 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
You should evaluate your language model on marginal likelihood over tokenisations
Sep 21, 2021
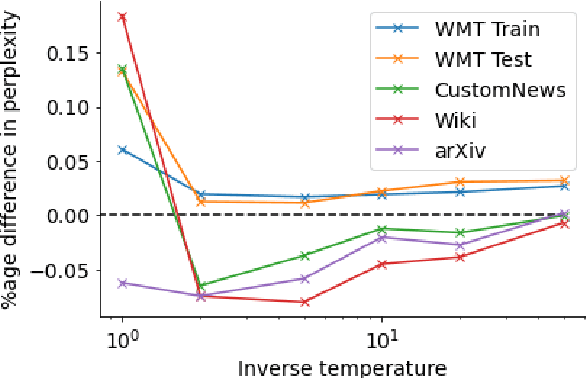
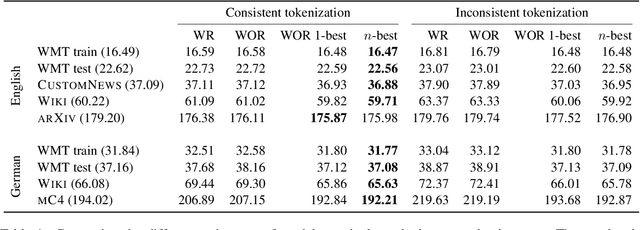
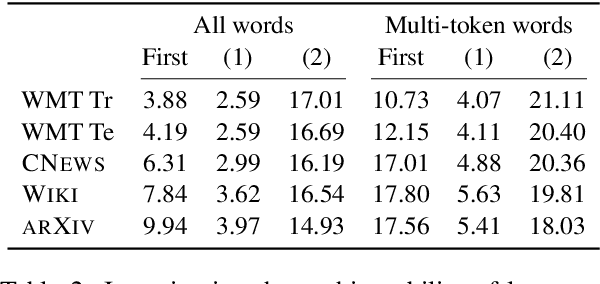
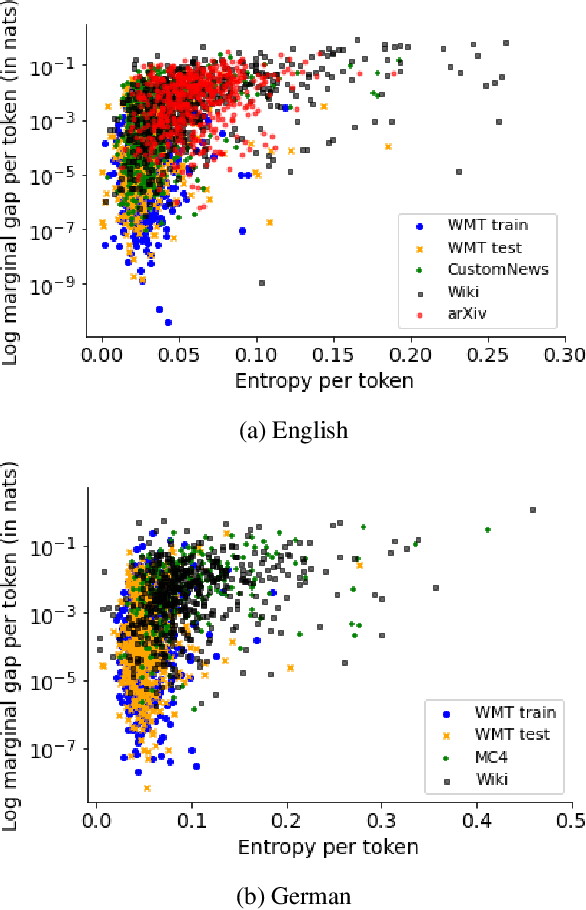
Neural language models typically tokenise input text into sub-word units to achieve an open vocabulary. The standard approach is to use a single canonical tokenisation at both train and test time. We suggest that this approach is unsatisfactory and may bottleneck our evaluation of language model performance. Using only the one-best tokenisation ignores tokeniser uncertainty over alternative tokenisations, which may hurt model out-of-domain performance. In this paper, we argue that instead, language models should be evaluated on their marginal likelihood over tokenisations. We compare different estimators for the marginal likelihood based on sampling, and show that it is feasible to estimate the marginal likelihood with a manageable number of samples. We then evaluate pretrained English and German language models on both the one-best-tokenisation and marginal perplexities, and show that the marginal perplexity can be significantly better than the one best, especially on out-of-domain data. We link this difference in perplexity to the tokeniser uncertainty as measured by tokeniser entropy. We discuss some implications of our results for language model training and evaluation, particularly with regard to tokenisation robustness.
Fast Extraction of Word Embedding from Q-contexts
Sep 15, 2021
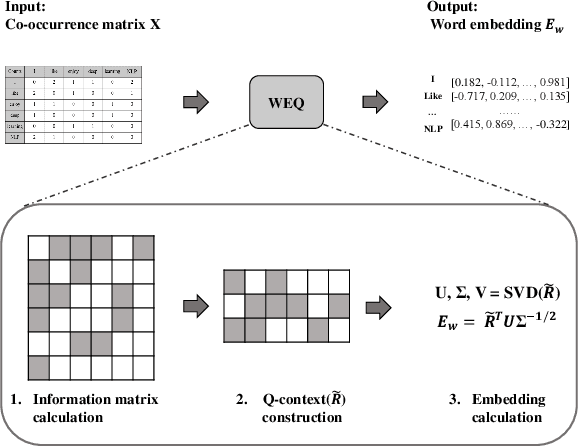
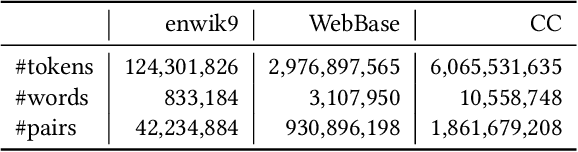
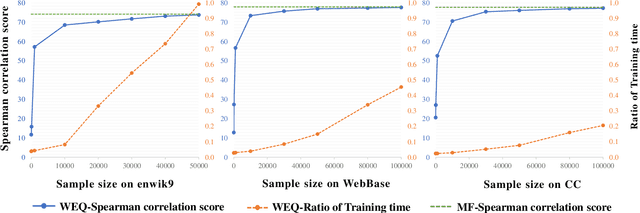
The notion of word embedding plays a fundamental role in natural language processing (NLP). However, pre-training word embedding for very large-scale vocabulary is computationally challenging for most existing methods. In this work, we show that with merely a small fraction of contexts (Q-contexts)which are typical in the whole corpus (and their mutual information with words), one can construct high-quality word embedding with negligible errors. Mutual information between contexts and words can be encoded canonically as a sampling state, thus, Q-contexts can be fast constructed. Furthermore, we present an efficient and effective WEQ method, which is capable of extracting word embedding directly from these typical contexts. In practical scenarios, our algorithm runs 11$\sim$13 times faster than well-established methods. By comparing with well-known methods such as matrix factorization, word2vec, GloVeand fasttext, we demonstrate that our method achieves comparable performance on a variety of downstream NLP tasks, and in the meanwhile maintains run-time and resource advantages over all these baselines.
Neural Waveshaping Synthesis
Jul 11, 2021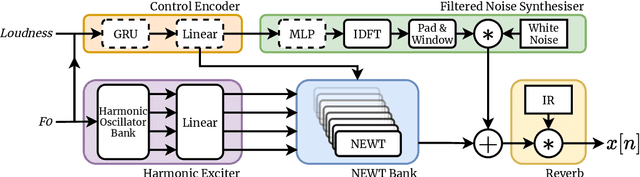
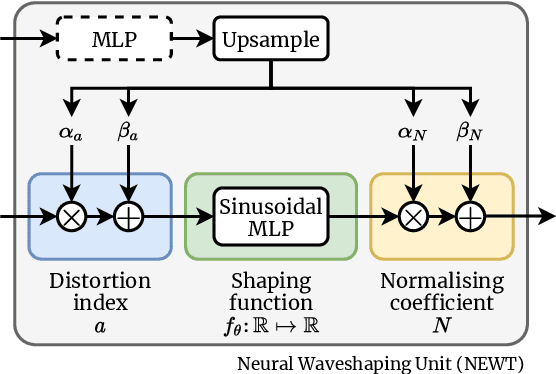
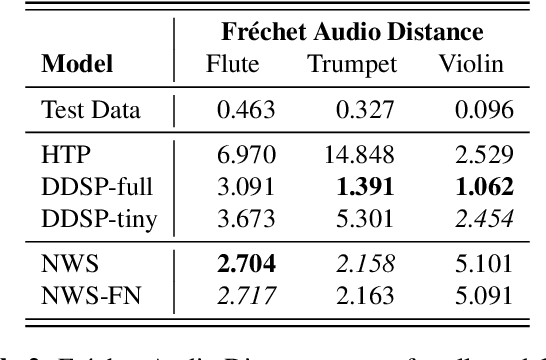
We present the Neural Waveshaping Unit (NEWT): a novel, lightweight, fully causal approach to neural audio synthesis which operates directly in the waveform domain, with an accompanying optimisation (FastNEWT) for efficient CPU inference. The NEWT uses time-distributed multilayer perceptrons with periodic activations to implicitly learn nonlinear transfer functions that encode the characteristics of a target timbre. Once trained, a NEWT can produce complex timbral evolutions by simple affine transformations of its input and output signals. We paired the NEWT with a differentiable noise synthesiser and reverb and found it capable of generating realistic musical instrument performances with only 260k total model parameters, conditioned on F0 and loudness features. We compared our method to state-of-the-art benchmarks with a multi-stimulus listening test and the Fr\'echet Audio Distance and found it performed competitively across the tested timbral domains. Our method significantly outperformed the benchmarks in terms of generation speed, and achieved real-time performance on a consumer CPU, both with and without FastNEWT, suggesting it is a viable basis for future creative sound design tools.
A Computationally Efficient EK-PMBM Filter for Bistatic mmWave Radio SLAM
Sep 08, 2021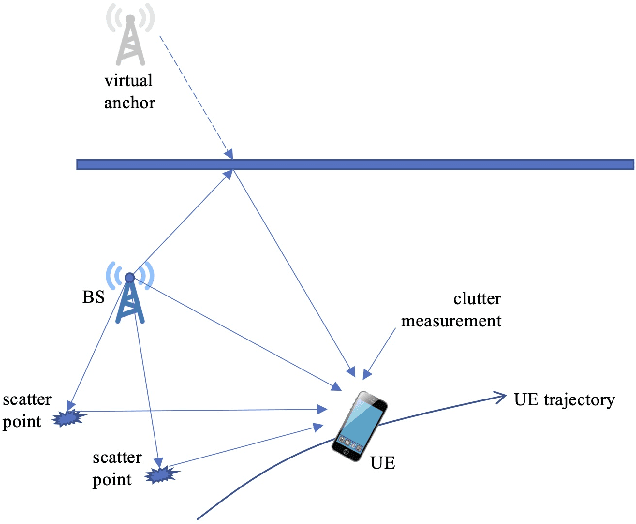
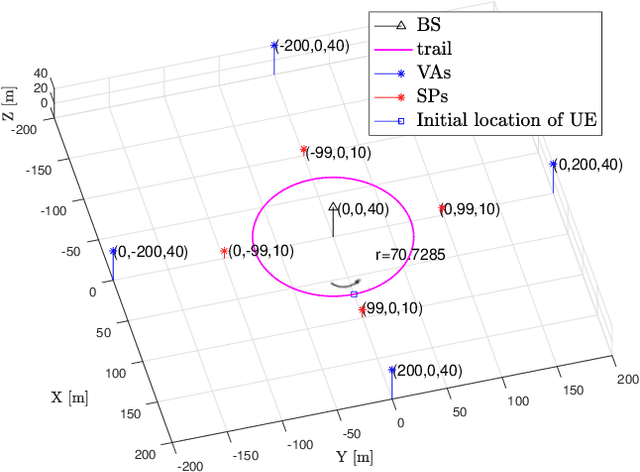
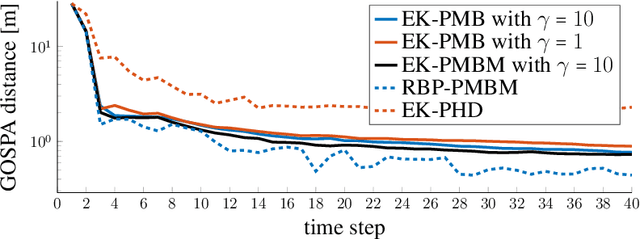
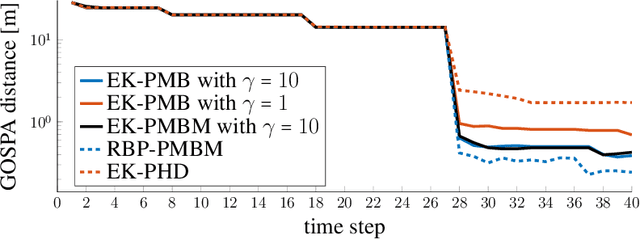
Millimeter wave (mmWave) signals are useful for simultaneous localization and mapping (SLAM), due to their inherent geometric connection to the propagation environment and the propagation channel. To solve the SLAM problem, existing approaches rely on sigma-point or particle-based approximations, leading to high computational complexity, precluding real-time execution. We propose a novel low-complexity SLAM filter, based on the Poisson multi-Bernoulli mixture (PMBM) filter. It utilizes the extended Kalman (EK) first-order Taylor series based Gaussian approximation of the filtering distribution, and applies the track-oriented marginal multi-Bernoulli/Poisson (TOMB/P) algorithm to approximate the resulting PMBM as a Poisson multi-Bernoulli (PMB). The filter can account for different landmark types in radio SLAM and multiple data association hypotheses. Hence, it has an adjustable complexity/performance trade-off. Simulation results show that the developed SLAM filter can greatly reduce the computational cost, while it keeps the good performance of mapping and user state estimation.
Learning a subspace of policies for online adaptation in Reinforcement Learning
Oct 11, 2021
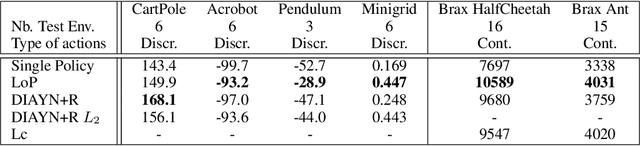

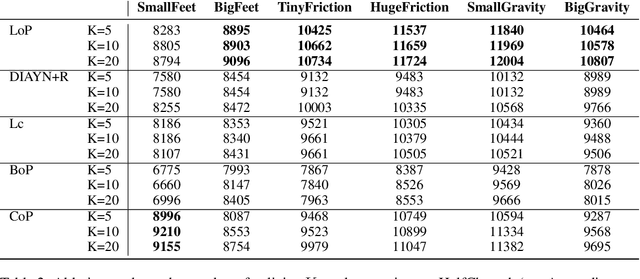
Deep Reinforcement Learning (RL) is mainly studied in a setting where the training and the testing environments are similar. But in many practical applications, these environments may differ. For instance, in control systems, the robot(s) on which a policy is learned might differ from the robot(s) on which a policy will run. It can be caused by different internal factors (e.g., calibration issues, system attrition, defective modules) or also by external changes (e.g., weather conditions). There is a need to develop RL methods that generalize well to variations of the training conditions. In this article, we consider the simplest yet hard to tackle generalization setting where the test environment is unknown at train time, forcing the agent to adapt to the system's new dynamics. This online adaptation process can be computationally expensive (e.g., fine-tuning) and cannot rely on meta-RL techniques since there is just a single train environment. To do so, we propose an approach where we learn a subspace of policies within the parameter space. This subspace contains an infinite number of policies that are trained to solve the training environment while having different parameter values. As a consequence, two policies in that subspace process information differently and exhibit different behaviors when facing variations of the train environment. Our experiments carried out over a large variety of benchmarks compare our approach with baselines, including diversity-based methods. In comparison, our approach is simple to tune, does not need any extra component (e.g., discriminator) and learns policies able to gather a high reward on unseen environments.
Reinforcement Learning for Systematic FX Trading
Oct 15, 2021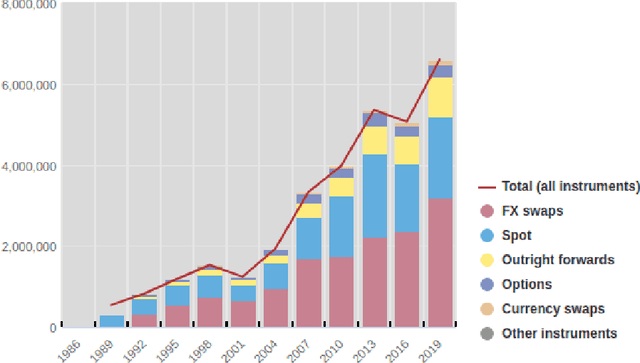
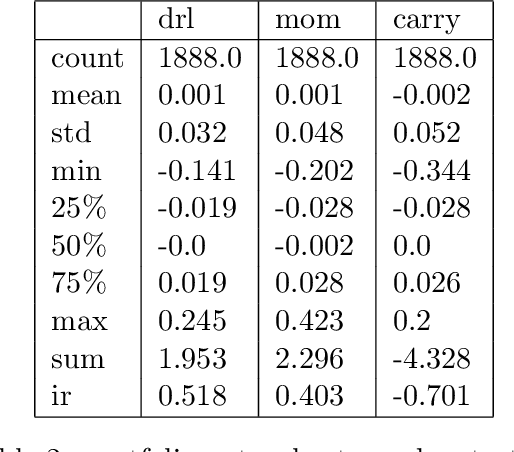
We conduct a detailed experiment on major cash fx pairs, accurately accounting for transaction and funding costs. These sources of profit and loss, including the price trends that occur in the currency markets, are made available to our recurrent reinforcement learner via a quadratic utility, which learns to target a position directly. We improve upon earlier work, by casting the problem of learning to target a risk position, in an online learning context. This online learning occurs sequentially in time, but also in the form of transfer learning. We transfer the output of radial basis function hidden processing units, whose means, covariances and overall size are determined by Gaussian mixture models, to the recurrent reinforcement learner and baseline momentum trader. Thus the intrinsic nature of the feature space is learnt and made available to the upstream models. The recurrent reinforcement learning trader achieves an annualised portfolio information ratio of 0.52 with compound return of 9.3%, net of execution and funding cost, over a 7 year test set. This is despite forcing the model to trade at the close of the trading day 5pm EST, when trading costs are statistically the most expensive. These results are comparable with the momentum baseline trader, reflecting the low interest differential environment since the the 2008 financial crisis, and very obvious currency trends since then. The recurrent reinforcement learner does nevertheless maintain an important advantage, in that the model's weights can be adapted to reflect the different sources of profit and loss variation. This is demonstrated visually by a USDRUB trading agent, who learns to target different positions, that reflect trading in the absence or presence of cost.
Towards the Classification of Error-Related Potentials using Riemannian Geometry
Sep 21, 2021
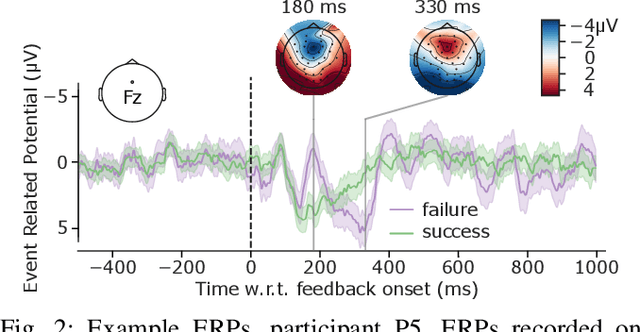
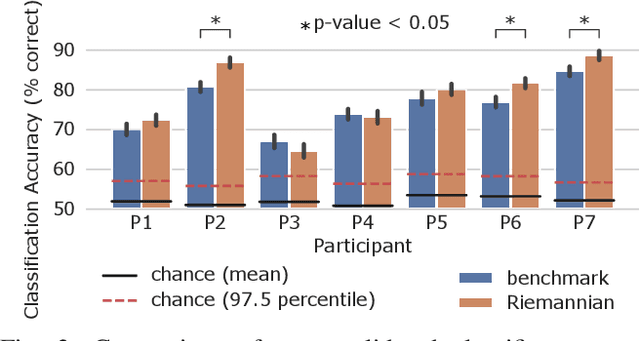

The error-related potential (ErrP) is an event-related potential (ERP) evoked by an experimental participant's recognition of an error during task performance. ErrPs, originally described by cognitive psychologists, have been adopted for use in brain-computer interfaces (BCIs) for the detection and correction of errors, and the online refinement of decoding algorithms. Riemannian geometry-based feature extraction and classification is a new approach to BCI which shows good performance in a range of experimental paradigms, but has yet to be applied to the classification of ErrPs. Here, we describe an experiment that elicited ErrPs in seven normal participants performing a visual discrimination task. Audio feedback was provided on each trial. We used multi-channel electroencephalogram (EEG) recordings to classify ErrPs (success/failure), comparing a Riemannian geometry-based method to a traditional approach that computes time-point features. Overall, the Riemannian approach outperformed the traditional approach (78.2% versus 75.9% accuracy, p < 0.05); this difference was statistically significant (p < 0.05) in three of seven participants. These results indicate that the Riemannian approach better captured the features from feedback-elicited ErrPs, and may have application in BCI for error detection and correction.
Independent Deeply Learned Tensor Analysis for Determined Audio Source Separation
Jun 10, 2021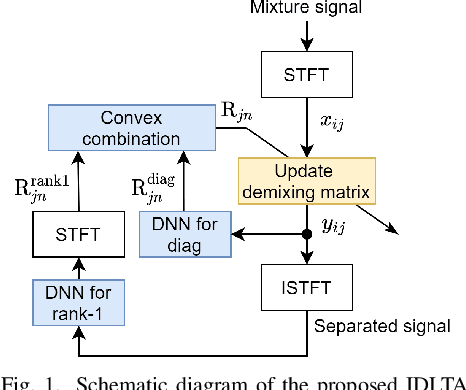
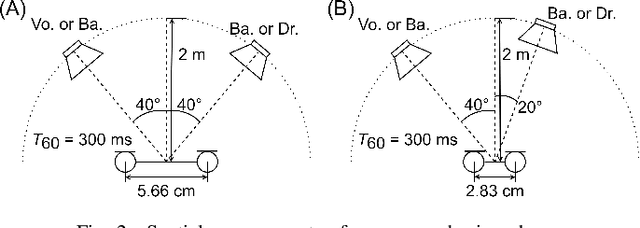

We address the determined audio source separation problem in the time-frequency domain. In independent deeply learned matrix analysis (IDLMA), it is assumed that the inter-frequency correlation of each source spectrum is zero, which is inappropriate for modeling nonstationary signals such as music signals. To account for the correlation between frequencies, independent positive semidefinite tensor analysis has been proposed. This unsupervised (blind) method, however, severely restrict the structure of frequency covariance matrices (FCMs) to reduce the number of model parameters. As an extension of these conventional approaches, we here propose a supervised method that models FCMs using deep neural networks (DNNs). It is difficult to directly infer FCMs using DNNs. Therefore, we also propose a new FCM model represented as a convex combination of a diagonal FCM and a rank-1 FCM. Our FCM model is flexible enough to not only consider inter-frequency correlation, but also capture the dynamics of time-varying FCMs of nonstationary signals. We infer the proposed FCMs using two DNNs: DNN for power spectrum estimation and DNN for time-domain signal estimation. An experimental result of separating music signals shows that the proposed method provides higher separation performance than IDLMA.
Asking questions on handwritten document collections
Oct 02, 2021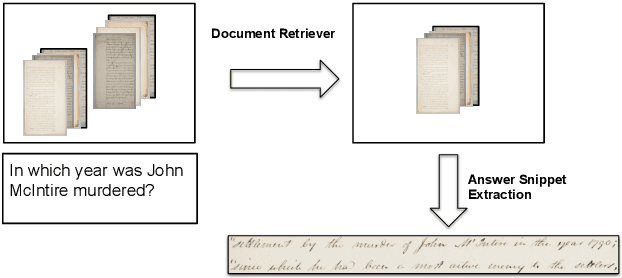

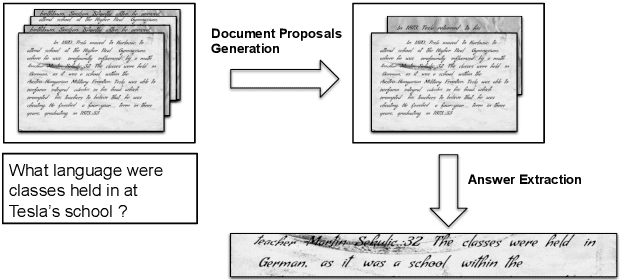

This work addresses the problem of Question Answering (QA) on handwritten document collections. Unlike typical QA and Visual Question Answering (VQA) formulations where the answer is a short text, we aim to locate a document snippet where the answer lies. The proposed approach works without recognizing the text in the documents. We argue that the recognition-free approach is suitable for handwritten documents and historical collections where robust text recognition is often difficult. At the same time, for human users, document image snippets containing answers act as a valid alternative to textual answers. The proposed approach uses an off-the-shelf deep embedding network which can project both textual words and word images into a common sub-space. This embedding bridges the textual and visual domains and helps us retrieve document snippets that potentially answer a question. We evaluate results of the proposed approach on two new datasets: (i) HW-SQuAD: a synthetic, handwritten document image counterpart of SQuAD1.0 dataset and (ii) BenthamQA: a smaller set of QA pairs defined on documents from the popular Bentham manuscripts collection. We also present a thorough analysis of the proposed recognition-free approach compared to a recognition-based approach which uses text recognized from the images using an OCR. Datasets presented in this work are available to download at docvqa.org
* pre-print version
FaceCook: Face Generation Based on Linear Scaling Factors
Sep 08, 2021

With the excellent disentanglement properties of state-of-the-art generative models, image editing has been the dominant approach to control the attributes of synthesised face images. However, these edited results often suffer from artifacts or incorrect feature rendering, especially when there is a large discrepancy between the image to be edited and the desired feature set. Therefore, we propose a new approach to mapping the latent vectors of the generative model to the scaling factors through solving a set of multivariate linear equations. The coefficients of the equations are the eigenvectors of the weight parameters of the pre-trained model, which form the basis of a hyper coordinate system. The qualitative and quantitative results both show that the proposed method outperforms the baseline in terms of image diversity. In addition, the method is much more time-efficient because you can obtain synthesised images with desirable features directly from the latent vectors, rather than the former process of editing randomly generated images requiring many processing steps.