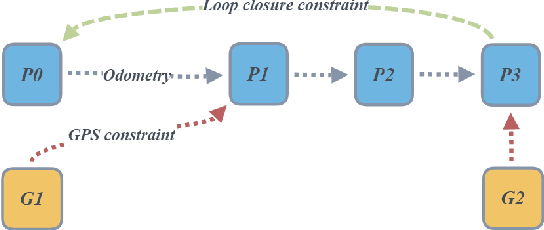
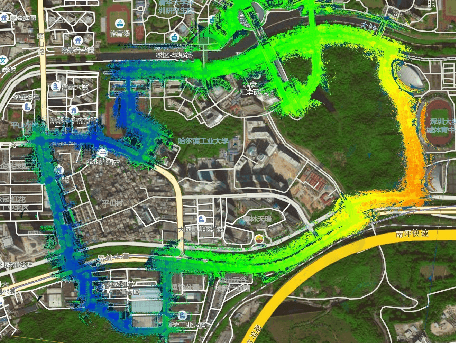

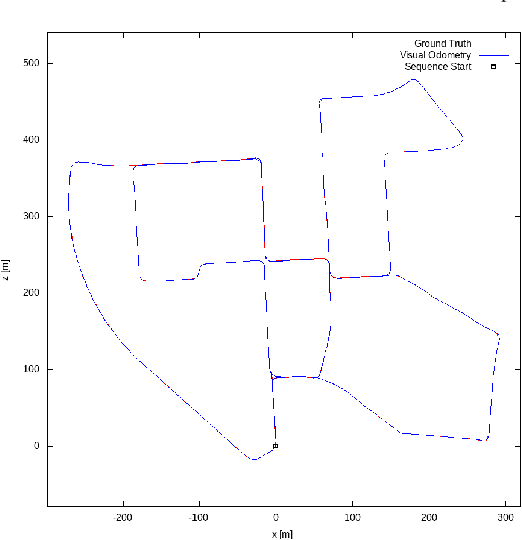
Localization, or position fixing, is an important problem in robotics research. In this paper, we propose a novel approach for long-term localization in a changing environment using 3D LiDAR. We first create the map of a real environment using GPS and LiDAR. Then, we divide the map into several small parts as the targets for cloud registration, which can not only improve the robustness but also reduce the registration time. PointLocalization allows us to fuse different kinds of odometers, which can optimize the accuracy and frequency of localization results. We evaluate our algorithm on an unmanned ground vehicle (UGV) using LiDAR and a wheel encoder, and obtain the localization results at more than 20 Hz after fusion. The algorithm can also localize the UGV in a 180-degree field of view (FOV). Using an outdated map captured six months ago, this algorithm shows great robustness, and the test results show that it can achieve an accuracy of 10 cm. PointLocalization has been tested for a period of more than six months in a crowded factory and has operated successfully over a distance of more than 2000 km.
Experience feedback using Representation Learning for Few-Shot Object Detection on Aerial Images
Sep 27, 2021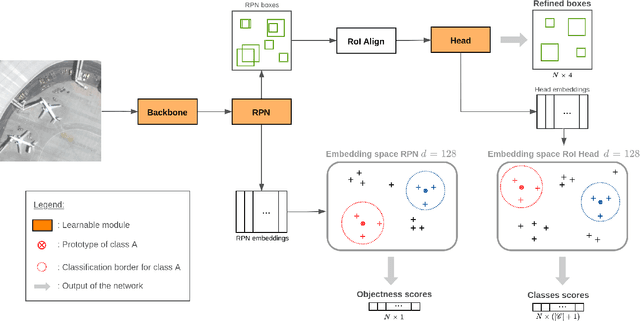
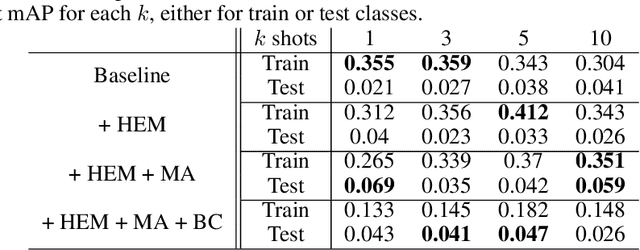
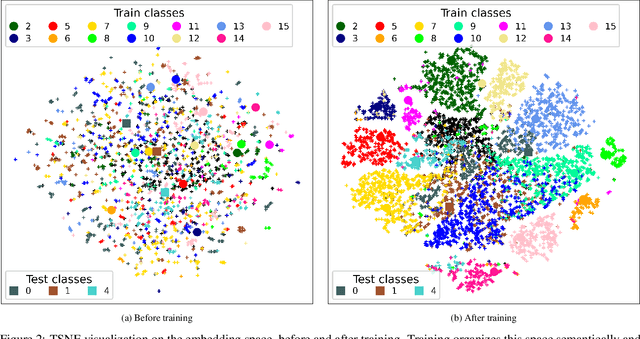
This paper proposes a few-shot method based on Faster R-CNN and representation learning for object detection in aerial images. The two classification branches of Faster R-CNN are replaced by prototypical networks for online adaptation to new classes. These networks produce embeddings vectors for each generated box, which are then compared with class prototypes. The distance between an embedding and a prototype determines the corresponding classification score. The resulting networks are trained in an episodic manner. A new detection task is randomly sampled at each epoch, consisting in detecting only a subset of the classes annotated in the dataset. This training strategy encourages the network to adapt to new classes as it would at test time. In addition, several ideas are explored to improve the proposed method such as a hard negative examples mining strategy and self-supervised clustering for background objects. The performance of our method is assessed on DOTA, a large-scale remote sensing images dataset. The experiments conducted provide a broader understanding of the capabilities of representation learning. It highlights in particular some intrinsic weaknesses for the few-shot object detection task. Finally, some suggestions and perspectives are formulated according to these insights.
Attention Gate in Traffic Forecasting
Sep 27, 2021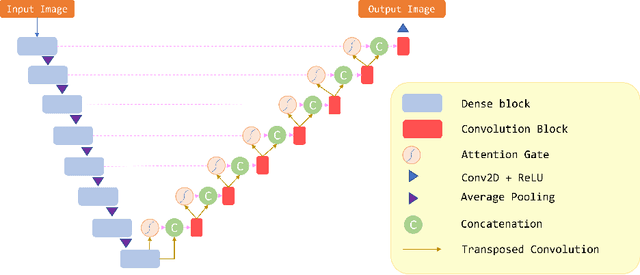
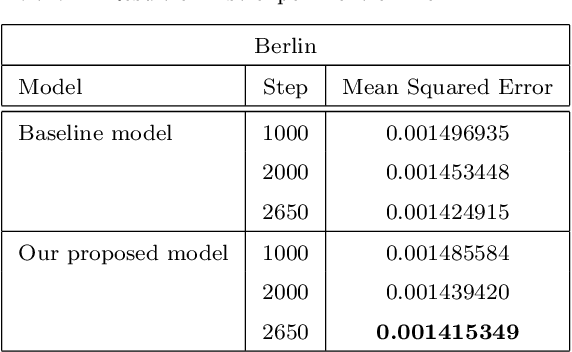
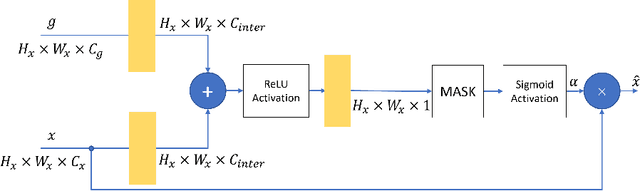
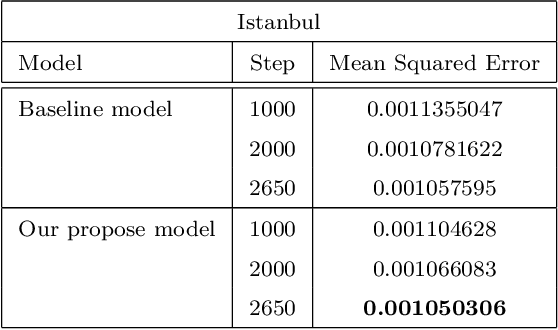
Because of increased urban complexity and growing populations, more and more challenges about predicting city-wide mobility behavior are being organized. Traffic Map Movie Forecasting Challenge 2020 is secondly held in the competition track of the Thirty-fourth Conference on Neural Information Processing Systems (NeurIPS). Similar to Traffic4Cast 2019, the task is to predict traffic flow volume, average speed in major directions on the geographical area of three big cities: Berlin, Istanbul, and Moscow. In this paper, we apply the attention mechanism on U-Net based model, especially we add an attention gate on the skip-connection between contraction path and expansion path. An attention gates filter features from the contraction path before combining with features on the expansion path, it enables our model to reduce the effect of non-traffic region features and focus more on crucial region features. In addition to the competition data, we also propose two extra features which often affect traffic flow, that are time and weekdays. We experiment with our model on the competition dataset and reproduce the winner solution in the same environment. Overall, our model archives better performance than recent methods.