 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The ByteDance Speaker Diarization System for the VoxCeleb Speaker Recognition Challenge 2021
Sep 05, 2021
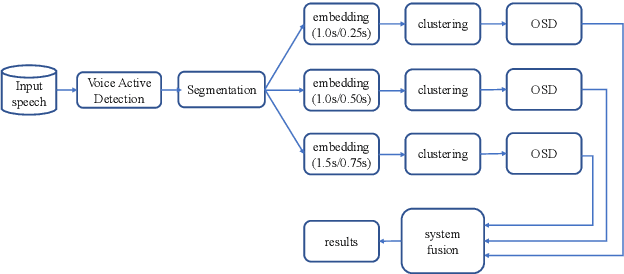

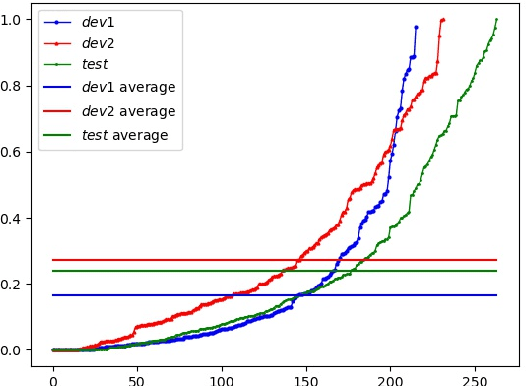
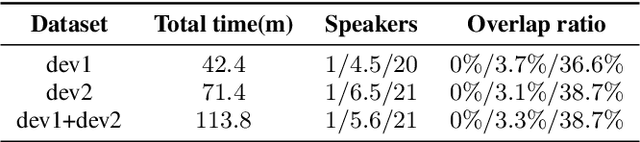
This paper describes the ByteDance speaker diarization system for the fourth track of the VoxCeleb Speaker Recognition Challenge 2021 (VoxSRC-21). The VoxSRC-21 provides both the dev set and test set of VoxConverse for use in validation and a standalone test set for evaluation. We first collect the duration and signal-to-noise ratio (SNR) of all audio and find that the distribution of the VoxConverse's test set and the VoxSRC-21's test set is more closer. Our system consists of voice active detection (VAD), speaker embedding extraction, spectral clustering followed by a re-clustering step based on agglomerative hierarchical clustering (AHC) and overlapped speech detection and handling. Finally, we integrate systems with different time scales using DOVER-Lap. Our best system achieves 5.15\% of the diarization error rate (DER) on evaluation set, ranking the second at the diarization track of the challenge.
Spatiotemporal Texture Reconstruction for Dynamic Objects Using a Single RGB-D Camera
Aug 20, 2021This paper presents an effective method for generating a spatiotemporal (time-varying) texture map for a dynamic object using a single RGB-D camera. The input of our framework is a 3D template model and an RGB-D image sequence. Since there are invisible areas of the object at a frame in a single-camera setup, textures of such areas need to be borrowed from other frames. We formulate the problem as an MRF optimization and define cost functions to reconstruct a plausible spatiotemporal texture for a dynamic object. Experimental results demonstrate that our spatiotemporal textures can reproduce the active appearances of captured objects better than approaches using a single texture map.
Accelerated MRI Reconstruction with Separable and Enhanced Low-Rank Hankel Regularization
Jul 24, 2021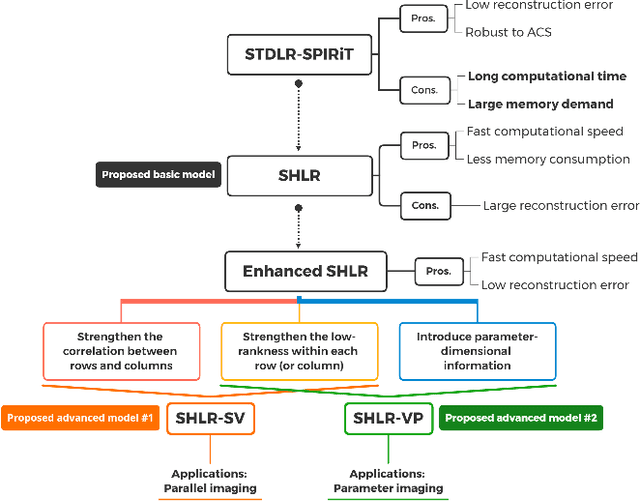
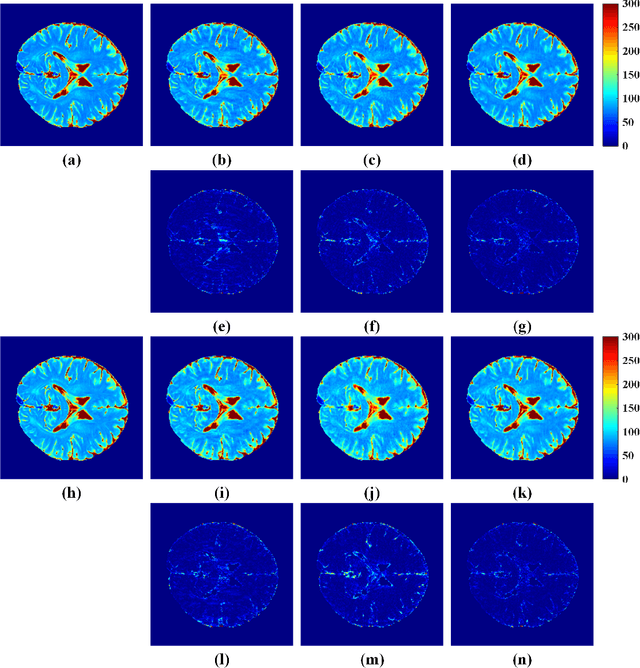
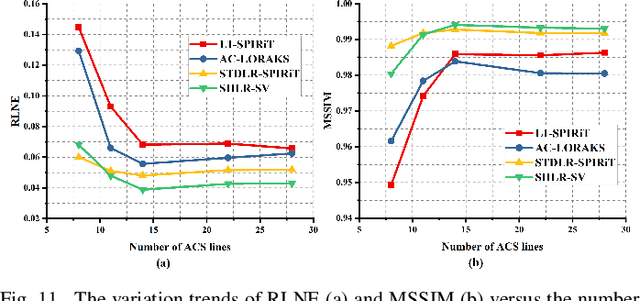
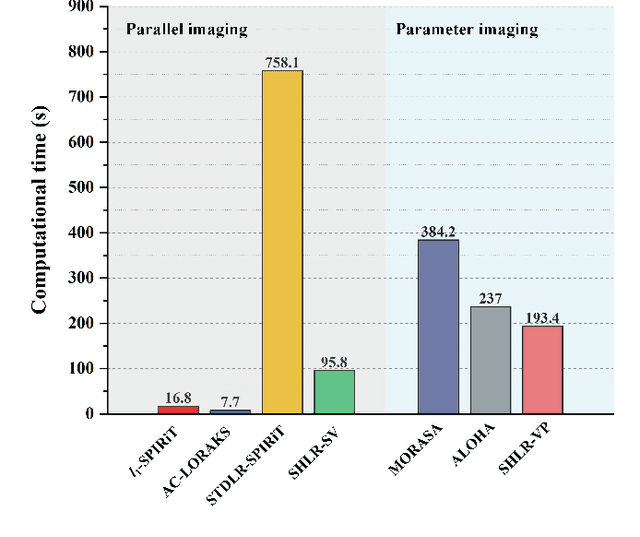
The combination of the sparse sampling and the low-rank structured matrix reconstruction has shown promising performance, enabling a significant reduction of the magnetic resonance imaging data acquisition time. However, the low-rank structured approaches demand considerable memory consumption and are time-consuming due to a noticeable number of matrix operations performed on the huge-size block Hankel-like matrix. In this work, we proposed a novel framework to utilize the low-rank property but meanwhile to achieve faster reconstructions and promising results. The framework allows us to enforce the low-rankness of Hankel matrices constructing from 1D vectors instead of 2D matrices from 1D vectors and thus avoid the construction of huge block Hankel matrix for 2D k-space matrices. Moreover, under this framework, we can easily incorporate other information, such as the smooth phase of the image and the low-rankness in the parameter dimension, to further improve the image quality. We built and validated two models for parallel and parameter magnetic resonance imaging experiments, respectively. Our retrospective in-vivo results indicate that the proposed approaches enable faster reconstructions than the state-of-the-art approaches, e.g., about 8x faster than STDLRSPIRiT, and faithful removal of undersampling artifacts.
GPU Accelerated Batch Multi-Convex Trajectory Optimization for a Rectangular Holonomic Mobile Robot
Sep 27, 2021
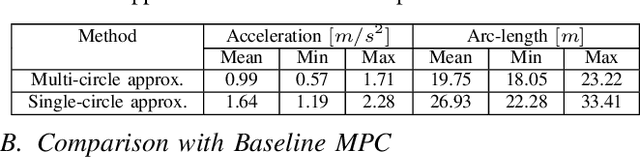
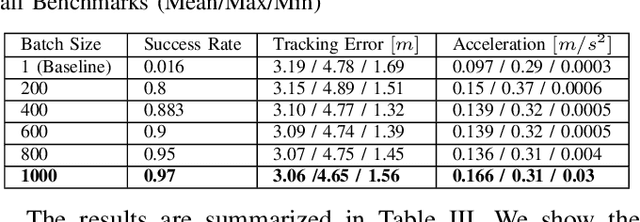
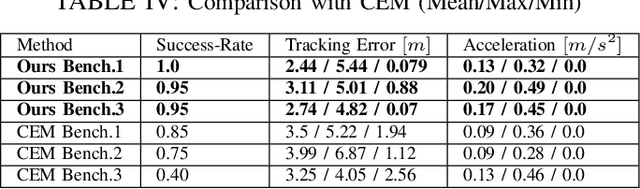
We present a batch trajectory optimizer that can simultaneously solve hundreds of different instances of the problem in real-time. We consider holonomic robots but relax the assumption of circular base footprint. Our main algorithmic contributions lie in: (i) improving the computational tractability of the underlying non-convex problem and (ii) leveraging batch computation to mitigate initialization bottlenecks and improve solution quality. We achieve both goals by deriving a multi-convex reformulation of the kinematics and collision avoidance constraints. We exploit these structures through an Alternating Minimization approach and show that the resulting batch operation reduces to computing just matrix-vector products that can be trivially accelerated over GPUs. We improve the state-of-the-art in three respects. First, we improve quality of navigation (success-rate, tracking) as compared to baseline approach that relies on computing a single locally optimal trajectory at each control loop. Second, we show that when initialized with trajectory samples from a Gaussian distribution, our batch optimizer outperforms state-of-the-art cross-entropy method in solution quality. Finally, our batch optimizer is several orders of magnitude faster than the conceptually simpler alternative of running different optimization instances in parallel CPU threads. \textbf{Codes:} \url{https://tinyurl.com/a3b99m8}
DANIEL: A Fast and Robust Consensus Maximization Method for Point Cloud Registration with High Outlier Ratios
Oct 12, 2021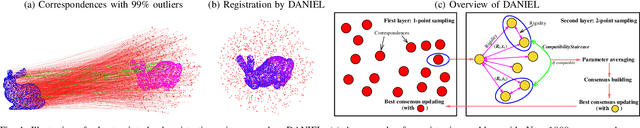
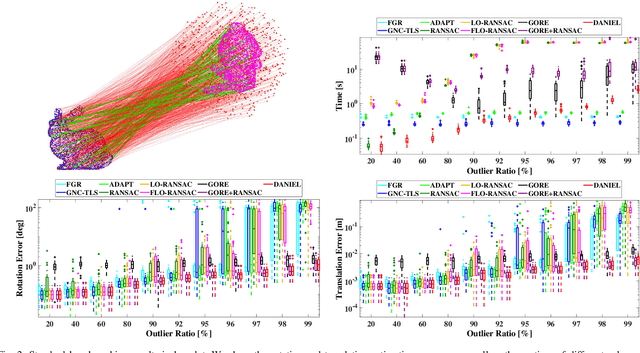
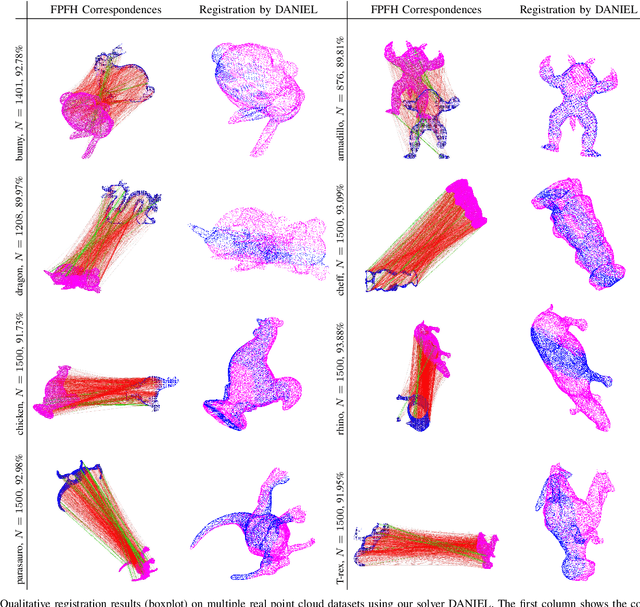

Correspondence-based point cloud registration is a cornerstone in geometric computer vision, robotics perception, photogrammetry and remote sensing, which seeks to estimate the best rigid transformation between two point clouds from the correspondences established over 3D keypoints. However, due to limited robustness and accuracy, current 3D keypoint matching techniques are very prone to yield outliers, probably even in very large numbers, making robust estimation for point cloud registration of great importance. Unfortunately, existing robust methods may suffer from high computational cost or insufficient robustness when encountering high (or even extreme) outlier ratios, hardly ideal enough for practical use. In this paper, we present a novel time-efficient RANSAC-type consensus maximization solver, named DANIEL (Double-layered sAmpliNg with consensus maximization based on stratIfied Element-wise compatibiLity), for robust registration. DANIEL is designed with two layers of random sampling, in order to find inlier subsets with the lowest computational cost possible. Specifically, we: (i) apply the rigidity constraint to prune raw outliers in the first layer of one-point sampling, (ii) introduce a series of stratified element-wise compatibility tests to conduct rapid compatibility checking between minimal models so as to realize more efficient consensus maximization in the second layer of two-point sampling, and (iii) probabilistic termination conditions are employed to ensure the timely return of the final inlier set. Based on a variety of experiments over multiple real datasets, we show that DANIEL is robust against over 99% outliers and also significantly faster than existing state-of-the-art robust solvers (e.g. RANSAC, FGR, GORE).
High Precision Indoor Localization with Dummy Antennas -- An Experimental Study
Aug 24, 2021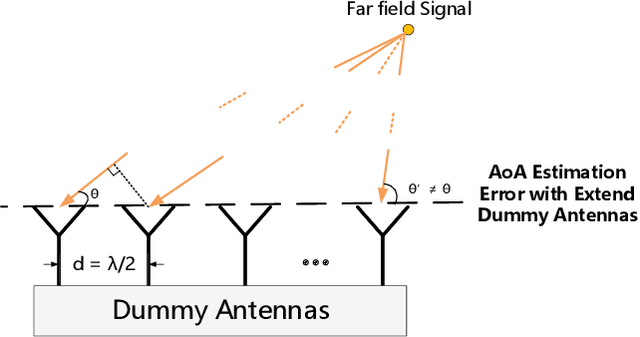
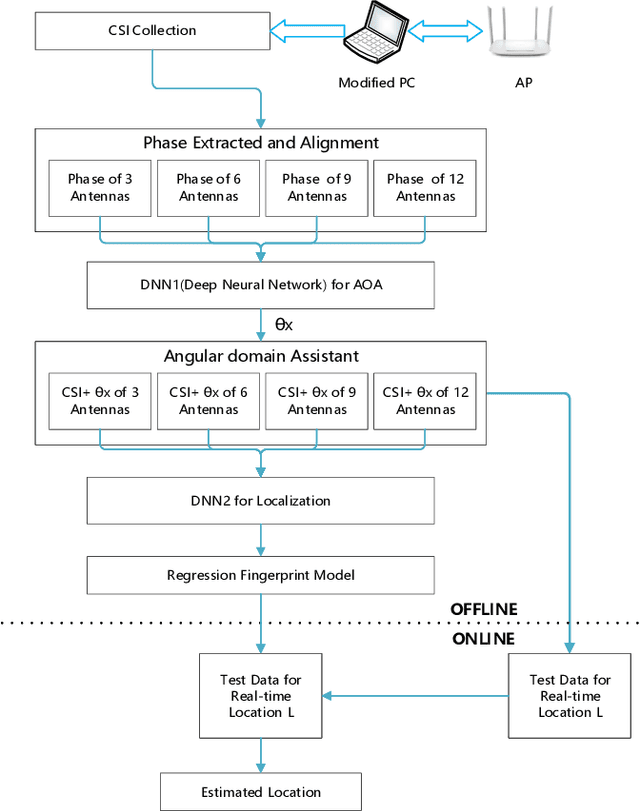
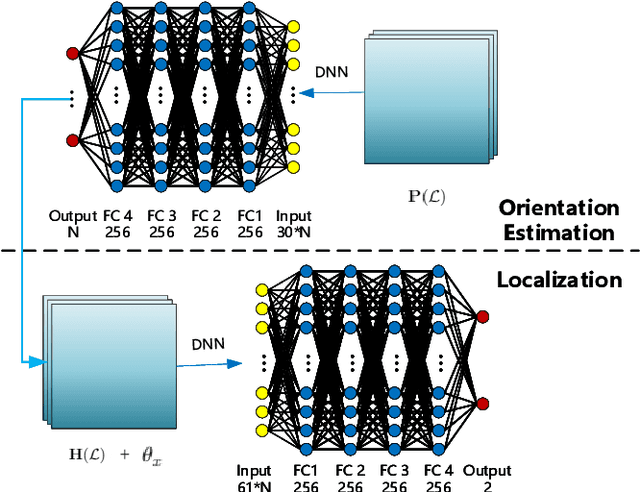

With the rising demand for indoor localization, high precision technique-based fingerprints became increasingly important nowadays. The newest advanced localization system makes effort to improve localization accuracy in the time or frequency domain, for example, the UWB localization technique can achieve centimeter-level accuracy but have a high cost. Therefore, we present a spatial domain extension-based scheme with low cost and verify the effectiveness of antennas extension in localization accuracy. In this paper, we achieve sub-meter level localization accuracy using a single AP by extending three radio links of the modified laptops to more antennas. Moreover, the experimental results show that the localization performance is superior as the number of antennas increases with the help of spatial domain extension and angular domain assisted.
Towards Incremental Transformers: An Empirical Analysis of Transformer Models for Incremental NLU
Sep 15, 2021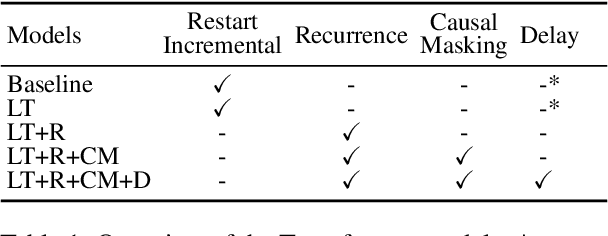
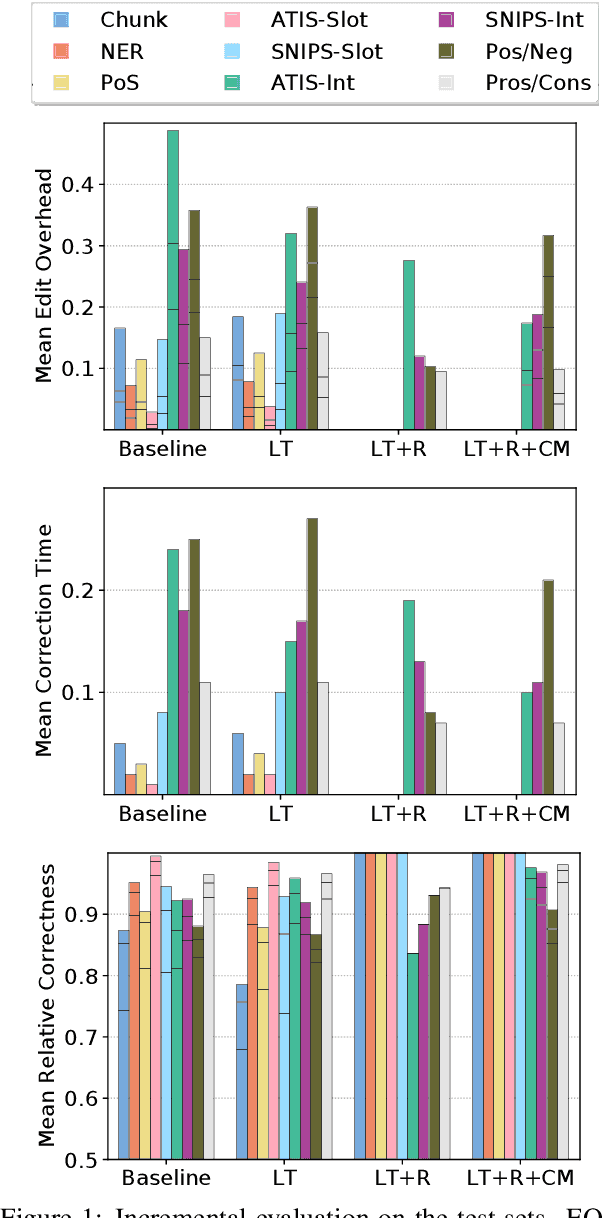
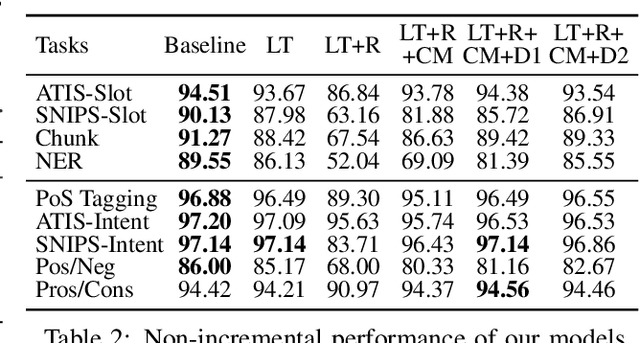
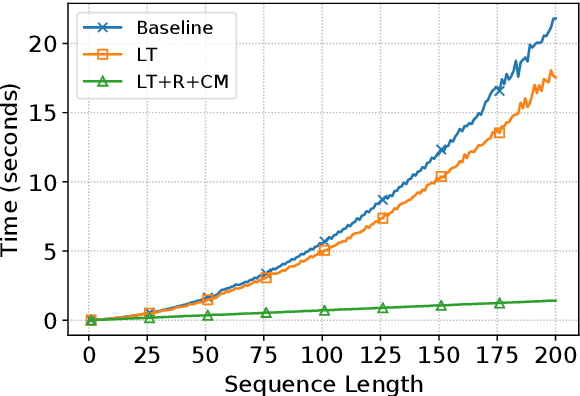
Incremental processing allows interactive systems to respond based on partial inputs, which is a desirable property e.g. in dialogue agents. The currently popular Transformer architecture inherently processes sequences as a whole, abstracting away the notion of time. Recent work attempts to apply Transformers incrementally via restart-incrementality by repeatedly feeding, to an unchanged model, increasingly longer input prefixes to produce partial outputs. However, this approach is computationally costly and does not scale efficiently for long sequences. In parallel, we witness efforts to make Transformers more efficient, e.g. the Linear Transformer (LT) with a recurrence mechanism. In this work, we examine the feasibility of LT for incremental NLU in English. Our results show that the recurrent LT model has better incremental performance and faster inference speed compared to the standard Transformer and LT with restart-incrementality, at the cost of part of the non-incremental (full sequence) quality. We show that the performance drop can be mitigated by training the model to wait for right context before committing to an output and that training with input prefixes is beneficial for delivering correct partial outputs.
A Generalized Theory of Power
Sep 08, 2021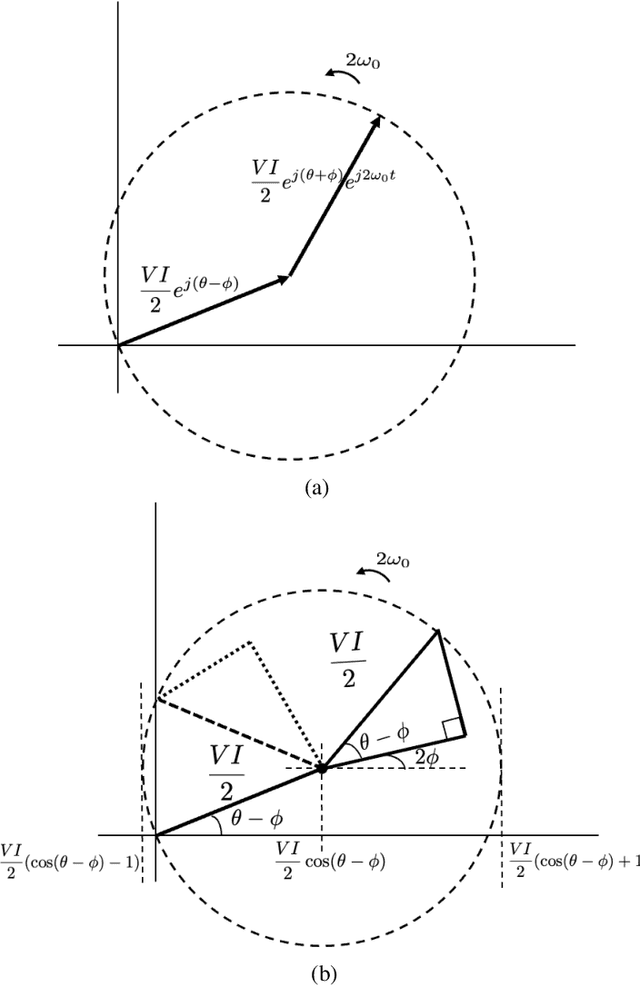
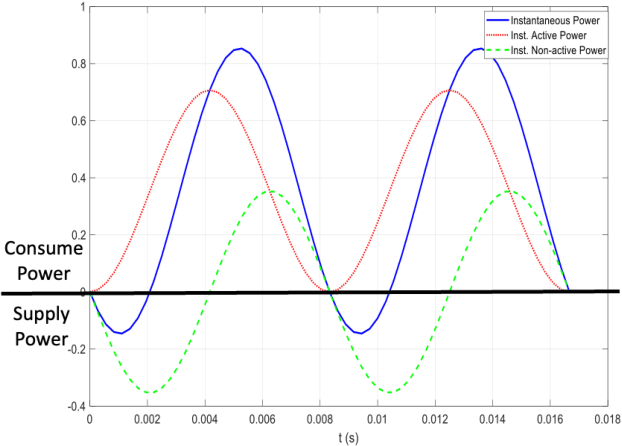
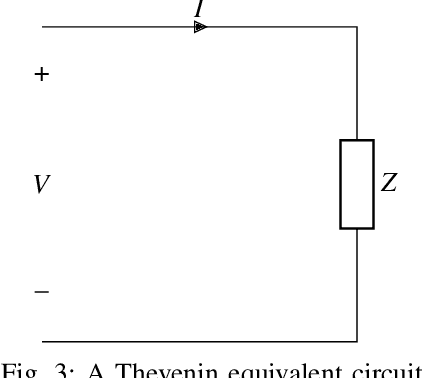
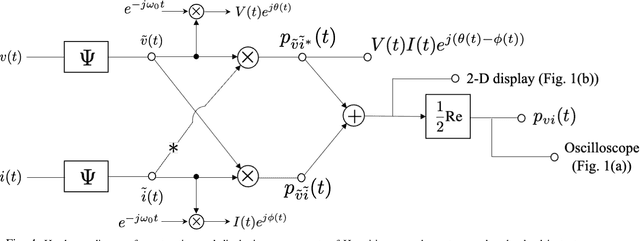
The complex representation of real-valued instantaneous power may be written as the sum of two complex powers, one Hermitian and the other non-Hermitian, or complementary. A virtue of this representation is that it consists of a power triangle rotating around a fixed phasor, thus clarifying what should be meant by the power triangle. The in-phase and quadrature components of complementary power encode for active and non-active power. When instantaneous power is defined for a Thevenin equivalent circuit, these are time-varying real and reactive power components. These claims hold for sinusoidal voltage and current, and for non-sinusoidal voltage and current. Spectral representations of Hermitian, complementary, and instantaneous power show that, frequency-by-frequency, these powers behave exactly as they behave in the single frequency sinusoidal case. Simple hardware diagrams show how instantaneous active and non-active power may be extracted from metered voltage and current, even in certain non-sinusoidal cases.
TorchEsegeta: Framework for Interpretability and Explainability of Image-based Deep Learning Models
Oct 16, 2021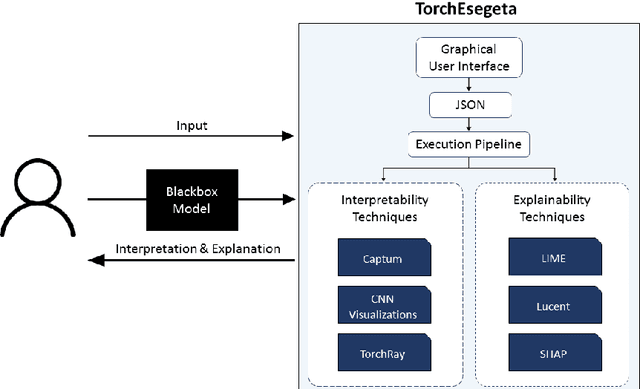
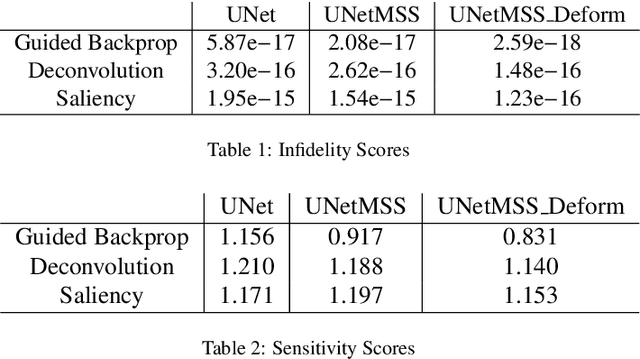
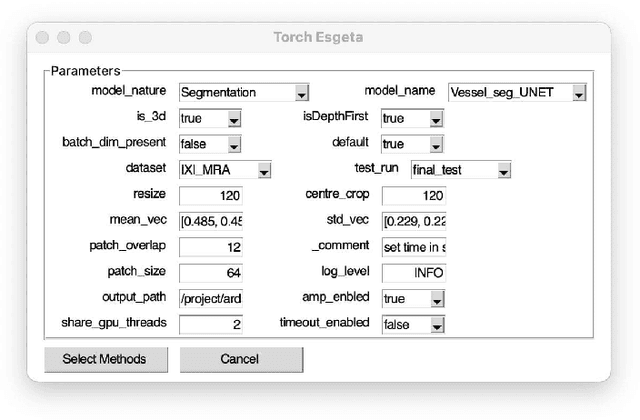
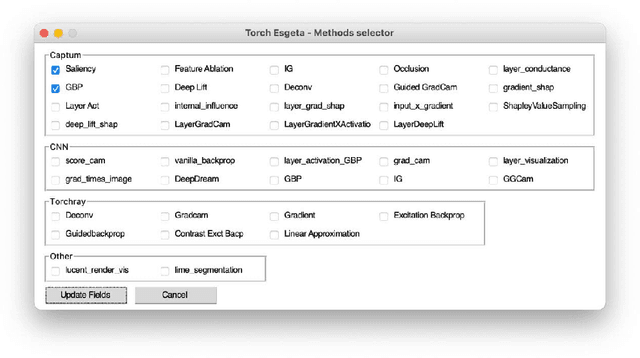
Clinicians are often very sceptical about applying automatic image processing approaches, especially deep learning based methods, in practice. One main reason for this is the black-box nature of these approaches and the inherent problem of missing insights of the automatically derived decisions. In order to increase trust in these methods, this paper presents approaches that help to interpret and explain the results of deep learning algorithms by depicting the anatomical areas which influence the decision of the algorithm most. Moreover, this research presents a unified framework, TorchEsegeta, for applying various interpretability and explainability techniques for deep learning models and generate visual interpretations and explanations for clinicians to corroborate their clinical findings. In addition, this will aid in gaining confidence in such methods. The framework builds on existing interpretability and explainability techniques that are currently focusing on classification models, extending them to segmentation tasks. In addition, these methods have been adapted to 3D models for volumetric analysis. The proposed framework provides methods to quantitatively compare visual explanations using infidelity and sensitivity metrics. This framework can be used by data scientists to perform post-hoc interpretations and explanations of their models, develop more explainable tools and present the findings to clinicians to increase their faith in such models. The proposed framework was evaluated based on a use case scenario of vessel segmentation models trained on Time-of-fight (TOF) Magnetic Resonance Angiogram (MRA) images of the human brain. Quantitative and qualitative results of a comparative study of different models and interpretability methods are presented. Furthermore, this paper provides an extensive overview of several existing interpretability and explainability methods.
Improving Uncertainty of Deep Learning-based Object Classification on Radar Spectra using Label Smoothing
Sep 27, 2021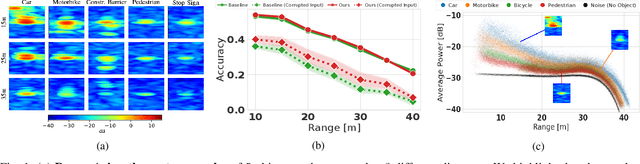
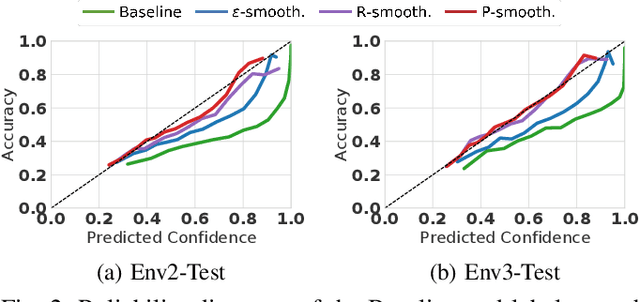
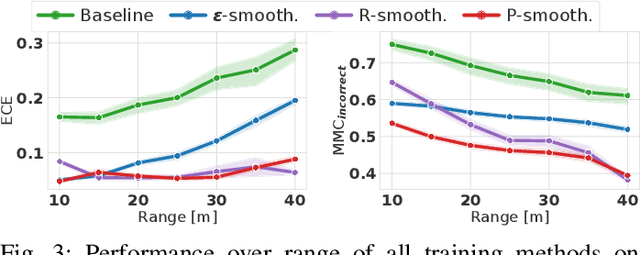
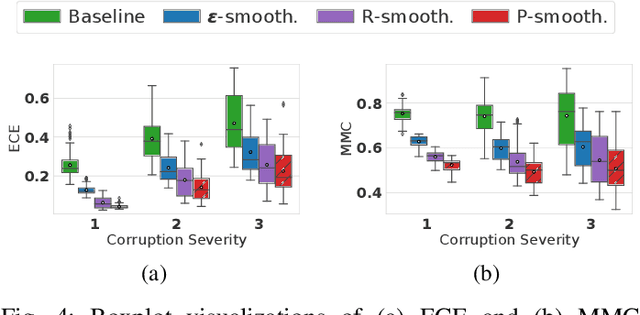
Object type classification for automotive radar has greatly improved with recent deep learning (DL) solutions, however these developments have mostly focused on the classification accuracy. Before employing DL solutions in safety-critical applications, such as automated driving, an indispensable prerequisite is the accurate quantification of the classifiers' reliability. Unfortunately, DL classifiers are characterized as black-box systems which output severely over-confident predictions, leading downstream decision-making systems to false conclusions with possibly catastrophic consequences. We find that deep radar classifiers maintain high-confidences for ambiguous, difficult samples, e.g. small objects measured at large distances, under domain shift and signal corruptions, regardless of the correctness of the predictions. The focus of this article is to learn deep radar spectra classifiers which offer robust real-time uncertainty estimates using label smoothing during training. Label smoothing is a technique of refining, or softening, the hard labels typically available in classification datasets. In this article, we exploit radar-specific know-how to define soft labels which encourage the classifiers to learn to output high-quality calibrated uncertainty estimates, thereby partially resolving the problem of over-confidence. Our investigations show how simple radar knowledge can easily be combined with complex data-driven learning algorithms to yield safe automotive radar perception.