 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Gradient Forward-Propagation for Large-Scale Temporal Video Modelling
Jul 12, 2021
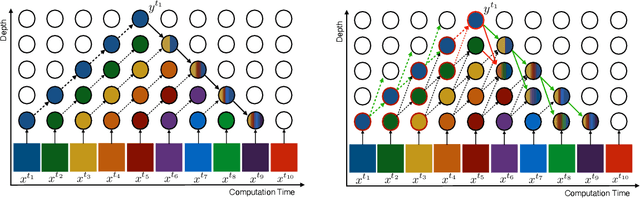
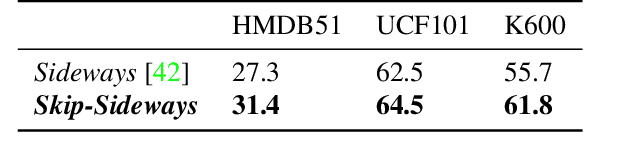
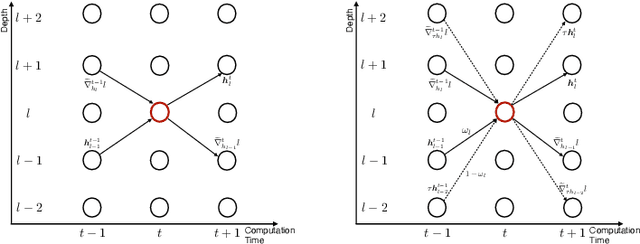

How can neural networks be trained on large-volume temporal data efficiently? To compute the gradients required to update parameters, backpropagation blocks computations until the forward and backward passes are completed. For temporal signals, this introduces high latency and hinders real-time learning. It also creates a coupling between consecutive layers, which limits model parallelism and increases memory consumption. In this paper, we build upon Sideways, which avoids blocking by propagating approximate gradients forward in time, and we propose mechanisms for temporal integration of information based on different variants of skip connections. We also show how to decouple computation and delegate individual neural modules to different devices, allowing distributed and parallel training. The proposed Skip-Sideways achieves low latency training, model parallelism, and, importantly, is capable of extracting temporal features, leading to more stable training and improved performance on real-world action recognition video datasets such as HMDB51, UCF101, and the large-scale Kinetics-600. Finally, we also show that models trained with Skip-Sideways generate better future frames than Sideways models, and hence they can better utilize motion cues.
Lightweight Network Architecture for Real-Time Action Recognition
May 21, 2019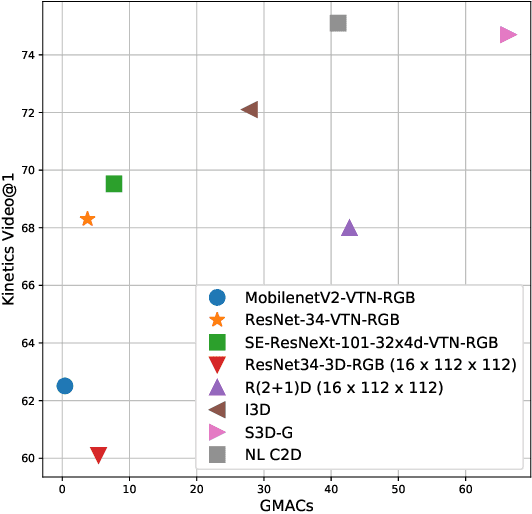

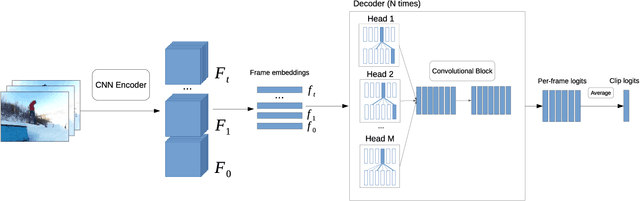

In this work we present a new efficient approach to Human Action Recognition called Video Transformer Network (VTN). It leverages the latest advances in Computer Vision and Natural Language Processing and applies them to video understanding. The proposed method allows us to create lightweight CNN models that achieve high accuracy and real-time speed using just an RGB mono camera and general purpose CPU. Furthermore, we explain how to improve accuracy by distilling from multiple models with different modalities into a single model. We conduct a comparison with state-of-the-art methods and show that our approach performs on par with most of them on famous Action Recognition datasets. We benchmark the inference time of the models using the modern inference framework and argue that our approach compares favorably with other methods in terms of speed/accuracy trade-off, running at 56 FPS on CPU. The models and the training code are available.
Intensity-Based Feature Selection for Near Real-Time Damage Diagnosis of Building Structures
Oct 23, 2019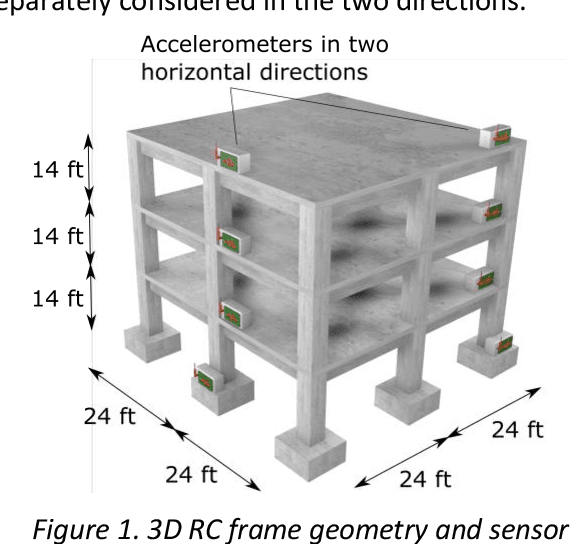
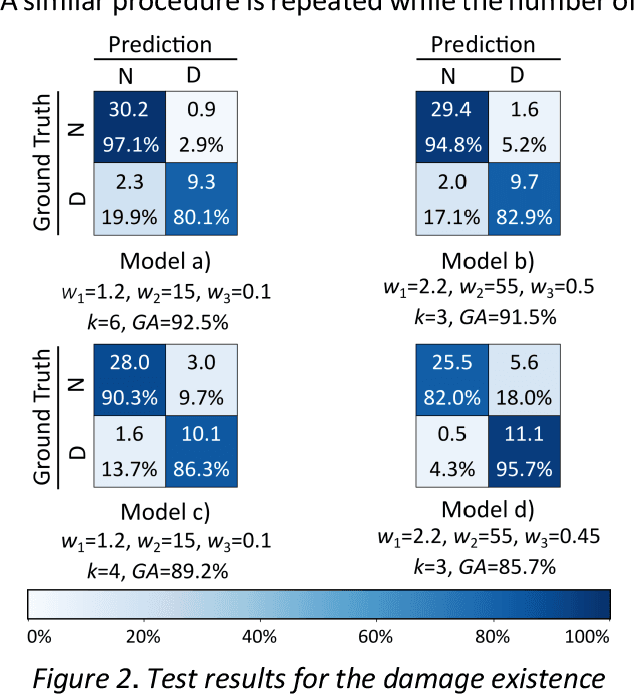
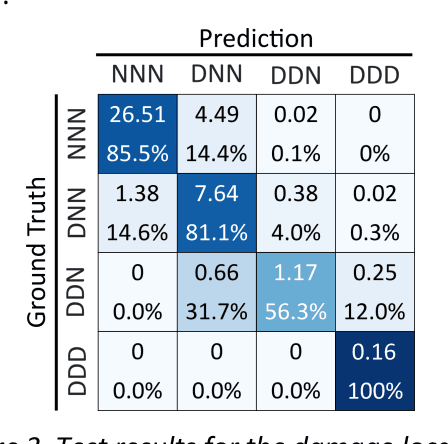
Near real-time damage diagnosis of building structures after extreme events (e.g., earthquakes) is of great importance in structural health monitoring. Unlike conventional methods that are usually time-consuming and require human expertise, pattern recognition algorithms have the potential to interpret sensor recordings as soon as this information is available. This paper proposes a robust framework to build a damage prediction model for building structures. Support vector machines are used to predict the existence as well as the probable location of the damage. The model is designed to consider probabilistic approaches in determining hazard intensity given the existing attenuation models in performance-based earthquake engineering. Performance of the model regarding accurate and safe predictions is enhanced using Bayesian optimization. The proposed framework is evaluated on a reinforced concrete moment frame. Targeting a selected large earthquake scenario, 6,240 nonlinear time history analyses are performed using OpenSees. Simulation results are engineered to extract low-dimensional intensity-based features that can be used as damage indicators. For the given case study, the proposed model achieves a promising accuracy of 83.1% to identify damage location, demonstrating the great potential of model capabilities.
Inferring Coordination Strategies from Time Series of Movement Data
Nov 04, 2019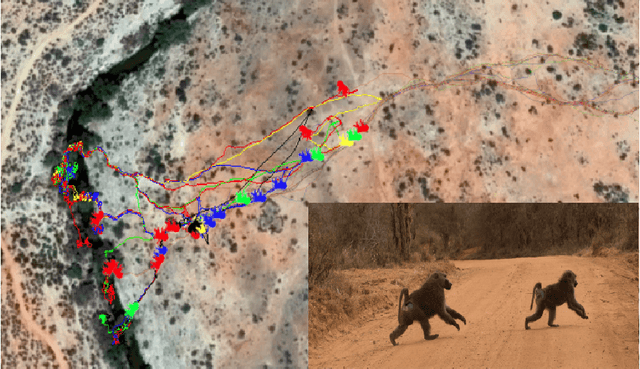
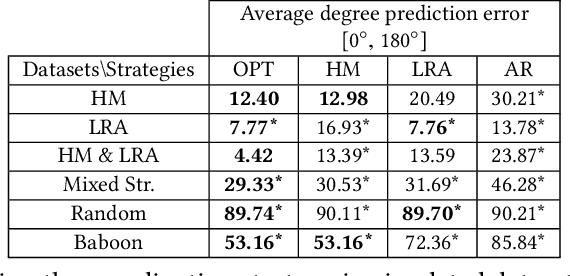
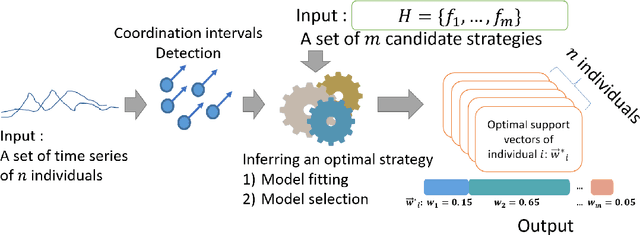
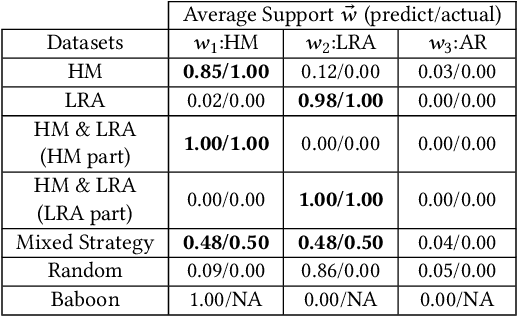
How do groups of individuals achieve consensus in movement decisions? Do individuals follow their friends, the one predetermined leader, or whomever just happens to be nearby? To address these questions computationally, we formalize Coordination Strategy Inference Problem. In this setting, a group of multiple individuals moves in a coordinated manner towards a target path. Each individual uses a specific strategy to follow others (e.g. nearest neighbors, pre-defined leaders, preferred friends). Given a set of time series that includes coordinated movement and a set of candidate strategies as inputs, we provide the first methodology (to the best of our knowledge) to infer the set of strategies that each individual uses to achieve movement coordination at the group level. We evaluate and demonstrate the performance of the proposed framework by predicting the direction of movement of an individual in a group in both simulated datasets as well as two real-world datasets: a school of fish and a troop of baboons. Moreover, since there is no prior methodology for inferring individual-level strategies, we compare our framework with the state-of-the-art approach for the task of classification of group-level-coordination models. The results show that our approach is highly accurate in inferring the correct strategy in simulated datasets even in complicated mixed strategy settings, which no existing method can infer. In the task of classification of group-level-coordination models, our framework performs better than the state-of-the-art approach in all datasets. Animal data experiments show that fish, as expected, follow their neighbors, while baboons have a preference to follow specific individuals. Our methodology generalizes to arbitrary time series data of real numbers, beyond movement data.
Unsupervised Landmark Detection Based Spatiotemporal Motion Estimation for 4D Dynamic Medical Images
Oct 12, 2021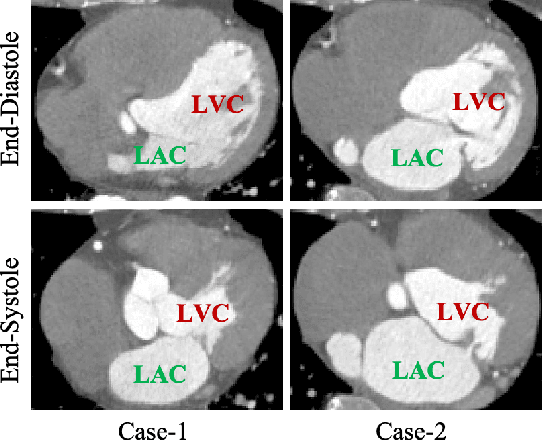

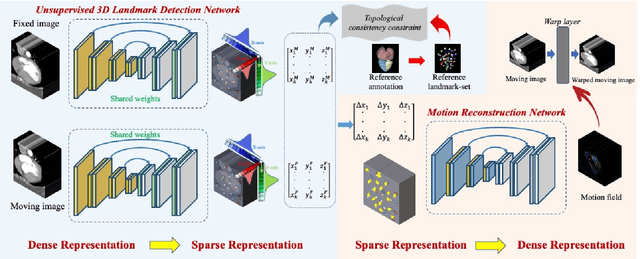
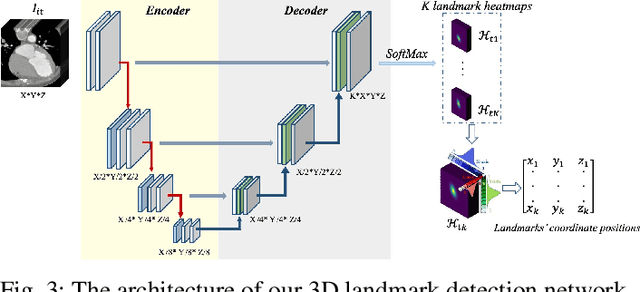
Motion estimation is a fundamental step in dynamic medical image processing for the assessment of target organ anatomy and function. However, existing image-based motion estimation methods, which optimize the motion field by evaluating the local image similarity, are prone to produce implausible estimation, especially in the presence of large motion. In this study, we provide a novel motion estimation framework of Dense-Sparse-Dense (DSD), which comprises two stages. In the first stage, we process the raw dense image to extract sparse landmarks to represent the target organ anatomical topology and discard the redundant information that is unnecessary for motion estimation. For this purpose, we introduce an unsupervised 3D landmark detection network to extract spatially sparse but representative landmarks for the target organ motion estimation. In the second stage, we derive the sparse motion displacement from the extracted sparse landmarks of two images of different time points. Then, we present a motion reconstruction network to construct the motion field by projecting the sparse landmarks displacement back into the dense image domain. Furthermore, we employ the estimated motion field from our two-stage DSD framework as initialization and boost the motion estimation quality in light-weight yet effective iterative optimization. We evaluate our method on two dynamic medical imaging tasks to model cardiac motion and lung respiratory motion, respectively. Our method has produced superior motion estimation accuracy compared to existing comparative methods. Besides, the extensive experimental results demonstrate that our solution can extract well representative anatomical landmarks without any requirement of manual annotation. Our code is publicly available online.
Data Assimilation Predictive GAN (DA-PredGAN): applied to determine the spread of COVID-19
May 17, 2021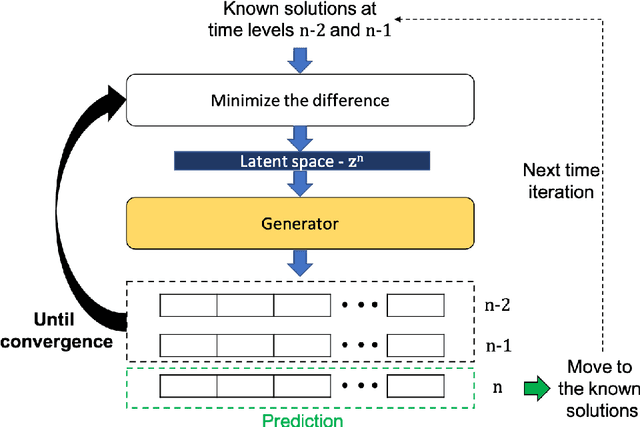

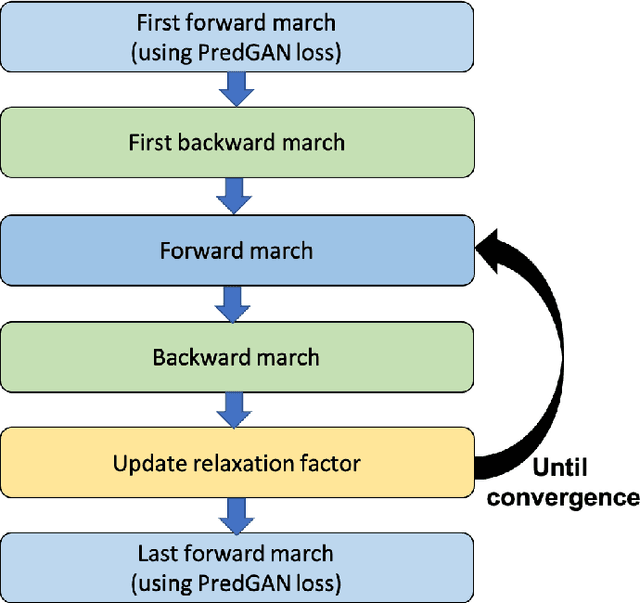
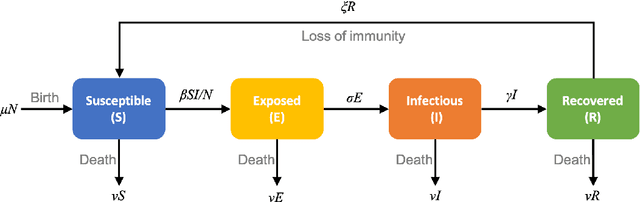
We propose the novel use of a generative adversarial network (GAN) (i) to make predictions in time (PredGAN) and (ii) to assimilate measurements (DA-PredGAN). In the latter case, we take advantage of the natural adjoint-like properties of generative models and the ability to simulate forwards and backwards in time. GANs have received much attention recently, after achieving excellent results for their generation of realistic-looking images. We wish to explore how this property translates to new applications in computational modelling and to exploit the adjoint-like properties for efficient data assimilation. To predict the spread of COVID-19 in an idealised town, we apply these methods to a compartmental model in epidemiology that is able to model space and time variations. To do this, the GAN is set within a reduced-order model (ROM), which uses a low-dimensional space for the spatial distribution of the simulation states. Then the GAN learns the evolution of the low-dimensional states over time. The results show that the proposed methods can accurately predict the evolution of the high-fidelity numerical simulation, and can efficiently assimilate observed data and determine the corresponding model parameters.
A scalable and fast artificial neural network syndrome decoder for surface codes
Oct 12, 2021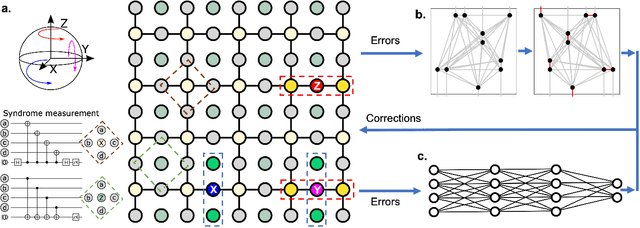
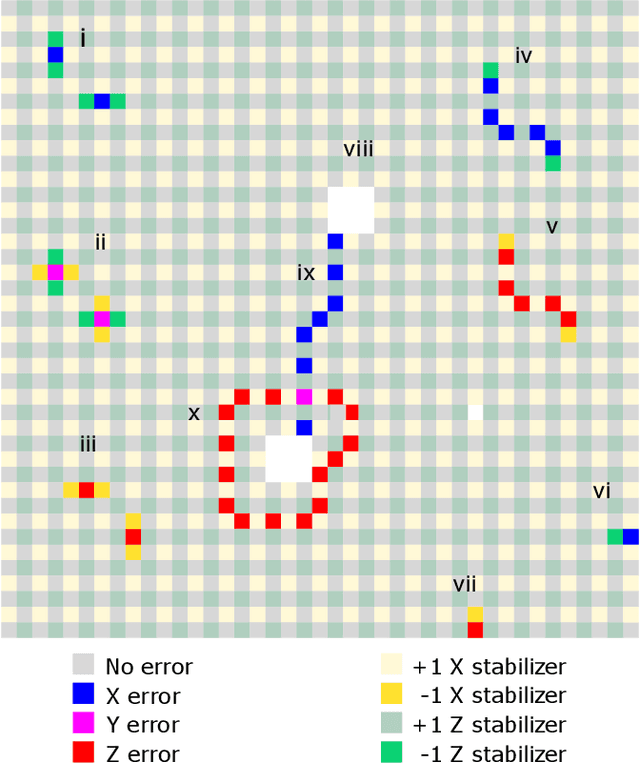
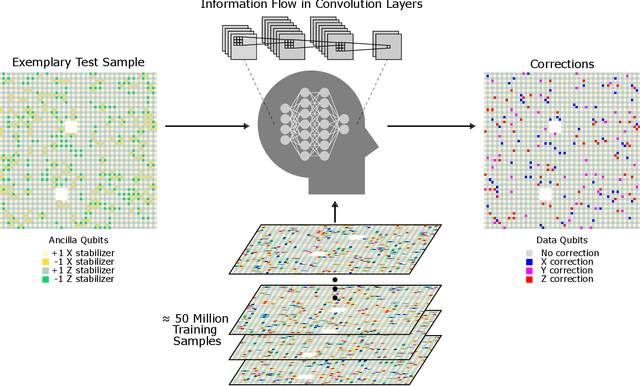
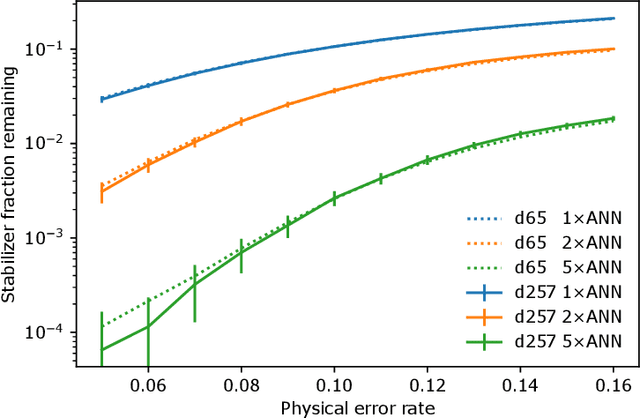
Surface code error correction offers a highly promising pathway to achieve scalable fault-tolerant quantum computing. When operated as stabilizer codes, surface code computations consist of a syndrome decoding step where measured stabilizer operators are used to determine appropriate corrections for errors in physical qubits. Decoding algorithms have undergone substantial development, with recent work incorporating machine learning (ML) techniques. Despite promising initial results, the ML-based syndrome decoders are still limited to small scale demonstrations with low latency and are incapable of handling surface codes with boundary conditions and various shapes needed for lattice surgery and braiding. Here, we report the development of an artificial neural network (ANN) based scalable and fast syndrome decoder capable of decoding surface codes of arbitrary shape and size with data qubits suffering from the depolarizing error model. Based on rigorous training over 50 million random quantum error instances, our ANN decoder is shown to work with code distances exceeding 1000 (more than 4 million physical qubits), which is the largest ML-based decoder demonstration to-date. The established ANN decoder demonstrates an execution time in principle independent of code distance, implying that its implementation on dedicated hardware could potentially offer surface code decoding times of O($\mu$sec), commensurate with the experimentally realisable qubit coherence times. With the anticipated scale-up of quantum processors within the next decade, their augmentation with a fast and scalable syndrome decoder such as developed in our work is expected to play a decisive role towards experimental implementation of fault-tolerant quantum information processing.
A cost-benefit analysis of cross-lingual transfer methods
May 29, 2021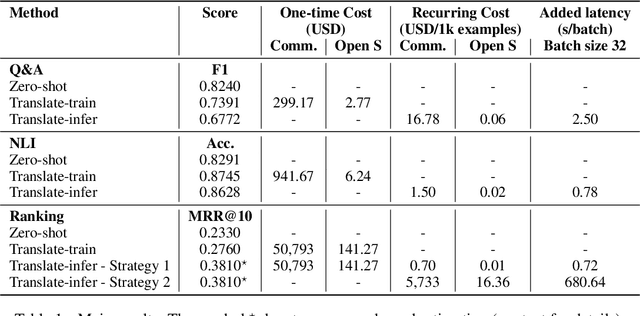
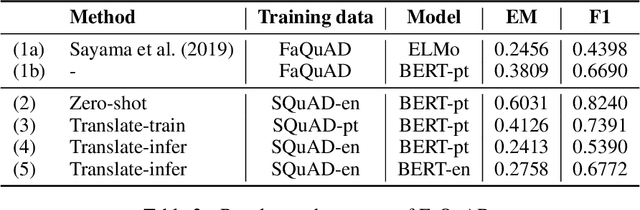
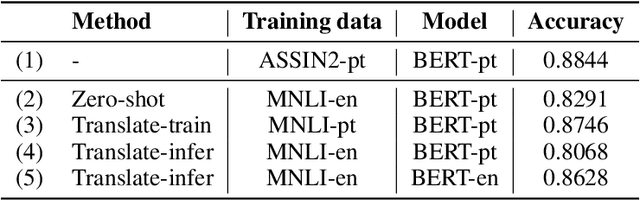
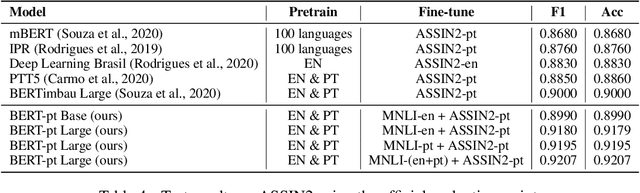
An effective method for cross-lingual transfer is to fine-tune a bilingual or multilingual model on a supervised dataset in one language and evaluating it on another language in a zero-shot manner. Translating examples at training time or inference time are also viable alternatives. However, there are costs associated with these methods that are rarely addressed in the literature. In this work, we analyze cross-lingual methods in terms of their effectiveness (e.g., accuracy), development and deployment costs, as well as their latencies at inference time. Our experiments on three tasks indicate that the best cross-lingual method is highly task-dependent. Finally, by combining zero-shot and translation methods, we achieve the state-of-the-art in two of the three datasets used in this work. Based on these results, we question the need for manually labeled training data in a target language. Code, models and translated datasets are available at https://github.com/unicamp-dl/cross-lingual-analysis
Joint Dynamic Passive Beamforming and Resource Allocation for IRS-Aided Full-Duplex WPCN
Aug 15, 2021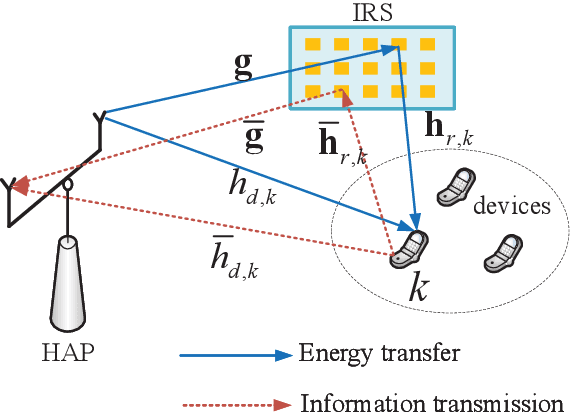
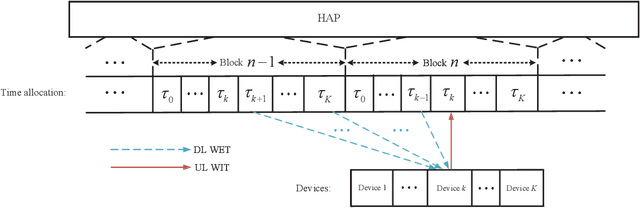
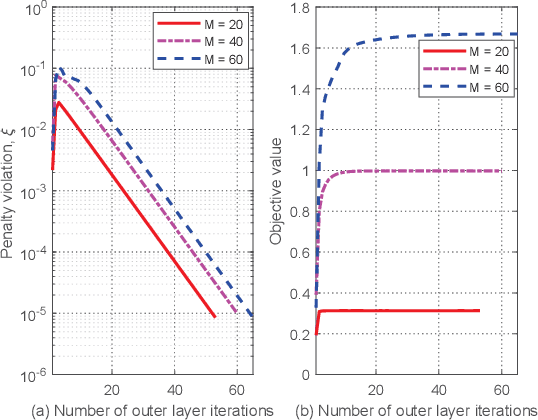
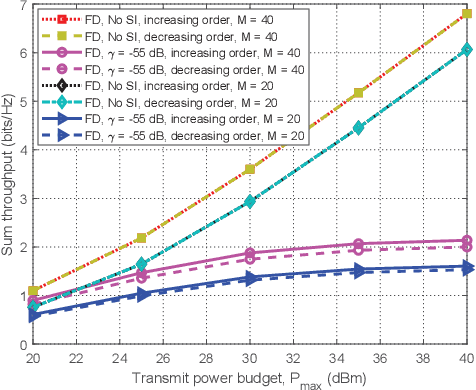
This paper studies intelligent reflecting surface (IRS)-aided full-duplex (FD) wireless-powered communication network (WPCN), where a hybrid access point (HAP) broadcasts energy signals to multiple devices for their energy harvesting in the downlink (DL) and meanwhile receives information signals in the uplink (UL) with the help of IRS. Particularly, we propose three types of IRS beamforming configurations to strike a balance between the system performance and signaling overhead as well as implementation complexity. We first propose the fully dynamic IRS beamforming, where the IRS phase-shift vectors vary with each time slot for both DL wireless energy transfer (WET) and UL wireless information transmission (WIT). To further reduce signaling overhead and implementation complexity, we then study two special cases, namely, partially dynamic IRS beamforming and static IRS beamforming. For the former case, two different phase-shift vectors can be exploited for the DL WET and the UL WIT, respectively, whereas for the latter case, the same phase-shift vector needs to be applied for both DL and UL transmissions. We aim to maximize the system throughput by jointly optimizing the time allocation, HAP transmit power, and IRS phase shifts for the above three cases. Two efficient algorithms based on alternating optimization and penalty-based algorithms are respectively proposed for both perfect self-interference cancellation (SIC) case and imperfect SIC case by applying successive convex approximation and difference-of-convex optimization techniques. Simulation results demonstrate the benefits of IRS for enhancing the performance of FD-WPCN, and also show that the IRS-aided FD-WPCN is able to achieve significantly performance gain compared to its counterpart with half-duplex when the self-interference (SI) is properly suppressed.
Multi-Modal Temporal Convolutional Network for Anticipating Actions in Egocentric Videos
Jul 18, 2021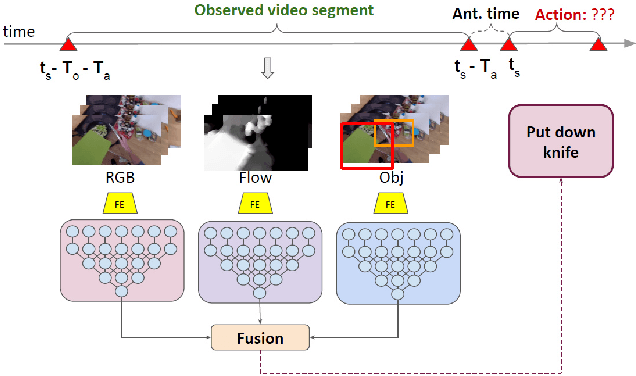
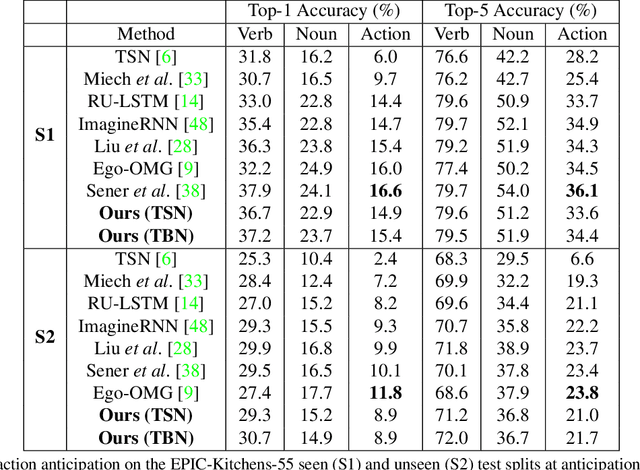
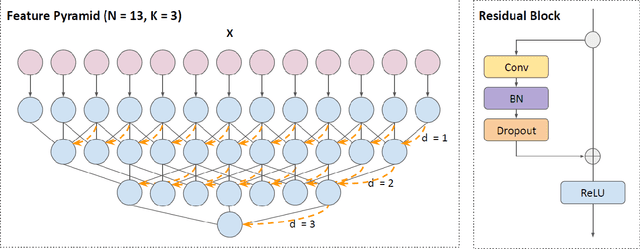
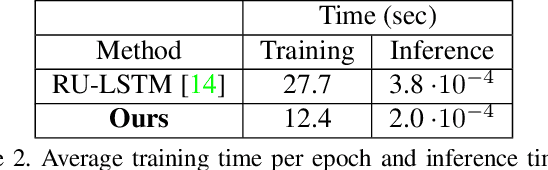
Anticipating human actions is an important task that needs to be addressed for the development of reliable intelligent agents, such as self-driving cars or robot assistants. While the ability to make future predictions with high accuracy is crucial for designing the anticipation approaches, the speed at which the inference is performed is not less important. Methods that are accurate but not sufficiently fast would introduce a high latency into the decision process. Thus, this will increase the reaction time of the underlying system. This poses a problem for domains such as autonomous driving, where the reaction time is crucial. In this work, we propose a simple and effective multi-modal architecture based on temporal convolutions. Our approach stacks a hierarchy of temporal convolutional layers and does not rely on recurrent layers to ensure a fast prediction. We further introduce a multi-modal fusion mechanism that captures the pairwise interactions between RGB, flow, and object modalities. Results on two large-scale datasets of egocentric videos, EPIC-Kitchens-55 and EPIC-Kitchens-100, show that our approach achieves comparable performance to the state-of-the-art approaches while being significantly faster.