 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Mitigating Current Variation in Particle Beam Microscopy
Jun 08, 2021
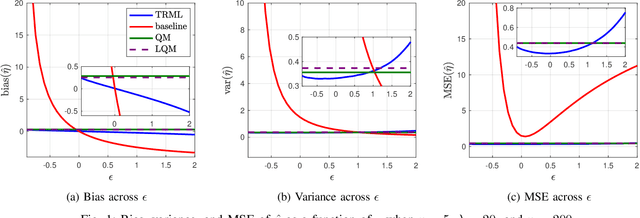
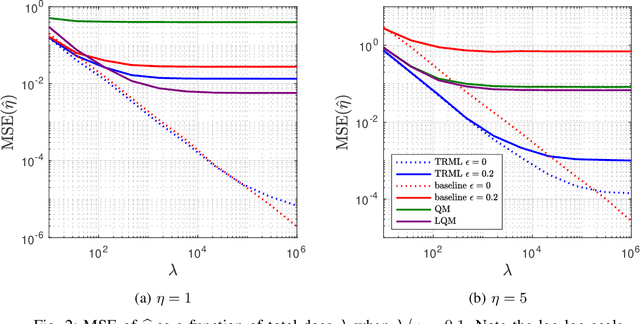
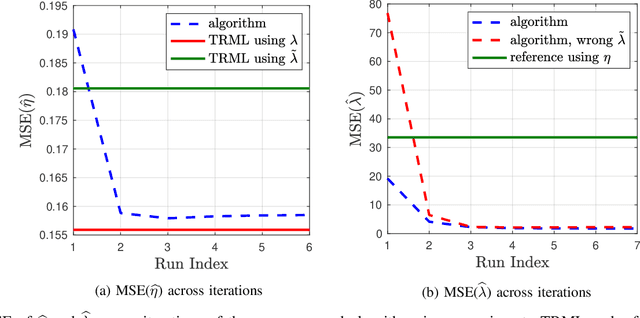

Particle beam microscopy uses a scanning beam of charged particles to create images of samples, and the quality of image reconstruction suffers when this beam current varies over time. Neither conventional reconstruction methods nor time-resolved sensing acknowledges beam current variation, although through sensitivity analysis, my project demonstrates that when the beam current variation is appreciable, time-resolved sensing has significant improvement compared to conventional methods in terms of image reconstruction quality, specifically mean-squared error (MSE). To more actively combat this unknown varying beam current's effects, my project further focuses on designing an algorithm that uses time-resolved sensing for even better image reconstruction quality in the presence of beam current variation. This algorithm works by simultaneously estimating the unknown beam current variation in addition to the underlying image, offering an alternative to more conventional methods, which exploit statistical assumptions of the image content without explicitly estimating the beam current. Using a concept of excess MSE due to beam current variation, this algorithm provides a factor of 7 improvement on average, which could lead to less expensive equipment in the future. Beyond improving the image estimation, this algorithm offers a novel estimation of the beam current, potentially providing more control in manufacturing and fabrication processes.
Memory-Efficient CNN Accelerator Based on Interlayer Feature Map Compression
Oct 12, 2021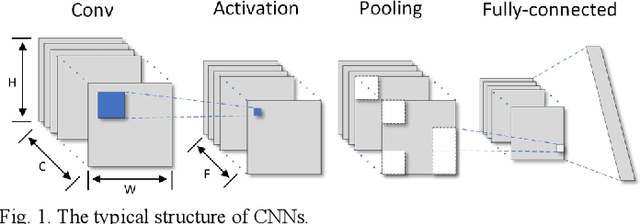
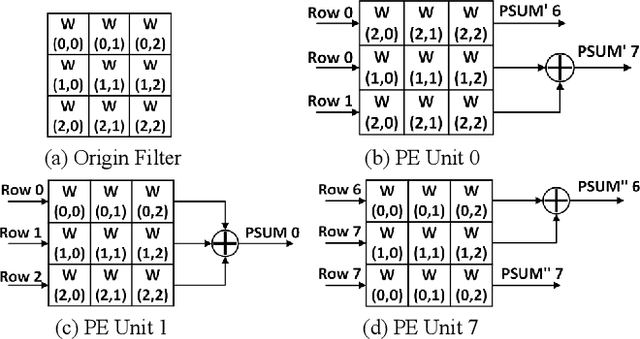
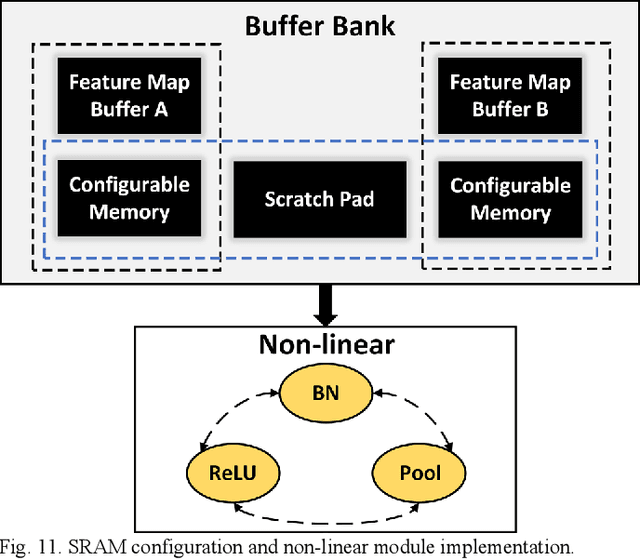
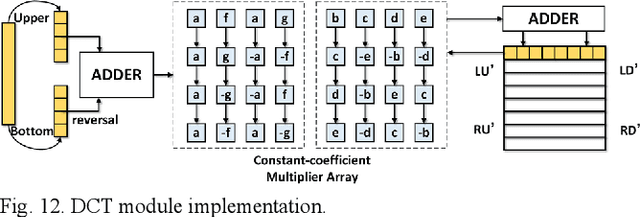
Existing deep convolutional neural networks (CNNs) generate massive interlayer feature data during network inference. To maintain real-time processing in embedded systems, large on-chip memory is required to buffer the interlayer feature maps. In this paper, we propose an efficient hardware accelerator with an interlayer feature compression technique to significantly reduce the required on-chip memory size and off-chip memory access bandwidth. The accelerator compresses interlayer feature maps through transforming the stored data into frequency domain using hardware-implemented 8x8 discrete cosine transform (DCT). The high-frequency components are removed after the DCT through quantization. Sparse matrix compression is utilized to further compress the interlayer feature maps. The on-chip memory allocation scheme is designed to support dynamic configuration of the feature map buffer size and scratch pad size according to different network-layer requirements. The hardware accelerator combines compression, decompression, and CNN acceleration into one computing stream, achieving minimal compressing and processing delay. A prototype accelerator is implemented on an FPGA platform and also synthesized in TSMC 28-nm COMS technology. It achieves 403GOPS peak throughput and 1.4x~3.3x interlayer feature map reduction by adding light hardware area overhead, making it a promising hardware accelerator for intelligent IoT devices.
Automated Design of Heuristics for the Container Relocation Problem
Jul 28, 2021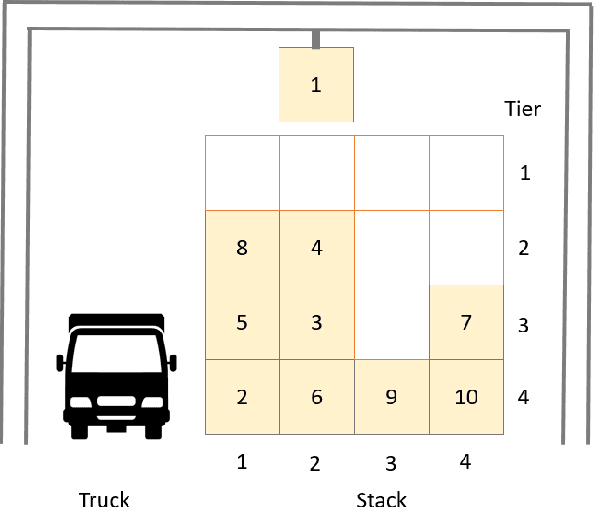
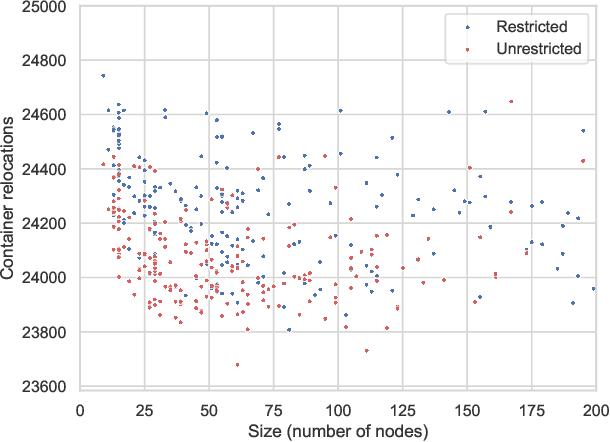
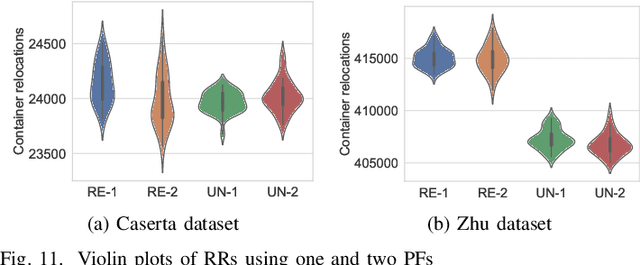
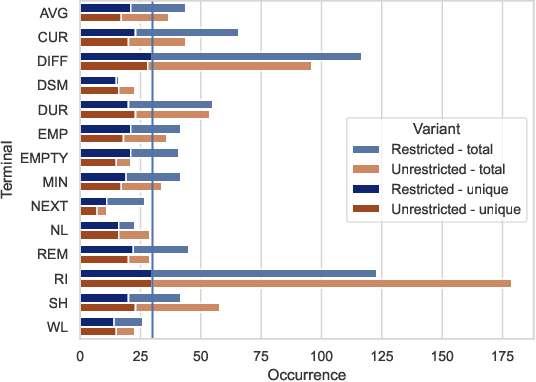
The container relocation problem is a challenging combinatorial optimisation problem tasked with finding a sequence of container relocations required to retrieve all containers by a given order. Due to the complexity of this problem, heuristic methods are often applied to obtain acceptable solutions in a small amount of time. These include relocation rules (RRs) that determine the relocation moves that need to be performed to efficiently retrieve the next container based on certain yard properties. Such rules are often designed manually by domain experts, which is a time-consuming and challenging task. This paper investigates the application of genetic programming (GP) to design effective RRs automatically. The experimental results show that GP evolved RRs outperform several existing manually designed RRs. Additional analyses of the proposed approach demonstrate that the evolved rules generalise well across a wide range of unseen problems and that their performance can be further enhanced. Therefore, the proposed method presents a viable alternative to existing manually designed RRs and opens a new research direction in the area of container relocation problems.
Cubature Kalman Filter Based Training of Hybrid Differential Equation Recurrent Neural Network Physiological Dynamic Models
Oct 12, 2021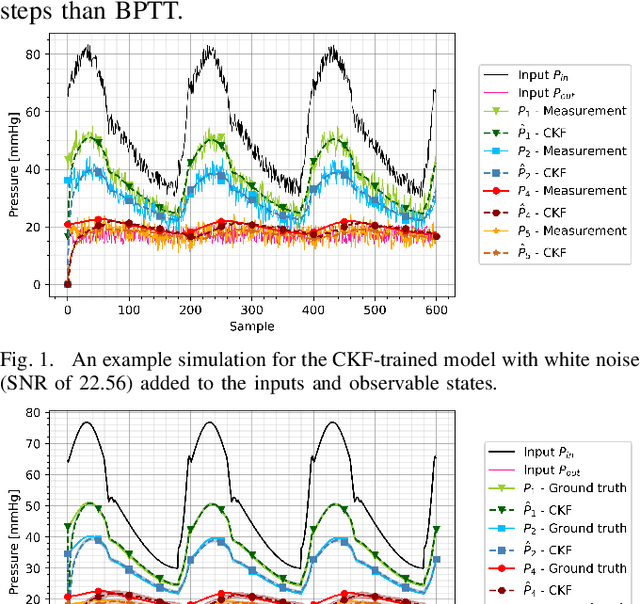
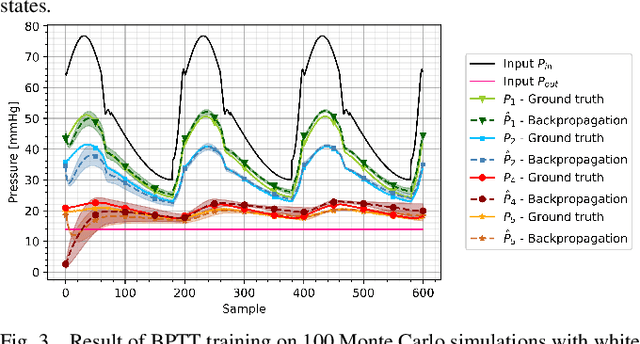
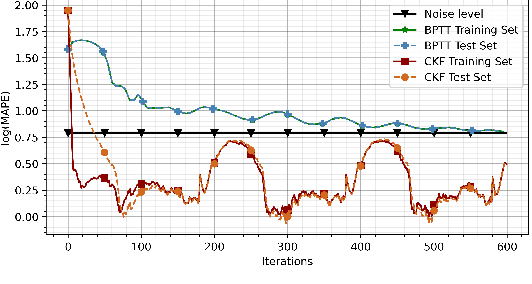
Modeling biological dynamical systems is challenging due to the interdependence of different system components, some of which are not fully understood. To fill existing gaps in our ability to mechanistically model physiological systems, we propose to combine neural networks with physics-based models. Specifically, we demonstrate how we can approximate missing ordinary differential equations (ODEs) coupled with known ODEs using Bayesian filtering techniques to train the model parameters and simultaneously estimate dynamic state variables. As a study case we leverage a well-understood model for blood circulation in the human retina and replace one of its core ODEs with a neural network approximation, representing the case where we have incomplete knowledge of the physiological state dynamics. Results demonstrate that state dynamics corresponding to the missing ODEs can be approximated well using a neural network trained using a recursive Bayesian filtering approach in a fashion coupled with the known state dynamic differential equations. This demonstrates that dynamics and impact of missing state variables can be captured through joint state estimation and model parameter estimation within a recursive Bayesian state estimation (RBSE) framework. Results also indicate that this RBSE approach to training the NN parameters yields better outcomes (measurement/state estimation accuracy) than training the neural network with backpropagation through time in the same setting.
Efficient Bayesian network structure learning via local Markov boundary search
Oct 12, 2021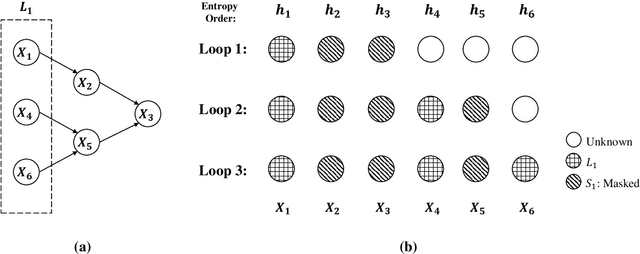
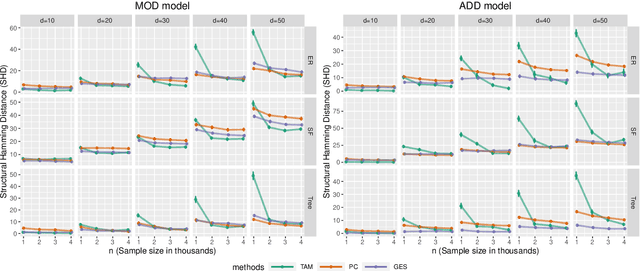
We analyze the complexity of learning directed acyclic graphical models from observational data in general settings without specific distributional assumptions. Our approach is information-theoretic and uses a local Markov boundary search procedure in order to recursively construct ancestral sets in the underlying graphical model. Perhaps surprisingly, we show that for certain graph ensembles, a simple forward greedy search algorithm (i.e. without a backward pruning phase) suffices to learn the Markov boundary of each node. This substantially improves the sample complexity, which we show is at most polynomial in the number of nodes. This is then applied to learn the entire graph under a novel identifiability condition that generalizes existing conditions from the literature. As a matter of independent interest, we establish finite-sample guarantees for the problem of recovering Markov boundaries from data. Moreover, we apply our results to the special case of polytrees, for which the assumptions simplify, and provide explicit conditions under which polytrees are identifiable and learnable in polynomial time. We further illustrate the performance of the algorithm, which is easy to implement, in a simulation study. Our approach is general, works for discrete or continuous distributions without distributional assumptions, and as such sheds light on the minimal assumptions required to efficiently learn the structure of directed graphical models from data.
Anomaly Detection in Predictive Maintenance: A New Evaluation Framework for Temporal Unsupervised Anomaly Detection Algorithms
May 26, 2021
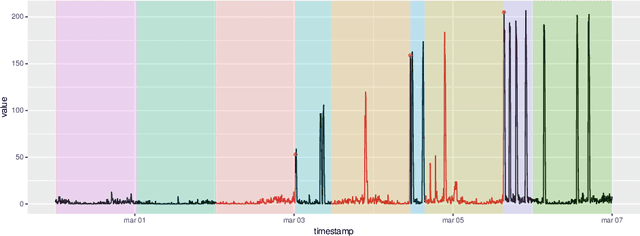
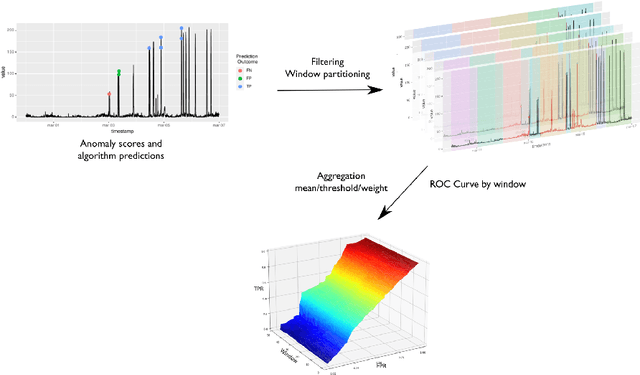

The research in anomaly detection lacks a unified definition of what represents an anomalous instance. Discrepancies in the nature itself of an anomaly lead to multiple paradigms of algorithms design and experimentation. Predictive maintenance is a special case, where the anomaly represents a failure that must be prevented. Related time-series research as outlier and novelty detection or time-series classification does not apply to the concept of an anomaly in this field, because they are not single points which have not been seen previously and may not be precisely annotated. Moreover, due to the lack of annotated anomalous data, many benchmarks are adapted from supervised scenarios. To address these issues, we generalise the concept of positive and negative instances to intervals to be able to evaluate unsupervised anomaly detection algorithms. We also preserve the imbalance scheme for evaluation through the proposal of the Preceding Window ROC, a generalisation for the calculation of ROC curves for time-series scenarios. We also adapt the mechanism from a established time-series anomaly detection benchmark to the proposed generalisations to reward early detection. Therefore, the proposal represents a flexible evaluation framework for the different scenarios. To show the usefulness of this definition, we include a case study of Big Data algorithms with a real-world time-series problem provided by the company ArcelorMittal, and compare the proposal with an evaluation method.
Sequential Joint Shape and Pose Estimation of Vehicles with Application to Automatic Amodal Segmentation Labeling
Sep 20, 2021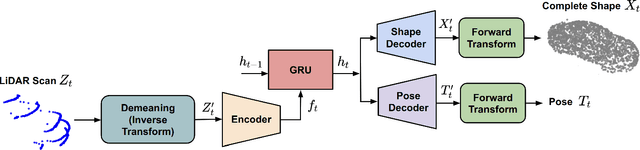

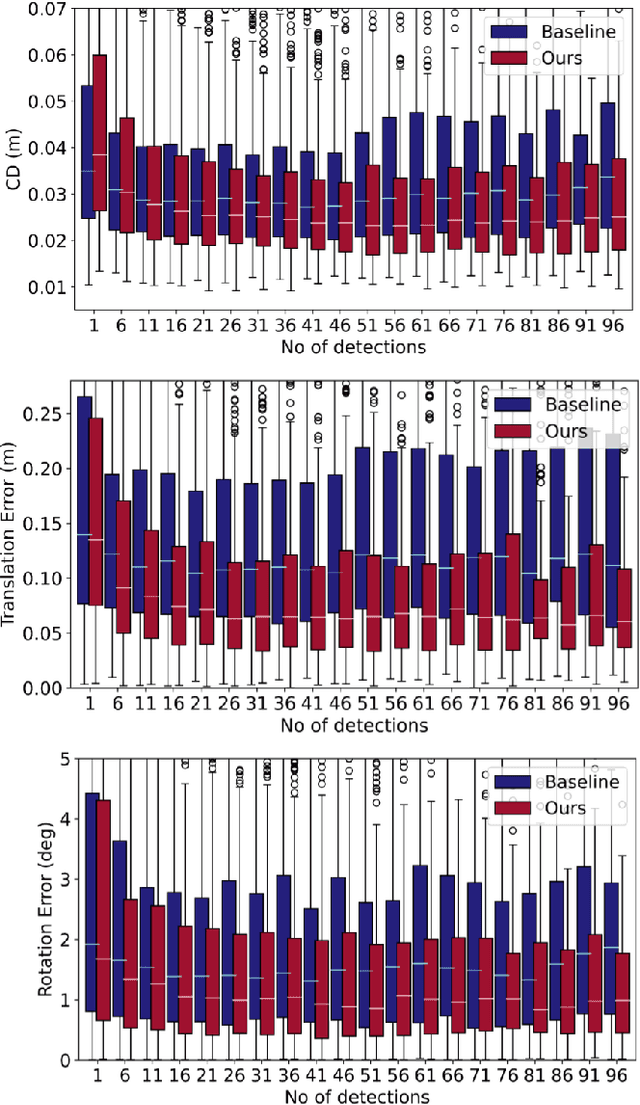

Shape and pose estimation is a critical perception problem for a self-driving car to fully understand its surrounding environment. One fundamental challenge in solving this problem is the incomplete sensor signal (e.g., LiDAR scans), especially for faraway or occluded objects. In this paper, we propose a novel algorithm to address this challenge, we explicitly leverage the sensor signal captured over consecutive time: the consecutive signals can provide more information of an object, including different viewpoints and its motion. By encoding the consecutive signal via a recurrent neural network, our algorithm not only improves shape and pose estimation, but also produces a labeling tool that can benefit other tasks in autonomous driving research. Specifically, building upon our algorithm, we propose a novel pipeline to automatically annotate high-quality labels for amodal segmentation on images, which are hard and laborious to annotate manually. Our code and data will be made publicly available.
Training Spiking Neural Networks Using Lessons From Deep Learning
Oct 01, 2021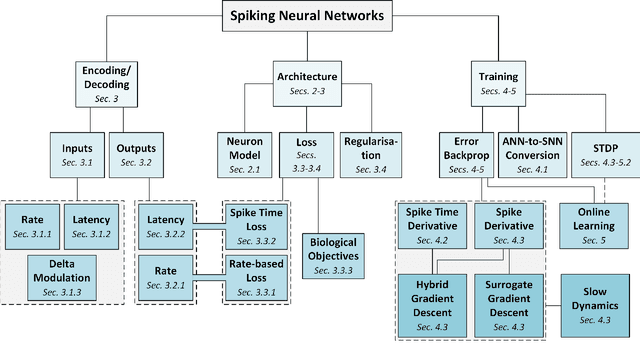

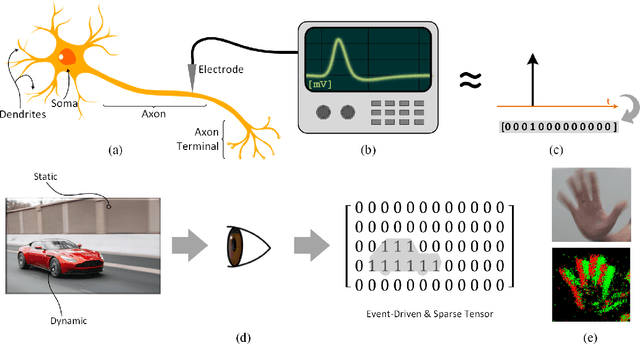

The brain is the perfect place to look for inspiration to develop more efficient neural networks. The inner workings of our synapses and neurons provide a glimpse at what the future of deep learning might look like. This paper serves as a tutorial and perspective showing how to apply the lessons learnt from several decades of research in deep learning, gradient descent, backpropagation and neuroscience to biologically plausible spiking neural neural networks. We also explore the delicate interplay between encoding data as spikes and the learning process; the challenges and solutions of applying gradient-based learning to spiking neural networks; the subtle link between temporal backpropagation and spike timing dependent plasticity, and how deep learning might move towards biologically plausible online learning. Some ideas are well accepted and commonly used amongst the neuromorphic engineering community, while others are presented or justified for the first time here. A series of companion interactive tutorials complementary to this paper using our Python package, snnTorch, are also made available: https://snntorch.readthedocs.io/en/latest/tutorials/index.html
Real-Time Anomaly Detection With HMOF Feature
Dec 12, 2018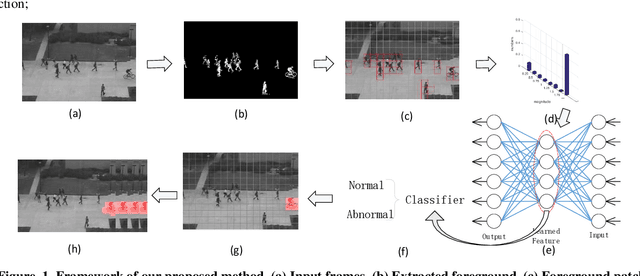
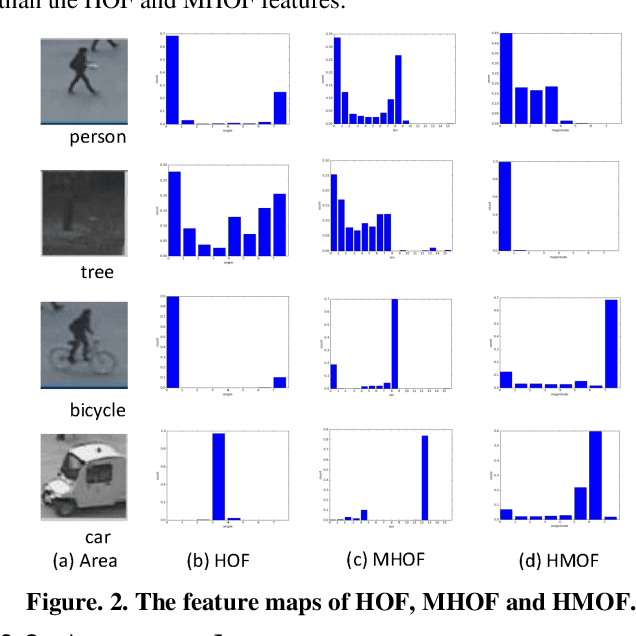
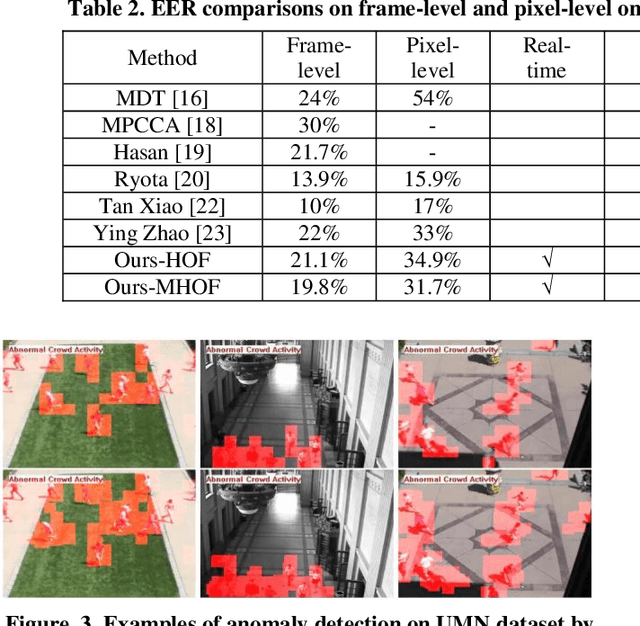

Anomaly detection is a challenging problem in intelligent video surveillance. Most existing methods are computation consuming, which cannot satisfy the real-time requirement. In this paper, we propose a real-time anomaly detection framework with low computational complexity and high efficiency. A new feature, named Histogram of Magnitude Optical Flow (HMOF), is proposed to capture the motion of video patches. Compared with existing feature descriptors, HMOF is more sensitive to motion magnitude and more efficient to distinguish anomaly information. The HMOF features are computed for foreground patches, and are reconstructed by the auto-encoder for better clustering. Then, we use Gaussian Mixture Model (GMM) Classifiers to distinguish anomalies from normal activities in videos. Experimental results show that our framework outperforms state-of-the-art methods, and can reliably detect anomalies in real-time.
Deep speech inpainting of time-frequency masks
Oct 20, 2019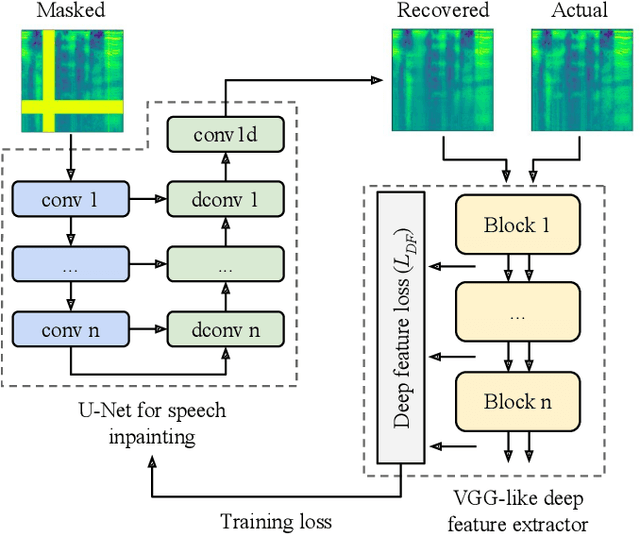
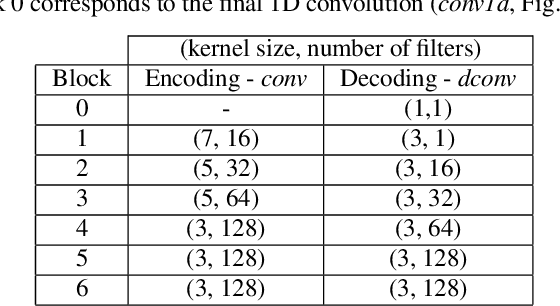
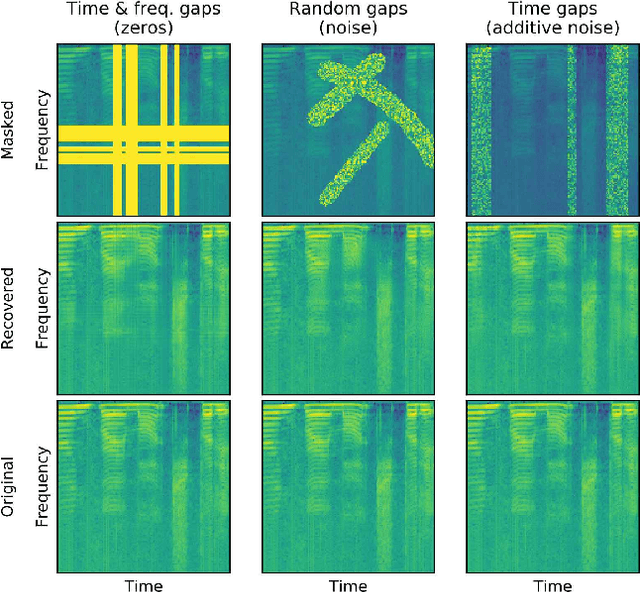
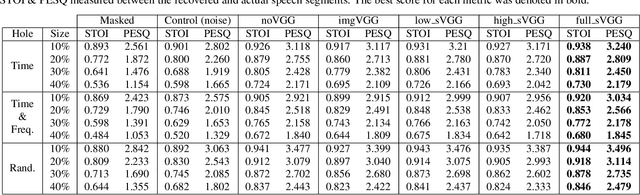
In particularly noisy environments, transient loud intrusions can completely overpower parts of the speech signal, leading to an inevitable loss of information. Recent algorithms for noise suppression often yield impressive results but tend to struggle when the signal-to-noise ratio (SNR) of the mixture is low or when parts of the signal are missing. To address these issues, here we introduce an end-to-end framework for the retrieval of missing or severely distorted parts of time-frequency representation of speech, from the short-term context, thus speech inpainting. The framework is based on a convolutional U-Net trained via deep feature losses, obtained through speechVGG, a deep speech feature extractor pre-trained on the word classification task. Our evaluation results demonstrate that the proposed framework is effective at recovering large portions of missing or distorted parts of speech. Specifically, it yields notable improvements in STOI & PESQ objective metrics, as assessed using the LibriSpeech dataset.