 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep hierarchical reinforcement agents for automated penetration testing
Sep 14, 2021
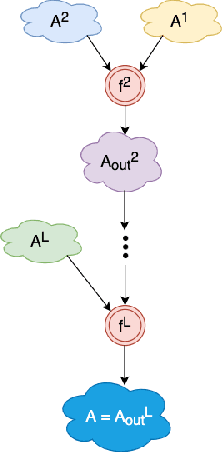
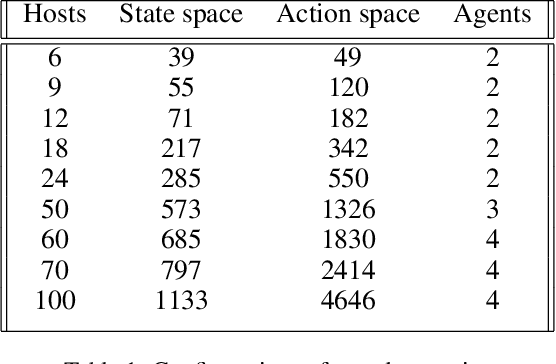
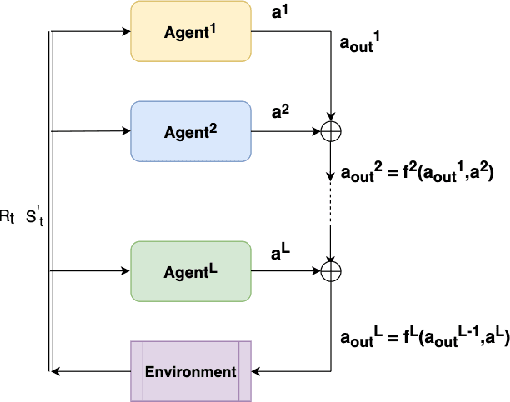
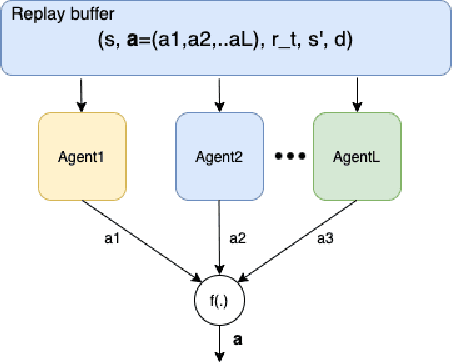
Penetration testing the organised attack of a computer system in order to test existing defences has been used extensively to evaluate network security. This is a time consuming process and requires in-depth knowledge for the establishment of a strategy that resembles a real cyber-attack. This paper presents a novel deep reinforcement learning architecture with hierarchically structured agents called HA-DRL, which employs an algebraic action decomposition strategy to address the large discrete action space of an autonomous penetration testing simulator where the number of actions is exponentially increased with the complexity of the designed cybersecurity network. The proposed architecture is shown to find the optimal attacking policy faster and more stably than a conventional deep Q-learning agent which is commonly used as a method to apply artificial intelligence in automatic penetration testing.
Lung Cancer Lesion Detection in Histopathology Images Using Graph-Based Sparse PCA Network
Oct 27, 2021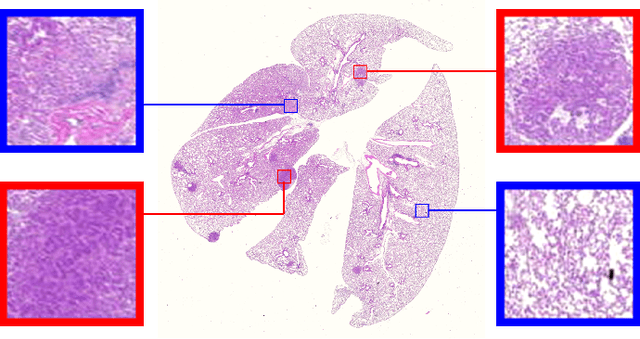
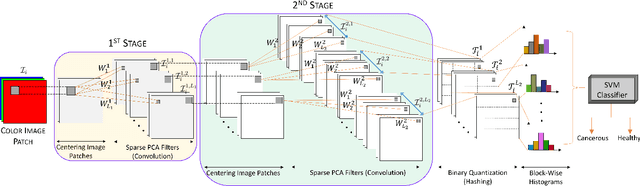
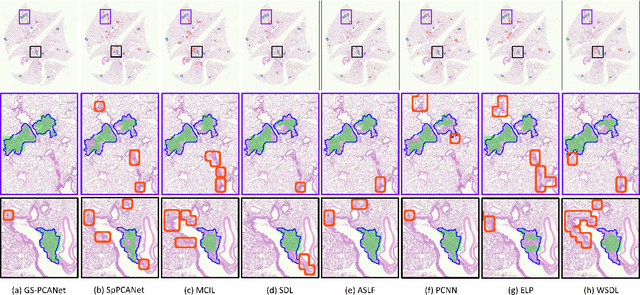
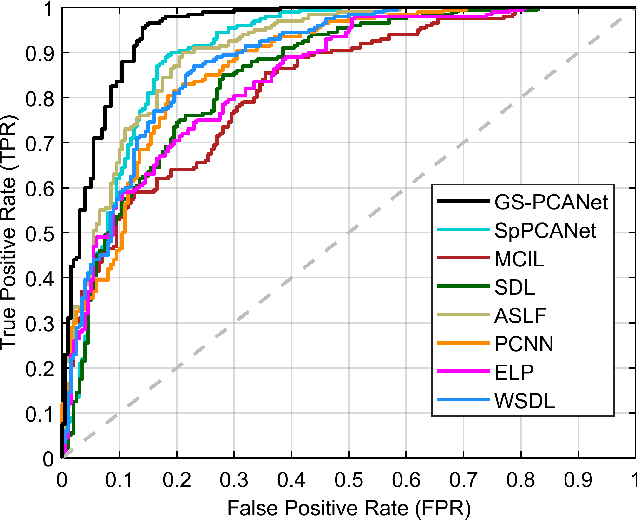
Early detection of lung cancer is critical for improvement of patient survival. To address the clinical need for efficacious treatments, genetically engineered mouse models (GEMM) have become integral in identifying and evaluating the molecular underpinnings of this complex disease that may be exploited as therapeutic targets. Assessment of GEMM tumor burden on histopathological sections performed by manual inspection is both time consuming and prone to subjective bias. Therefore, an interplay of needs and challenges exists for computer-aided diagnostic tools, for accurate and efficient analysis of these histopathology images. In this paper, we propose a simple machine learning approach called the graph-based sparse principal component analysis (GS-PCA) network, for automated detection of cancerous lesions on histological lung slides stained by hematoxylin and eosin (H&E). Our method comprises four steps: 1) cascaded graph-based sparse PCA, 2) PCA binary hashing, 3) block-wise histograms, and 4) support vector machine (SVM) classification. In our proposed architecture, graph-based sparse PCA is employed to learn the filter banks of the multiple stages of a convolutional network. This is followed by PCA hashing and block histograms for indexing and pooling. The meaningful features extracted from this GS-PCA are then fed to an SVM classifier. We evaluate the performance of the proposed algorithm on H&E slides obtained from an inducible K-rasG12D lung cancer mouse model using precision/recall rates, F-score, Tanimoto coefficient, and area under the curve (AUC) of the receiver operator characteristic (ROC) and show that our algorithm is efficient and provides improved detection accuracy compared to existing algorithms.
What Averages Do Not Tell -- Predicting Real Life Processes with Sequential Deep Learning
Oct 31, 2021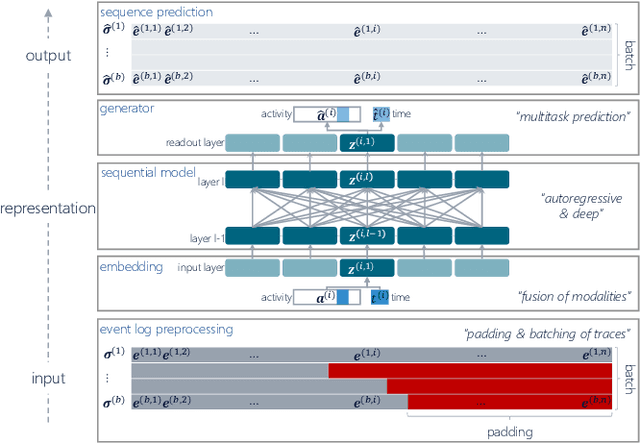
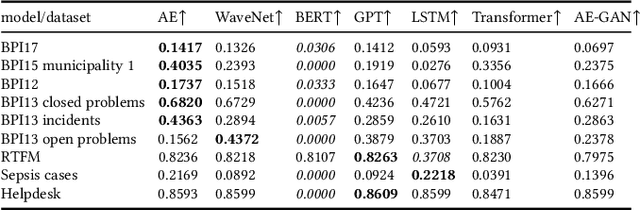
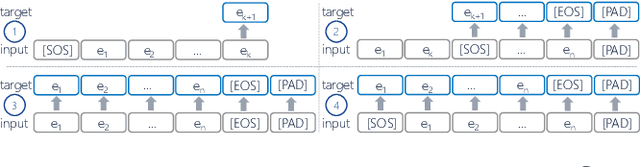
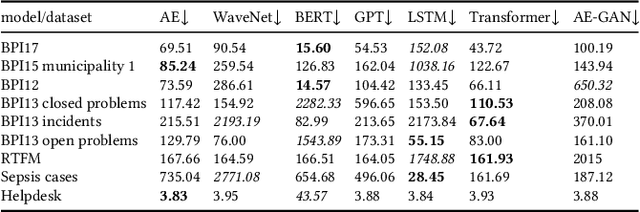
Deep Learning is proven to be an effective tool for modeling sequential data as shown by the success in Natural Language, Computer Vision and Signal Processing. Process Mining concerns discovering insights on business processes from their execution data that are logged by supporting information systems. The logged data (event log) is formed of event sequences (traces) that correspond to executions of a process. Many Deep Learning techniques have been successfully adapted for predictive Process Mining that aims to predict process outcomes, remaining time, the next event, or even the suffix of running traces. Traces in Process Mining are multimodal sequences and very differently structured than natural language sentences or images. This may require a different approach to processing. So far, there has been little focus on these differences and the challenges introduced. Looking at suffix prediction as the most challenging of these tasks, the performance of Deep Learning models was evaluated only on average measures and for a small number of real-life event logs. Comparing the results between papers is difficult due to different pre-processing and evaluation strategies. Challenges that may be relevant are the skewness of trace-length distribution and the skewness of the activity distribution in real-life event logs. We provide an end-to-end framework which enables to compare the performance of seven state-of-the-art sequential architectures in common settings. Results show that sequence modeling still has a lot of room for improvement for majority of the more complex datasets. Further research and insights are required to get consistent performance not just in average measures but additionally over all the prefixes.
Cost-effective vibration analysis through data-backed pipeline optimisation
Aug 16, 2021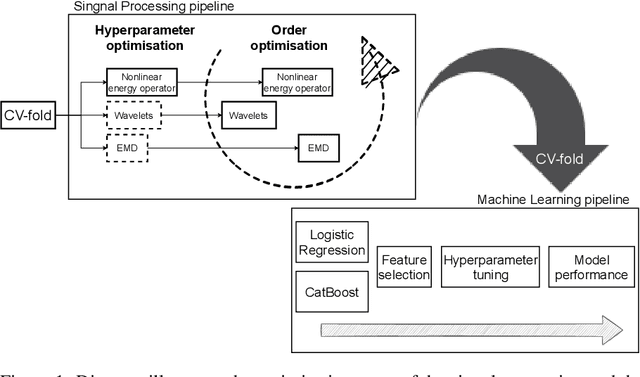

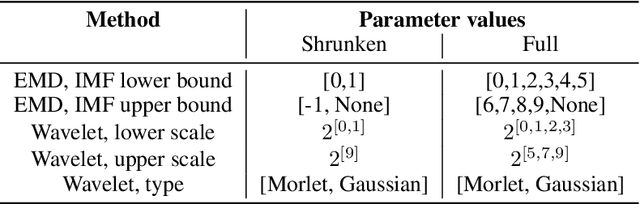
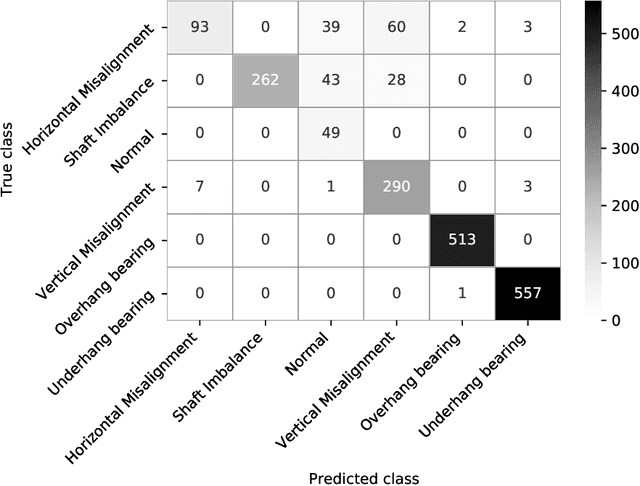
Vibration analysis is an active area of research, aimed, among other targets, at an accurate classification of machinery failure modes. This often leads to complex and convoluted signal processing pipeline designs, which are computationally demanding and cannot be deployed in the Edge devices. In the current work, we address this issue by proposing a data-driven methodology that allows optimising and justifying the complexity of the signal processing pipelines. Additionally, aiming to make IoT vibration analysis systems more cost- and computationally effective, on the example of MAFAULDA vibration dataset, we assess the changes in the failure classification performance at low sampling rates as well as short observation time windows. We find out that a decrease of the sampling rate from 50 kHz to 1 kHz leads to a statistically significant classification performance drop. A statistically significant decrease is also observed for the 0.1 second time windows compared to the 5-second ones. However, the effect sizes are small to medium, suggesting that in certain settings lower sampling rates and shorter observation windows can be used. The proposed optimisation approach, as well as statistically supported findings of the study, allow a more efficient design of IoT vibration analysis systems, both in terms of complexity and costs, bringing us one step closer to the IoT/Edge-based vibration analysis.
Learning Correlation Space for Time Series
May 15, 2018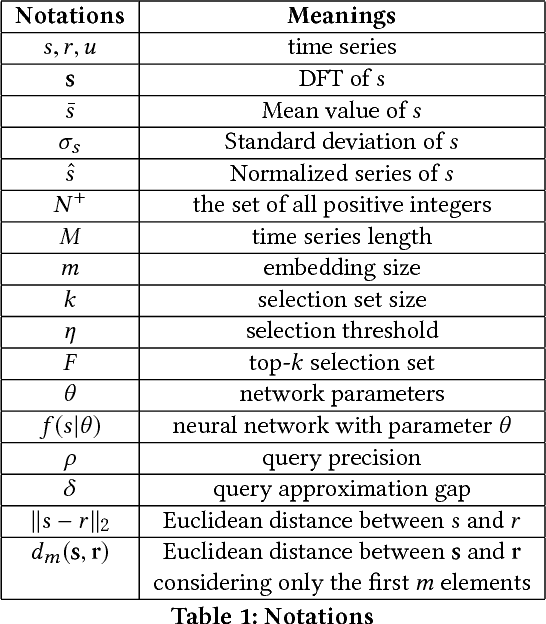
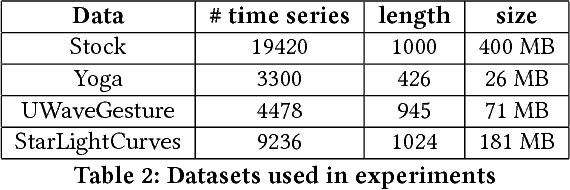
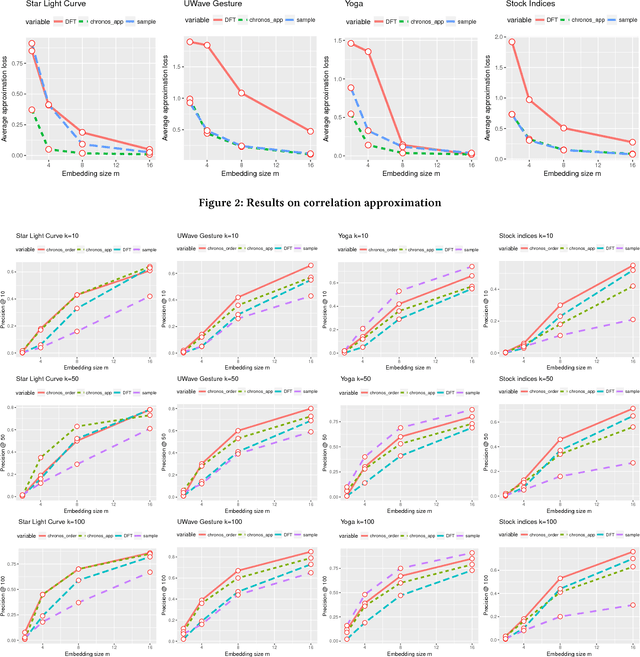
We propose an approximation algorithm for efficient correlation search in time series data. In our method, we use Fourier transform and neural network to embed time series into a low-dimensional Euclidean space. The given space is learned such that time series correlation can be effectively approximated from Euclidean distance between corresponding embedded vectors. Therefore, search for correlated time series can be done using an index in the embedding space for efficient nearest neighbor search. Our theoretical analysis illustrates that our method's accuracy can be guaranteed under certain regularity conditions. We further conduct experiments on real-world datasets and the results show that our method indeed outperforms the baseline solution. In particular, for approximation of correlation, our method reduces the approximation loss by a half in most test cases compared to the baseline solution. For top-$k$ highest correlation search, our method improves the precision from 5\% to 20\% while the query time is similar to the baseline approach query time.
RootPainter3D: Interactive-machine-learning enables rapid and accurate contouring for radiotherapy
Jun 22, 2021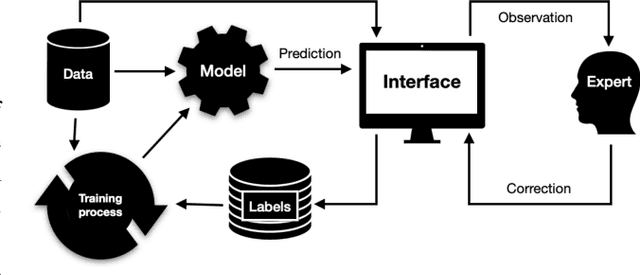

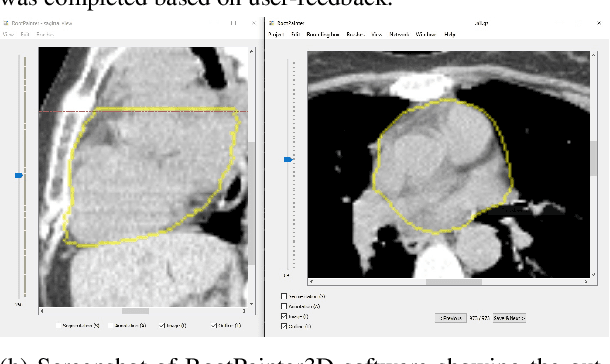
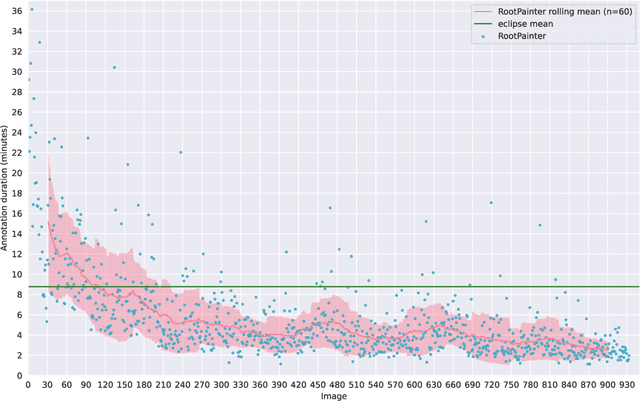
Organ-at-risk contouring is still a bottleneck in radiotherapy, with many deep learning methods falling short of promised results when evaluated on clinical data. We investigate the accuracy and time-savings resulting from the use of an interactive-machine-learning method for an organ-at-risk contouring task. We compare the method to the Eclipse contouring software and find strong agreement with manual delineations, with a dice score of 0.95. The annotations created using corrective-annotation also take less time to create as more images are annotated, resulting in substantial time savings compared to manual methods, with hearts that take 2 minutes and 2 seconds to delineate on average, after 923 images have been delineated, compared to 7 minutes and 1 seconds when delineating manually. Our experiment demonstrates that interactive-machine-learning with corrective-annotation provides a fast and accessible way for non computer-scientists to train deep-learning models to segment their own structures of interest as part of routine clinical workflows. Source code is available at \href{https://github.com/Abe404/RootPainter3D}{this HTTPS URL}.
Deep speech inpainting of time-frequency masks
Oct 22, 2019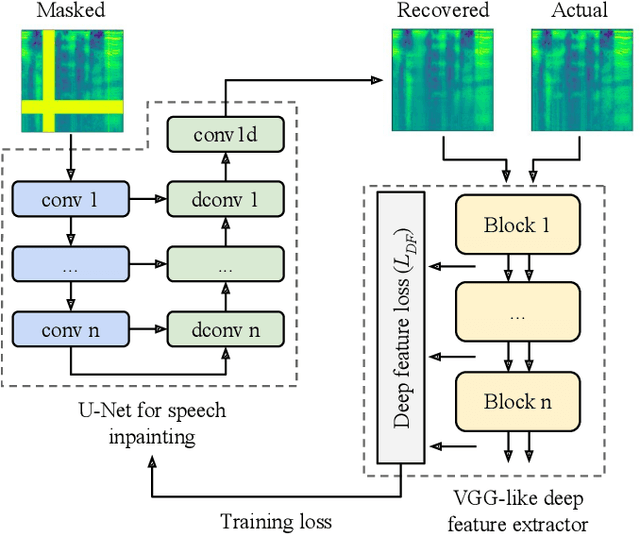
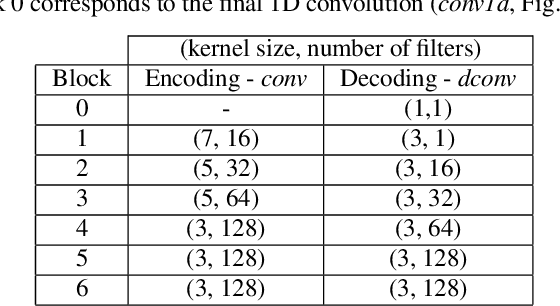
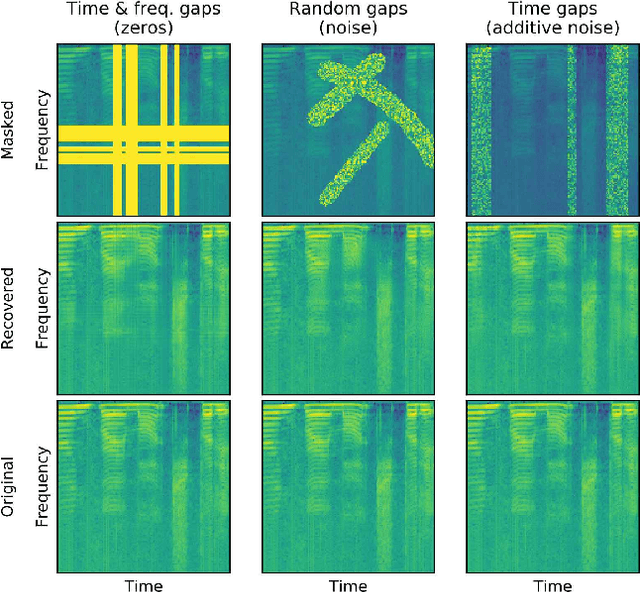
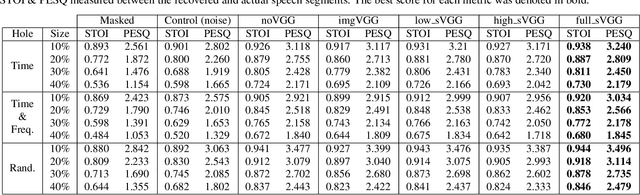
In particularly noisy environments, transient loud intrusions can completely overpower parts of the speech signal, leading to an inevitable loss of information. Recent algorithms for noise suppression often yield impressive results but tend to struggle when the signal-to-noise ratio (SNR) of the mixture is low or when parts of the signal are missing. To address these issues, here we introduce an end-to-end framework for the retrieval of missing or severely distorted parts of time-frequency representation of speech, from the short-term context, thus speech inpainting. The framework is based on a convolutional U-Net trained via deep feature losses, obtained through speechVGG, a deep speech feature extractor pre-trained on the word classification task. Our evaluation results demonstrate that the proposed framework is effective at recovering large portions of missing or distorted parts of speech. Specifically, it yields notable improvements in STOI & PESQ objective metrics, as assessed using the LibriSpeech dataset.
Cross-Modality Domain Adaptation for Vestibular Schwannoma and Cochlea Segmentation
Sep 21, 2021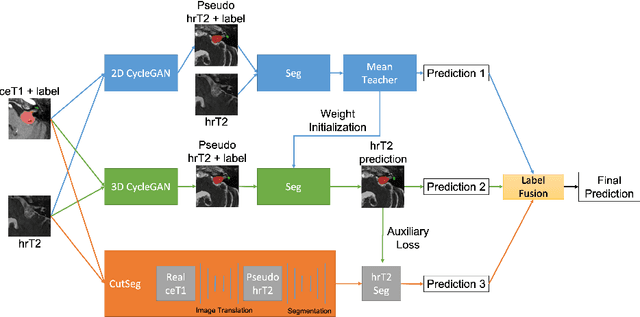


Automatic methods to segment the vestibular schwannoma (VS) tumors and the cochlea from magnetic resonance imaging (MRI) are critical to VS treatment planning. Although supervised methods have achieved satisfactory performance in VS segmentation, they require full annotations by experts, which is laborious and time-consuming. In this work, we aim to tackle the VS and cochlea segmentation problem in an unsupervised domain adaptation setting. Our proposed method leverages both the image-level domain alignment to minimize the domain divergence and semi-supervised training to further boost the performance. Furthermore, we propose to fuse the labels predicted from multiple models via noisy label correction. Our results on the challenge validation leaderboard showed that our unsupervised method has achieved promising VS and cochlea segmentation performance with mean dice score of 0.8261 $\pm$ 0.0416; The mean dice value for the tumor is 0.8302 $\pm$ 0.0772. This is comparable to the weakly-supervised based method.
RAIL-KD: RAndom Intermediate Layer Mapping for Knowledge Distillation
Oct 01, 2021
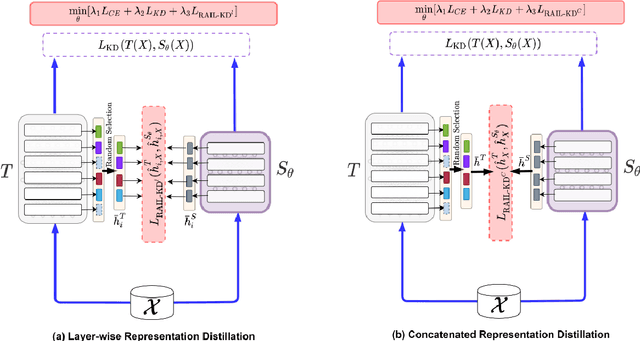
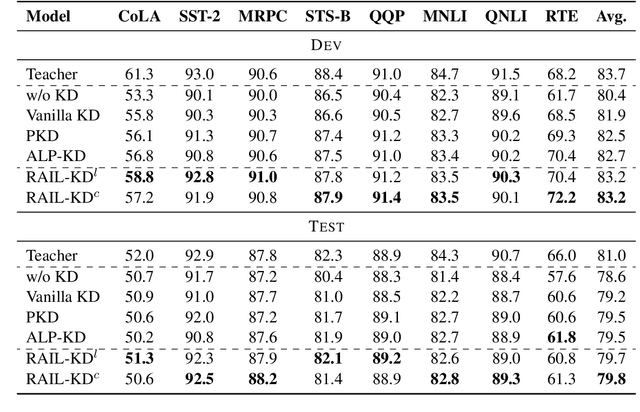
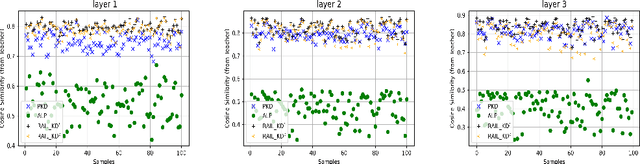
Intermediate layer knowledge distillation (KD) can improve the standard KD technique (which only targets the output of teacher and student models) especially over large pre-trained language models. However, intermediate layer distillation suffers from excessive computational burdens and engineering efforts required for setting up a proper layer mapping. To address these problems, we propose a RAndom Intermediate Layer Knowledge Distillation (RAIL-KD) approach in which, intermediate layers from the teacher model are selected randomly to be distilled into the intermediate layers of the student model. This randomized selection enforce that: all teacher layers are taken into account in the training process, while reducing the computational cost of intermediate layer distillation. Also, we show that it act as a regularizer for improving the generalizability of the student model. We perform extensive experiments on GLUE tasks as well as on out-of-domain test sets. We show that our proposed RAIL-KD approach outperforms other state-of-the-art intermediate layer KD methods considerably in both performance and training-time.
Distance-aware Quantization
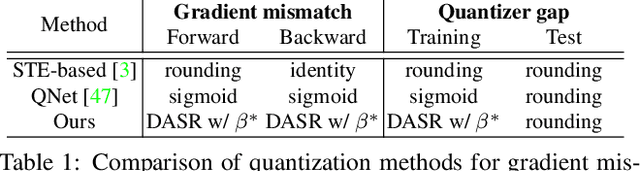
Aug 16, 2021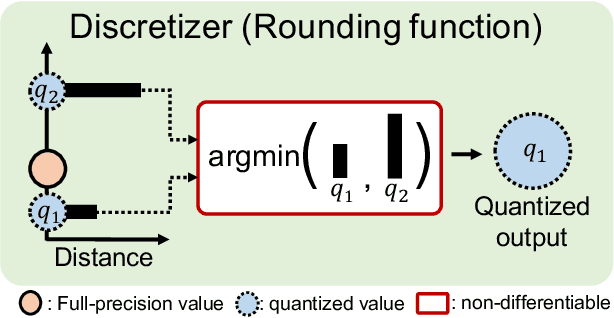
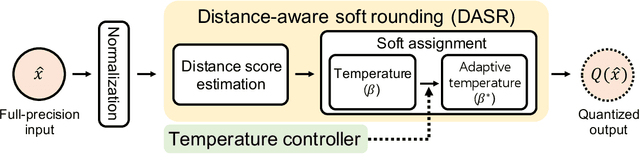

We address the problem of network quantization, that is, reducing bit-widths of weights and/or activations to lighten network architectures. Quantization methods use a rounding function to map full-precision values to the nearest quantized ones, but this operation is not differentiable. There are mainly two approaches to training quantized networks with gradient-based optimizers. First, a straight-through estimator (STE) replaces the zero derivative of the rounding with that of an identity function, which causes a gradient mismatch problem. Second, soft quantizers approximate the rounding with continuous functions at training time, and exploit the rounding for quantization at test time. This alleviates the gradient mismatch, but causes a quantizer gap problem. We alleviate both problems in a unified framework. To this end, we introduce a novel quantizer, dubbed a distance-aware quantizer (DAQ), that mainly consists of a distance-aware soft rounding (DASR) and a temperature controller. To alleviate the gradient mismatch problem, DASR approximates the discrete rounding with the kernel soft argmax, which is based on our insight that the quantization can be formulated as a distance-based assignment problem between full-precision values and quantized ones. The controller adjusts the temperature parameter in DASR adaptively according to the input, addressing the quantizer gap problem. Experimental results on standard benchmarks show that DAQ outperforms the state of the art significantly for various bit-widths without bells and whistles.