 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Trajectory-based Reinforcement Learning of Non-prehensile Manipulation Skills for Semi-Autonomous Teleoperation
Sep 27, 2021
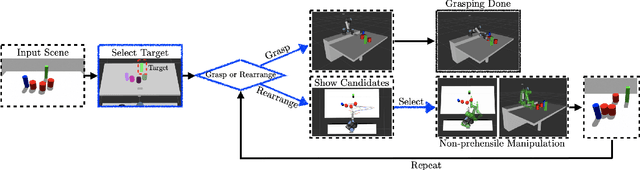
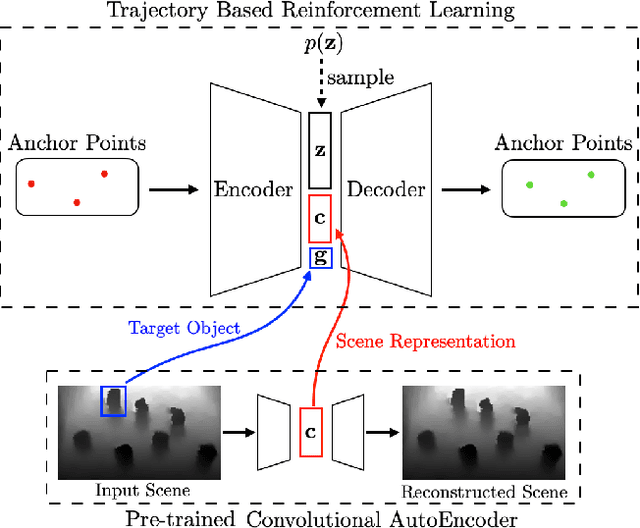
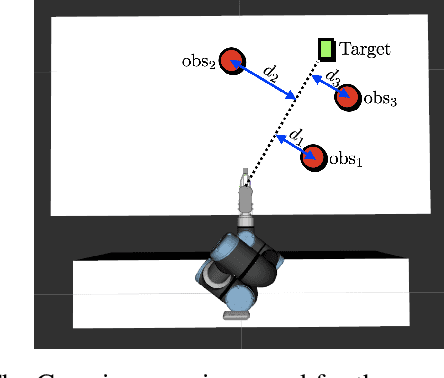
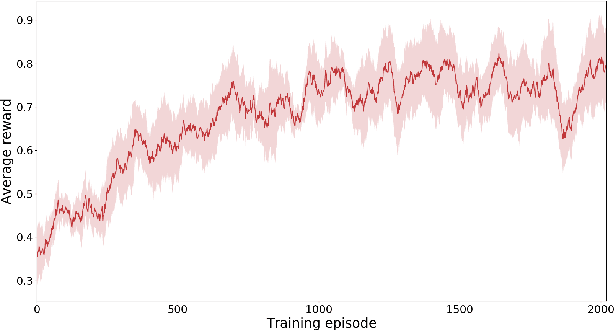
In this paper, we present a semi-autonomous teleoperation framework for a pick-and-place task using an RGB-D sensor. In particular, we assume that the target object is located in a cluttered environment where both prehensile grasping and non-prehensile manipulation are combined for efficient teleoperation. A trajectory-based reinforcement learning is utilized for learning the non-prehensile manipulation to rearrange the objects for enabling direct grasping. From the depth image of the cluttered environment and the location of the goal object, the learned policy can provide multiple options of non-prehensile manipulation to the human operator. We carefully design a reward function for the rearranging task where the policy is trained in a simulational environment. Then, the trained policy is transferred to a real-world and evaluated in a number of real-world experiments with the varying number of objects where we show that the proposed method outperforms manual keyboard control in terms of the time duration for the grasping.
A Hybrid Wired/Wireless Deterministic Network for Smart Grid
May 13, 2021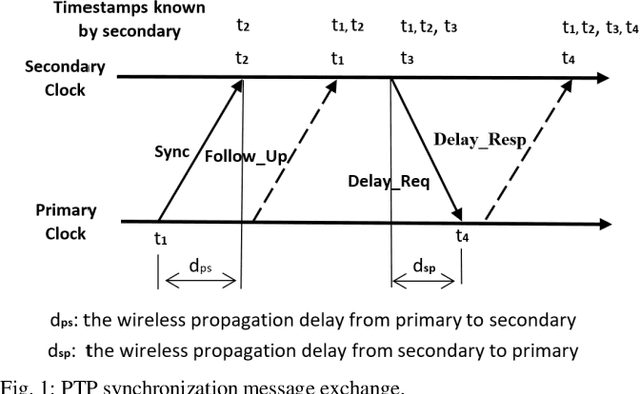
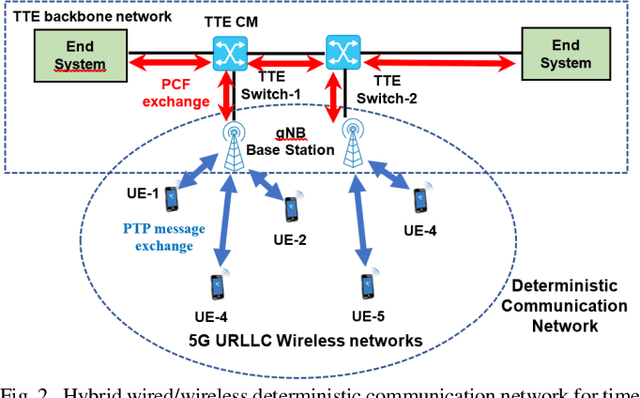
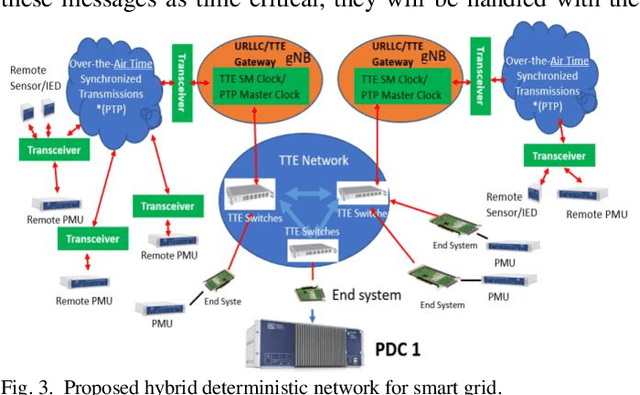
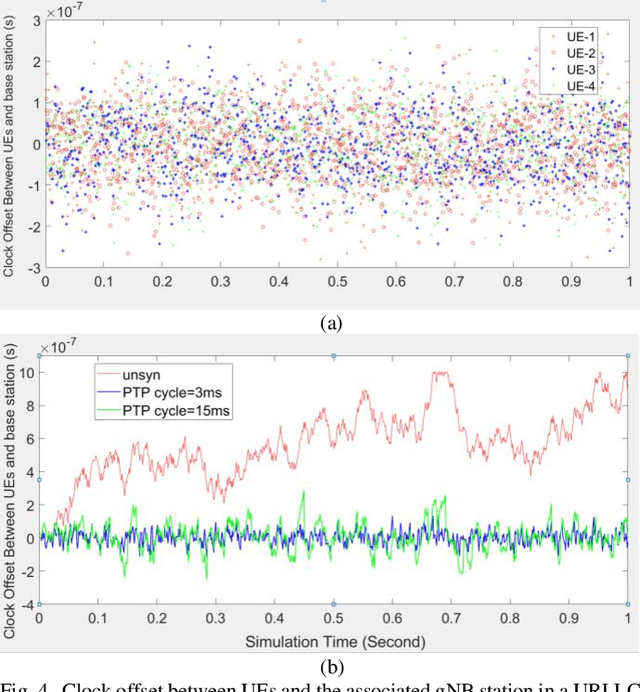
With the rapid growth of time-critical applications in smart grid, robotics, autonomous vehicles, and industrial automation, demand for high reliability, low latency and strictly bounded jitter is sharply increasing. High-precision time synchronization communications, such as Time Triggered Ethernet (TTE), have been successfully developed for wired networks. However, the high cost of deploying additional equipment and extra wiring limits the scalability of these networks. Therefore, in this paper, a hybrid wired/wireless high-precision time synchronization network based on a combination of high-speed TTE and 5G Ultra-Reliable and Low-Latency Communications (URLLC) is proposed. The main motivation is to comply with the low latency, low jitter, and high reliability requirements of time critical applications, such as smart grid synchrophasor communications. Therefore, in the proposed hybrid network architecture, a high-speed TTE is considered as the main bus (i.e., backbone network), whereas a Precision Time Protocol (PTP) aided 5G-URLLC-based wireless access is used as a sub-network. The main challenge is to achieve interoperability between the PTP aided URLLC and the TTE, while ensuring high precision timing and synchronization. The simulation results demonstrate the impact of the PTP-aided URLLC in maintaining network reliability, latency, and jitter in full coordination with the TTE-network.
KalmanNet: Neural Network Aided Kalman Filtering for Partially Known Dynamics
Jul 21, 2021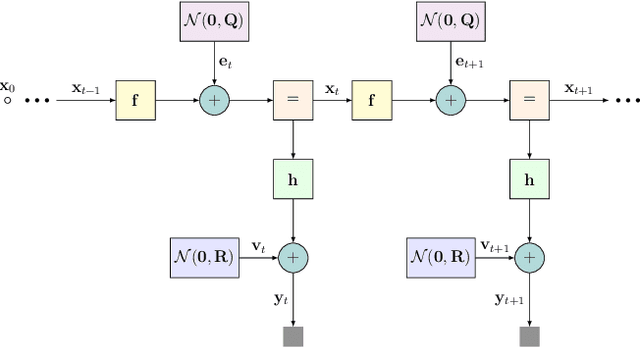
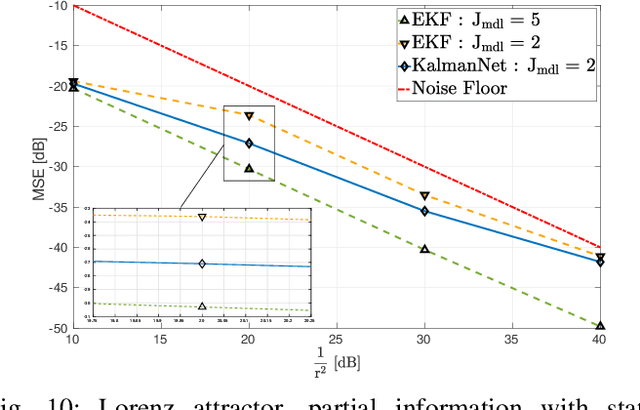
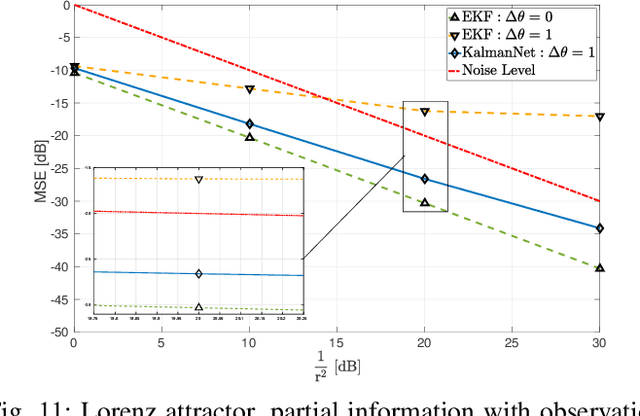
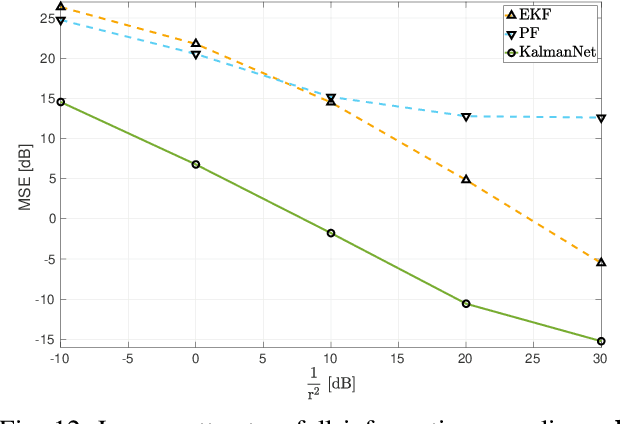
Real-time state estimation of dynamical systems is a fundamental task in signal processing and control. For systems that are well-represented by a fully known linear Gaussian state space (SS) model, the celebrated Kalman filter (KF) is a low complexity optimal solution. However, both linearity of the underlying SS model and accurate knowledge of it are often not encountered in practice. Here, we present KalmanNet, a real-time state estimator that learns from data to carry out Kalman filtering under non-linear dynamics with partial information. By incorporating the structural SS model with a dedicated recurrent neural network module in the flow of the KF, we retain data efficiency and interpretability of the classic algorithm while implicitly learning complex dynamics from data. We numerically demonstrate that KalmanNet overcomes nonlinearities and model mismatch, outperforming classic filtering methods operating with both mismatched and accurate domain knowledge.
Predictive Quality of Service (PQoS): The Next Frontier for Fully Autonomous Systems
Sep 20, 2021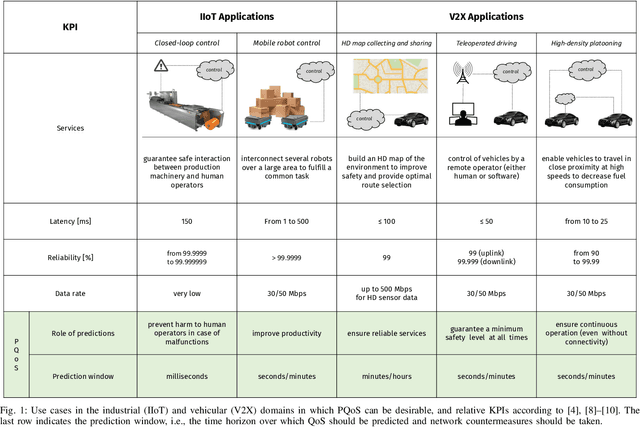
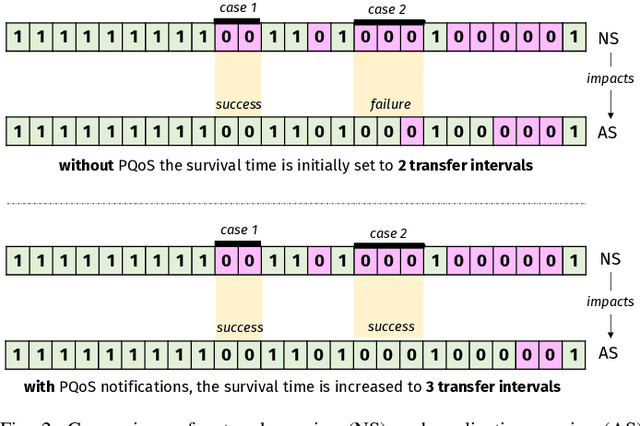
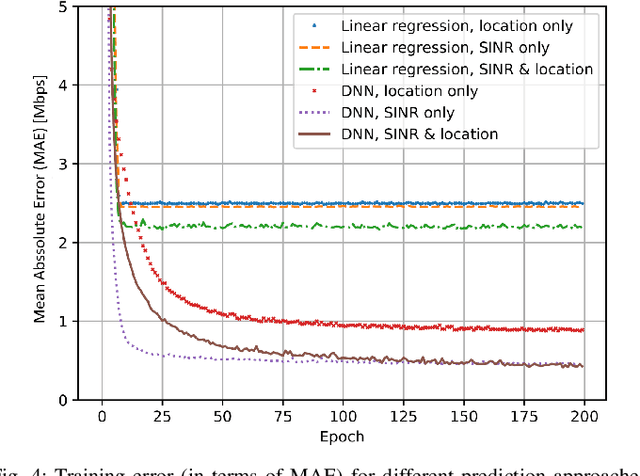
Recent advances in software, hardware, computing and control have fueled significant progress in the field of autonomous systems. Notably, autonomous machines should continuously estimate how the scenario in which they move and operate will evolve within a predefined time frame, and foresee whether or not the network will be able to fulfill the agreed Quality of Service (QoS). If not, appropriate countermeasures should be taken to satisfy the application requirements. Along these lines, in this paper we present possible methods to enable predictive QoS (PQoS) in autonomous systems, and discuss which use cases will particularly benefit from network prediction. Then, we shed light on the challenges in the field that are still open for future research. As a case study, we demonstrate whether machine learning can facilitate PQoS in a teleoperated-driving-like use case, as a function of different measurement signals.
Class Incremental Online Streaming Learning
Oct 20, 2021
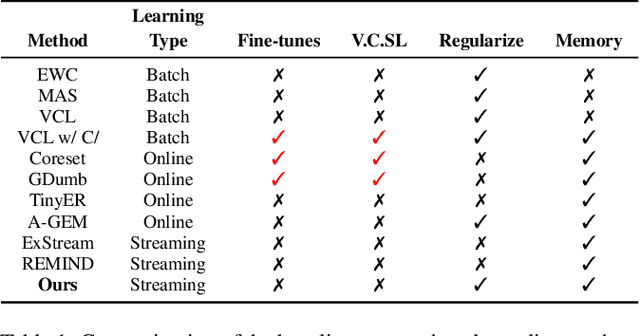

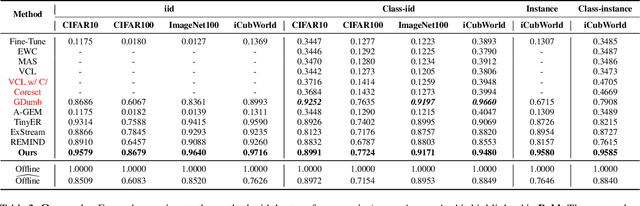
A wide variety of methods have been developed to enable lifelong learning in conventional deep neural networks. However, to succeed, these methods require a `batch' of samples to be available and visited multiple times during training. While this works well in a static setting, these methods continue to suffer in a more realistic situation where data arrives in \emph{online streaming manner}. We empirically demonstrate that the performance of current approaches degrades if the input is obtained as a stream of data with the following restrictions: $(i)$ each instance comes one at a time and can be seen only once, and $(ii)$ the input data violates the i.i.d assumption, i.e., there can be a class-based correlation. We propose a novel approach (CIOSL) for the class-incremental learning in an \emph{online streaming setting} to address these challenges. The proposed approach leverages implicit and explicit dual weight regularization and experience replay. The implicit regularization is leveraged via the knowledge distillation, while the explicit regularization incorporates a novel approach for parameter regularization by learning the joint distribution of the buffer replay and the current sample. Also, we propose an efficient online memory replay and replacement buffer strategy that significantly boosts the model's performance. Extensive experiments and ablation on challenging datasets show the efficacy of the proposed method.
Learning Attacker's Bounded Rationality Model in Security Games
Sep 27, 2021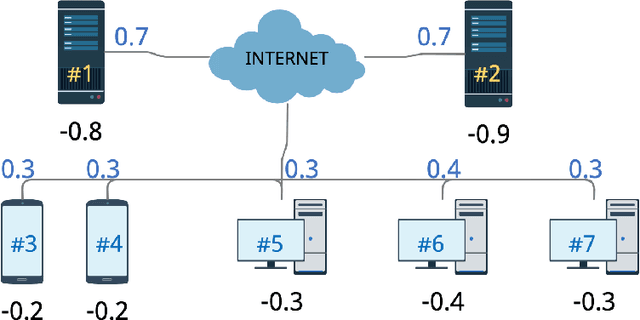
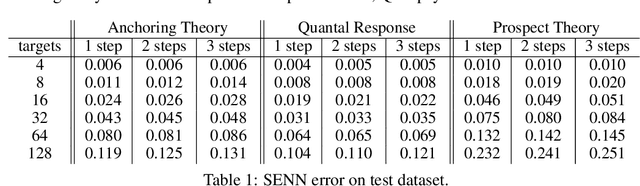
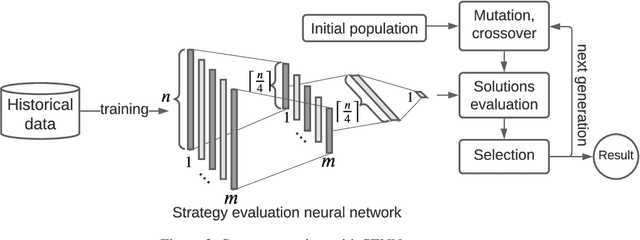
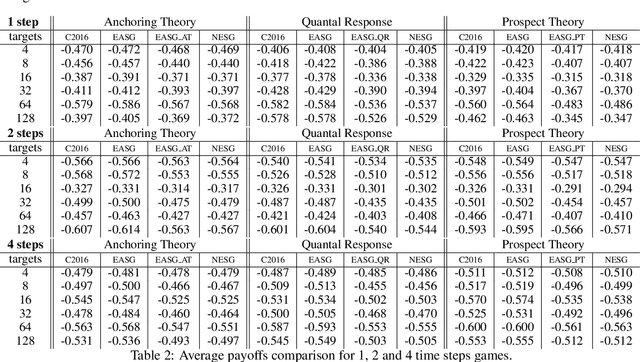
The paper proposes a novel neuroevolutionary method (NESG) for calculating leader's payoff in Stackelberg Security Games. The heart of NESG is strategy evaluation neural network (SENN). SENN is able to effectively evaluate leader's strategies against an opponent who may potentially not behave in a perfectly rational way due to certain cognitive biases or limitations. SENN is trained on historical data and does not require any direct prior knowledge regarding the follower's target preferences, payoff distribution or bounded rationality model. NESG was tested on a set of 90 benchmark games inspired by real-world cybersecurity scenario known as deep packet inspections. Experimental results show an advantage of applying NESG over the existing state-of-the-art methods when playing against not perfectly rational opponents. The method provides high quality solutions with superior computation time scalability. Due to generic and knowledge-free construction of NESG, the method may be applied to various real-life security scenarios.
Attitude Reconstruction from Inertial Measurement: Mitigating Runge Effect for Dynamic Applications
Jul 10, 2021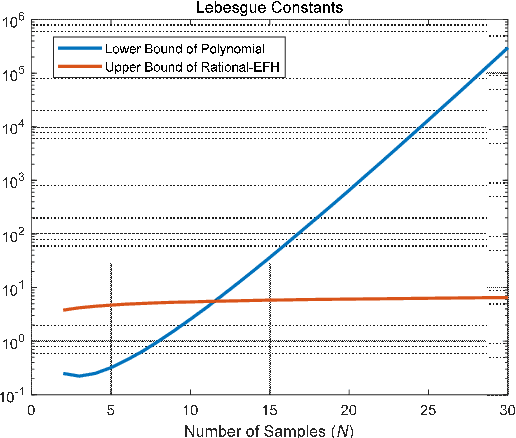
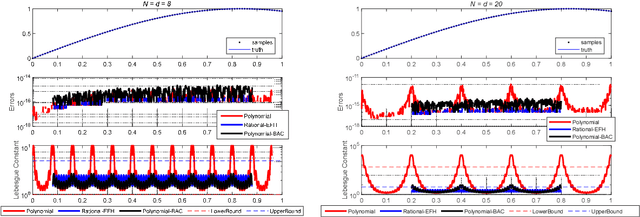
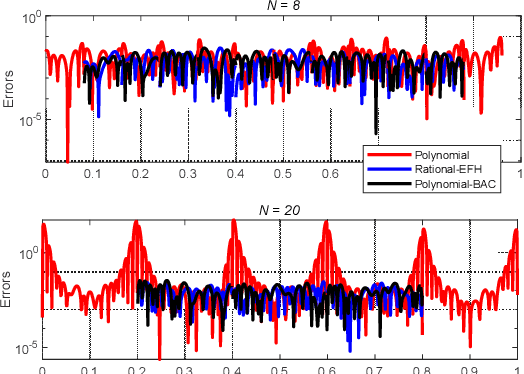
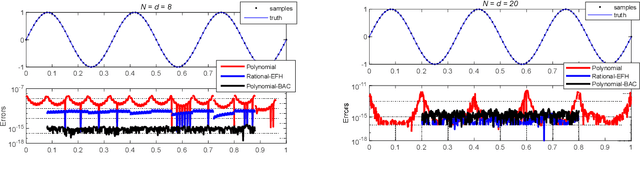
Time-equispaced inertial measurements are practically used as inputs for motion determination. Polynomial interpolation is a common technique of recovering the gyroscope signal but is subject to a fundamentally numerical stability problem due to the Runge effect on equispaced samples. This paper reviews the theoretical results of Runge phenomenon in related areas and proposes a straightforward borrowing-and-cutting (BAC) strategy to depress it. It employs the neighboring samples for higher-order polynomial interpolation but only uses the middle polynomial segment in the actual time interval. The BAC strategy has been incorporated into attitude computation by functional iteration, leading to accuracy benefit of several orders of magnitude under the classical coning motion. It would potentially bring significant benefits to the inertial navigation computation under sustained dynamic motions.
Optimal Auction Design for the Gradual Procurement of Strategic Service Provider Agents
Oct 25, 2021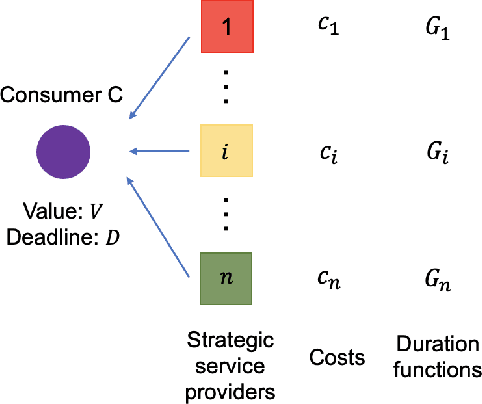
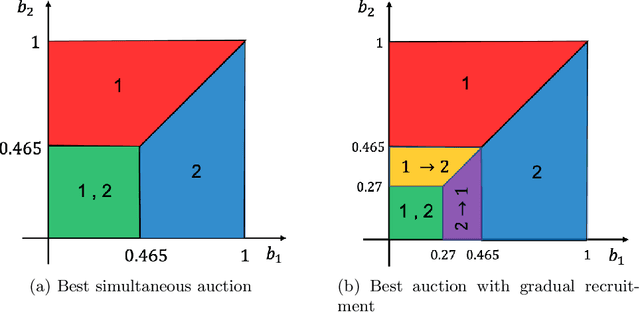
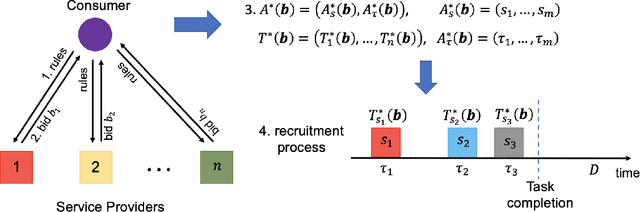
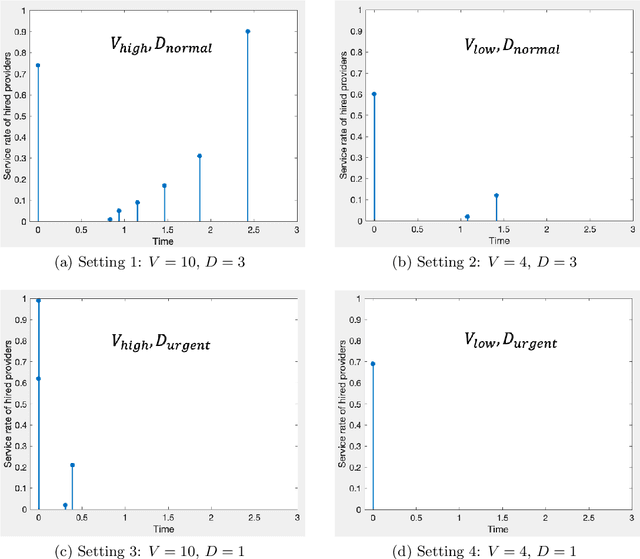
We consider an outsourcing problem where a software agent procures multiple services from providers with uncertain reliabilities to complete a computational task before a strict deadline. The service consumer requires a procurement strategy that achieves the optimal balance between success probability and invocation cost. However, the service providers are self-interested and may misrepresent their private cost information if it benefits them. For such settings, we design a novel procurement auction that provides the consumer with the highest possible revenue, while giving sufficient incentives to providers to tell the truth about their costs. This auction creates a contingent plan for gradual service procurement that suggests recruiting a new provider only when the success probability of the already hired providers drops below a time-dependent threshold. To make this auction incentive compatible, we propose a novel weighted threshold payment scheme which pays the minimum among all truthful mechanisms. Using the weighted payment scheme, we also design a low-complexity near-optimal auction that reduces the computational complexity of the optimal mechanism by 99% with only marginal performance loss (less than 1%). We demonstrate the effectiveness and strength of our proposed auctions through both game theoretical and numerical analysis. The experiment results confirm that the proposed auctions exhibit 59% improvement in performance over the current state-of-the-art, by increasing success probability up to 79% and reducing invocation cost by up to 11%.
Tetra-Tagging: Word-Synchronous Parsing with Linear-Time Inference
Apr 22, 2019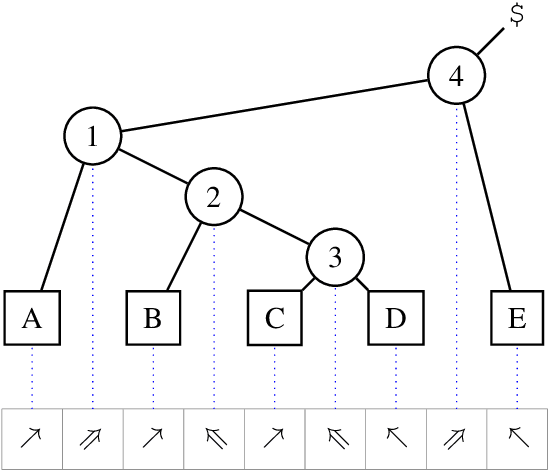

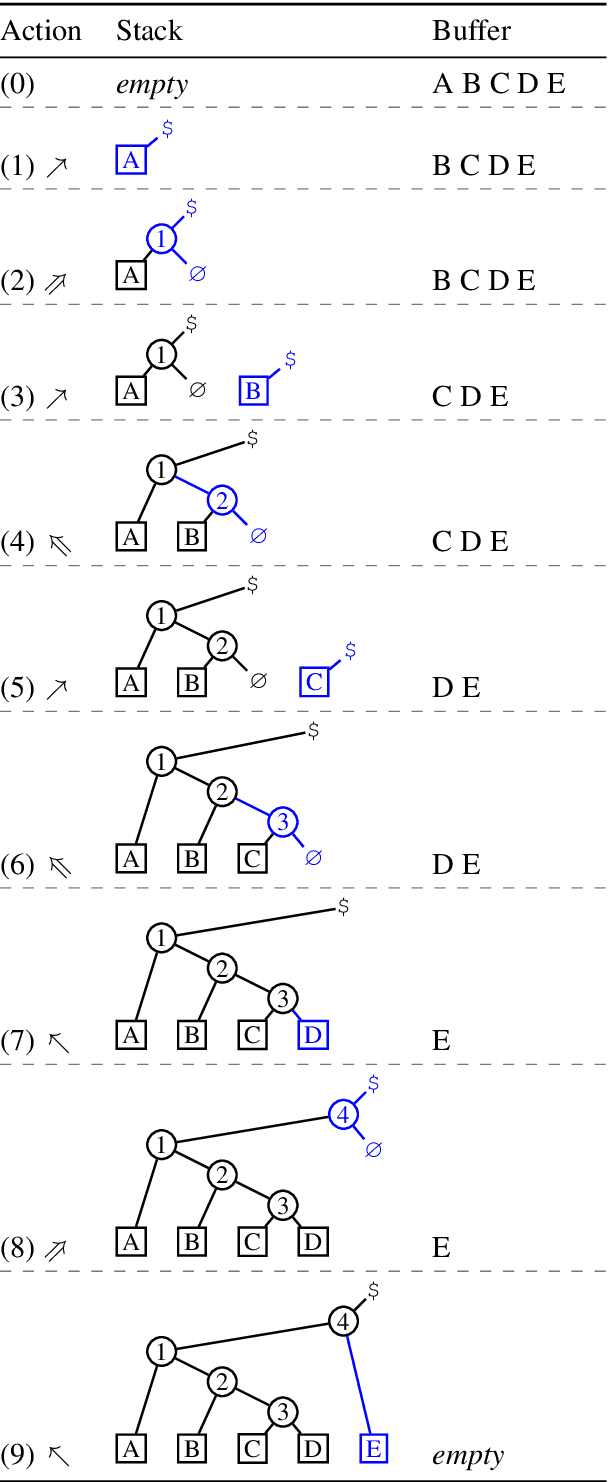
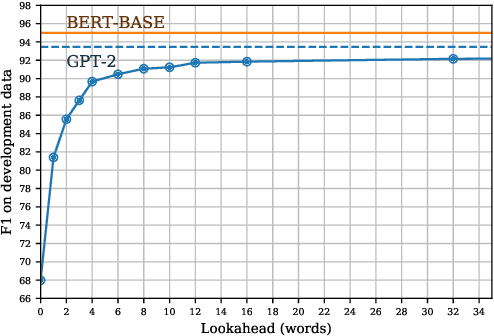
We present a constituency parsing algorithm that maps from word-aligned contextualized feature vectors to parse trees. Our algorithm proceeds strictly left-to-right, processing one word at a time by assigning it a label from a small vocabulary. We show that, with mild assumptions, our inference procedure requires constant computation time per word. Our method gets 95.4 F1 on the WSJ test set.
onlineforecast: An R package for adaptive and recursive forecasting
Sep 27, 2021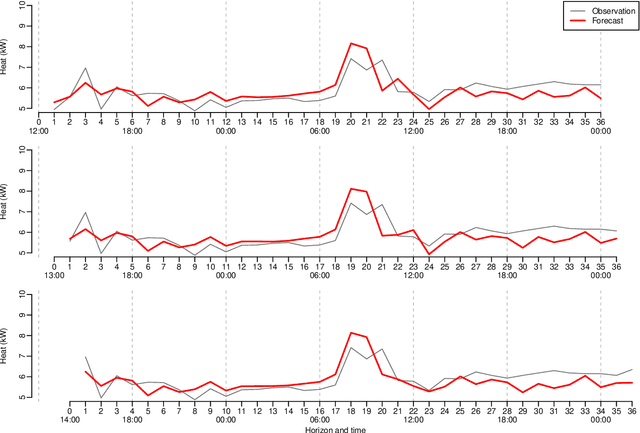
Systems that rely on forecasts to make decisions, e.g. control or energy trading systems, require frequent updates of the forecasts. Usually, the forecasts are updated whenever new observations become available, hence in an online setting. We present the R package onlineforecast that provides a generalized setup of data and models for online forecasting. It has functionality for time-adaptive fitting of linear regression-based models. Furthermore, dynamical and non-linear effects can be easily included in the models. The setup is tailored to enable effective use of forecasts as model inputs, e.g. numerical weather forecast. Users can create new models for their particular system applications and run models in an operational online setting. The package also allows users to easily replace parts of the setup, e.g. use kernel or neural network methods for estimation. The package comes with comprehensive vignettes and examples of online forecasting applications in energy systems, but can easily be applied in all fields where online forecasting is used.