 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Minimizing LR(1) State Machines is NP-Hard
Oct 02, 2021
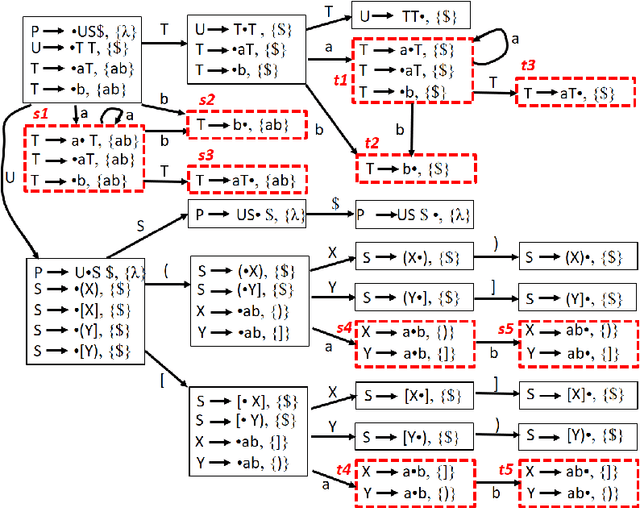
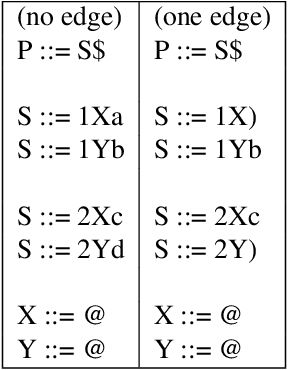
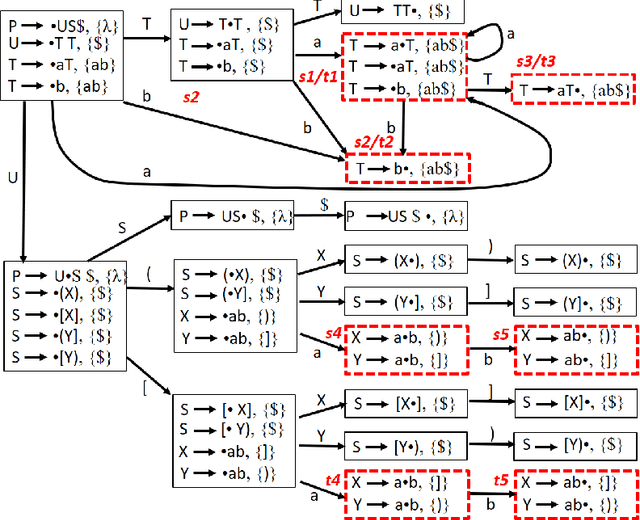
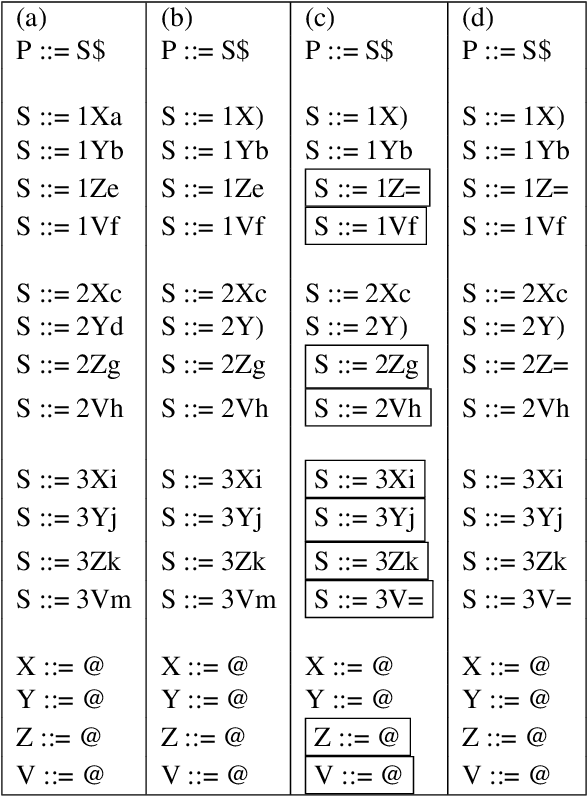
LR(1) parsing was a focus of extensive research in the past 50 years. Though most fundamental mysteries have been resolved, a few remain hidden in the dark corners. The one we bumped into is the minimization of the LR(1) state machines, which we prove is NP-hard. It is the node-coloring problem that is reduced to the minimization puzzle. The reduction makes use of two technique: indirect reduction and incremental construction. Indirect reduction means the graph to be colored is not reduced to an LR(1) state machine directly. Instead, it is reduced to a context-free grammar from which an LR(1) state machine is derived. Furthermore, by considering the nodes in the graph to be colored one at a time, the context-free grammar is incrementally extended from a template context-free grammar that is for a two-node graph. The extension is done by adding new grammar symbols and rules. A minimized LR(1) machine can be used to recover a minimum coloring of the original graph.
A Deep Learning Approach for Masking Fetal Gender in Ultrasound Images
Sep 14, 2021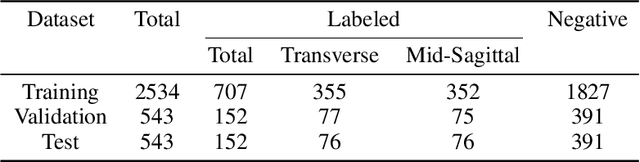
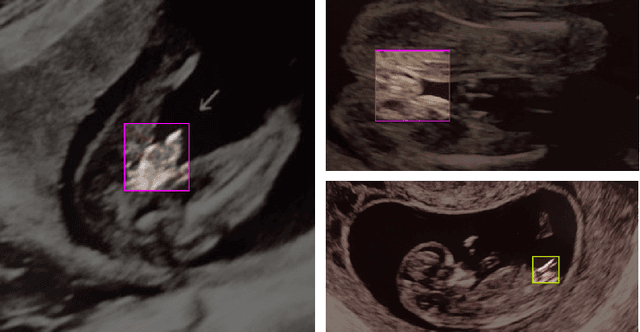
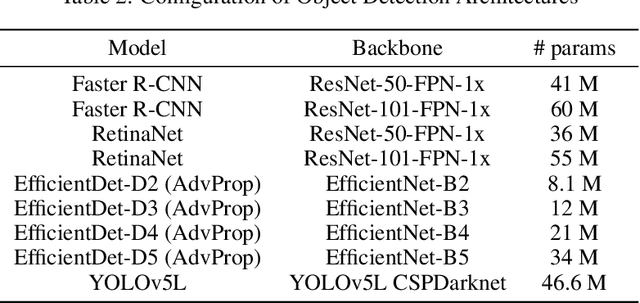
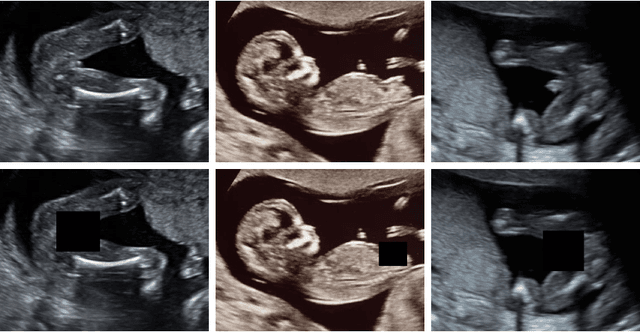
Ultrasound (US) imaging is highly effective with regards to both cost and versatility in real-time diagnosis; however, determination of fetal gender by US scan in the early stages of pregnancy is also a cause of sex-selective abortion. This work proposes a deep learning object detection approach to accurately mask fetal gender in US images in order to increase the accessibility of the technology. We demonstrate how the YOLOv5L architecture exhibits superior performance relative to other object detection models on this task. Our model achieves 45.8% AP[0.5:0.95], 92% F1-score and 0.006 False Positive Per Image rate on our test set. Furthermore, we introduce a bounding box delay rule based on frame-to-frame structural similarity to reduce the false negative rate by 85%, further improving masking reliability.
A Queueing-Theoretic Framework for Vehicle Dispatching in Dynamic Car-Hailing [technical report]
Aug 11, 2021![Figure 1 for A Queueing-Theoretic Framework for Vehicle Dispatching in Dynamic Car-Hailing [technical report]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Ffc232beef2f64fd18a8e781332d3e64520fe1361%2F1-Figure1-1.png&w=640&q=75)
![Figure 2 for A Queueing-Theoretic Framework for Vehicle Dispatching in Dynamic Car-Hailing [technical report]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Ffc232beef2f64fd18a8e781332d3e64520fe1361%2F3-Table1-1.png&w=640&q=75)
![Figure 3 for A Queueing-Theoretic Framework for Vehicle Dispatching in Dynamic Car-Hailing [technical report]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Ffc232beef2f64fd18a8e781332d3e64520fe1361%2F4-Figure2-1.png&w=640&q=75)
![Figure 4 for A Queueing-Theoretic Framework for Vehicle Dispatching in Dynamic Car-Hailing [technical report]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Ffc232beef2f64fd18a8e781332d3e64520fe1361%2F10-Table2-1.png&w=640&q=75)
With the rapid development of smart mobile devices, the car-hailing platforms (e.g., Uber or Lyft) have attracted much attention from both the academia and the industry. In this paper, we consider an important dynamic car-hailing problem, namely \textit{maximum revenue vehicle dispatching} (MRVD), in which rider requests dynamically arrive and drivers need to serve as many riders as possible such that the entire revenue of the platform is maximized. We prove that the MRVD problem is NP-hard and intractable. In addition, the dynamic car-hailing platforms have no information of the future riders, which makes the problem even harder. To handle the MRVD problem, we propose a queueing-based vehicle dispatching framework, which first uses existing machine learning algorithms to predict the future vehicle demand of each region, then estimates the idle time periods of drivers through a queueing model for each region. With the information of the predicted vehicle demands and estimated idle time periods of drivers, we propose two batch-based vehicle dispatching algorithms to efficiently assign suitable drivers to riders such that the expected overall revenue of the platform is maximized during each batch processing. Through extensive experiments, we demonstrate the efficiency and effectiveness of our proposed approaches over both real and synthetic datasets.
Fast Projection onto the Capped Simplex withApplications to Sparse Regression in Bioinformatics
Oct 19, 2021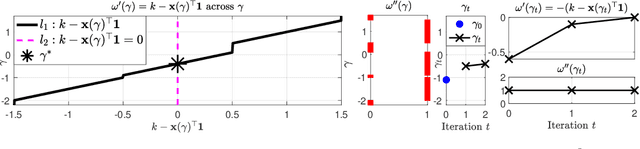
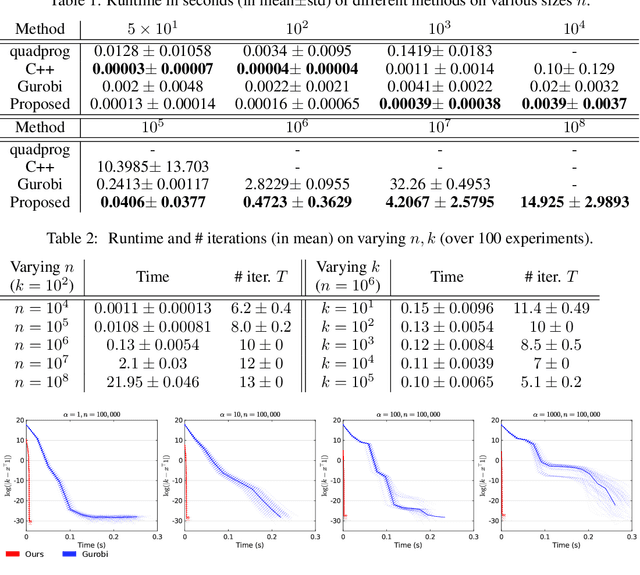
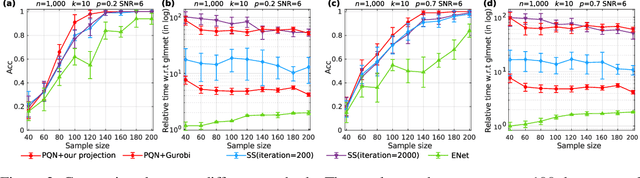
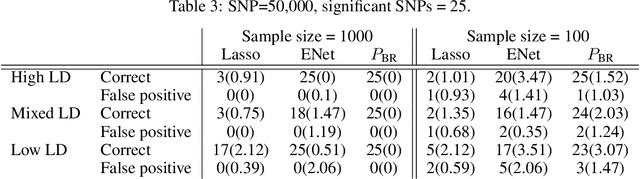
We consider the problem of projecting a vector onto the so-called k-capped simplex, which is a hyper-cube cut by a hyperplane. For an n-dimensional input vector with bounded elements, we found that a simple algorithm based on Newton's method is able to solve the projection problem to high precision with a complexity roughly about O(n), which has a much lower computational cost compared with the existing sorting-based methods proposed in the literature. We provide a theory for partial explanation and justification of the method. We demonstrate that the proposed algorithm can produce a solution of the projection problem with high precision on large scale datasets, and the algorithm is able to significantly outperform the state-of-the-art methods in terms of runtime (about 6-8 times faster than a commercial software with respect to CPU time for input vector with 1 million variables or more). We further illustrate the effectiveness of the proposed algorithm on solving sparse regression in a bioinformatics problem. Empirical results on the GWAS dataset (with 1,500,000 single-nucleotide polymorphisms) show that, when using the proposed method to accelerate the Projected Quasi-Newton (PQN) method, the accelerated PQN algorithm is able to handle huge-scale regression problem and it is more efficient (about 3-6 times faster) than the current state-of-the-art methods.
AP-MTL: Attention Pruned Multi-task Learning Model for Real-time Instrument Detection and Segmentation in Robot-assisted Surgery
Mar 10, 2020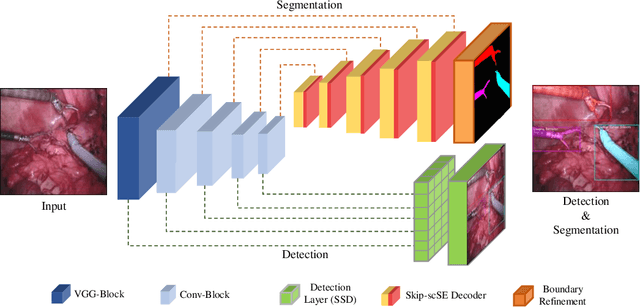
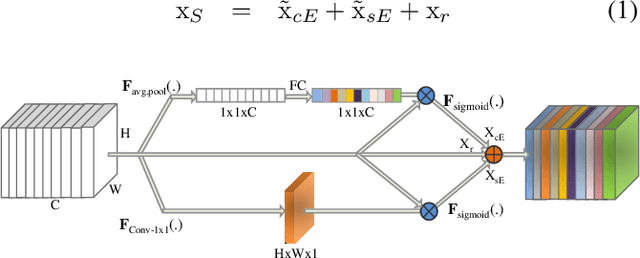
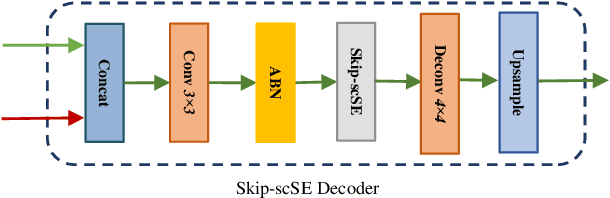
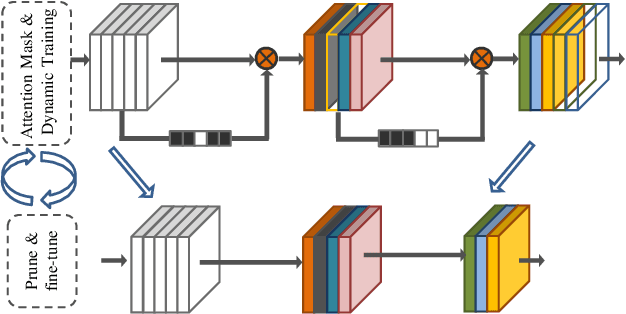
Surgical scene understanding and multi-tasking learning are crucial for image-guided robotic surgery. Training a real-time robotic system for the detection and segmentation of high-resolution images provides a challenging problem with the limited computational resource. The perception drawn can be applied in effective real-time feedback, surgical skill assessment, and human-robot collaborative surgeries to enhance surgical outcomes. For this purpose, we develop a novel end-to-end trainable real-time Multi-Task Learning (MTL) model with weight-shared encoder and task-aware detection and segmentation decoders. Optimization of multiple tasks at the same convergence point is vital and presents a complex problem. Thus, we propose an asynchronous task-aware optimization (ATO) technique to calculate task-oriented gradients and train the decoders independently. Moreover, MTL models are always computationally expensive, which hinder real-time applications. To address this challenge, we introduce a global attention dynamic pruning (GADP) by removing less significant and sparse parameters. We further design a skip squeeze and excitation (SE) module, which suppresses weak features, excites significant features and performs dynamic spatial and channel-wise feature re-calibration. Validating on the robotic instrument segmentation dataset of MICCAI endoscopic vision challenge, our model significantly outperforms state-of-the-art segmentation and detection models, including best-performed models in the challenge.
Incorporating Data Uncertainty in Object Tracking Algorithms
Sep 22, 2021
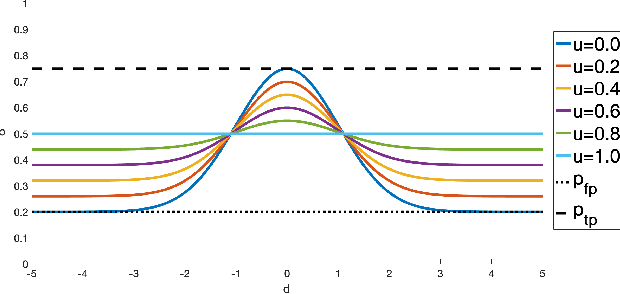

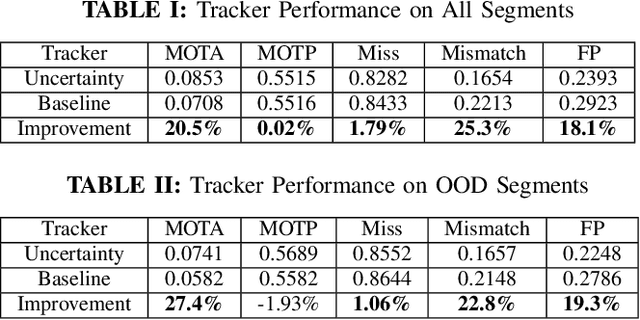
Methodologies for incorporating the uncertainties characteristic of data-driven object detectors into object tracking algorithms are explored. Object tracking methods rely on measurement error models, typically in the form of measurement noise, false positive rates, and missed detection rates. Each of these quantities, in general, can be dependent on object or measurement location. However, for detections generated from neural-network processed camera inputs, these measurement error statistics are not sufficient to represent the primary source of errors, namely a dissimilarity between run-time sensor input and the training data upon which the detector was trained. To this end, we investigate incorporating data uncertainty into object tracking methods such as to improve the ability to track objects, and particularly those which out-of-distribution w.r.t. training data. The proposed methodologies are validated on an object tracking benchmark as well on experiments with a real autonomous aircraft.
An algorithm for a fairer and better voting system
Oct 13, 2021The major finding, of this article, is an ensemble method, but more exactly, a novel, better ranked voting system (and other variations of it), that aims to solve the problem of finding the best candidate to represent the voters. We have the source code on GitHub, for making realistic simulations of elections, based on artificial intelligence for comparing different variations of the algorithm, and other already known algorithms. We have convincing evidence that our algorithm is better than Instant-Runoff Voting, Preferential Block Voting, Single Transferable Vote, and First Past The Post (if certain, natural conditions are met, to support the wisdom of the crowds). By also comparing with the best voter, we demonstrated the wisdom of the crowds, suggesting that democracy (distributed system) is a better option than dictatorship (centralized system), if those certain, natural conditions are met. Voting systems are not restricted to politics, they are ensemble methods for artificial intelligence, but the context of this article is natural intelligence. It is important to find a system that is fair (e.g. freedom of expression on the ballot exists), especially when the outcome of the voting system has social impact: some voting systems have the unfair inevitability to trend (over time) towards the same two major candidates (Duverger's law).
StarGANv2-VC: A Diverse, Unsupervised, Non-parallel Framework for Natural-Sounding Voice Conversion
Jul 23, 2021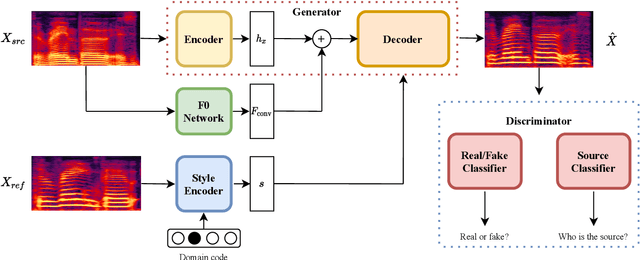
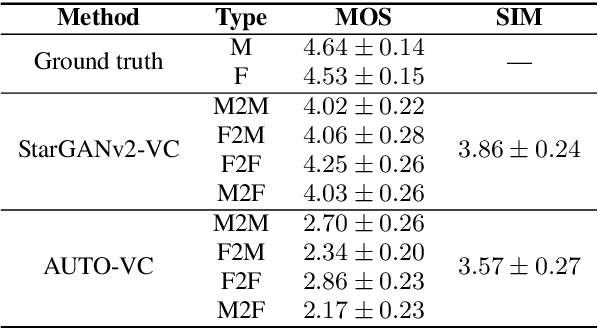
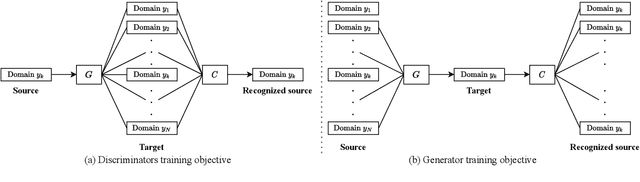
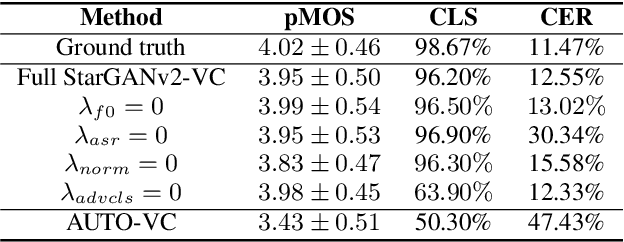
We present an unsupervised non-parallel many-to-many voice conversion (VC) method using a generative adversarial network (GAN) called StarGAN v2. Using a combination of adversarial source classifier loss and perceptual loss, our model significantly outperforms previous VC models. Although our model is trained only with 20 English speakers, it generalizes to a variety of voice conversion tasks, such as any-to-many, cross-lingual, and singing conversion. Using a style encoder, our framework can also convert plain reading speech into stylistic speech, such as emotional and falsetto speech. Subjective and objective evaluation experiments on a non-parallel many-to-many voice conversion task revealed that our model produces natural sounding voices, close to the sound quality of state-of-the-art text-to-speech (TTS) based voice conversion methods without the need for text labels. Moreover, our model is completely convolutional and with a faster-than-real-time vocoder such as Parallel WaveGAN can perform real-time voice conversion.
Score-based diffusion models for accelerated MRI
Oct 08, 2021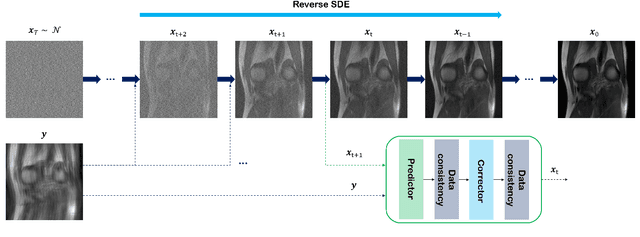
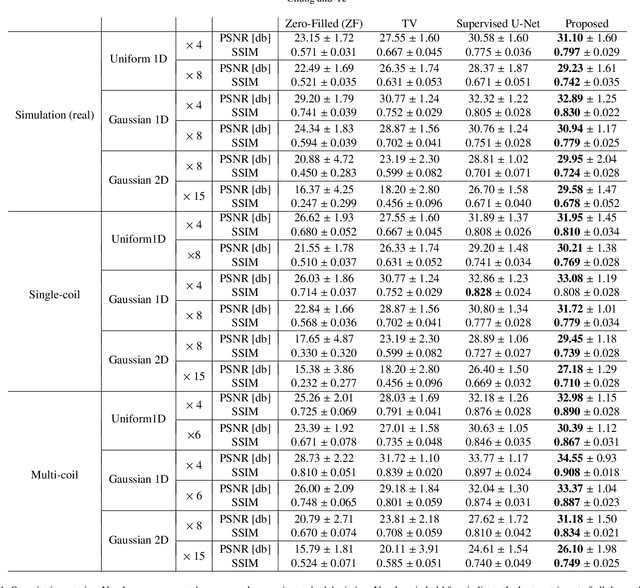
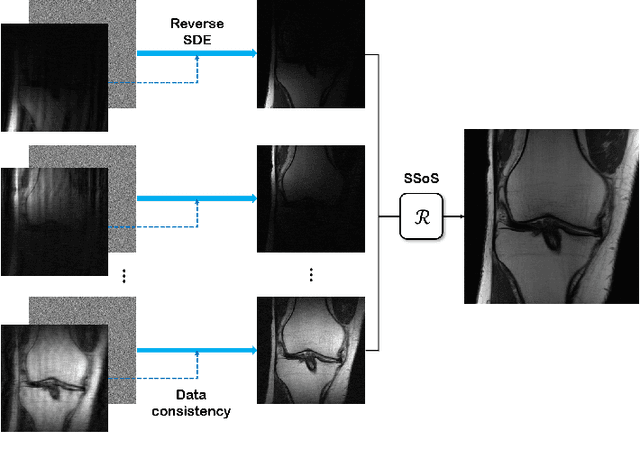
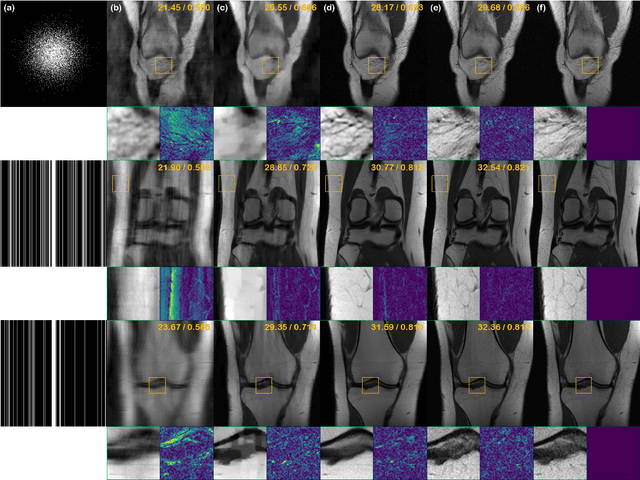
Score-based diffusion models provide a powerful way to model images using the gradient of the data distribution. Leveraging the learned score function as a prior, here we introduce a way to sample data from a conditional distribution given the measurements, such that the model can be readily used for solving inverse problems in imaging, especially for accelerated MRI. In short, we train a continuous time-dependent score function with denoising score matching. Then, at the inference stage, we iterate between numerical SDE solver and data consistency projection step to achieve reconstruction. Our model requires magnitude images only for training, and yet is able to reconstruct complex-valued data, and even extends to parallel imaging. The proposed method is agnostic to sub-sampling patterns, and can be used with any sampling schemes. Also, due to its generative nature, our approach can quantify uncertainty, which is not possible with standard regression settings. On top of all the advantages, our method also has very strong performance, even beating the models trained with full supervision. With extensive experiments, we verify the superiority of our method in terms of quality and practicality.
Graph Communal Contrastive Learning
Oct 28, 2021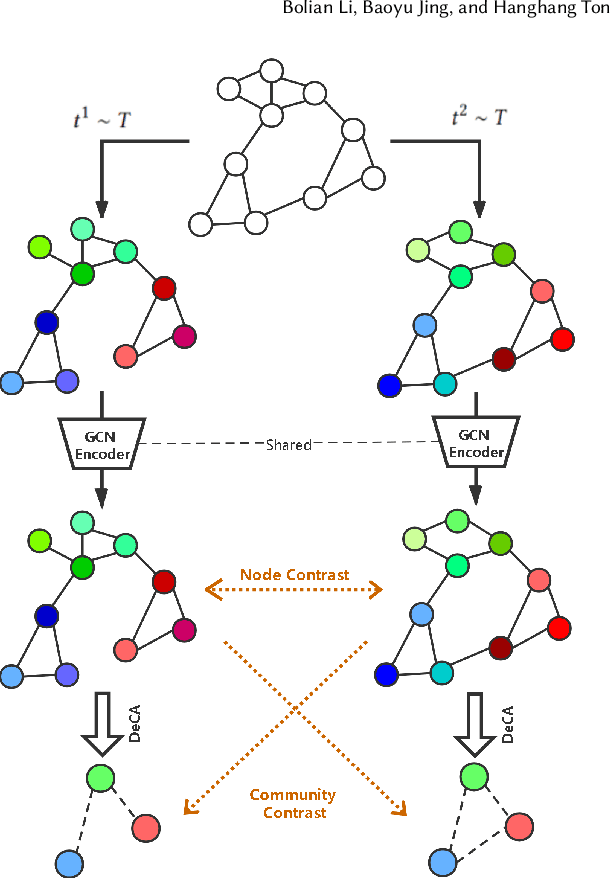

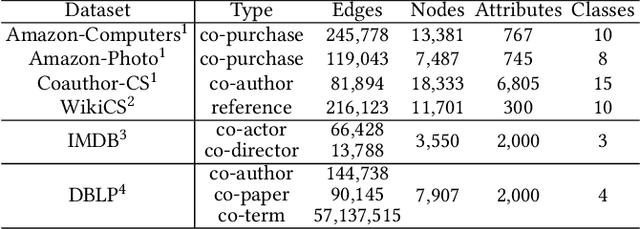
Graph representation learning is crucial for many real-world applications (e.g. social relation analysis). A fundamental problem for graph representation learning is how to effectively learn representations without human labeling, which is usually costly and time-consuming. Graph contrastive learning (GCL) addresses this problem by pulling the positive node pairs (or similar nodes) closer while pushing the negative node pairs (or dissimilar nodes) apart in the representation space. Despite the success of the existing GCL methods, they primarily sample node pairs based on the node-level proximity yet the community structures have rarely been taken into consideration. As a result, two nodes from the same community might be sampled as a negative pair. We argue that the community information should be considered to identify node pairs in the same communities, where the nodes insides are semantically similar. To address this issue, we propose a novel Graph Communal Contrastive Learning (gCooL) framework to jointly learn the community partition and learn node representations in an end-to-end fashion. Specifically, the proposed gCooL consists of two components: a Dense Community Aggregation (DeCA) algorithm for community detection and a Reweighted Self-supervised Cross-contrastive (ReSC) training scheme to utilize the community information. Additionally, the real-world graphs are complex and often consist of multiple views. In this paper, we demonstrate that the proposed gCooL can also be naturally adapted to multiplex graphs. Finally, we comprehensively evaluate the proposed gCooL on a variety of real-world graphs. The experimental results show that the gCooL outperforms the state-of-the-art methods.