 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
State of Security and Privacy Practices of Top Websites in the East African Community (EAC)
Oct 13, 2021
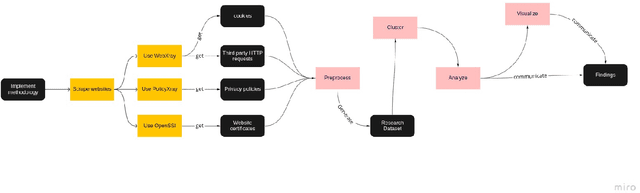
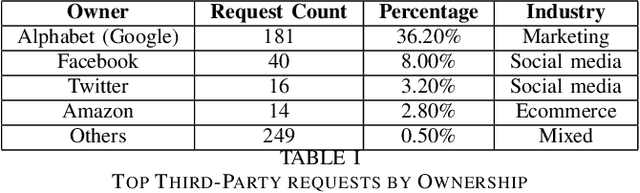
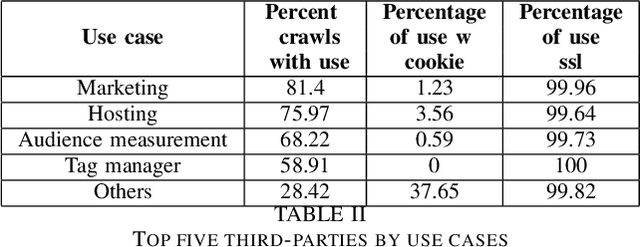
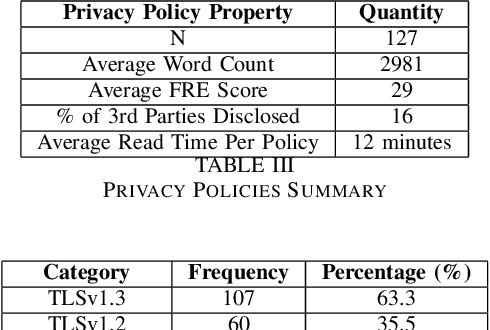
Growth in technology has resulted in the large-scale collection and processing of Personally Identifiable Information by organizations that run digital services such as websites, which led to the emergence of new legislation to regulate PII collection and processing by organizations. Subsequently, several African countries have recently started enacting new data protection regulations due to recent technological innovations. However, there is little information about the security and privacy practices of top websites serving content to EAC citizens. We, therefore, analyze the website operators' patterns in terms of third-party tracking, security of data transmission, cookie information, and privacy policies for 169 top EAC website operators using WebXray, OpenSSL, and Alexa top websites API. Our results show that only 75 percent of the analyzed websites have a privacy policy in place. Out of this, only 16 percent of the third-party tracking companies that track users on a particular website are disclosed in the site's privacy policy statements which means that users don not have a way of knowing which third parties collect data about them when they visit a website. Such privacy policies take time to read and are difficult to understand; on average, it takes a college graduate to comprehend the policy and a user spends 12 minutes to read the policy. Additionally, most third-party tracking on EAC websites is related to advertisement and belongs to companies outside the EAC. This means that EAC lawmakers need to enact suitable laws to ensure that people's privacy is protected as the rate of technology adoption continues to increase.
An Explainable-AI approach for Diagnosis of COVID-19 using MALDI-ToF Mass Spectrometry
Sep 28, 2021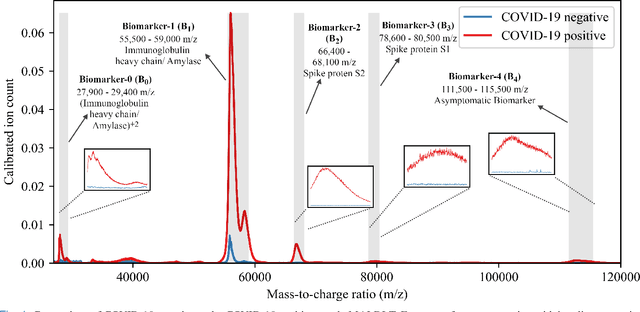
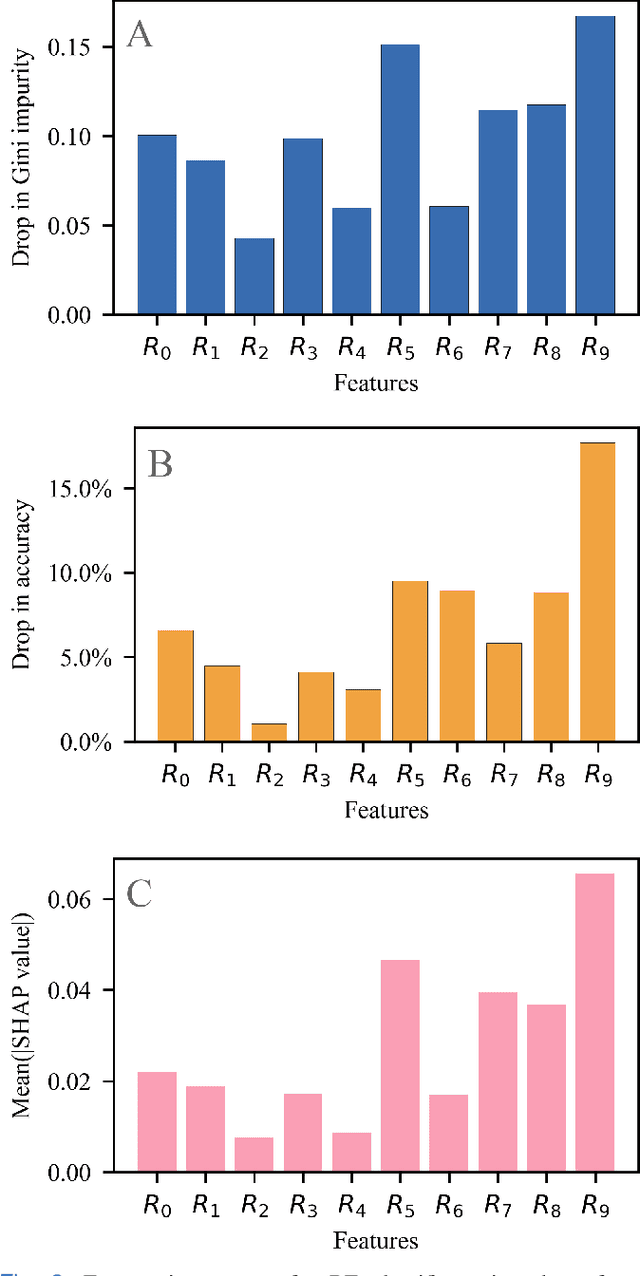
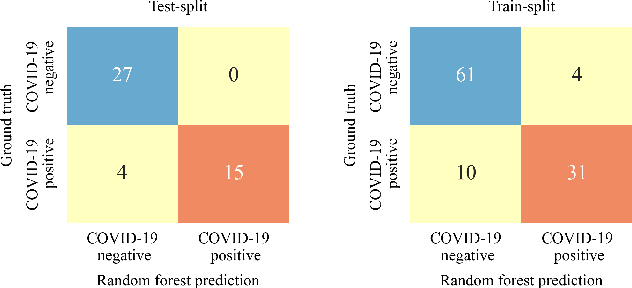
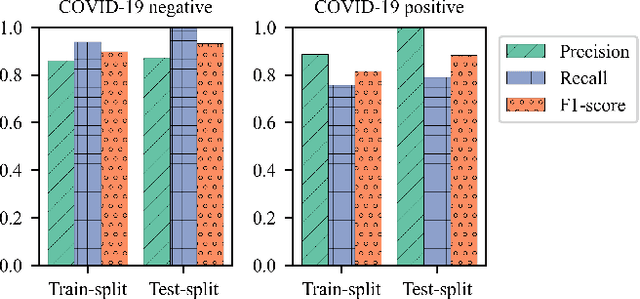
The novel severe acute respiratory syndrome coronavirus type-2 (SARS-CoV-2) caused a global pandemic that has taken more than 4.5 million lives and severely affected the global economy. To curb the spread of the virus, an accurate, cost-effective, and quick testing for large populations is exceedingly important in order to identify, isolate, and treat infected people. Current testing methods commonly use PCR (Polymerase Chain Reaction) based equipment that have limitations on throughput, cost-effectiveness, and simplicity of procedure which creates a compelling need for developing additional coronavirus disease-2019 (COVID-19) testing mechanisms, that are highly sensitive, rapid, trustworthy, and convenient to use by the public. We propose a COVID-19 testing method using artificial intelligence (AI) techniques on MALDI-ToF (matrix-assisted laser desorption/ionization time-of-flight) data extracted from 152 human gargle samples (60 COVID-19 positive tests and 92 COVID-19 negative tests). Our AI-based approach leverages explainable-AI (X-AI) methods to explain the decision rules behind the predictive algorithm both on a local (per-sample) and global (all-samples) basis to make the AI model more trustworthy. Finally, we evaluated our proposed method using a 70%-30% train-test-split strategy and achieved a training accuracy of 86.79% and a testing accuracy of 91.30%.
AutoPhaseNN: Unsupervised Physics-aware Deep Learning of 3D Nanoscale Coherent Imaging
Sep 28, 2021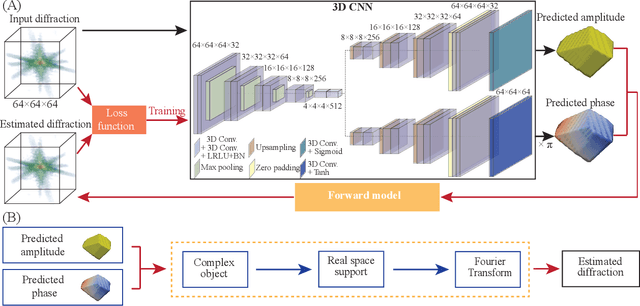
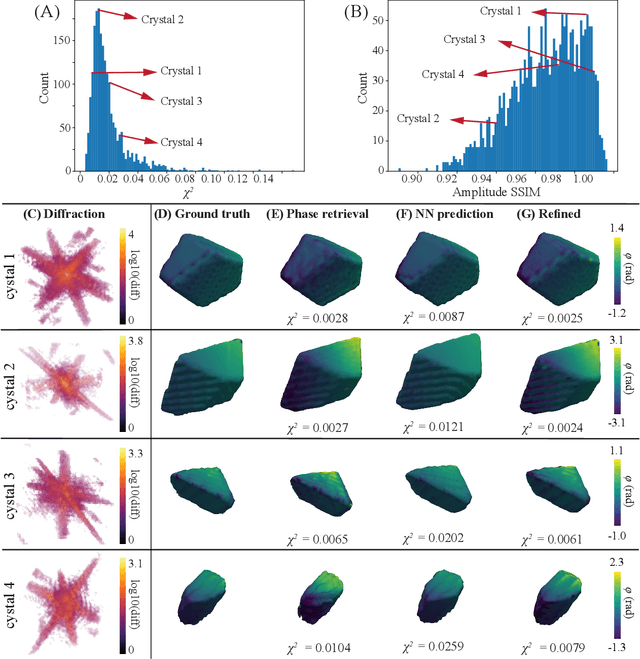
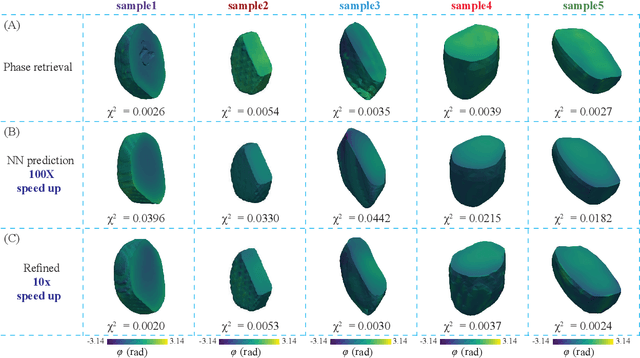
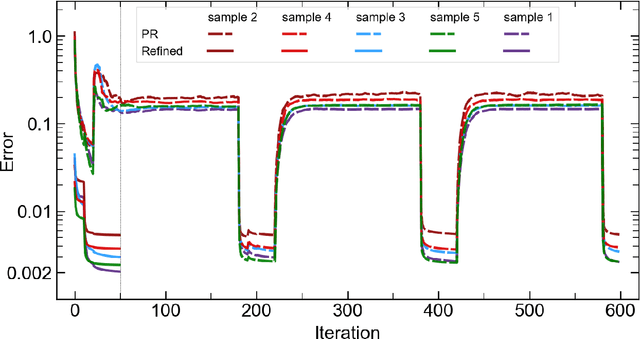
The problem of phase retrieval, or the algorithmic recovery of lost phase information from measured intensity alone, underlies various imaging methods from astronomy to nanoscale imaging. Traditional methods of phase retrieval are iterative in nature, and are therefore computationally expensive and time consuming. More recently, deep learning (DL) models have been developed to either provide learned priors to iterative phase retrieval or in some cases completely replace phase retrieval with networks that learn to recover the lost phase information from measured intensity alone. However, such models require vast amounts of labeled data, which can only be obtained through simulation or performing computationally prohibitive phase retrieval on hundreds of or even thousands of experimental datasets. Using a 3D nanoscale X-ray imaging modality (Bragg Coherent Diffraction Imaging or BCDI) as a representative technique, we demonstrate AutoPhaseNN, a DL-based approach which learns to solve the phase problem without labeled data. By incorporating the physics of the imaging technique into the DL model during training, AutoPhaseNN learns to invert 3D BCDI data from reciprocal space to real space in a single shot without ever being shown real space images. Once trained, AutoPhaseNN is about one hundred times faster than traditional iterative phase retrieval methods while providing comparable image quality.
Linear Convergence of Entropy-Regularized Natural Policy Gradient with Linear Function Approximation
Jun 08, 2021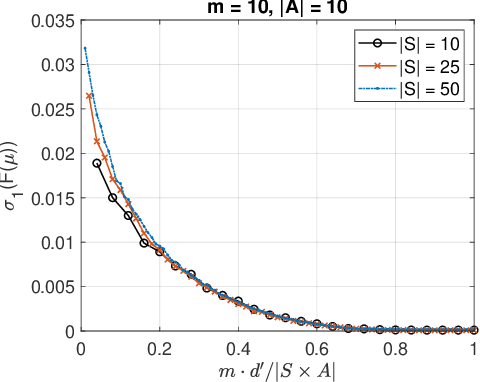
Natural policy gradient (NPG) methods with function approximation achieve impressive empirical success in reinforcement learning problems with large state-action spaces. However, theoretical understanding of their convergence behaviors remains limited in the function approximation setting. In this paper, we perform a finite-time analysis of NPG with linear function approximation and softmax parameterization, and prove for the first time that widely used entropy regularization method, which encourages exploration, leads to linear convergence rate. We adopt a Lyapunov drift analysis to prove the convergence results and explain the effectiveness of entropy regularization in improving the convergence rates.
Asking Questions Like Educational Experts: Automatically Generating Question-Answer Pairs on Real-World Examination Data
Sep 17, 2021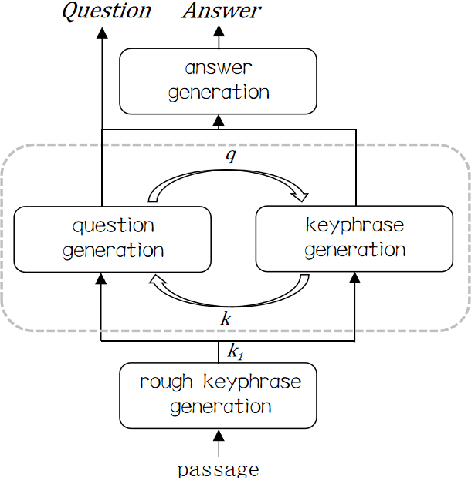

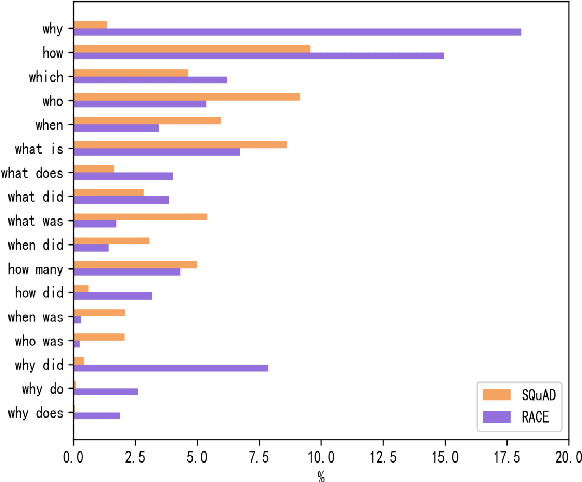
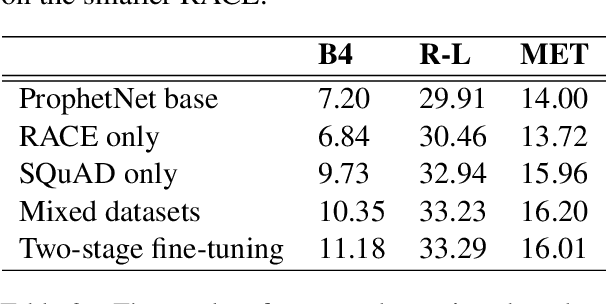
Generating high quality question-answer pairs is a hard but meaningful task. Although previous works have achieved great results on answer-aware question generation, it is difficult to apply them into practical application in the education field. This paper for the first time addresses the question-answer pair generation task on the real-world examination data, and proposes a new unified framework on RACE. To capture the important information of the input passage we first automatically generate(rather than extracting) keyphrases, thus this task is reduced to keyphrase-question-answer triplet joint generation. Accordingly, we propose a multi-agent communication model to generate and optimize the question and keyphrases iteratively, and then apply the generated question and keyphrases to guide the generation of answers. To establish a solid benchmark, we build our model on the strong generative pre-training model. Experimental results show that our model makes great breakthroughs in the question-answer pair generation task. Moreover, we make a comprehensive analysis on our model, suggesting new directions for this challenging task.
Human Pose Regression with Residual Log-likelihood Estimation
Jul 26, 2021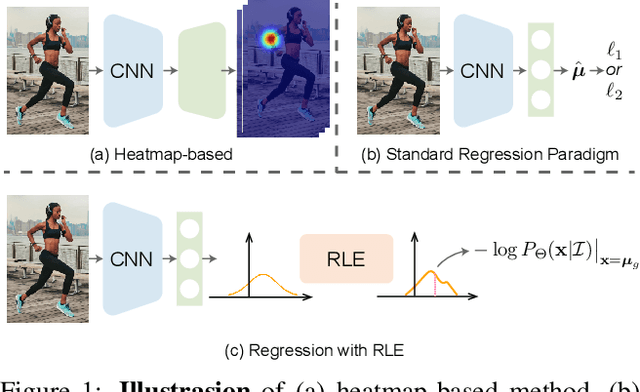
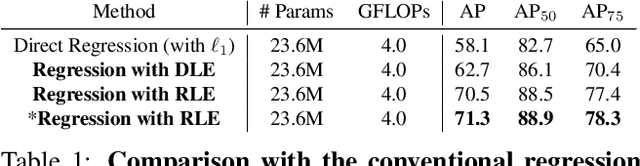
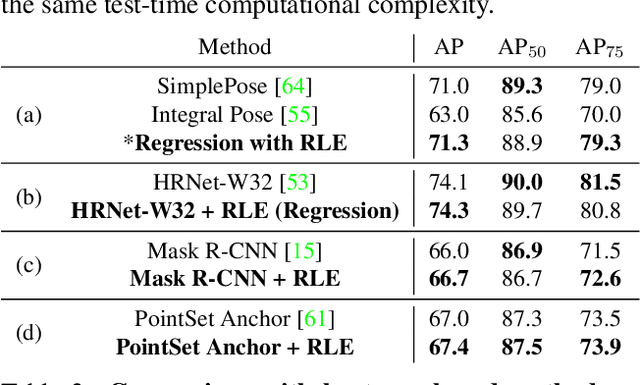
Heatmap-based methods dominate in the field of human pose estimation by modelling the output distribution through likelihood heatmaps. In contrast, regression-based methods are more efficient but suffer from inferior performance. In this work, we explore maximum likelihood estimation (MLE) to develop an efficient and effective regression-based methods. From the perspective of MLE, adopting different regression losses is making different assumptions about the output density function. A density function closer to the true distribution leads to a better regression performance. In light of this, we propose a novel regression paradigm with Residual Log-likelihood Estimation (RLE) to capture the underlying output distribution. Concretely, RLE learns the change of the distribution instead of the unreferenced underlying distribution to facilitate the training process. With the proposed reparameterization design, our method is compatible with off-the-shelf flow models. The proposed method is effective, efficient and flexible. We show its potential in various human pose estimation tasks with comprehensive experiments. Compared to the conventional regression paradigm, regression with RLE bring 12.4 mAP improvement on MSCOCO without any test-time overhead. Moreover, for the first time, especially on multi-person pose estimation, our regression method is superior to the heatmap-based methods. Our code is available at https://github.com/Jeff-sjtu/res-loglikelihood-regression
Guiding Global Placement With Reinforcement Learning
Sep 06, 2021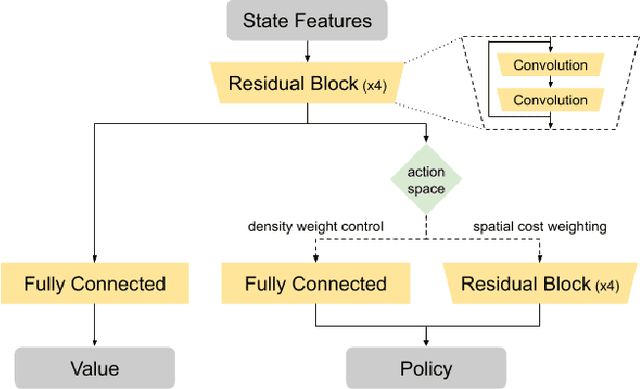
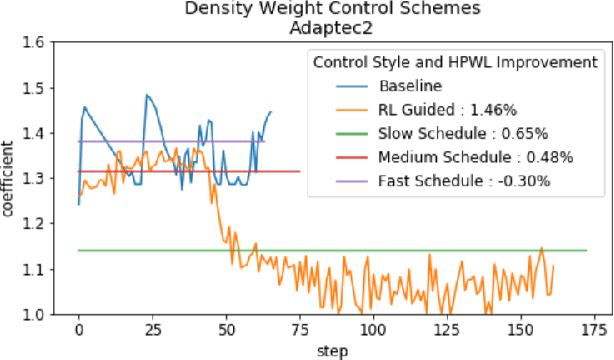
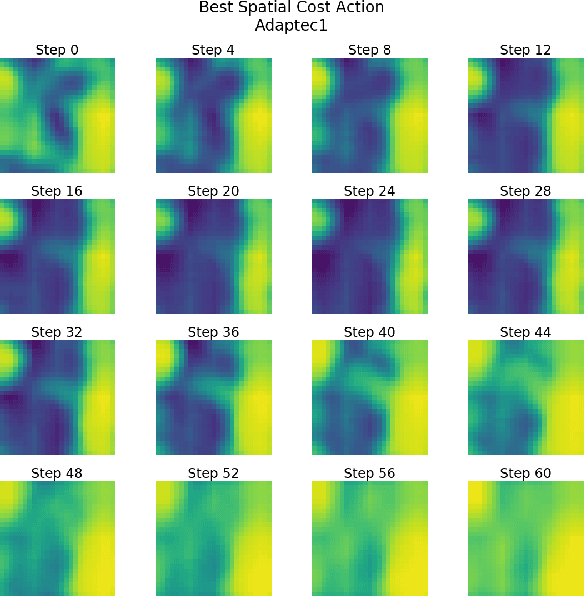
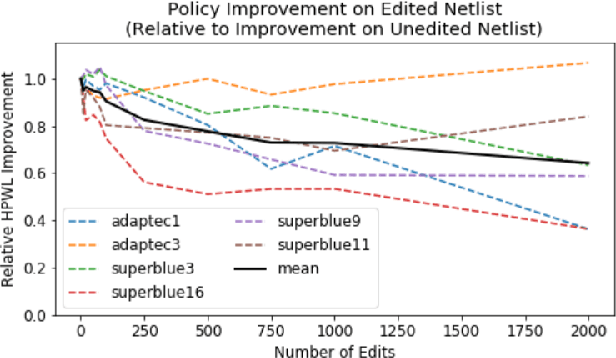
Recent advances in GPU accelerated global and detail placement have reduced the time to solution by an order of magnitude. This advancement allows us to leverage data driven optimization (such as Reinforcement Learning) in an effort to improve the final quality of placement results. In this work we augment state-of-the-art, force-based global placement solvers with a reinforcement learning agent trained to improve the final detail placed Half Perimeter Wire Length (HPWL). We propose novel control schemes with either global or localized control of the placement process. We then train reinforcement learning agents to use these controls to guide placement to improved solutions. In both cases, the augmented optimizer finds improved placement solutions. Our trained agents achieve an average 1% improvement in final detail place HPWL across a range of academic benchmarks and more than 1% in global place HPWL on real industry designs.
Active Learning for Deep Visual Tracking
Oct 17, 2021


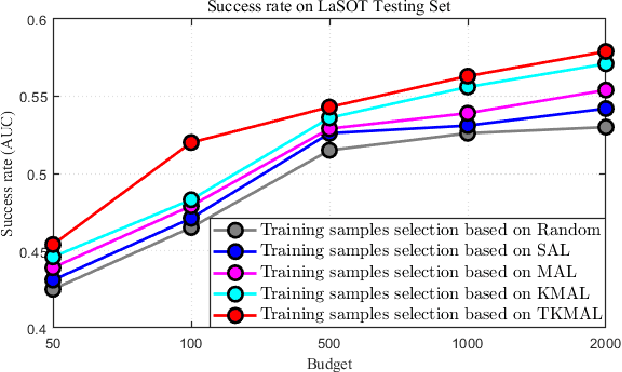
Convolutional neural networks (CNNs) have been successfully applied to the single target tracking task in recent years. Generally, training a deep CNN model requires numerous labeled training samples, and the number and quality of these samples directly affect the representational capability of the trained model. However, this approach is restrictive in practice, because manually labeling such a large number of training samples is time-consuming and prohibitively expensive. In this paper, we propose an active learning method for deep visual tracking, which selects and annotates the unlabeled samples to train the deep CNNs model. Under the guidance of active learning, the tracker based on the trained deep CNNs model can achieve competitive tracking performance while reducing the labeling cost. More specifically, to ensure the diversity of selected samples, we propose an active learning method based on multi-frame collaboration to select those training samples that should be and need to be annotated. Meanwhile, considering the representativeness of these selected samples, we adopt a nearest neighbor discrimination method based on the average nearest neighbor distance to screen isolated samples and low-quality samples. Therefore, the training samples subset selected based on our method requires only a given budget to maintain the diversity and representativeness of the entire sample set. Furthermore, we adopt a Tversky loss to improve the bounding box estimation of our tracker, which can ensure that the tracker achieves more accurate target states. Extensive experimental results confirm that our active learning-based tracker (ALT) achieves competitive tracking accuracy and speed compared with state-of-the-art trackers on the seven most challenging evaluation benchmarks.
Robust Control Under Uncertainty via Bounded Rationality and Differential Privacy
Sep 17, 2021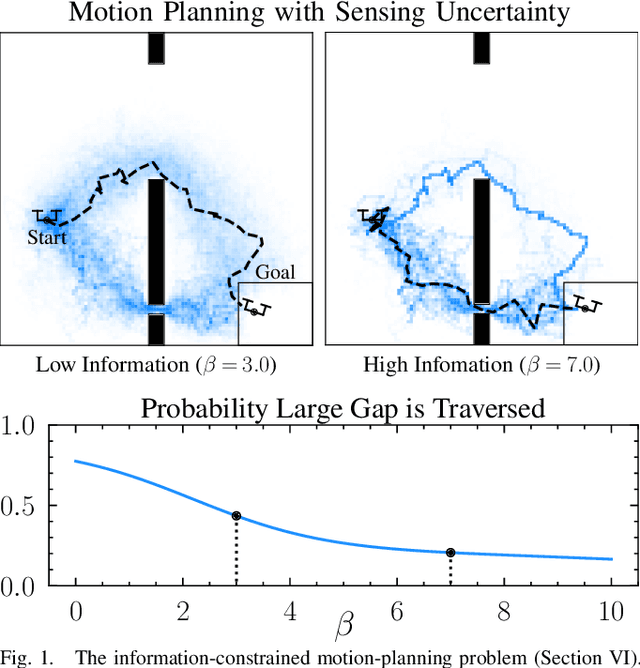
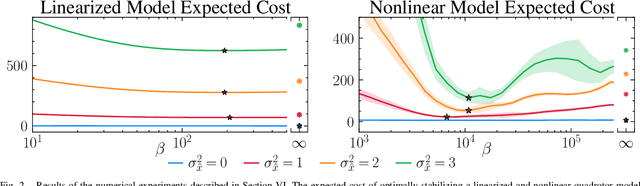
The rapid development of affordable and compact high-fidelity sensors (e.g., cameras and LIDAR) allows robots to construct detailed estimates of their states and environments. However, the availability of such rich sensor information introduces two technical challenges: (i) the lack of analytic sensing models, which makes it difficult to design controllers that are robust to sensor failures, and (ii) the computational expense of processing the high-dimensional sensor information in real time. This paper addresses these challenges using the theory of differential privacy, which allows us to (i) design controllers with bounded sensitivity to errors in state estimates, and (ii) bound the amount of state information used for control (i.e., to impose bounded rationality). The resulting framework approximates the separation principle and allows us to derive an upper-bound on the cost incurred with a faulty state estimator in terms of three quantities: the cost incurred using a perfect state estimator, the magnitude of state estimation errors, and the level of differential privacy. We demonstrate the efficacy of our framework numerically on different robotics problems, including nonlinear system stabilization and motion planning.
Compressing Deep ODE-Nets using Basis Function Expansions
Jun 21, 2021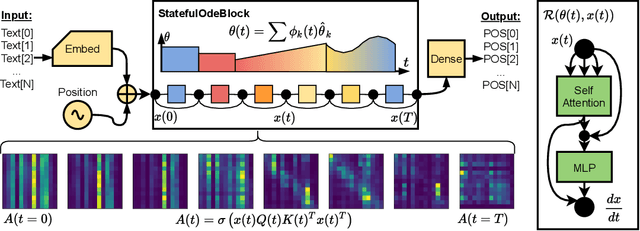

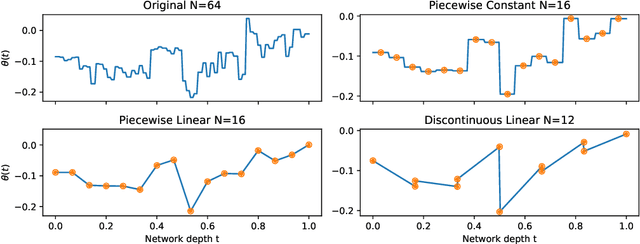
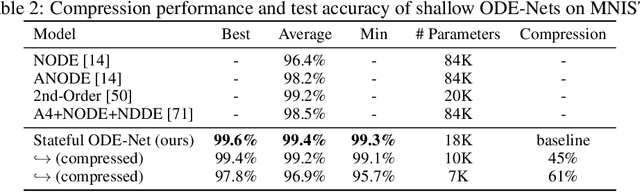
The recently-introduced class of ordinary differential equation networks (ODE-Nets) establishes a fruitful connection between deep learning and dynamical systems. In this work, we reconsider formulations of the weights as continuous-depth functions using linear combinations of basis functions. This perspective allows us to compress the weights through a change of basis, without retraining, while maintaining near state-of-the-art performance. In turn, both inference time and the memory footprint are reduced, enabling quick and rigorous adaptation between computational environments. Furthermore, our framework enables meaningful continuous-in-time batch normalization layers using function projections. The performance of basis function compression is demonstrated by applying continuous-depth models to (a) image classification tasks using convolutional units and (b) sentence-tagging tasks using transformer encoder units.