 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
OncoPetNet: A Deep Learning based AI system for mitotic figure counting on H&E stained whole slide digital images in a large veterinary diagnostic lab setting
Aug 17, 2021
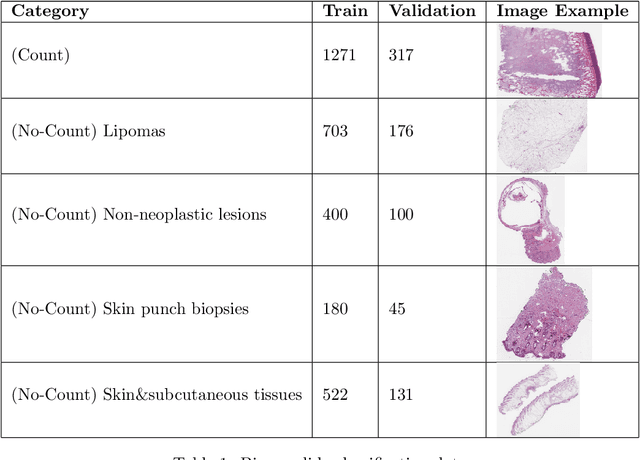


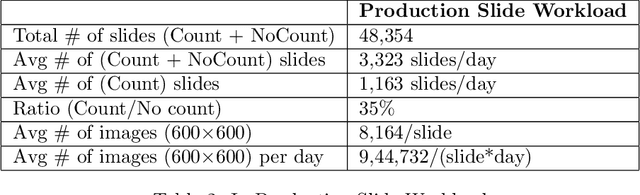
Background: Histopathology is an important modality for the diagnosis and management of many diseases in modern healthcare, and plays a critical role in cancer care. Pathology samples can be large and require multi-site sampling, leading to upwards of 20 slides for a single tumor, and the human-expert tasks of site selection and and quantitative assessment of mitotic figures are time consuming and subjective. Automating these tasks in the setting of a digital pathology service presents significant opportunities to improve workflow efficiency and augment human experts in practice. Approach: Multiple state-of-the-art deep learning techniques for histopathology image classification and mitotic figure detection were used in the development of OncoPetNet. Additionally, model-free approaches were used to increase speed and accuracy. The robust and scalable inference engine leverages Pytorch's performance optimizations as well as specifically developed speed up techniques in inference. Results: The proposed system, demonstrated significantly improved mitotic counting performance for 41 cancer cases across 14 cancer types compared to human expert baselines. In 21.9% of cases use of OncoPetNet led to change in tumor grading compared to human expert evaluation. In deployment, an effective 0.27 min/slide inference was achieved in a high throughput veterinary diagnostic pathology service across 2 centers processing 3,323 digital whole slide images daily. Conclusion: This work represents the first successful automated deployment of deep learning systems for real-time expert-level performance on important histopathology tasks at scale in a high volume clinical practice. The resulting impact outlines important considerations for model development, deployment, clinical decision making, and informs best practices for implementation of deep learning systems in digital histopathology practices.
Neural Network Branch-and-Bound for Neural Network Verification
Jul 27, 2021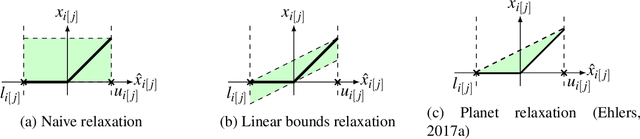

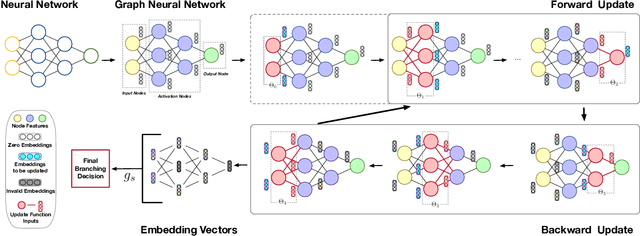

Many available formal verification methods have been shown to be instances of a unified Branch-and-Bound (BaB) formulation. We propose a novel machine learning framework that can be used for designing an effective branching strategy as well as for computing better lower bounds. Specifically, we learn two graph neural networks (GNN) that both directly treat the network we want to verify as a graph input and perform forward-backward passes through the GNN layers. We use one GNN to simulate the strong branching heuristic behaviour and another to compute a feasible dual solution of the convex relaxation, thereby providing a valid lower bound. We provide a new verification dataset that is more challenging than those used in the literature, thereby providing an effective alternative for testing algorithmic improvements for verification. Whilst using just one of the GNNs leads to a reduction in verification time, we get optimal performance when combining the two GNN approaches. Our combined framework achieves a 50\% reduction in both the number of branches and the time required for verification on various convolutional networks when compared to several state-of-the-art verification methods. In addition, we show that our GNN models generalize well to harder properties on larger unseen networks.
Orientation-Aware Planning for Parallel Task Execution of Omni-Directional Mobile Robot
Aug 02, 2021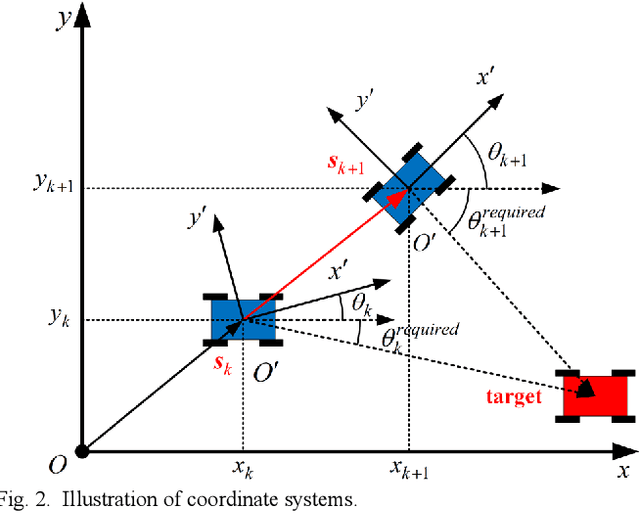
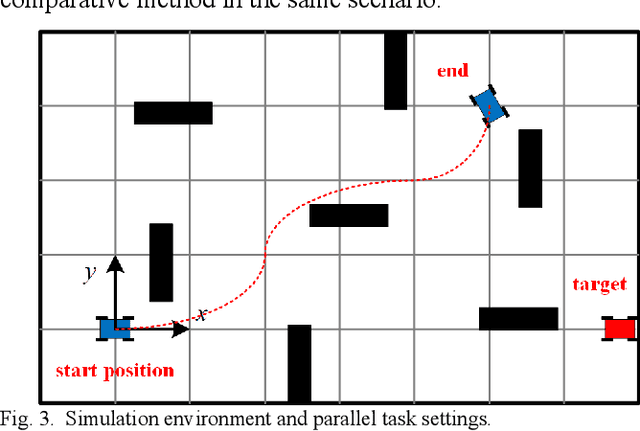
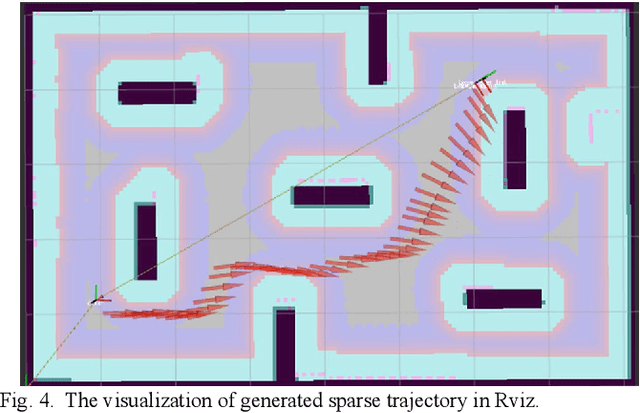
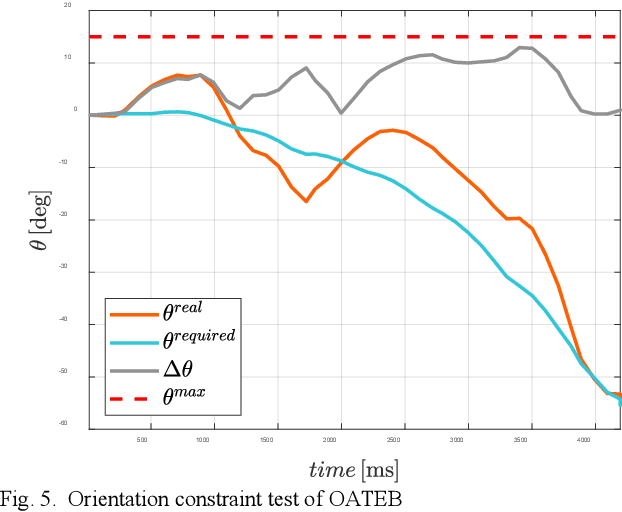
Omni-directional mobile robot (OMR) systems have been very popular in academia and industry for their superb maneuverability and flexibility. Yet their potential has not been fully exploited, where the extra degree of freedom in OMR can potentially enable the robot to carry out extra tasks. For instance, gimbals or sensors on robots may suffer from a limited field of view or be constrained by the inherent mechanical design, which will require the chassis to be orientation-aware and respond in time. To solve this problem and further develop the OMR systems, in this paper, we categorize the tasks related to OMR chassis into orientation transition tasks and position transition tasks, where the two tasks can be carried out at the same time. By integrating the parallel task goals in a single planning problem, we proposed an orientation-aware planning architecture for OMR systems to execute the orientation transition and position transition in a unified and efficient way. A modified trajectory optimization method called orientation-aware timed-elastic-band (OATEB) is introduced to generate the trajectory that satisfies the requirements of both tasks. Experiments in both 2D simulated environments and real scenes are carried out. A four-wheeled OMR is deployed to conduct the real scene experiment and the results demonstrate that the proposed method is capable of simultaneously executing parallel tasks and is applicable to real-life scenarios.
Hypernetworks for Continual Semi-Supervised Learning
Oct 05, 2021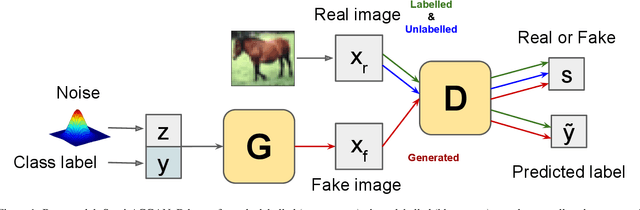


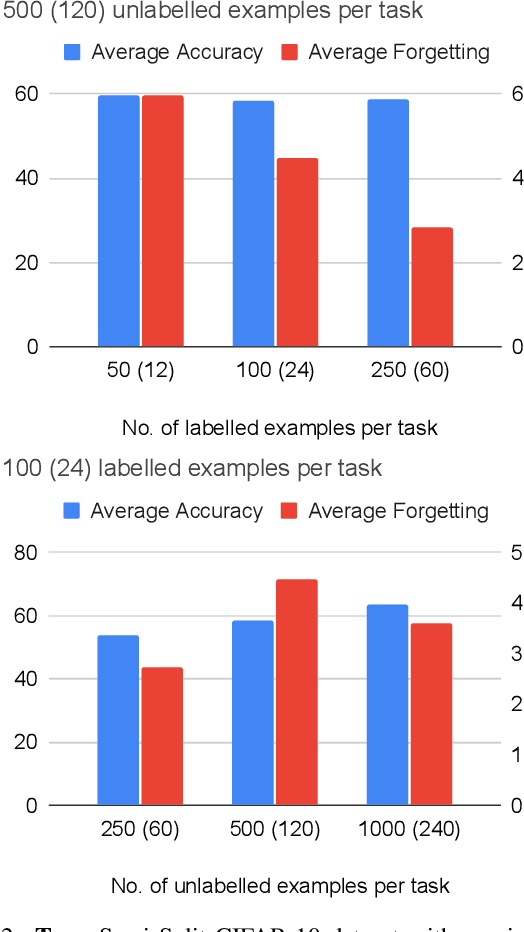
Learning from data sequentially arriving, possibly in a non i.i.d. way, with changing task distribution over time is called continual learning. Much of the work thus far in continual learning focuses on supervised learning and some recent works on unsupervised learning. In many domains, each task contains a mix of labelled (typically very few) and unlabelled (typically plenty) training examples, which necessitates a semi-supervised learning approach. To address this in a continual learning setting, we propose a framework for semi-supervised continual learning called Meta-Consolidation for Continual Semi-Supervised Learning (MCSSL). Our framework has a hypernetwork that learns the meta-distribution that generates the weights of a semi-supervised auxiliary classifier generative adversarial network $(\textit{Semi-ACGAN})$ as the base network. We consolidate the knowledge of sequential tasks in the hypernetwork, and the base network learns the semi-supervised learning task. Further, we present $\textit{Semi-Split CIFAR-10}$, a new benchmark for continual semi-supervised learning, obtained by modifying the $\textit{Split CIFAR-10}$ dataset, in which the tasks with labelled and unlabelled data arrive sequentially. Our proposed model yields significant improvements in the continual semi-supervised learning setting. We compare the performance of several existing continual learning approaches on the proposed continual semi-supervised learning benchmark of the Semi-Split CIFAR-10 dataset.
Learning-based Noise Component Map Estimation for Image Denoising
Sep 24, 2021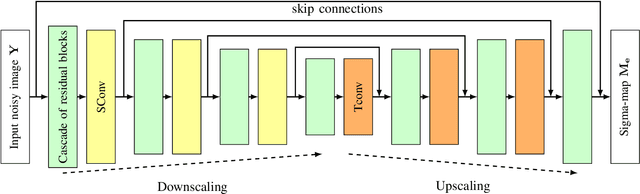
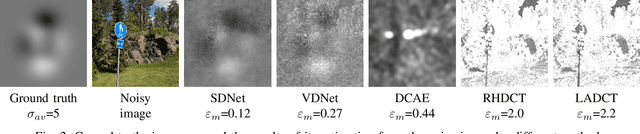
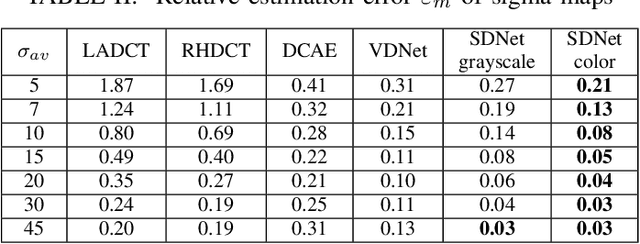
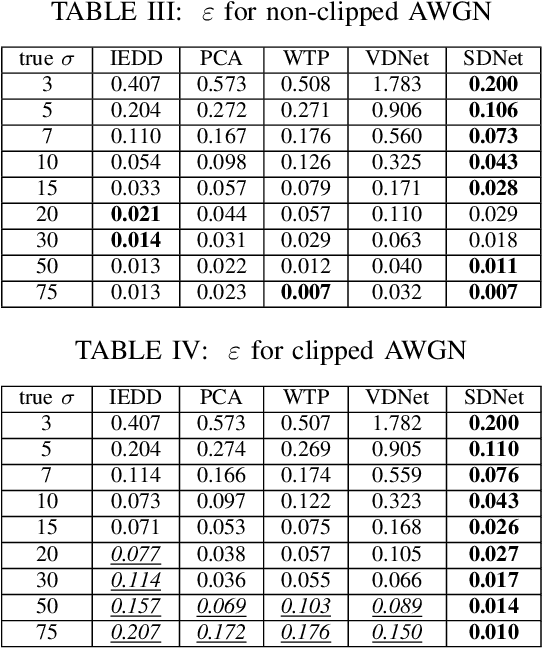
A problem of image denoising when images are corrupted by a non-stationary noise is considered in this paper. Since in practice no a priori information on noise is available, noise statistics should be pre-estimated for image denoising. In this paper, deep convolutional neural network (CNN) based method for estimation of a map of local, patch-wise, standard deviations of noise (so-called sigma-map) is proposed. It achieves the state-of-the-art performance in accuracy of estimation of sigma-map for the case of non-stationary noise, as well as estimation of noise variance for the case of additive white Gaussian noise. Extensive experiments on image denoising using estimated sigma-maps demonstrate that our method outperforms recent CNN-based blind image denoising methods by up to 6 dB in PSNR, as well as other state-of-the-art methods based on sigma-map estimation by up to 0.5 dB, providing same time better usage flexibility. Comparison with the ideal case, when denoising is applied using ground-truth sigma-map, shows that a difference of corresponding PSNR values for most of noise levels is within 0.1-0.2 dB and does not exceeds 0.6 dB.
Deep neural network Based Low-latency Speech Separation with Asymmetric analysis-Synthesis Window Pair
Jun 22, 2021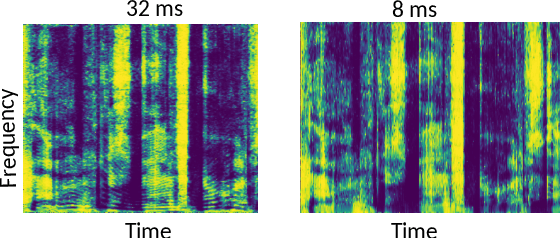
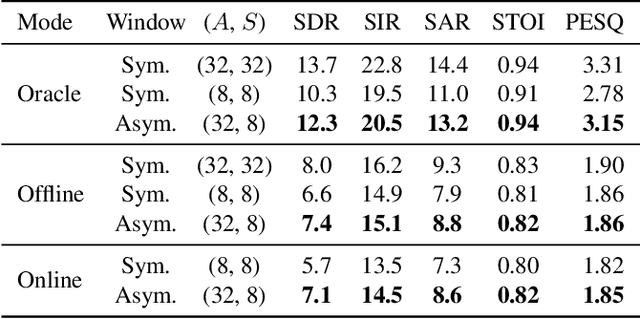
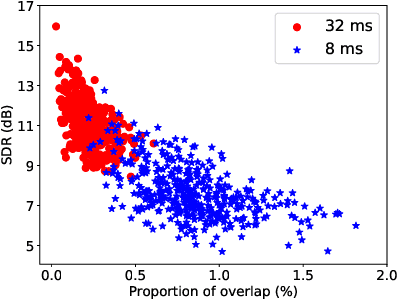
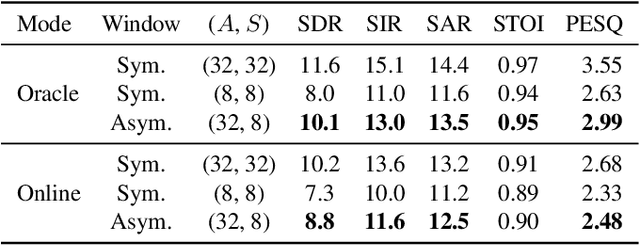
Time-frequency masking or spectrum prediction computed via short symmetric windows are commonly used in low-latency deep neural network (DNN) based source separation. In this paper, we propose the usage of an asymmetric analysis-synthesis window pair which allows for training with targets with better frequency resolution, while retaining the low-latency during inference suitable for real-time speech enhancement or assisted hearing applications. In order to assess our approach across various model types and datasets, we evaluate it with both speaker-independent deep clustering (DC) model and a speaker-dependent mask inference (MI) model. We report an improvement in separation performance of up to 1.5 dB in terms of source-to-distortion ratio (SDR) while maintaining an algorithmic latency of 8 ms.
Rethinking Temporal Fusion for Video-based Person Re-identification on Semantic and Time Aspect
Nov 28, 2019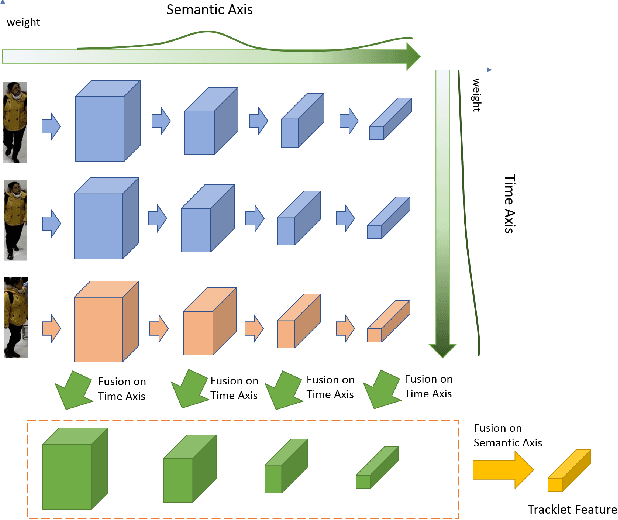
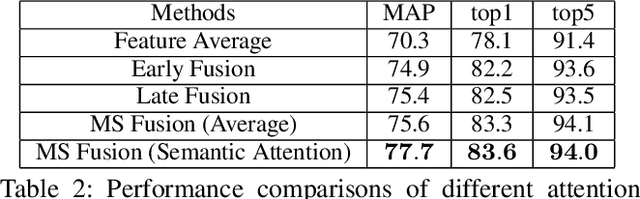
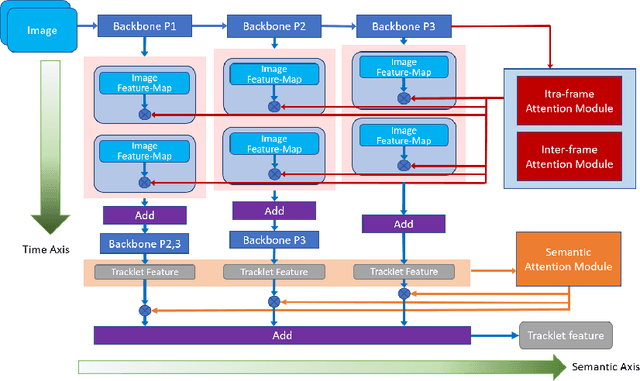
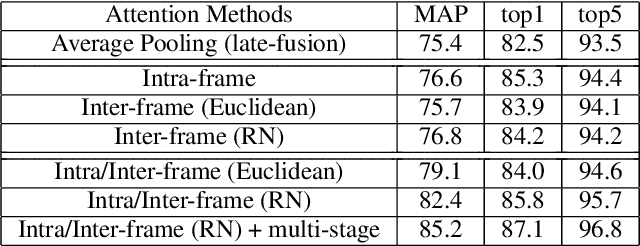
Recently, the research interest of person re-identification (ReID) has gradually turned to video-based methods, which acquire a person representation by aggregating frame features of an entire video. However, existing video-based ReID methods do not consider the semantic difference brought by the outputs of different network stages, which potentially compromises the information richness of the person features. Furthermore, traditional methods ignore important relationship among frames, which causes information redundancy in fusion along the time axis. To address these issues, we propose a novel general temporal fusion framework to aggregate frame features on both semantic aspect and time aspect. As for the semantic aspect, a multi-stage fusion network is explored to fuse richer frame features at multiple semantic levels, which can effectively reduce the information loss caused by the traditional single-stage fusion. While, for the time axis, the existing intra-frame attention method is improved by adding a novel inter-frame attention module, which effectively reduces the information redundancy in temporal fusion by taking the relationship among frames into consideration. The experimental results show that our approach can effectively improve the video-based re-identification accuracy, achieving the state-of-the-art performance.
A dynamic programming algorithm for informative measurements and near-optimal path-planning
Sep 24, 2021

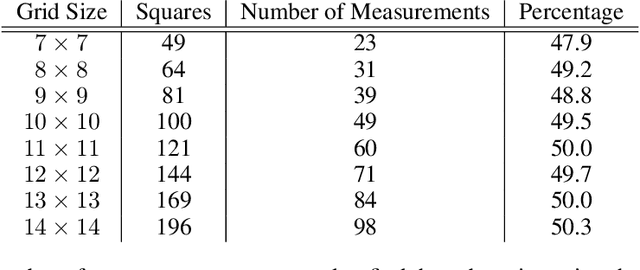
An informative measurement is the most efficient way to gain information about an unknown state. We give a first-principles derivation of a general-purpose dynamic programming algorithm that returns a sequence of informative measurements by sequentially maximizing the entropy of possible measurement outcomes. This algorithm can be used by an autonomous agent or robot to decide where best to measure next, planning a path corresponding to an optimal sequence of informative measurements. This algorithm is applicable to states and controls that are continuous or discrete, and agent dynamics that is either stochastic or deterministic; including Markov decision processes. Recent results from approximate dynamic programming and reinforcement learning, including on-line approximations such as rollout and Monte Carlo tree search, allow an agent or robot to solve the measurement task in real-time. The resulting near-optimal solutions include non-myopic paths and measurement sequences that can generally outperform, sometimes substantially, commonly-used greedy heuristics such as maximizing the entropy of each measurement outcome. This is demonstrated for a global search problem, where on-line planning with an extended local search is found to reduce the number of measurements in the search by half.
Overprotective Training Environments Fall Short at Testing Time: Let Models Contribute to Their Own Training
Mar 30, 2021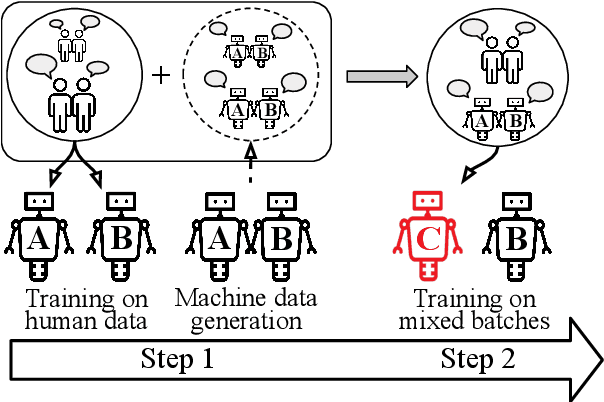
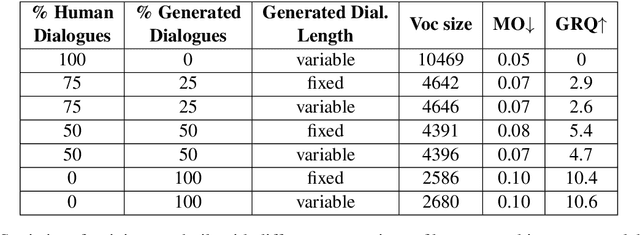

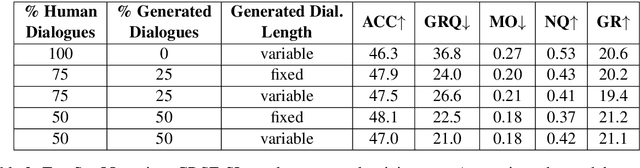
Despite important progress, conversational systems often generate dialogues that sound unnatural to humans. We conjecture that the reason lies in their different training and testing conditions: agents are trained in a controlled "lab" setting but tested in the "wild". During training, they learn to generate an utterance given the human dialogue history. On the other hand, during testing, they must interact with each other, and hence deal with noisy data. We propose to fill this gap by training the model with mixed batches containing both samples of human and machine-generated dialogues. We assess the validity of the proposed method on GuessWhat?!, a visual referential game.
Online Metro Origin-Destination Prediction via Heterogeneous Information Aggregation
Aug 02, 2021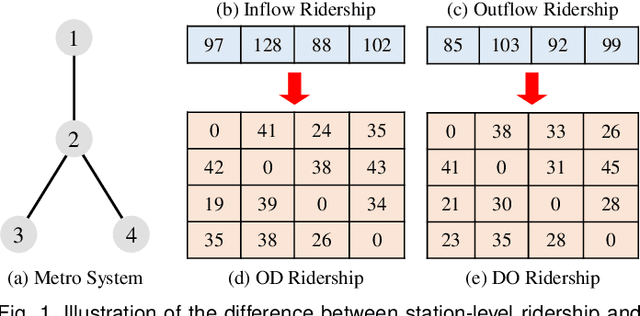
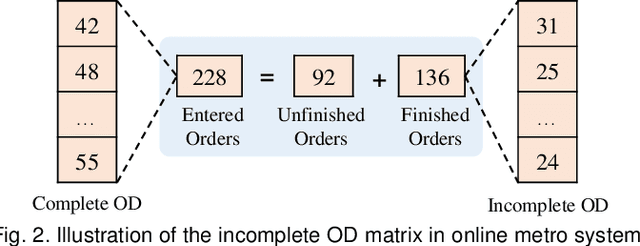
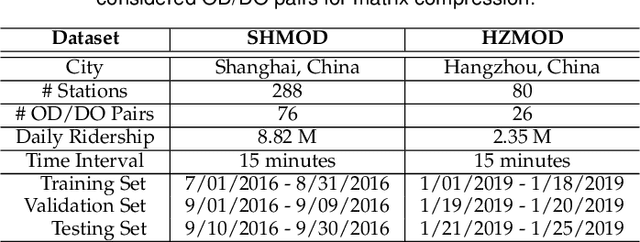
Metro origin-destination prediction is a crucial yet challenging time-series analysis task in intelligent transportation systems, which aims to accurately forecast two specific types of cross-station ridership, i.e., Origin-Destination (OD) one and Destination-Origin (DO) one. However, complete OD matrices of previous time intervals can not be obtained immediately in online metro systems, and conventional methods only used limited information to forecast the future OD and DO ridership separately. In this work, we proposed a novel neural network module termed Heterogeneous Information Aggregation Machine (HIAM), which fully exploits heterogeneous information of historical data (e.g., incomplete OD matrices, unfinished order vectors, and DO matrices) to jointly learn the evolutionary patterns of OD and DO ridership. Specifically, an OD modeling branch estimates the potential destinations of unfinished orders explicitly to complement the information of incomplete OD matrices, while a DO modeling branch takes DO matrices as input to capture the spatial-temporal distribution of DO ridership. Moreover, a Dual Information Transformer is introduced to propagate the mutual information among OD features and DO features for modeling the OD-DO causality and correlation. Based on the proposed HIAM, we develop a unified Seq2Seq network to forecast the future OD and DO ridership simultaneously. Extensive experiments conducted on two large-scale benchmarks demonstrate the effectiveness of our method for online metro origin-destination prediction.