 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
You are caught stealing my winning lottery ticket! Making a lottery ticket claim its ownership
Oct 30, 2021

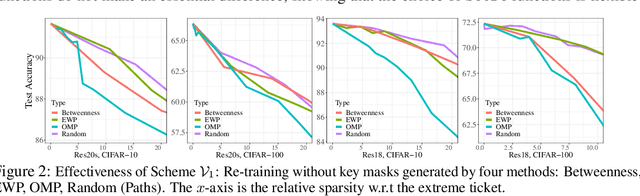


Despite tremendous success in many application scenarios, the training and inference costs of using deep learning are also rapidly increasing over time. The lottery ticket hypothesis (LTH) emerges as a promising framework to leverage a special sparse subnetwork (i.e., winning ticket) instead of a full model for both training and inference, that can lower both costs without sacrificing the performance. The main resource bottleneck of LTH is however the extraordinary cost to find the sparse mask of the winning ticket. That makes the found winning ticket become a valuable asset to the owners, highlighting the necessity of protecting its copyright. Our setting adds a new dimension to the recently soaring interest in protecting against the intellectual property (IP) infringement of deep models and verifying their ownerships, since they take owners' massive/unique resources to develop or train. While existing methods explored encrypted weights or predictions, we investigate a unique way to leverage sparse topological information to perform lottery verification, by developing several graph-based signatures that can be embedded as credentials. By further combining trigger set-based methods, our proposal can work in both white-box and black-box verification scenarios. Through extensive experiments, we demonstrate the effectiveness of lottery verification in diverse models (ResNet-20, ResNet-18, ResNet-50) on CIFAR-10 and CIFAR-100. Specifically, our verification is shown to be robust to removal attacks such as model fine-tuning and pruning, as well as several ambiguity attacks. Our codes are available at https://github.com/VITA-Group/NO-stealing-LTH.
Convolutional generative adversarial imputation networks for spatio-temporal missing data in storm surge simulations
Nov 03, 2021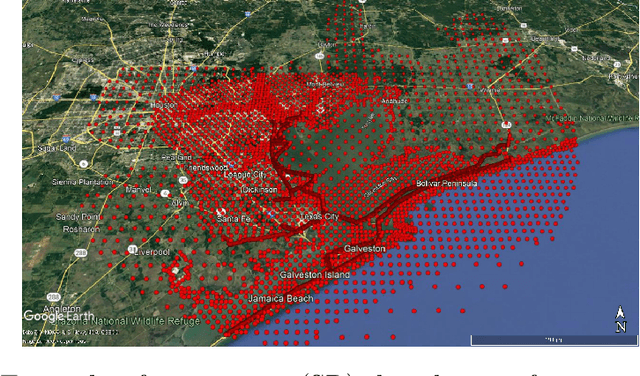
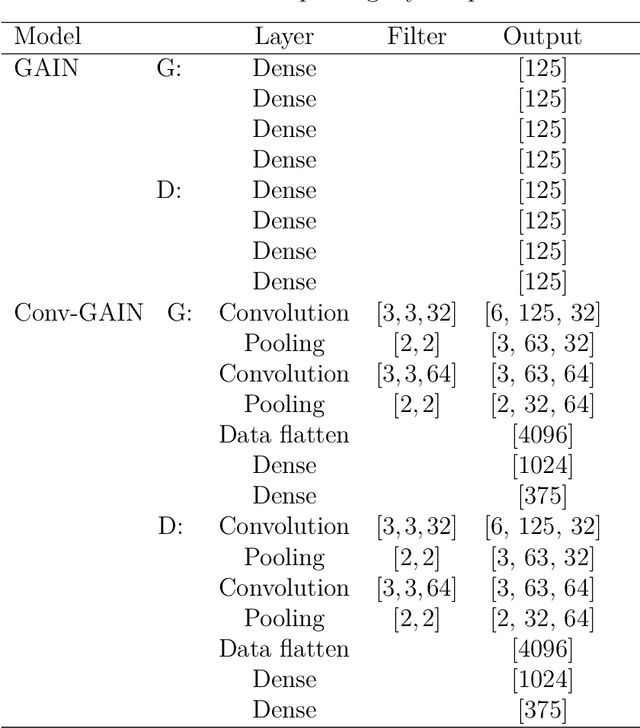
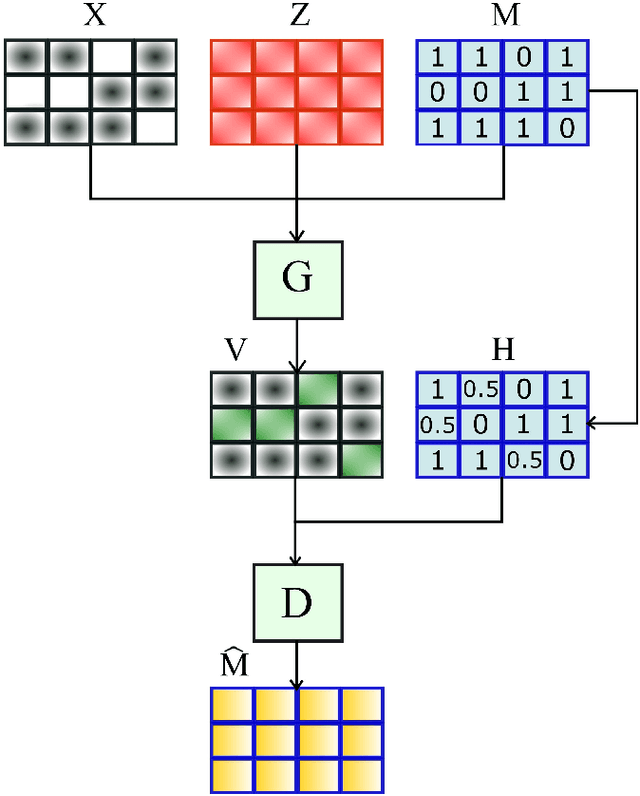

Imputation of missing data is a task that plays a vital role in a number of engineering and science applications. Often such missing data arise in experimental observations from limitations of sensors or post-processing transformation errors. Other times they arise from numerical and algorithmic constraints in computer simulations. One such instance and the application emphasis of this paper are numerical simulations of storm surge. The simulation data corresponds to time-series surge predictions over a number of save points within the geographic domain of interest, creating a spatio-temporal imputation problem where the surge points are heavily correlated spatially and temporally, and the missing values regions are structurally distributed at random. Very recently, machine learning techniques such as neural network methods have been developed and employed for missing data imputation tasks. Generative Adversarial Nets (GANs) and GAN-based techniques have particularly attracted attention as unsupervised machine learning methods. In this study, the Generative Adversarial Imputation Nets (GAIN) performance is improved by applying convolutional neural networks instead of fully connected layers to better capture the correlation of data and promote learning from the adjacent surge points. Another adjustment to the method needed specifically for the studied data is to consider the coordinates of the points as additional features to provide the model more information through the convolutional layers. We name our proposed method as Convolutional Generative Adversarial Imputation Nets (Conv-GAIN). The proposed method's performance by considering the improvements and adaptations required for the storm surge data is assessed and compared to the original GAIN and a few other techniques. The results show that Conv-GAIN has better performance than the alternative methods on the studied data.
Clique percolation method: memory efficient almost exact communities
Oct 04, 2021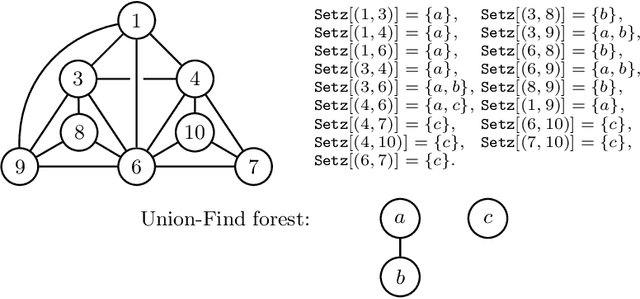
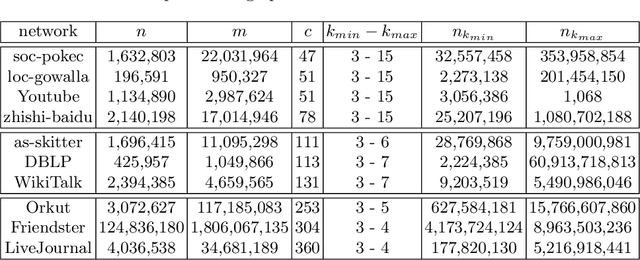
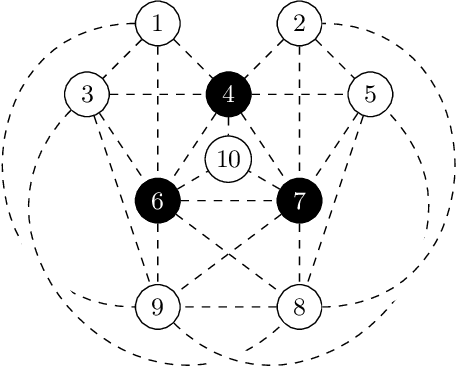
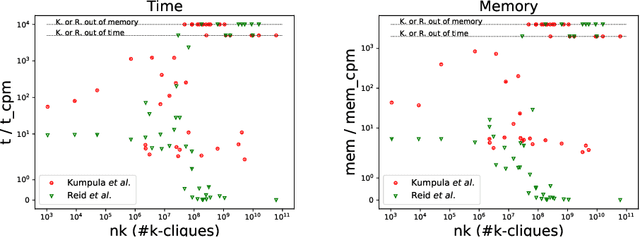
Automatic detection of relevant groups of nodes in large real-world graphs, i.e. community detection, has applications in many fields and has received a lot of attention in the last twenty years. The most popular method designed to find overlapping communities (where a node can belong to several communities) is perhaps the clique percolation method (CPM). This method formalizes the notion of community as a maximal union of $k$-cliques that can be reached from each other through a series of adjacent $k$-cliques, where two cliques are adjacent if and only if they overlap on $k-1$ nodes. Despite much effort CPM has not been scalable to large graphs for medium values of $k$. Recent work has shown that it is possible to efficiently list all $k$-cliques in very large real-world graphs for medium values of $k$. We build on top of this work and scale up CPM. In cases where this first algorithm faces memory limitations, we propose another algorithm, CPMZ, that provides a solution close to the exact one, using more time but less memory.
COVID-19 India Dataset: Parsing Detailed COVID-19 Data in Daily Health Bulletins from States in India
Sep 27, 2021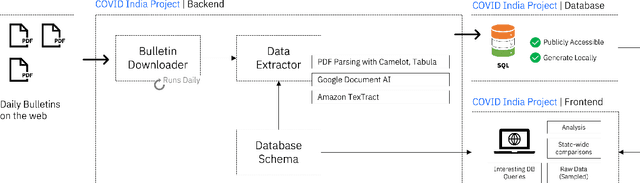
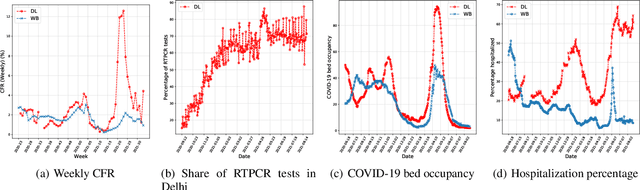
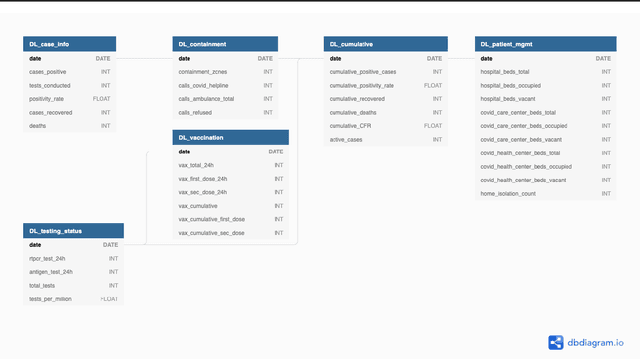
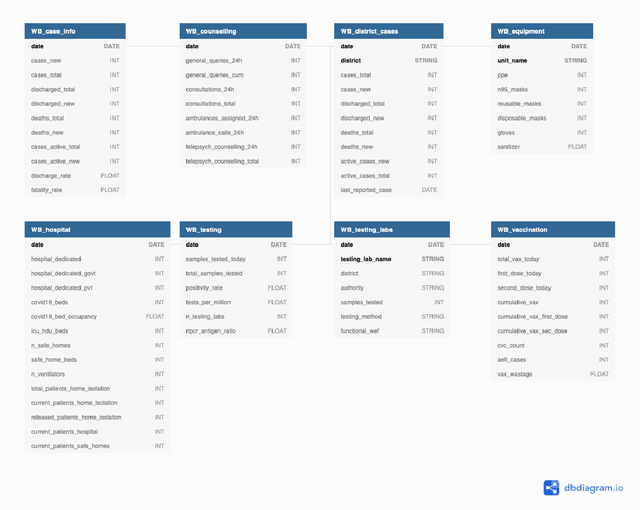
While India remains one of the hotspots of the COVID-19 pandemic, data about the pandemic from the country has proved to be largely inaccessible for use at scale. Much of the data exists in an unstructured form on the web, and limited aspects of such data are available through public APIs maintained manually through volunteer efforts. This has proved to be difficult both in terms of ease of access to detailed data as well as with regards to the maintenance of manual data-keeping over time. This paper reports on a recently launched project aimed at automating the extraction of such data from public health bulletins with the help of a combination of classical PDF parsers as well as state-of-the-art ML-based documents extraction APIs. In this paper, we will describe the automated data-extraction technique, the nature of the generated data, and exciting avenues of ongoing work.
A Survey of Open Source User Activity Traces with Applications to User Mobility Characterization and Modeling
Oct 15, 2021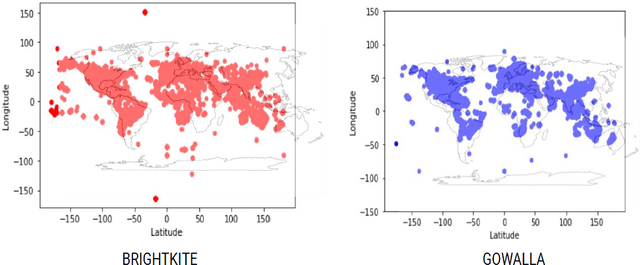
The current state-of-the-art in user mobility research has extensively relied on open-source mobility traces captured from pedestrian and vehicular activity through a variety of communication technologies as users engage in a wide-range of applications, including connected healthcare, localization, social media, e-commerce, etc. Most of these traces are feature-rich and diverse, not only in the information they provide, but also in how they can be used and leveraged. This diversity poses two main challenges for researchers and practitioners who wish to make use of available mobility datasets. First, it is quite difficult to get a bird's eye view of the available traces without spending considerable time looking them up. Second, once they have found the traces, they still need to figure out whether the traces are adequate to their needs. The purpose of this survey is three-fold. It proposes a taxonomy to classify open-source mobility traces including their mobility mode, data source and collection technology. It then uses the proposed taxonomy to classify existing open-source mobility traces and finally, highlights three case studies using popular publicly available datasets to showcase how our taxonomy can tease out feature sets in traces to help determine their applicability to specific use-cases.
PhyloTransformer: A Discriminative Model for Mutation Prediction Based on a Multi-head Self-attention Mechanism
Nov 03, 2021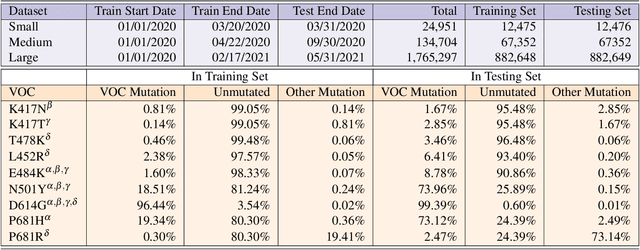
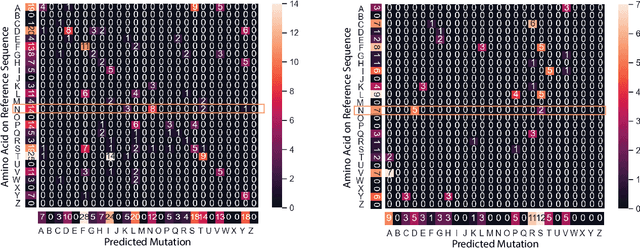
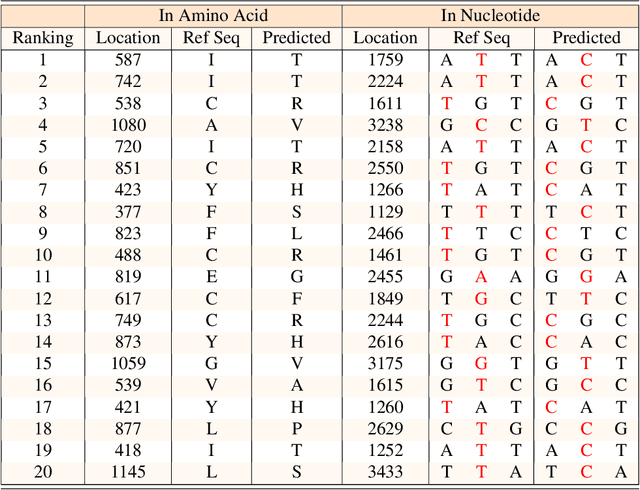
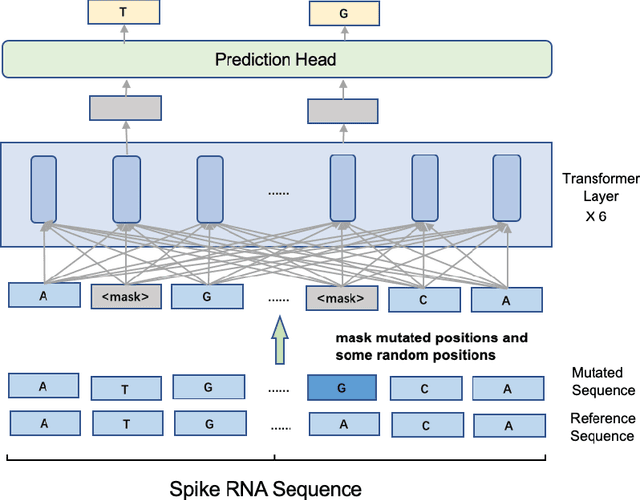
Severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) has caused an ongoing pandemic infecting 219 million people as of 10/19/21, with a 3.6% mortality rate. Natural selection can generate favorable mutations with improved fitness advantages; however, the identified coronaviruses may be the tip of the iceberg, and potentially more fatal variants of concern (VOCs) may emerge over time. Understanding the patterns of emerging VOCs and forecasting mutations that may lead to gain of function or immune escape is urgently required. Here we developed PhyloTransformer, a Transformer-based discriminative model that engages a multi-head self-attention mechanism to model genetic mutations that may lead to viral reproductive advantage. In order to identify complex dependencies between the elements of each input sequence, PhyloTransformer utilizes advanced modeling techniques, including a novel Fast Attention Via positive Orthogonal Random features approach (FAVOR+) from Performer, and the Masked Language Model (MLM) from Bidirectional Encoder Representations from Transformers (BERT). PhyloTransformer was trained with 1,765,297 genetic sequences retrieved from the Global Initiative for Sharing All Influenza Data (GISAID) database. Firstly, we compared the prediction accuracy of novel mutations and novel combinations using extensive baseline models; we found that PhyloTransformer outperformed every baseline method with statistical significance. Secondly, we examined predictions of mutations in each nucleotide of the receptor binding motif (RBM), and we found our predictions were precise and accurate. Thirdly, we predicted modifications of N-glycosylation sites to identify mutations associated with altered glycosylation that may be favored during viral evolution. We anticipate that PhyloTransformer may guide proactive vaccine design for effective targeting of future SARS-CoV-2 variants.
LPRules: Rule Induction in Knowledge Graphs Using Linear Programming
Oct 15, 2021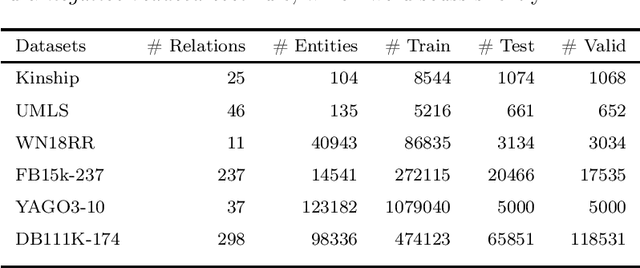
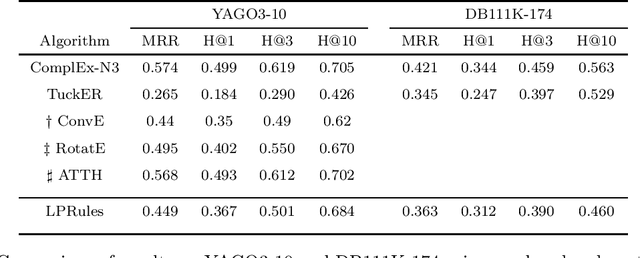
Knowledge graph (KG) completion is a well-studied problem in AI. Rule-based methods and embedding-based methods form two of the solution techniques. Rule-based methods learn first-order logic rules that capture existing facts in an input graph and then use these rules for reasoning about missing facts. A major drawback of such methods is the lack of scalability to large datasets. In this paper, we present a simple linear programming (LP) model to choose rules from a list of candidate rules and assign weights to them. For smaller KGs, we use simple heuristics to create the candidate list. For larger KGs, we start with a small initial candidate list, and then use standard column generation ideas to add more rules in order to improve the LP model objective value. To foster interpretability and generalizability, we limit the complexity of the set of chosen rules via explicit constraints, and tune the complexity hyperparameter for individual datasets. We show that our method can obtain state-of-the-art results for three out of four widely used KG datasets, while taking significantly less computing time than other popular rule learners including some based on neuro-symbolic methods. The improved scalability of our method allows us to tackle large datasets such as YAGO3-10.
sigmoidF1: A Smooth F1 Score Surrogate Loss for Multilabel Classification
Aug 24, 2021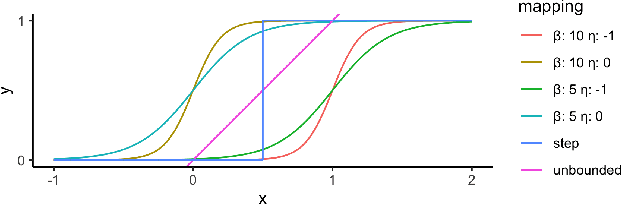

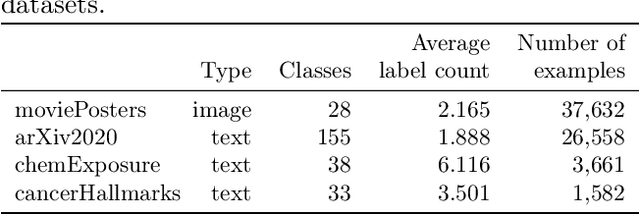
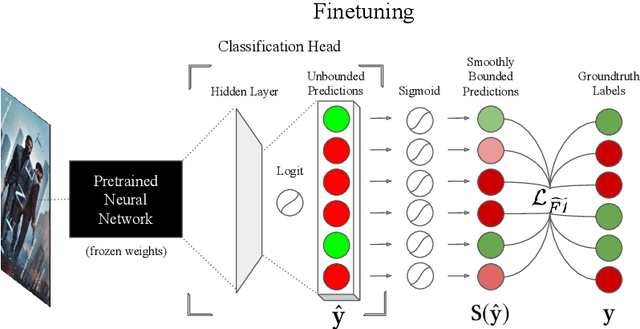
Multiclass multilabel classification refers to the task of attributing multiple labels to examples via predictions. Current models formulate a reduction of that multilabel setting into either multiple binary classifications or multiclass classification, allowing for the use of existing loss functions (sigmoid, cross-entropy, logistic, etc.). Empirically, these methods have been reported to achieve good performance on different metrics (F1 score, Recall, Precision, etc.). Theoretically though, the multilabel classification reductions does not accommodate for the prediction of varying numbers of labels per example and the underlying losses are distant estimates of the performance metrics. We propose a loss function, sigmoidF1. It is an approximation of the F1 score that (I) is smooth and tractable for stochastic gradient descent, (II) naturally approximates a multilabel metric, (III) estimates label propensities and label counts. More generally, we show that any confusion matrix metric can be formulated with a smooth surrogate. We evaluate the proposed loss function on different text and image datasets, and with a variety of metrics, to account for the complexity of multilabel classification evaluation. In our experiments, we embed the sigmoidF1 loss in a classification head that is attached to state-of-the-art efficient pretrained neural networks MobileNetV2 and DistilBERT. Our experiments show that sigmoidF1 outperforms other loss functions on four datasets and several metrics. These results show the effectiveness of using inference-time metrics as loss function at training time in general and their potential on non-trivial classification problems like multilabel classification.
Trajectory-based Reinforcement Learning of Non-prehensile Manipulation Skills for Semi-Autonomous Teleoperation
Sep 27, 2021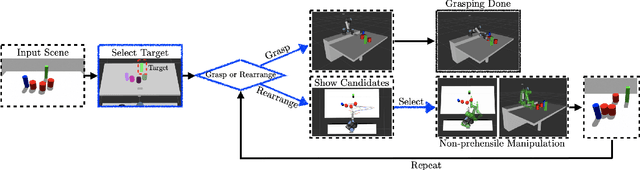
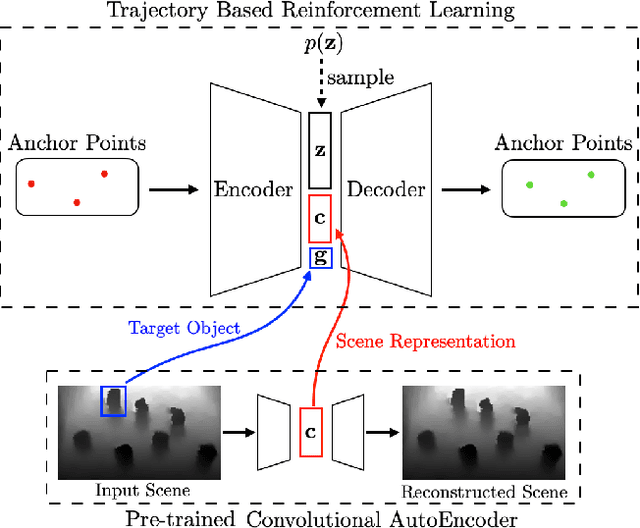
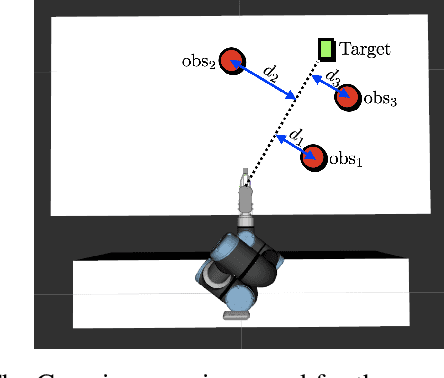
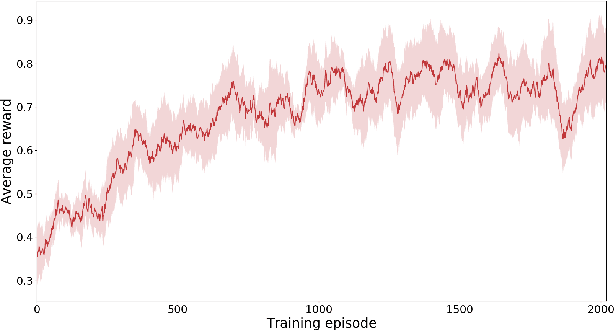
In this paper, we present a semi-autonomous teleoperation framework for a pick-and-place task using an RGB-D sensor. In particular, we assume that the target object is located in a cluttered environment where both prehensile grasping and non-prehensile manipulation are combined for efficient teleoperation. A trajectory-based reinforcement learning is utilized for learning the non-prehensile manipulation to rearrange the objects for enabling direct grasping. From the depth image of the cluttered environment and the location of the goal object, the learned policy can provide multiple options of non-prehensile manipulation to the human operator. We carefully design a reward function for the rearranging task where the policy is trained in a simulational environment. Then, the trained policy is transferred to a real-world and evaluated in a number of real-world experiments with the varying number of objects where we show that the proposed method outperforms manual keyboard control in terms of the time duration for the grasping.
Learning to Bid in Contextual First Price Auctions
Sep 07, 2021In this paper, we investigate the problem about how to bid in repeated contextual first price auctions. We consider a single bidder (learner) who repeatedly bids in the first price auctions: at each time $t$, the learner observes a context $x_t\in \mathbb{R}^d$ and decides the bid based on historical information and $x_t$. We assume a structured linear model of the maximum bid of all the others $m_t = \alpha_0\cdot x_t + z_t$, where $\alpha_0\in \mathbb{R}^d$ is unknown to the learner and $z_t$ is randomly sampled from a noise distribution $\mathcal{F}$ with log-concave density function $f$. We consider both \emph{binary feedback} (the learner can only observe whether she wins or not) and \emph{full information feedback} (the learner can observe $m_t$) at the end of each time $t$. For binary feedback, when the noise distribution $\mathcal{F}$ is known, we propose a bidding algorithm, by using maximum likelihood estimation (MLE) method to achieve at most $\widetilde{O}(\sqrt{\log(d) T})$ regret. Moreover, we generalize this algorithm to the setting with binary feedback and the noise distribution is unknown but belongs to a parametrized family of distributions. For the full information feedback with \emph{unknown} noise distribution, we provide an algorithm that achieves regret at most $\widetilde{O}(\sqrt{dT})$. Our approach combines an estimator for log-concave density functions and then MLE method to learn the noise distribution $\mathcal{F}$ and linear weight $\alpha_0$ simultaneously. We also provide a lower bound result such that any bidding policy in a broad class must achieve regret at least $\Omega(\sqrt{T})$, even when the learner receives the full information feedback and $\mathcal{F}$ is known.