 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Egocentric Hand-object Interaction Detection and Application
Sep 29, 2021
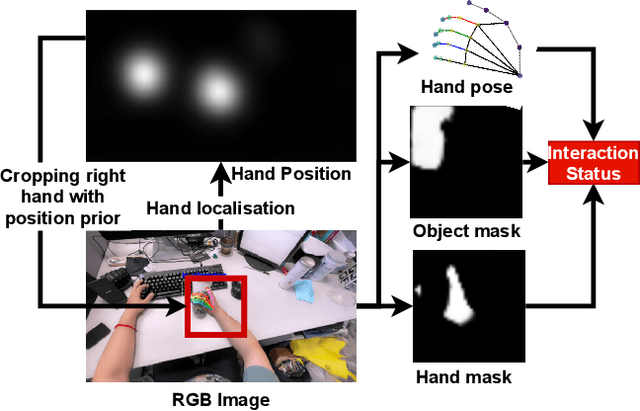
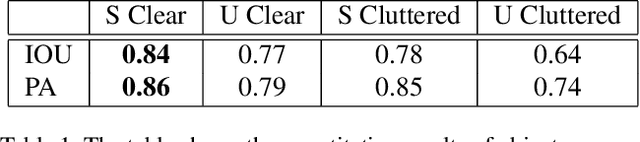
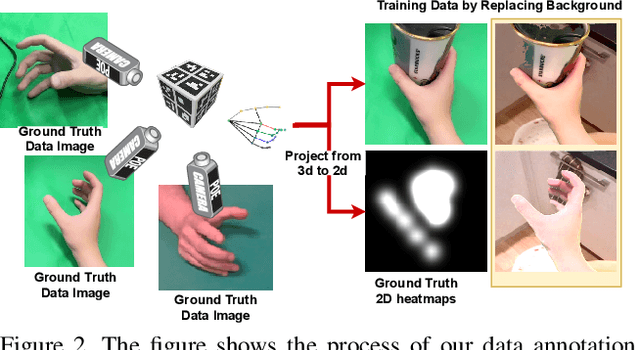

In this paper, we present a method to detect the hand-object interaction from an egocentric perspective. In contrast to massive data-driven discriminator based method like \cite{Shan20}, we propose a novel workflow that utilises the cues of hand and object. Specifically, we train networks predicting hand pose, hand mask and in-hand object mask to jointly predict the hand-object interaction status. We compare our method with the most recent work from Shan et al. \cite{Shan20} on selected images from EPIC-KITCHENS \cite{damen2018scaling} dataset and achieve $89\%$ accuracy on HOI (hand-object interaction) detection which is comparative to Shan's ($92\%$). However, for real-time performance, with the same machine, our method can run over $\textbf{30}$ FPS which is much efficient than Shan's ($\textbf{1}\sim\textbf{2}$ FPS). Furthermore, with our approach, we are able to segment script-less activities from where we extract the frames with the HOI status detection. We achieve $\textbf{68.2\%}$ and $\textbf{82.8\%}$ F1 score on GTEA \cite{fathi2011learning} and the UTGrasp \cite{cai2015scalable} dataset respectively which are all comparative to the SOTA methods.
Better Self-training for Image Classification through Self-supervision
Sep 09, 2021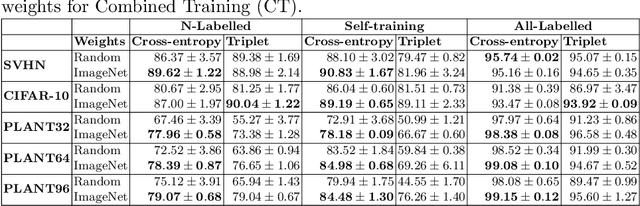
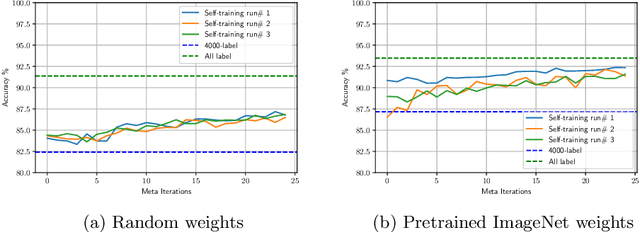
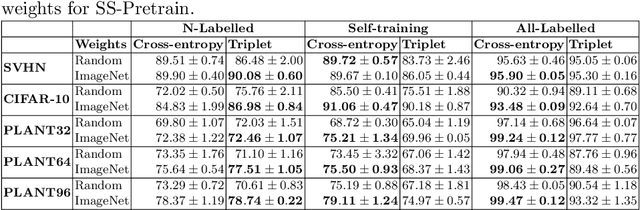
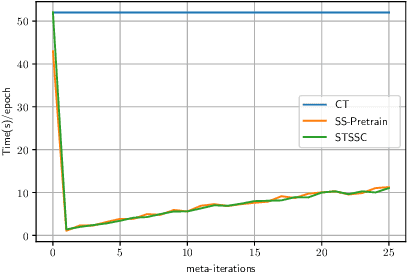
Self-training is a simple semi-supervised learning approach: Unlabelled examples that attract high-confidence predictions are labelled with their predictions and added to the training set, with this process being repeated multiple times. Recently, self-supervision -- learning without manual supervision by solving an automatically-generated pretext task -- has gained prominence in deep learning. This paper investigates three different ways of incorporating self-supervision into self-training to improve accuracy in image classification: self-supervision as pretraining only, self-supervision performed exclusively in the first iteration of self-training, and self-supervision added to every iteration of self-training. Empirical results on the SVHN, CIFAR-10, and PlantVillage datasets, using both training from scratch, and Imagenet-pretrained weights, show that applying self-supervision only in the first iteration of self-training can greatly improve accuracy, for a modest increase in computation time.
Adversarial Attacks on Deep Neural Networks for Time Series Classification
Mar 17, 2019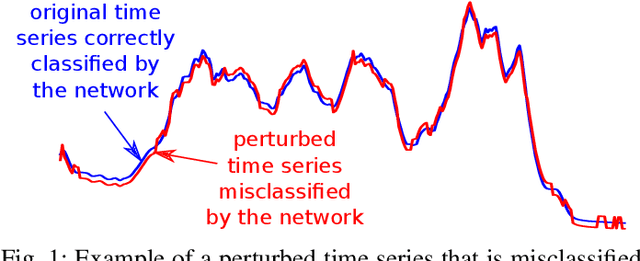

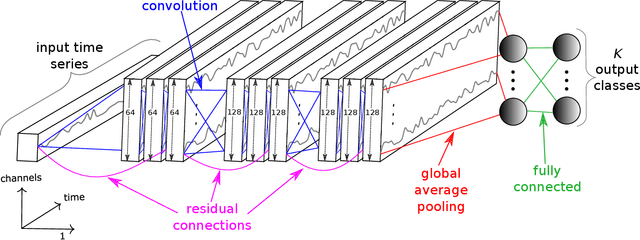
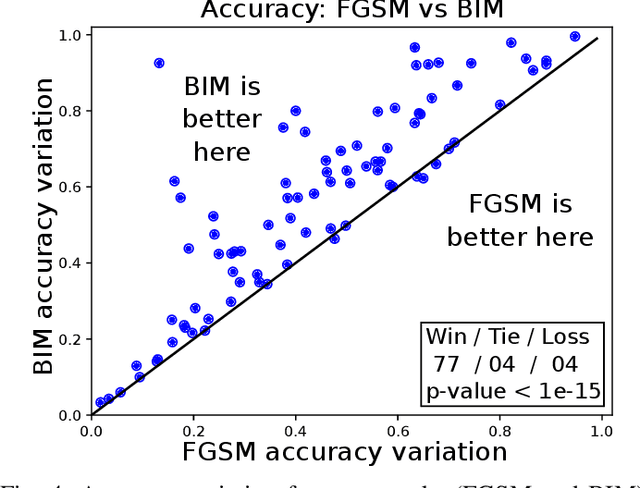
Time Series Classification (TSC) problems are encountered in many real life data mining tasks ranging from medicine and security to human activity recognition and food safety. With the recent success of deep neural networks in various domains such as computer vision and natural language processing, researchers started adopting these techniques for solving time series data mining problems. However, to the best of our knowledge, no previous work has considered the vulnerability of deep learning models to adversarial time series examples, which could potentially make them unreliable in situations where the decision taken by the classifier is crucial such as in medicine and security. For computer vision problems, such attacks have been shown to be very easy to perform by altering the image and adding an imperceptible amount of noise to trick the network into wrongly classifying the input image. Following this line of work, we propose to leverage existing adversarial attack mechanisms to add a special noise to the input time series in order to decrease the network's confidence when classifying instances at test time. Our results reveal that current state-of-the-art deep learning time series classifiers are vulnerable to adversarial attacks which can have major consequences in multiple domains such as food safety and quality assurance.
PASTE: A Tagging-Free Decoding Framework Using Pointer Networks for Aspect Sentiment Triplet Extraction
Oct 10, 2021


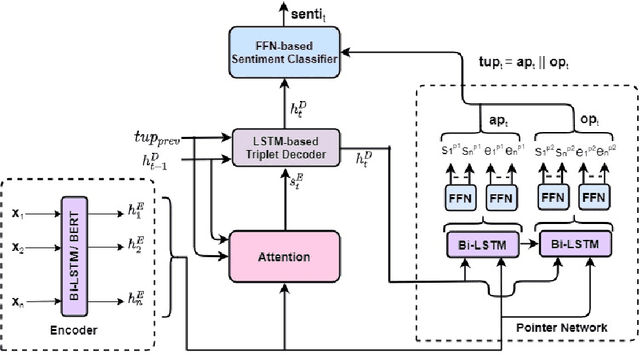
Aspect Sentiment Triplet Extraction (ASTE) deals with extracting opinion triplets, consisting of an opinion target or aspect, its associated sentiment, and the corresponding opinion term/span explaining the rationale behind the sentiment. Existing research efforts are majorly tagging-based. Among the methods taking a sequence tagging approach, some fail to capture the strong interdependence between the three opinion factors, whereas others fall short of identifying triplets with overlapping aspect/opinion spans. A recent grid tagging approach on the other hand fails to capture the span-level semantics while predicting the sentiment between an aspect-opinion pair. Different from these, we present a tagging-free solution for the task, while addressing the limitations of the existing works. We adapt an encoder-decoder architecture with a Pointer Network-based decoding framework that generates an entire opinion triplet at each time step thereby making our solution end-to-end. Interactions between the aspects and opinions are effectively captured by the decoder by considering their entire detected spans while predicting their connecting sentiment. Extensive experiments on several benchmark datasets establish the better efficacy of our proposed approach, especially in the recall, and in predicting multiple and aspect/opinion-overlapped triplets from the same review sentence. We report our results both with and without BERT and also demonstrate the utility of domain-specific BERT post-training for the task.
Signal automata and hidden Markov models
May 04, 2021A generic method for inferring a dynamical hidden Markov model from a time series is proposed. Under reasonable hypothesis, the model is updated in constant time whenever a new measurement arrives.
Vision-Aided Beam Tracking: Explore the Proper Use of Camera Images with Deep Learning
Sep 29, 2021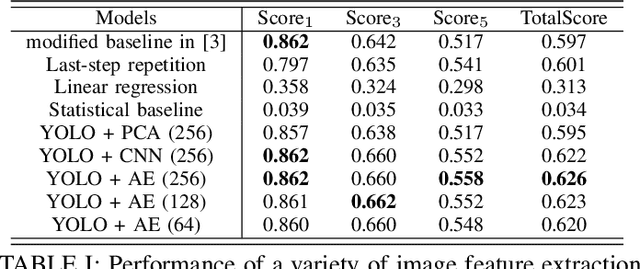
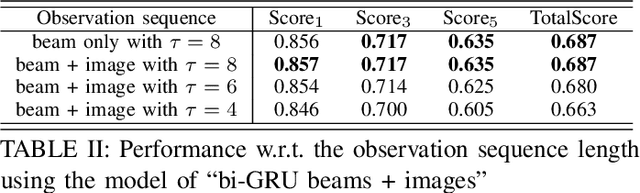
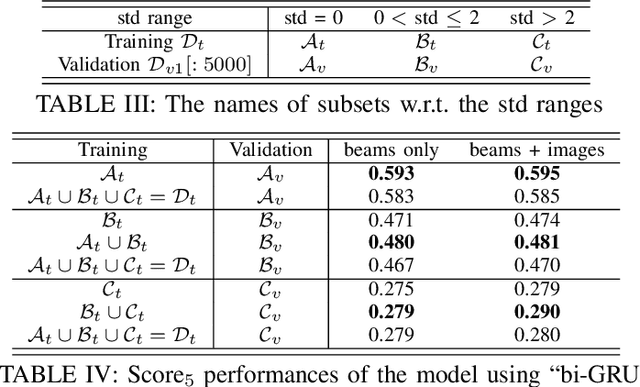
We investigate the problem of wireless beam tracking on mmWave bands with the assistance of camera images. In particular, based on the user's beam indices used and camera images taken in the trajectory, we predict the optimal beam indices in the next few time spots. To resolve this problem, we first reformulate the "ViWi" dataset in [1] to get rid of the image repetition problem. Then we develop a deep learning approach and investigate various model components to achieve the best performance. Finally, we explore whether, when, and how to use the image for better beam prediction. To answer this question, we split the dataset into three clusters -- (LOS, light NLOS, serious NLOS)-like -- based on the standard deviation of the beam sequence. With experiments we demonstrate that using the image indeed helps beam tracking especially when the user is in serious NLOS, and the solution relies on carefully-designed dataset for training a model. Generally speaking, including NLOS-like data for training a model does not benefit beam tracking of the user in LOS, but including light NLOS-like data for training a model benefits beam tracking of the user in serious NLOS.
Leveraging distributed contact force measurements for slip detection: a physics-based approach enabled by a data-driven tactile sensor
Sep 23, 2021
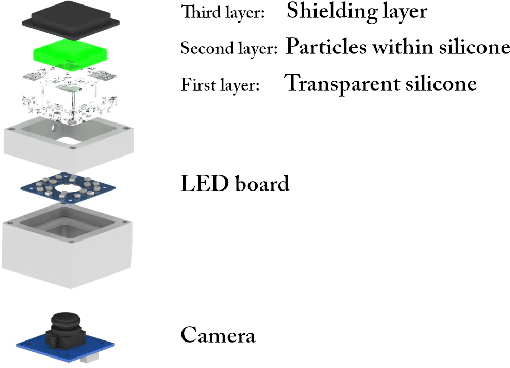
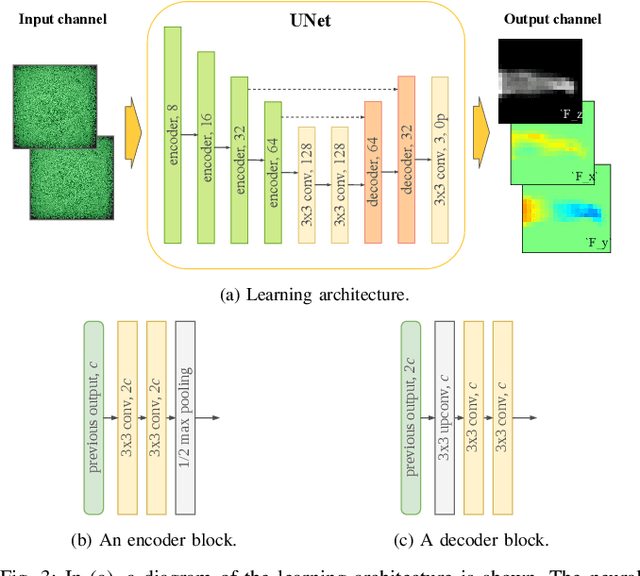

Grasping objects whose physical properties are unknown is still a great challenge in robotics. Most solutions rely entirely on visual data to plan the best grasping strategy. However, to match human abilities and be able to reliably pick and hold unknown objects, the integration of an artificial sense of touch in robotic systems is pivotal. This paper describes a novel model-based slip detection pipeline that can predict possibly failing grasps in real-time and signal a necessary increase in grip force. As such, the slip detector does not rely on manually collected data, but exploits physics to generalize across different tasks. To evaluate the approach, a state-of-the-art vision-based tactile sensor that accurately estimates distributed forces was integrated into a grasping setup composed of a six degrees-of-freedom cobot and a two-finger gripper. Results show that the system can reliably predict slip while manipulating objects of different shapes, materials, and weights. The sensor can detect both translational and rotational slip in various scenarios, making it suitable to improve the stability of a grasp.
Inverse Kinematics and Dexterous Workspace Formulation for 2-Segment Continuum Robots with Inextensible Segments
Oct 05, 2021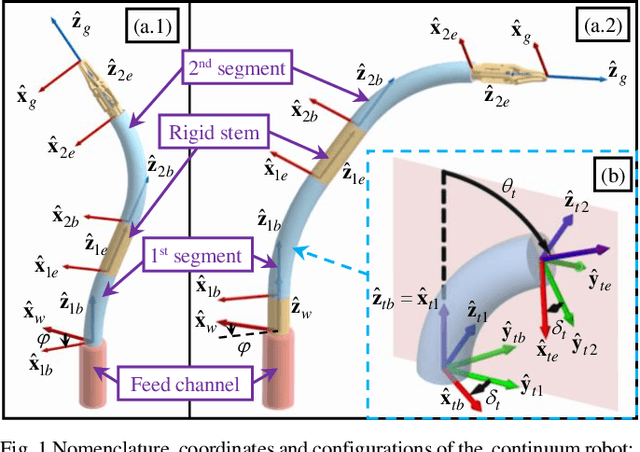
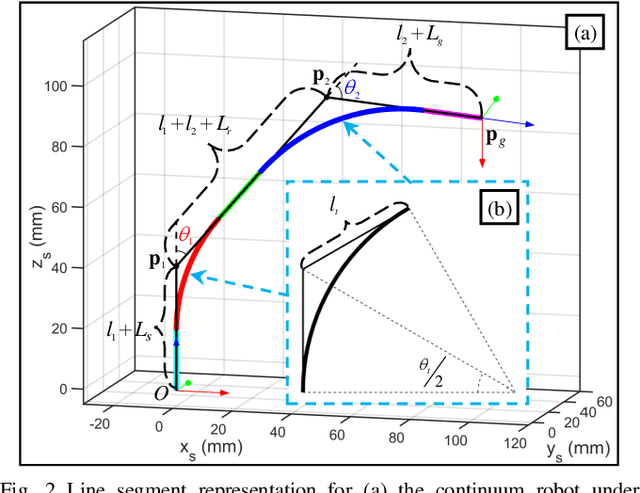
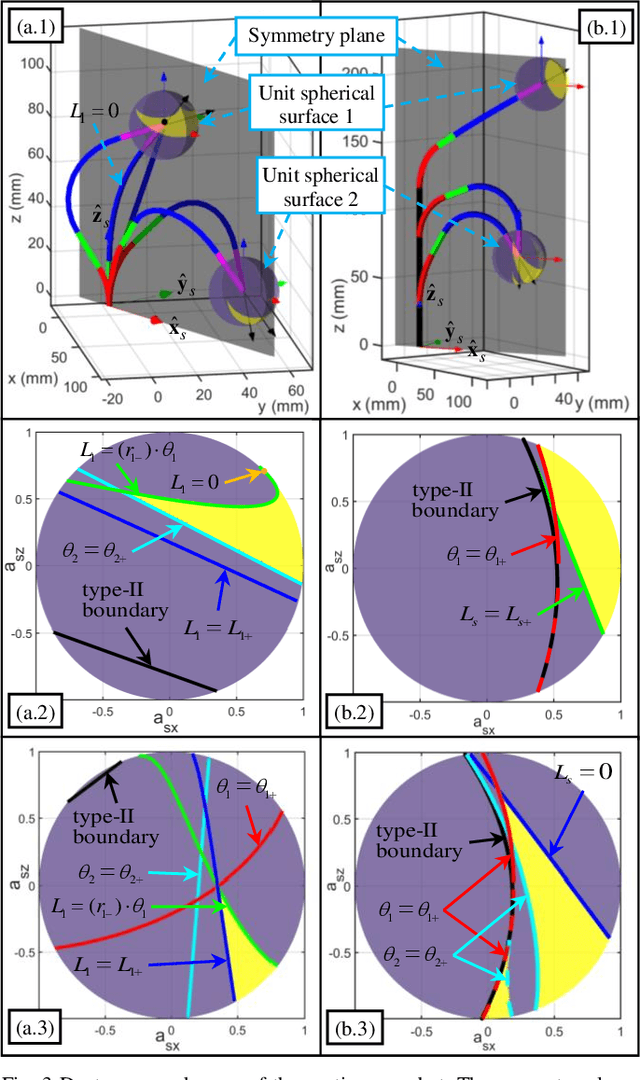
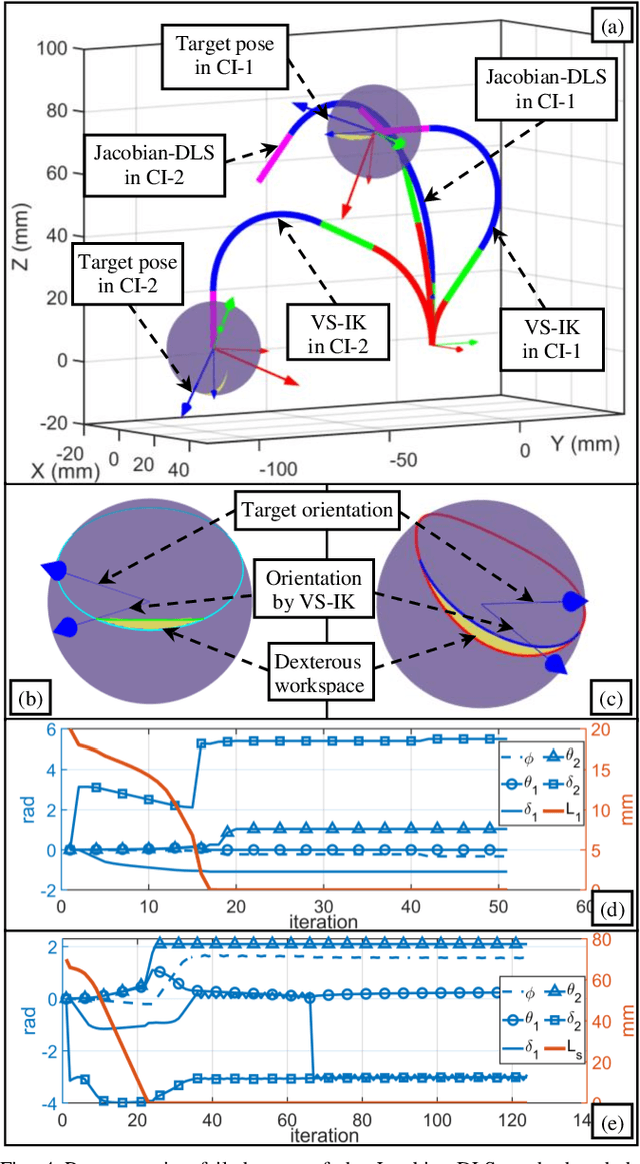
The inverse kinematics (IK) problem of continuum robots has been investigated in depth in the past decades. Under the constant-curvature bending assumption, closed-form IK solution has been obtained for continuum robots with variable segment lengths. Attempting to close the gap towards a complete solution, this paper presents an efficient solution for the IK problem of 2-segment continuum robots with one or two inextensible segments (a.k.a, constant segment lengths). Via representing the robot's shape as piecewise line segments, the configuration variables are separated from the IK formulation such that solving a one-variable nonlinear equation leads to the solution of the entire IK problem. Furthermore, an in-depth investigation of the boundaries of the dexterous workspace of the end effector caused by the configuration variables limits as well as the angular velocity singularities of the continuum robots was established. This dexterous workspace formulation, which is derived for the first time to the best of the authors' knowledge, is particularly useful to find the closest orientation to a target pose when the target orientation is out of the dexterous workspace. In the comparative simulation studies between the proposed method and the Jacobian-based IK method involving 500,000 cases, the proposed variable separation method solved 100% of the IK problems with much higher computational efficiency.
Fully Spiking Variational Autoencoder
Oct 05, 2021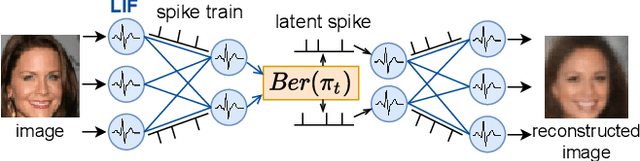
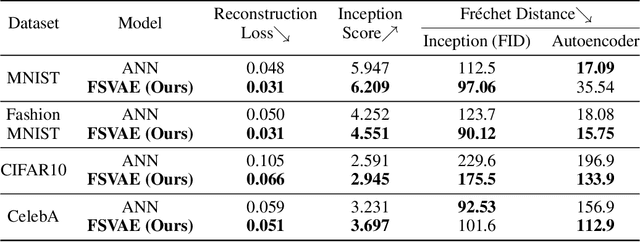
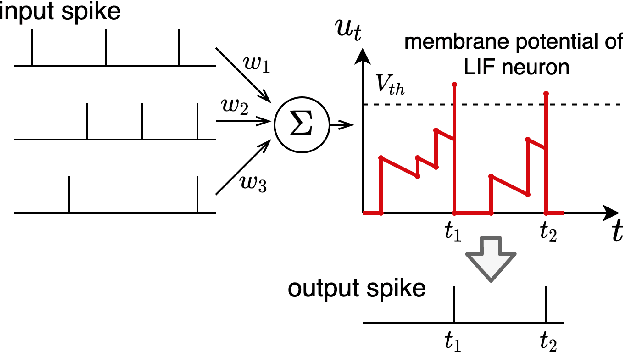

Spiking neural networks (SNNs) can be run on neuromorphic devices with ultra-high speed and ultra-low energy consumption because of their binary and event-driven nature. Therefore, SNNs are expected to have various applications, including as generative models being running on edge devices to create high-quality images. In this study, we build a variational autoencoder (VAE) with SNN to enable image generation. VAE is known for its stability among generative models; recently, its quality advanced. In vanilla VAE, the latent space is represented as a normal distribution, and floating-point calculations are required in sampling. However, this is not possible in SNNs because all features must be binary time series data. Therefore, we constructed the latent space with an autoregressive SNN model, and randomly selected samples from its output to sample the latent variables. This allows the latent variables to follow the Bernoulli process and allows variational learning. Thus, we build the Fully Spiking Variational Autoencoder where all modules are constructed with SNN. To the best of our knowledge, we are the first to build a VAE only with SNN layers. We experimented with several datasets, and confirmed that it can generate images with the same or better quality compared to conventional ANNs. The code is available at https://github.com/kamata1729/FullySpikingVAE
Higher Order Kernel Mean Embeddings to Capture Filtrations of Stochastic Processes
Sep 29, 2021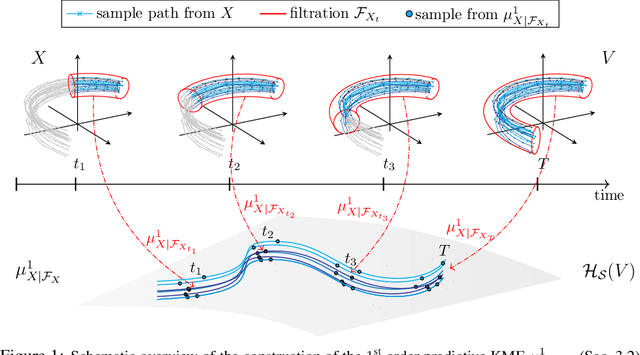


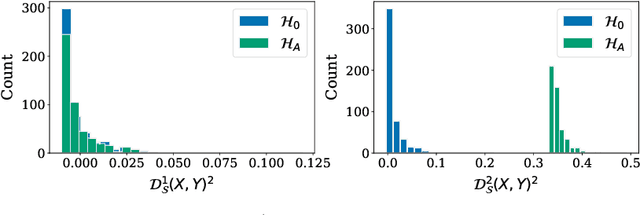
Stochastic processes are random variables with values in some space of paths. However, reducing a stochastic process to a path-valued random variable ignores its filtration, i.e. the flow of information carried by the process through time. By conditioning the process on its filtration, we introduce a family of higher order kernel mean embeddings (KMEs) that generalizes the notion of KME and captures additional information related to the filtration. We derive empirical estimators for the associated higher order maximum mean discrepancies (MMDs) and prove consistency. We then construct a filtration-sensitive kernel two-sample test able to pick up information that gets missed by the standard MMD test. In addition, leveraging our higher order MMDs we construct a family of universal kernels on stochastic processes that allows to solve real-world calibration and optimal stopping problems in quantitative finance (such as the pricing of American options) via classical kernel-based regression methods. Finally, adapting existing tests for conditional independence to the case of stochastic processes, we design a causal-discovery algorithm to recover the causal graph of structural dependencies among interacting bodies solely from observations of their multidimensional trajectories.