 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Mechanical Chameleons: Evaluating the effects of a social robot's non-verbal behavior on social influence
Sep 02, 2021
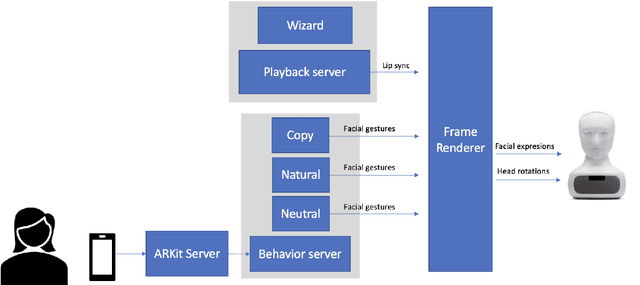

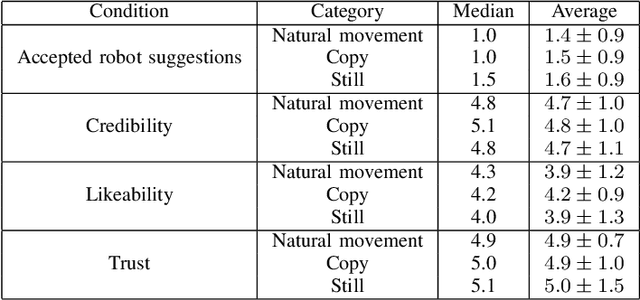
In this paper we present a pilot study which investigates how non-verbal behavior affects social influence in social robots. We also present a modular system which is capable of controlling the non-verbal behavior based on the interlocutor's facial gestures (head movements and facial expressions) in real time, and a study investigating whether three different strategies for facial gestures ("still", "natural movement", i.e. movements recorded from another conversation, and "copy", i.e. mimicking the user with a four second delay) has any affect on social influence and decision making in a "survival task". Our preliminary results show there was no significant difference between the three conditions, but this might be due to among other things a low number of study participants (12).
Generative Adversarial Imitation Learning for End-to-End Autonomous Driving on Urban Environments
Oct 16, 2021
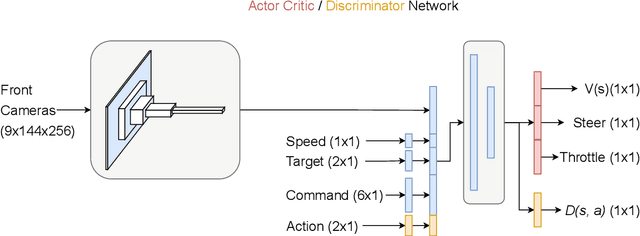

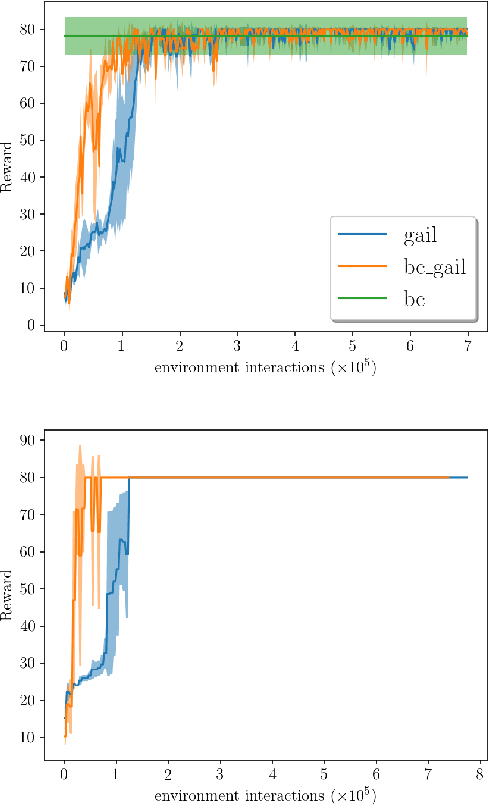
Autonomous driving is a complex task, which has been tackled since the first self-driving car ALVINN in 1989, with a supervised learning approach, or behavioral cloning (BC). In BC, a neural network is trained with state-action pairs that constitute the training set made by an expert, i.e., a human driver. However, this type of imitation learning does not take into account the temporal dependencies that might exist between actions taken in different moments of a navigation trajectory. These type of tasks are better handled by reinforcement learning (RL) algorithms, which need to define a reward function. On the other hand, more recent approaches to imitation learning, such as Generative Adversarial Imitation Learning (GAIL), can train policies without explicitly requiring to define a reward function, allowing an agent to learn by trial and error directly on a training set of expert trajectories. In this work, we propose two variations of GAIL for autonomous navigation of a vehicle in the realistic CARLA simulation environment for urban scenarios. Both of them use the same network architecture, which process high dimensional image input from three frontal cameras, and other nine continuous inputs representing the velocity, the next point from the sparse trajectory and a high-level driving command. We show that both of them are capable of imitating the expert trajectory from start to end after training ends, but the GAIL loss function that is augmented with BC outperforms the former in terms of convergence time and training stability.
Nys-Curve: Nyström-Approximated Curvature for Stochastic Optimization
Oct 16, 2021



The quasi-Newton methods generally provide curvature information by approximating the Hessian using the secant equation. However, the secant equation becomes insipid in approximating the Newton step owing to its use of the first-order derivatives. In this study, we propose an approximate Newton step-based stochastic optimization algorithm for large-scale empirical risk minimization of convex functions with linear convergence rates. Specifically, we compute a partial column Hessian of size ($d\times k$) with $k\ll d$ randomly selected variables, then use the \textit{Nystr\"om method} to better approximate the full Hessian matrix. To further reduce the computational complexity per iteration, we directly compute the update step ($\Delta\boldsymbol{w}$) without computing and storing the full Hessian or its inverse. Furthermore, to address large-scale scenarios in which even computing a partial Hessian may require significant time, we used distribution-preserving (DP) sub-sampling to compute a partial Hessian. The DP sub-sampling generates $p$ sub-samples with similar first and second-order distribution statistics and selects a single sub-sample at each epoch in a round-robin manner to compute the partial Hessian. We integrate our approximated Hessian with stochastic gradient descent and stochastic variance-reduced gradients to solve the logistic regression problem. The numerical experiments show that the proposed approach was able to obtain a better approximation of Newton\textquotesingle s method with performance competitive with the state-of-the-art first-order and the stochastic quasi-Newton methods.
HPOBench: A Collection of Reproducible Multi-Fidelity Benchmark Problems for HPO
Sep 14, 2021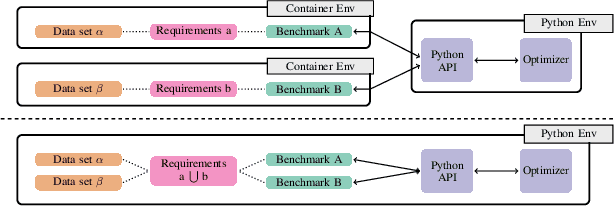
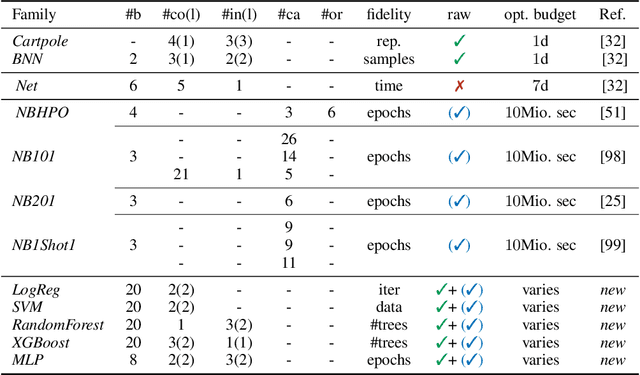

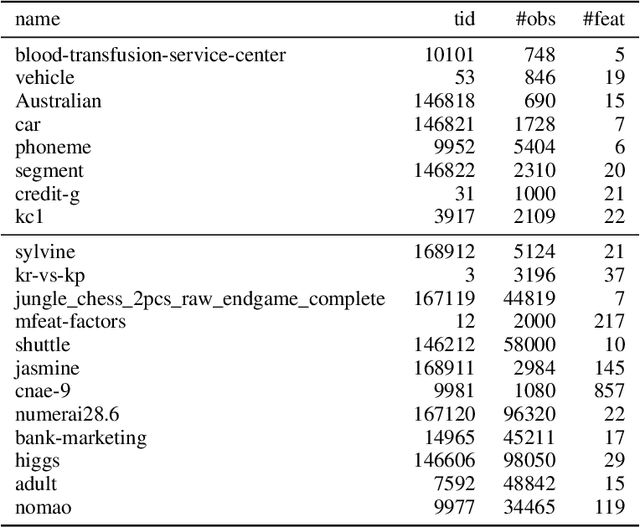
To achieve peak predictive performance, hyperparameter optimization (HPO) is a crucial component of machine learning and its applications. Over the last years,the number of efficient algorithms and tools for HPO grew substantially. At the same time, the community is still lacking realistic, diverse, computationally cheap,and standardized benchmarks. This is especially the case for multi-fidelity HPO methods. To close this gap, we propose HPOBench, which includes 7 existing and 5 new benchmark families, with in total more than 100 multi-fidelity benchmark problems. HPOBench allows to run this extendable set of multi-fidelity HPO benchmarks in a reproducible way by isolating and packaging the individual benchmarks in containers. It also provides surrogate and tabular benchmarks for computationally affordable yet statistically sound evaluations. To demonstrate the broad compatibility of HPOBench and its usefulness, we conduct an exemplary large-scale study evaluating 6 well known multi-fidelity HPO tools.
Computational Paremiology: Charting the temporal, ecological dynamics of proverb use in books, news articles, and tweets
Jul 10, 2021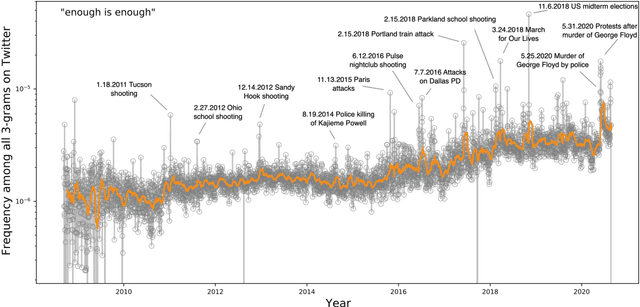
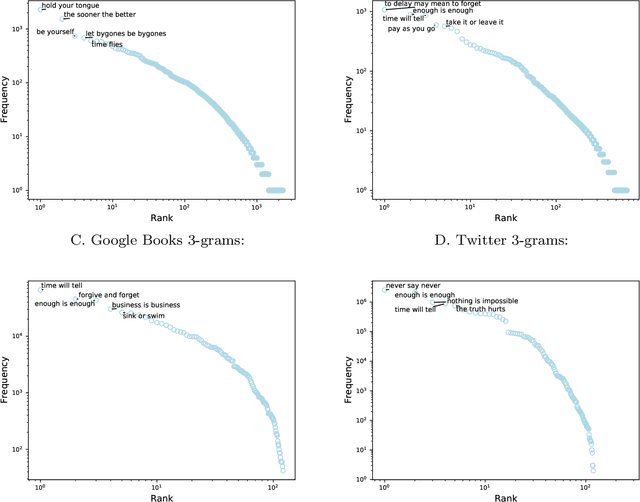
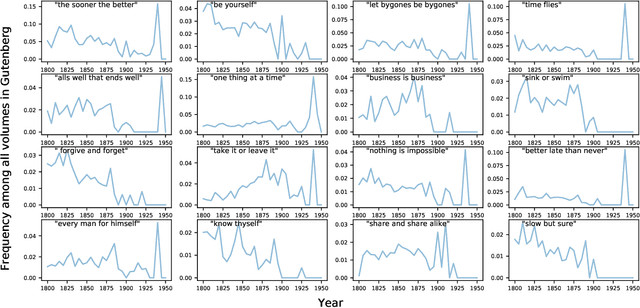
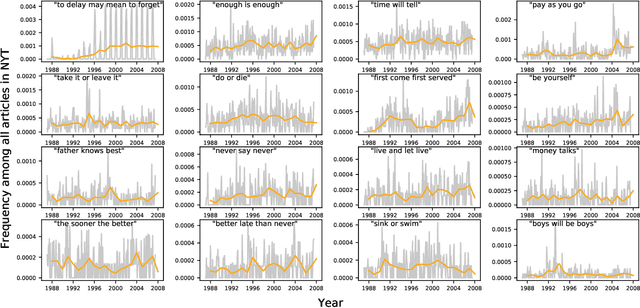
Proverbs are an essential component of language and culture, and though much attention has been paid to their history and currency, there has been comparatively little quantitative work on changes in the frequency with which they are used over time. With wider availability of large corpora reflecting many diverse genres of documents, it is now possible to take a broad and dynamic view of the importance of the proverb. Here, we measure temporal changes in the relevance of proverbs within three corpora, differing in kind, scale, and time frame: Millions of books over centuries; hundreds of millions of news articles over twenty years; and billions of tweets over a decade. We find that proverbs present heavy-tailed frequency-of-usage rank distributions in each venue; exhibit trends reflecting the cultural dynamics of the eras covered; and have evolved into contemporary forms on social media.
Imitating Deep Learning Dynamics via Locally Elastic Stochastic Differential Equations
Oct 11, 2021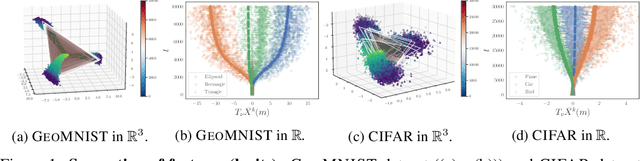
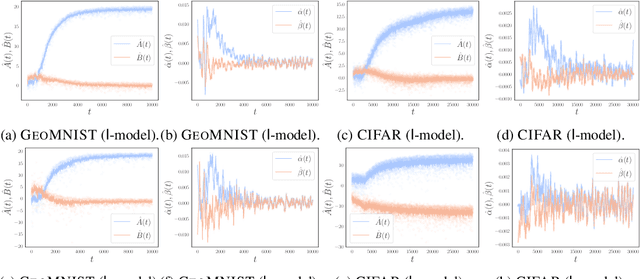
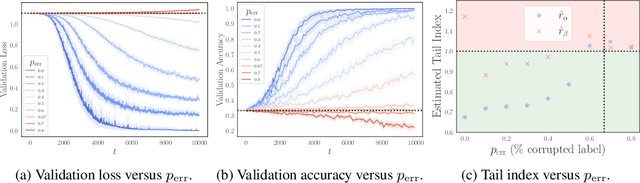
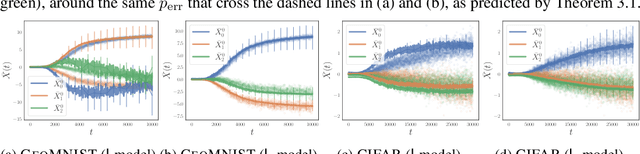
Understanding the training dynamics of deep learning models is perhaps a necessary step toward demystifying the effectiveness of these models. In particular, how do data from different classes gradually become separable in their feature spaces when training neural networks using stochastic gradient descent? In this study, we model the evolution of features during deep learning training using a set of stochastic differential equations (SDEs) that each corresponds to a training sample. As a crucial ingredient in our modeling strategy, each SDE contains a drift term that reflects the impact of backpropagation at an input on the features of all samples. Our main finding uncovers a sharp phase transition phenomenon regarding the {intra-class impact: if the SDEs are locally elastic in the sense that the impact is more significant on samples from the same class as the input, the features of the training data become linearly separable, meaning vanishing training loss; otherwise, the features are not separable, regardless of how long the training time is. Moreover, in the presence of local elasticity, an analysis of our SDEs shows that the emergence of a simple geometric structure called the neural collapse of the features. Taken together, our results shed light on the decisive role of local elasticity in the training dynamics of neural networks. We corroborate our theoretical analysis with experiments on a synthesized dataset of geometric shapes and CIFAR-10.
A Reinforcement Learning based Path Planning Approach in 3D Environment
May 21, 2021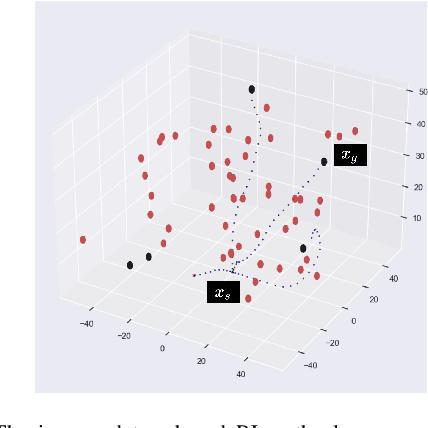
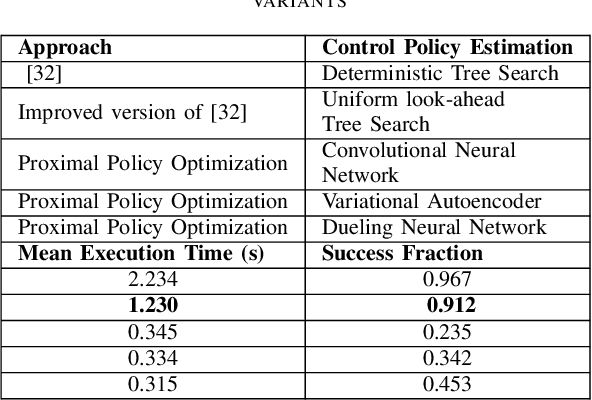
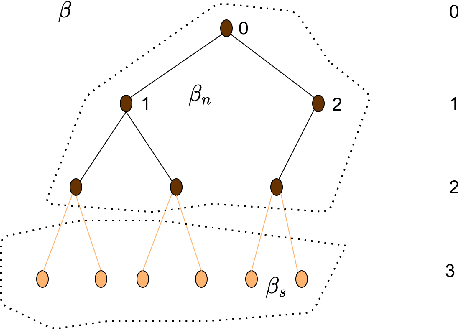
Optimal trajectory planning involves obstacles avoidance in which path planning is the key to success in optimal trajectory planning. Due to the computational demands, most of the path planning algorithms can not be employed for real-time based applications. Model-based Reinforcement Learning approaches for path planning got certain success in the recent past. Yet, most of such approaches do not have deterministic output due to the nature of those approaches. We analyzed several types of reinforcement learning-based approaches for path planning. One of them is a deterministic tree-based approach and the other two approaches are based on Q-learning and approximate policy gradient, respectively. We tested preceding approaches on two different type of simulators. Each of which consists of a set of random obstacles which could be changed or moved dynamically. After analysing the result and computation time, we concluded that the deterministic tree search approach provides a highly accurate result. However, the computational time is considerably higher than the other two approaches. Finally, the comparative results are provided in terms of accuracy and computational time as evidence.
A Reasoning Engine for the Gamification of Loop-Invariant Discovery
Sep 02, 2021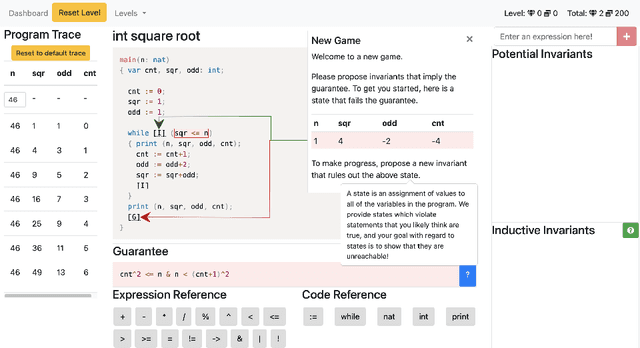
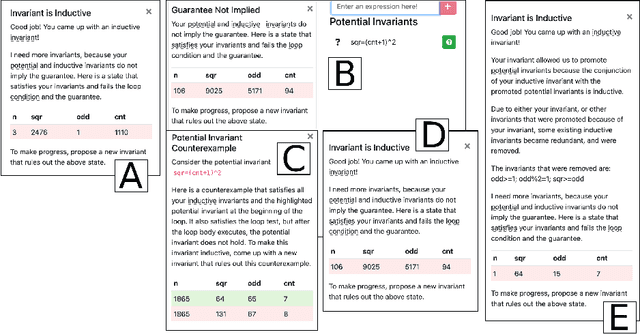

We describe the design and implementation of a reasoning engine that facilitates the gamification of loop-invariant discovery. Our reasoning engine enables students, computational agents and regular software engineers with no formal methods expertise to collaboratively prove interesting theorems about simple programs using browser-based, online games. Within an hour, players are able to specify and verify properties of programs that are beyond the capabilities of fully-automated tools. The hour limit includes the time for setting up the system, completing a short tutorial explaining game play and reasoning about simple imperative programs. Players are never required to understand formal proofs; they only provide insights by proposing invariants. The reasoning engine is responsible for managing and evaluating the proposed invariants, as well as generating actionable feedback.
Breaking the Softmax Bottleneck for Sequential Recommender Systems with Dropout and Decoupling
Oct 11, 2021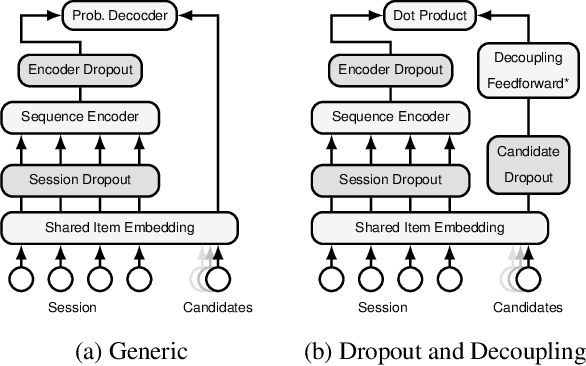

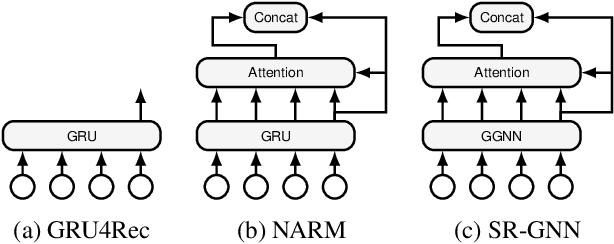
The Softmax bottleneck was first identified in language modeling as a theoretical limit on the expressivity of Softmax-based models. Being one of the most widely-used methods to output probability, Softmax-based models have found a wide range of applications, including session-based recommender systems (SBRSs). Softmax-based models consist of a Softmax function on top of a final linear layer. The bottleneck has been shown to be caused by rank deficiency in the final linear layer due to its connection with matrix factorization. In this paper, we show that there are more aspects to the Softmax bottleneck in SBRSs. Contrary to common beliefs, overfitting does happen in the final linear layer, while it is often associated with complex networks. Furthermore, we identified that the common technique of sharing item embeddings among session sequences and the candidate pool creates a tight-coupling that also contributes to the bottleneck. We propose a simple yet effective method, Dropout and Decoupling (D&D), to alleviate these problems. Our experiments show that our method significantly improves the accuracy of a variety of Softmax-based SBRS algorithms. When compared to other computationally expensive methods, such as MLP and MoS (Mixture of Softmaxes), our method performs on par with and at times even better than those methods, while keeping the same time complexity as Softmax-based models.
Towards Streaming Egocentric Action Anticipation
Oct 11, 2021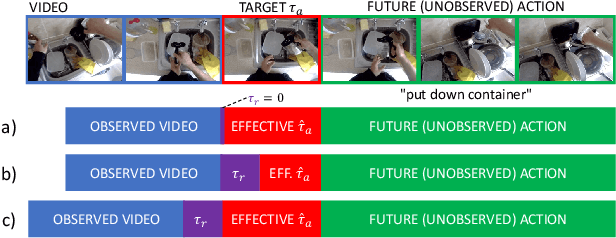
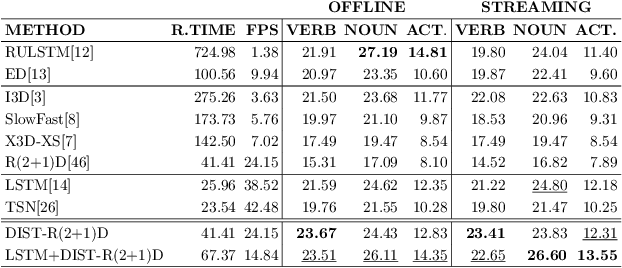
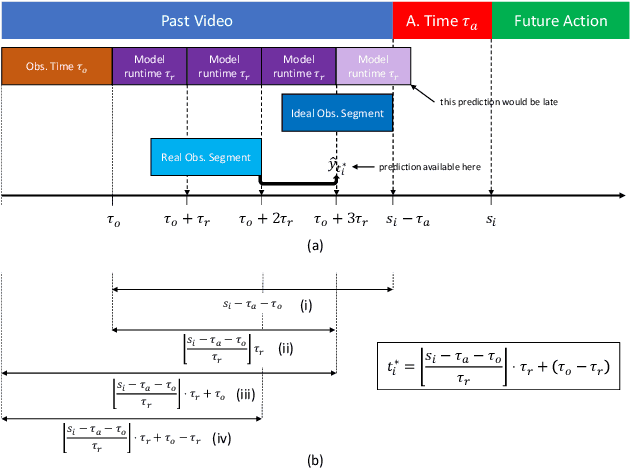
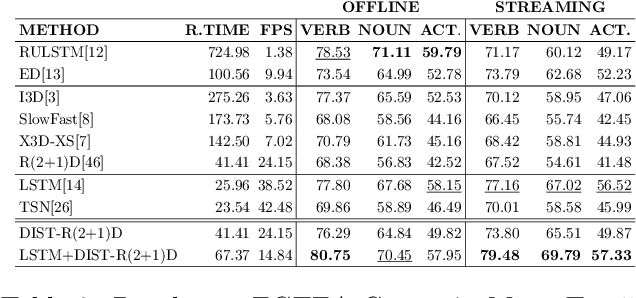
Egocentric action anticipation is the task of predicting the future actions a camera wearer will likely perform based on past video observations. While in a real-world system it is fundamental to output such predictions before the action begins, past works have not generally paid attention to model runtime during evaluation. Indeed, current evaluation schemes assume that predictions can be made offline, and hence that computational resources are not limited. In contrast, in this paper, we propose a ``streaming'' egocentric action anticipation evaluation protocol which explicitly considers model runtime for performance assessment, assuming that predictions will be available only after the current video segment is processed, which depends on the processing time of a method. Following the proposed evaluation scheme, we benchmark different state-of-the-art approaches for egocentric action anticipation on two popular datasets. Our analysis shows that models with a smaller runtime tend to outperform heavier models in the considered streaming scenario, thus changing the rankings generally observed in standard offline evaluations. Based on this observation, we propose a lightweight action anticipation model consisting in a simple feed-forward 3D CNN, which we propose to optimize using knowledge distillation techniques and a custom loss. The results show that the proposed approach outperforms prior art in the streaming scenario, also in combination with other lightweight models.