 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Otimizacao de pesos e funcoes de ativacao de redes neurais aplicadas na previsao de series temporais
Jul 29, 2021
Neural Networks have been applied for time series prediction with good experimental results that indicate the high capacity to approximate functions with good precision. Most neural models used in these applications use activation functions with fixed parameters. However, it is known that the choice of activation function strongly influences the complexity and performance of the neural network and that a limited number of activation functions have been used. In this work, we propose the use of a family of free parameter asymmetric activation functions for neural networks and show that this family of defined activation functions satisfies the requirements of the universal approximation theorem. A methodology for the global optimization of this family of activation functions with free parameter and the weights of the connections between the processing units of the neural network is used. The central idea of the proposed methodology is to simultaneously optimize the weights and the activation function used in a multilayer perceptron network (MLP), through an approach that combines the advantages of simulated annealing, tabu search and a local learning algorithm, with the purpose of improving performance in the adjustment and forecasting of time series. We chose two learning algorithms: backpropagation with the term momentum (BPM) and LevenbergMarquardt (LM).
A machine-learning framework for daylight and visual comfort assessment in early design stages
Sep 14, 2021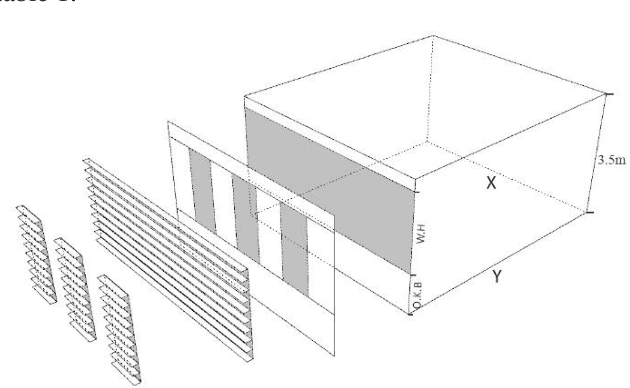
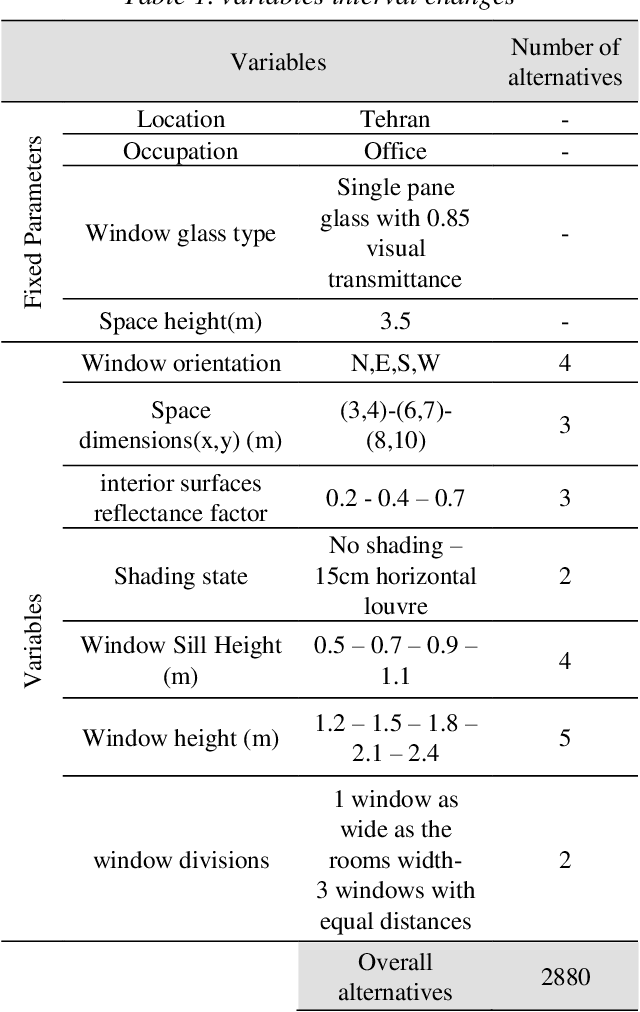
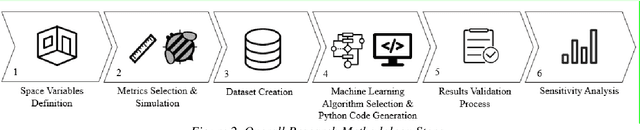

This research is mainly focused on the assessment of machine learning algorithms in the prediction of daylight and visual comfort metrics in the early design stages. A dataset was primarily developed from 2880 simulations derived from Honeybee for Grasshopper. The simulations were done for a shoebox space with a one side window. The alternatives emerged from different physical features, including room dimensions, interior surfaces reflectance, window dimensions and orientations, number of windows, and shading states. 5 metrics were used for daylight evaluations, including UDI, sDA, mDA, ASE, and sVD. Quality Views were analyzed for the same shoebox spaces via a grasshopper-based algorithm, developed from the LEED v4 evaluation framework for Quality Views. The dataset was further analyzed with an Artificial Neural Network algorithm written in Python. The accuracy of the predictions was estimated at 97% on average. The developed model could be used in early design stages analyses without the need for time-consuming simulations in previously used platforms and programs.
Convergence Analysis of Schr{ö}dinger-F{ö}llmer Sampler without Convexity
Jul 10, 2021Schr\"{o}dinger-F\"{o}llmer sampler (SFS) is a novel and efficient approach for sampling from possibly unnormalized distributions without ergodicity. SFS is based on the Euler-Maruyama discretization of Schr\"{o}dinger-F\"{o}llmer diffusion process $$\mathrm{d} X_{t}=-\nabla U\left(X_t, t\right) \mathrm{d} t+\mathrm{d} B_{t}, \quad t \in[0,1],\quad X_0=0$$ on the unit interval, which transports the degenerate distribution at time zero to the target distribution at time one. In \cite{sfs21}, the consistency of SFS is established under a restricted assumption that %the drift term $b(x,t)$ the potential $U(x,t)$ is uniformly (on $t$) strongly %concave convex (on $x$). In this paper we provide a nonasymptotic error bound of SFS in Wasserstein distance under some smooth and bounded conditions on the density ratio of the target distribution over the standard normal distribution, but without requiring the strongly convexity of the potential.
Continual Learning for Grounded Instruction Generation by Observing Human Following Behavior
Aug 10, 2021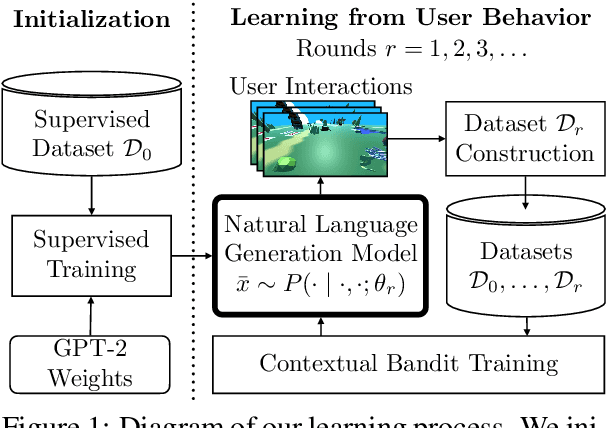

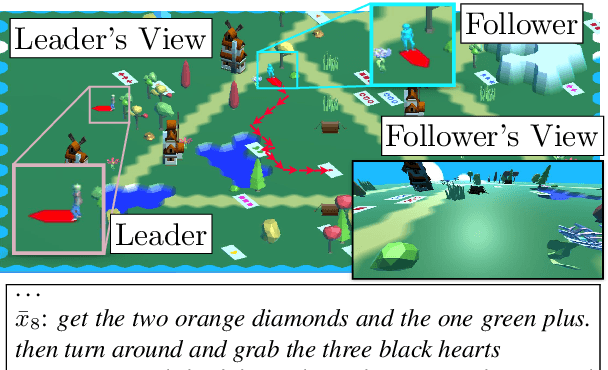
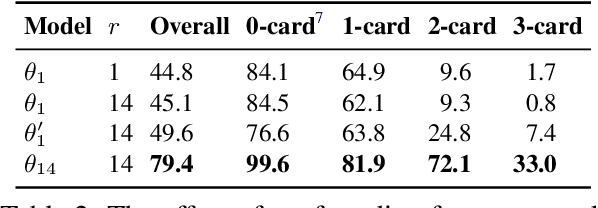
We study continual learning for natural language instruction generation, by observing human users' instruction execution. We focus on a collaborative scenario, where the system both acts and delegates tasks to human users using natural language. We compare user execution of generated instructions to the original system intent as an indication to the system's success communicating its intent. We show how to use this signal to improve the system's ability to generate instructions via contextual bandit learning. In interaction with real users, our system demonstrates dramatic improvements in its ability to generate language over time.
Constants of Motion: The Antidote to Chaos in Optimization and Game Dynamics
Sep 10, 2021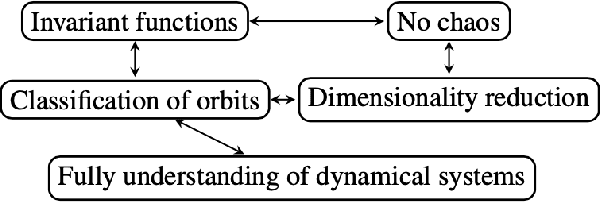
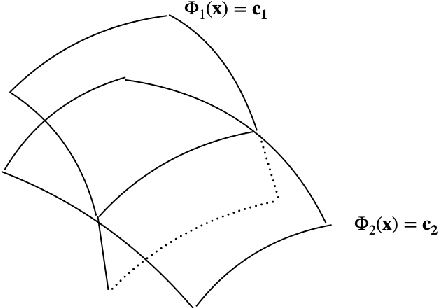
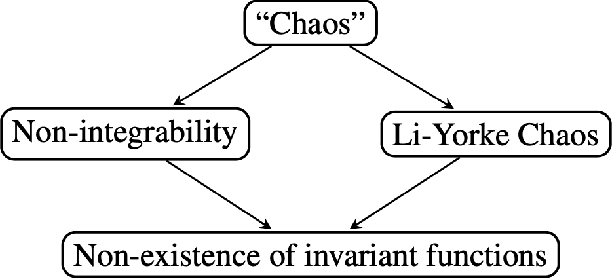
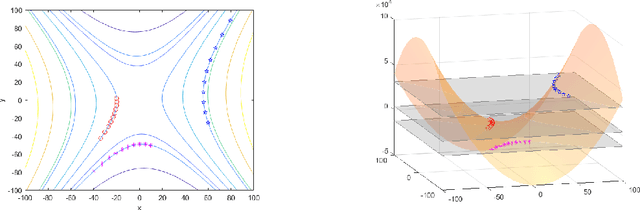
Several recent works in online optimization and game dynamics have established strong negative complexity results including the formal emergence of instability and chaos even in small such settings, e.g., $2\times 2$ games. These results motivate the following question: Which methodological tools can guarantee the regularity of such dynamics and how can we apply them in standard settings of interest such as discrete-time first-order optimization dynamics? We show how proving the existence of invariant functions, i.e., constant of motions, is a fundamental contribution in this direction and establish a plethora of such positive results (e.g. gradient descent, multiplicative weights update, alternating gradient descent and manifold gradient descent) both in optimization as well as in game settings. At a technical level, for some conservation laws we provide an explicit and concise closed form, whereas for other ones we present non-constructive proofs using tools from dynamical systems.
OmniTrack: Real-time detection and tracking of objects, text and logos in video
Oct 14, 2019
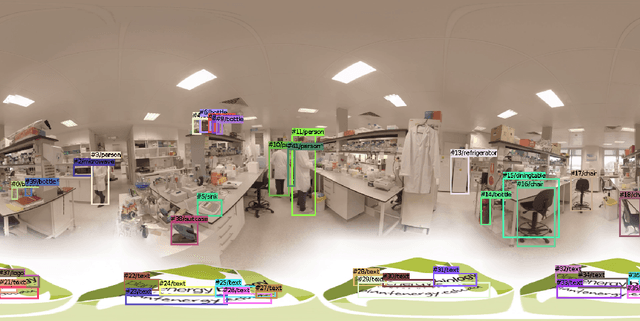
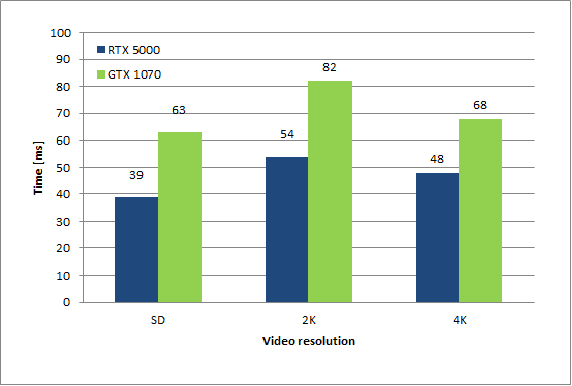
The automatic detection and tracking of general objects (like persons, animals or cars), text and logos in a video is crucial for many video understanding tasks, and usually real-time processing as required. We propose OmniTrack, an efficient and robust algorithm which is able to automatically detect and track objects, text as well as brand logos in real-time. It combines a powerful deep learning based object detector (YoloV3) with high-quality optical flow methods. Based on the reference YoloV3 C++ implementation, we did some important performance optimizations which will be described. The major steps in the training procedure for the combined detector for text and logo will be presented. We will describe then the OmniTrack algorithm, consisting of the phases preprocessing, feature calculation, prediction, matching and update. Several performance optimizations have been implemented there as well, like doing the object detection and optical flow calculation asynchronously. Experiments show that the proposed algorithm runs in real-time for standard definition ($720x576$) video on a PC with a Quadro RTX 5000 GPU.
PubTables-1M: Towards a universal dataset and metrics for training and evaluating table extraction models
Oct 12, 2021

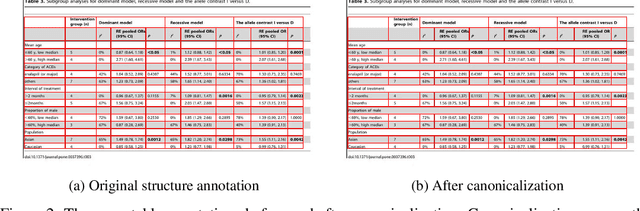
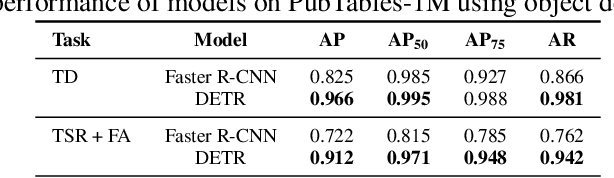
Recently, interest has grown in applying machine learning to the problem of table structure inference and extraction from unstructured documents. However, progress in this area has been challenging both to make and to measure, due to several issues that arise in training and evaluating models from labeled data. This includes challenges as fundamental as the lack of a single definitive ground truth output for each input sample and the lack of an ideal metric for measuring partial correctness for this task. To address these issues we propose a new dataset, PubMed Tables One Million (PubTables-1M), and a new class of metric, grid table similarity (GriTS). PubTables-1M is nearly twice as large as the previous largest comparable dataset, contains highly-detailed structure annotations, and can be used for models across multiple architectures and modalities. Further, it addresses issues such as ambiguity and lack of consistency in the annotations via a novel canonicalization and quality control procedure. We apply DETR to table extraction for the first time and show that object detection models trained on PubTables-1M produce excellent results out-of-the-box for all three tasks of detection, structure recognition, and functional analysis. It is our hope that PubTables-1M and GriTS can further progress in this area by creating data and metrics suitable for training and evaluating a wide variety of models for table extraction. Data and code will be released at https://github.com/microsoft/table-transformer.
Modeling Time to Open of Emails with a Latent State for User Engagement Level
Aug 18, 2019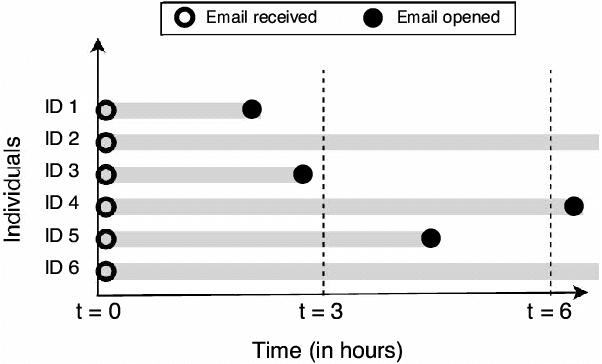
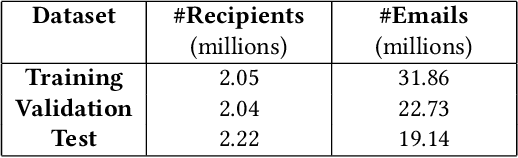
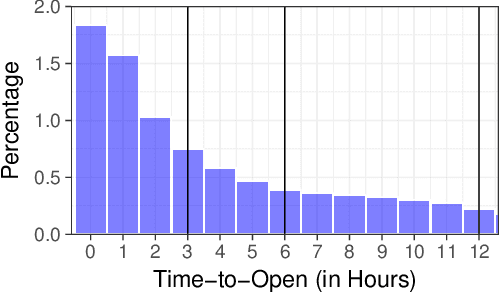

Email messages have been an important mode of communication, not only for work, but also for social interactions and marketing. When messages have time sensitive information, it becomes relevant for the sender to know what is the expected time within which the email will be read by the recipient. In this paper we use a survival analysis framework to predict the time to open an email once it has been received. We use the Cox Proportional Hazards (CoxPH) model that offers a way to combine various features that might affect the event of opening an email. As an extension, we also apply a mixture model (MM) approach to CoxPH that distinguishes between recipients, based on a latent state of how prone to opening the messages each individual is. We compare our approach with standard classification and regression models. While the classification model provides predictions on the likelihood of an email being opened, the regression model provides prediction of the real-valued time to open. The use of survival analysis based methods allows us to jointly model both the open event as well as the time-to-open. We experimented on a large real-world dataset of marketing emails sent in a 3-month time duration. The mixture model achieves the best accuracy on our data where a high proportion of email messages go unopened.
* 9 pages, 5 figures, WSDM'18, February 5-9, 2018, Marina Del Rey, CA, USA, https://dl.acm.org/citation.cfm?id=3159683
Wake-Cough: cough spotting and cougher identification for personalised long-term cough monitoring
Oct 07, 2021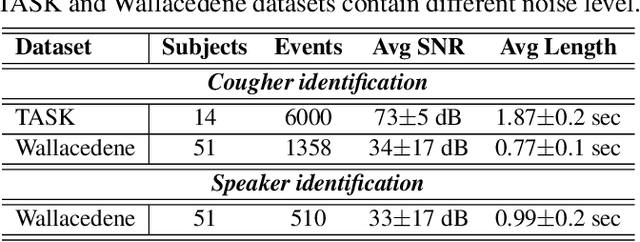

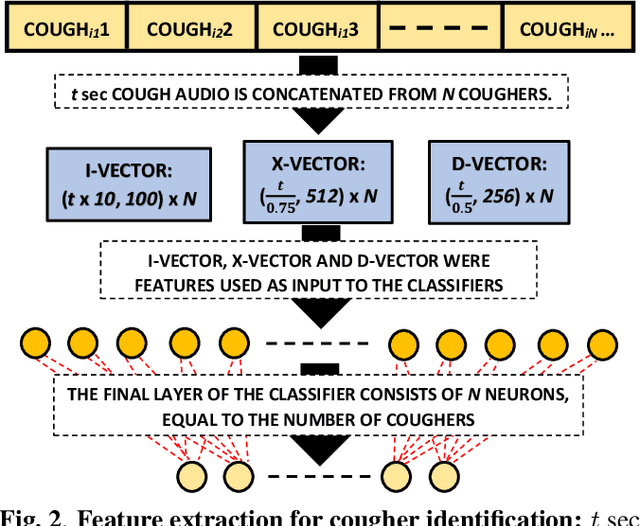
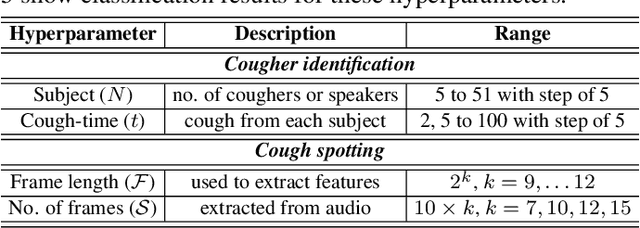
We present 'wake-cough', an application of wake-word spotting to coughs using Resnet50 and identifying coughers using i-vectors, for the purpose of a long-term, personalised cough monitoring system. Coughs, recorded in a quiet (73$\pm$5 dB) and noisy (34$\pm$17 dB) environment, were used to extract i-vectors, x-vectors and d-vectors, used as features to the classifiers. The system achieves 90.02\% accuracy from an MLP to discriminate 51 coughers using 2-sec long cough segments in the noisy environment. When discriminating between 5 and 14 coughers using longer (100 sec) segments in the quiet environment, this accuracy rises to 99.78\% and 98.39\% respectively. Unlike speech, i-vectors outperform x-vectors and d-vectors in identifying coughers. These coughs were added as an extra class in the Google Speech Commands dataset and features were extracted by preserving the end-to-end time-domain information in an event. The highest accuracy of 88.58\% is achieved in spotting coughs among 35 other trigger phrases using a Resnet50. Wake-cough represents a personalised, non-intrusive, cough monitoring system, which is power efficient as using wake-word detection method can keep a smartphone-based monitoring device mostly dormant. This makes wake-cough extremely attractive in multi-bed ward environments to monitor patient's long-term recovery from lung ailments such as tuberculosis and COVID-19.
Defined the predictors of the lightning over India by using artificial neural network
Apr 28, 2021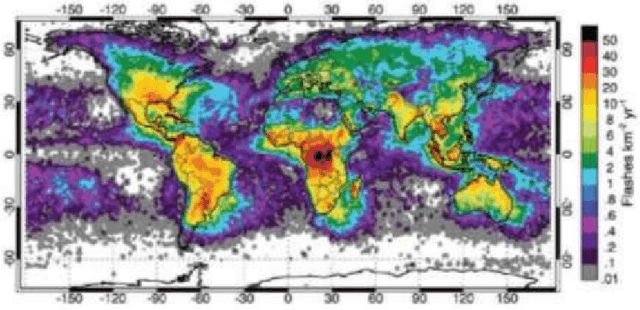
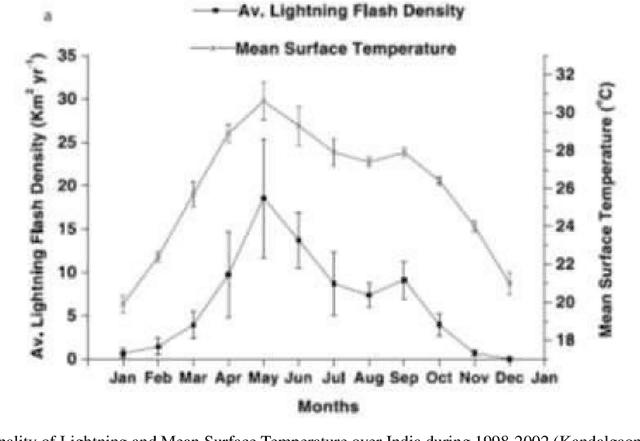
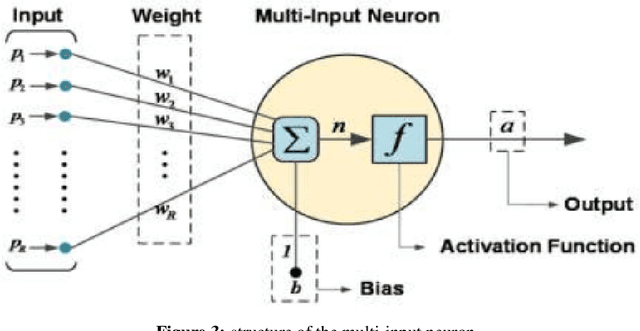
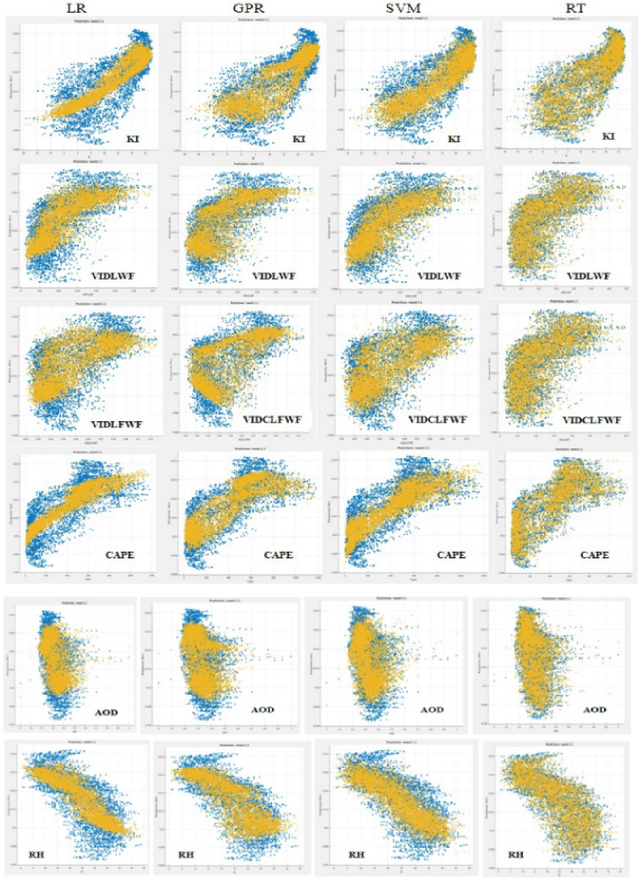
Lightning casualties cause tremendous loss to life and property. However, very lately lightning has been considered as one of the major natural calamities which is now studied or monitored with proper instrumentation. The lightning characteristics over India have been studying by using daily data low resolution time series and monthly data high resolution monthly climatology. We have used ANN time series method (a neural network) to analyze the time series and defined which one will be the best predictor of lightning over India. The time series of lightning is output(dependent) and input (independent) are k-index, AOD, Cape etc. The Gaussian process regression, support vector machine, regression trees and linear regression defined the input variables. Which show approximately linear relation.