 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Granger Causality: A Review and Recent Advances
May 07, 2021
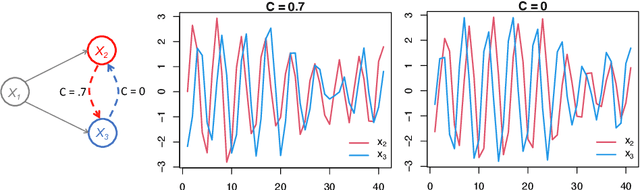
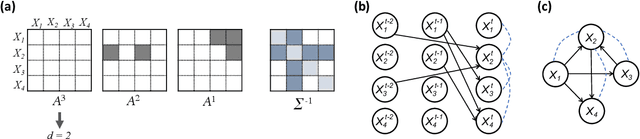
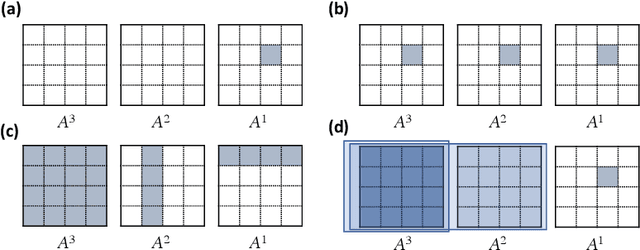
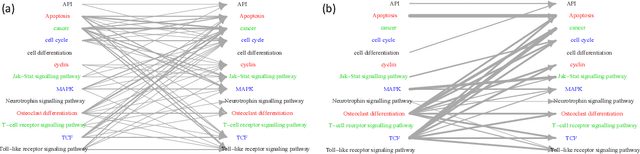
Introduced more than a half century ago, Granger causality has become a popular tool for analyzing time series data in many application domains, from economics and finance to genomics and neuroscience. Despite this popularity, the validity of this notion for inferring causal relationships among time series has remained the topic of continuous debate. Moreover, while the original definition was general, limitations in computational tools have primarily limited the applications of Granger causality to simple bivariate vector auto-regressive processes or pairwise relationships among a set of variables. Starting with a review of early developments and debates, this paper discusses recent advances that address various shortcomings of the earlier approaches, from models for high-dimensional time series to more recent developments that account for nonlinear and non-Gaussian observations and allow for sub-sampled and mixed frequency time series.
Client Selection Approach in Support of Clustered Federated Learning over Wireless Edge Networks
Aug 16, 2021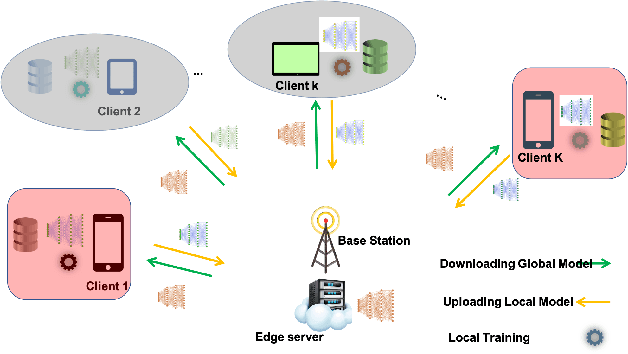
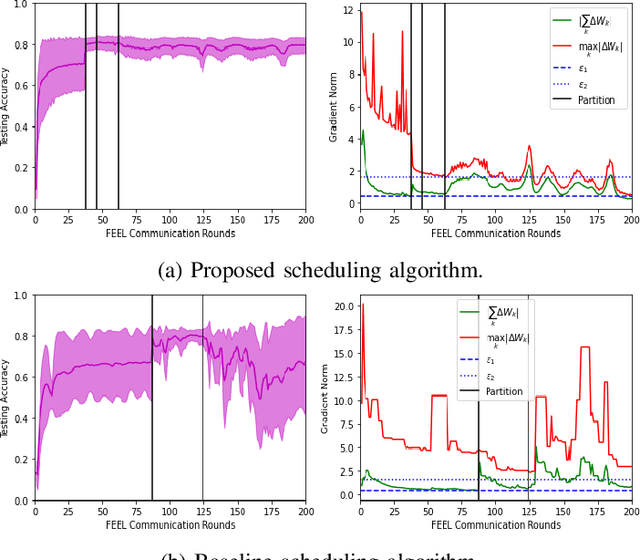
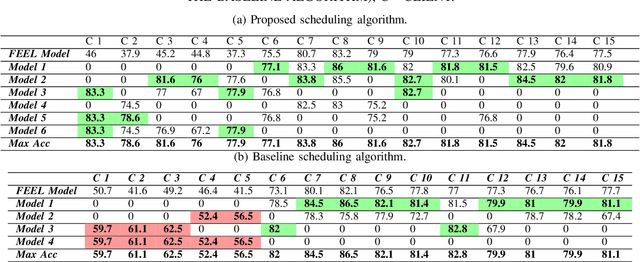
Clustered Federated Multitask Learning (CFL) was introduced as an efficient scheme to obtain reliable specialized models when data is imbalanced and distributed in a non-i.i.d. (non-independent and identically distributed) fashion amongst clients. While a similarity measure metric, like the cosine similarity, can be used to endow groups of the client with a specialized model, this process can be arduous as the server should involve all clients in each of the federated learning rounds. Therefore, it is imperative that a subset of clients is selected periodically due to the limited bandwidth and latency constraints at the network edge. To this end, this paper proposes a new client selection algorithm that aims to accelerate the convergence rate for obtaining specialized machine learning models that achieve high test accuracies for all client groups. Specifically, we introduce a client selection approach that leverages the devices' heterogeneity to schedule the clients based on their round latency and exploits the bandwidth reuse for clients that consume more time to update the model. Then, the server performs model averaging and clusters the clients based on predefined thresholds. When a specific cluster reaches a stationary point, the proposed algorithm uses a greedy scheduling algorithm for that group by selecting the clients with less latency to update the model. Extensive experiments show that the proposed approach lowers the training time and accelerates the convergence rate by up to 50% while imbuing each client with a specialized model that is fit for its local data distribution.
Enhancing Time Series Momentum Strategies Using Deep Neural Networks
Apr 09, 2019While time series momentum is a well-studied phenomenon in finance, common strategies require the explicit definition of both a trend estimator and a position sizing rule. In this paper, we introduce Deep Momentum Networks -- a hybrid approach which injects deep learning based trading rules into the volatility scaling framework of time series momentum. The model also simultaneously learns both trend estimation and position sizing in a data-driven manner, with networks directly trained by optimising the Sharpe ratio of the signal. Backtesting on a portfolio of 88 continuous futures contracts, we demonstrate that the Sharpe-optimised LSTM improved traditional methods by more than two times in the absence of transactions costs, and continue outperforming when considering transaction costs up to 2-3 basis points. To account for more illiquid assets, we also propose a turnover regularisation term which trains the network to factor in costs at run-time.
An Efficient UAV-based Artificial Intelligence Framework for Real-Time Visual Tasks
Apr 13, 2020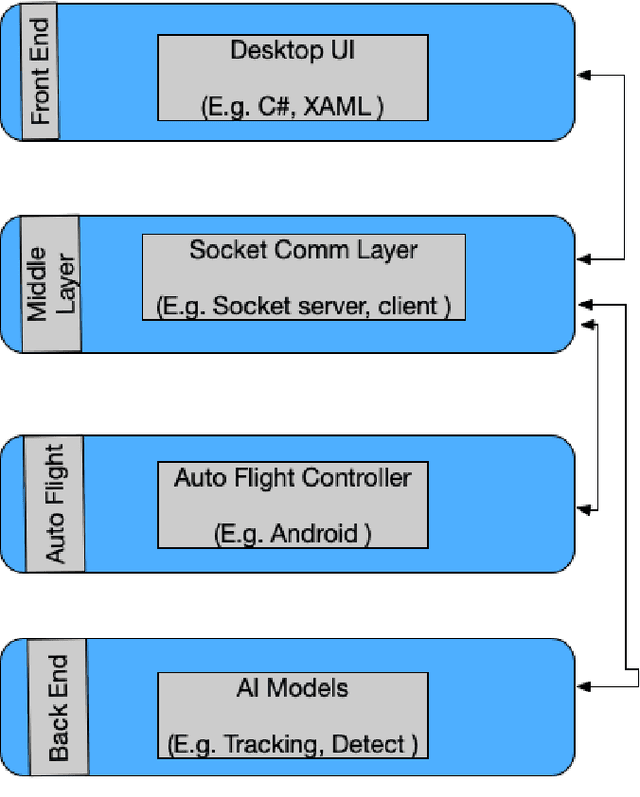
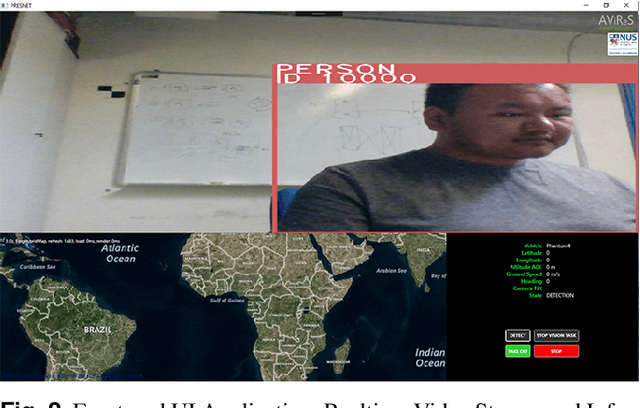
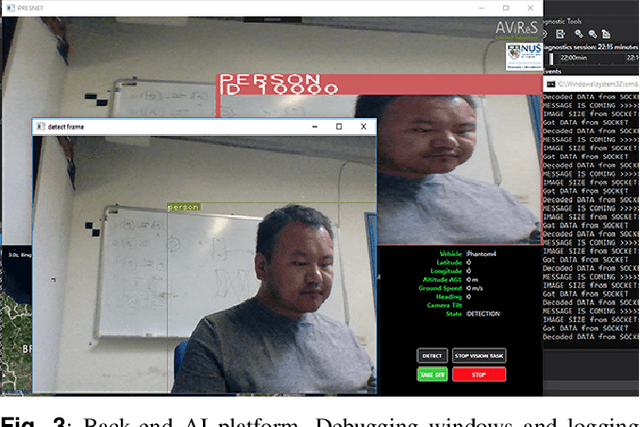
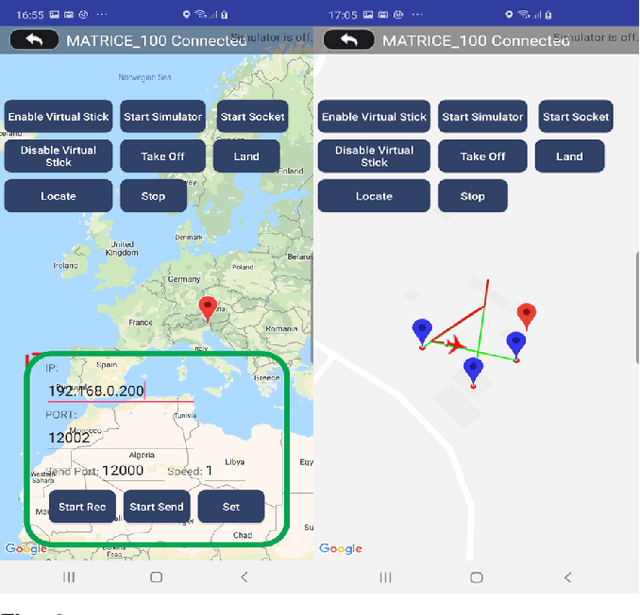
Modern Unmanned Aerial Vehicles equipped with state of the art artificial intelligence (AI) technologies are opening to a wide plethora of novel and interesting applications. While this field received a strong impact from the recent AI breakthroughs, most of the provided solutions either entirely rely on commercial software or provide a weak integration interface which denies the development of additional techniques. This leads us to propose a novel and efficient framework for the UAV-AI joint technology. Intelligent UAV systems encounter complex challenges to be tackled without human control. One of these complex challenges is to be able to carry out computer vision tasks in real-time use cases. In this paper we focus on this challenge and introduce a multi-layer AI (MLAI) framework to allow easy integration of ad-hoc visual-based AI applications. To show its features and its advantages, we implemented and evaluated different modern visual-based deep learning models for object detection, target tracking and target handover.
Rating transitions forecasting: a filtering approach
Sep 22, 2021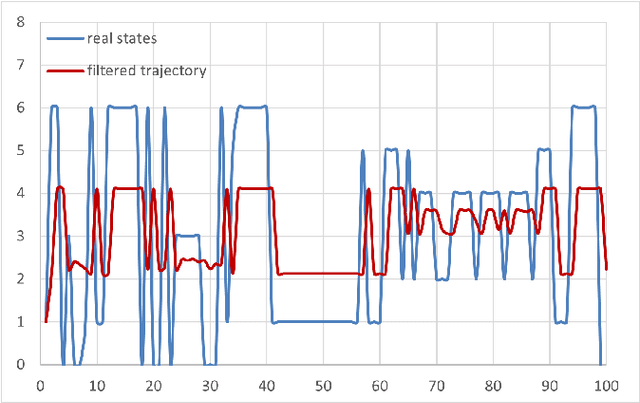
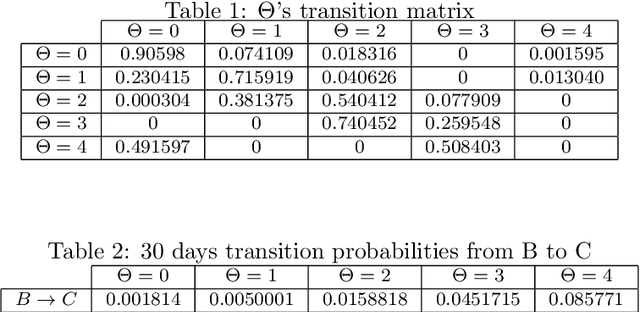
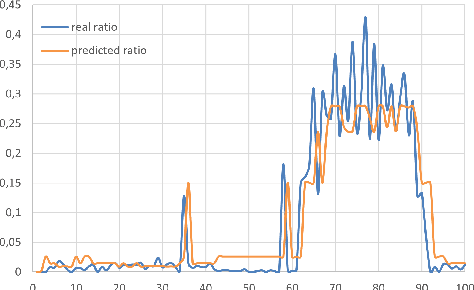
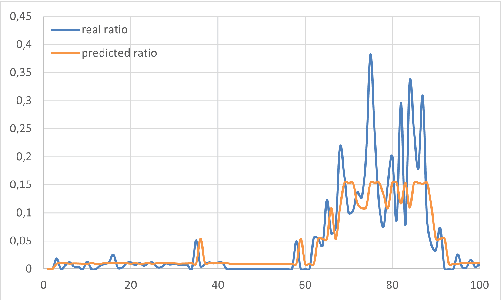
Analyzing the effect of business cycle on rating transitions has been a subject of great interest these last fifteen years, particularly due to the increasing pressure coming from regulators for stress testing. In this paper, we consider that the dynamics of rating migrations is governed by an unobserved latent factor. Under a point process filtering framework, we explain how the current state of the hidden factor can be efficiently inferred from observations of rating histories. We then adapt the classical Baum-Welsh algorithm to our setting and show how to estimate the latent factor parameters. Once calibrated, we may reveal and detect economic changes affecting the dynamics of rating migration, in real-time. To this end we adapt a filtering formula which can then be used for predicting future transition probabilities according to economic regimes without using any external covariates. We propose two filtering frameworks: a discrete and a continuous version. We demonstrate and compare the efficiency of both approaches on fictive data and on a corporate credit rating database. The methods could also be applied to retail credit loans.
Coloured noise time series as appropriate models for environmental variation in artificial evolutionary systems
Jun 29, 2020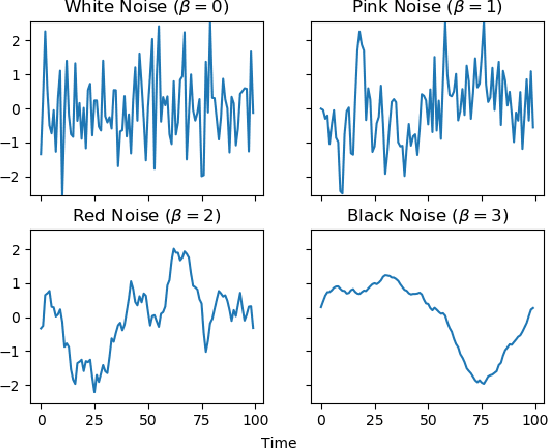
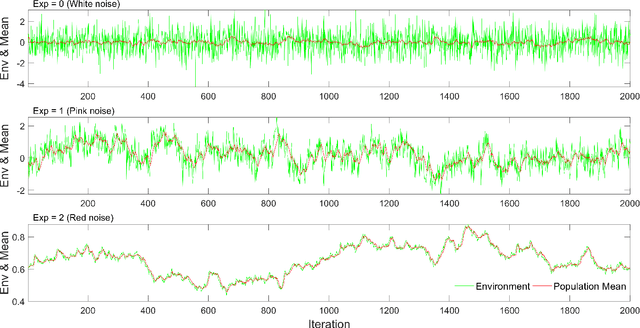
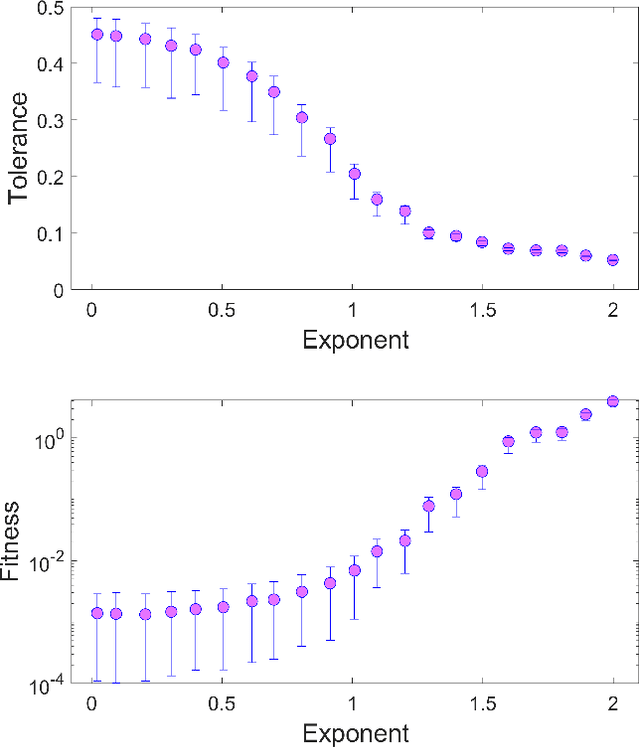
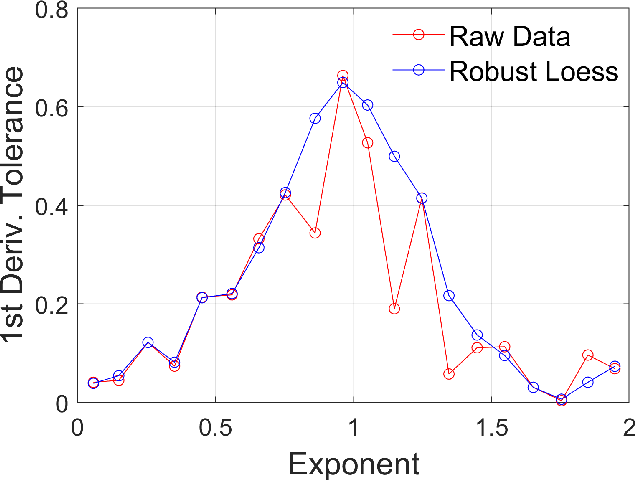
Ecological, environmental and geophysical time series consistently exhibit the characteristics of coloured (1/f^\b{eta}) noise. Here we briefly survey the literature on coloured noise, population persistence and related evolutionary dynamics, before introducing coloured noise as an appropriate model for environmental variation in artificial evolutionary systems. To illustrate and explore the effects of different noise colours, a simple evolutionary model that examines the trade-off between specialism and generalism in fluctuating environments is applied. The results of the model clearly demonstrate a need for greater generalism as environmental variability becomes `whiter', whilst specialisation is favoured as environmental variability becomes `redder'. Pink noise, sitting midway between white and red noise, is shown to be the point at which the pressures for generalism and specialism balance, providing some insight in to why `pinker' noise is increasingly being seen as an appropriate model of typical environmental variability. We go on to discuss how the results presented here feed in to a wider discussion on evolutionary responses to fluctuating environments. Ultimately we argue that Artificial Life as a field should embrace the use of coloured noise to produce models of environmental variability.
A Variational Perspective on Diffusion-Based Generative Models and Score Matching
Jun 05, 2021


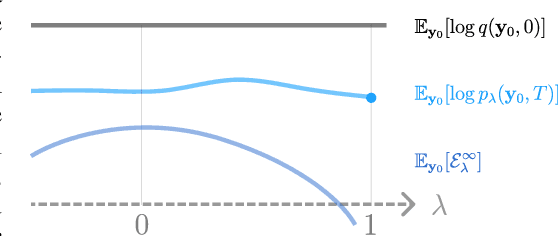
Discrete-time diffusion-based generative models and score matching methods have shown promising results in modeling high-dimensional image data. Recently, Song et al. (2021) show that diffusion processes that transform data into noise can be reversed via learning the score function, i.e. the gradient of the log-density of the perturbed data. They propose to plug the learned score function into an inverse formula to define a generative diffusion process. Despite the empirical success, a theoretical underpinning of this procedure is still lacking. In this work, we approach the (continuous-time) generative diffusion directly and derive a variational framework for likelihood estimation, which includes continuous-time normalizing flows as a special case, and can be seen as an infinitely deep variational autoencoder. Under this framework, we show that minimizing the score-matching loss is equivalent to maximizing a lower bound of the likelihood of the plug-in reverse SDE proposed by Song et al. (2021), bridging the theoretical gap.
Word2Pix: Word to Pixel Cross Attention Transformer in Visual Grounding
Jul 31, 2021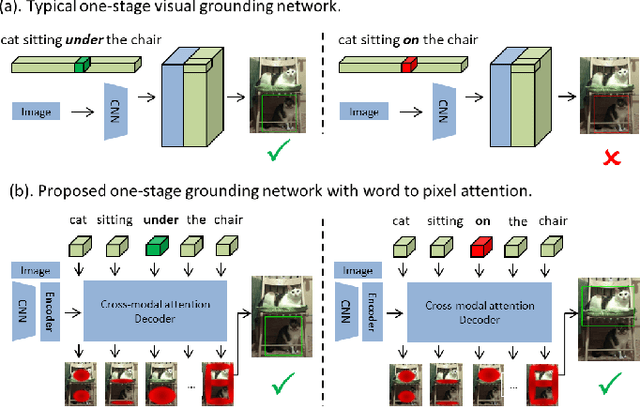
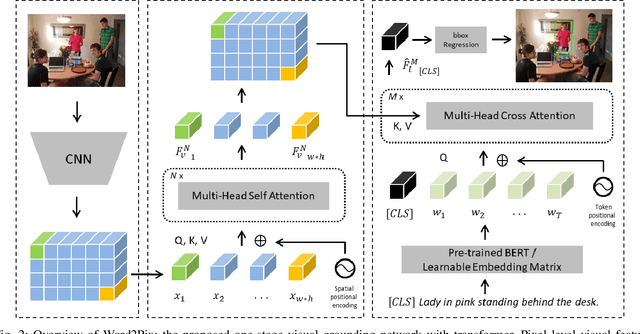

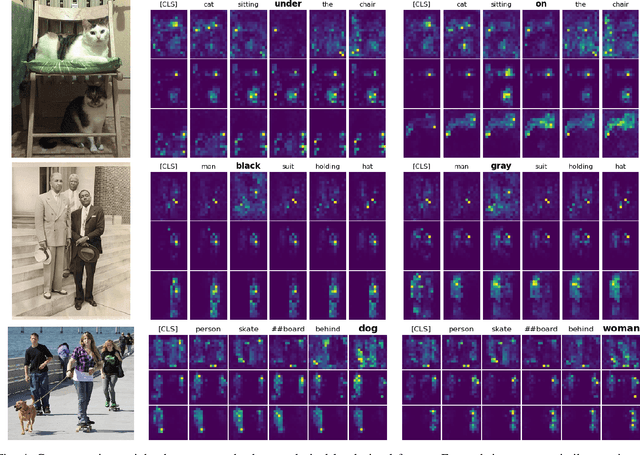
Current one-stage methods for visual grounding encode the language query as one holistic sentence embedding before fusion with visual feature. Such a formulation does not treat each word of a query sentence on par when modeling language to visual attention, therefore prone to neglect words which are less important for sentence embedding but critical for visual grounding. In this paper we propose Word2Pix: a one-stage visual grounding network based on encoder-decoder transformer architecture that enables learning for textual to visual feature correspondence via word to pixel attention. The embedding of each word from the query sentence is treated alike by attending to visual pixels individually instead of single holistic sentence embedding. In this way, each word is given equivalent opportunity to adjust the language to vision attention towards the referent target through multiple stacks of transformer decoder layers. We conduct the experiments on RefCOCO, RefCOCO+ and RefCOCOg datasets and the proposed Word2Pix outperforms existing one-stage methods by a notable margin. The results obtained also show that Word2Pix surpasses two-stage visual grounding models, while at the same time keeping the merits of one-stage paradigm namely end-to-end training and real-time inference speed intact.
A Closer Look at Prototype Classifier for Few-shot Image Classification
Oct 14, 2021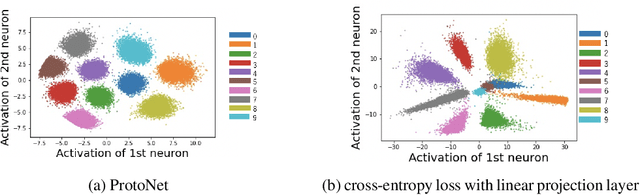
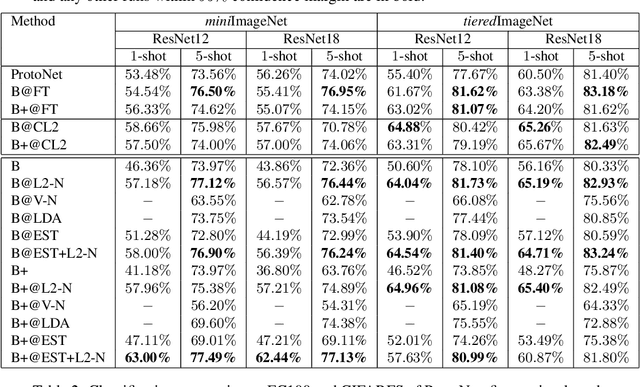
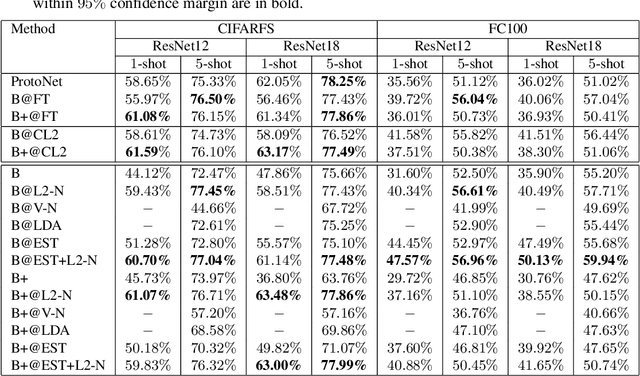
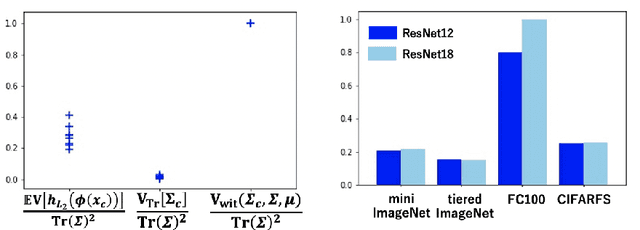
The prototypical network is a prototype classifier based on meta-learning and is widely used for few-shot learning because it classifies unseen examples by constructing class-specific prototypes without adjusting hyper-parameters during meta-testing. Interestingly, recent research has attracted a lot of attention, showing that a linear classifier with fine-tuning, which does not use a meta-learning algorithm, performs comparably with the prototypical network. However, fine-tuning requires additional hyper-parameters when adapting a model to a new environment. In addition, although the purpose of few-shot learning is to enable the model to quickly adapt to a new environment, fine-tuning needs to be applied every time a new class appears, making fast adaptation difficult. In this paper, we analyze how a prototype classifier works equally well without fine-tuning and meta-learning. We experimentally found that directly using the feature vector extracted using standard pre-trained models to construct a prototype classifier in meta-testing does not perform as well as the prototypical network and linear classifiers with fine-tuning and feature vectors of pre-trained models. Thus, we derive a novel generalization bound for the prototypical network and show that focusing on the variance of the norm of a feature vector can improve performance. We experimentally investigated several normalization methods for minimizing the variance of the norm and found that the same performance can be obtained by using the L2 normalization and embedding space transformation without fine-tuning or meta-learning.
LoGG3D-Net: Locally Guided Global Descriptor Learning for 3D Place Recognition
Sep 22, 2021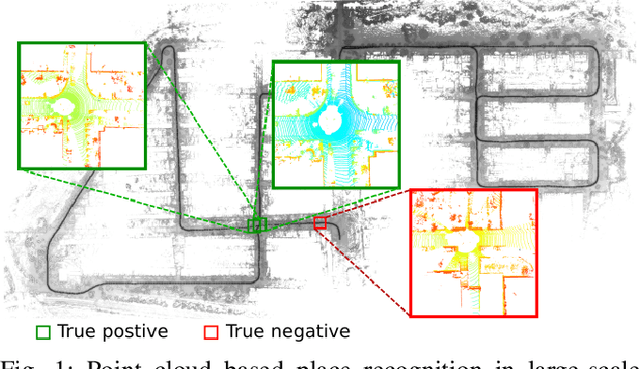
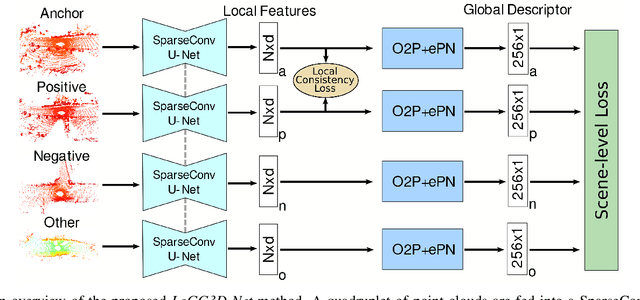
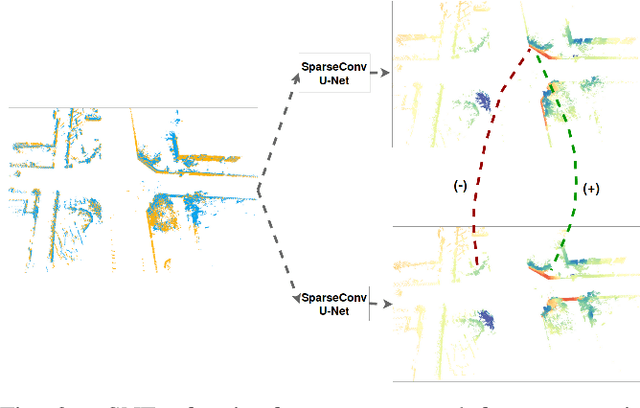
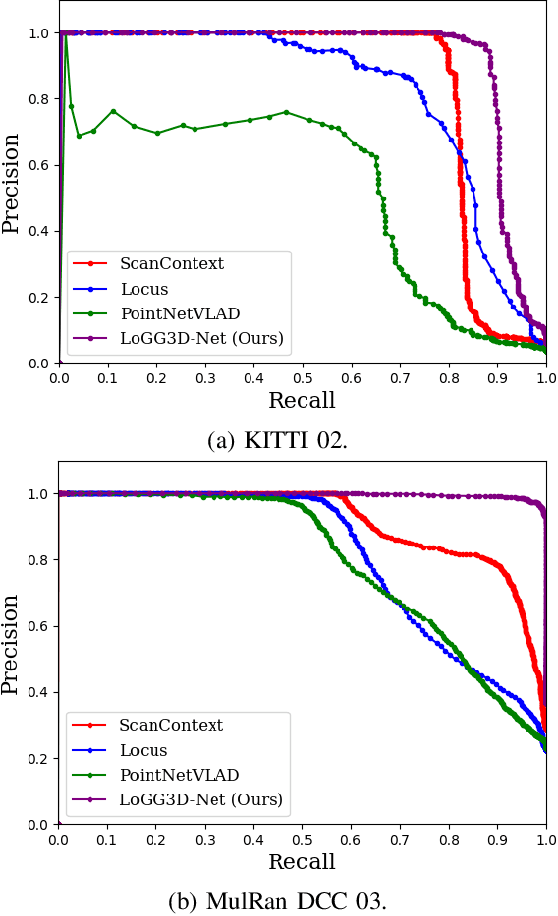
Retrieval-based place recognition is an efficient and effective solution for enabling re-localization within a pre-built map or global data association for Simultaneous Localization and Mapping (SLAM). The accuracy of such an approach is heavily dependent on the quality of the extracted scene-level representation. While end-to-end solutions, which learn a global descriptor from input point clouds, have demonstrated promising results, such approaches are limited in their ability to enforce desirable properties at the local feature level. In this paper, we demonstrate that the inclusion of an additional training signal (local consistency loss) can guide the network to learning local features which are consistent across revisits, hence leading to more repeatable global descriptors resulting in an overall improvement in place recognition performance. We formulate our approach in an end-to-end trainable architecture called LoGG3D-Net. Experiments on two large-scale public benchmarks (KITTI and MulRan) show that our method achieves mean $F1_{max}$ scores of $0.939$ and $0.968$ on KITTI and MulRan, respectively while operating in near real-time.