 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Qualitative and Quantitative Analysis of Diversity in Cross-document Coreference Resolution Datasets
Sep 11, 2021

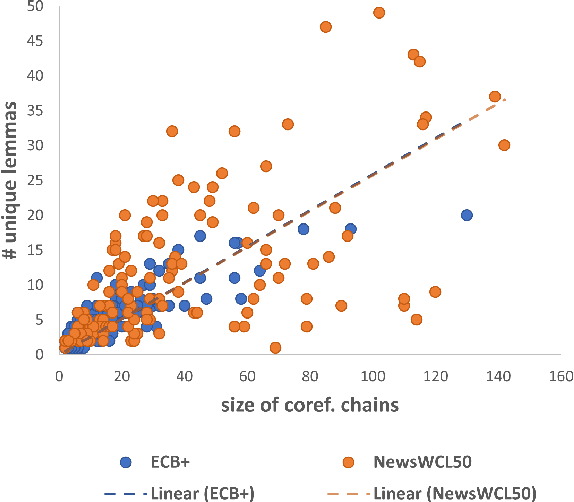
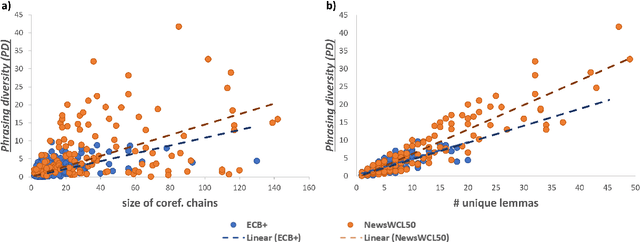
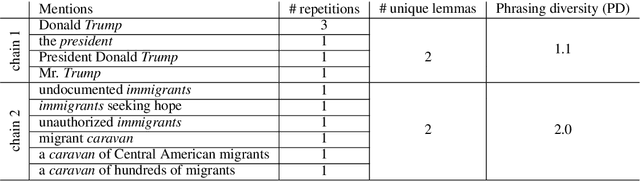
Cross-document coreference resolution (CDCR) datasets, such as ECB+, contain manually annotated event-centric mentions of events and entities that form coreference chains with identity relations. ECB+ is a state-of-the-art CDCR dataset that focuses on the resolution of events and their descriptive attributes, i.e., actors, location, and date-time. NewsWCL50 is a dataset that annotates coreference chains of both events and entities with a strong variance of word choice and more loosely-related coreference anaphora, e.g., bridging or near-identity relations. In this paper, we qualitatively and quantitatively compare annotation schemes of ECB+ and NewsWCL50 with multiple criteria. We propose a phrasing diversity metric (PD) that compares lexical diversity within coreference chains on a more detailed level than previously proposed metric, e.g., a number of unique lemmas. We discuss the different tasks that both CDCR datasets create, i.e., lexical disambiguation and lexical diversity challenges, and propose a direction for further CDCR evaluation.
Machine Learning Constructives and Local Searches for the Travelling Salesman Problem
Aug 02, 2021

The ML-Constructive heuristic is a recently presented method and the first hybrid method capable of scaling up to real scale traveling salesman problems. It combines machine learning techniques and classic optimization techniques. In this paper we present improvements to the computational weight of the original deep learning model. In addition, as simpler models reduce the execution time, the possibility of adding a local-search phase is explored to further improve performance. Experimental results corroborate the quality of the proposed improvements.
AutoMCM: Maneuver Coordination Service with Abstracted Functions for Autonomous Driving
Jul 14, 2021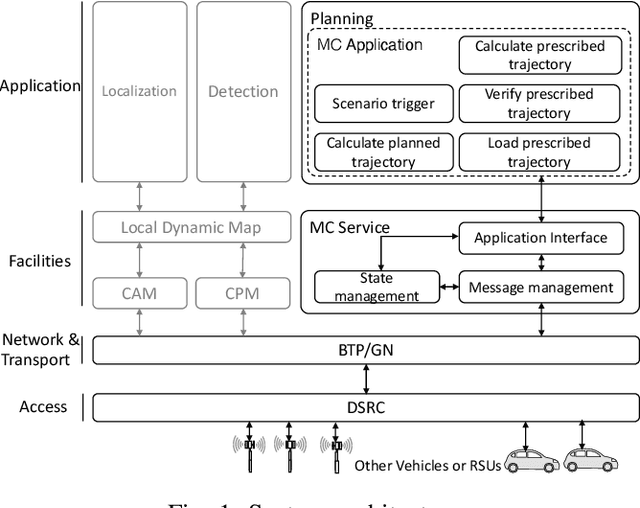
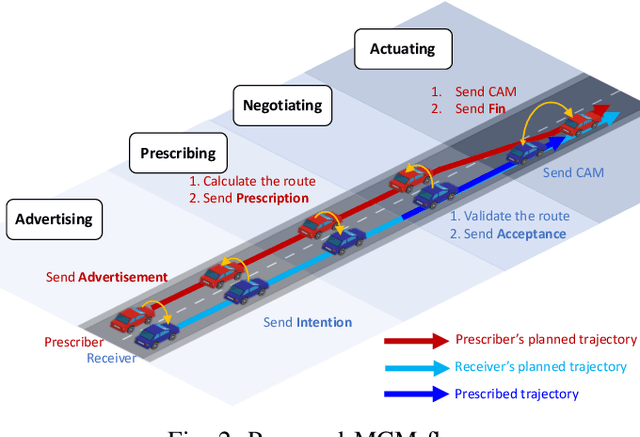
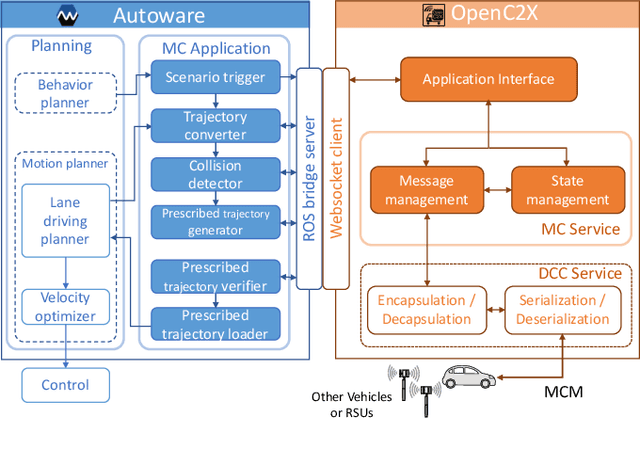
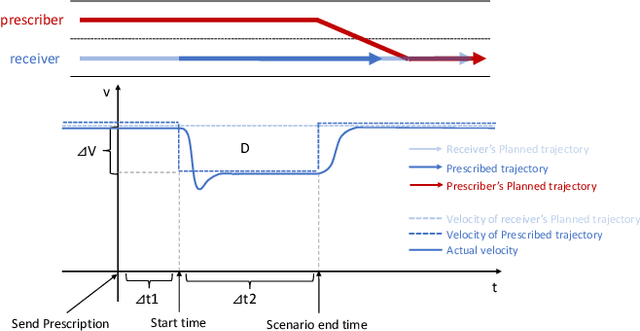
A cooperative intelligent transport system (C-ITS) uses vehicle-to-everything (V2X) technology to make self-driving vehicles safer and more efficient. Current C-ITS applications have mainly focused on real-time information sharing, such as for cooperative perception. In addition to better real-time perception, self-driving vehicles need to achieve higher safety and efficiency by coordinating action plans. This study designs a maneuver coordination (MC) protocol that uses seven messages to cover various scenarios and an abstracted MC support service. We implement our proposal as AutoMCM by extending two open-source software tools: Autoware for autonomous driving and OpenC2X for C-ITS. The results show that our system effectively reduces the communication bandwidth by limiting message exchange in an event-driven manner. Furthermore, it shows that the vehicles run 15% faster when the vehicle speed is 30 km/h and 28% faster when the vehicle speed is 50 km/h using our scheme. Our system shows robustness against packet loss in experiments when the message timeout parameters are appropriately set.
Finding Strong Gravitational Lenses Through Self-Attention
Oct 18, 2021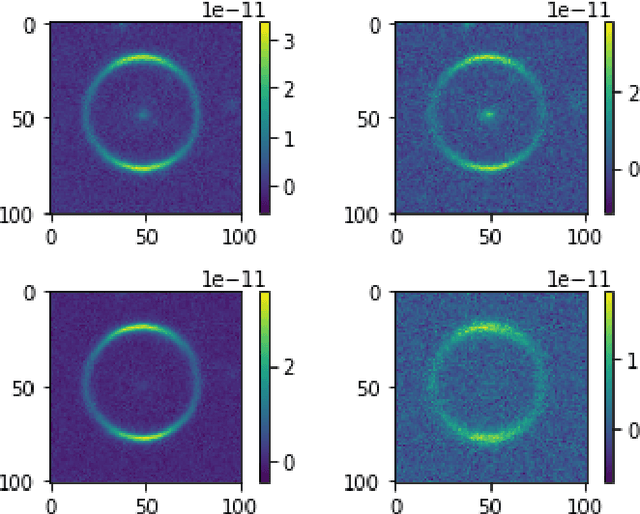
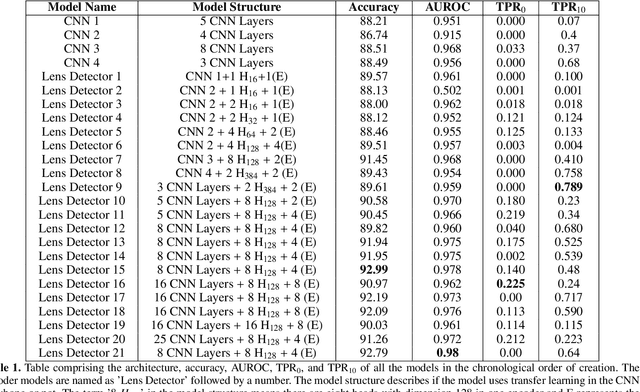
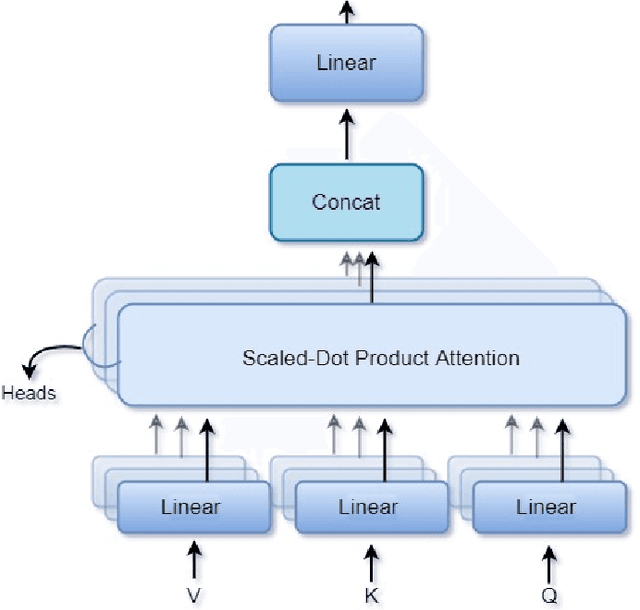
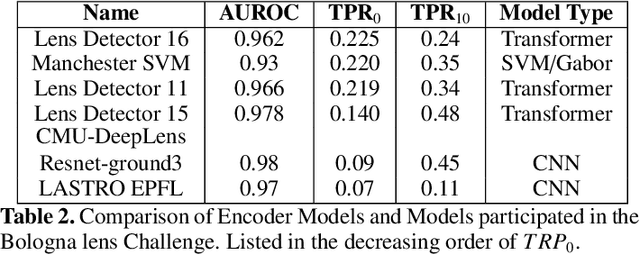
The upcoming large scale surveys are expected to find approximately $10^5$ strong gravitational systems by analyzing data of many orders of magnitude than the current era. In this scenario, non-automated techniques will be highly challenging and time-consuming. We propose a new automated architecture based on the principle of self-attention to find strong gravitational lensing. The advantages of self-attention based encoder models over convolution neural networks are investigated and encoder models are analyzed to optimize performance. We constructed 21 self-attention based encoder models and four convolution neural networks trained to identify gravitational lenses from the Bologna Lens Challenge. Each model is trained separately using 18,000 simulated images, cross-validated using 2 000 images, and then applied to a test set with 100 000 images. We used four different metrics for evaluation: classification accuracy, the area under the receiver operating characteristic curve (AUROC), the $TPR_0$ score and the $TPR_{10}$ score. The performance of the self-attention based encoder models and CNN's participated in the challenge are compared. The encoder models performed better than the CNNs and surpassed the CNN models that participated in the bologna lens challenge by a high margin for the $TPR_0$ and $TPR_{10}$. In terms of the AUROC, the encoder models scored equivalent to the top CNN model by only using one-sixth parameters to that of the CNN. Self-Attention based models have a clear advantage compared to simpler CNNs. A low computational cost and complexity make it a highly competing architecture to currently used residual neural networks. Moreover, introducing the encoder layers can also tackle the over-fitting problem present in the CNN's by acting as effective filters.
DeepSSM: A Blueprint for Image-to-Shape Deep Learning Models
Oct 14, 2021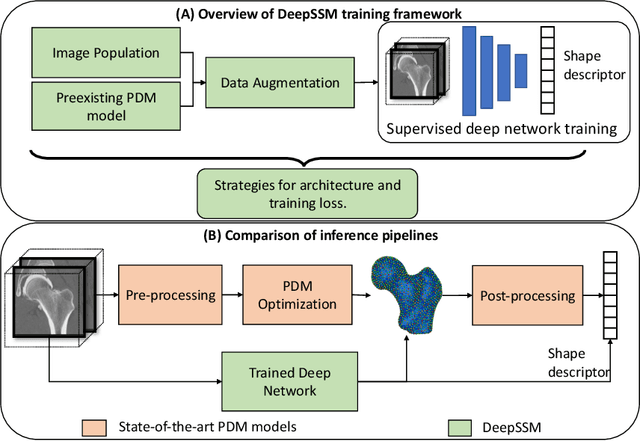

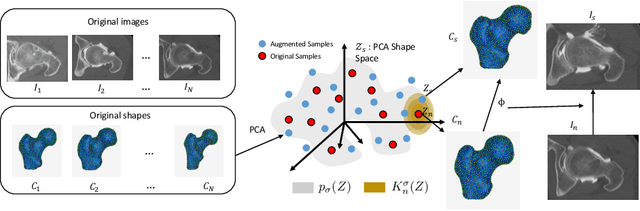
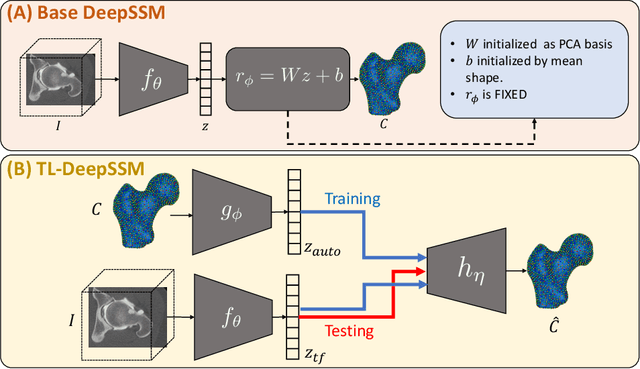
Statistical shape modeling (SSM) characterizes anatomical variations in a population of shapes generated from medical images. SSM requires consistent shape representation across samples in shape cohort. Establishing this representation entails a processing pipeline that includes anatomy segmentation, re-sampling, registration, and non-linear optimization. These shape representations are then used to extract low-dimensional shape descriptors that facilitate subsequent analyses in different applications. However, the current process of obtaining these shape descriptors from imaging data relies on human and computational resources, requiring domain expertise for segmenting anatomies of interest. Moreover, this same taxing pipeline needs to be repeated to infer shape descriptors for new image data using a pre-trained/existing shape model. Here, we propose DeepSSM, a deep learning-based framework for learning the functional mapping from images to low-dimensional shape descriptors and their associated shape representations, thereby inferring statistical representation of anatomy directly from 3D images. Once trained using an existing shape model, DeepSSM circumvents the heavy and manual pre-processing and segmentation and significantly improves the computational time, making it a viable solution for fully end-to-end SSM applications. In addition, we introduce a model-based data-augmentation strategy to address data scarcity. Finally, this paper presents and analyzes two different architectural variants of DeepSSM with different loss functions using three medical datasets and their downstream clinical application. Experiments showcase that DeepSSM performs comparably or better to the state-of-the-art SSM both quantitatively and on application-driven downstream tasks. Therefore, DeepSSM aims to provide a comprehensive blueprint for deep learning-based image-to-shape models.
Towards efficient end-to-end speech recognition with biologically-inspired neural networks
Oct 04, 2021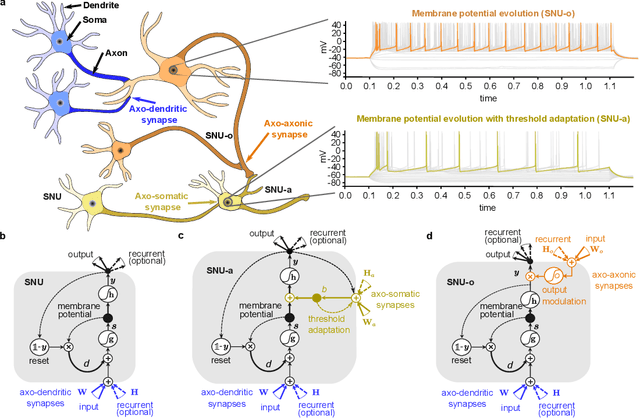


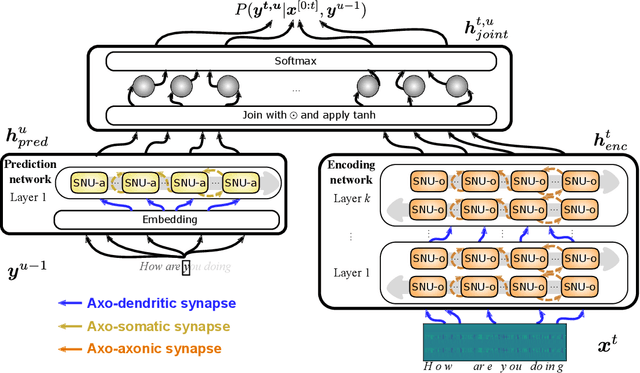
Automatic speech recognition (ASR) is a capability which enables a program to process human speech into a written form. Recent developments in artificial intelligence (AI) have led to high-accuracy ASR systems based on deep neural networks, such as the recurrent neural network transducer (RNN-T). However, the core components and the performed operations of these approaches depart from the powerful biological counterpart, i.e., the human brain. On the other hand, the current developments in biologically-inspired ASR models, based on spiking neural networks (SNNs), lag behind in terms of accuracy and focus primarily on small scale applications. In this work, we revisit the incorporation of biologically-plausible models into deep learning and we substantially enhance their capabilities, by taking inspiration from the diverse neural and synaptic dynamics found in the brain. In particular, we introduce neural connectivity concepts emulating the axo-somatic and the axo-axonic synapses. Based on this, we propose novel deep learning units with enriched neuro-synaptic dynamics and integrate them into the RNN-T architecture. We demonstrate for the first time, that a biologically realistic implementation of a large-scale ASR model can yield competitive performance levels compared to the existing deep learning models. Specifically, we show that such an implementation bears several advantages, such as a reduced computational cost and a lower latency, which are critical for speech recognition applications.
Online Robust Reinforcement Learning with Model Uncertainty
Sep 29, 2021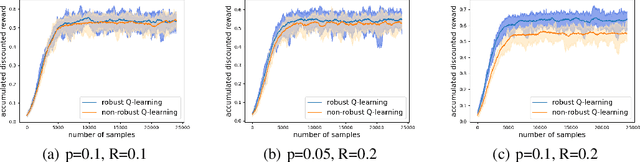
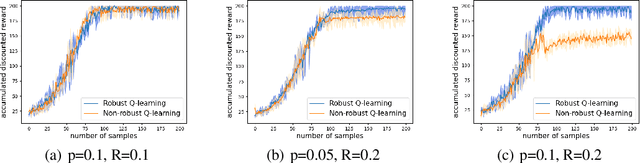
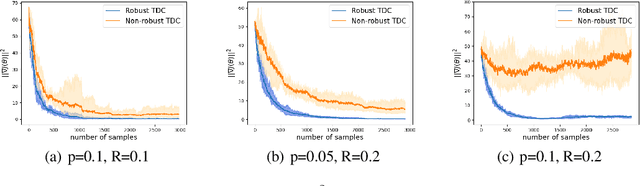
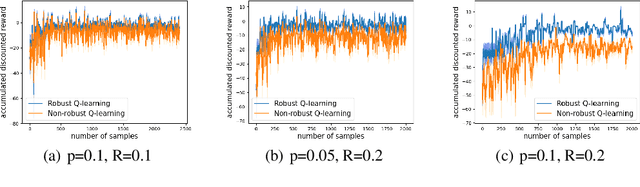
Robust reinforcement learning (RL) is to find a policy that optimizes the worst-case performance over an uncertainty set of MDPs. In this paper, we focus on model-free robust RL, where the uncertainty set is defined to be centering at a misspecified MDP that generates a single sample trajectory sequentially and is assumed to be unknown. We develop a sample-based approach to estimate the unknown uncertainty set and design a robust Q-learning algorithm (tabular case) and robust TDC algorithm (function approximation setting), which can be implemented in an online and incremental fashion. For the robust Q-learning algorithm, we prove that it converges to the optimal robust Q function, and for the robust TDC algorithm, we prove that it converges asymptotically to some stationary points. Unlike the results in [Roy et al., 2017], our algorithms do not need any additional conditions on the discount factor to guarantee the convergence. We further characterize the finite-time error bounds of the two algorithms and show that both the robust Q-learning and robust TDC algorithms converge as fast as their vanilla counterparts(within a constant factor). Our numerical experiments further demonstrate the robustness of our algorithms. Our approach can be readily extended to robustify many other algorithms, e.g., TD, SARSA, and other GTD algorithms.
Learning to Price Against a Moving Target
Jun 08, 2021In the Learning to Price setting, a seller posts prices over time with the goal of maximizing revenue while learning the buyer's valuation. This problem is very well understood when values are stationary (fixed or iid). Here we study the problem where the buyer's value is a moving target, i.e., they change over time either by a stochastic process or adversarially with bounded variation. In either case, we provide matching upper and lower bounds on the optimal revenue loss. Since the target is moving, any information learned soon becomes out-dated, which forces the algorithms to keep switching between exploring and exploiting phases.
Multi-Task Learning for User Engagement and Adoption in Live Video Streaming Events
Jun 18, 2021
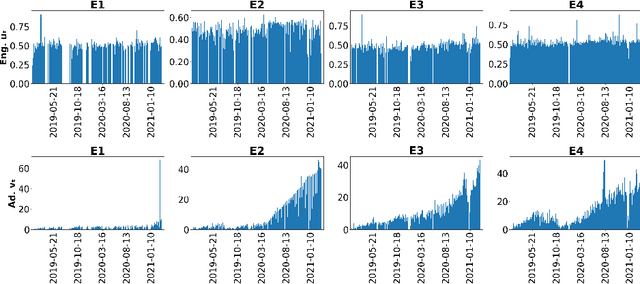
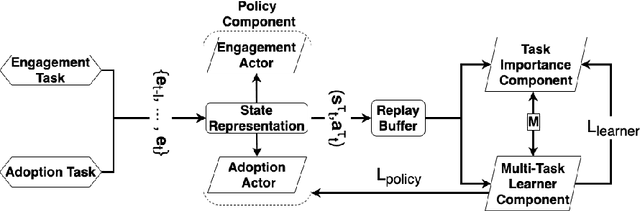
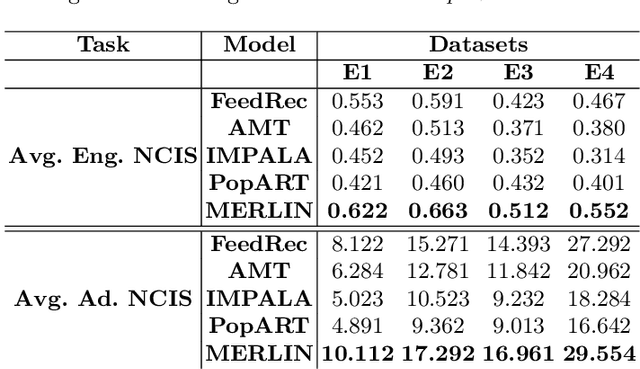
Nowadays, live video streaming events have become a mainstay in viewer's communication in large international enterprises. Provided that viewers are distributed worldwide, the main challenge resides on how to schedule the optimal event's time so as to improve both the viewer's engagement and adoption. In this paper we present a multi-task deep reinforcement learning model to select the time of a live video streaming event, aiming to optimize the viewer's engagement and adoption at the same time. We consider the engagement and adoption of the viewers as independent tasks and formulate a unified loss function to learn a common policy. In addition, we account for the fact that each task might have different contribution to the training strategy of the agent. Therefore, to determine the contribution of each task to the agent's training, we design a Transformer's architecture for the state-action transitions of each task. We evaluate our proposed model on four real-world datasets, generated by the live video streaming events of four large enterprises spanning from January 2019 until March 2021. Our experiments demonstrate the effectiveness of the proposed model when compared with several state-of-the-art strategies. For reproduction purposes, our evaluation datasets and implementation are publicly available at https://github.com/stefanosantaris/merlin.
Adaptive Latent Space Tuning for Non-Stationary Distributions
May 08, 2021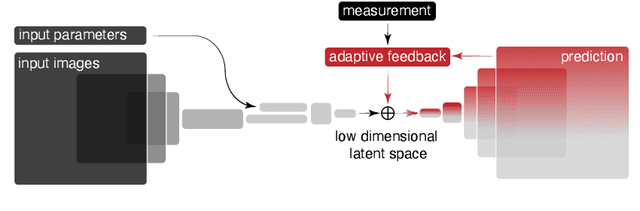
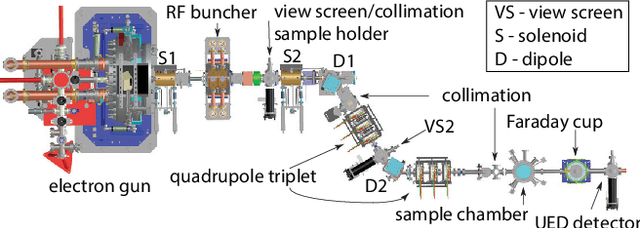
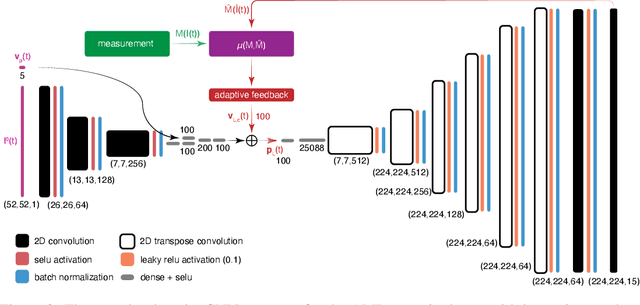
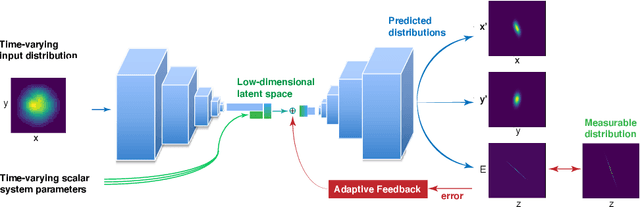
Powerful deep learning tools, such as convolutional neural networks (CNN), are able to learn the input-output relationships of large complicated systems directly from data. Encoder-decoder deep CNNs are able to extract features directly from images, mix them with scalar inputs within a general low-dimensional latent space, and then generate new complex 2D outputs which represent complex physical phenomenon. One important challenge faced by deep learning methods is large non-stationary systems whose characteristics change quickly with time for which re-training is not feasible. In this paper we present a method for adaptive tuning of the low-dimensional latent space of deep encoder-decoder style CNNs based on real-time feedback to quickly compensate for unknown and fast distribution shifts. We demonstrate our approach for predicting the properties of a time-varying charged particle beam in a particle accelerator whose components (accelerating electric fields and focusing magnetic fields) are also quickly changing with time.