 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Predicting Credit Risk for Unsecured Lending: A Machine Learning Approach
Oct 05, 2021

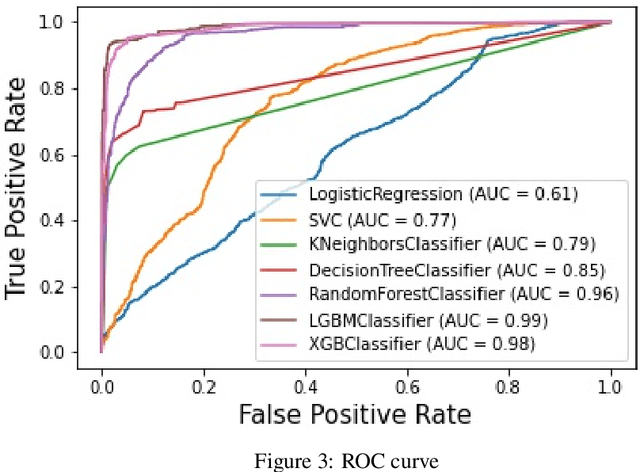
Since the 1990s, there have been significant advances in the technology space and the e-Commerce area, leading to an exponential increase in demand for cashless payment solutions. This has led to increased demand for credit cards, bringing along with it the possibility of higher credit defaults and hence higher delinquency rates, over a period of time. The purpose of this research paper is to build a contemporary credit scoring model to forecast credit defaults for unsecured lending (credit cards), by employing machine learning techniques. As much of the customer payments data available to lenders, for forecasting Credit defaults, is imbalanced (skewed), on account of a limited subset of default instances, this poses a challenge for predictive modelling. In this research, this challenge is addressed by deploying Synthetic Minority Oversampling Technique (SMOTE), a proven technique to iron out such imbalances, from a given dataset. On running the research dataset through seven different machine learning models, the results indicate that the Light Gradient Boosting Machine (LGBM) Classifier model outperforms the other six classification techniques. Thus, our research indicates that the LGBM classifier model is better equipped to deliver higher learning speeds, better efficiencies and manage larger data volumes. We expect that deployment of this model will enable better and timely prediction of credit defaults for decision-makers in commercial lending institutions and banks.
Unsupervised Cross-Modality Domain Adaptation for Segmenting Vestibular Schwannoma and Cochlea with Data Augmentation and Model Ensemble
Sep 24, 2021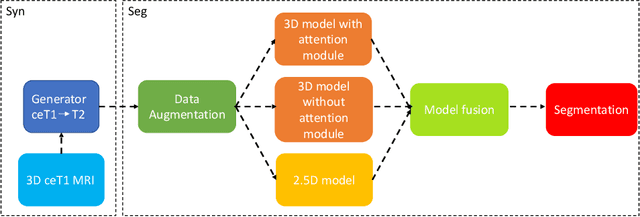
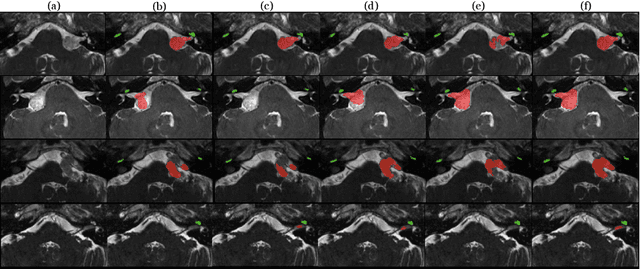
Magnetic resonance images (MRIs) are widely used to quantify vestibular schwannoma and the cochlea. Recently, deep learning methods have shown state-of-the-art performance for segmenting these structures. However, training segmentation models may require manual labels in target domain, which is expensive and time-consuming. To overcome this problem, domain adaptation is an effective way to leverage information from source domain to obtain accurate segmentations without requiring manual labels in target domain. In this paper, we propose an unsupervised learning framework to segment the VS and cochlea. Our framework leverages information from contrast-enhanced T1-weighted (ceT1-w) MRIs and its labels, and produces segmentations for T2-weighted MRIs without any labels in the target domain. We first applied a generator to achieve image-to-image translation. Next, we ensemble outputs from an ensemble of different models to obtain final segmentations. To cope with MRIs from different sites/scanners, we applied various 'online' augmentations during training to better capture the geometric variability and the variability in image appearance and quality. Our method is easy to build and produces promising segmentations, with a mean Dice score of 0.7930 and 0.7432 for VS and cochlea respectively in the validation set.
Analyzing the Impact of COVID-19 on Economy from the Perspective of Users Reviews
Oct 05, 2021
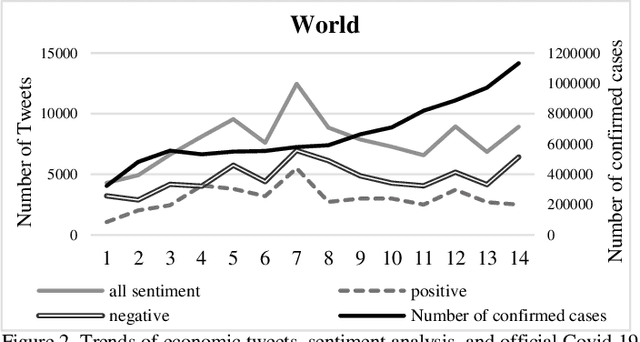

One of the most important incidents in the world in 2020 is the outbreak of the Coronavirus. Users on social networks publish a large number of comments about this event. These comments contain important hidden information of public opinion regarding this pandemic. In this research, a large number of Coronavirus-related tweets are considered and analyzed using natural language processing and information retrieval science. Initially, the location of the tweets is determined using a dictionary prepared through the Geo-Names geographic database, which contains detailed and complete information of places such as city names, streets, and postal codes. Then, using a large dictionary prepared from the terms of economics, related tweets are extracted and sentiments corresponded to tweets are analyzed with the help of the RoBERTa language-based model, which has high accuracy and good performance. Finally, the frequency chart of tweets related to the economy and their sentiment scores (positive and negative tweets) is plotted over time for the entire world and the top 10 economies. From the analysis of the charts, we learn that the reason for publishing economic tweets is not only the increase in the number of people infected with the Coronavirus but also imposed restrictions and lockdowns in countries. The consequences of these restrictions include the loss of millions of jobs and the economic downturn.
OncoPetNet: A Deep Learning based AI system for mitotic figure counting on H&E stained whole slide digital images in a large veterinary diagnostic lab setting
Aug 17, 2021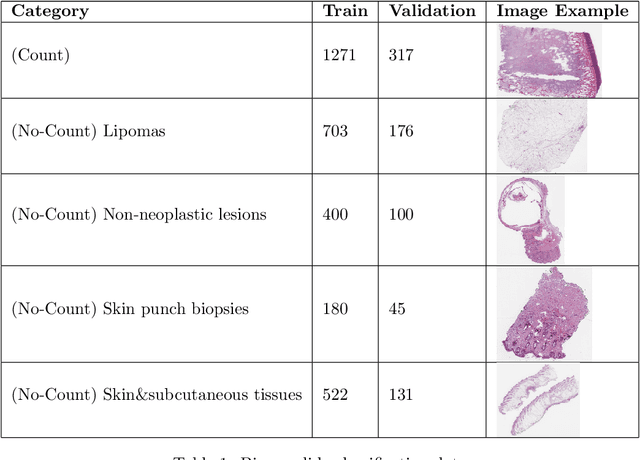


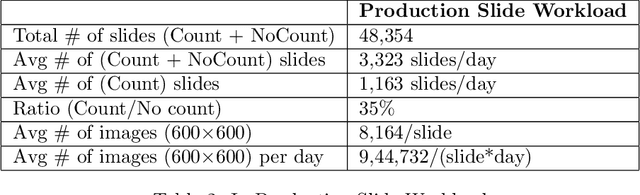
Background: Histopathology is an important modality for the diagnosis and management of many diseases in modern healthcare, and plays a critical role in cancer care. Pathology samples can be large and require multi-site sampling, leading to upwards of 20 slides for a single tumor, and the human-expert tasks of site selection and and quantitative assessment of mitotic figures are time consuming and subjective. Automating these tasks in the setting of a digital pathology service presents significant opportunities to improve workflow efficiency and augment human experts in practice. Approach: Multiple state-of-the-art deep learning techniques for histopathology image classification and mitotic figure detection were used in the development of OncoPetNet. Additionally, model-free approaches were used to increase speed and accuracy. The robust and scalable inference engine leverages Pytorch's performance optimizations as well as specifically developed speed up techniques in inference. Results: The proposed system, demonstrated significantly improved mitotic counting performance for 41 cancer cases across 14 cancer types compared to human expert baselines. In 21.9% of cases use of OncoPetNet led to change in tumor grading compared to human expert evaluation. In deployment, an effective 0.27 min/slide inference was achieved in a high throughput veterinary diagnostic pathology service across 2 centers processing 3,323 digital whole slide images daily. Conclusion: This work represents the first successful automated deployment of deep learning systems for real-time expert-level performance on important histopathology tasks at scale in a high volume clinical practice. The resulting impact outlines important considerations for model development, deployment, clinical decision making, and informs best practices for implementation of deep learning systems in digital histopathology practices.
Real-time and Large-scale Fleet Allocation of Autonomous Taxis: A Case Study in New York Manhattan Island
Sep 06, 2020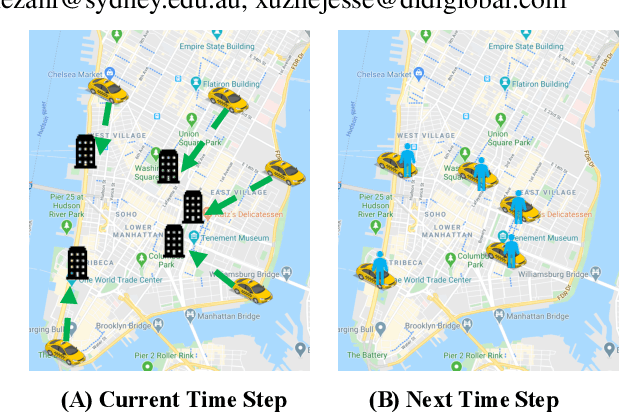

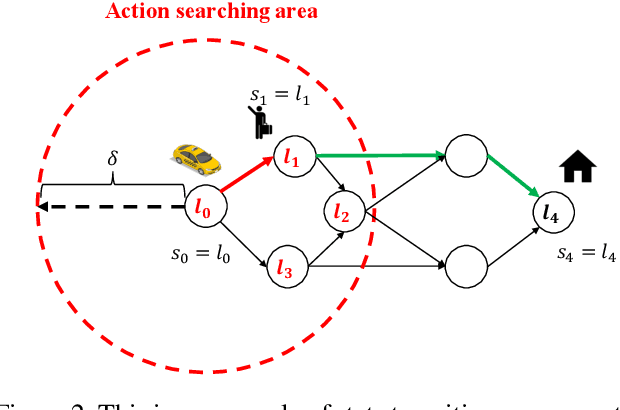
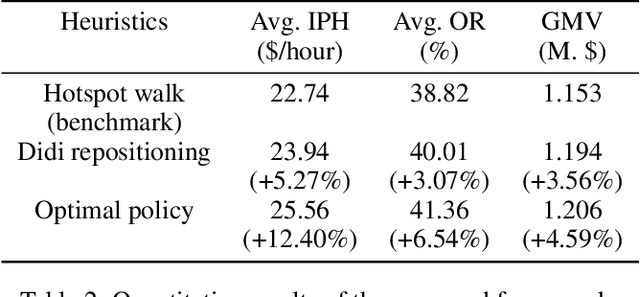
Nowadays, autonomous taxis become a highly promising transportation mode, which helps relieve traffic congestion and avoid road accidents. However, it hinders the wide implementation of this service that traditional models fail to efficiently allocate the available fleet to deal with the imbalance of supply (autonomous taxis) and demand (trips), the poor cooperation of taxis, hardly satisfied resource constraints, and on-line platform's requirements. To figure out such urgent problems from a global and more farsighted view, we employ a Constrained Multi-agent Markov Decision Processes (CMMDP) to model fleet allocation decisions, which can be easily split into sub-problems formulated as a 'Dynamic assignment problem' combining both immediate rewards and future gains. We also leverage a Column Generation algorithm to guarantee the efficiency and optimality in a large scale. Through extensive experiments, the proposed approach not only achieves remarkable improvements over the state-of-the-art benchmarks in terms of the individual's efficiency (arriving at 12.40%, 6.54% rise of income and utilization, respectively) and the platform's profit (reaching 4.59% promotion) but also reveals a time-varying fleet adjustment policy to minimize the operation cost of the platform.
Self-conditioning pre-trained language models
Sep 30, 2021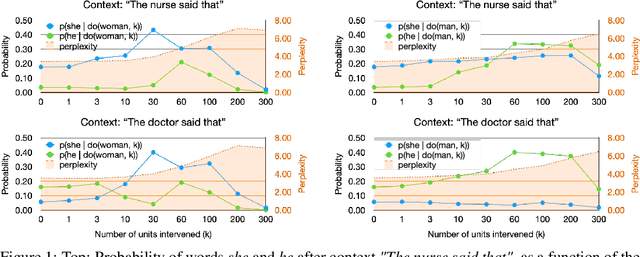
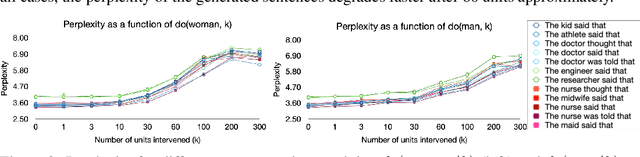
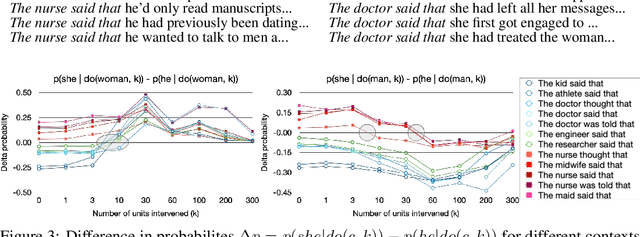
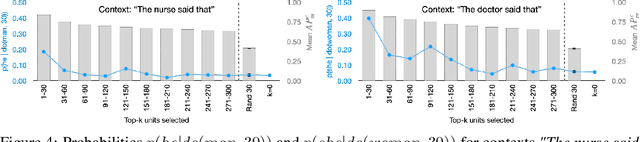
We study the presence of expert units in pre-trained Transformer-based Language Models (TLMs), and how they can be used to condition text generation to contain specific concepts. We define expert units to be neurons that are able to detect a concept in the input with a given average precision. A concept is represented with a set of sentences that either do or do not contain the concept. Leveraging the OneSec dataset, we compile a dataset of 1344 concepts that allows diverse expert units in TLMs to be discovered. Our experiments demonstrate that off-the-shelf pre-trained TLMs can be conditioned on their own knowledge (self-conditioning) to generate text that contains a given concept. To this end, we intervene on the top expert units by fixing their output during inference, and we show experimentally that this is an effective method to condition TLMs. Our method does not require fine-tuning the model or using additional parameters, which allows conditioning large TLM with minimal compute resources. Furthermore, by intervening on a small number of experts in GPT2, we can achieve parity with respect to two concepts at generation time. The specific case of gender bias is explored, and we show that, for given contexts, gender parity is achieved while maintaining the model's perplexity.
Long Short-Term Transformer for Online Action Detection
Jul 07, 2021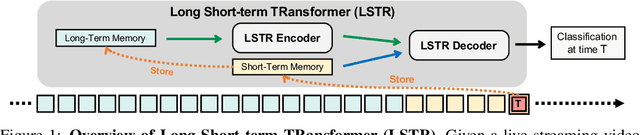
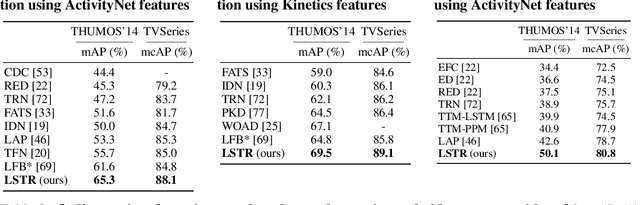
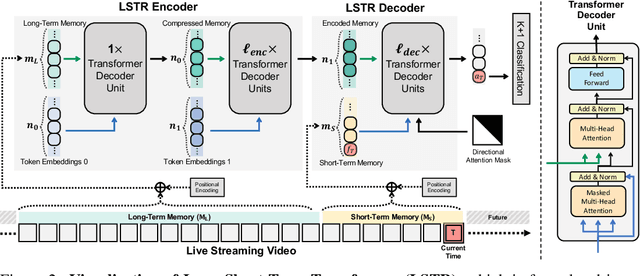
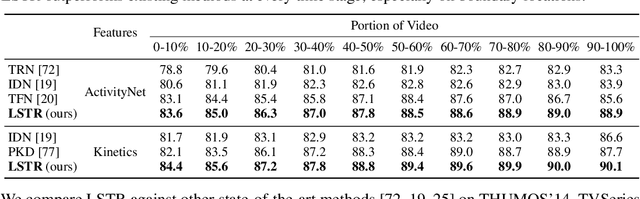
In this paper, we present Long Short-term TRansformer (LSTR), a new temporal modeling algorithm for online action detection, by employing a long- and short-term memories mechanism that is able to model prolonged sequence data. It consists of an LSTR encoder that is capable of dynamically exploiting coarse-scale historical information from an extensively long time window (e.g., 2048 long-range frames of up to 8 minutes), together with an LSTR decoder that focuses on a short time window (e.g., 32 short-range frames of 8 seconds) to model the fine-scale characterization of the ongoing event. Compared to prior work, LSTR provides an effective and efficient method to model long videos with less heuristic algorithm design. LSTR achieves significantly improved results on standard online action detection benchmarks, THUMOS'14, TVSeries, and HACS Segment, over the existing state-of-the-art approaches. Extensive empirical analysis validates the setup of the long- and short-term memories and the design choices of LSTR.
HySPA: Hybrid Span Generation for Scalable Text-to-Graph Extraction
Jun 30, 2021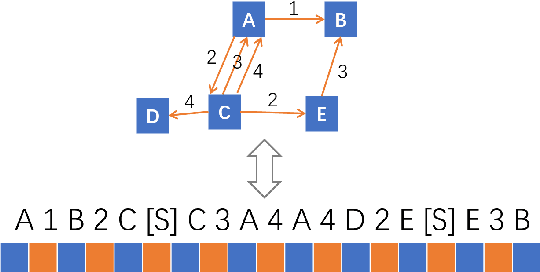

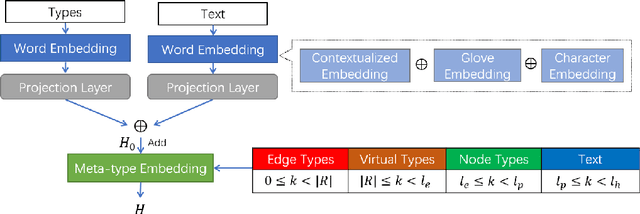
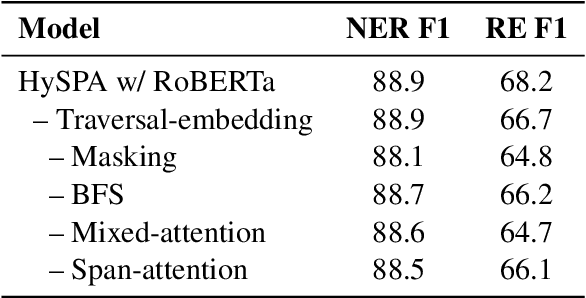
Text-to-Graph extraction aims to automatically extract information graphs consisting of mentions and types from natural language texts. Existing approaches, such as table filling and pairwise scoring, have shown impressive performance on various information extraction tasks, but they are difficult to scale to datasets with longer input texts because of their second-order space/time complexities with respect to the input length. In this work, we propose a Hybrid Span Generator (HySPA) that invertibly maps the information graph to an alternating sequence of nodes and edge types, and directly generates such sequences via a hybrid span decoder which can decode both the spans and the types recurrently in linear time and space complexities. Extensive experiments on the ACE05 dataset show that our approach also significantly outperforms state-of-the-art on the joint entity and relation extraction task.
Intensity-Based Feature Selection for Near Real-Time Damage Diagnosis of Building Structures
Oct 23, 2019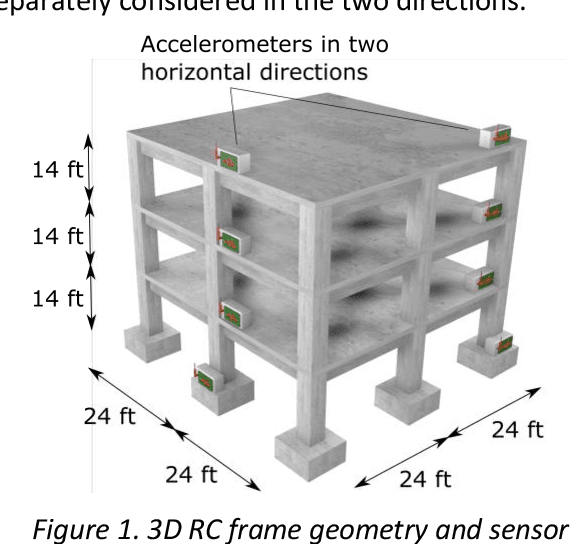
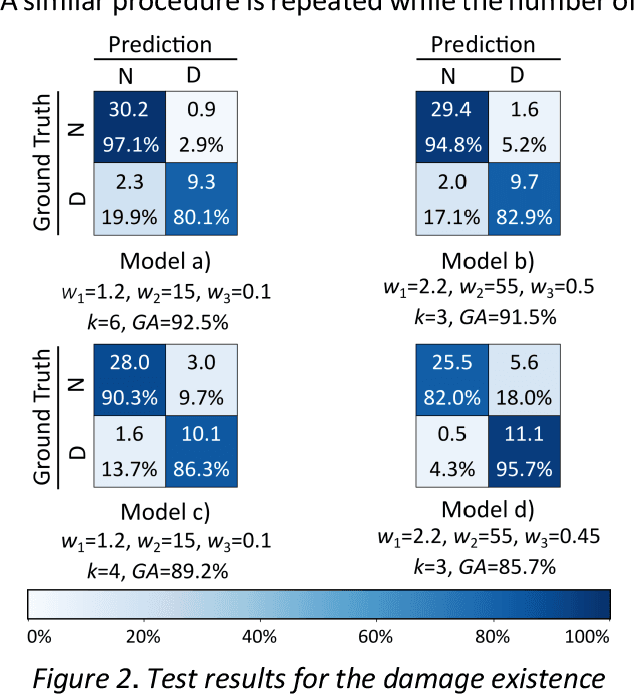
Near real-time damage diagnosis of building structures after extreme events (e.g., earthquakes) is of great importance in structural health monitoring. Unlike conventional methods that are usually time-consuming and require human expertise, pattern recognition algorithms have the potential to interpret sensor recordings as soon as this information is available. This paper proposes a robust framework to build a damage prediction model for building structures. Support vector machines are used to predict the existence as well as the probable location of the damage. The model is designed to consider probabilistic approaches in determining hazard intensity given the existing attenuation models in performance-based earthquake engineering. Performance of the model regarding accurate and safe predictions is enhanced using Bayesian optimization. The proposed framework is evaluated on a reinforced concrete moment frame. Targeting a selected large earthquake scenario, 6,240 nonlinear time history analyses are performed using OpenSees. Simulation results are engineered to extract low-dimensional intensity-based features that can be used as damage indicators. For the given case study, the proposed model achieves a promising accuracy of 83.1% to identify damage location, demonstrating the great potential of model capabilities.
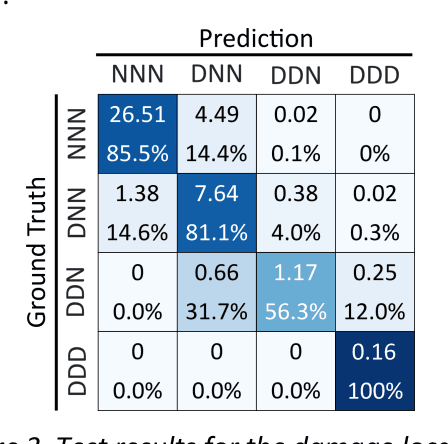
Communication-Efficient Federated Learning with Binary Neural Networks
Oct 05, 2021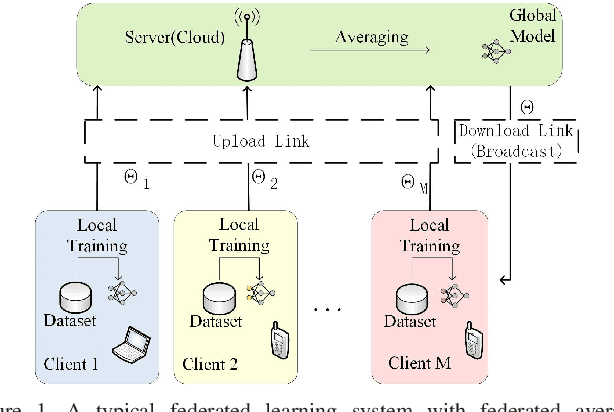
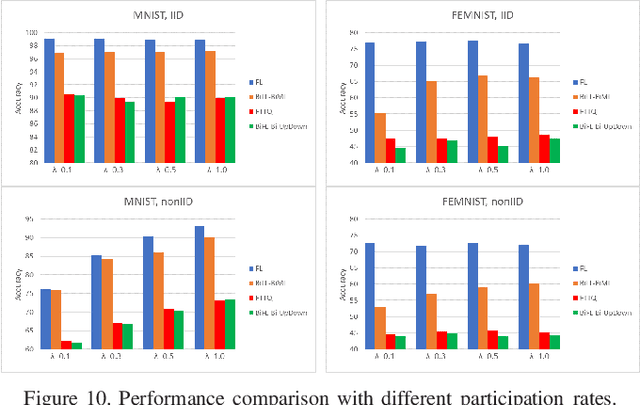
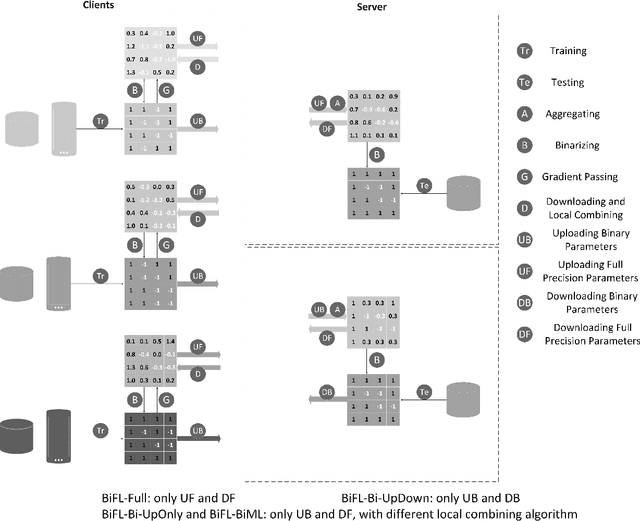

Federated learning (FL) is a privacy-preserving machine learning setting that enables many devices to jointly train a shared global model without the need to reveal their data to a central server. However, FL involves a frequent exchange of the parameters between all the clients and the server that coordinates the training. This introduces extensive communication overhead, which can be a major bottleneck in FL with limited communication links. In this paper, we consider training the binary neural networks (BNN) in the FL setting instead of the typical real-valued neural networks to fulfill the stringent delay and efficiency requirement in wireless edge networks. We introduce a novel FL framework of training BNN, where the clients only upload the binary parameters to the server. We also propose a novel parameter updating scheme based on the Maximum Likelihood (ML) estimation that preserves the performance of the BNN even without the availability of aggregated real-valued auxiliary parameters that are usually needed during the training of the BNN. Moreover, for the first time in the literature, we theoretically derive the conditions under which the training of BNN is converging. { Numerical results show that the proposed FL framework significantly reduces the communication cost compared to the conventional neural networks with typical real-valued parameters, and the performance loss incurred by the binarization can be further compensated by a hybrid method.