 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
REFLACX, a dataset of reports and eye-tracking data for localization of abnormalities in chest x-rays
Sep 29, 2021
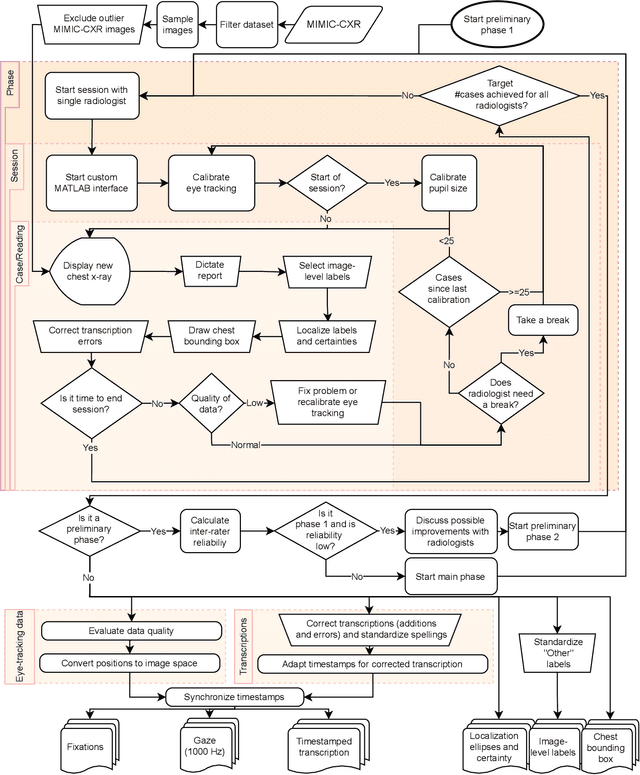
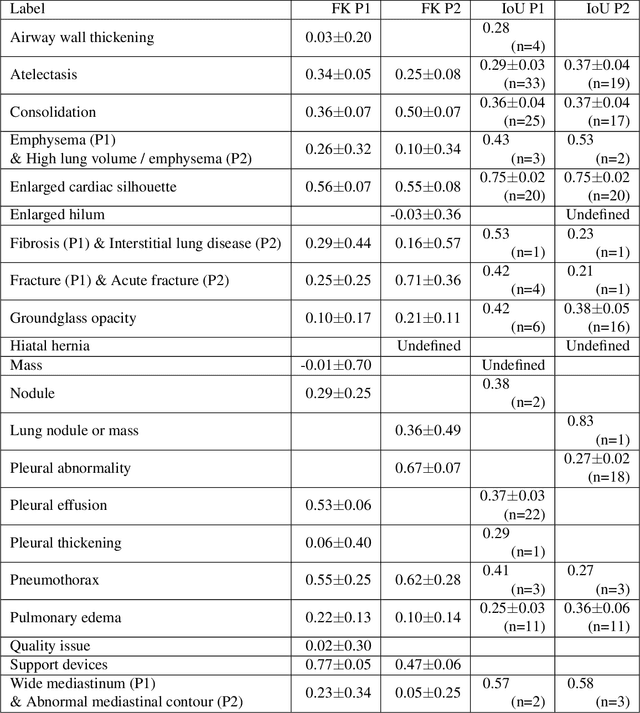
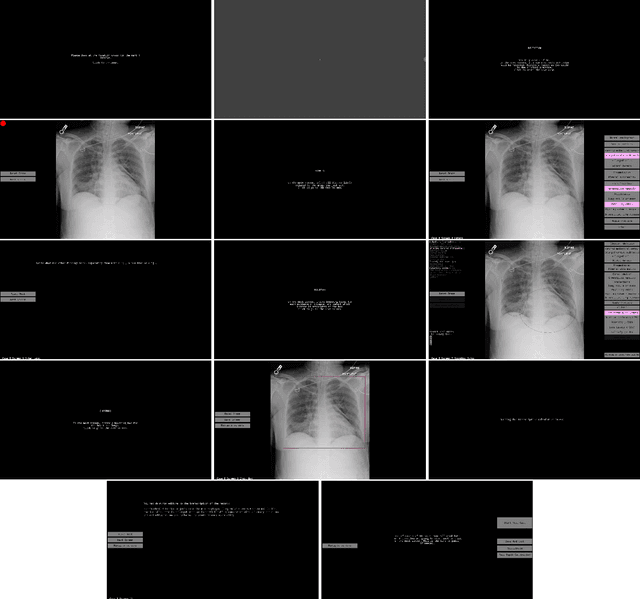
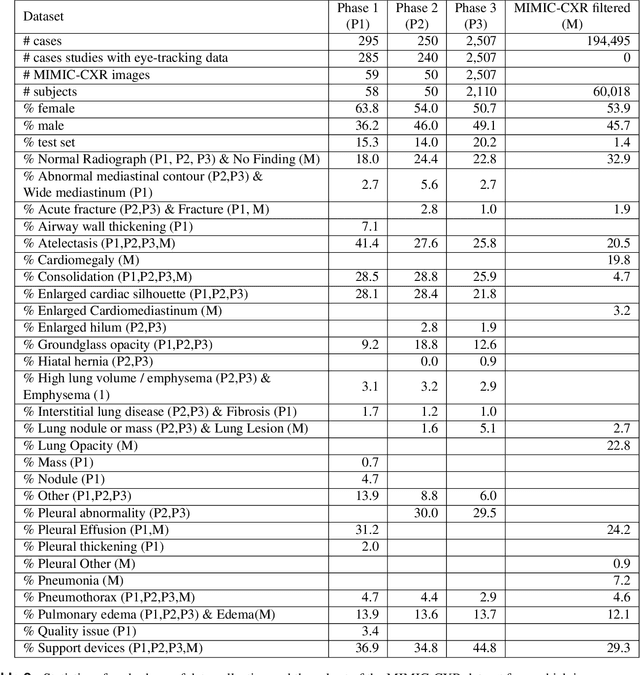
Deep learning has shown recent success in classifying anomalies in chest x-rays, but datasets are still small compared to natural image datasets. Supervision of abnormality localization has been shown to improve trained models, partially compensating for dataset sizes. However, explicitly labeling these anomalies requires an expert and is very time-consuming. We propose a method for collecting implicit localization data using an eye tracker to capture gaze locations and a microphone to capture a dictation of a report, imitating the setup of a reading room, and potentially scalable for large datasets. The resulting REFLACX (Reports and Eye-Tracking Data for Localization of Abnormalities in Chest X-rays) dataset was labeled by five radiologists and contains 3,032 synchronized sets of eye-tracking data and timestamped report transcriptions. We also provide bounding boxes around lungs and heart and validation labels consisting of ellipses localizing abnormalities and image-level labels. Furthermore, a small subset of the data contains readings from all radiologists, allowing for the calculation of inter-rater scores.
Online Fairness-Aware Learning with Imbalanced Data Streams
Aug 13, 2021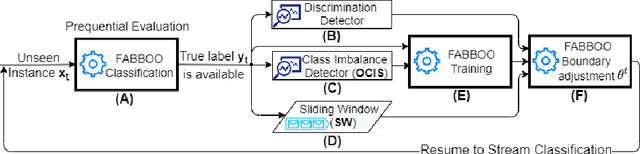

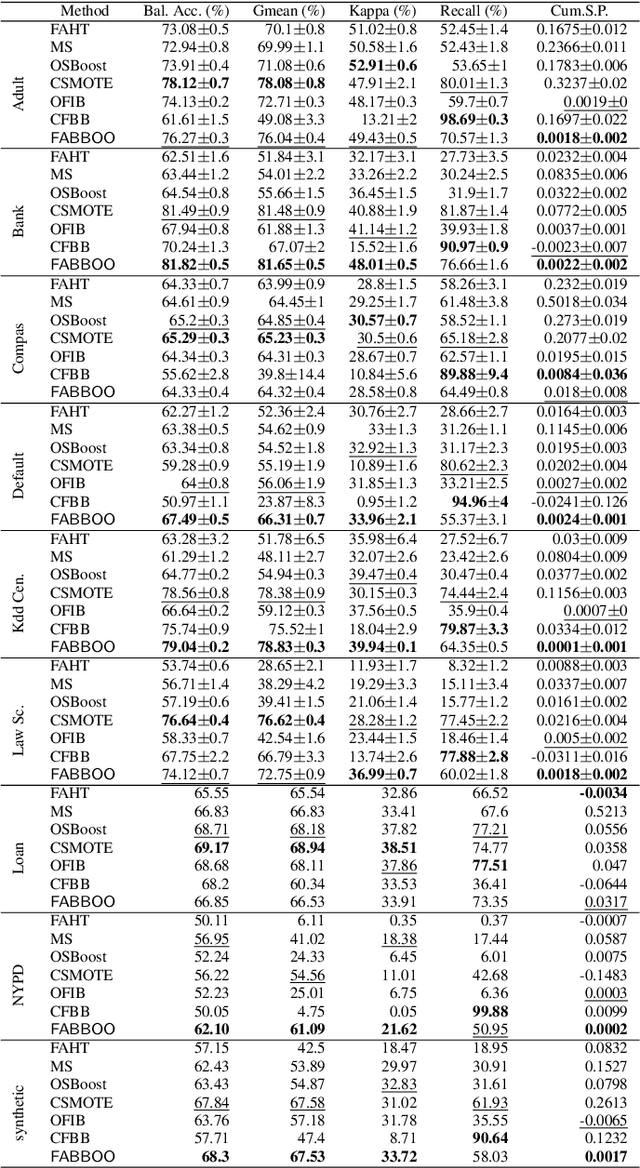
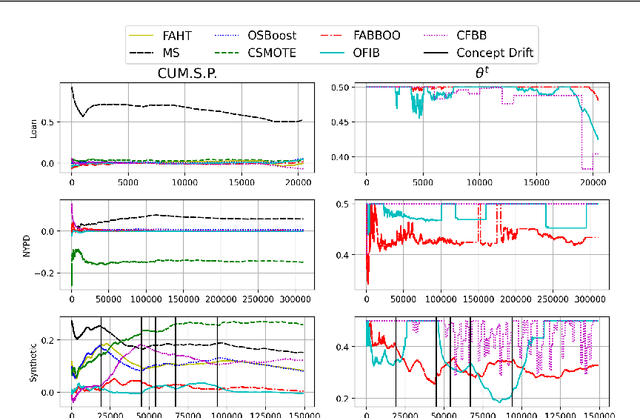
Data-driven learning algorithms are employed in many online applications, in which data become available over time, like network monitoring, stock price prediction, job applications, etc. The underlying data distribution might evolve over time calling for model adaptation as new instances arrive and old instances become obsolete. In such dynamic environments, the so-called data streams, fairness-aware learning cannot be considered as a one-off requirement, but rather it should comprise a continual requirement over the stream. Recent fairness-aware stream classifiers ignore the problem of class imbalance, which manifests in many real-life applications, and mitigate discrimination mainly because they "reject" minority instances at large due to their inability to effectively learn all classes. In this work, we propose \ours, an online fairness-aware approach that maintains a valid and fair classifier over the stream. \ours~is an online boosting approach that changes the training distribution in an online fashion by monitoring stream's class imbalance and tweaks its decision boundary to mitigate discriminatory outcomes over the stream. Experiments on 8 real-world and 1 synthetic datasets from different domains with varying class imbalance demonstrate the superiority of our method over state-of-the-art fairness-aware stream approaches with a range (relative) increase [11.2\%-14.2\%] in balanced accuracy, [22.6\%-31.8\%] in gmean, [42.5\%-49.6\%] in recall, [14.3\%-25.7\%] in kappa and [89.4\%-96.6\%] in statistical parity (fairness).
Towards Cognitive Navigation: Design and Implementation of a Biologically Inspired Head Direction Cell Network
Sep 22, 2021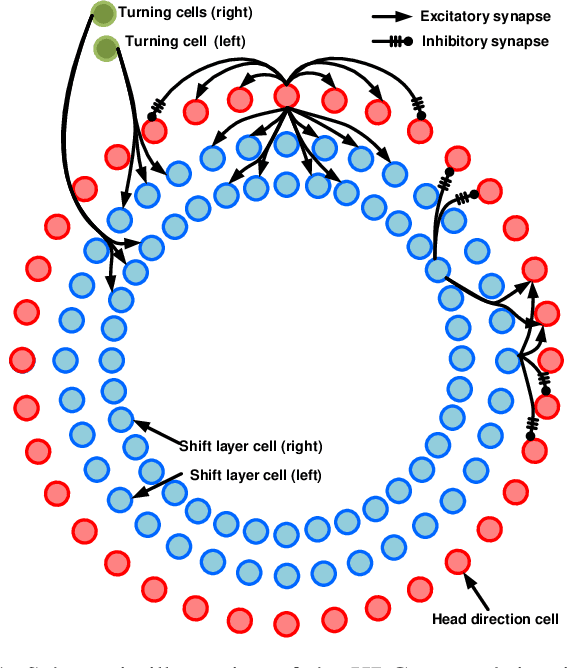
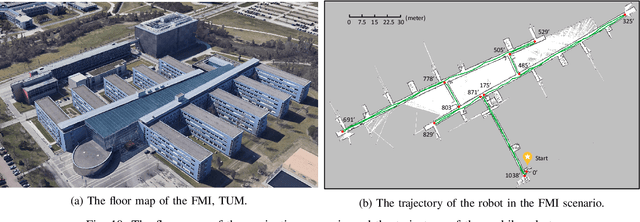
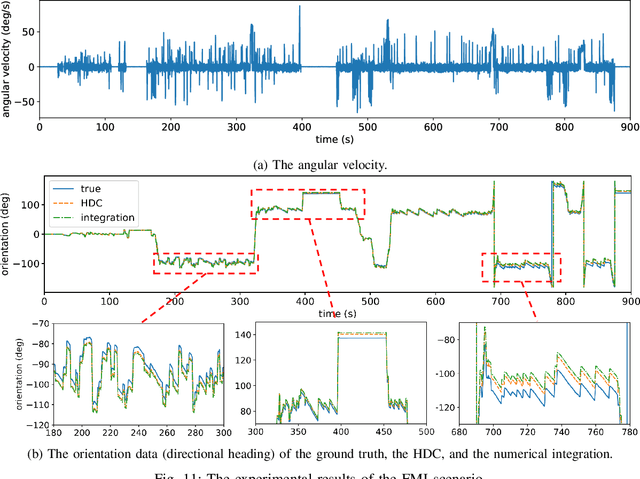
As a vital cognitive function of animals, the navigation skill is first built on the accurate perception of the directional heading in the environment. Head direction cells (HDCs), found in the limbic system of animals, are proven to play an important role in identifying the directional heading allocentrically in the horizontal plane, independent of the animal's location and the ambient conditions of the environment. However, practical HDC models that can be implemented in robotic applications are rarely investigated, especially those that are biologically plausible and yet applicable to the real world. In this paper, we propose a computational HDC network which is consistent with several neurophysiological findings concerning biological HDCs, and then implement it in robotic navigation tasks. The HDC network keeps a representation of the directional heading only relying on the angular velocity as an input. We examine the proposed HDC model in extensive simulations and real-world experiments and demonstrate its excellent performance in terms of accuracy and real-time capability.
Antenna Array Enabled Space/Air/Ground Communications and Networking for 6G
Oct 25, 2021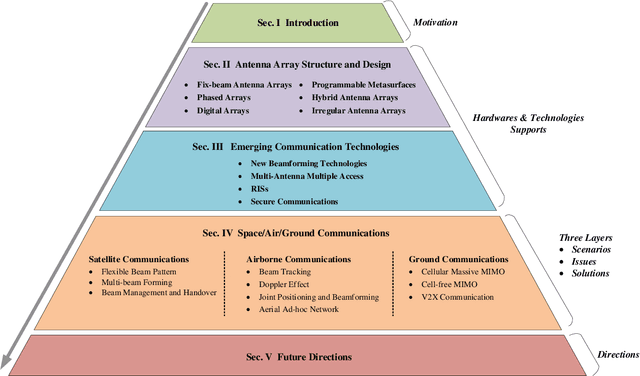
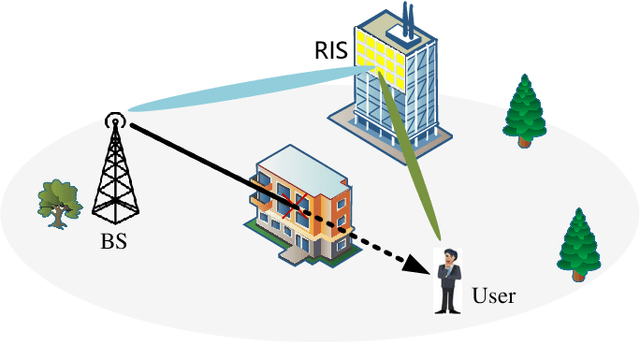
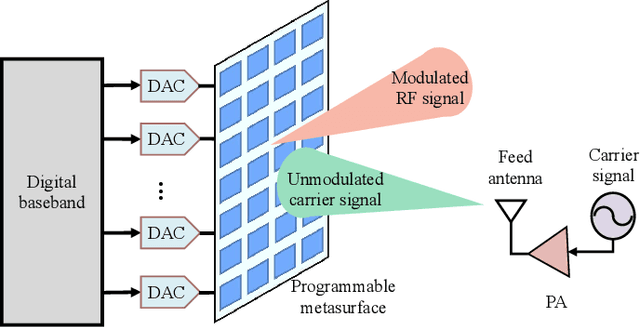
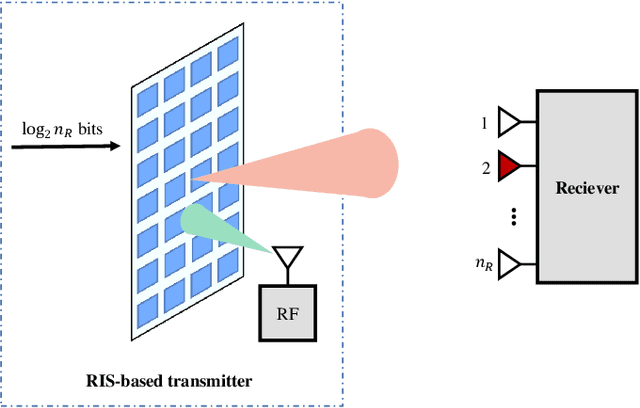
Antenna arrays have a long history of more than 100 years and have evolved closely with the development of electronic and information technologies, playing an indispensable role in wireless communications and radar. With the rapid development of electronic and information technologies, the demand for all-time, all-domain, and full-space network services has exploded, and new communication requirements have been put forward on various space/air/ground platforms. To meet the ever increasing requirements of the future sixth generation (6G) wireless communications, such as high capacity, wide coverage, low latency, and strong robustness, it is promising to employ different types of antenna arrays with various beamforming technologies in space/air/ground communication networks, bringing in advantages such as considerable antenna gains, multiplexing gains, and diversity gains. However, enabling antenna array for space/air/ground communication networks poses specific, distinctive and tricky challenges, which has aroused extensive research attention. This paper aims to overview the field of antenna array enabled space/air/ground communications and networking. The technical potentials and challenges of antenna array enabled space/air/ground communications and networking are presented first. Subsequently, the antenna array structures and designs are discussed. We then discuss various emerging technologies facilitated by antenna arrays to meet the new communication requirements of space/air/ground communication systems. Enabled by these emerging technologies, the distinct characteristics, challenges, and solutions for space communications, airborne communications, and ground communications are reviewed. Finally, we present promising directions for future research in antenna array enabled space/air/ground communications and networking.
Active Sampling for Linear Regression Beyond the $\ell_2$ Norm
Nov 09, 2021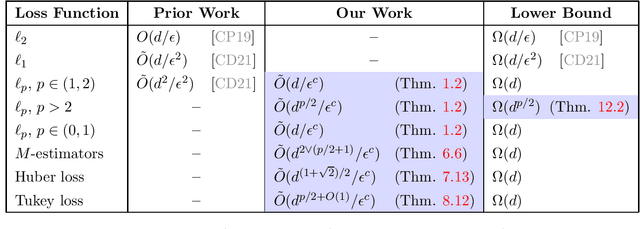
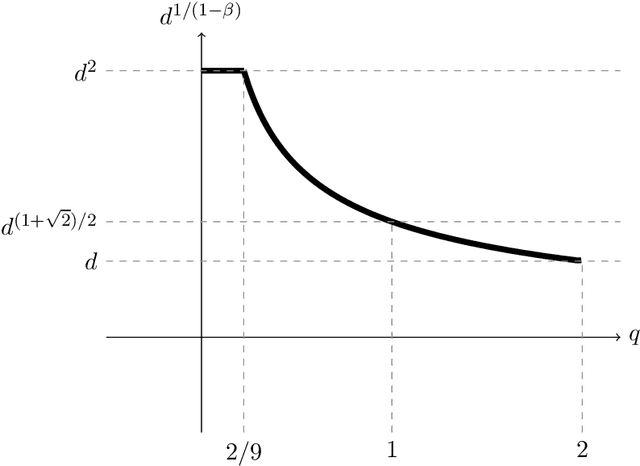
We study active sampling algorithms for linear regression, which aim to query only a small number of entries of a target vector $b\in\mathbb{R}^n$ and output a near minimizer to $\min_{x\in\mathbb{R}^d}\|Ax-b\|$, where $A\in\mathbb{R}^{n \times d}$ is a design matrix and $\|\cdot\|$ is some loss function. For $\ell_p$ norm regression for any $0<p<\infty$, we give an algorithm based on Lewis weight sampling that outputs a $(1+\epsilon)$ approximate solution using just $\tilde{O}(d^{\max(1,{p/2})}/\mathrm{poly}(\epsilon))$ queries to $b$. We show that this dependence on $d$ is optimal, up to logarithmic factors. Our result resolves a recent open question of Chen and Derezi\'{n}ski, who gave near optimal bounds for the $\ell_1$ norm, and suboptimal bounds for $\ell_p$ regression with $p\in(1,2)$. We also provide the first total sensitivity upper bound of $O(d^{\max\{1,p/2\}}\log^2 n)$ for loss functions with at most degree $p$ polynomial growth. This improves a recent result of Tukan, Maalouf, and Feldman. By combining this with our techniques for the $\ell_p$ regression result, we obtain an active regression algorithm making $\tilde O(d^{1+\max\{1,p/2\}}/\mathrm{poly}(\epsilon))$ queries, answering another open question of Chen and Derezi\'{n}ski. For the important special case of the Huber loss, we further improve our bound to an active sample complexity of $\tilde O(d^{(1+\sqrt2)/2}/\epsilon^c)$ and a non-active sample complexity of $\tilde O(d^{4-2\sqrt 2}/\epsilon^c)$, improving a previous $d^4$ bound for Huber regression due to Clarkson and Woodruff. Our sensitivity bounds have further implications, improving a variety of previous results using sensitivity sampling, including Orlicz norm subspace embeddings and robust subspace approximation. Finally, our active sampling results give the first sublinear time algorithms for Kronecker product regression under every $\ell_p$ norm.
ContractNLI: A Dataset for Document-level Natural Language Inference for Contracts
Oct 05, 2021
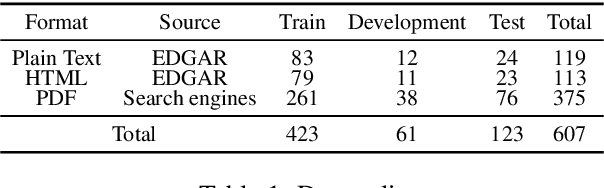

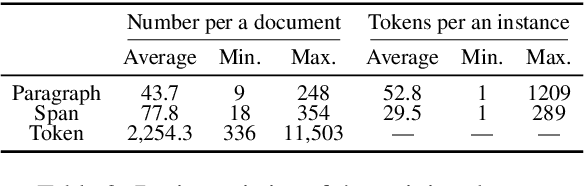
Reviewing contracts is a time-consuming procedure that incurs large expenses to companies and social inequality to those who cannot afford it. In this work, we propose "document-level natural language inference (NLI) for contracts", a novel, real-world application of NLI that addresses such problems. In this task, a system is given a set of hypotheses (such as "Some obligations of Agreement may survive termination.") and a contract, and it is asked to classify whether each hypothesis is "entailed by", "contradicting to" or "not mentioned by" (neutral to) the contract as well as identifying "evidence" for the decision as spans in the contract. We annotated and release the largest corpus to date consisting of 607 annotated contracts. We then show that existing models fail badly on our task and introduce a strong baseline, which (1) models evidence identification as multi-label classification over spans instead of trying to predict start and end tokens, and (2) employs more sophisticated context segmentation for dealing with long documents. We also show that linguistic characteristics of contracts, such as negations by exceptions, are contributing to the difficulty of this task and that there is much room for improvement.
Cooperative Assistance in Robotic Surgery through Multi-Agent Reinforcement Learning
Oct 10, 2021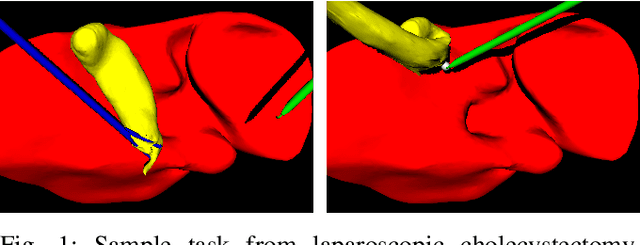

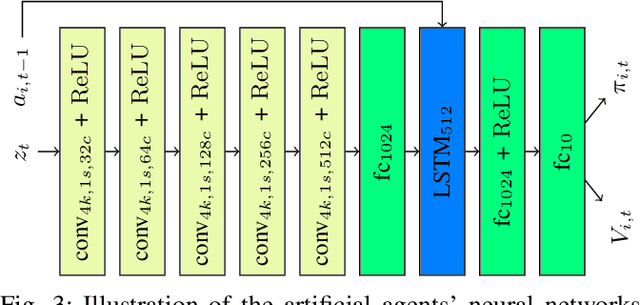
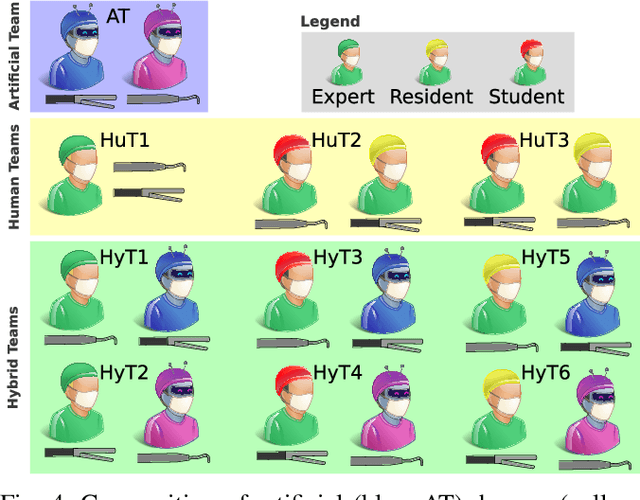
Cognitive cooperative assistance in robot-assisted surgery holds the potential to increase quality of care in minimally invasive interventions. Automation of surgical tasks promises to reduce the mental exertion and fatigue of surgeons. In this work, multi-agent reinforcement learning is demonstrated to be robust to the distribution shift introduced by pairing a learned policy with a human team member. Multi-agent policies are trained directly from images in simulation to control multiple instruments in a sub task of the minimally invasive removal of the gallbladder. These agents are evaluated individually and in cooperation with humans to demonstrate their suitability as autonomous assistants. Compared to human teams, the hybrid teams with artificial agents perform better considering completion time (44.4% to 71.2% shorter) as well as number of collisions (44.7% to 98.0% fewer). Path lengths, however, increase under control of an artificial agent (11.4% to 33.5% longer). A multi-agent formulation of the learning problem was favored over a single-agent formulation on this surgical sub task, due to the sequential learning of the two instruments. This approach may be extended to other tasks that are difficult to formulate within the standard reinforcement learning framework. Multi-agent reinforcement learning may shift the paradigm of cognitive robotic surgery towards seamless cooperation between surgeons and assistive technologies.
A Deep Reinforcement Learning Framework for Contention-Based Spectrum Sharing
Oct 05, 2021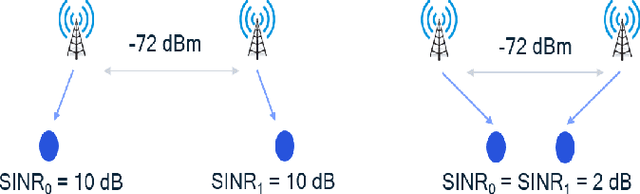
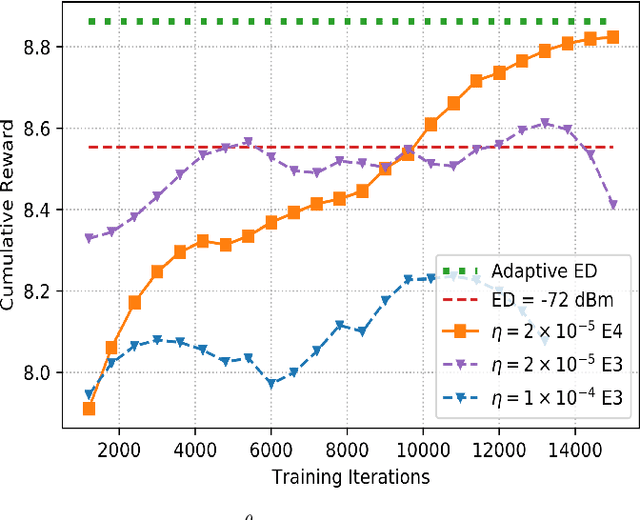
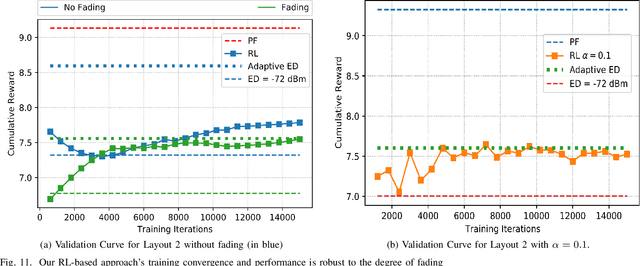
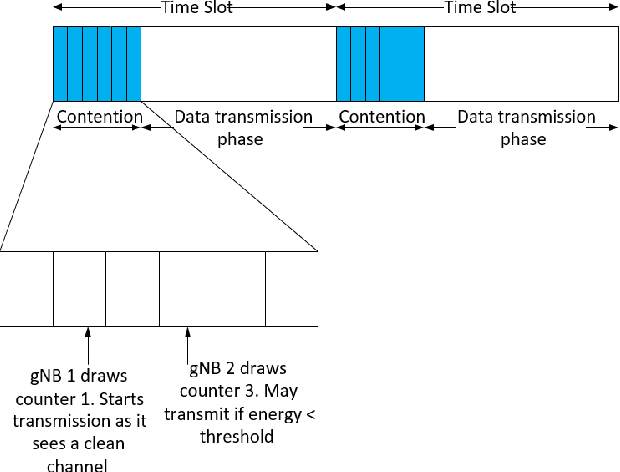
The increasing number of wireless devices operating in unlicensed spectrum motivates the development of intelligent adaptive approaches to spectrum access. We consider decentralized contention-based medium access for base stations (BSs) operating on unlicensed shared spectrum, where each BS autonomously decides whether or not to transmit on a given resource. The contention decision attempts to maximize not its own downlink throughput, but rather a network-wide objective. We formulate this problem as a decentralized partially observable Markov decision process with a novel reward structure that provides long term proportional fairness in terms of throughput. We then introduce a two-stage Markov decision process in each time slot that uses information from spectrum sensing and reception quality to make a medium access decision. Finally, we incorporate these features into a distributed reinforcement learning framework for contention-based spectrum access. Our formulation provides decentralized inference, online adaptability and also caters to partial observability of the environment through recurrent Q-learning. Empirically, we find its maximization of the proportional fairness metric to be competitive with a genie-aided adaptive energy detection threshold, while being robust to channel fading and small contention windows.
* 14 pages, 11 figures, 4 tables
Multi-axis Attentive Prediction for Sparse EventData: An Application to Crime Prediction
Oct 05, 2021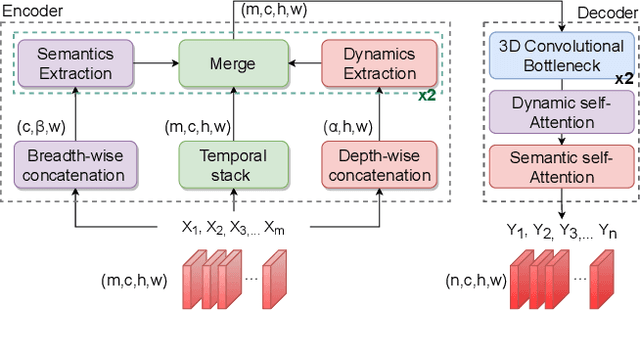

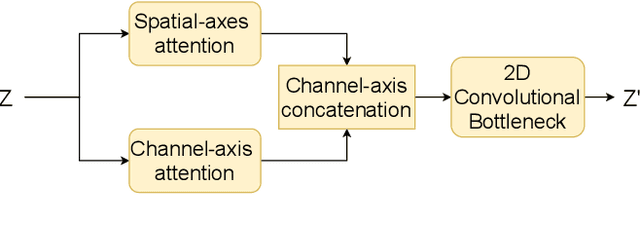
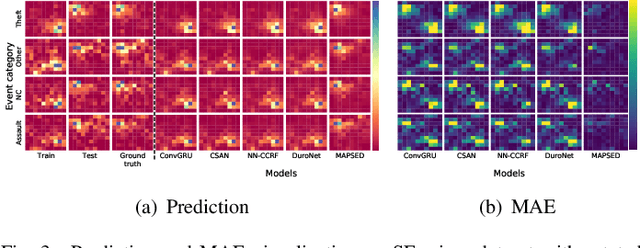
Spatiotemporal prediction of event data is a challenging task with a long history of research. While recent work in spatiotemporal prediction has leveraged deep sequential models that substantially improve over classical approaches, these models are prone to overfitting when the observation is extremely sparse, as in the task of crime event prediction. To overcome these sparsity issues, we present Multi-axis Attentive Prediction for Sparse Event Data (MAPSED). We propose a purely attentional approach to extract both short-term dynamics and long-term semantics of event propagation through two observation angles. Unlike existing temporal prediction models that propagate latent information primarily along the temporal dimension, the MAPSED simultaneously operates over all axes (time, 2D space, event type) of the embedded data tensor. We additionally introduce a novel Frobenius norm-based contrastive learning objective to improve latent representational generalization.Empirically, we validate MAPSED on two publicly accessible urban crime datasets for spatiotemporal sparse event prediction, where MAPSED outperforms both classical and state-of-the-art deep learning models. The proposed contrastive learning objective significantly enhances the MAPSED's ability to capture the semantics and dynamics of the events, resulting in better generalization ability to combat sparse observations.
Meta Learning on a Sequence of Imbalanced Domains with Difficulty Awareness
Sep 29, 2021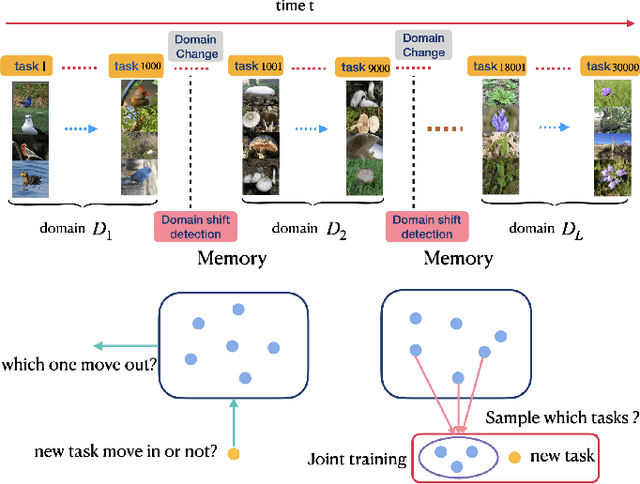
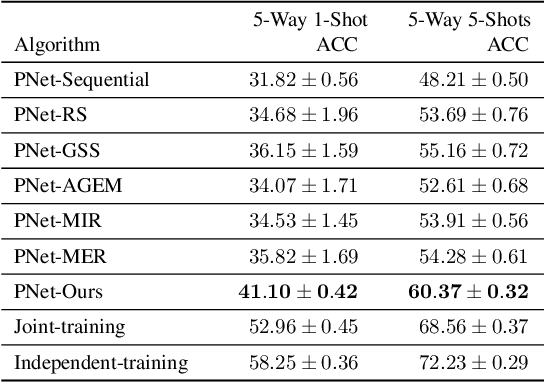
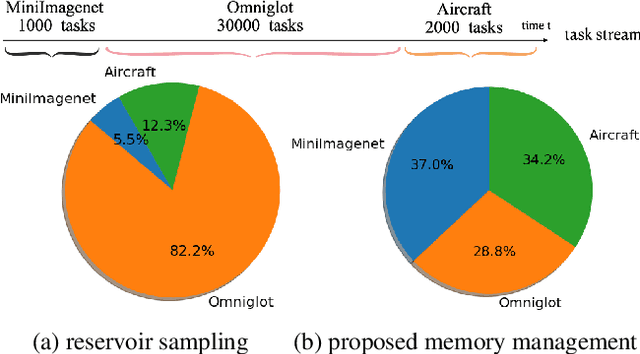
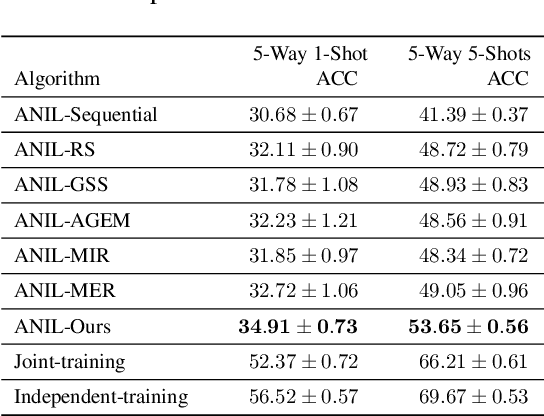
Recognizing new objects by learning from a few labeled examples in an evolving environment is crucial to obtain excellent generalization ability for real-world machine learning systems. A typical setting across current meta learning algorithms assumes a stationary task distribution during meta training. In this paper, we explore a more practical and challenging setting where task distribution changes over time with domain shift. Particularly, we consider realistic scenarios where task distribution is highly imbalanced with domain labels unavailable in nature. We propose a kernel-based method for domain change detection and a difficulty-aware memory management mechanism that jointly considers the imbalanced domain size and domain importance to learn across domains continuously. Furthermore, we introduce an efficient adaptive task sampling method during meta training, which significantly reduces task gradient variance with theoretical guarantees. Finally, we propose a challenging benchmark with imbalanced domain sequences and varied domain difficulty. We have performed extensive evaluations on the proposed benchmark, demonstrating the effectiveness of our method. We made our code publicly available.