 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Temporal Registration in Application to In-utero MRI Time Series
Mar 06, 2019
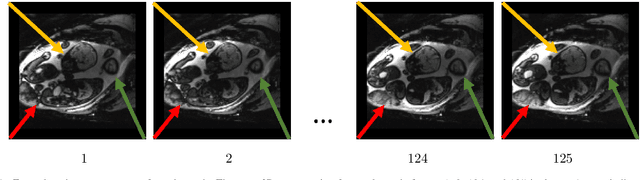
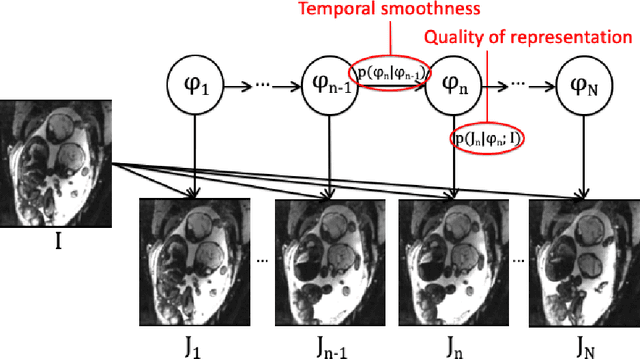
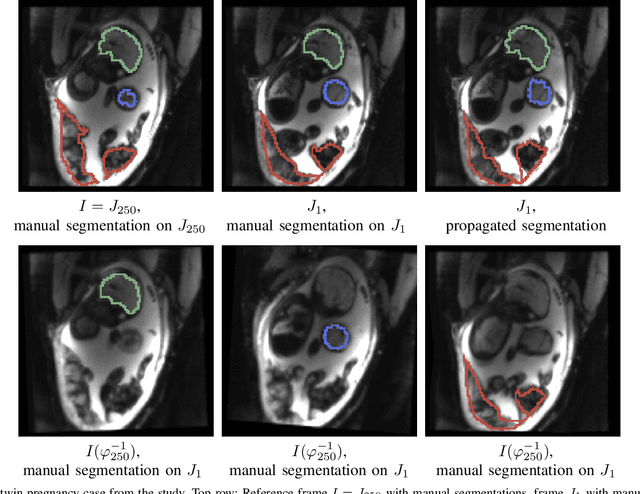
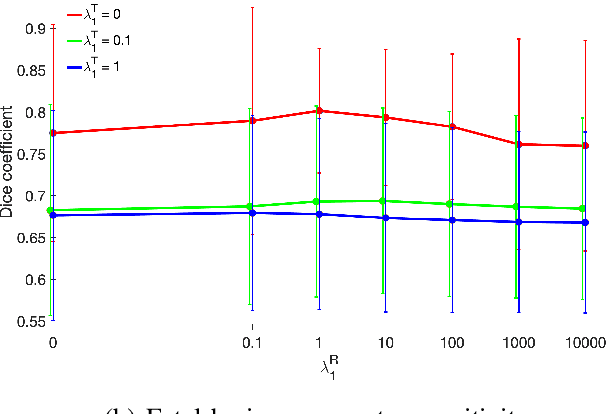
We present a robust method to correct for motion in volumetric in-utero MRI time series. Time-course analysis for in-utero volumetric MRI time series often suffers from substantial and unpredictable fetal motion. Registration provides voxel correspondences between images and is commonly employed for motion correction. Current registration methods often fail when aligning images that are substantially different from a template (reference image). To achieve accurate and robust alignment, we make a Markov assumption on the nature of motion and take advantage of the temporal smoothness in the image data. Forward message passing in the corresponding hidden Markov model (HMM) yields an estimation algorithm that only has to account for relatively small motion between consecutive frames. We evaluate the utility of the temporal model in the context of in-utero MRI time series alignment by examining the accuracy of propagated segmentation label maps. Our results suggest that the proposed model captures accurately the temporal dynamics of transformations in in-utero MRI time series.
DeepScale: An Online Frame Size Adaptation Framework to Accelerate Visual Multi-object Tracking
Jul 22, 2021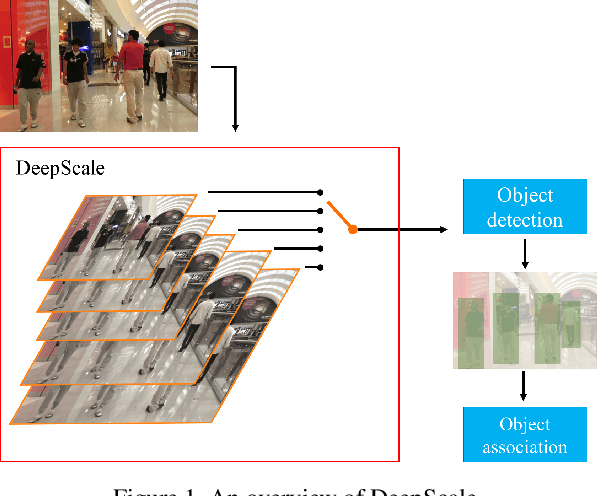

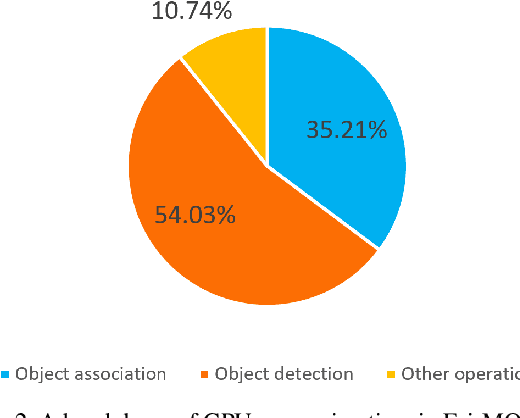
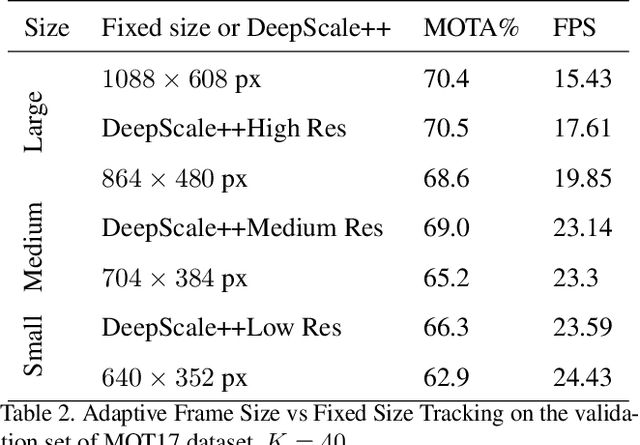
In surveillance and search and rescue applications, it is important to perform multi-target tracking (MOT) in real-time on low-end devices. Today's MOT solutions employ deep neural networks, which tend to have high computation complexity. Recognizing the effects of frame sizes on tracking performance, we propose DeepScale, a model agnostic frame size selection approach that operates on top of existing fully convolutional network-based trackers to accelerate tracking throughput. In the training stage, we incorporate detectability scores into a one-shot tracker architecture so that DeepScale can learn representation estimations for different frame sizes in a self-supervised manner. During inference, based on user-controlled parameters, it can find a suitable trade-off between tracking accuracy and speed by adapting frame sizes at run time. Extensive experiments and benchmark tests on MOT datasets demonstrate the effectiveness and flexibility of DeepScale. Compared to a state-of-the-art tracker, DeepScale++, a variant of DeepScale achieves 1.57X accelerated with only moderate degradation (~ 2.4) in tracking accuracy on the MOT15 dataset in one configuration.
Benchmarking the Combinatorial Generalizability of Complex Query Answering on Knowledge Graphs
Sep 18, 2021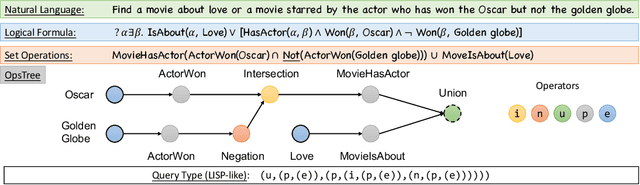
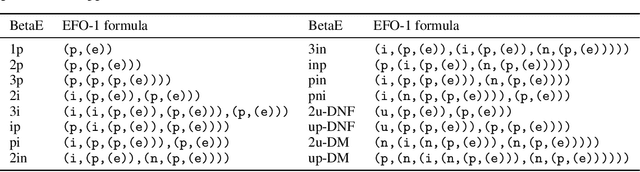

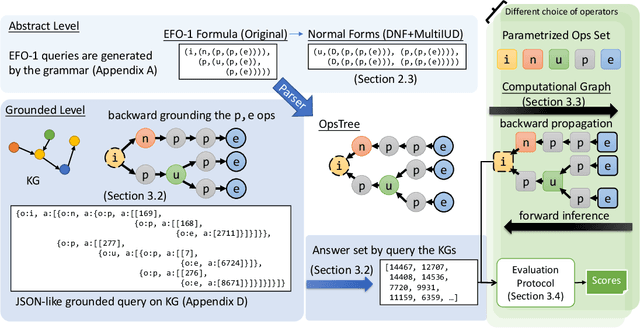
Complex Query Answering (CQA) is an important reasoning task on knowledge graphs. Current CQA learning models have been shown to be able to generalize from atomic operators to more complex formulas, which can be regarded as the combinatorial generalizability. In this paper, we present EFO-1-QA, a new dataset to benchmark the combinatorial generalizability of CQA models by including 301 different queries types, which is 20 times larger than existing datasets. Besides, our work, for the first time, provides a benchmark to evaluate and analyze the impact of different operators and normal forms by using (a) 7 choices of the operator systems and (b) 9 forms of complex queries. Specifically, we provide the detailed study of the combinatorial generalizability of two commonly used operators, i.e., projection and intersection, and justify the impact of the forms of queries given the canonical choice of operators. Our code and data can provide an effective pipeline to benchmark CQA models.
Multi Agent System for Machine Learning Under Uncertainty in Cyber Physical Manufacturing System
Jul 28, 2021



Recent advancements in predictive machine learning has led to its application in various use cases in manufacturing. Most research focused on maximising predictive accuracy without addressing the uncertainty associated with it. While accuracy is important, focusing primarily on it poses an overfitting danger, exposing manufacturers to risk, ultimately hindering the adoption of these techniques. In this paper, we determine the sources of uncertainty in machine learning and establish the success criteria of a machine learning system to function well under uncertainty in a cyber-physical manufacturing system (CPMS) scenario. Then, we propose a multi-agent system architecture which leverages probabilistic machine learning as a means of achieving such criteria. We propose possible scenarios for which our proposed architecture is useful and discuss future work. Experimentally, we implement Bayesian Neural Networks for multi-tasks classification on a public dataset for the real-time condition monitoring of a hydraulic system and demonstrate the usefulness of the system by evaluating the probability of a prediction being accurate given its uncertainty. We deploy these models using our proposed agent-based framework and integrate web visualisation to demonstrate its real-time feasibility.
ML-aided power allocation for Tactical MIMO
Sep 14, 2021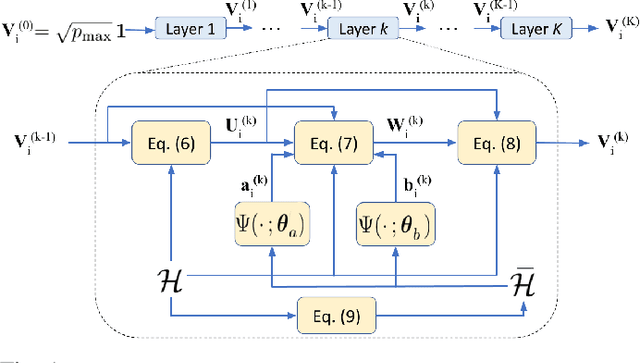
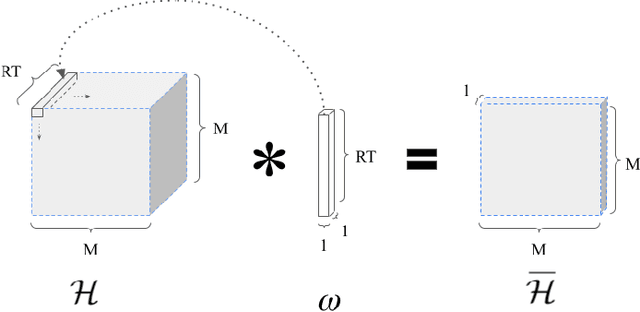
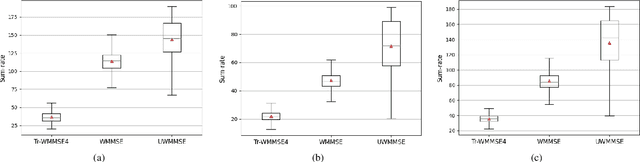
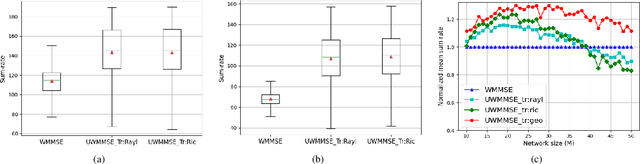
We study the problem of optimal power allocation in single-hop multi-antenna ad-hoc wireless networks. A standard technique to solve this problem involves optimizing a tri-convex function under power constraints using a block-coordinate-descent (BCD) based iterative algorithm. This approach, termed WMMSE, tends to be computationally complex and time consuming. Several learning-based approaches have been proposed to speed up the power allocation process. A recent work, UWMMSE, learns an affine transformation of a WMMSE parameter in an unfolded structure to accelerate convergence. In spite of achieving promising results, its application is limited to single-antenna wireless networks. In this work, we present a UWMMSE framework for power allocation in (multiple-input multiple-output) MIMO interference networks. Through an empirical study, we illustrate the superiority of our approach in comparison to WMMSE and also analyze its robustness to changes in channel conditions and network size.
Noise-Resistant Deep Metric Learning with Probabilistic Instance Filtering
Aug 03, 2021
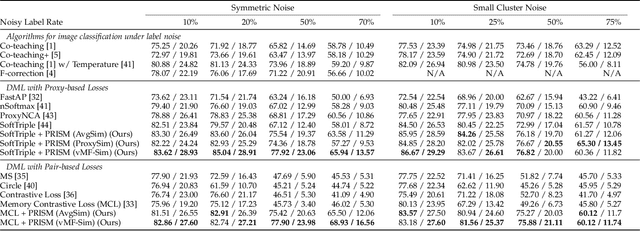
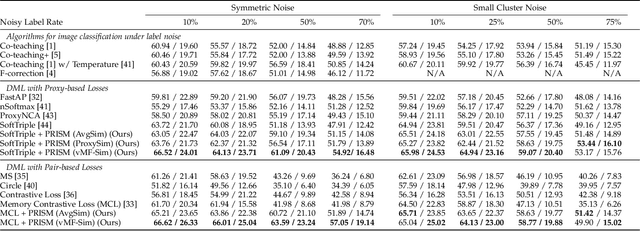
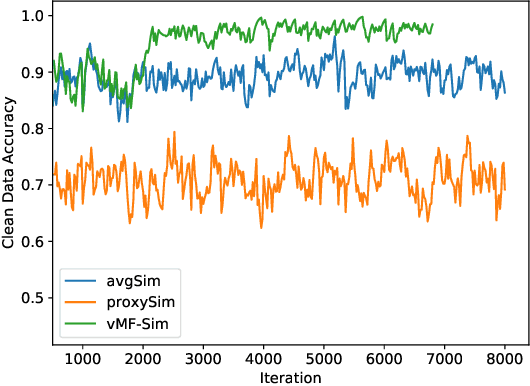
Noisy labels are commonly found in real-world data, which cause performance degradation of deep neural networks. Cleaning data manually is labour-intensive and time-consuming. Previous research mostly focuses on enhancing classification models against noisy labels, while the robustness of deep metric learning (DML) against noisy labels remains less well-explored. In this paper, we bridge this important gap by proposing Probabilistic Ranking-based Instance Selection with Memory (PRISM) approach for DML. PRISM calculates the probability of a label being clean, and filters out potentially noisy samples. Specifically, we propose three methods to calculate this probability: 1) Average Similarity Method (AvgSim), which calculates the average similarity between potentially noisy data and clean data; 2) Proxy Similarity Method (ProxySim), which replaces the centers maintained by AvgSim with the proxies trained by proxy-based method; and 3) von Mises-Fisher Distribution Similarity (vMF-Sim), which estimates a von Mises-Fisher distribution for each data class. With such a design, the proposed approach can deal with challenging DML situations in which the majority of the samples are noisy. Extensive experiments on both synthetic and real-world noisy dataset show that the proposed approach achieves up to 8.37% higher Precision@1 compared with the best performing state-of-the-art baseline approaches, within reasonable training time.
IPN Hand: A Video Dataset and Benchmark for Real-Time Continuous Hand Gesture Recognition
Apr 20, 2020


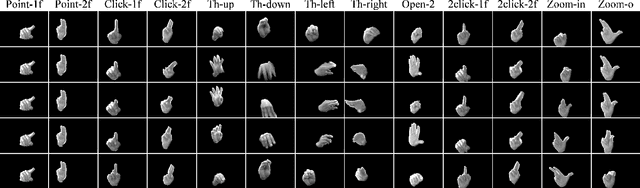
In the research community of continuous hand gesture recognition (HGR), the current publicly available datasets lack real-world elements needed to build responsive and efficient HGR systems. In this paper, we introduce a new benchmark dataset named IPN Hand with sufficient size, variation, and real-world elements able to train and evaluate deep neural networks. This dataset contains more than 4 000 gesture samples and 800 000 RGB frames from 50 distinct subjects. We design 13 different static and dynamic gestures focused on interaction with touchless screens. We especially consider the scenario when continuous gestures are performed without transition states, and when subjects perform natural movements with their hands as non-gesture actions. Gestures were collected from about 30 diverse scenes, with real-world variation in background and illumination. With our dataset, the performance of three 3D-CNN models is evaluated on the tasks of isolated and continuous real-time HGR. Furthermore, we analyze the possibility of increasing the recognition accuracy by adding multiple modalities derived from RGB frames, i.e., optical flow and semantic segmentation, while keeping the real-time performance of the 3D-CNN model. Our empirical study also provides a comparison with the publicly available nvGesture (NVIDIA) dataset. The experimental results show that the state-of-the-art ResNext-101 model decreases about 30% accuracy when using our real-world dataset, demonstrating that the IPN Hand dataset can be used as a benchmark, and may help the community to step forward in the continuous HGR. Our dataset and pre-trained models used in the evaluation are publicly available at https://github.com/GibranBenitez/IPN-hand.
Time Matters in Using Data Augmentation for Vision-based Deep Reinforcement Learning
Feb 17, 2021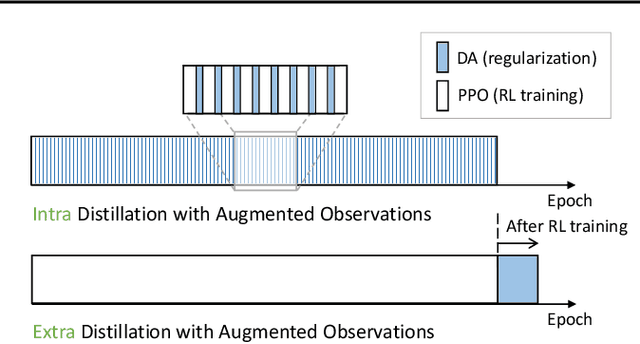
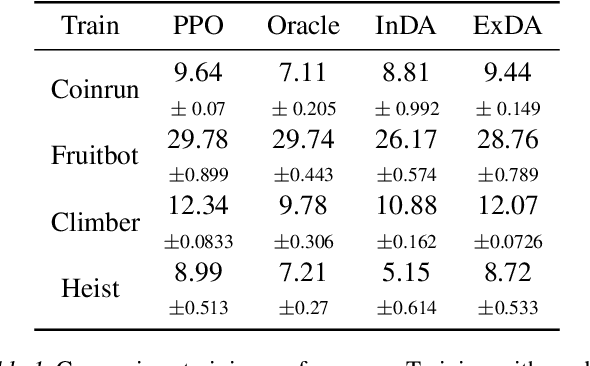
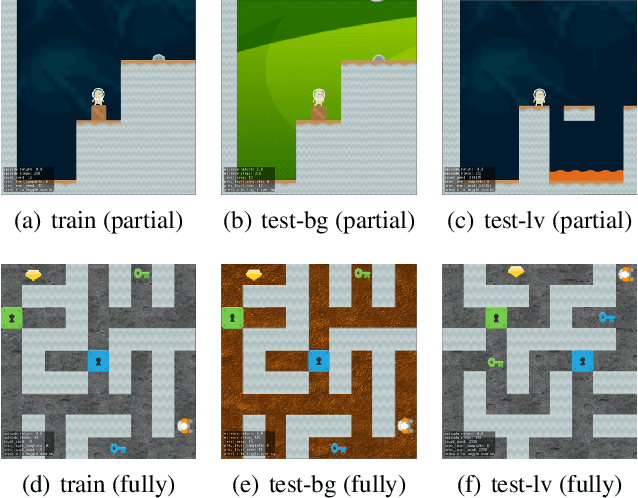
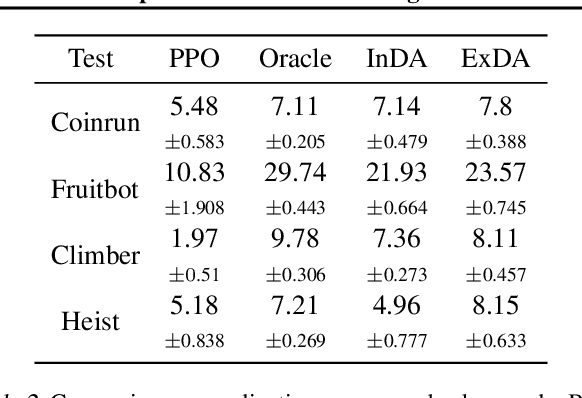
Data augmentation technique from computer vision has been widely considered as a regularization method to improve data efficiency and generalization performance in vision-based reinforcement learning. We variate the timing of using augmentation, which is, in turn, critical depending on tasks to be solved in training and testing. According to our experiments on Open AI Procgen Benchmark, if the regularization imposed by augmentation is helpful only in testing, it is better to procrastinate the augmentation after training than to use it during training in terms of sample and computation complexity. We note that some of such augmentations can disturb the training process. Conversely, an augmentation providing regularization useful in training needs to be used during the whole training period to fully utilize its benefit in terms of not only generalization but also data efficiency. These phenomena suggest a useful timing control of data augmentation in reinforcement learning.
Interactive Learning for Identifying Relevant Tweets to Support Real-time Situational Awareness
Aug 01, 2019
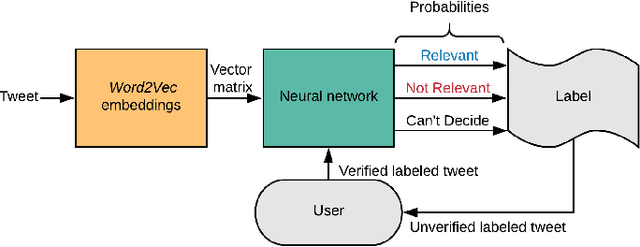
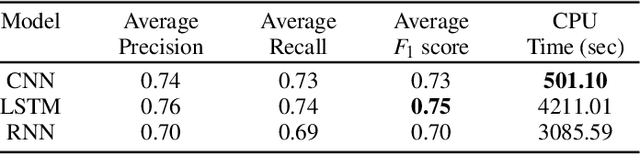
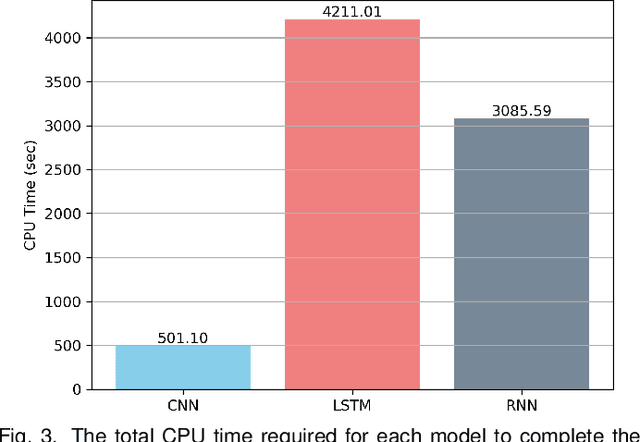
Various domain users are increasingly leveraging real-time social media data to gain rapid situational awareness. However, due to the high noise in the deluge of data, effectively determining semantically relevant information can be difficult, further complicated by the changing definition of relevancy by each end user for different events. The majority of existing methods for short text relevance classification fail to incorporate users' knowledge into the classification process. Existing methods that incorporate interactive user feedback focus on historical datasets. Therefore, classifiers cannot be interactively retrained for specific events or user-dependent needs in real-time. This limits real-time situational awareness, as streaming data that is incorrectly classified cannot be corrected immediately, permitting the possibility for important incoming data to be incorrectly classified as well. We present a novel interactive learning framework to improve the classification process in which the user iteratively corrects the relevancy of tweets in real-time to train the classification model on-the-fly for immediate predictive improvements. We computationally evaluate our classification model adapted to learn at interactive rates. Our results show that our approach outperforms state-of-the-art machine learning models. In addition, we integrate our framework with the extended Social Media Analytics and Reporting Toolkit (SMART) 2.0 system, allowing the use of our interactive learning framework within a visual analytics system tailored for real-time situational awareness. To demonstrate our framework's effectiveness, we provide domain expert feedback from first responders who used the extended SMART 2.0 system.
Near-Field Millimeter-Wave Imaging via Arrays in the Shape of Polyline
Sep 07, 2021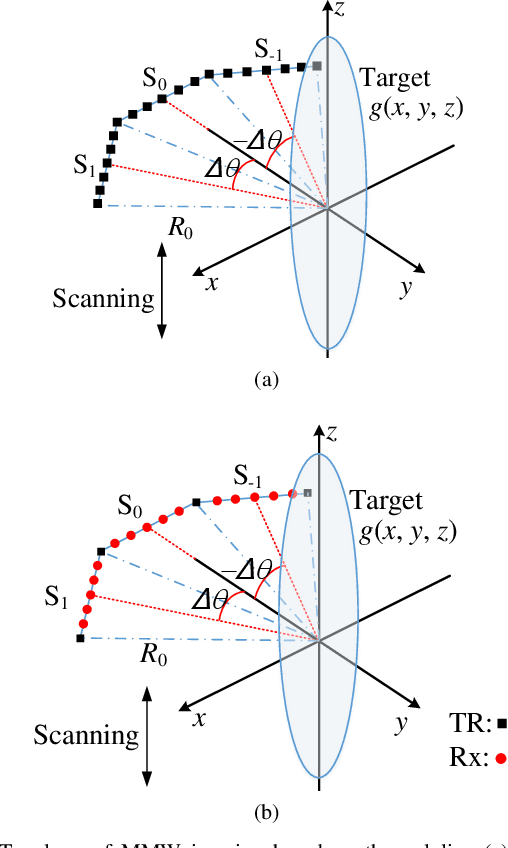

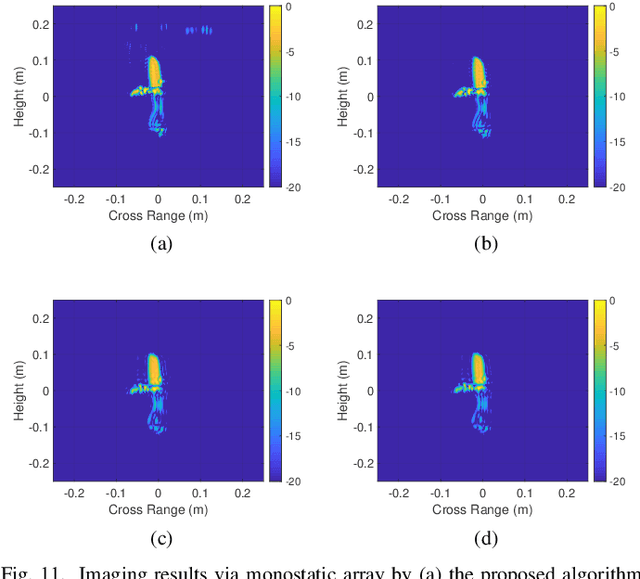
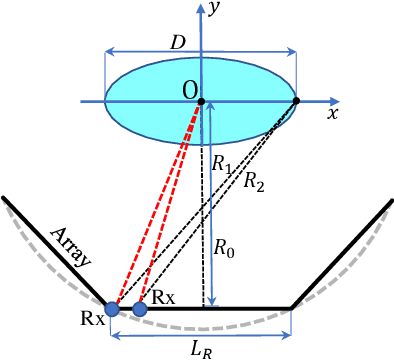
This paper proposes a polyline shaped array based system scheme, associated with mechanical scanning along the perpendicular direction of the array, for near-field millimeter-wave (MMW) imaging. Each section of the polyline is a chord of a circle with equal length. The polyline array, which can be realized as a monostatic array or a multistatic one, is capable of providing more observation angles than the linear or planar arrays. Further, we present the related three-dimensional (3-D) imaging algorithms based on a hybrid processing in the time domain and the spatial frequency domain. The nonuniform fast Fourier transform (NUFFT) is utilized to improve the computational efficiency. Simulations and experimental results are provided to demonstrate the efficacy of the proposed method in comparison with the back-projection (BP) algorithm.