 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-Time Subpixel Fast Bilateral Stereo
Aug 15, 2018
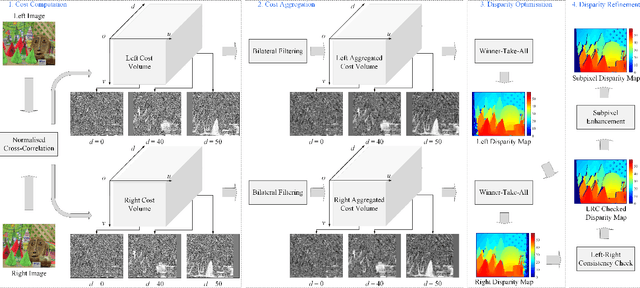
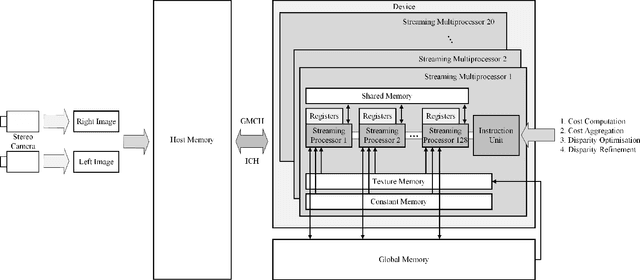
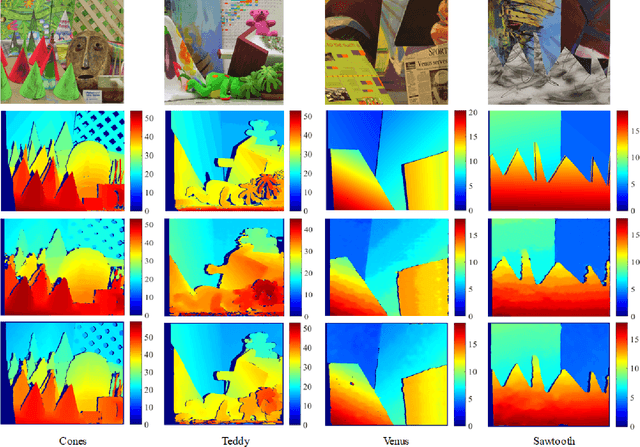
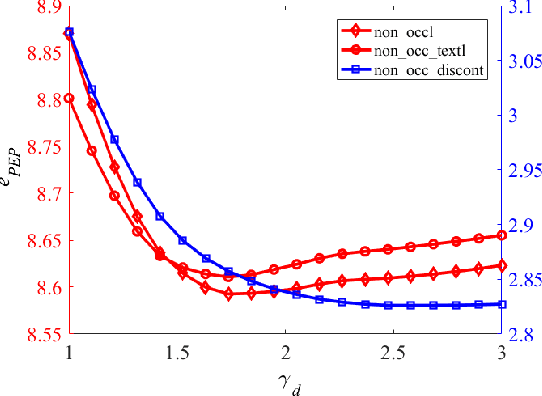
Stereo vision technique has been widely used in robotic systems to acquire 3-D information. In recent years, many researchers have applied bilateral filtering in stereo vision to adaptively aggregate the matching costs. This has greatly improved the accuracy of the estimated disparity maps. However, the process of filtering the whole cost volume is very time consuming and therefore the researchers have to resort to some powerful hardware for the real-time purpose. This paper presents the implementation of fast bilateral stereo on a state-of-the-art GPU. By highly exploiting the parallel computing architecture of the GPU, the fast bilateral stereo performs in real time when processing the Middlebury stereo datasets.
DeepVecFont: Synthesizing High-quality Vector Fonts via Dual-modality Learning
Oct 13, 2021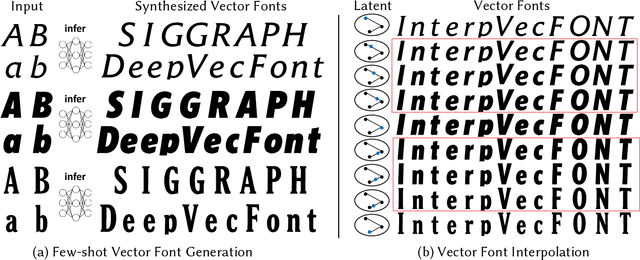
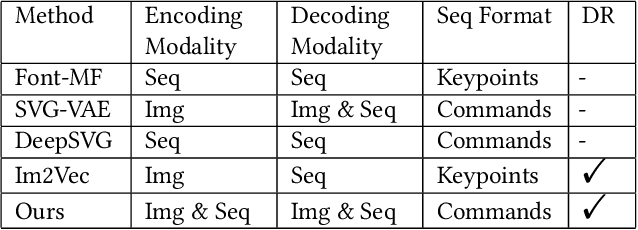
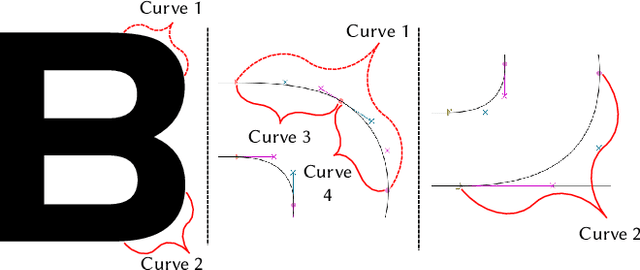
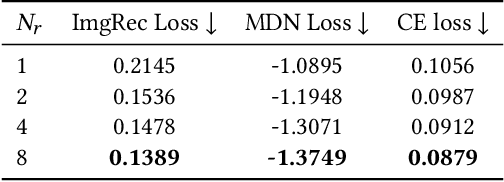
Automatic font generation based on deep learning has aroused a lot of interest in the last decade. However, only a few recently-reported approaches are capable of directly generating vector glyphs and their results are still far from satisfactory. In this paper, we propose a novel method, DeepVecFont, to effectively resolve this problem. Using our method, for the first time, visually-pleasing vector glyphs whose quality and compactness are both comparable to human-designed ones can be automatically generated. The key idea of our DeepVecFont is to adopt the techniques of image synthesis, sequence modeling and differentiable rasterization to exhaustively exploit the dual-modality information (i.e., raster images and vector outlines) of vector fonts. The highlights of this paper are threefold. First, we design a dual-modality learning strategy which utilizes both image-aspect and sequence-aspect features of fonts to synthesize vector glyphs. Second, we provide a new generative paradigm to handle unstructured data (e.g., vector glyphs) by randomly sampling plausible synthesis results to get the optimal one which is further refined under the guidance of generated structured data (e.g., glyph images). Finally, qualitative and quantitative experiments conducted on a publicly-available dataset demonstrate that our method obtains high-quality synthesis results in the applications of vector font generation and interpolation, significantly outperforming the state of the art.
A Framework for Learning Assessment through Multimodal Analysis of Reading Behaviour and Language Comprehension
Oct 22, 2021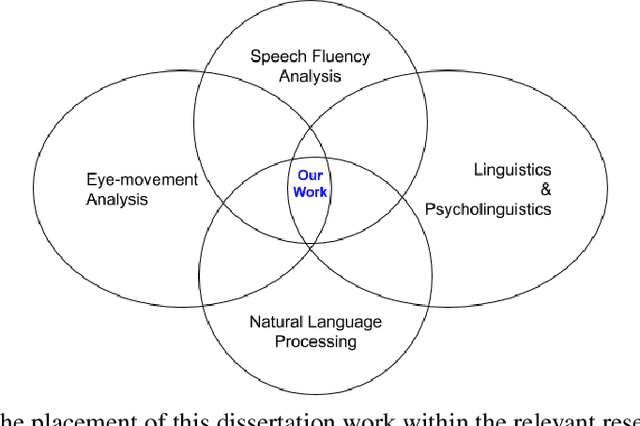

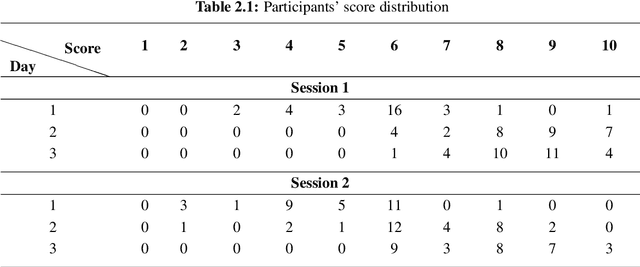
Reading comprehension, which has been defined as gaining an understanding of written text through a process of translating grapheme into meaning, is an important academic skill. Other language learning skills - writing, speaking and listening, all are connected to reading comprehension. There have been several measures proposed by researchers to automate the assessment of comprehension skills for second language (L2) learners, especially English as Second Language (ESL) and English as Foreign Language (EFL) learners. However, current methods measure particular skills without analysing the impact of reading frequency on comprehension skills. In this dissertation, we show how different skills could be measured and scored automatically. We also demonstrate, using example experiments on multiple forms of learners' responses, how frequent reading practices could impact on the variables of multimodal skills (reading pattern, writing, and oral fluency). This thesis comprises of five studies. The first and second studies are based on eye-tracking data collected from EFL readers in repeated reading (RR) sessions. The third and fourth studies are to evaluate free-text summary written by EFL readers in repeated reading sessions. The fifth and last study, described in the sixth chapter of the thesis, is to evaluate recorded oral summaries recited by EFL readers in repeated reading sessions. In a nutshell, through this dissertation, we show that multimodal skills of learners could be assessed to measure their comprehension skills as well as to measure the effect of repeated readings on these skills in the course of time, by finding significant features and by applying machine learning techniques with a combination of statistical models such as LMER.
Challenges in Procedural Multimodal Machine Comprehension:A Novel Way To Benchmark
Oct 22, 2021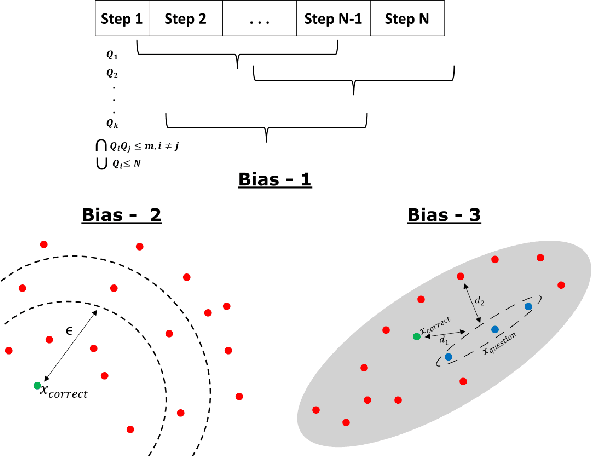
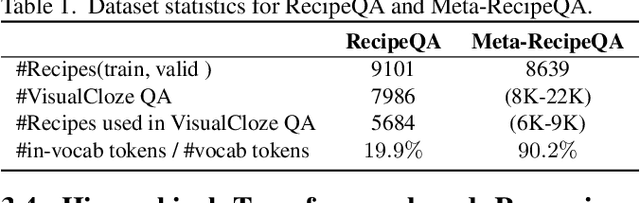
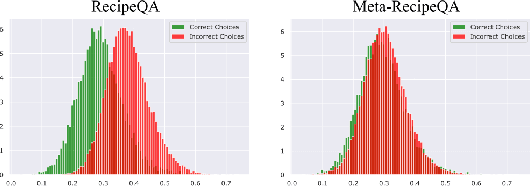
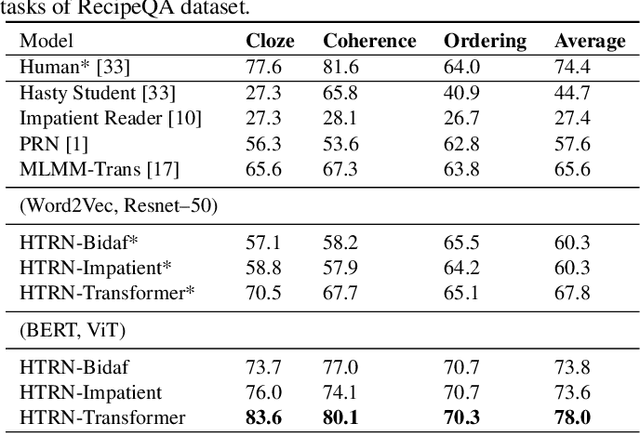
We focus on Multimodal Machine Reading Comprehension (M3C) where a model is expected to answer questions based on given passage (or context), and the context and the questions can be in different modalities. Previous works such as RecipeQA have proposed datasets and cloze-style tasks for evaluation. However, we identify three critical biases stemming from the question-answer generation process and memorization capabilities of large deep models. These biases makes it easier for a model to overfit by relying on spurious correlations or naive data patterns. We propose a systematic framework to address these biases through three Control-Knobs that enable us to generate a test bed of datasets of progressive difficulty levels. We believe that our benchmark (referred to as Meta-RecipeQA) will provide, for the first time, a fine grained estimate of a model's generalization capabilities. We also propose a general M3C model that is used to realize several prior SOTA models and motivate a novel hierarchical transformer based reasoning network (HTRN). We perform a detailed evaluation of these models with different language and visual features on our benchmark. We observe a consistent improvement with HTRN over SOTA (~18% in Visual Cloze task and ~13% in average over all the tasks). We also observe a drop in performance across all the models when testing on RecipeQA and proposed Meta-RecipeQA (e.g. 83.6% versus 67.1% for HTRN), which shows that the proposed dataset is relatively less biased. We conclude by highlighting the impact of the control knobs with some quantitative results.
Self-supervised Multi-scale Consistency for Weakly Supervised Segmentation Learning
Aug 26, 2021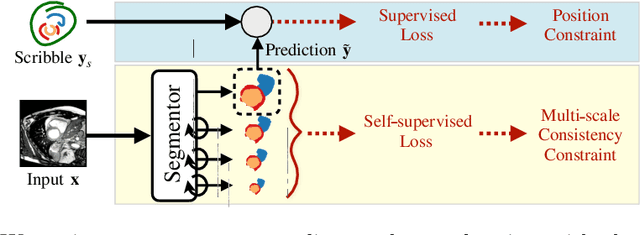
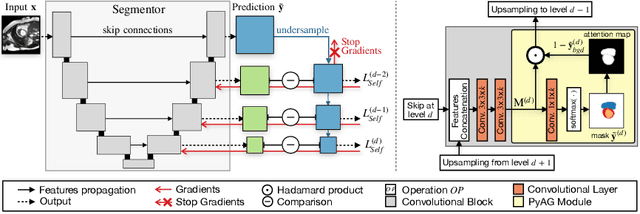
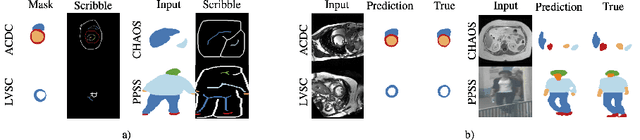
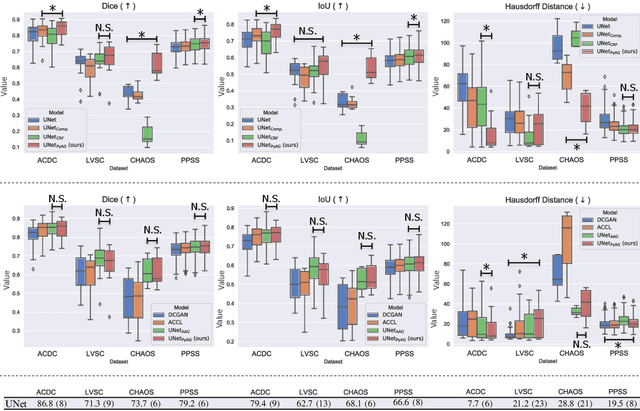
Collecting large-scale medical datasets with fine-grained annotations is time-consuming and requires experts. For this reason, weakly supervised learning aims at optimising machine learning models using weaker forms of annotations, such as scribbles, which are easier and faster to collect. Unfortunately, training with weak labels is challenging and needs regularisation. Herein, we introduce a novel self-supervised multi-scale consistency loss, which, coupled with an attention mechanism, encourages the segmentor to learn multi-scale relationships between objects and improves performance. We show state-of-the-art performance on several medical and non-medical datasets. The code used for the experiments is available at https://vios-s.github.io/multiscale-pyag.
Evolving Space-Time Neural Architectures for Videos
Nov 26, 2018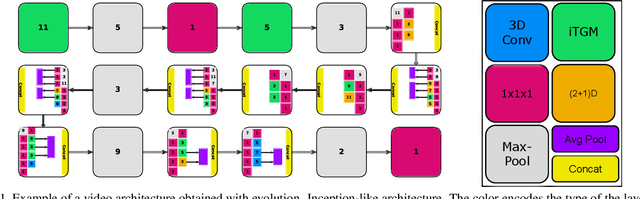
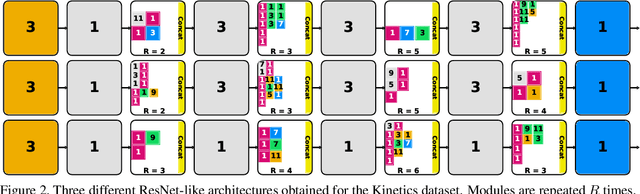
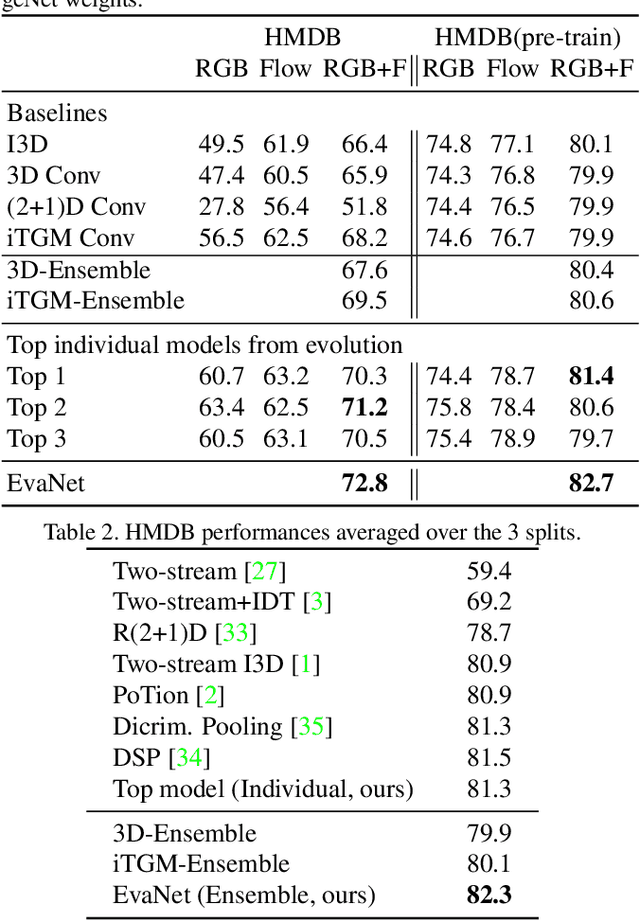
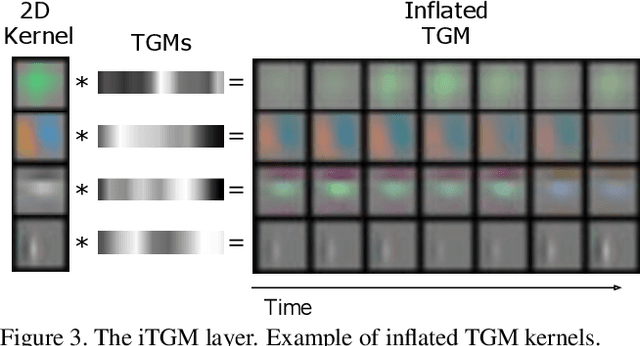
In this paper, we present a new method for evolving video CNN models to find architectures that more optimally captures rich spatio-temporal information in videos. Previous work, taking advantage of 3D convolutional layers, obtained promising results by manually designing CNN architectures for videos. We here develop an evolutionary algorithm that automatically explores models with different types and combinations of space-time convolutional layers to jointly capture various spatial and temporal aspects of video representations. We further propose a new key component in video model evolution, the iTGM layer, which more efficiently utilizes its parameters to allow learning of space-time interactions over longer time horizons. The experiments confirm the advantages of our video CNN architecture evolution, with results outperforming previous state-of-the-art models. Our algorithm discovers new and interesting video architecture structures.
Spending Money Wisely: Online Electronic Coupon Allocation based on Real-Time User Intent Detection
Aug 23, 2020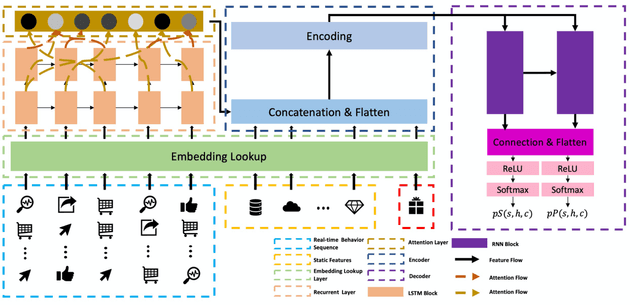
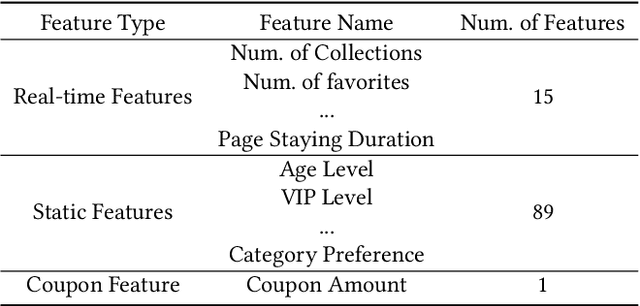
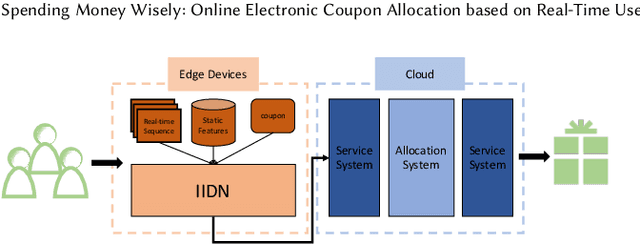
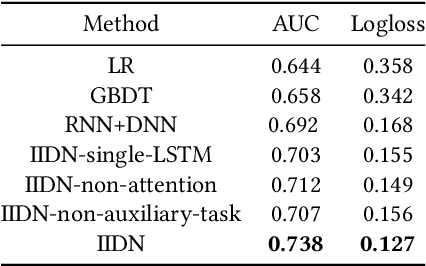
Online electronic coupon (e-coupon) is becoming a primary tool for e-commerce platforms to attract users to place orders. E-coupons are the digital equivalent of traditional paper coupons which provide customers with discounts or gifts. One of the fundamental problems related is how to deliver e-coupons with minimal cost while users' willingness to place an order is maximized. We call this problem the coupon allocation problem. This is a non-trivial problem since the number of regular users on a mature e-platform often reaches hundreds of millions and the types of e-coupons to be allocated are often multiple. The policy space is extremely large and the online allocation has to satisfy a budget constraint. Besides, one can never observe the responses of one user under different policies which increases the uncertainty of the policy making process. Previous work fails to deal with these challenges. In this paper, we decompose the coupon allocation task into two subtasks: the user intent detection task and the allocation task. Accordingly, we propose a two-stage solution: at the first stage (detection stage), we put forward a novel Instantaneous Intent Detection Network (IIDN) which takes the user-coupon features as input and predicts user real-time intents; at the second stage (allocation stage), we model the allocation problem as a Multiple-Choice Knapsack Problem (MCKP) and provide a computational efficient allocation method using the intents predicted at the detection stage. We conduct extensive online and offline experiments and the results show the superiority of our proposed framework, which has brought great profits to the platform and continues to function online.
Run-Time Efficient RNN Compression for Inference on Edge Devices
Jun 18, 2019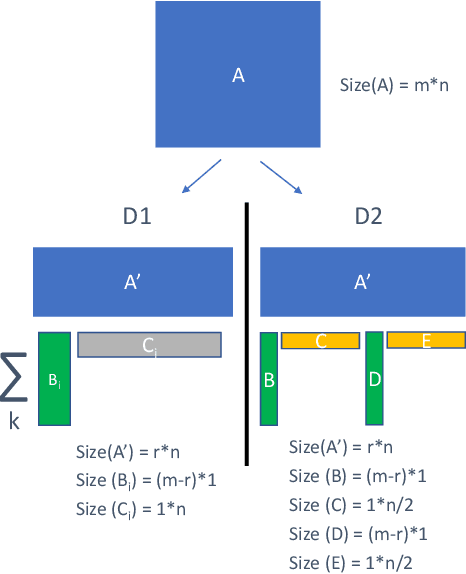
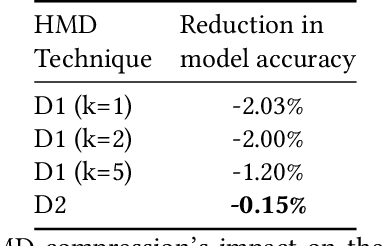
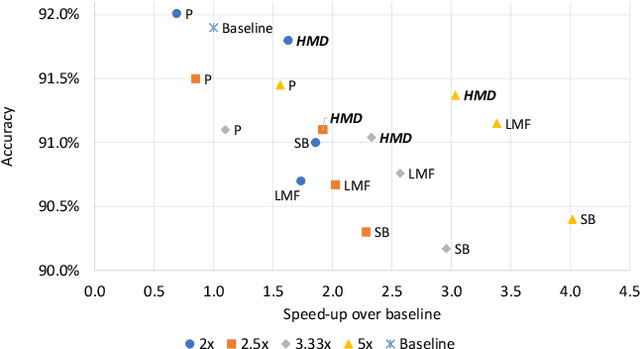
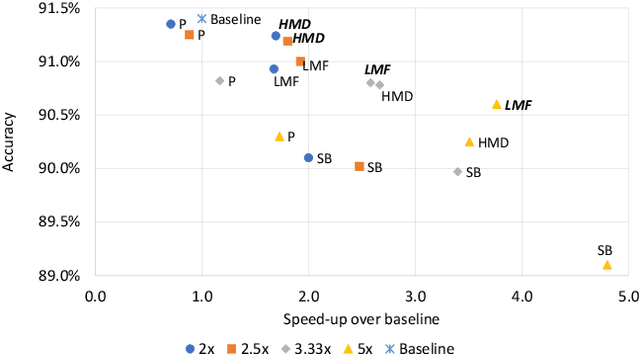
Recurrent neural networks can be large and compute-intensive, yet many applications that benefit from RNNs run on small devices with very limited compute and storage capabilities while still having run-time constraints. As a result, there is a need for compression techniques that can achieve significant compression without negatively impacting inference run-time and task accuracy. This paper explores a new compressed RNN cell implementation called Hybrid Matrix Decomposition (HMD) that achieves this dual objective. This scheme divides the weight matrix into two parts - an unconstrained upper half and a lower half composed of rank-1 blocks. This results in output features where the upper sub-vector has "richer" features while the lower-sub vector has "constrained" features". HMD can compress RNNs by a factor of 2-4x while having a faster run-time than pruning and retaining more model accuracy than matrix factorization. We evaluate this technique on 3 benchmarks.
Semi-Autoregressive Image Captioning
Oct 13, 2021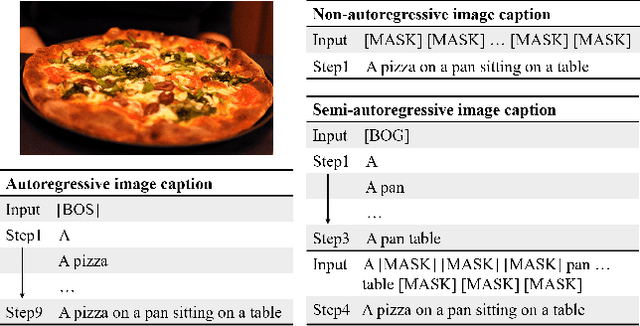
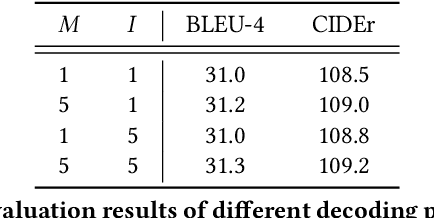
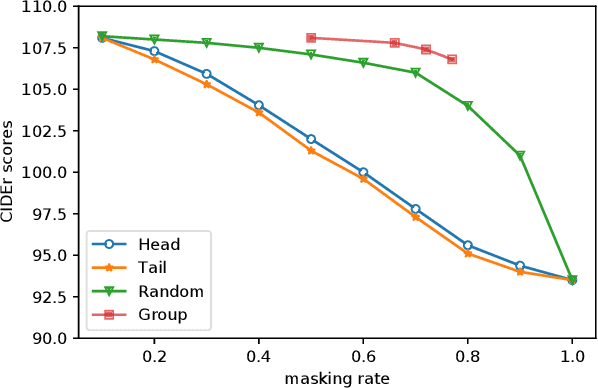
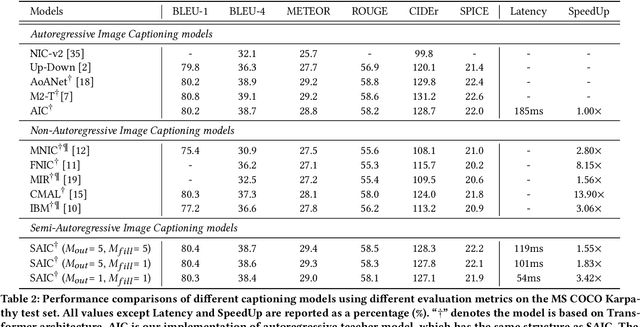
Current state-of-the-art approaches for image captioning typically adopt an autoregressive manner, i.e., generating descriptions word by word, which suffers from slow decoding issue and becomes a bottleneck in real-time applications. Non-autoregressive image captioning with continuous iterative refinement, which eliminates the sequential dependence in a sentence generation, can achieve comparable performance to the autoregressive counterparts with a considerable acceleration. Nevertheless, based on a well-designed experiment, we empirically proved that iteration times can be effectively reduced when providing sufficient prior knowledge for the language decoder. Towards that end, we propose a novel two-stage framework, referred to as Semi-Autoregressive Image Captioning (SAIC), to make a better trade-off between performance and speed. The proposed SAIC model maintains autoregressive property in global but relieves it in local. Specifically, SAIC model first jumpily generates an intermittent sequence in an autoregressive manner, that is, it predicts the first word in every word group in order. Then, with the help of the partially deterministic prior information and image features, SAIC model non-autoregressively fills all the skipped words with one iteration. Experimental results on the MS COCO benchmark demonstrate that our SAIC model outperforms the preceding non-autoregressive image captioning models while obtaining a competitive inference speedup. Code is available at https://github.com/feizc/SAIC.
Towards Continual Knowledge Learning of Language Models
Oct 08, 2021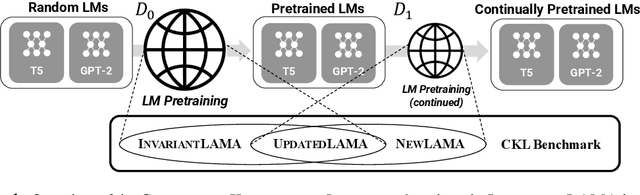

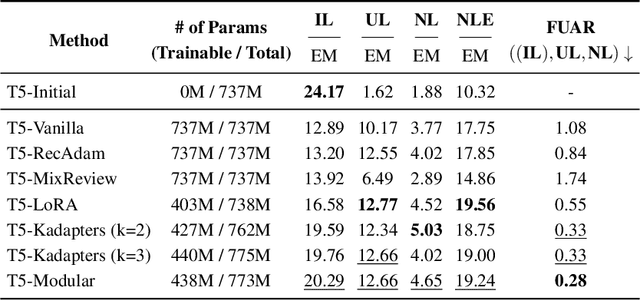
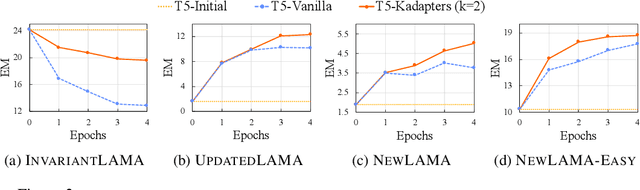
Large Language Models (LMs) are known to encode world knowledge in their parameters as they pretrain on a vast amount of web corpus, which is often utilized for performing knowledge-dependent downstream tasks such as question answering, fact-checking, and open dialogue. In real-world scenarios, the world knowledge stored in the LMs can quickly become outdated as the world changes, but it is non-trivial to avoid catastrophic forgetting and reliably acquire new knowledge while preserving invariant knowledge. To push the community towards better maintenance of ever-changing LMs, we formulate a new continual learning (CL) problem called Continual Knowledge Learning (CKL). We construct a new benchmark and metric to quantify the retention of time-invariant world knowledge, the update of outdated knowledge, and the acquisition of new knowledge. We adopt applicable recent methods from literature to create several strong baselines. Through extensive experiments, we find that CKL exhibits unique challenges that are not addressed in previous CL setups, where parameter expansion is necessary to reliably retain and learn knowledge simultaneously. By highlighting the critical causes of knowledge forgetting, we show that CKL is a challenging and important problem that helps us better understand and train ever-changing LMs.