 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Temporal Pattern Attention for Multivariate Time Series Forecasting
Sep 12, 2018
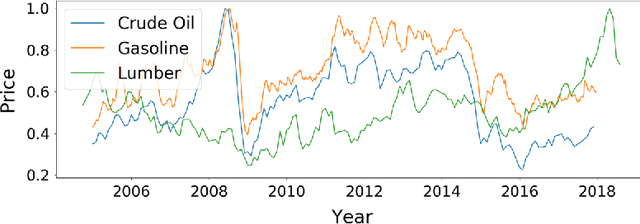
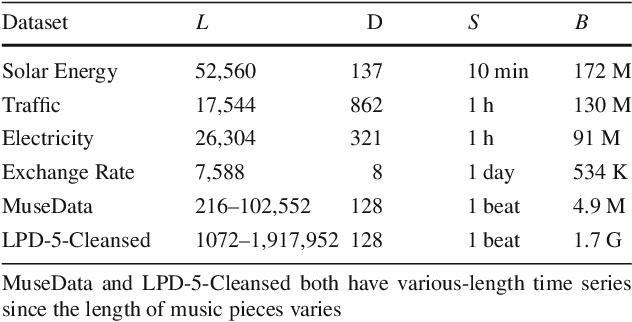
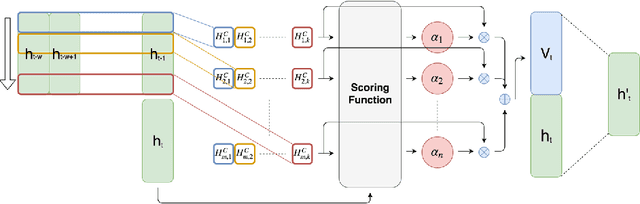
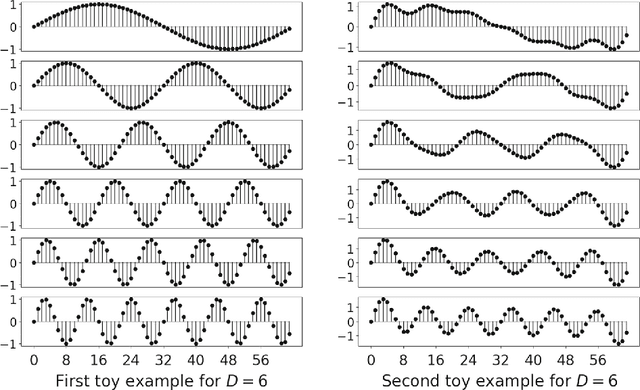
Forecasting multivariate time series data, such as prediction of electricity consumption, solar power production, and polyphonic piano pieces, has numerous valuable applications. However, complex and non-linear interdependencies between time steps and series complicate the task. To obtain accurate prediction, it is crucial to model long-term dependency in time series data, which can be achieved to some good extent by recurrent neural network (RNN) with attention mechanism. Typical attention mechanism reviews the information at each previous time step and selects the relevant information to help generate the outputs, but it fails to capture the temporal patterns across multiple time steps. In this paper, we propose to use a set of filters to extract time-invariant temporal patterns, which is similar to transforming time series data into its "frequency domain". Then we proposed a novel attention mechanism to select relevant time series, and use its "frequency domain" information for forecasting. We applied the proposed model on several real-world tasks and achieved the state-of-the-art performance in all of them with only one exception. We also show that to some degree the learned filters play the role of bases in discrete Fourier transform.
Blindness (Diabetic Retinopathy) Severity Scale Detection
Oct 04, 2021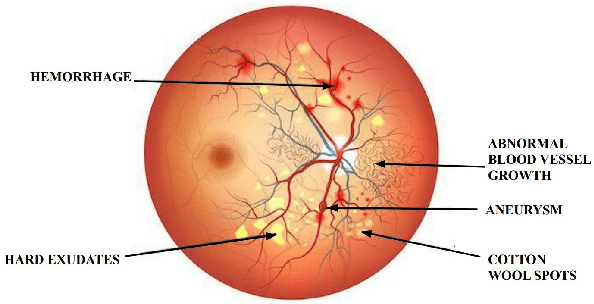

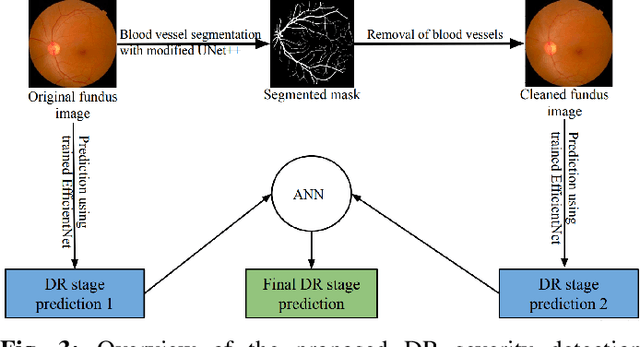
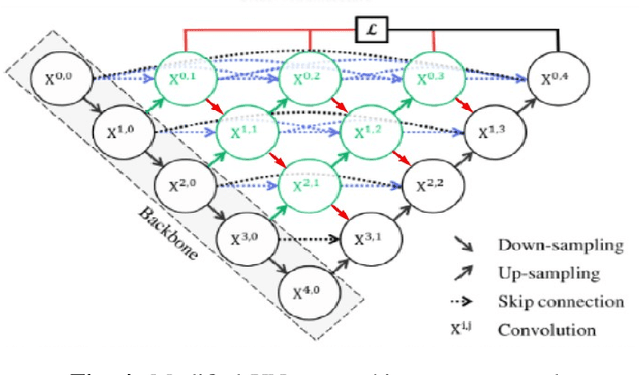
Diabetic retinopathy (DR) is a severe complication of diabetes that can cause permanent blindness. Timely diagnosis and treatment of DR are critical to avoid total loss of vision. Manual diagnosis is time consuming and error-prone. In this paper, we propose a novel deep learning based method for automatic screening of retinal fundus images to detect and classify DR based on the severity. The method uses a dual-path configuration of deep neural networks to achieve the objective. In the first step, a modified UNet++ based retinal vessel segmentation is used to create a fundus image that emphasises elements like haemorrhages, cotton wool spots, and exudates that are vital to identify the DR stages. Subsequently, two convolutional neural networks (CNN) classifiers take the original image and the newly created fundus image respectively as inputs and identify the severity of DR on a scale of 0 to 4. These two scores are then passed through a shallow neural network classifier (ANN) to predict the final DR stage. The public datasets STARE, DRIVE, CHASE DB1, and APTOS are used for training and evaluation. Our method achieves an accuracy of 94.80% and Quadratic Weighted Kappa (QWK) score of 0.9254, and outperform many state-of-the-art methods.
Signal Acquisition of Luojia-1A Low Earth Orbit Navigation Augmentation System with Software Defined Receiver
May 31, 2021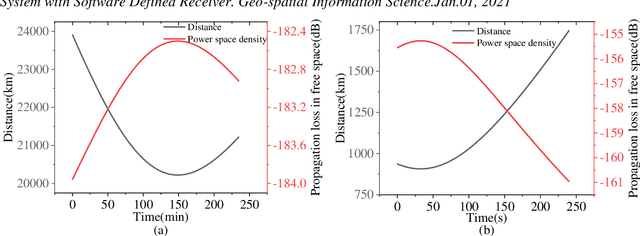
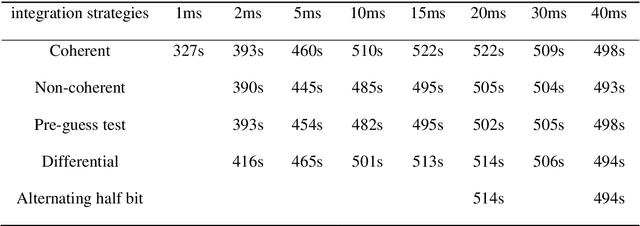
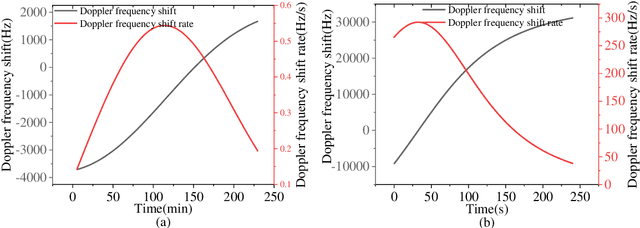
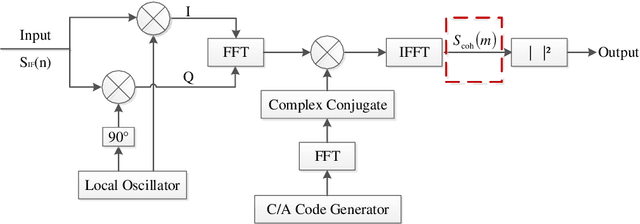
Low earth orbit (LEO) satellite navigation signal can be used as an opportunity signal in case of a Global navigation satellite system (GNSS) outage, or as an enhancement means of traditional GNSS positioning algorithms. No matter which service mode is used, signal acquisition is the prerequisite of providing enhanced LEO navigation service. Compared with the medium orbit satellite, the transit time of the LEO satellite is shorter. Thus, it is of great significance to expand the successful acquisition time range of the LEO signal. Previous studies on LEO signal acquisition are based on simulation data. However, signal acquisition research based on real data is very important. In this work, the signal characteristics of LEO satellite: power space density in free space and the Doppler shift of LEO satellite are individually studied. The unified symbol definitions of several integration algorithms based on the parallel search signal acquisition algorithm are given. To verify these algorithms for LEO signal acquisition, a software-defined receiver (SDR) is developed. The performance of those integration algorithms on expanding the successful acquisition time range is verified by the real data collected from the Luojia-1A satellite. The experimental results show that the integration strategy can expand the successful acquisition time range, and it will not expand indefinitely with the integration duration.
Towards Multi-Agent Reinforcement Learning using Quantum Boltzmann Machines
Sep 22, 2021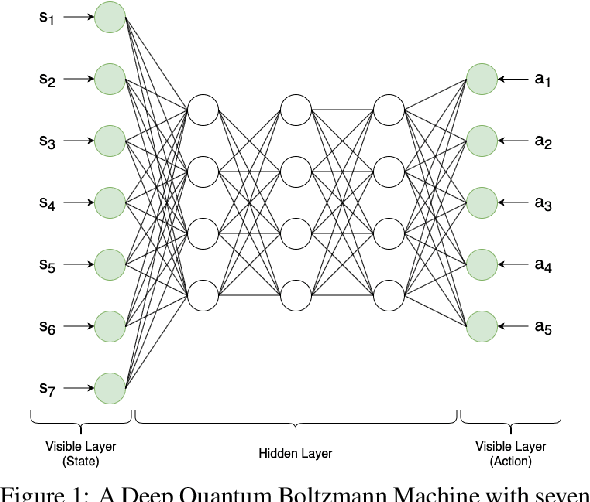
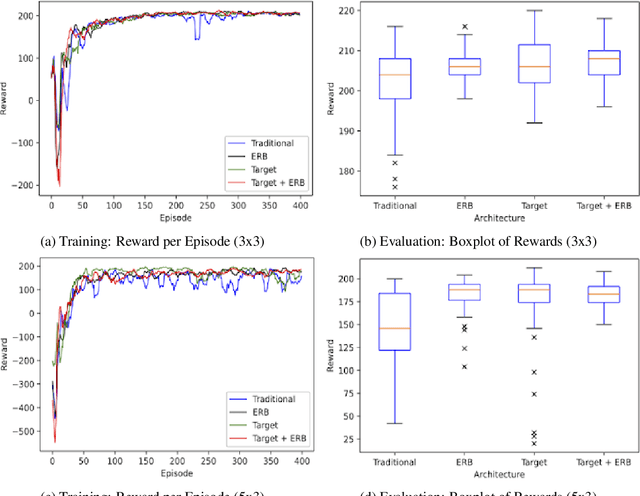
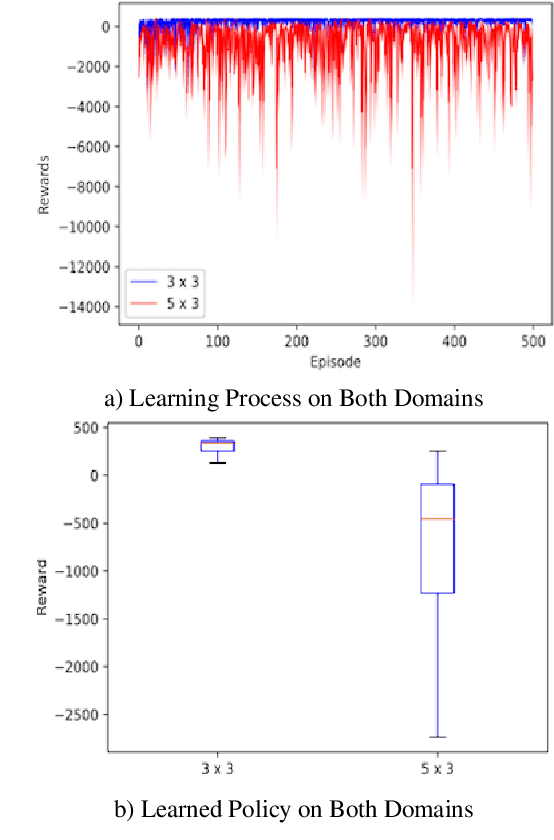
Reinforcement learning has driven impressive advances in machine learning. Simultaneously, quantum-enhanced machine learning algorithms using quantum annealing underlie heavy developments. Recently, a multi-agent reinforcement learning (MARL) architecture combining both paradigms has been proposed. This novel algorithm, which utilizes Quantum Boltzmann Machines (QBMs) for Q-value approximation has outperformed regular deep reinforcement learning in terms of time-steps needed to converge. However, this algorithm was restricted to single-agent and small 2x2 multi-agent grid domains. In this work, we propose an extension to the original concept in order to solve more challenging problems. Similar to classic DQNs, we add an experience replay buffer and use different networks for approximating the target and policy values. The experimental results show that learning becomes more stable and enables agents to find optimal policies in grid-domains with higher complexity. Additionally, we assess how parameter sharing influences the agents behavior in multi-agent domains. Quantum sampling proves to be a promising method for reinforcement learning tasks, but is currently limited by the QPU size and therefore by the size of the input and Boltzmann machine.
Mapping and Validating a Point Neuron Model on Intel's Neuromorphic Hardware Loihi
Sep 22, 2021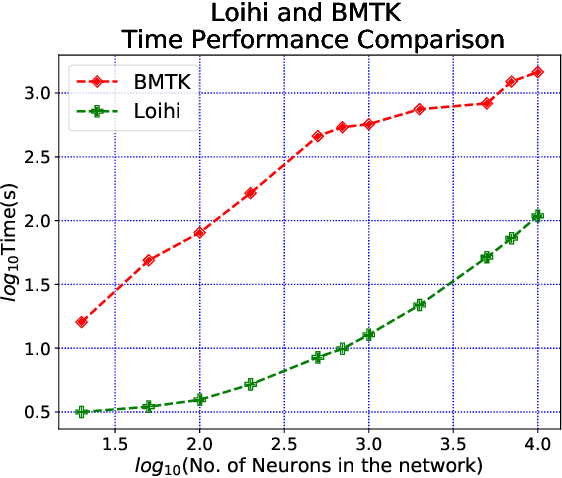
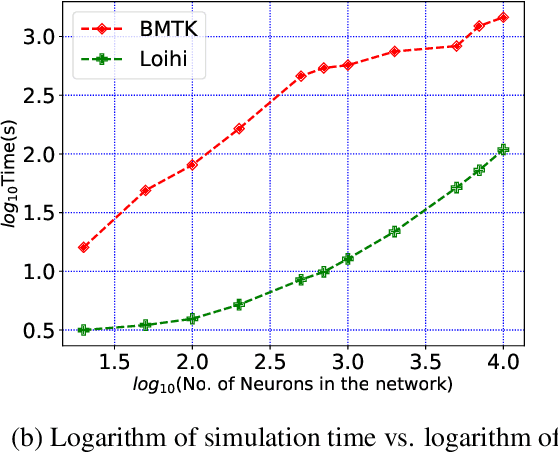
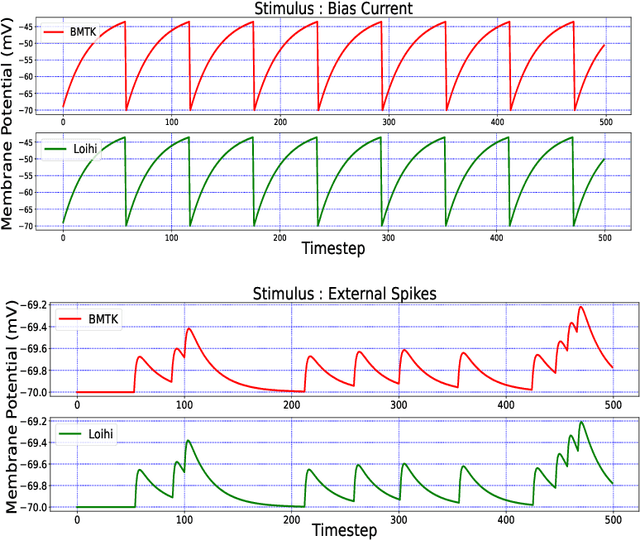
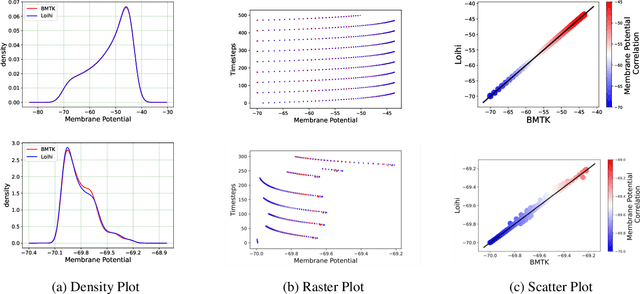
Neuromorphic hardware is based on emulating the natural biological structure of the brain. Since its computational model is similar to standard neural models, it could serve as a computational acceleration for research projects in the field of neuroscience and artificial intelligence, including biomedical applications. However, in order to exploit this new generation of computer chips, rigorous simulation and consequent validation of brain-based experimental data is imperative. In this work, we investigate the potential of Intel's fifth generation neuromorphic chip - `Loihi', which is based on the novel idea of Spiking Neural Networks (SNNs) emulating the neurons in the brain. The work is implemented in context of simulating the Leaky Integrate and Fire (LIF) models based on the mouse primary visual cortex matched to a rich data set of anatomical, physiological and behavioral constraints. Simulations on the classical hardware serve as the validation platform for the neuromorphic implementation. We find that Loihi replicates classical simulations very efficiently and scales notably well in terms of both time and energy performance as the networks get larger.
Two-Stage Deep Learning for Accelerated 3D Time-of-Flight MRA without Matched Training Data
Aug 04, 2020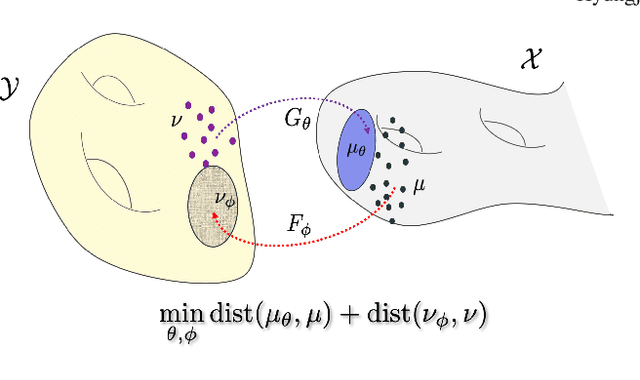
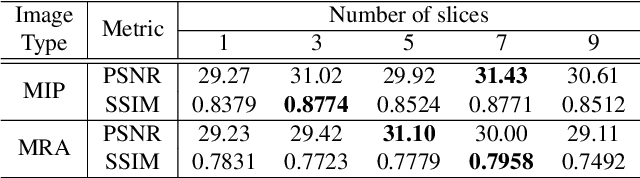
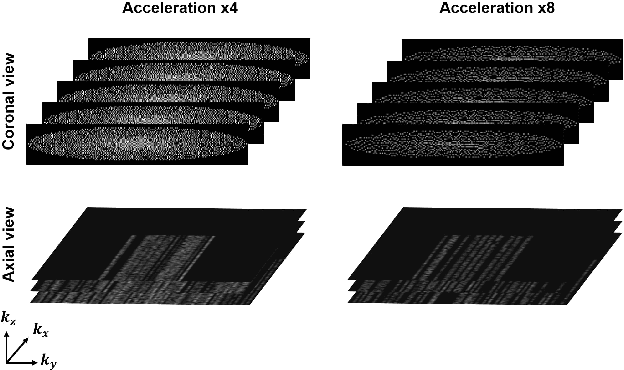
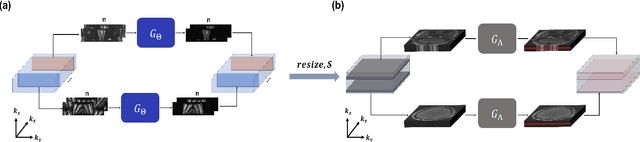
Time-of-flight magnetic resonance angiography (TOF-MRA) is one of the most widely used non-contrast MR imaging methods to visualize blood vessels, but due to the 3-D volume acquisition highly accelerated acquisition is necessary. Accordingly, high quality reconstruction from undersampled TOF-MRA is an important research topic for deep learning. However, most existing deep learning works require matched reference data for supervised training, which are often difficult to obtain. By extending the recent theoretical understanding of cycleGAN from the optimal transport theory, here we propose a novel two-stage unsupervised deep learning approach, which is composed of the multi-coil reconstruction network along the coronal plane followed by a multi-planar refinement network along the axial plane. Specifically, the first network is trained in the square-root of sum of squares (SSoS) domain to achieve high quality parallel image reconstruction, whereas the second refinement network is designed to efficiently learn the characteristics of highly-activated blood flow using double-headed max-pool discriminator. Extensive experiments demonstrate that the proposed learning process without matched reference exceeds performance of state-of-the-art compressed sensing (CS)-based method and provides comparable or even better results than supervised learning approaches.
How Different Text-preprocessing Techniques Using The BERT Model Affect The Gender Profiling of Authors
Sep 28, 2021

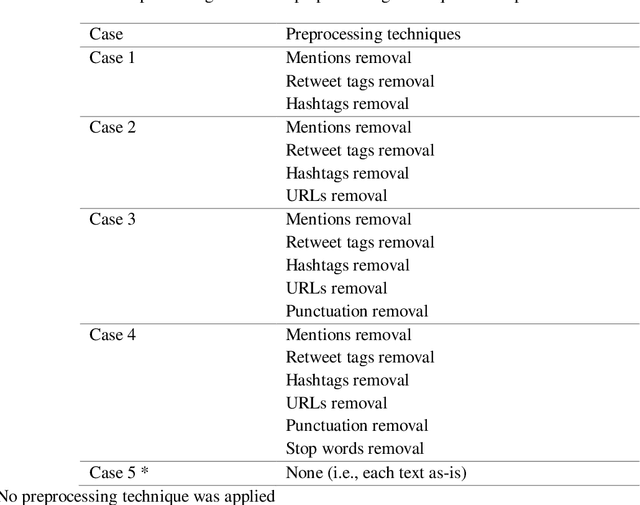

Forensic author profiling plays an important role in indicating possible profiles for suspects. Among the many automated solutions recently proposed for author profiling, transfer learning outperforms many other state-of-the-art techniques in natural language processing. Nevertheless, the sophisticated technique has yet to be fully exploited for author profiling. At the same time, whereas current methods of author profiling, all largely based on features engineering, have spawned significant variation in each model used, transfer learning usually requires a preprocessed text to be fed into the model. We reviewed multiple references in the literature and determined the most common preprocessing techniques associated with authors' genders profiling. Considering the variations in potential preprocessing techniques, we conducted an experimental study that involved applying five such techniques to measure each technique's effect while using the BERT model, chosen for being one of the most-used stock pretrained models. We used the Hugging face transformer library to implement the code for each preprocessing case. In our five experiments, we found that BERT achieves the best accuracy in predicting the gender of the author when no preprocessing technique is applied. Our best case achieved 86.67% accuracy in predicting the gender of authors.
DECAF: Deep Extreme Classification with Label Features
Aug 01, 2021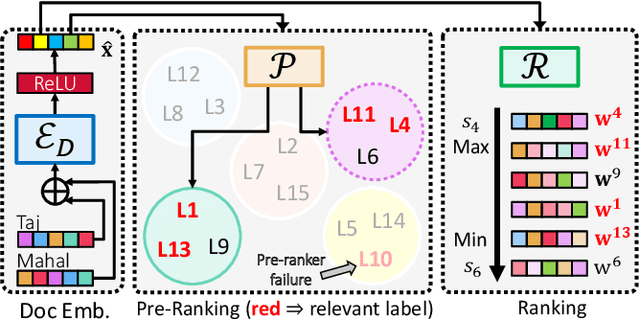
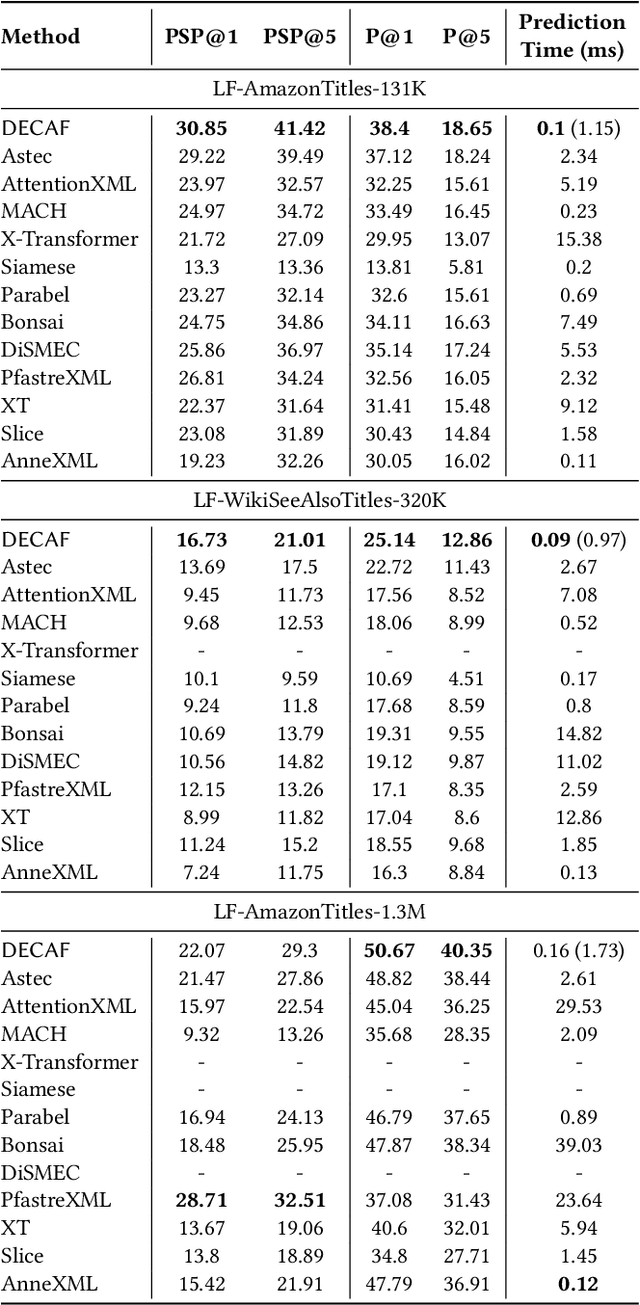
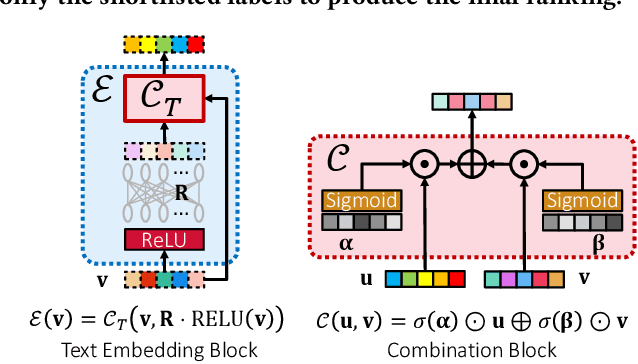
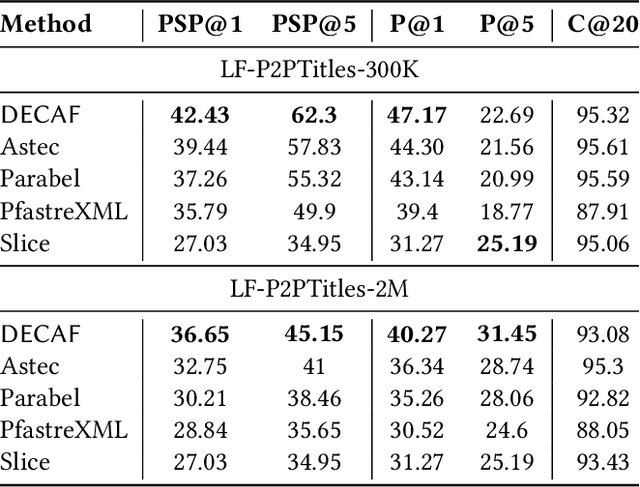
Extreme multi-label classification (XML) involves tagging a data point with its most relevant subset of labels from an extremely large label set, with several applications such as product-to-product recommendation with millions of products. Although leading XML algorithms scale to millions of labels, they largely ignore label meta-data such as textual descriptions of the labels. On the other hand, classical techniques that can utilize label metadata via representation learning using deep networks struggle in extreme settings. This paper develops the DECAF algorithm that addresses these challenges by learning models enriched by label metadata that jointly learn model parameters and feature representations using deep networks and offer accurate classification at the scale of millions of labels. DECAF makes specific contributions to model architecture design, initialization, and training, enabling it to offer up to 2-6% more accurate prediction than leading extreme classifiers on publicly available benchmark product-to-product recommendation datasets, such as LF-AmazonTitles-1.3M. At the same time, DECAF was found to be up to 22x faster at inference than leading deep extreme classifiers, which makes it suitable for real-time applications that require predictions within a few milliseconds. The code for DECAF is available at the following URL https://github.com/Extreme-classification/DECAF.
Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting
Jun 24, 2021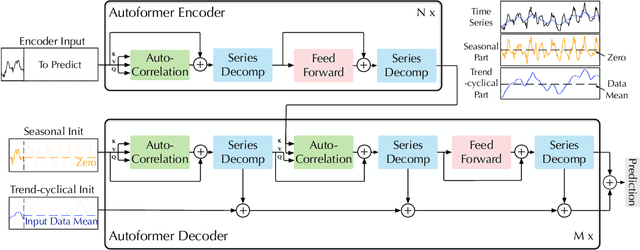
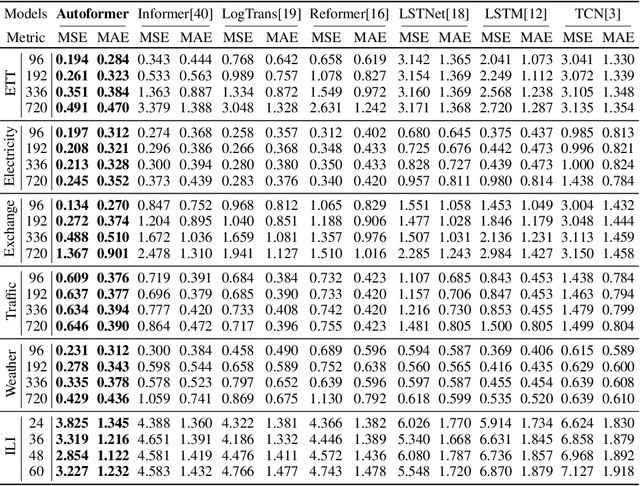
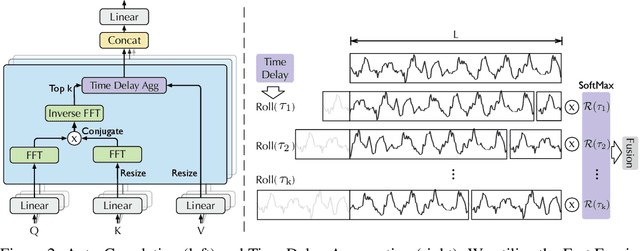
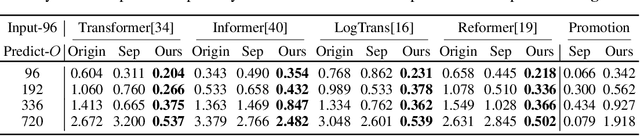
Extending the forecasting time is a critical demand for real applications, such as extreme weather early warning and long-term energy consumption planning. This paper studies the \textit{long-term forecasting} problem of time series. Prior Transformer-based models adopt various self-attention mechanisms to discover the long-range dependencies. However, intricate temporal patterns of the long-term future prohibit the model from finding reliable dependencies. Also, Transformers have to adopt the sparse versions of point-wise self-attentions for long series efficiency, resulting in the information utilization bottleneck. Towards these challenges, we propose Autoformer as a novel decomposition architecture with an Auto-Correlation mechanism. We go beyond the pre-processing convention of series decomposition and renovate it as a basic inner block of deep models. This design empowers Autoformer with progressive decomposition capacities for complex time series. Further, inspired by the stochastic process theory, we design the Auto-Correlation mechanism based on the series periodicity, which conducts the dependencies discovery and representation aggregation at the sub-series level. Auto-Correlation outperforms self-attention in both efficiency and accuracy. In long-term forecasting, Autoformer yields state-of-the-art accuracy, with a 38% relative improvement on six benchmarks, covering five practical applications: energy, traffic, economics, weather and disease.
Faster Improvement Rate Population Based Training
Sep 28, 2021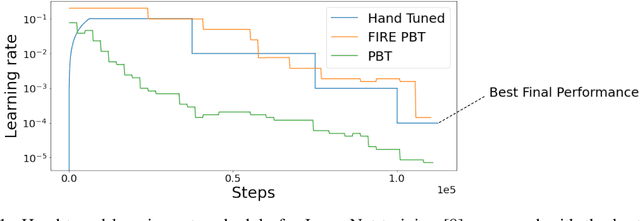
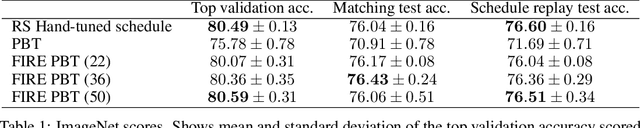
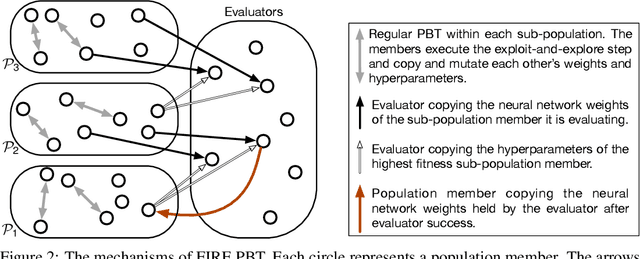
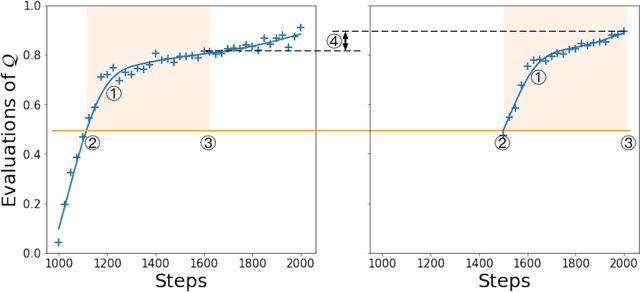
The successful training of neural networks typically involves careful and time consuming hyperparameter tuning. Population Based Training (PBT) has recently been proposed to automate this process. PBT trains a population of neural networks concurrently, frequently mutating their hyperparameters throughout their training. However, the decision mechanisms of PBT are greedy and favour short-term improvements which can, in some cases, lead to poor long-term performance. This paper presents Faster Improvement Rate PBT (FIRE PBT) which addresses this problem. Our method is guided by an assumption: given two neural networks with similar performance and training with similar hyperparameters, the network showing the faster rate of improvement will lead to a better final performance. Using this, we derive a novel fitness metric and use it to make some of the population members focus on long-term performance. Our experiments show that FIRE PBT is able to outperform PBT on the ImageNet benchmark and match the performance of networks that were trained with a hand-tuned learning rate schedule. We apply FIRE PBT to reinforcement learning tasks and show that it leads to faster learning and higher final performance than both PBT and random hyperparameter search.