 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The AI Economist: Optimal Economic Policy Design via Two-level Deep Reinforcement Learning
Aug 05, 2021
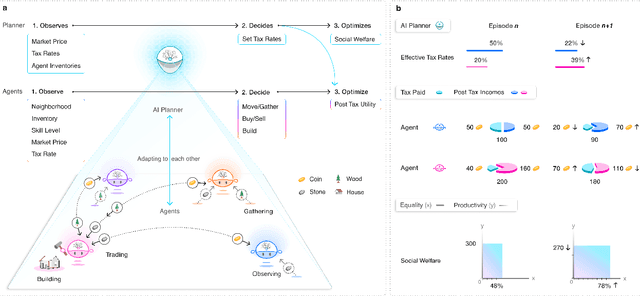
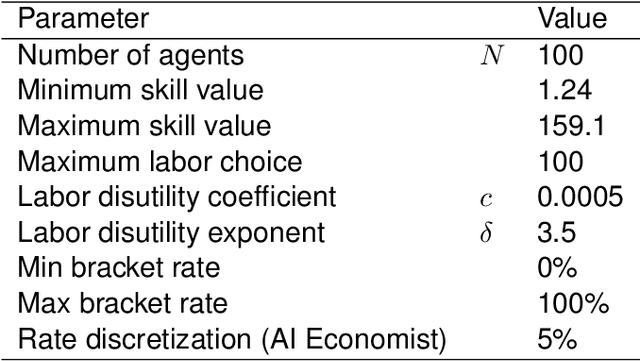
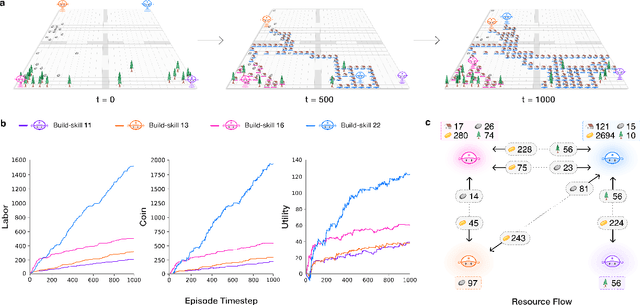
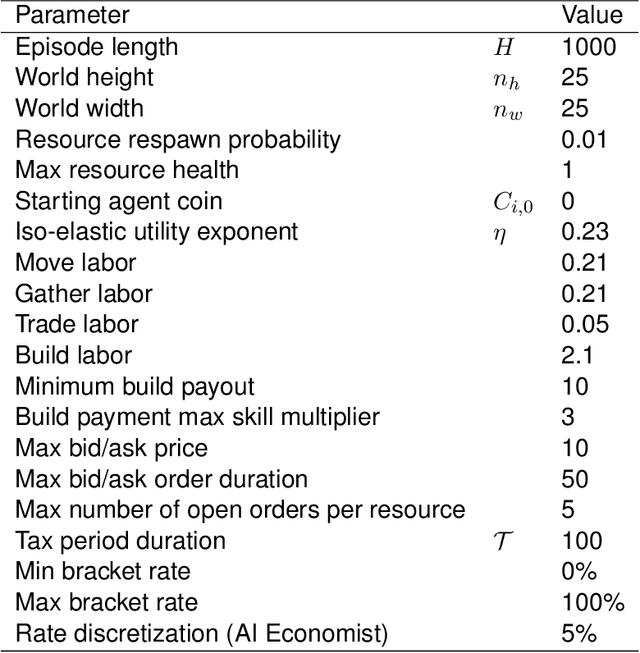
AI and reinforcement learning (RL) have improved many areas, but are not yet widely adopted in economic policy design, mechanism design, or economics at large. At the same time, current economic methodology is limited by a lack of counterfactual data, simplistic behavioral models, and limited opportunities to experiment with policies and evaluate behavioral responses. Here we show that machine-learning-based economic simulation is a powerful policy and mechanism design framework to overcome these limitations. The AI Economist is a two-level, deep RL framework that trains both agents and a social planner who co-adapt, providing a tractable solution to the highly unstable and novel two-level RL challenge. From a simple specification of an economy, we learn rational agent behaviors that adapt to learned planner policies and vice versa. We demonstrate the efficacy of the AI Economist on the problem of optimal taxation. In simple one-step economies, the AI Economist recovers the optimal tax policy of economic theory. In complex, dynamic economies, the AI Economist substantially improves both utilitarian social welfare and the trade-off between equality and productivity over baselines. It does so despite emergent tax-gaming strategies, while accounting for agent interactions and behavioral change more accurately than economic theory. These results demonstrate for the first time that two-level, deep RL can be used for understanding and as a complement to theory for economic design, unlocking a new computational learning-based approach to understanding economic policy.
Offline Meta-Reinforcement Learning for Industrial Insertion
Oct 12, 2021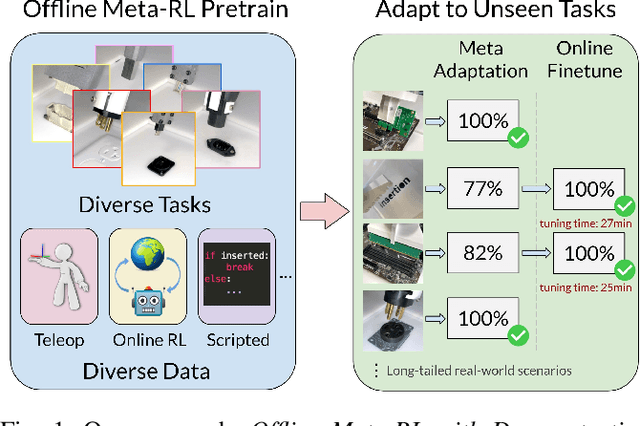
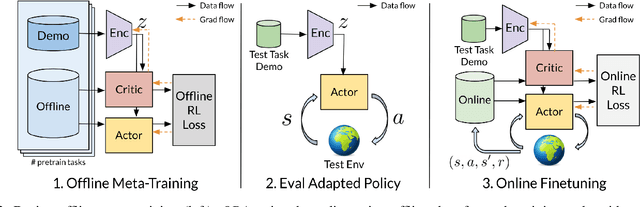


Reinforcement learning (RL) can in principle make it possible for robots to automatically adapt to new tasks, but in practice current RL methods require a very large number of trials to accomplish this. In this paper, we tackle rapid adaptation to new tasks through the framework of meta-learning, which utilizes past tasks to learn to adapt, with a specific focus on industrial insertion tasks. We address two specific challenges by applying meta-learning in this setting. First, conventional meta-RL algorithms require lengthy online meta-training phases. We show that this can be replaced with appropriately chosen offline data, resulting in an offline meta-RL method that only requires demonstrations and trials from each of the prior tasks, without the need to run costly meta-RL procedures online. Second, meta-RL methods can fail to generalize to new tasks that are too different from those seen at meta-training time, which poses a particular challenge in industrial applications, where high success rates are critical. We address this by combining contextual meta-learning with direct online finetuning: if the new task is similar to those seen in the prior data, then the contextual meta-learner adapts immediately, and if it is too different, it gradually adapts through finetuning. We show that our approach is able to quickly adapt to a variety of different insertion tasks, learning how to perform them with a success rate of 100% using only a fraction of the samples needed for learning the tasks from scratch. Experiment videos and details are available at https://sites.google.com/view/offline-metarl-insertion.
Stigmergy-based collision-avoidance algorithm for self-organising swarms
Sep 22, 2021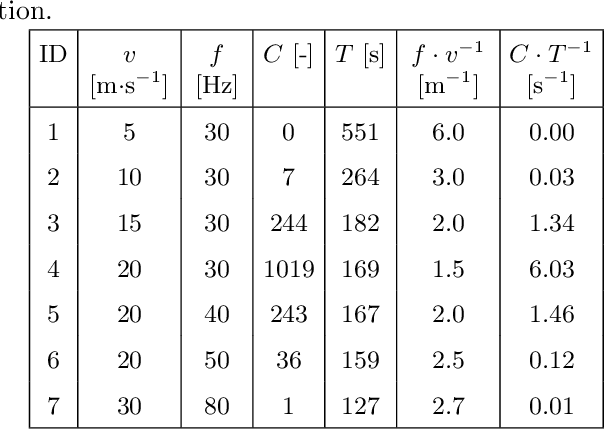
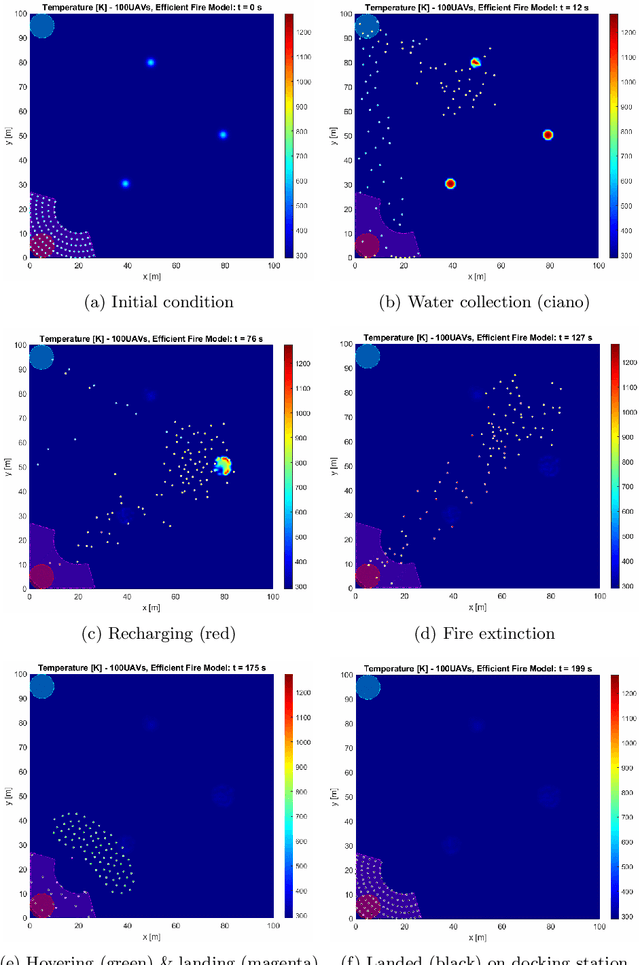
Real-time multi-agent collision-avoidance algorithms comprise a key enabling technology for the practical use of self-organising swarms of drones. This paper proposes a decentralised reciprocal collision-avoidance algorithm, which is based on stigmergy and scalable. The algorithm is computationally inexpensive, based on the gradient of the locally measured dynamic cumulative signal strength field which results from the signals emitted by the swarm. The signal strength acts as a repulsor on each drone, which then tends to steer away from the noisiest regions (cluttered environment), thus avoiding collisions. The magnitudes of these repulsive forces can be tuned to control the relative importance assigned to collision avoidance with respect to the other phenomena affecting the agent's dynamics. We carried out numerical experiments on a self-organising swarm of drones aimed at fighting wildfires autonomously. As expected, it has been found that the collision rate can be reduced either by decreasing the cruise speed of the agents and/or by increasing the sampling frequency of the global signal strength field. A convenient by-product of the proposed collision-avoidance algorithm is that it helps maintain diversity in the swarm, thus enhancing exploration.
FaceEraser: Removing Facial Parts for Augmented Reality
Sep 22, 2021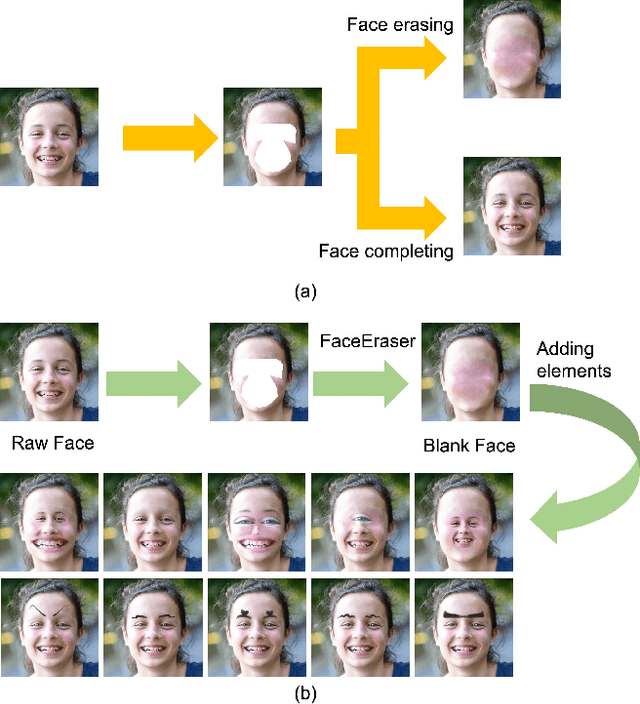
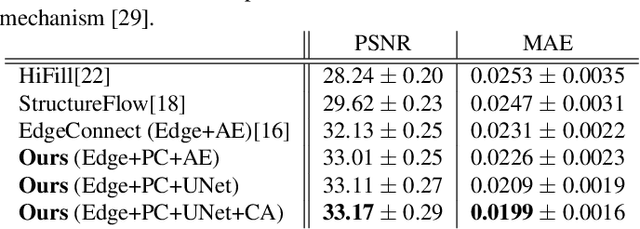
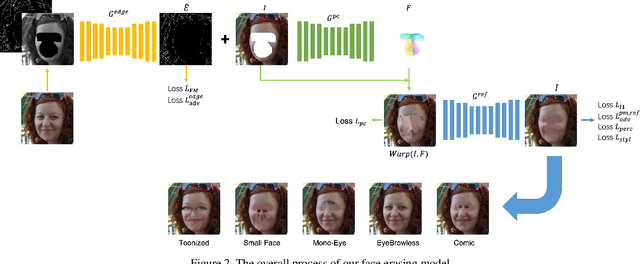
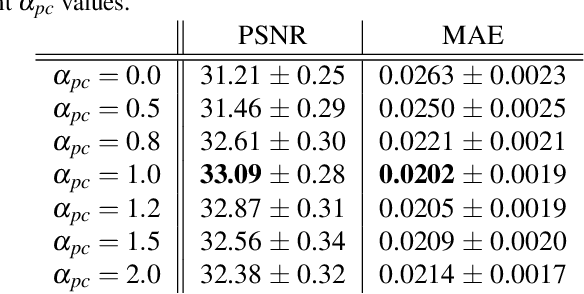
Our task is to remove all facial parts (e.g., eyebrows, eyes, mouth and nose), and then impose visual elements onto the ``blank'' face for augmented reality. Conventional object removal methods rely on image inpainting techniques (e.g., EdgeConnect, HiFill) that are trained in a self-supervised manner with randomly manipulated image pairs. Specifically, given a set of natural images, randomly masked images are used as inputs and the raw images are treated as ground truths. Whereas, this technique does not satisfy the requirements of facial parts removal, as it is hard to obtain ``ground-truth'' images with real ``blank'' faces. To address this issue, we propose a novel data generation technique to produce paired training data that well mimic the ``blank'' faces. In the mean time, we propose a novel network architecture for improved inpainting quality for our task. Finally, we demonstrate various face-oriented augmented reality applications on top of our facial parts removal model. Our method has been integrated into commercial products and its effectiveness has been verified with unconstrained user inputs. The source codes, pre-trained models and training data will be released for research purposes.
TxT: Crossmodal End-to-End Learning with Transformers
Sep 09, 2021
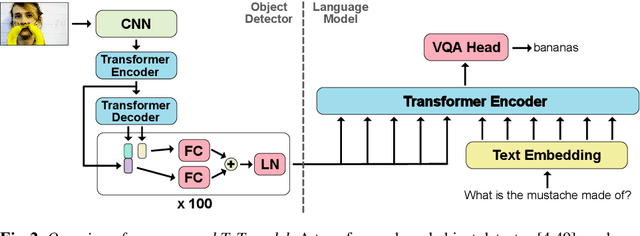

Reasoning over multiple modalities, e.g. in Visual Question Answering (VQA), requires an alignment of semantic concepts across domains. Despite the widespread success of end-to-end learning, today's multimodal pipelines by and large leverage pre-extracted, fixed features from object detectors, typically Faster R-CNN, as representations of the visual world. The obvious downside is that the visual representation is not specifically tuned to the multimodal task at hand. At the same time, while transformer-based object detectors have gained popularity, they have not been employed in today's multimodal pipelines. We address both shortcomings with TxT, a transformer-based crossmodal pipeline that enables fine-tuning both language and visual components on the downstream task in a fully end-to-end manner. We overcome existing limitations of transformer-based detectors for multimodal reasoning regarding the integration of global context and their scalability. Our transformer-based multimodal model achieves considerable gains from end-to-end learning for multimodal question answering.
A Diffeomorphic Aging Model for Adult Human Brain from Cross-Sectional Data
Jun 28, 2021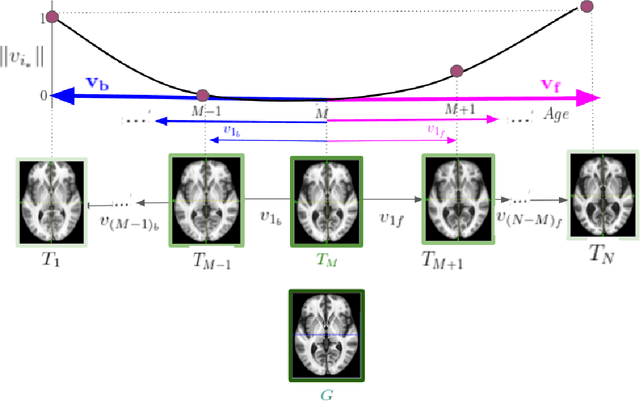
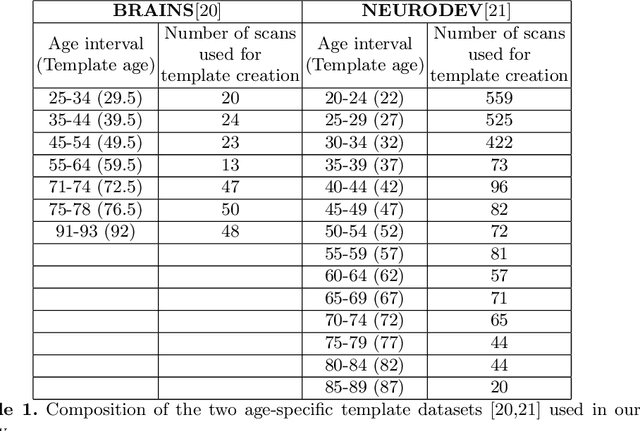
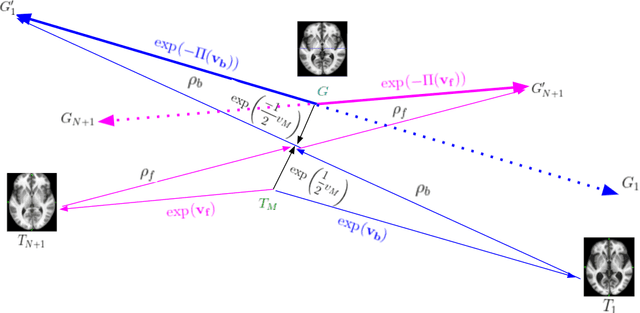
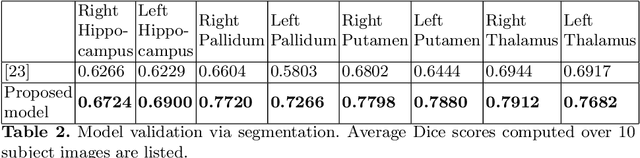
Normative aging trends of the brain can serve as an important reference in the assessment of neurological structural disorders. Such models are typically developed from longitudinal brain image data -- follow-up data of the same subject over different time points. In practice, obtaining such longitudinal data is difficult. We propose a method to develop an aging model for a given population, in the absence of longitudinal data, by using images from different subjects at different time points, the so-called cross-sectional data. We define an aging model as a diffeomorphic deformation on a structural template derived from the data and propose a method that develops topology preserving aging model close to natural aging. The proposed model is successfully validated on two public cross-sectional datasets which provide templates constructed from different sets of subjects at different age points.
Multiwavelet-based Operator Learning for Differential Equations
Sep 28, 2021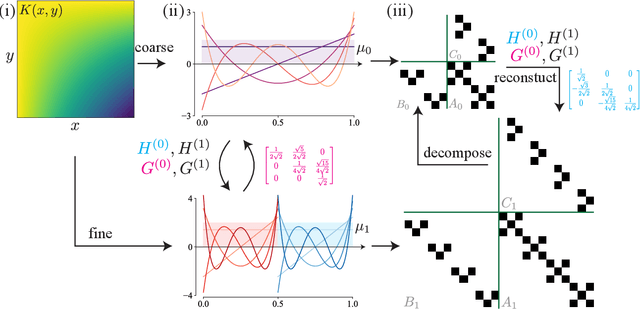
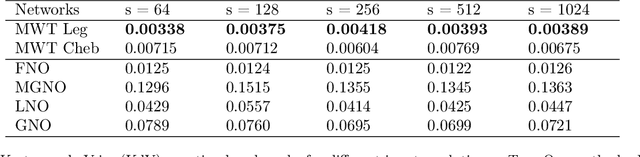
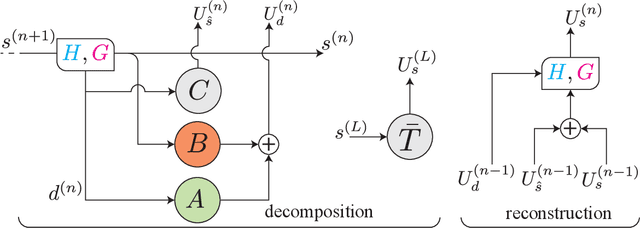
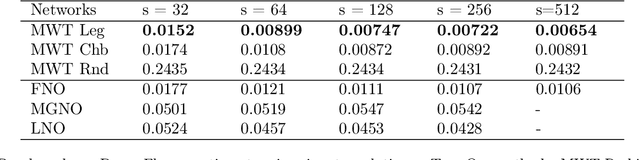
The solution of a partial differential equation can be obtained by computing the inverse operator map between the input and the solution space. Towards this end, we introduce a \textit{multiwavelet-based neural operator learning scheme} that compresses the associated operator's kernel using fine-grained wavelets. By explicitly embedding the inverse multiwavelet filters, we learn the projection of the kernel onto fixed multiwavelet polynomial bases. The projected kernel is trained at multiple scales derived from using repeated computation of multiwavelet transform. This allows learning the complex dependencies at various scales and results in a resolution-independent scheme. Compare to the prior works, we exploit the fundamental properties of the operator's kernel which enable numerically efficient representation. We perform experiments on the Korteweg-de Vries (KdV) equation, Burgers' equation, Darcy Flow, and Navier-Stokes equation. Compared with the existing neural operator approaches, our model shows significantly higher accuracy and achieves state-of-the-art in a range of datasets. For the time-varying equations, the proposed method exhibits a ($2X-10X$) improvement ($0.0018$ ($0.0033$) relative $L2$ error for Burgers' (KdV) equation). By learning the mappings between function spaces, the proposed method has the ability to find the solution of a high-resolution input after learning from lower-resolution data.
dbcsp: User-friendly R package for Distance-Based Common Spacial Patterns
Sep 02, 2021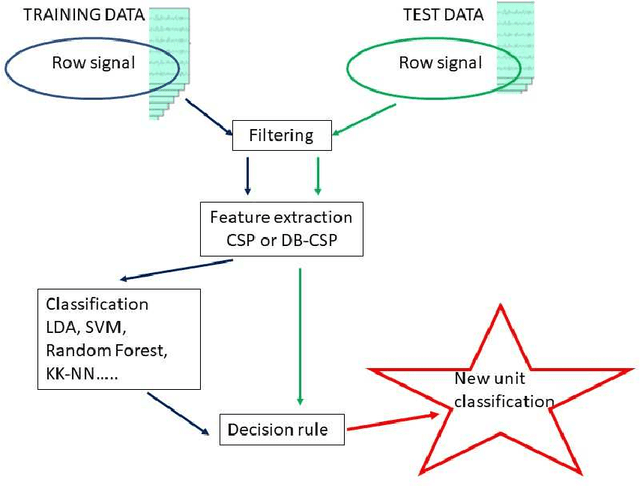
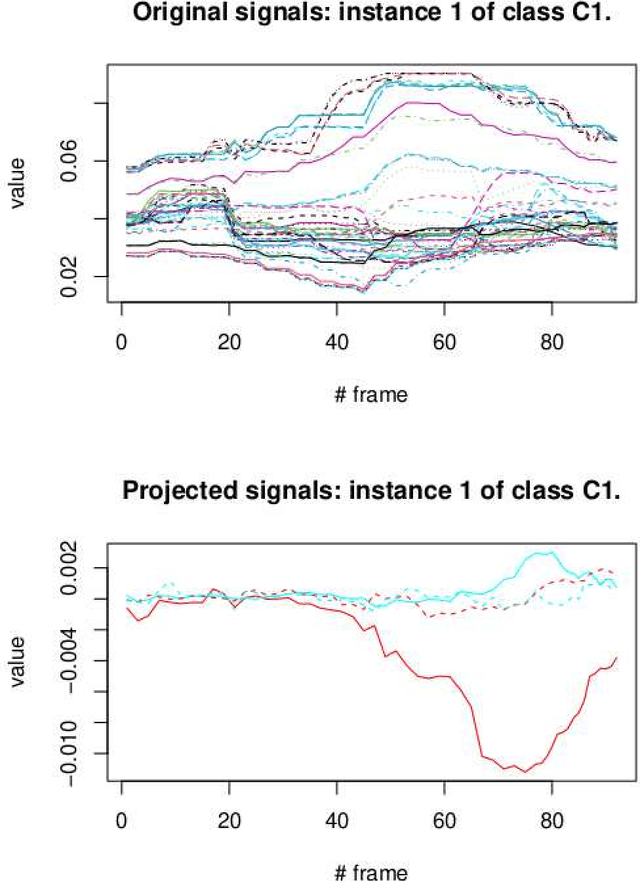
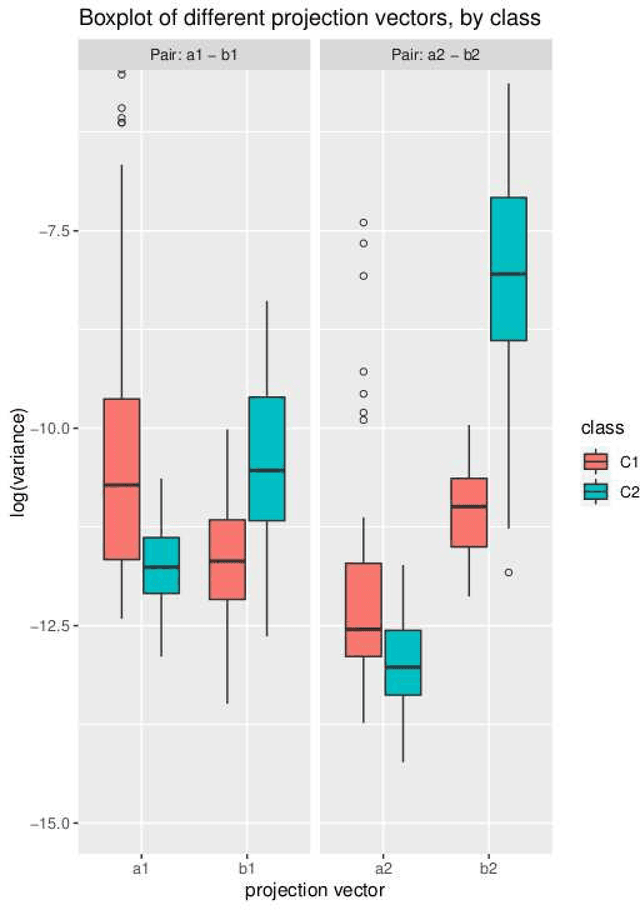
Common Spacial Patterns (CSP) is a widely used method to analyse electroencephalography (EEG) data, concerning the supervised classification of brain's activity. More generally, it can be useful to distinguish between multivariate signals recorded during a time span for two different classes. CSP is based on the simultaneous diagonalization of the average covariance matrices of signals from both classes and it allows to project the data into a low-dimensional subspace. Once data are represented in a low-dimensional subspace, a classification step must be carried out. The original CSP method is based on the Euclidean distance between signals and here, we extend it so that it can be applied on any appropriate distance for data at hand. Both, the classical CSP and the new Distance-Based CSP (DB-CSP) are implemented in an R package, called dbcsp.
Two-Stage Channel Estimation Approach for Cell-Free IoT With Massive Random Access
Sep 28, 2021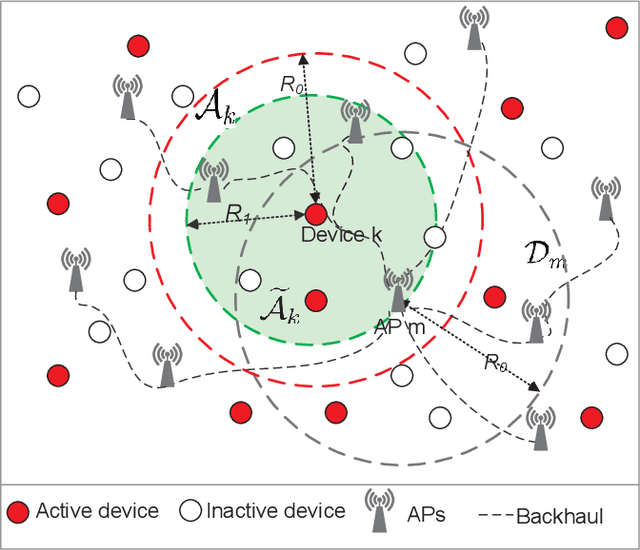
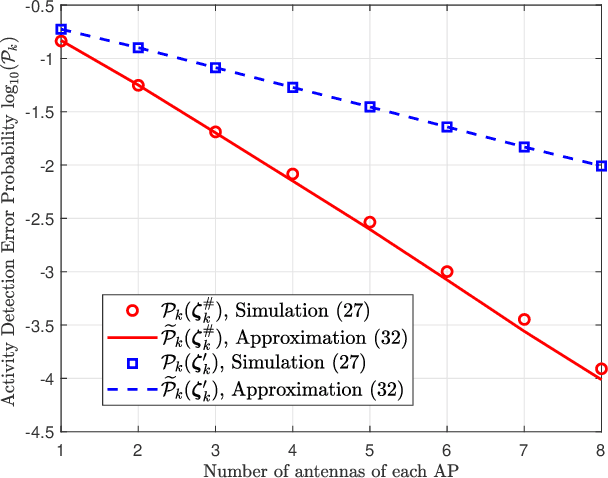
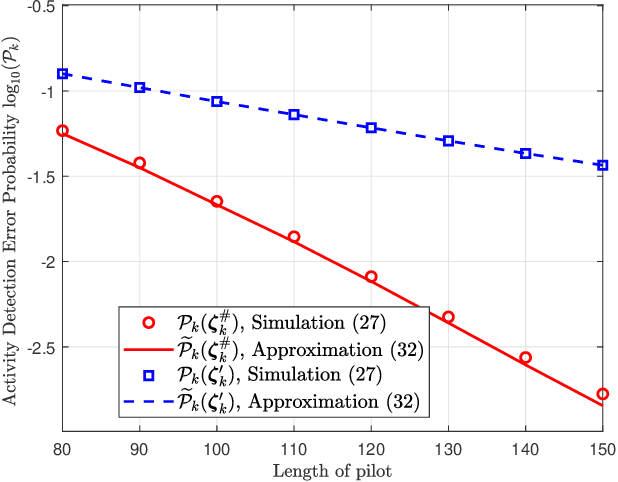
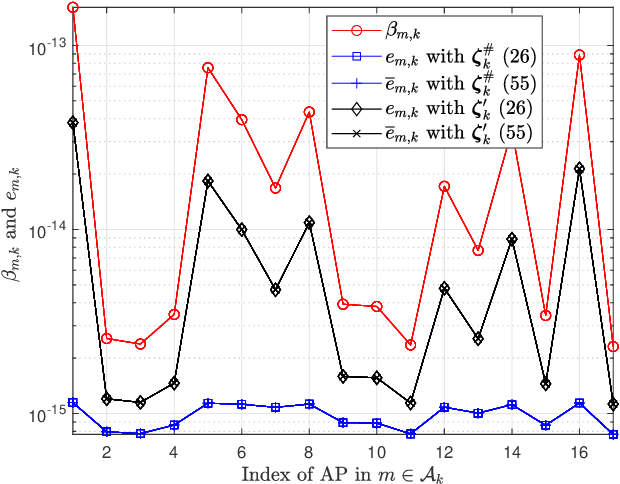
We investigate the activity detection and channel estimation issues for cell-free Internet of Things (IoT) networks with massive random access. In each time slot, only partial devices are active and communicate with neighboring access points (APs) using non-orthogonal random pilot sequences. Different from the centralized processing in cellular networks, the activity detection and channel estimation in cell-free IoT is more challenging due to the distributed and user-centric architecture. We propose a two-stage approach to detect the random activities of devices and estimate their channel states. In the first stage, the activity of each device is jointly detected by its adjacent APs based on the vector approximate message passing (Vector AMP) algorithm. In the second stage, each AP re-estimates the channel using the linear minimum mean square error (LMMSE) method based on the detected activities to improve the channel estimation accuracy. We derive closed-form expressions for the activity detection error probability and the mean-squared channel estimation errors for a typical device. Finally, we analyze the performance of the entire cell-free IoT network in terms of coverage probability. Simulation results validate the derived closed-form expressions and show that the cell-free IoT significantly outperforms the collocated massive MIMO and small-cell schemes in terms of coverage probability.
JKOnet: Proximal Optimal Transport Modeling of Population Dynamics
Jun 11, 2021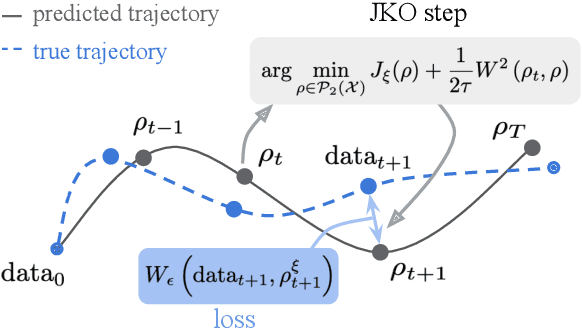

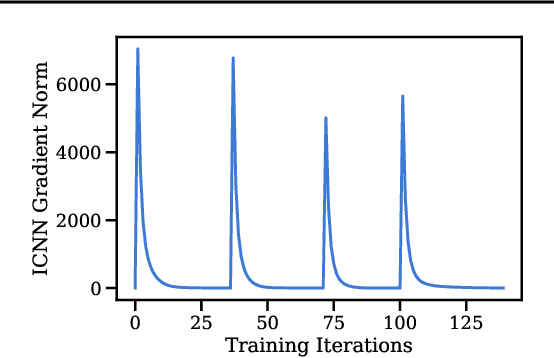
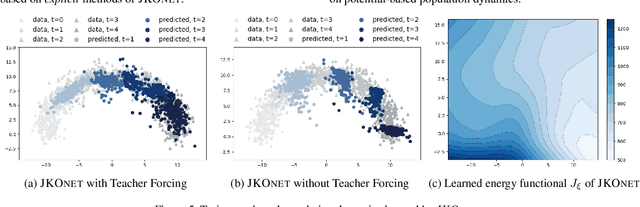
Consider a heterogeneous population of points evolving with time. While the population evolves, both in size and nature, we can observe it periodically, through snapshots taken at different timestamps. Each of these snapshots is formed by sampling points from the population at that time, and then creating features to recover point clouds. While these snapshots describe the population's evolution on aggregate, they do not provide directly insights on individual trajectories. This scenario is encountered in several applications, notably single-cell genomics experiments, tracking of particles, or when studying crowd motion. In this paper, we propose to model that dynamic as resulting from the celebrated Jordan-Kinderlehrer-Otto (JKO) proximal scheme. The JKO scheme posits that the configuration taken by a population at time $t$ is one that trades off a decrease w.r.t. an energy (the model we seek to learn) penalized by an optimal transport distance w.r.t. the previous configuration. To that end, we propose JKOnet, a neural architecture that combines an energy model on measures, with (small) optimal displacements solved with input convex neural networks (ICNN). We demonstrate the applicability of our model to explain and predict population dynamics.