 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Video 3D Sampling for Self-supervised Representation Learning
Jul 08, 2021
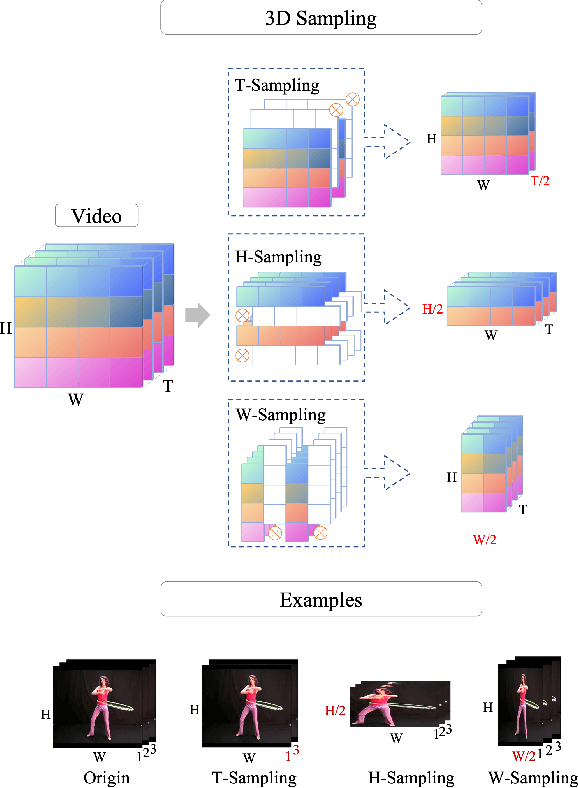
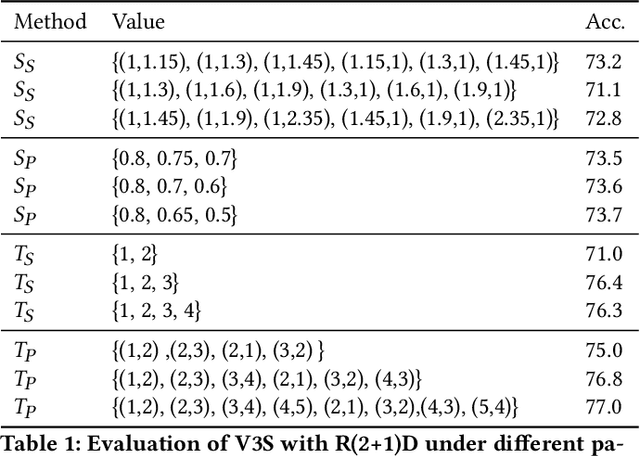
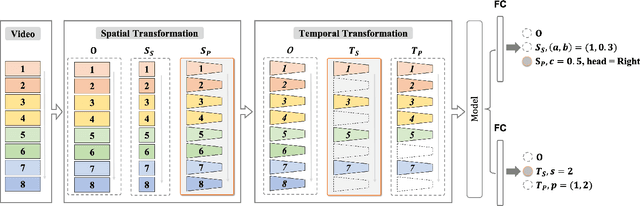
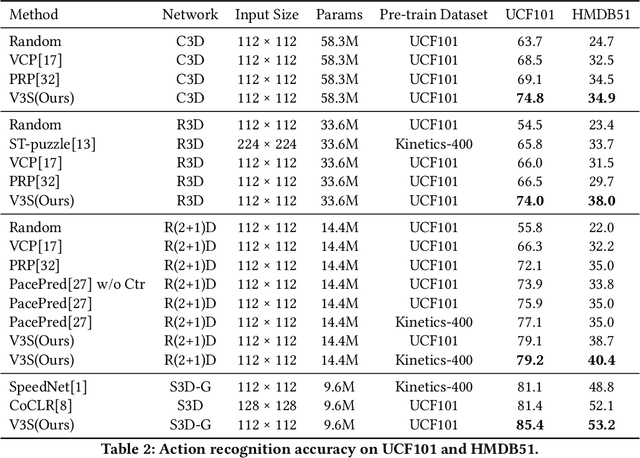
Most of the existing video self-supervised methods mainly leverage temporal signals of videos, ignoring that the semantics of moving objects and environmental information are all critical for video-related tasks. In this paper, we propose a novel self-supervised method for video representation learning, referred to as Video 3D Sampling (V3S). In order to sufficiently utilize the information (spatial and temporal) provided in videos, we pre-process a video from three dimensions (width, height, time). As a result, we can leverage the spatial information (the size of objects), temporal information (the direction and magnitude of motions) as our learning target. In our implementation, we combine the sampling of the three dimensions and propose the scale and projection transformations in space and time respectively. The experimental results show that, when applied to action recognition, video retrieval and action similarity labeling, our approach improves the state-of-the-arts with significant margins.
RAIL-KD: RAndom Intermediate Layer Mapping for Knowledge Distillation
Sep 21, 2021
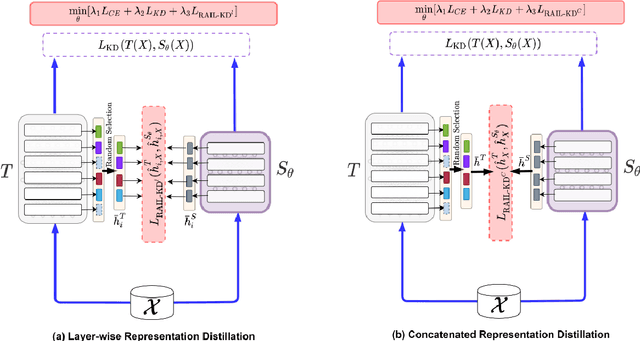
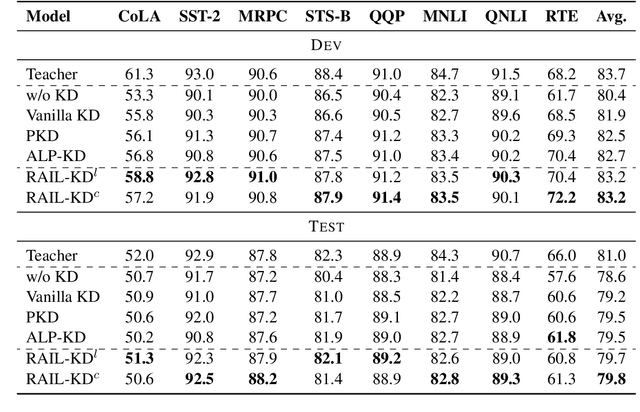
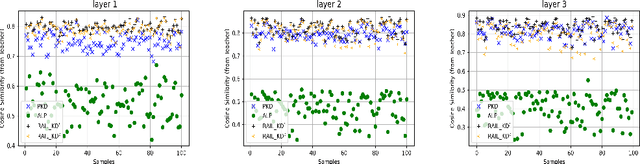
Intermediate layer knowledge distillation (KD) can improve the standard KD technique (which only targets the output of teacher and student models) especially over large pre-trained language models. However, intermediate layer distillation suffers from excessive computational burdens and engineering efforts required for setting up a proper layer mapping. To address these problems, we propose a RAndom Intermediate Layer Knowledge Distillation (RAIL-KD) approach in which, intermediate layers from the teacher model are selected randomly to be distilled into the intermediate layers of the student model. This randomized selection enforce that: all teacher layers are taken into account in the training process, while reducing the computational cost of intermediate layer distillation. Also, we show that it act as a regularizer for improving the generalizability of the student model. We perform extensive experiments on GLUE tasks as well as on out-of-domain test sets. We show that our proposed RAIL-KD approach outperforms other state-of-the-art intermediate layer KD methods considerably in both performance and training-time.
Fully Automated Machine Learning Pipeline for Echocardiogram Segmentation
Jul 18, 2021
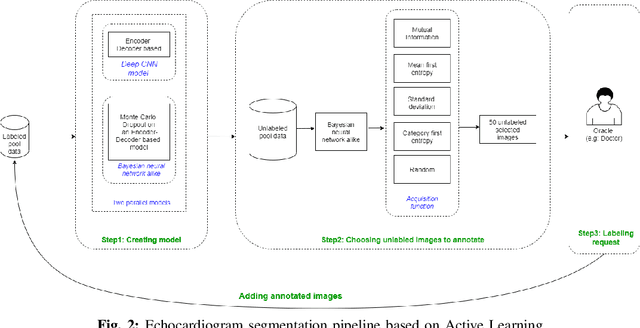
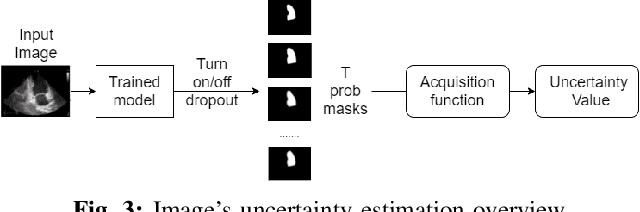
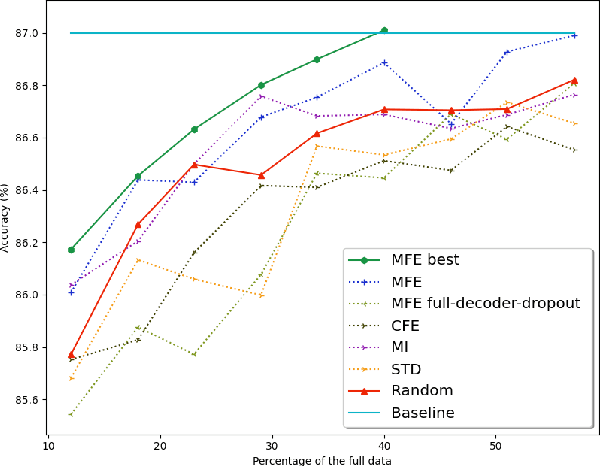
Nowadays, cardiac diagnosis largely depends on left ventricular function assessment. With the help of the segmentation deep learning model, the assessment of the left ventricle becomes more accessible and accurate. However, deep learning technique still faces two main obstacles: the difficulty in acquiring sufficient training data and time-consuming in developing quality models. In the ordinary data acquisition process, the dataset was selected randomly from a large pool of unlabeled images for labeling, leading to massive labor time to annotate those images. Besides that, hand-designed model development is laborious and also costly. This paper introduces a pipeline that relies on Active Learning to ease the labeling work and utilizes Neural Architecture Search's idea to design the adequate deep learning model automatically. We called this Fully automated machine learning pipeline for echocardiogram segmentation. The experiment results show that our method obtained the same IOU accuracy with only two-fifths of the original training dataset, and the searched model got the same accuracy as the hand-designed model given the same training dataset.
Experience feedback using Representation Learning for Few-Shot Object Detection on Aerial Images
Sep 27, 2021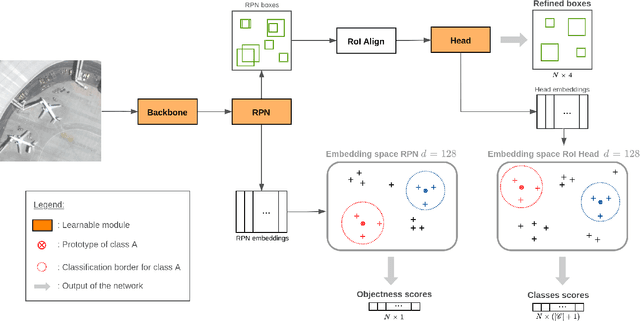
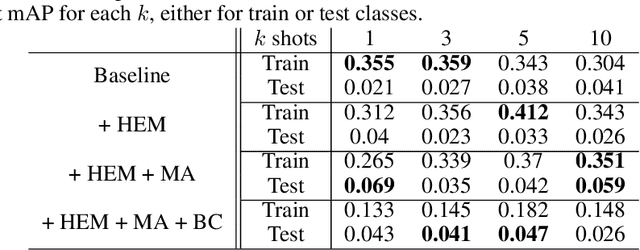
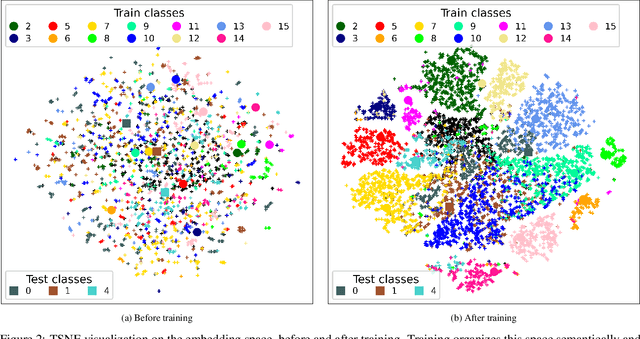
This paper proposes a few-shot method based on Faster R-CNN and representation learning for object detection in aerial images. The two classification branches of Faster R-CNN are replaced by prototypical networks for online adaptation to new classes. These networks produce embeddings vectors for each generated box, which are then compared with class prototypes. The distance between an embedding and a prototype determines the corresponding classification score. The resulting networks are trained in an episodic manner. A new detection task is randomly sampled at each epoch, consisting in detecting only a subset of the classes annotated in the dataset. This training strategy encourages the network to adapt to new classes as it would at test time. In addition, several ideas are explored to improve the proposed method such as a hard negative examples mining strategy and self-supervised clustering for background objects. The performance of our method is assessed on DOTA, a large-scale remote sensing images dataset. The experiments conducted provide a broader understanding of the capabilities of representation learning. It highlights in particular some intrinsic weaknesses for the few-shot object detection task. Finally, some suggestions and perspectives are formulated according to these insights.
Attention Gate in Traffic Forecasting
Sep 27, 2021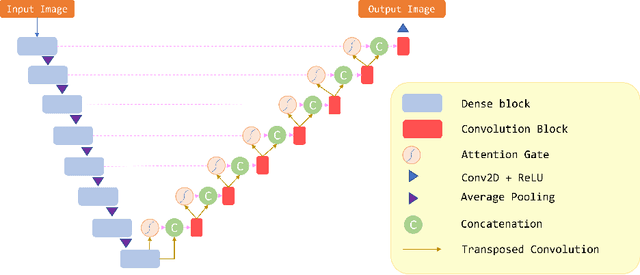
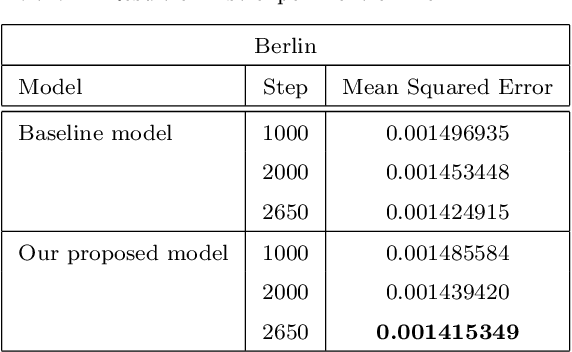
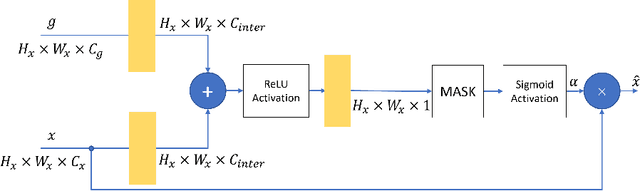
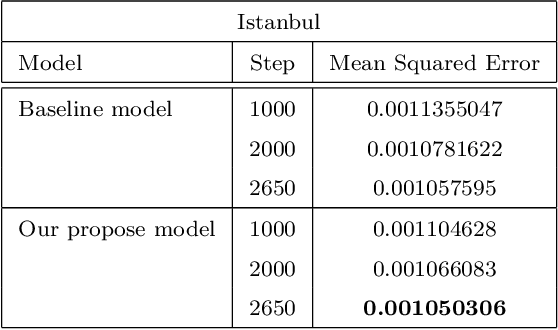
Because of increased urban complexity and growing populations, more and more challenges about predicting city-wide mobility behavior are being organized. Traffic Map Movie Forecasting Challenge 2020 is secondly held in the competition track of the Thirty-fourth Conference on Neural Information Processing Systems (NeurIPS). Similar to Traffic4Cast 2019, the task is to predict traffic flow volume, average speed in major directions on the geographical area of three big cities: Berlin, Istanbul, and Moscow. In this paper, we apply the attention mechanism on U-Net based model, especially we add an attention gate on the skip-connection between contraction path and expansion path. An attention gates filter features from the contraction path before combining with features on the expansion path, it enables our model to reduce the effect of non-traffic region features and focus more on crucial region features. In addition to the competition data, we also propose two extra features which often affect traffic flow, that are time and weekdays. We experiment with our model on the competition dataset and reproduce the winner solution in the same environment. Overall, our model archives better performance than recent methods.
ConTIG: Continuous Representation Learning on Temporal Interaction Graphs
Sep 27, 2021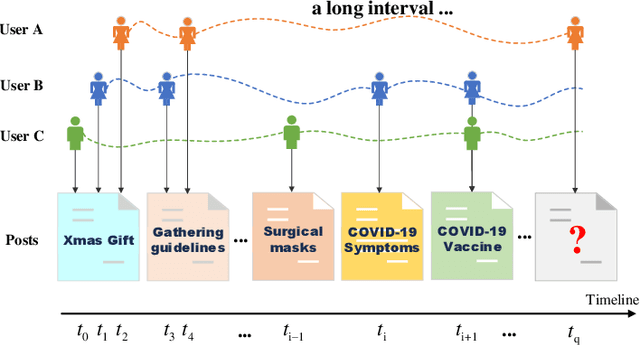
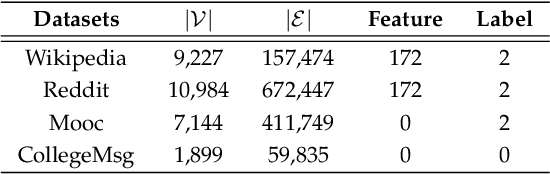
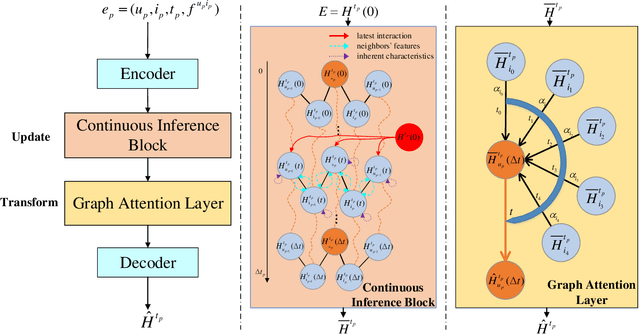
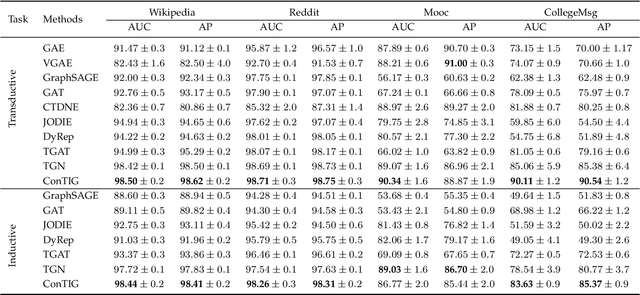
Representation learning on temporal interaction graphs (TIG) is to model complex networks with the dynamic evolution of interactions arising in a broad spectrum of problems. Existing dynamic embedding methods on TIG discretely update node embeddings merely when an interaction occurs. They fail to capture the continuous dynamic evolution of embedding trajectories of nodes. In this paper, we propose a two-module framework named ConTIG, a continuous representation method that captures the continuous dynamic evolution of node embedding trajectories. With two essential modules, our model exploit three-fold factors in dynamic networks which include latest interaction, neighbor features and inherent characteristics. In the first update module, we employ a continuous inference block to learn the nodes' state trajectories by learning from time-adjacent interaction patterns between node pairs using ordinary differential equations. In the second transform module, we introduce a self-attention mechanism to predict future node embeddings by aggregating historical temporal interaction information. Experiments results demonstrate the superiority of ConTIG on temporal link prediction, temporal node recommendation and dynamic node classification tasks compared with a range of state-of-the-art baselines, especially for long-interval interactions prediction.
Kinematically consistent recurrent neural networks for learning inverse problems in wave propagation
Oct 08, 2021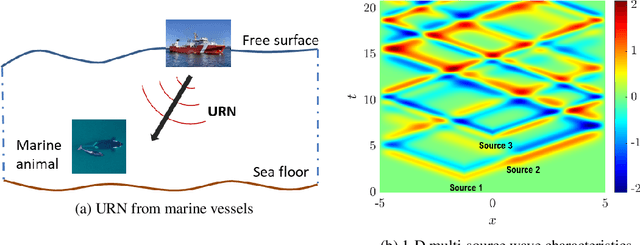


Although machine learning (ML) is increasingly employed recently for mechanistic problems, the black-box nature of conventional ML architectures lacks the physical knowledge to infer unforeseen input conditions. This implies both severe overfitting during a dearth of training data and inadequate physical interpretability, which motivates us to propose a new kinematically consistent, physics-based ML model. In particular, we attempt to perform physically interpretable learning of inverse problems in wave propagation without suffering overfitting restrictions. Towards this goal, we employ long short-term memory (LSTM) networks endowed with a physical, hyperparameter-driven regularizer, performing penalty-based enforcement of the characteristic geometries. Since these characteristics are the kinematical invariances of wave propagation phenomena, maintaining their structure provides kinematical consistency to the network. Even with modest training data, the kinematically consistent network can reduce the $L_1$ and $L_\infty$ error norms of the plain LSTM predictions by about 45% and 55%, respectively. It can also increase the horizon of the plain LSTM's forecasting by almost two times. To achieve this, an optimal range of the physical hyperparameter, analogous to an artificial bulk modulus, has been established through numerical experiments. The efficacy of the proposed method in alleviating overfitting, and the physical interpretability of the learning mechanism, are also discussed. Such an application of kinematically consistent LSTM networks for wave propagation learning is presented here for the first time.
Multi-trends Enhanced Dynamic Micro-video Recommendation
Oct 08, 2021
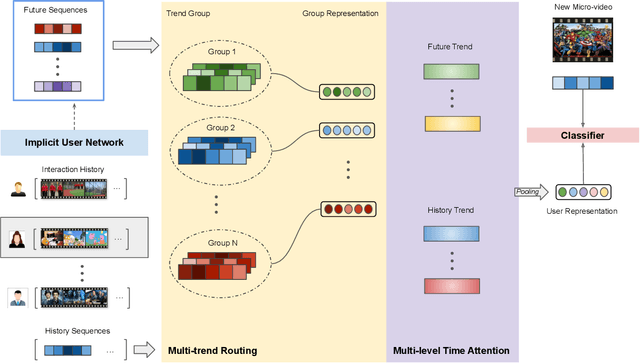
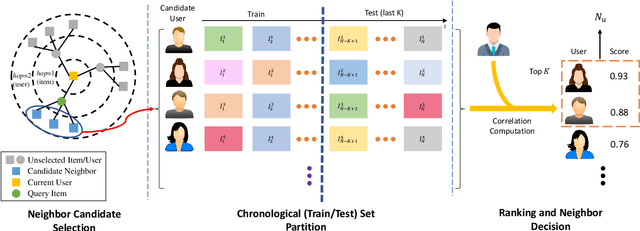

The explosively generated micro-videos on content sharing platforms call for recommender systems to permit personalized micro-video discovery with ease. Recent advances in micro-video recommendation have achieved remarkable performance in mining users' current preference based on historical behaviors. However, most of them neglect the dynamic and time-evolving nature of users' preference, and the prediction on future micro-videos with historically mined preference may deteriorate the effectiveness of recommender systems. In this paper, we propose the DMR framework to explicitly model dynamic multi-trends of users' current preference and make predictions based on both the history and future potential trends. We devise the DMR framework, which comprises: 1) the implicit user network module which identifies sequence fragments from other users with similar interests and extracts the sequence fragments that are chronologically behind the identified fragments; 2) the multi-trend routing module which assigns each extracted sequence fragment into a trend group and update the corresponding trend vector; 3) the history-future trend prediction module jointly uses the history preference vectors and future trend vectors to yield the final click-through-rate. We validate the effectiveness of DMR over multiple state-of-the-art micro-video recommenders on two publicly available real-world datasets. Relatively extensive analysis further demonstrate the superiority of modeling dynamic multi-trend for micro-video recommendation.
A Variational Perspective on Diffusion-Based Generative Models and Score Matching
Jun 05, 2021


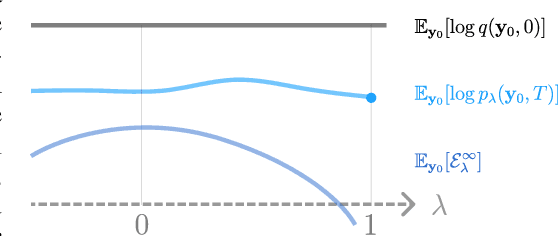
Discrete-time diffusion-based generative models and score matching methods have shown promising results in modeling high-dimensional image data. Recently, Song et al. (2021) show that diffusion processes that transform data into noise can be reversed via learning the score function, i.e. the gradient of the log-density of the perturbed data. They propose to plug the learned score function into an inverse formula to define a generative diffusion process. Despite the empirical success, a theoretical underpinning of this procedure is still lacking. In this work, we approach the (continuous-time) generative diffusion directly and derive a variational framework for likelihood estimation, which includes continuous-time normalizing flows as a special case, and can be seen as an infinitely deep variational autoencoder. Under this framework, we show that minimizing the score-matching loss is equivalent to maximizing a lower bound of the likelihood of the plug-in reverse SDE proposed by Song et al. (2021), bridging the theoretical gap.
CDSA: Cross-Dimensional Self-Attention for Multivariate, Geo-tagged Time Series Imputation
May 23, 2019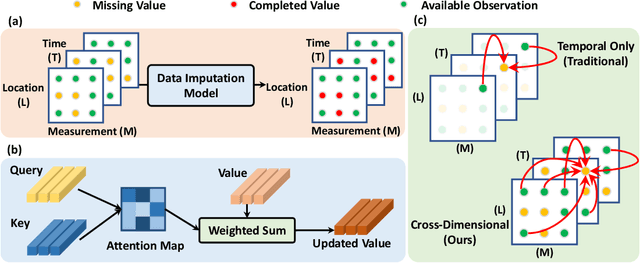

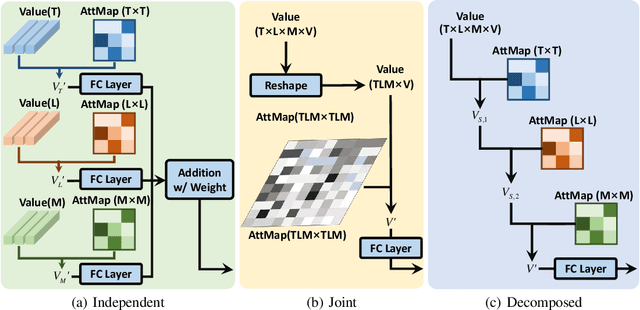
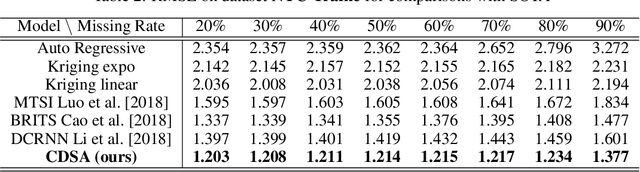
Many real-world applications involve multivariate, geo-tagged time series data: at each location, multiple sensors record corresponding measurements. For example, air quality monitoring system records PM2.5, CO, etc. The resulting time-series data often has missing values due to device outages or communication errors. In order to impute the missing values, state-of-the-art methods are built on Recurrent Neural Networks (RNN), which process each time stamp sequentially, prohibiting the direct modeling of the relationship between distant time stamps. Recently, the self-attention mechanism has been proposed for sequence modeling tasks such as machine translation, significantly outperforming RNN because the relationship between each two time stamps can be modeled explicitly. In this paper, we are the first to adapt the self-attention mechanism for multivariate, geo-tagged time series data. In order to jointly capture the self-attention across multiple dimensions, including time, location and the sensor measurements, while maintain low computational complexity, we propose a novel approach called Cross-Dimensional Self-Attention (CDSA) to process each dimension sequentially, yet in an order-independent manner. Our extensive experiments on four real-world datasets, including three standard benchmarks and our newly collected NYC-traffic dataset, demonstrate that our approach outperforms the state-of-the-art imputation and forecasting methods. A detailed systematic analysis confirms the effectiveness of our design choices.