 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Artificial Intelligence Hybrid Deep Learning Model for Groundwater Level Prediction Using MLP-ADAM
Jul 29, 2021
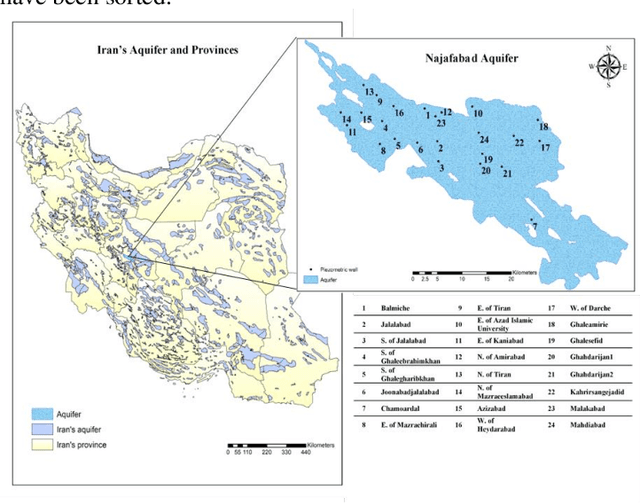
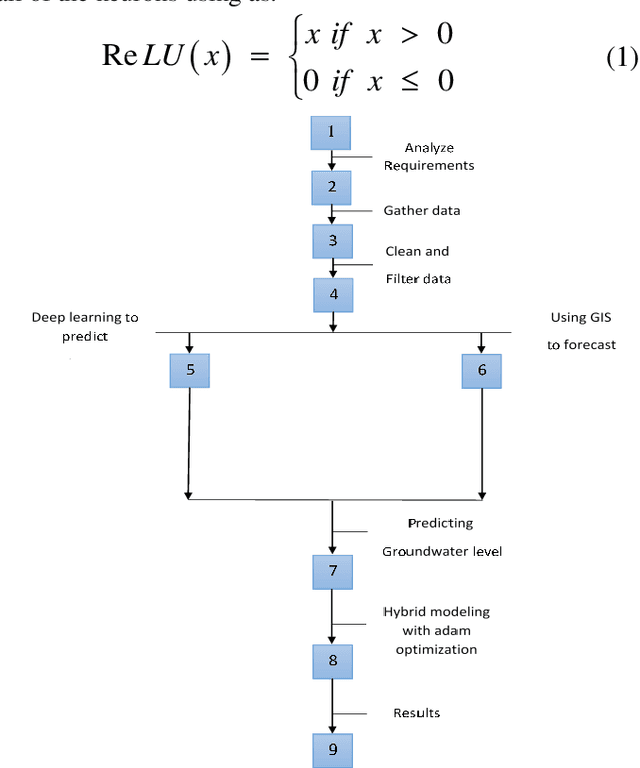
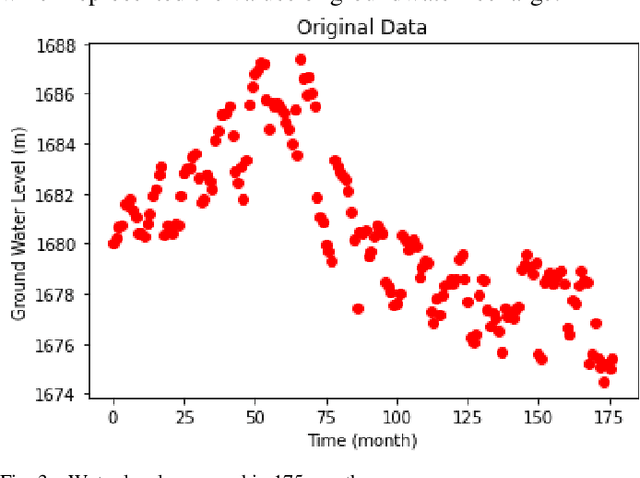
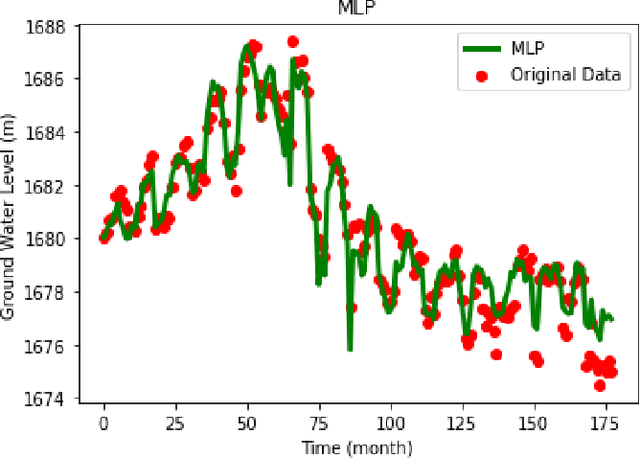
Groundwater is the largest storage of freshwater resources, which serves as the major inventory for most of the human consumption through agriculture, industrial, and domestic water supply. In the fields of hydrological, some researchers applied a neural network to forecast rainfall intensity in space-time and introduced the advantages of neural networks compared to numerical models. Then, many researches have been conducted applying data-driven models. Some of them extended an Artificial Neural Networks (ANNs) model to forecast groundwater level in semi-confined glacial sand and gravel aquifer under variable state, pumping extraction and climate conditions with significant accuracy. In this paper, a multi-layer perceptron is applied to simulate groundwater level. The adaptive moment estimation optimization algorithm is also used to this matter. The root mean squared error, mean absolute error, mean squared error and the coefficient of determination ( ) are used to evaluate the accuracy of the simulated groundwater level. Total value of and RMSE are 0.9458 and 0.7313 respectively which are obtained from the model output. Results indicate that deep learning algorithms can demonstrate a high accuracy prediction. Although the optimization of parameters is insignificant in numbers, but due to the value of time in modelling setup, it is highly recommended to apply an optimization algorithm in modelling.
No-Press Diplomacy from Scratch
Oct 06, 2021


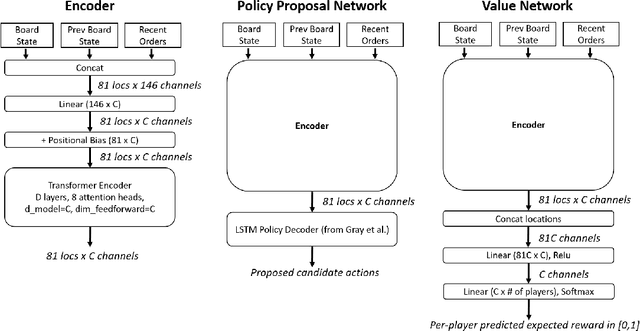
Prior AI successes in complex games have largely focused on settings with at most hundreds of actions at each decision point. In contrast, Diplomacy is a game with more than 10^20 possible actions per turn. Previous attempts to address games with large branching factors, such as Diplomacy, StarCraft, and Dota, used human data to bootstrap the policy or used handcrafted reward shaping. In this paper, we describe an algorithm for action exploration and equilibrium approximation in games with combinatorial action spaces. This algorithm simultaneously performs value iteration while learning a policy proposal network. A double oracle step is used to explore additional actions to add to the policy proposals. At each state, the target state value and policy for the model training are computed via an equilibrium search procedure. Using this algorithm, we train an agent, DORA, completely from scratch for a popular two-player variant of Diplomacy and show that it achieves superhuman performance. Additionally, we extend our methods to full-scale no-press Diplomacy and for the first time train an agent from scratch with no human data. We present evidence that this agent plays a strategy that is incompatible with human-data bootstrapped agents. This presents the first strong evidence of multiple equilibria in Diplomacy and suggests that self play alone may be insufficient for achieving superhuman performance in Diplomacy.
Automatic Identification of the End-Diastolic and End-Systolic Cardiac Frames from Invasive Coronary Angiography Videos
Oct 06, 2021
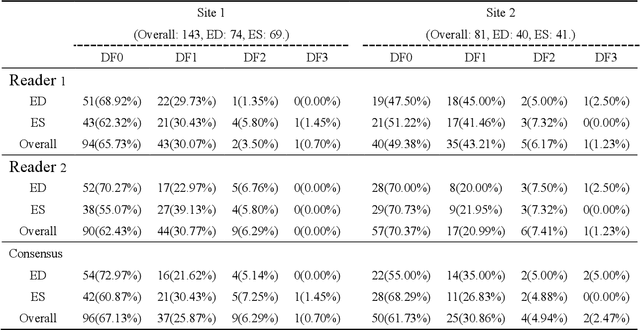
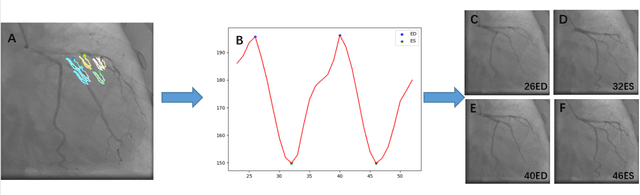
Automatic identification of proper image frames at the end-diastolic (ED) and end-systolic (ES) frames during the review of invasive coronary angiograms (ICA) is important to assess blood flow during a cardiac cycle, reconstruct the 3D arterial anatomy from bi-planar views, and generate the complementary fusion map with myocardial images. The current identification method primarily relies on visual interpretation, making it not only time-consuming but also less reproducible. In this paper, we propose a new method to automatically identify angiographic image frames associated with the ED and ES cardiac phases by using the trajectories of key vessel points (i.e. landmarks). More specifically, a detection algorithm is first used to detect the key points of coronary arteries, and then an optical flow method is employed to track the trajectories of the selected key points. The ED and ES frames are identified based on all these trajectories. Our method was tested with 62 ICA videos from two separate medical centers (22 and 9 patients in sites 1 and 2, respectively). Comparing consensus interpretations by two human expert readers, excellent agreement was achieved by the proposed algorithm: the agreement rates within a one-frame range were 92.99% and 92.73% for the automatic identification of the ED and ES image frames, respectively. In conclusion, the proposed automated method showed great potential for being an integral part of automated ICA image analysis.
An Efficient UAV-based Artificial Intelligence Framework for Real-Time Visual Tasks
Apr 13, 2020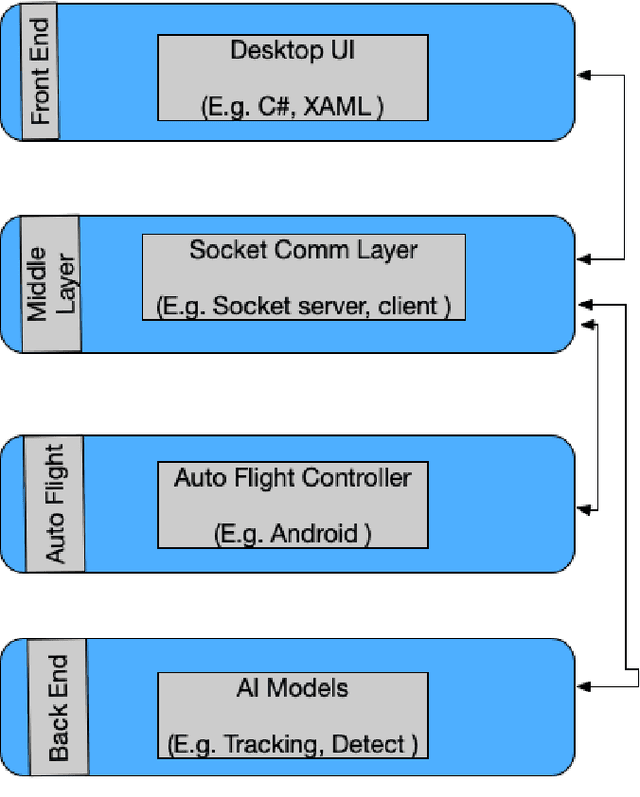
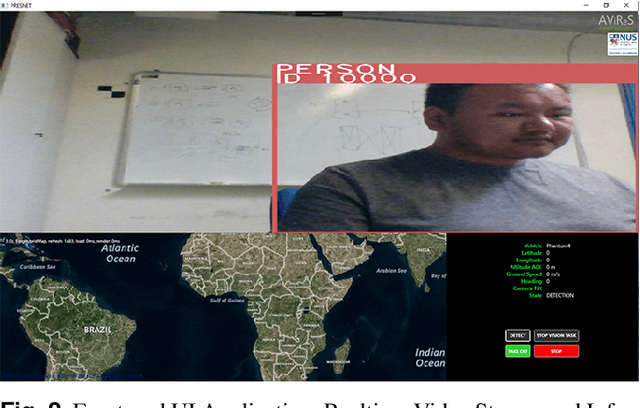
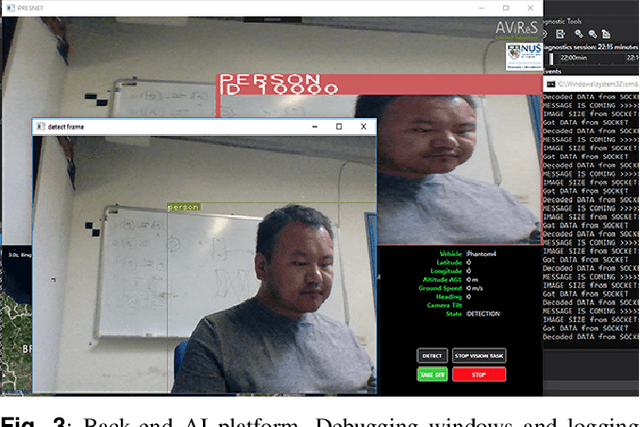
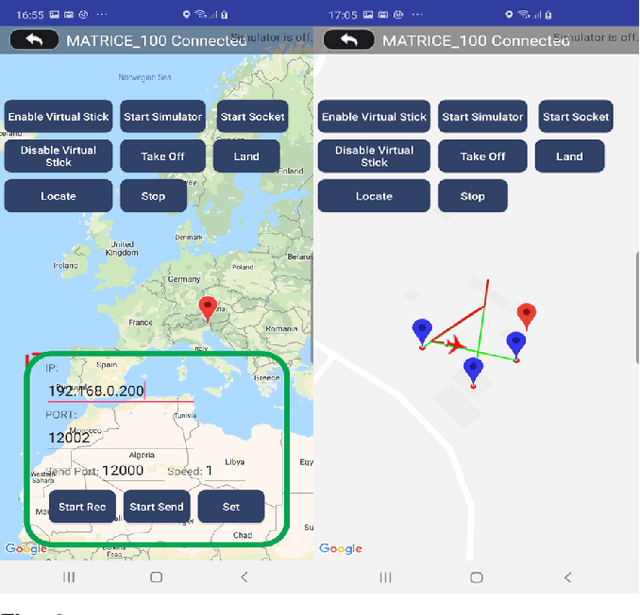
Modern Unmanned Aerial Vehicles equipped with state of the art artificial intelligence (AI) technologies are opening to a wide plethora of novel and interesting applications. While this field received a strong impact from the recent AI breakthroughs, most of the provided solutions either entirely rely on commercial software or provide a weak integration interface which denies the development of additional techniques. This leads us to propose a novel and efficient framework for the UAV-AI joint technology. Intelligent UAV systems encounter complex challenges to be tackled without human control. One of these complex challenges is to be able to carry out computer vision tasks in real-time use cases. In this paper we focus on this challenge and introduce a multi-layer AI (MLAI) framework to allow easy integration of ad-hoc visual-based AI applications. To show its features and its advantages, we implemented and evaluated different modern visual-based deep learning models for object detection, target tracking and target handover.
Grassmannian Constellation Design for Noncoherent MIMO Systems Using Autoencoders
Sep 01, 2021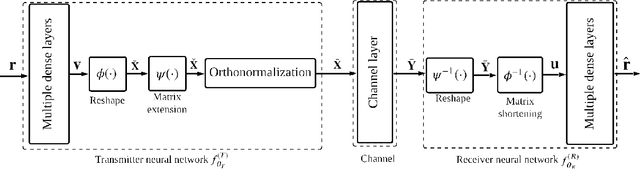
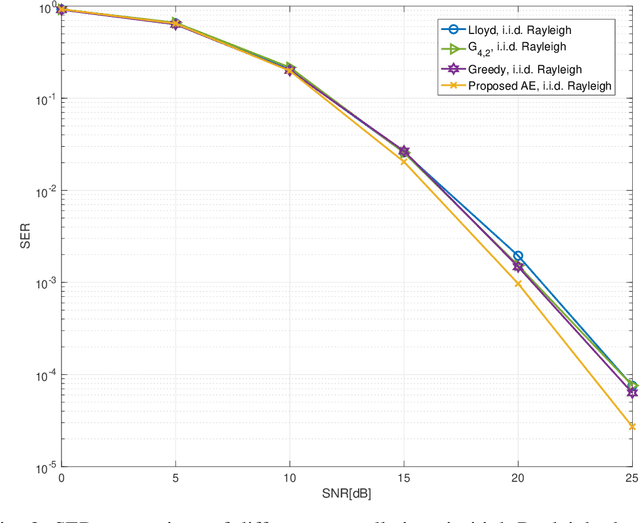
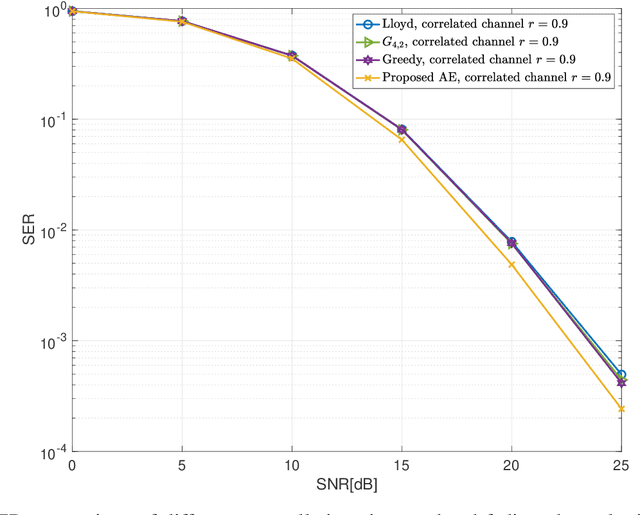
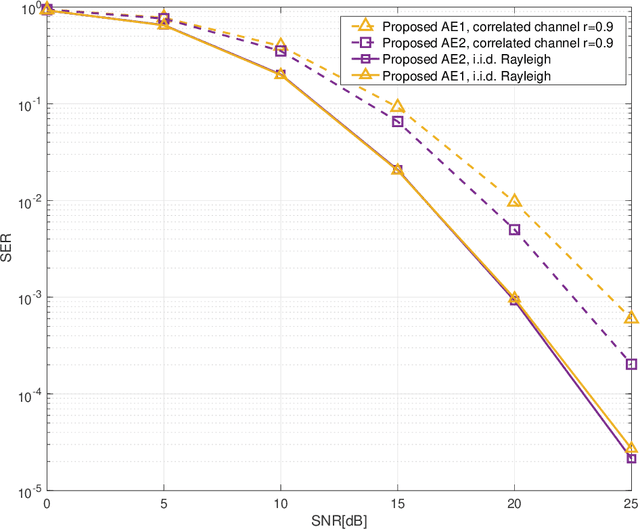
In this letter, we propose an autoencoder (AE) for designing Grassmannian constellations in noncoherent (NC) multiple-input multiple-output (MIMO) systems. To guarantee the properties of Grassmannian constellations, the proposed AE constructs the transmitted symbols following an unitary space-time modulation. It penalizes the difference between input and output symbols in terms of cross entropy during the training, which is regarded as a generic optimization method. The constellations learned by the proposed AE have substantial symbol error rate (SER) performance gains compared to the non-Grassmannian constellations and conventionally constructed Grassmannian constellations in high SNR regime. The resulting Grassmannian constellation of the proposed AE achieves higher diversity than the non-Grassmannian constellation in i.i.d. Rayleigh channels. Moreover, the proposed approach can be adaptive to different channel statistics by training with corresponding channel realizations.
Stochastic Transformer Networks with Linear Competing Units: Application to end-to-end SL Translation
Oct 01, 2021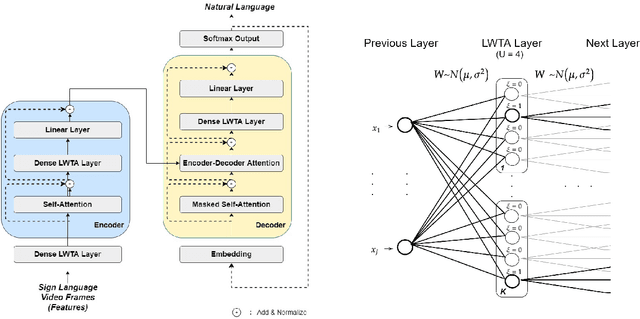


Automating sign language translation (SLT) is a challenging real world application. Despite its societal importance, though, research progress in the field remains rather poor. Crucially, existing methods that yield viable performance necessitate the availability of laborious to obtain gloss sequence groundtruth. In this paper, we attenuate this need, by introducing an end-to-end SLT model that does not entail explicit use of glosses; the model only needs text groundtruth. This is in stark contrast to existing end-to-end models that use gloss sequence groundtruth, either in the form of a modality that is recognized at an intermediate model stage, or in the form of a parallel output process, jointly trained with the SLT model. Our approach constitutes a Transformer network with a novel type of layers that combines: (i) local winner-takes-all (LWTA) layers with stochastic winner sampling, instead of conventional ReLU layers, (ii) stochastic weights with posterior distributions estimated via variational inference, and (iii) a weight compression technique at inference time that exploits estimated posterior variance to perform massive, almost lossless compression. We demonstrate that our approach can reach the currently best reported BLEU-4 score on the PHOENIX 2014T benchmark, but without making use of glosses for model training, and with a memory footprint reduced by more than 70%.
HUMAN4D: A Human-Centric Multimodal Dataset for Motions and Immersive Media
Oct 19, 2021

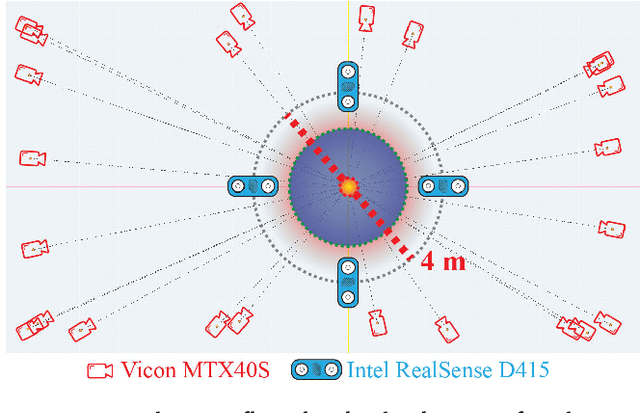
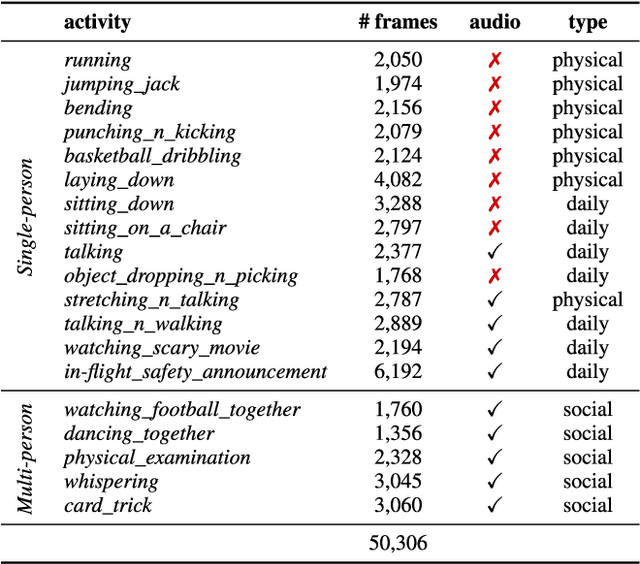
We introduce HUMAN4D, a large and multimodal 4D dataset that contains a variety of human activities simultaneously captured by a professional marker-based MoCap, a volumetric capture and an audio recording system. By capturing 2 female and $2$ male professional actors performing various full-body movements and expressions, HUMAN4D provides a diverse set of motions and poses encountered as part of single- and multi-person daily, physical and social activities (jumping, dancing, etc.), along with multi-RGBD (mRGBD), volumetric and audio data. Despite the existence of multi-view color datasets captured with the use of hardware (HW) synchronization, to the best of our knowledge, HUMAN4D is the first and only public resource that provides volumetric depth maps with high synchronization precision due to the use of intra- and inter-sensor HW-SYNC. Moreover, a spatio-temporally aligned scanned and rigged 3D character complements HUMAN4D to enable joint research on time-varying and high-quality dynamic meshes. We provide evaluation baselines by benchmarking HUMAN4D with state-of-the-art human pose estimation and 3D compression methods. For the former, we apply 2D and 3D pose estimation algorithms both on single- and multi-view data cues. For the latter, we benchmark open-source 3D codecs on volumetric data respecting online volumetric video encoding and steady bit-rates. Furthermore, qualitative and quantitative visual comparison between mesh-based volumetric data reconstructed in different qualities showcases the available options with respect to 4D representations. HUMAN4D is introduced to the computer vision and graphics research communities to enable joint research on spatio-temporally aligned pose, volumetric, mRGBD and audio data cues. The dataset and its code are available https://tofis.github.io/myurls/human4d.
Physical System for Non Time Sequence Data
Oct 07, 2020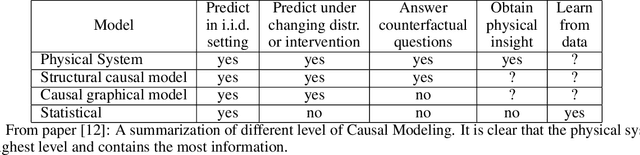
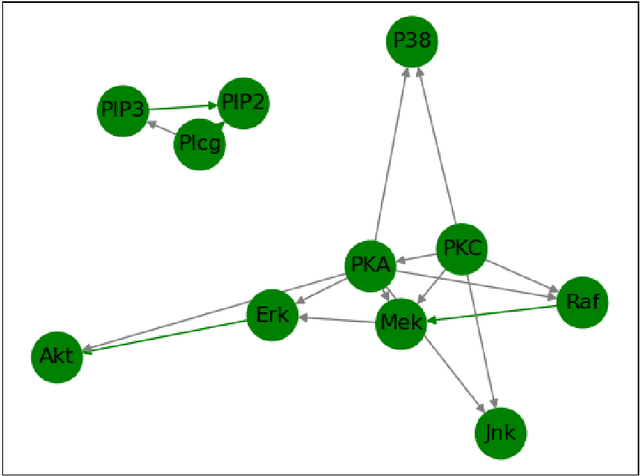
We propose a novelty approach to connect machine learning to causal structure learning by jacobian matrix of neural network w.r.t. input variables. In this paper, we extend the jacobian-based approach to physical system which is the method human explore and reason the world and it is the highest level of causality. By functions fitting with Neural ODE, we can read out causal structure from functions. This method also enforces a important acylicity constraint on continuous adjacency matrix of graph nodes and significantly reduce the computational complexity of search space of graph.
Modeling and Reasoning in Event Calculus using Goal-Directed Constraint Answer Set Programming
Jun 28, 2021
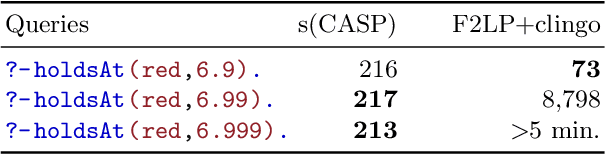


Automated commonsense reasoning is essential for building human-like AI systems featuring, for example, explainable AI. Event Calculus (EC) is a family of formalisms that model commonsense reasoning with a sound, logical basis. Previous attempts to mechanize reasoning using EC faced difficulties in the treatment of the continuous change in dense domains (e.g., time and other physical quantities), constraints among variables, default negation, and the uniform application of different inference methods, among others. We propose the use of s(CASP), a query-driven, top-down execution model for Predicate Answer Set Programming with Constraints, to model and reason using EC. We show how EC scenarios can be naturally and directly encoded in s(CASP) and how it enables deductive and abductive reasoning tasks in domains featuring constraints involving both dense time and dense fluents.
Communication-Efficient Federated Learning via Robust Distributed Mean Estimation
Aug 19, 2021
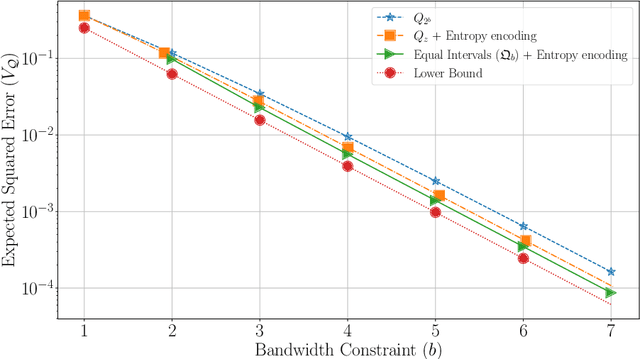
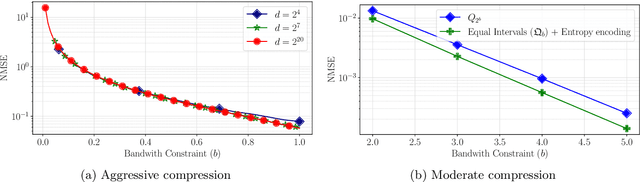
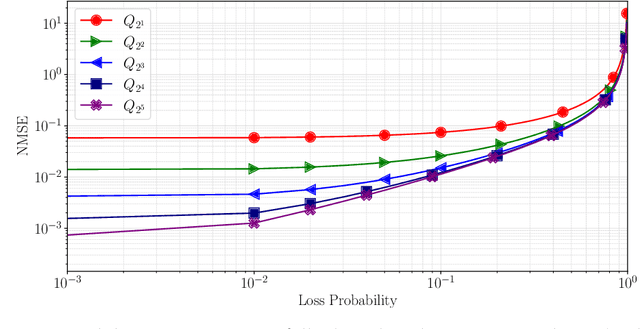
Federated learning commonly relies on algorithms such as distributed (mini-batch) SGD, where multiple clients compute their gradients and send them to a central coordinator for averaging and updating the model. To optimize the transmission time and the scalability of the training process, clients often use lossy compression to reduce the message sizes. DRIVE is a recent state of the art algorithm that compresses gradients using one bit per coordinate (with some lower-order overhead). In this technical report, we generalize DRIVE to support any bandwidth constraint as well as extend it to support heterogeneous client resources and make it robust to packet loss.