 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
HUMAN4D: A Human-Centric Multimodal Dataset for Motions and Immersive Media
Oct 14, 2021


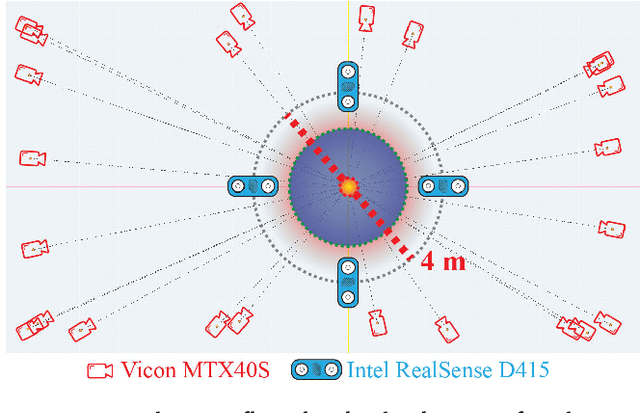
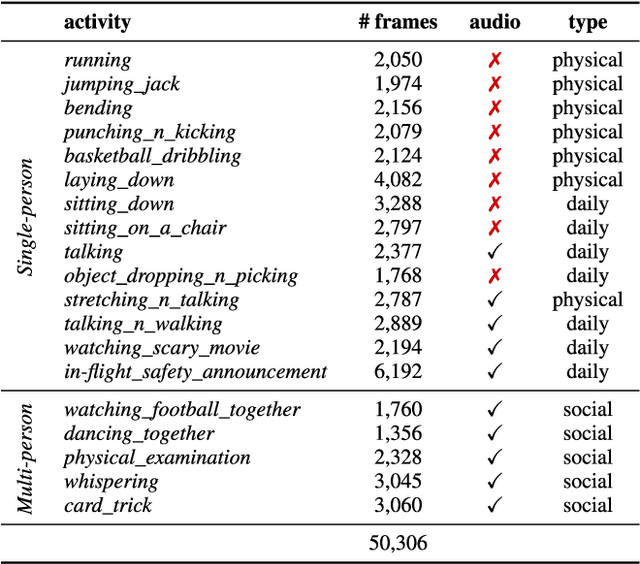
We introduce HUMAN4D, a large and multimodal 4D dataset that contains a variety of human activities simultaneously captured by a professional marker-based MoCap, a volumetric capture and an audio recording system. By capturing 2 female and $2$ male professional actors performing various full-body movements and expressions, HUMAN4D provides a diverse set of motions and poses encountered as part of single- and multi-person daily, physical and social activities (jumping, dancing, etc.), along with multi-RGBD (mRGBD), volumetric and audio data. Despite the existence of multi-view color datasets captured with the use of hardware (HW) synchronization, to the best of our knowledge, HUMAN4D is the first and only public resource that provides volumetric depth maps with high synchronization precision due to the use of intra- and inter-sensor HW-SYNC. Moreover, a spatio-temporally aligned scanned and rigged 3D character complements HUMAN4D to enable joint research on time-varying and high-quality dynamic meshes. We provide evaluation baselines by benchmarking HUMAN4D with state-of-the-art human pose estimation and 3D compression methods. For the former, we apply 2D and 3D pose estimation algorithms both on single- and multi-view data cues. For the latter, we benchmark open-source 3D codecs on volumetric data respecting online volumetric video encoding and steady bit-rates. Furthermore, qualitative and quantitative visual comparison between mesh-based volumetric data reconstructed in different qualities showcases the available options with respect to 4D representations. HUMAN4D is introduced to the computer vision and graphics research communities to enable joint research on spatio-temporally aligned pose, volumetric, mRGBD and audio data cues. The dataset and its code are available https://tofis.github.io/myurls/human4d.
FastCorrect 2: Fast Error Correction on Multiple Candidates for Automatic Speech Recognition
Oct 18, 2021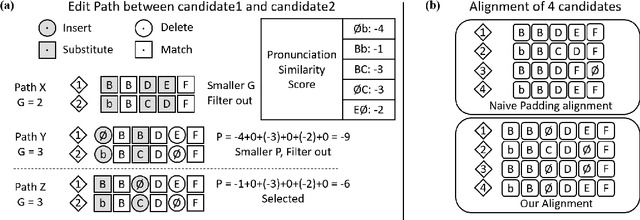
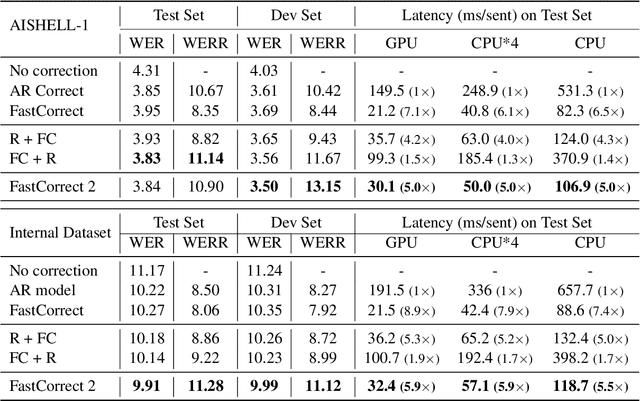
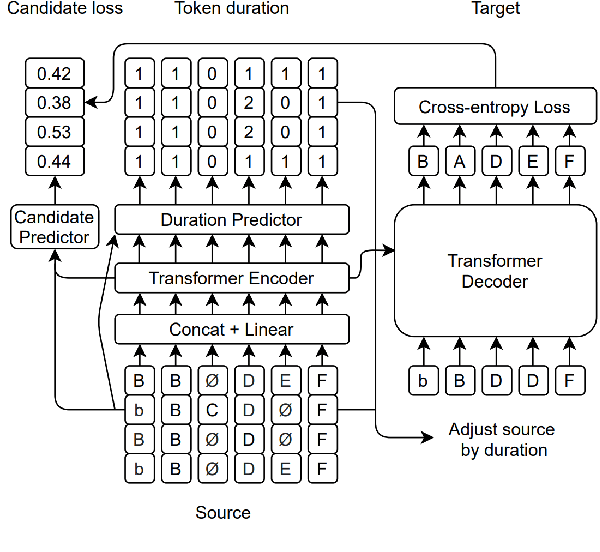
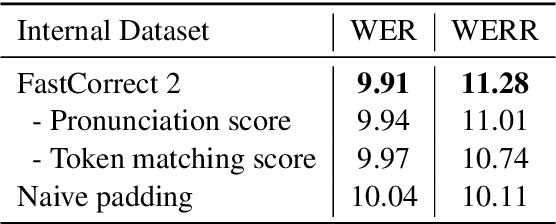
Error correction is widely used in automatic speech recognition (ASR) to post-process the generated sentence, and can further reduce the word error rate (WER). Although multiple candidates are generated by an ASR system through beam search, current error correction approaches can only correct one sentence at a time, failing to leverage the voting effect from multiple candidates to better detect and correct error tokens. In this work, we propose FastCorrect 2, an error correction model that takes multiple ASR candidates as input for better correction accuracy. FastCorrect 2 adopts non-autoregressive generation for fast inference, which consists of an encoder that processes multiple source sentences and a decoder that generates the target sentence in parallel from the adjusted source sentence, where the adjustment is based on the predicted duration of each source token. However, there are some issues when handling multiple source sentences. First, it is non-trivial to leverage the voting effect from multiple source sentences since they usually vary in length. Thus, we propose a novel alignment algorithm to maximize the degree of token alignment among multiple sentences in terms of token and pronunciation similarity. Second, the decoder can only take one adjusted source sentence as input, while there are multiple source sentences. Thus, we develop a candidate predictor to detect the most suitable candidate for the decoder. Experiments on our inhouse dataset and AISHELL-1 show that FastCorrect 2 can further reduce the WER over the previous correction model with single candidate by 3.2% and 2.6%, demonstrating the effectiveness of leveraging multiple candidates in ASR error correction. FastCorrect 2 achieves better performance than the cascaded re-scoring and correction pipeline and can serve as a unified post-processing module for ASR.
Graph Algorithms for Multiparallel Word Alignment
Sep 13, 2021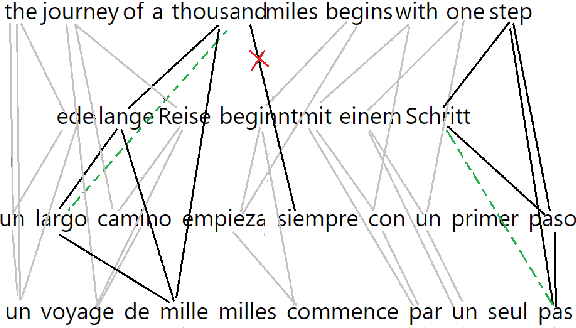

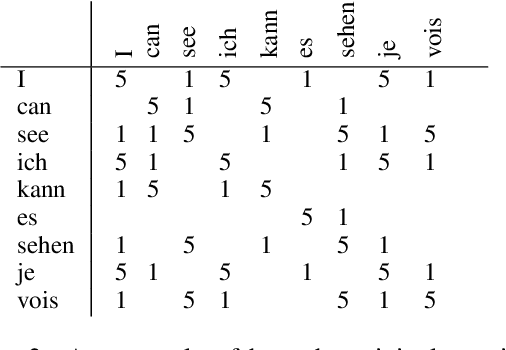

With the advent of end-to-end deep learning approaches in machine translation, interest in word alignments initially decreased; however, they have again become a focus of research more recently. Alignments are useful for typological research, transferring formatting like markup to translated texts, and can be used in the decoding of machine translation systems. At the same time, massively multilingual processing is becoming an important NLP scenario, and pretrained language and machine translation models that are truly multilingual are proposed. However, most alignment algorithms rely on bitexts only and do not leverage the fact that many parallel corpora are multiparallel. In this work, we exploit the multiparallelity of corpora by representing an initial set of bilingual alignments as a graph and then predicting additional edges in the graph. We present two graph algorithms for edge prediction: one inspired by recommender systems and one based on network link prediction. Our experimental results show absolute improvements in $F_1$ of up to 28% over the baseline bilingual word aligner in different datasets.
Bagging, optimized dynamic mode decomposition (BOP-DMD) for robust, stable forecasting with spatial and temporal uncertainty-quantification
Jul 22, 2021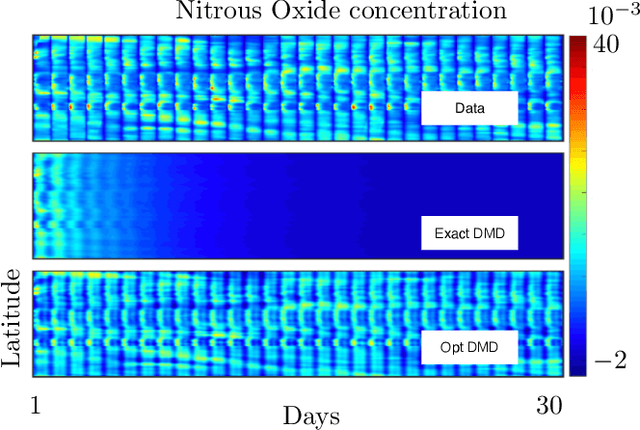
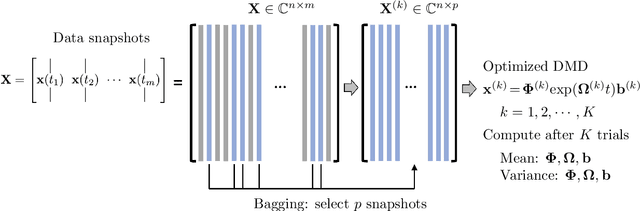
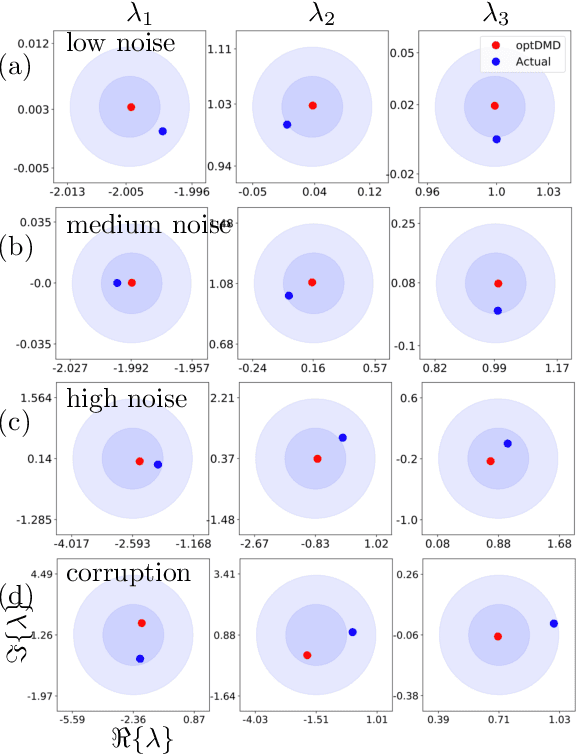
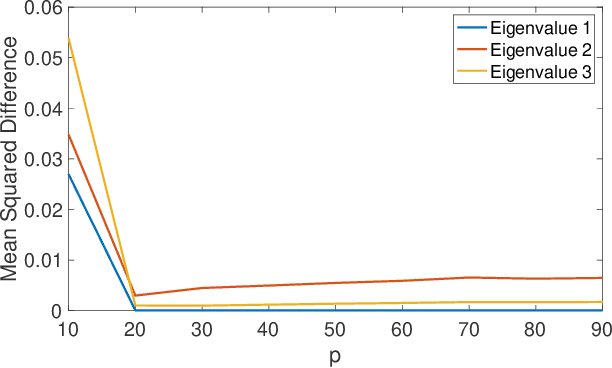
Dynamic mode decomposition (DMD) provides a regression framework for adaptively learning a best-fit linear dynamics model over snapshots of temporal, or spatio-temporal, data. A diversity of regression techniques have been developed for producing the linear model approximation whose solutions are exponentials in time. For spatio-temporal data, DMD provides low-rank and interpretable models in the form of dominant modal structures along with their exponential/oscillatory behavior in time. The majority of DMD algorithms, however, are prone to bias errors from noisy measurements of the dynamics, leading to poor model fits and unstable forecasting capabilities. The optimized DMD algorithm minimizes the model bias with a variable projection optimization, thus leading to stabilized forecasting capabilities. Here, the optimized DMD algorithm is improved by using statistical bagging methods whereby a single set of snapshots is used to produce an ensemble of optimized DMD models. The outputs of these models are averaged to produce a bagging, optimized dynamic mode decomposition (BOP-DMD). BOP-DMD not only improves performance, it also robustifies the model and provides both spatial and temporal uncertainty quantification (UQ). Thus unlike currently available DMD algorithms, BOP-DMD provides a stable and robust model for probabilistic, or Bayesian forecasting with comprehensive UQ metrics.
Structured Outdoor Architecture Reconstruction by Exploration and Classification
Aug 18, 2021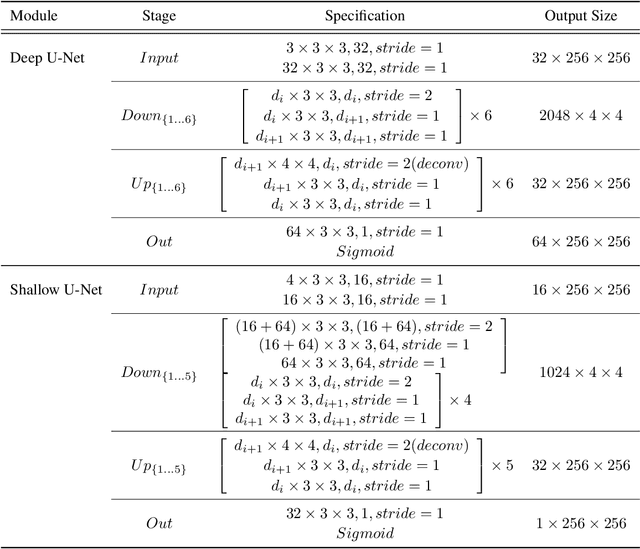


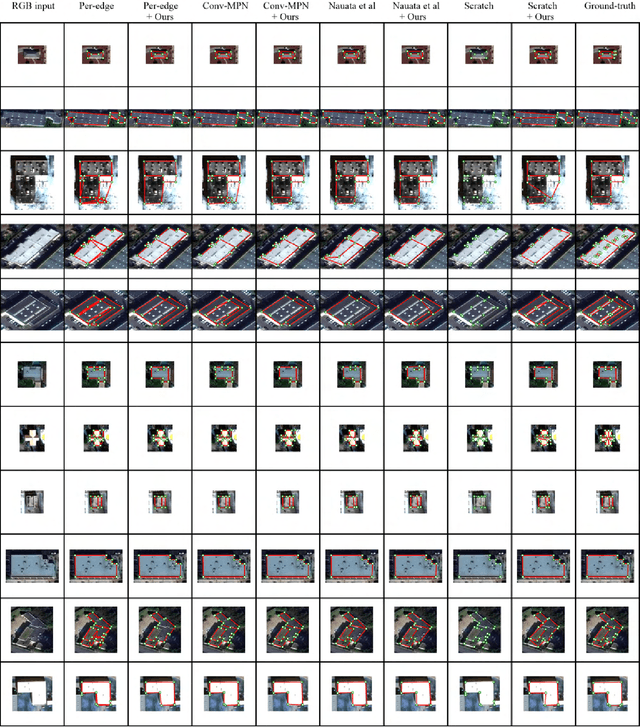
This paper presents an explore-and-classify framework for structured architectural reconstruction from an aerial image. Starting from a potentially imperfect building reconstruction by an existing algorithm, our approach 1) explores the space of building models by modifying the reconstruction via heuristic actions; 2) learns to classify the correctness of building models while generating classification labels based on the ground-truth, and 3) repeat. At test time, we iterate exploration and classification, seeking for a result with the best classification score. We evaluate the approach using initial reconstructions by two baselines and two state-of-the-art reconstruction algorithms. Qualitative and quantitative evaluations demonstrate that our approach consistently improves the reconstruction quality from every initial reconstruction.
Incremental Abstraction in Distributed Probabilistic SLAM Graphs
Sep 13, 2021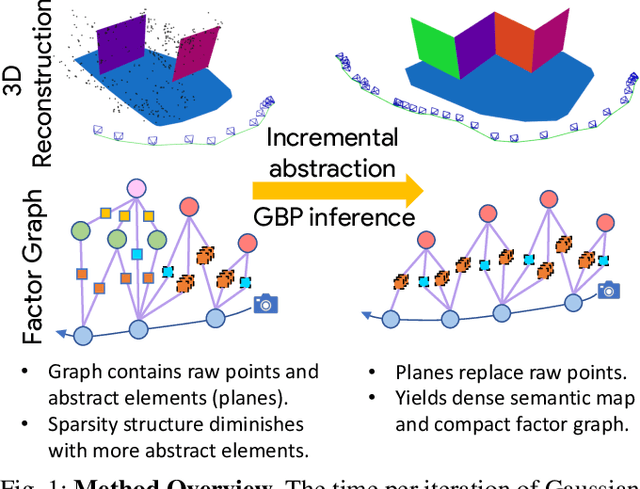
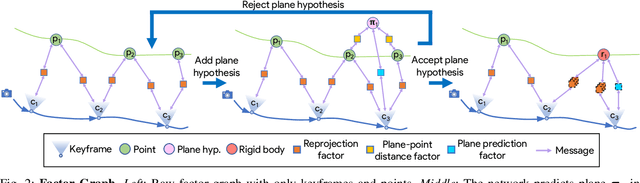
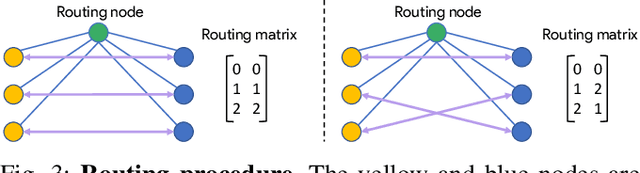
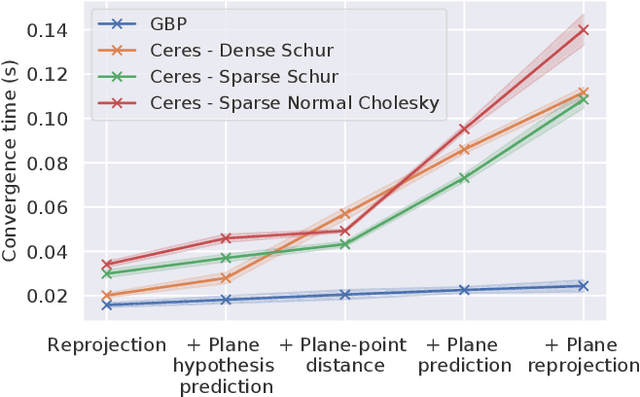
Scene graphs represent the key components of a scene in a compact and semantically rich way, but are difficult to build during incremental SLAM operation because of the challenges of robustly identifying abstract scene elements and optimising continually changing, complex graphs. We present a distributed, graph-based SLAM framework for incrementally building scene graphs based on two novel components. First, we propose an incremental abstraction framework in which a neural network proposes abstract scene elements that are incorporated into the factor graph of a feature-based monocular SLAM system. Scene elements are confirmed or rejected through optimisation and incrementally replace the points yielding a more dense, semantic and compact representation. Second, enabled by our novel routing procedure, we use Gaussian Belief Propagation (GBP) for distributed inference on a graph processor. The time per iteration of GBP is structure-agnostic and we demonstrate the speed advantages over direct methods for inference of heterogeneous factor graphs. We run our system on real indoor datasets using planar abstractions and recover the major planes with significant compression.
RoboRun: A Robot Runtime to Exploit Spatial Heterogeneity
Aug 30, 2021
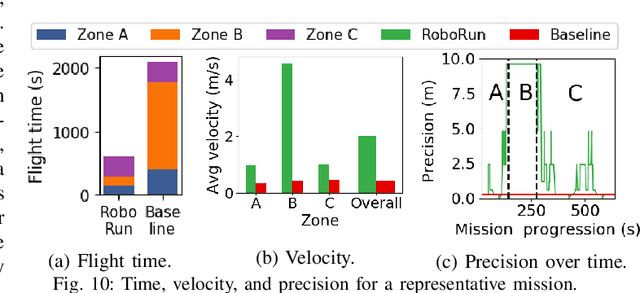
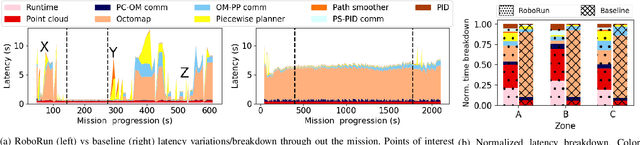
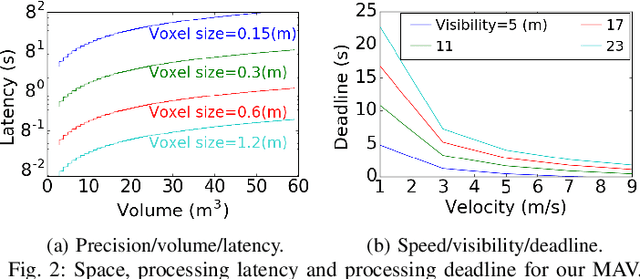
The limited onboard energy of autonomous mobile robots poses a tremendous challenge for practical deployment. Hence, efficient computing solutions are imperative. A crucial shortcoming of state-of-the-art computing solutions is that they ignore the robot's operating environment heterogeneity and make static, worst-case assumptions. As this heterogeneity impacts the system's computing payload, an optimal system must dynamically capture these changes in the environment and adjust its computational resources accordingly. This paper introduces RoboRun, a mobile-robot runtime that dynamically exploits the compute-environment synergy to improve performance and energy. We implement RoboRun in the Robot Operating System (ROS) and evaluate it on autonomous drones. We compare RoboRun against a state-of-the-art static design and show 4.5X and 4X improvements in mission time and energy, respectively, as well as a 36% reduction in CPU utilization.
Weakly-Supervised Object Detection Learning through Human-Robot Interaction
Jul 16, 2021
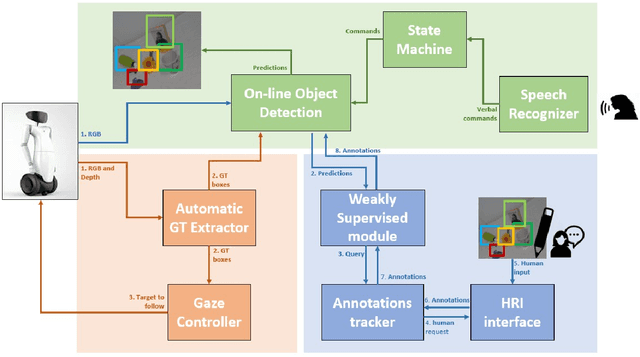

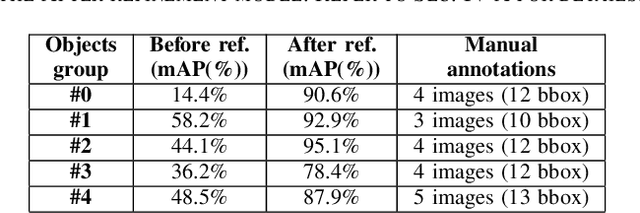
Reliable perception and efficient adaptation to novel conditions are priority skills for humanoids that function in dynamic environments. The vast advancements in latest computer vision research, brought by deep learning methods, are appealing for the robotics community. However, their adoption in applied domains is not straightforward since adapting them to new tasks is strongly demanding in terms of annotated data and optimization time. Nevertheless, robotic platforms, and especially humanoids, present opportunities (such as additional sensors and the chance to explore the environment) that can be exploited to overcome these issues. In this paper, we present a pipeline for efficiently training an object detection system on a humanoid robot. The proposed system allows to iteratively adapt an object detection model to novel scenarios, by exploiting: (i) a teacher-learner pipeline, (ii) weakly supervised learning techniques to reduce the human labeling effort and (iii) an on-line learning approach for fast model re-training. We use the R1 humanoid robot for both testing the proposed pipeline in a real-time application and acquire sequences of images to benchmark the method. We made the code of the application publicly available.
Real-Time and Accurate Object Detection in Compressed Video by Long Short-term Feature Aggregation
Mar 25, 2021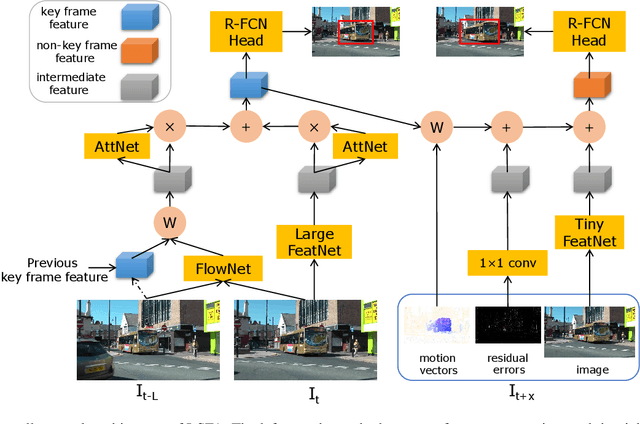
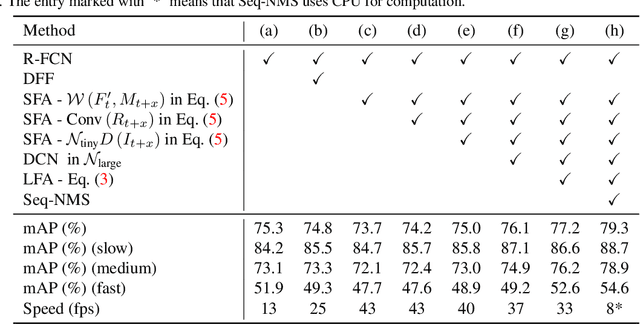
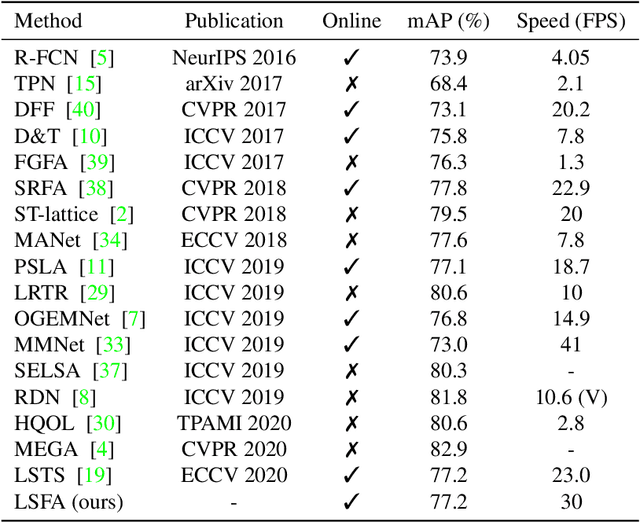

Video object detection is a fundamental problem in computer vision and has a wide spectrum of applications. Based on deep networks, video object detection is actively studied for pushing the limits of detection speed and accuracy. To reduce the computation cost, we sparsely sample key frames in video and treat the rest frames are non-key frames; a large and deep network is used to extract features for key frames and a tiny network is used for non-key frames. To enhance the features of non-key frames, we propose a novel short-term feature aggregation method to propagate the rich information in key frame features to non-key frame features in a fast way. The fast feature aggregation is enabled by the freely available motion cues in compressed videos. Further, key frame features are also aggregated based on optical flow. The propagated deep features are then integrated with the directly extracted features for object detection. The feature extraction and feature integration parameters are optimized in an end-to-end manner. The proposed video object detection network is evaluated on the large-scale ImageNet VID benchmark and achieves 77.2\% mAP, which is on-par with state-of-the-art accuracy, at the speed of 30 FPS using a Titan X GPU. The source codes are available at \url{https://github.com/hustvl/LSFA}.
Solving Large Break Minimization Problems in a Mirrored Double Round-robin Tournament Using Quantum Annealing
Oct 18, 2021
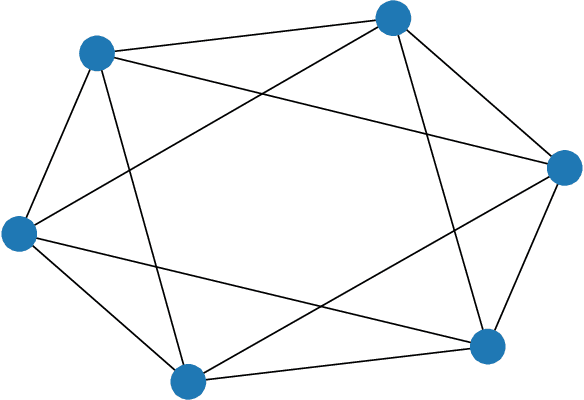
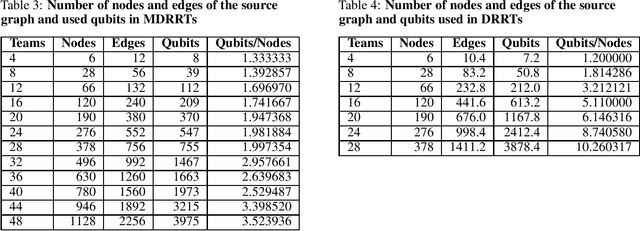
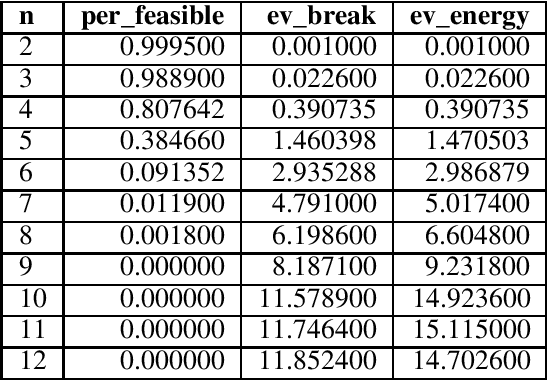
Quantum annealing (QA) has gained considerable attention because it can be applied to combinatorial optimization problems, which have numerous applications in logistics, scheduling, and finance. In recent years, research on solving practical combinatorial optimization problems using them has accelerated. However, researchers struggle to find practical combinatorial optimization problems, for which quantum annealers outperform other mathematical optimization solvers. Moreover, there are only a few studies that compare the performance of quantum annealers with one of the most sophisticated mathematical optimization solvers, such as Gurobi and CPLEX. In our study, we determine that QA demonstrates better performance than the solvers in the break minimization problem in a mirrored double round-robin tournament (MDRRT). We also explain the desirable performance of QA for the sparse interaction between variables and a problem without constraints. In this process, we demonstrate that the break minimization problem in an MDRRT can be expressed as a 4-regular graph. Through computational experiments, we solve this problem using our QA approach and two-integer programming approaches, which were performed using the latest quantum annealer D-Wave Advantage, and the sophisticated mathematical optimization solver, Gurobi, respectively. Further, we compare the quality of the solutions and the computational time. QA was able to determine the exact solution in 0.05 seconds for problems with 20 teams, which is a practical size. In the case of 36 teams, it took 84.8 s for the integer programming method to reach the objective function value, which was obtained by the quantum annealer in 0.05 s. These results not only present the break minimization problem in an MDRRT as an example of applying QA to practical optimization problems, but also contribute to find problems that can be effectively solved by QA.