 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Chinese Traditional Poetry Generating System Based on Deep Learning
Oct 24, 2021
Chinese traditional poetry is an important intangible cultural heritage of China and an artistic carrier of thought, culture, spirit and emotion. However, due to the strict rules of ancient poetry, it is very difficult to write poetry by machine. This paper proposes an automatic generation method of Chinese traditional poetry based on deep learning technology, which extracts keywords from each poem and matches them with the previous text to make the poem conform to the theme, and when a user inputs a paragraph of text, the machine obtains the theme and generates poem sentence by sentence. Using the classic word2vec model as the preprocessing model, the Chinese characters which are not understood by the computer are transformed into matrix for processing. Bi-directional Long Short-Term Memory is used as the neural network model to generate Chinese characters one by one and make the meaning of Chinese characters as accurate as possible. At the same time, TF-IDF and TextRank are used to extract keywords. Using the attention mechanism based encoding-decoding model, we can solve practical problems by transforming the model, and strengthen the important information of long-distance information, so as to grasp the key points without losing important information. In the aspect of emotion judgment, Long Short-Term Memory network is used. The final result shows that it can get good poetry outputs according to the user input text.
HUNTER: AI based Holistic Resource Management for Sustainable Cloud Computing
Oct 28, 2021
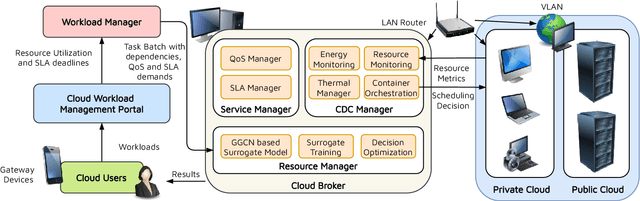
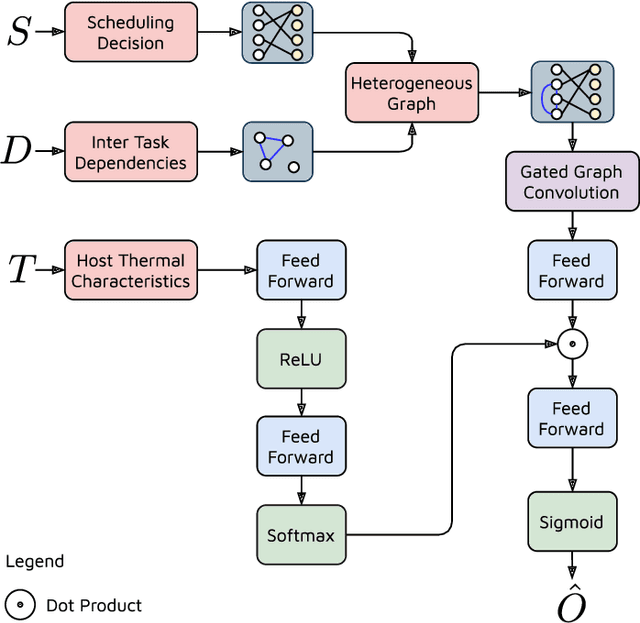
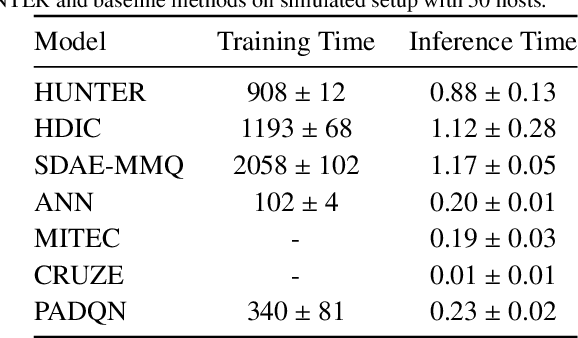
The worldwide adoption of cloud data centers (CDCs) has given rise to the ubiquitous demand for hosting application services on the cloud. Further, contemporary data-intensive industries have seen a sharp upsurge in the resource requirements of modern applications. This has led to the provisioning of an increased number of cloud servers, giving rise to higher energy consumption and, consequently, sustainability concerns. Traditional heuristics and reinforcement learning based algorithms for energy-efficient cloud resource management address the scalability and adaptability related challenges to a limited extent. Existing work often fails to capture dependencies across thermal characteristics of hosts, resource consumption of tasks and the corresponding scheduling decisions. This leads to poor scalability and an increase in the compute resource requirements, particularly in environments with non-stationary resource demands. To address these limitations, we propose an artificial intelligence (AI) based holistic resource management technique for sustainable cloud computing called HUNTER. The proposed model formulates the goal of optimizing energy efficiency in data centers as a multi-objective scheduling problem, considering three important models: energy, thermal and cooling. HUNTER utilizes a Gated Graph Convolution Network as a surrogate model for approximating the Quality of Service (QoS) for a system state and generating optimal scheduling decisions. Experiments on simulated and physical cloud environments using the CloudSim toolkit and the COSCO framework show that HUNTER outperforms state-of-the-art baselines in terms of energy consumption, SLA violation, scheduling time, cost and temperature by up to 12, 35, 43, 54 and 3 percent respectively.
AP-MTL: Attention Pruned Multi-task Learning Model for Real-time Instrument Detection and Segmentation in Robot-assisted Surgery
Mar 10, 2020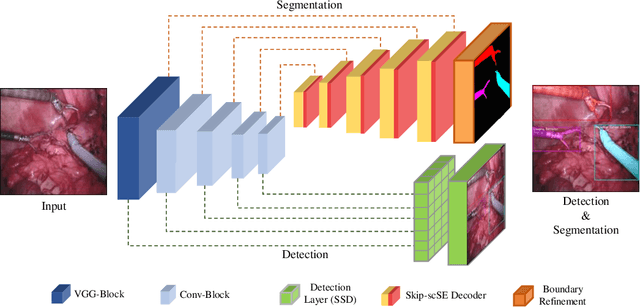
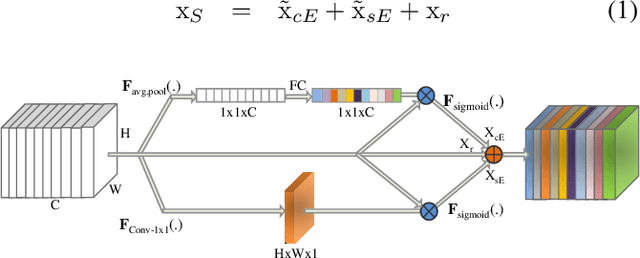
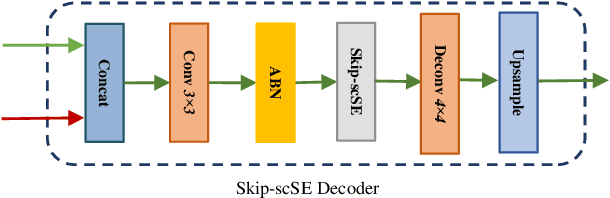
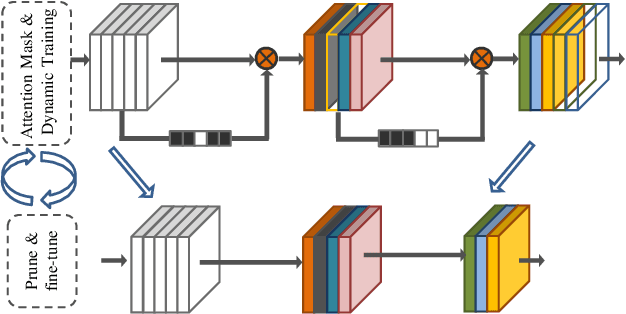
Surgical scene understanding and multi-tasking learning are crucial for image-guided robotic surgery. Training a real-time robotic system for the detection and segmentation of high-resolution images provides a challenging problem with the limited computational resource. The perception drawn can be applied in effective real-time feedback, surgical skill assessment, and human-robot collaborative surgeries to enhance surgical outcomes. For this purpose, we develop a novel end-to-end trainable real-time Multi-Task Learning (MTL) model with weight-shared encoder and task-aware detection and segmentation decoders. Optimization of multiple tasks at the same convergence point is vital and presents a complex problem. Thus, we propose an asynchronous task-aware optimization (ATO) technique to calculate task-oriented gradients and train the decoders independently. Moreover, MTL models are always computationally expensive, which hinder real-time applications. To address this challenge, we introduce a global attention dynamic pruning (GADP) by removing less significant and sparse parameters. We further design a skip squeeze and excitation (SE) module, which suppresses weak features, excites significant features and performs dynamic spatial and channel-wise feature re-calibration. Validating on the robotic instrument segmentation dataset of MICCAI endoscopic vision challenge, our model significantly outperforms state-of-the-art segmentation and detection models, including best-performed models in the challenge.
Text analysis and deep learning: A network approach
Oct 08, 2021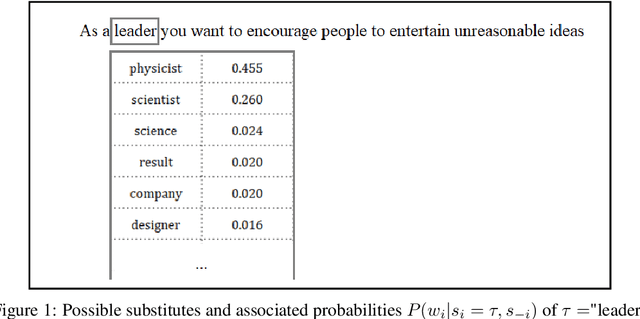
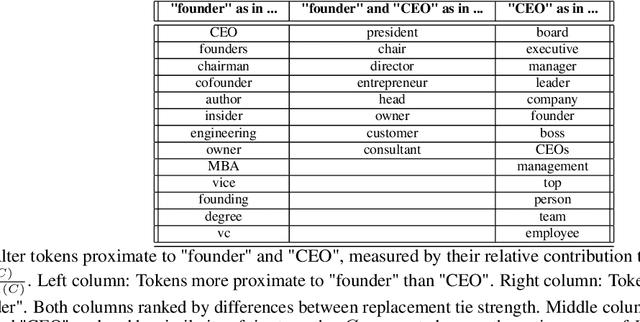
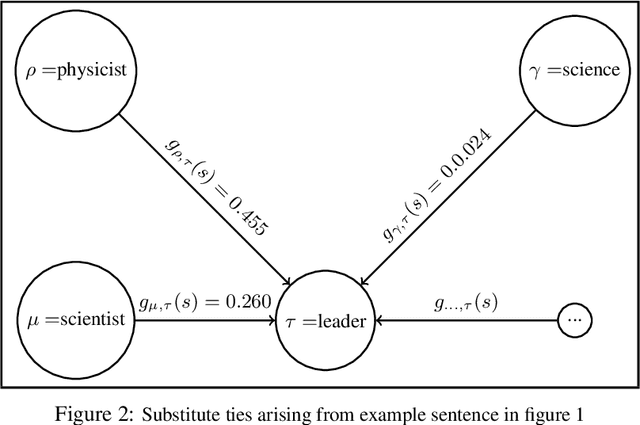
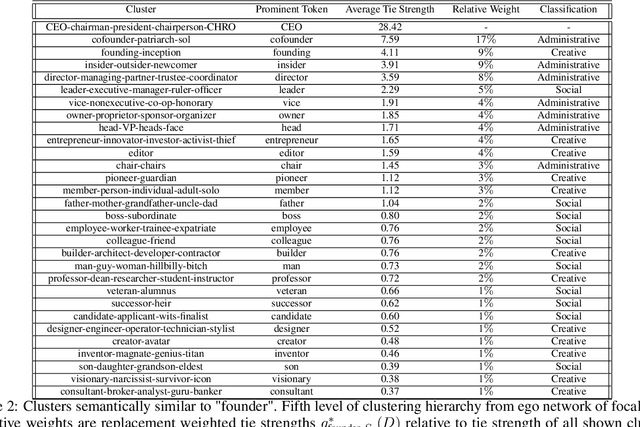
Much information available to applied researchers is contained within written language or spoken text. Deep language models such as BERT have achieved unprecedented success in many applications of computational linguistics. However, much less is known about how these models can be used to analyze existing text. We propose a novel method that combines transformer models with network analysis to form a self-referential representation of language use within a corpus of interest. Our approach produces linguistic relations strongly consistent with the underlying model as well as mathematically well-defined operations on them, while reducing the amount of discretionary choices of representation and distance measures. It represents, to the best of our knowledge, the first unsupervised method to extract semantic networks directly from deep language models. We illustrate our approach in a semantic analysis of the term "founder". Using the entire corpus of Harvard Business Review from 1980 to 2020, we find that ties in our network track the semantics of discourse over time, and across contexts, identifying and relating clusters of semantic and syntactic relations. Finally, we discuss how this method can also complement and inform analyses of the behavior of deep learning models.
Learning Models as Functionals of Signed-Distance Fields for Manipulation Planning
Oct 02, 2021



This work proposes an optimization-based manipulation planning framework where the objectives are learned functionals of signed-distance fields that represent objects in the scene. Most manipulation planning approaches rely on analytical models and carefully chosen abstractions/state-spaces to be effective. A central question is how models can be obtained from data that are not primarily accurate in their predictions, but, more importantly, enable efficient reasoning within a planning framework, while at the same time being closely coupled to perception spaces. We show that representing objects as signed-distance fields not only enables to learn and represent a variety of models with higher accuracy compared to point-cloud and occupancy measure representations, but also that SDF-based models are suitable for optimization-based planning. To demonstrate the versatility of our approach, we learn both kinematic and dynamic models to solve tasks that involve hanging mugs on hooks and pushing objects on a table. We can unify these quite different tasks within one framework, since SDFs are the common object representation. Video: https://youtu.be/ga8Wlkss7co
Predicting the 2020 US Presidential Election with Twitter
Jul 19, 2021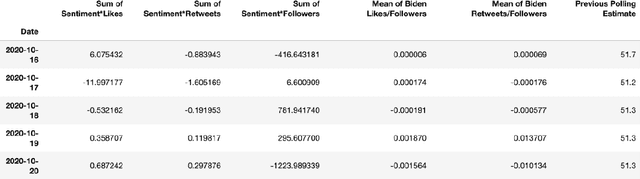
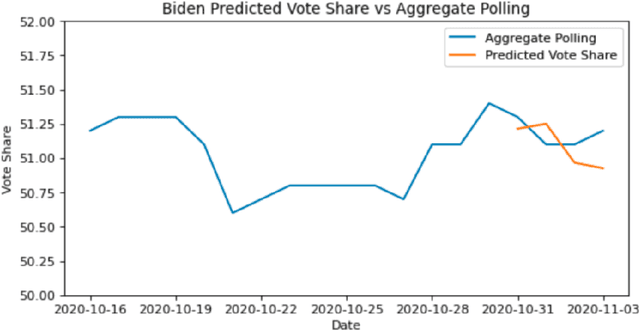
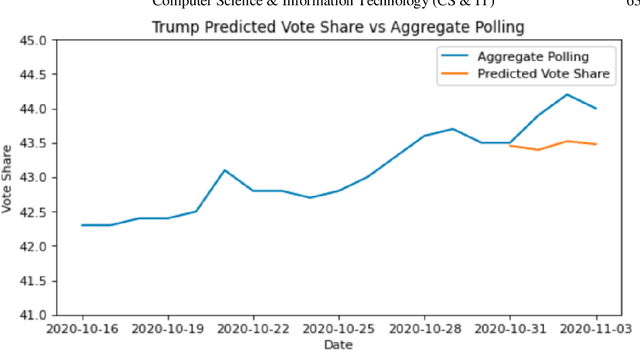
One major sub-domain in the subject of polling public opinion with social media data is electoral prediction. Electoral prediction utilizing social media data potentially would significantly affect campaign strategies, complementing traditional polling methods and providing cheaper polling in real-time. First, this paper explores past successful methods from research for analysis and prediction of the 2020 US Presidential Election using Twitter data. Then, this research proposes a new method for electoral prediction which combines sentiment, from NLP on the text of tweets, and structural data with aggregate polling, a time series analysis, and a special focus on Twitter users critical to the election. Though this method performed worse than its baseline of polling predictions, it is inconclusive whether this is an accurate method for predicting elections due to scarcity of data. More research and more data are needed to accurately measure this method's overall effectiveness.
Noisy-to-Noisy Voice Conversion Framework with Denoising Model
Sep 22, 2021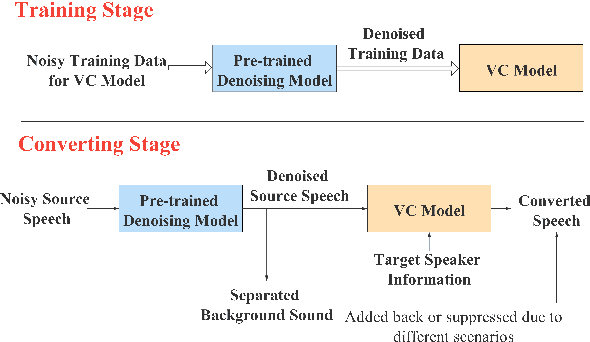
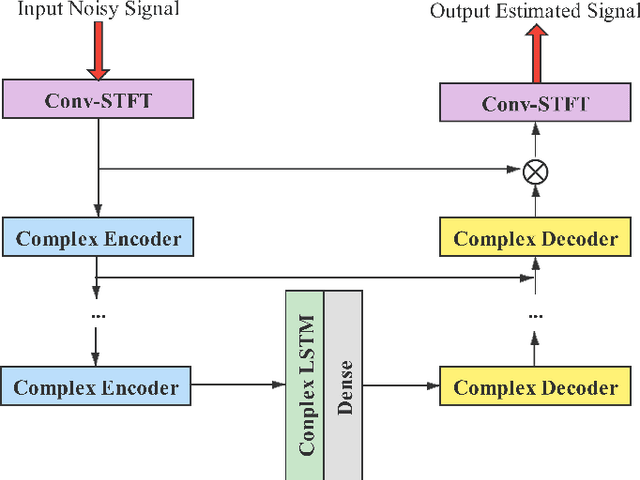
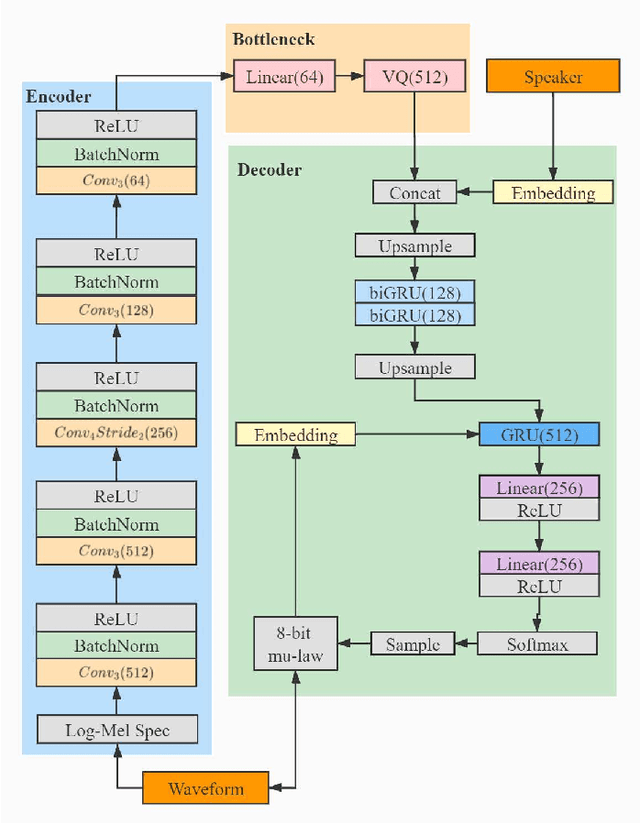
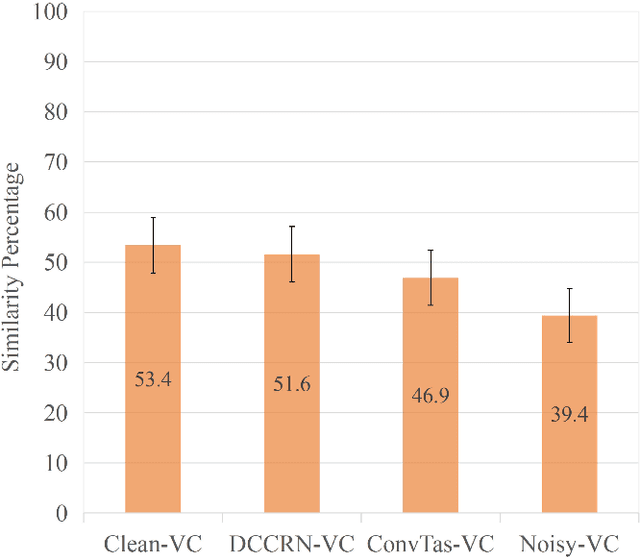
In a conventional voice conversion (VC) framework, a VC model is often trained with a clean dataset consisting of speech data carefully recorded and selected by minimizing background interference. However, collecting such a high-quality dataset is expensive and time-consuming. Leveraging crowd-sourced speech data in training is more economical. Moreover, for some real-world VC scenarios such as VC in video and VC-based data augmentation for speech recognition systems, the background sounds themselves are also informative and need to be maintained. In this paper, to explore VC with the flexibility of handling background sounds, we propose a noisy-to-noisy (N2N) VC framework composed of a denoising module and a VC module. With the proposed framework, we can convert the speaker's identity while preserving the background sounds. Both objective and subjective evaluations are conducted, and the results reveal the effectiveness of the proposed framework.
Discover, Hallucinate, and Adapt: Open Compound Domain Adaptation for Semantic Segmentation
Oct 08, 2021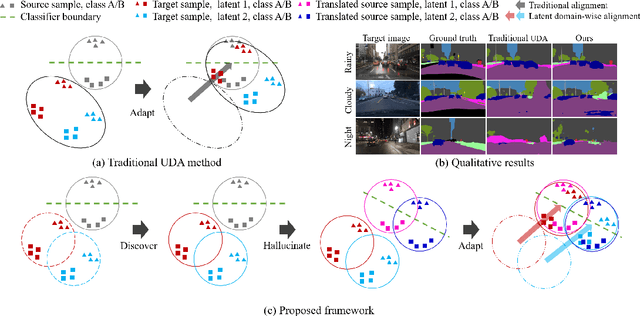
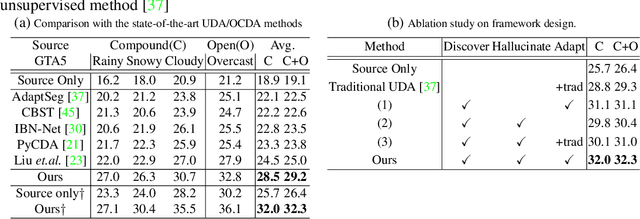
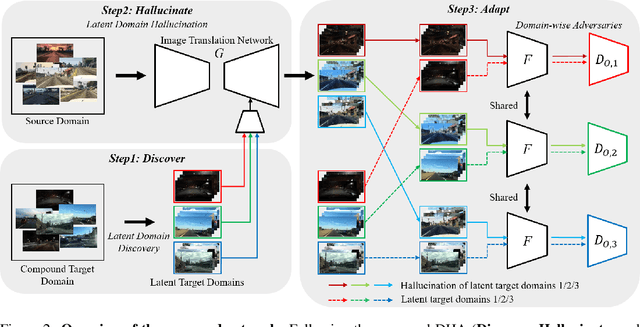
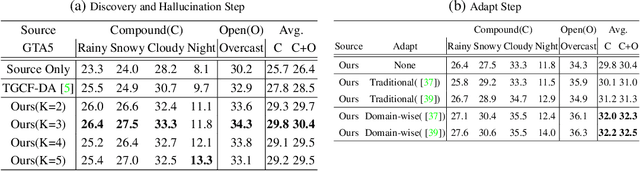
Unsupervised domain adaptation (UDA) for semantic segmentation has been attracting attention recently, as it could be beneficial for various label-scarce real-world scenarios (e.g., robot control, autonomous driving, medical imaging, etc.). Despite the significant progress in this field, current works mainly focus on a single-source single-target setting, which cannot handle more practical settings of multiple targets or even unseen targets. In this paper, we investigate open compound domain adaptation (OCDA), which deals with mixed and novel situations at the same time, for semantic segmentation. We present a novel framework based on three main design principles: discover, hallucinate, and adapt. The scheme first clusters compound target data based on style, discovering multiple latent domains (discover). Then, it hallucinates multiple latent target domains in source by using image-translation (hallucinate). This step ensures the latent domains in the source and the target to be paired. Finally, target-to-source alignment is learned separately between domains (adapt). In high-level, our solution replaces a hard OCDA problem with much easier multiple UDA problems. We evaluate our solution on standard benchmark GTA to C-driving, and achieved new state-of-the-art results.
DCASE 2021 Task 3: Spectrotemporally-aligned Features for Polyphonic Sound Event Localization and Detection
Jun 29, 2021
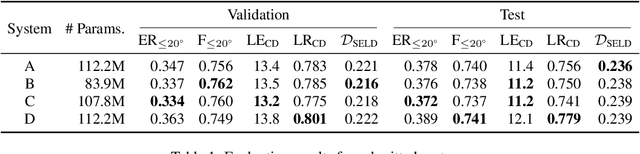
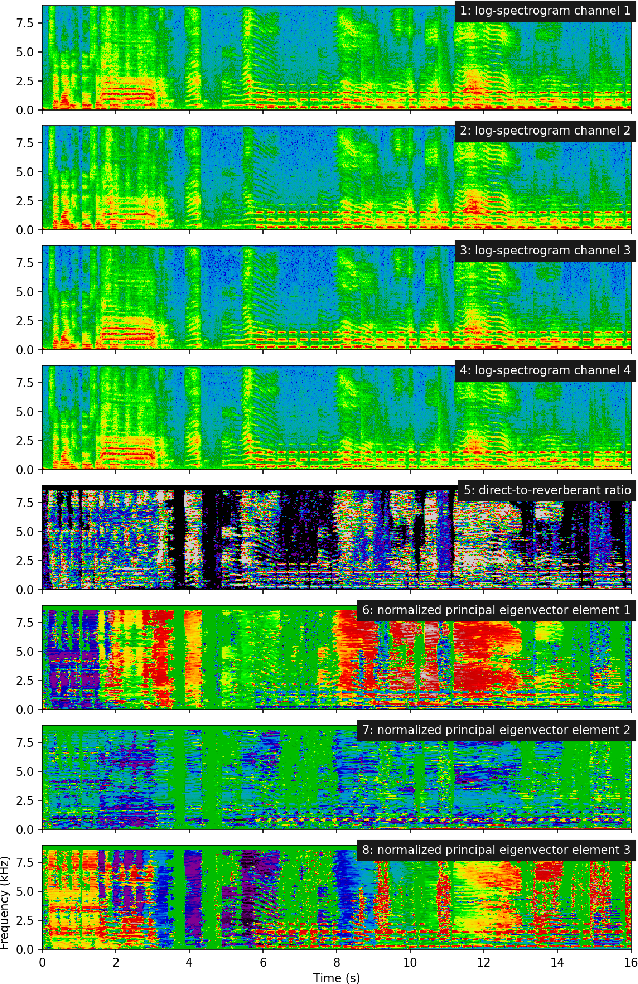
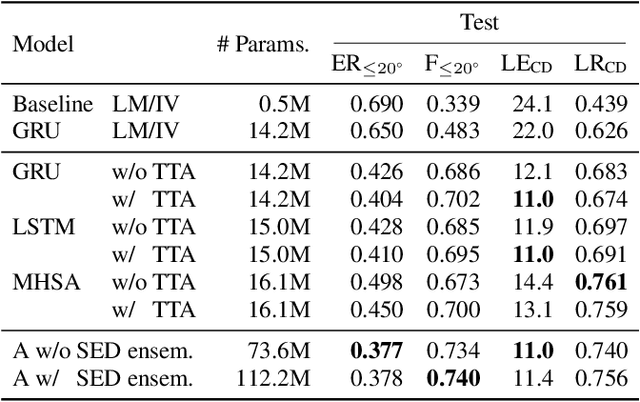
Sound event localization and detection consists of two subtasks which are sound event detection and direction-of-arrival estimation. While sound event detection mainly relies on time-frequency patterns to distinguish different sound classes, direction-of-arrival estimation uses magnitude or phase differences between microphones to estimate source directions. Therefore, it is often difficult to jointly train these two subtasks simultaneously. We propose a novel feature called spatial cue-augmented log-spectrogram (SALSA) with exact time-frequency mapping between the signal power and the source direction-of-arrival. The feature includes multichannel log-spectrograms stacked along with the estimated direct-to-reverberant ratio and a normalized version of the principal eigenvector of the spatial covariance matrix at each time-frequency bin on the spectrograms. Experimental results on the DCASE 2021 dataset for sound event localization and detection with directional interference showed that the deep learning-based models trained on this new feature outperformed the DCASE challenge baseline by a large margin. We combined several models with slightly different architectures that were trained on the new feature to further improve the system performances for the DCASE sound event localization and detection challenge.
Efficient Context-Aware Network for Abdominal Multi-organ Segmentation
Sep 22, 2021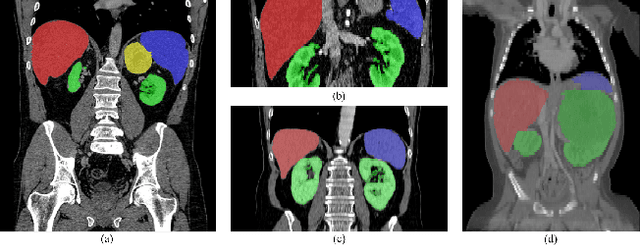
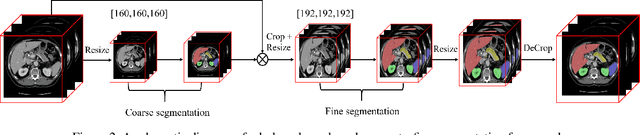
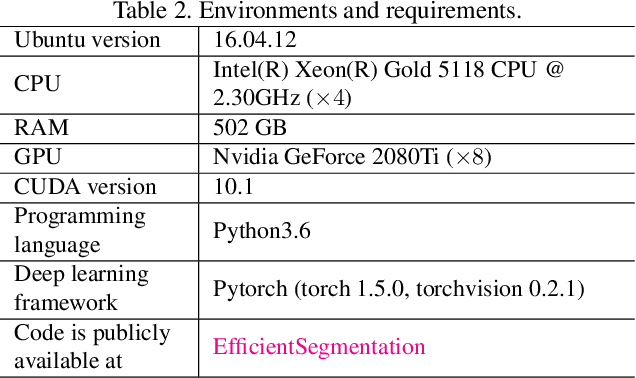
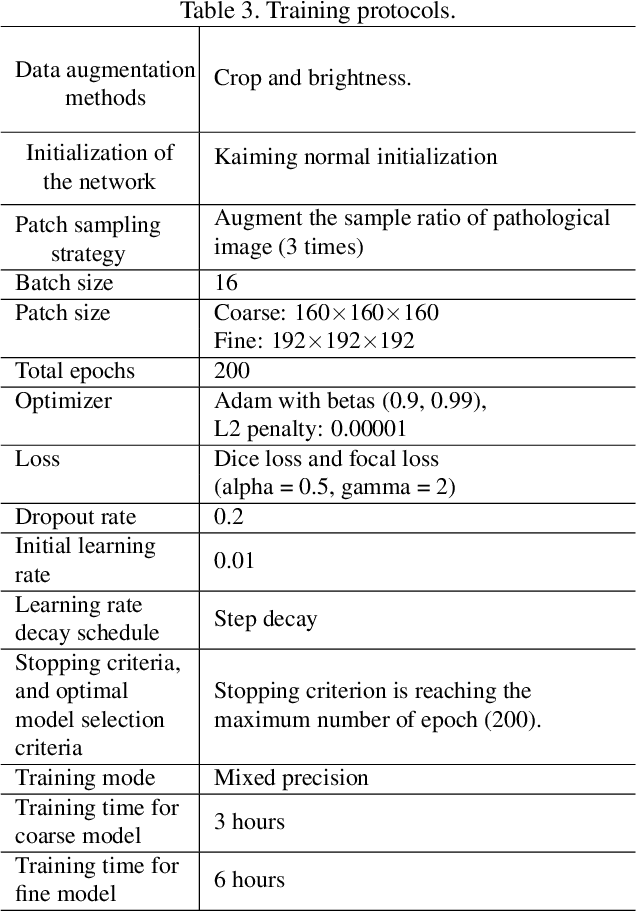
The contextual information, presented in abdominal CT scan, is relative consistent. In order to make full use of the overall 3D context, we develop a whole-volumebased coarse-to-fine framework for efficient and effective abdominal multi-organ segmentation. We propose a new efficientSegNet network, which is composed of encoder, decoder and context block. For the decoder module, anisotropic convolution with a k*k*1 intra-slice convolution and a 1*1*k inter-slice convolution, is designed to reduce the computation burden. For the context block, we propose strip pooling module to capture anisotropic and long-range contextual information, which exists in abdominal scene. Quantitative evaluation on the FLARE2021 validation cases, this method achieves the average dice similarity coefficient (DSC) of 0.895 and average normalized surface distance (NSD) of 0.775. The average running time is 9.8 s per case in inference phase, and maximum used GPU memory is 1017 MB.