 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Dynamic Toll Prediction Using Historical Data on Toll Roads: Case Study of the I-66 Inner Beltway
Apr 20, 2021
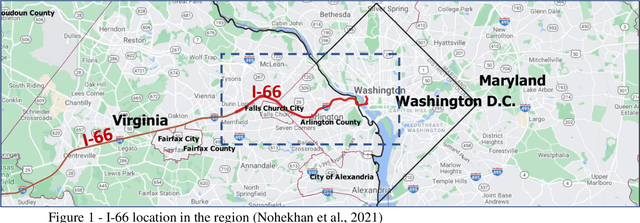
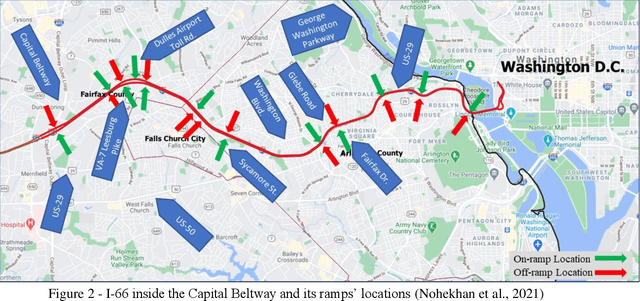
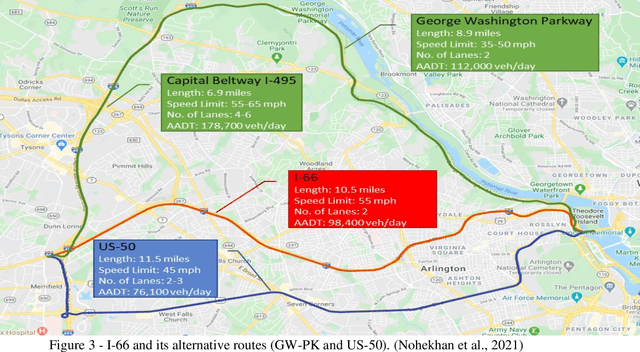
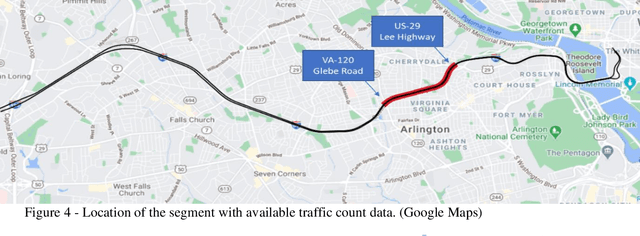
Providing the users of a dynamic tolling system with predictions of tolling prices and the travel time difference between the toll road and the alternative routes enables them to make their travel decisions before starting their trip. This study aims to provide accurate predictions of tolling price through training and testing random forest, multilayer perceptron, and long short-term memory models and compare them with the current situation that the best prediction is extending the current toll to the next timesteps. The prediction time horizon includes five 6-minute time intervals ahead of the present time. The prediction performance of models over the testing set reveals that while all the models were significantly better than the base model, the random forest outperforms all models. For instance, while in the trained models, the mean absolute error range is from $1.5 to $2.5 for the next six minutes to the next 30 minutes, respectively, the same measure in the base model is in the range of $2.5 to $6. The prediction of travel time difference along the toll road and its alternative route with the shortest travel time revealed that the multilayer perceptron performs marginally better than the base model. However, due to a relatively stable travel time difference, the current travel time difference is an acceptable prediction for the next 30 minutes prediction horizon.
Color Image Segmentation Using Multi-Objective Swarm Optimizer and Multi-level Histogram Thresholding
Oct 18, 2021
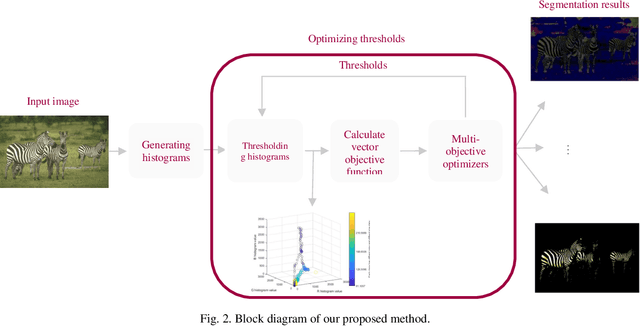
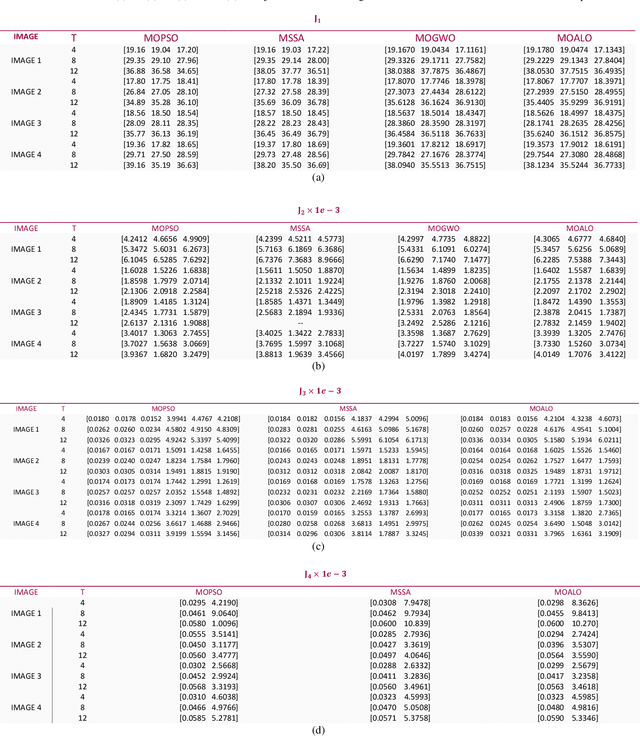
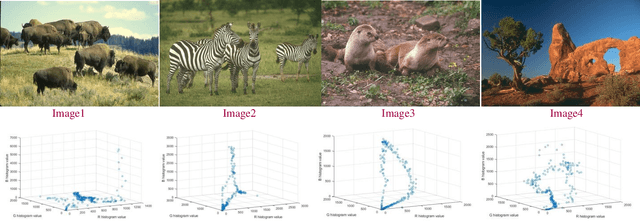
Rapid developments in swarm intelligence optimizers and computer processing abilities make opportunities to design more accurate, stable, and comprehensive methods for color image segmentation. This paper presents a new way for unsupervised image segmentation by combining histogram thresholding methods (Kapur's entropy and Otsu's method) and different multi-objective swarm intelligence algorithms (MOPSO, MOGWO, MSSA, and MOALO) to thresholding 3D histogram of a color image. More precisely, this method first combines the objective function of traditional thresholding algorithms to design comprehensive objective functions then uses multi-objective optimizers to find the best thresholds during the optimization of designed objective functions. Also, our method uses a vector objective function in 3D space that could simultaneously handle the segmentation of entire image color channels with the same thresholds. To optimize this vector objective function, we employ multiobjective swarm optimizers that can optimize multiple objective functions at the same time. Therefore, our method considers dependencies between channels to find the thresholds that satisfy objective functions of color channels (which we name as vector objective function) simultaneously. Segmenting entire color channels with the same thresholds also benefits from the fact that our proposed method needs fewer thresholds to segment the image than other thresholding algorithms; thus, it requires less memory space to save thresholds. It helps a lot when we want to segment many images to many regions. The subjective and objective results show the superiority of this method to traditional thresholding methods that separately threshold histograms of a color image.
Iterative Decoding for Compositional Generalization in Transformers
Oct 08, 2021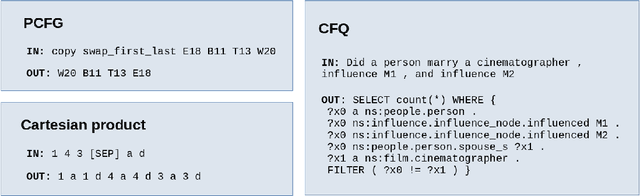
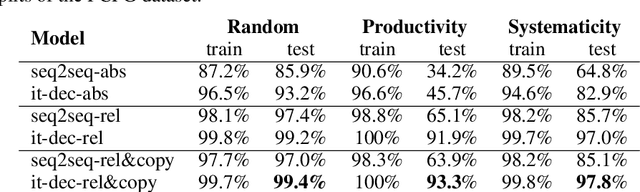
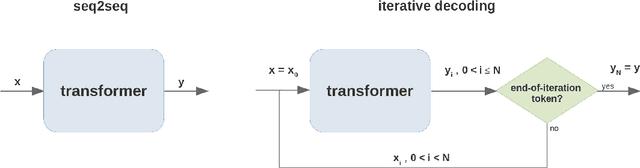
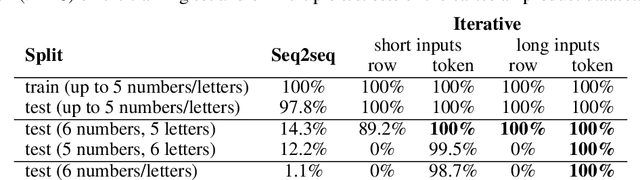
Deep learning models do well at generalizing to in-distribution data but struggle to generalize compositionally, i.e., to combine a set of learned primitives to solve more complex tasks. In particular, in sequence-to-sequence (seq2seq) learning, transformers are often unable to predict correct outputs for even marginally longer examples than those seen during training. This paper introduces iterative decoding, an alternative to seq2seq learning that (i) improves transformer compositional generalization and (ii) evidences that, in general, seq2seq transformers do not learn iterations that are not unrolled. Inspired by the idea of compositionality -- that complex tasks can be solved by composing basic primitives -- training examples are broken down into a sequence of intermediate steps that the transformer then learns iteratively. At inference time, the intermediate outputs are fed back to the transformer as intermediate inputs until an end-of-iteration token is predicted. Through numerical experiments, we show that transfomers trained via iterative decoding outperform their seq2seq counterparts on the PCFG dataset, and solve the problem of calculating Cartesian products between vectors longer than those seen during training with 100% accuracy, a task at which seq2seq models have been shown to fail. We also illustrate a limitation of iterative decoding, specifically, that it can make sorting harder to learn on the CFQ dataset.
Contracting Neural-Newton Solver
Jun 04, 2021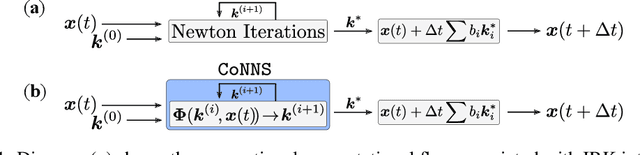
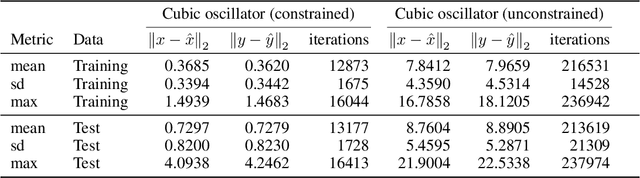
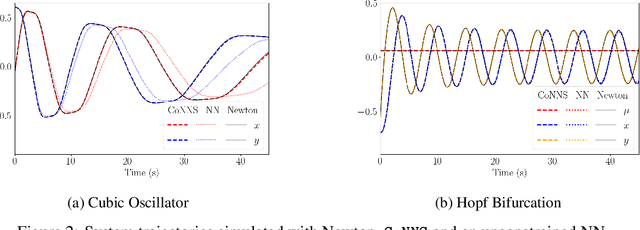
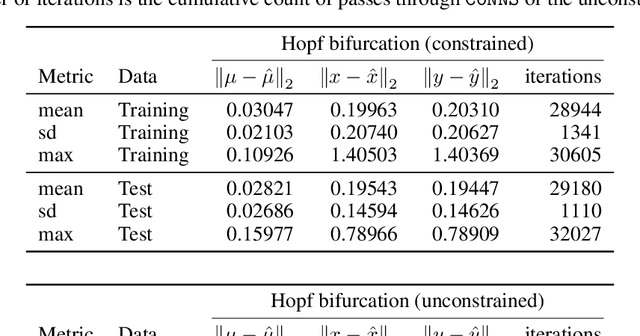
Recent advances in deep learning have set the focus on neural networks (NNs) that can successfully replace traditional numerical solvers in many applications, achieving impressive computing gains. One such application is time domain simulation, which is indispensable for the design, analysis and operation of many engineering systems. Simulating dynamical systems with implicit Newton-based solvers is a computationally heavy task, as it requires the solution of a parameterized system of differential and algebraic equations at each time step. A variety of NN-based methodologies have been shown to successfully approximate the dynamical trajectories computed by numerical time domain solvers at a fraction of the time. However, so far no previous NN-based model has explicitly captured the fact that any predicted point on the time domain trajectory also represents the fixed point of the numerical solver itself. As we show, explicitly capturing this property can lead to significantly increased NN accuracy and much smaller NN sizes. In this paper, we model the Newton solver at the heart of an implicit Runge-Kutta integrator as a contracting map iteratively seeking this fixed point. Our primary contribution is to develop a recurrent NN simulation tool, termed the Contracting Neural-Newton Solver (CoNNS), which explicitly captures the contracting nature of these Newton iterations. To build CoNNS, we train a feedforward NN and mimic this contraction behavior by embedding a series of training constraints which guarantee the mapping provided by the NN satisfies the Banach fixed-point theorem; thus, we are able to prove that successive passes through the NN are guaranteed to converge to a unique, fixed point.
Does Summary Evaluation Survive Translation to Other Languages?
Sep 16, 2021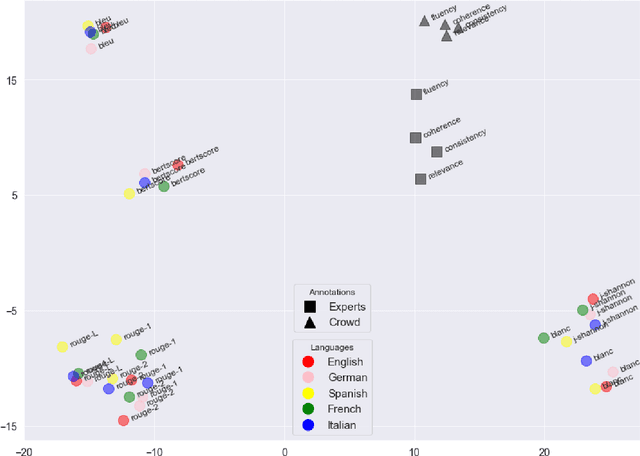
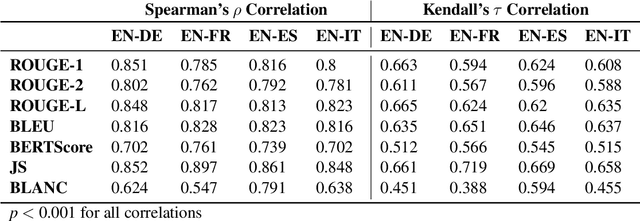
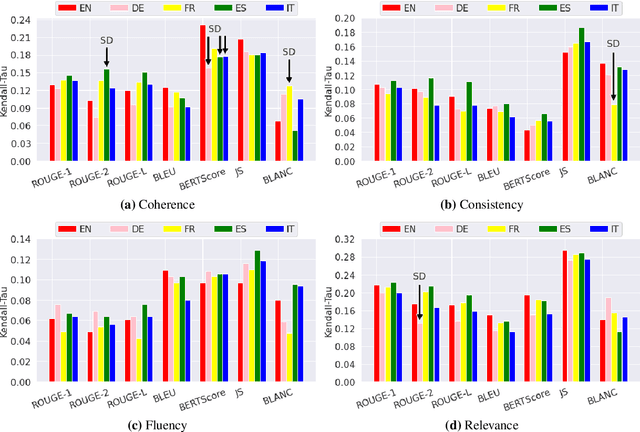
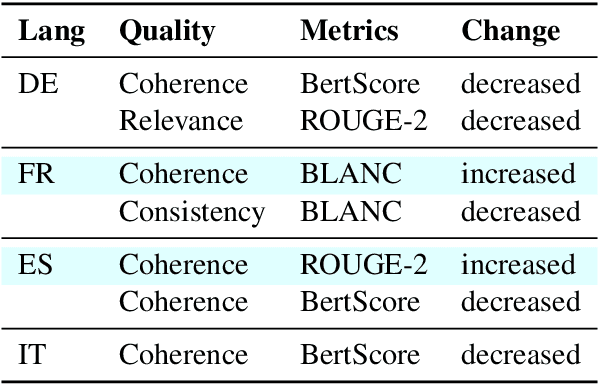
The creation of a large summarization quality dataset is a considerable, expensive, time-consuming effort, requiring careful planning and setup. It includes producing human-written and machine-generated summaries and evaluation of the summaries by humans, preferably by linguistic experts, and by automatic evaluation tools. If such effort is made in one language, it would be beneficial to be able to use it in other languages. To investigate how much we can trust the translation of such dataset without repeating human annotations in another language, we translated an existing English summarization dataset, SummEval dataset, to four different languages and analyzed the scores from the automatic evaluation metrics in translated languages, as well as their correlation with human annotations in the source language. Our results reveal that although translation changes the absolute value of automatic scores, the scores keep the same rank order and approximately the same correlations with human annotations.
Disentangling Identifiable Features from Noisy Data with Structured Nonlinear ICA
Jun 17, 2021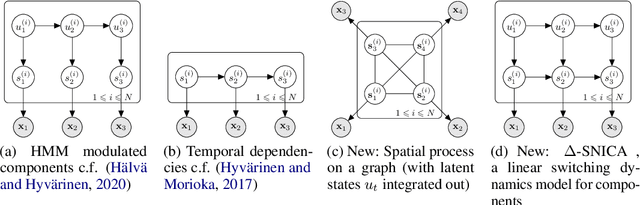
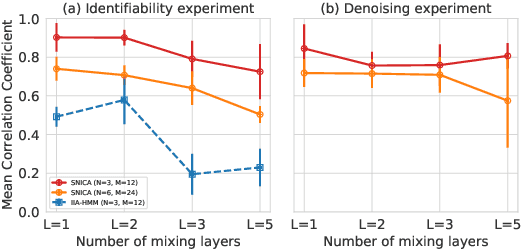
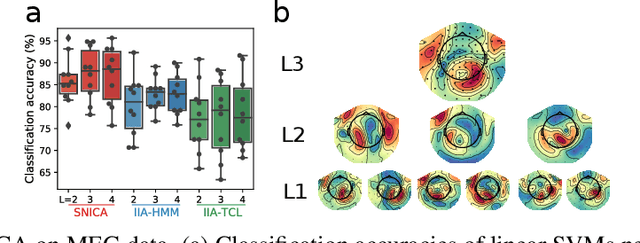
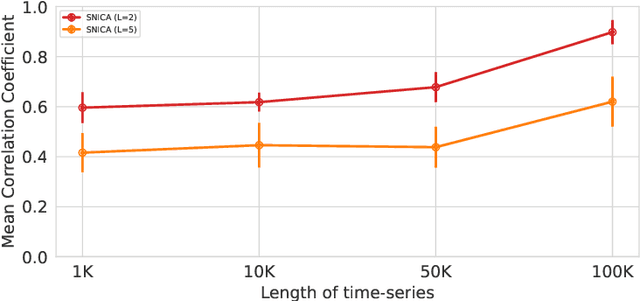
We introduce a new general identifiable framework for principled disentanglement referred to as Structured Nonlinear Independent Component Analysis (SNICA). Our contribution is to extend the identifiability theory of deep generative models for a very broad class of structured models. While previous works have shown identifiability for specific classes of time-series models, our theorems extend this to more general temporal structures as well as to models with more complex structures such as spatial dependencies. In particular, we establish the major result that identifiability for this framework holds even in the presence of noise of unknown distribution. The SNICA setting therefore subsumes all the existing nonlinear ICA models for time-series and also allows for new much richer identifiable models. Finally, as an example of our framework's flexibility, we introduce the first nonlinear ICA model for time-series that combines the following very useful properties: it accounts for both nonstationarity and autocorrelation in a fully unsupervised setting; performs dimensionality reduction; models hidden states; and enables principled estimation and inference by variational maximum-likelihood.
A Framework for Learning Assessment through Multimodal Analysis of Reading Behaviour and Language Comprehension
Oct 22, 2021

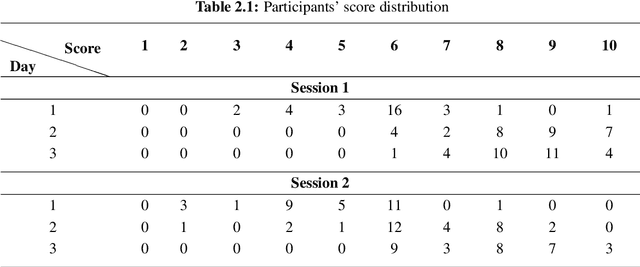
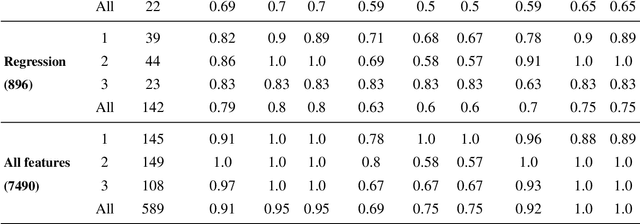
Reading comprehension, which has been defined as gaining an understanding of written text through a process of translating grapheme into meaning, is an important academic skill. Other language learning skills - writing, speaking and listening, all are connected to reading comprehension. There have been several measures proposed by researchers to automate the assessment of comprehension skills for second language (L2) learners, especially English as Second Language (ESL) and English as Foreign Language (EFL) learners. However, current methods measure particular skills without analysing the impact of reading frequency on comprehension skills. In this dissertation, we show how different skills could be measured and scored automatically. We also demonstrate, using example experiments on multiple forms of learners' responses, how frequent reading practices could impact on the variables of multimodal skills (reading pattern, writing, and oral fluency). This thesis comprises of five studies. The first and second studies are based on eye-tracking data collected from EFL readers in repeated reading (RR) sessions. The third and fourth studies are to evaluate free-text summary written by EFL readers in repeated reading sessions. The fifth and last study, described in the sixth chapter of the thesis, is to evaluate recorded oral summaries recited by EFL readers in repeated reading sessions. In a nutshell, through this dissertation, we show that multimodal skills of learners could be assessed to measure their comprehension skills as well as to measure the effect of repeated readings on these skills in the course of time, by finding significant features and by applying machine learning techniques with a combination of statistical models such as LMER.
An actor-critic algorithm with deep double recurrent agents to solve the job shop scheduling problem
Oct 18, 2021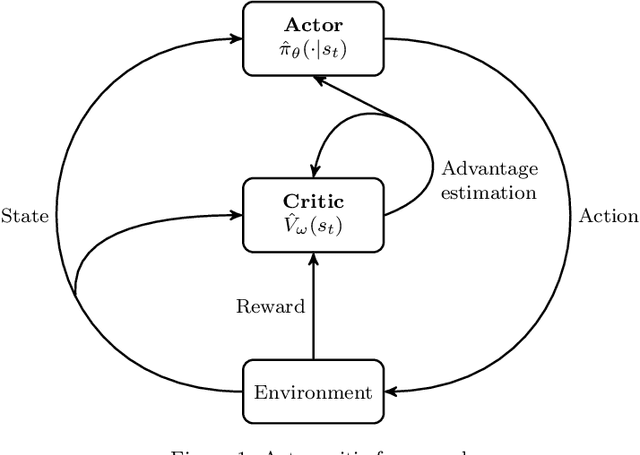
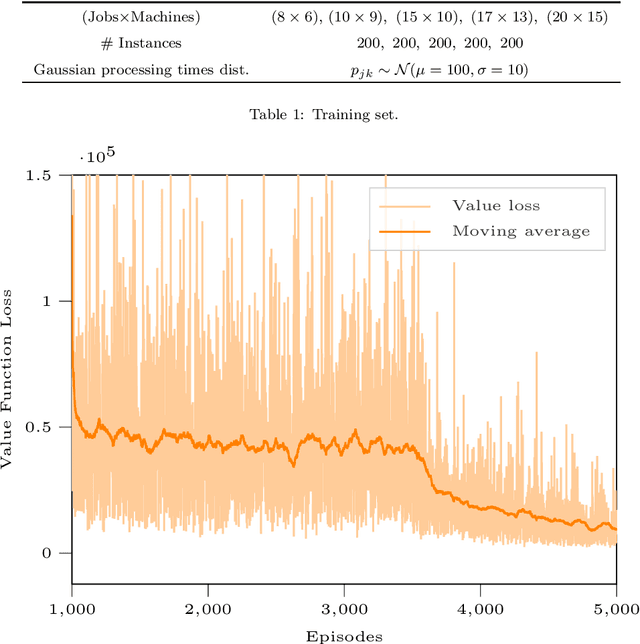
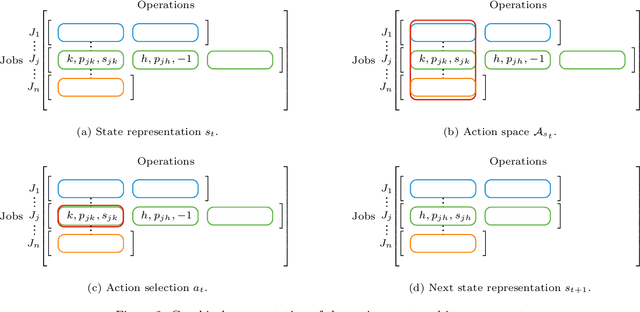

There is a growing interest in integrating machine learning techniques and optimization to solve challenging optimization problems. In this work, we propose a deep reinforcement learning methodology for the job shop scheduling problem (JSSP). The aim is to build up a greedy-like heuristic able to learn on some distribution of JSSP instances, different in the number of jobs and machines. The need for fast scheduling methods is well known, and it arises in many areas, from transportation to healthcare. We model the JSSP as a Markov Decision Process and then we exploit the efficacy of reinforcement learning to solve the problem. We adopt an actor-critic scheme, where the action taken by the agent is influenced by policy considerations on the state-value function. The procedures are adapted to take into account the challenging nature of JSSP, where the state and the action space change not only for every instance but also after each decision. To tackle the variability in the number of jobs and operations in the input, we modeled the agent using two incident LSTM models, a special type of deep neural network. Experiments show the algorithm reaches good solutions in a short time, proving that is possible to generate new greedy heuristics just from learning-based methodologies. Benchmarks have been generated in comparison with the commercial solver CPLEX. As expected, the model can generalize, to some extent, to larger problems or instances originated by a different distribution from the one used in training.
Applying supervised and reinforcement learning methods to create neural-network-based agents for playing StarCraft II
Sep 26, 2021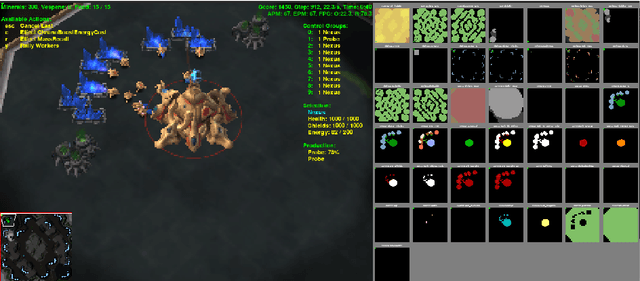
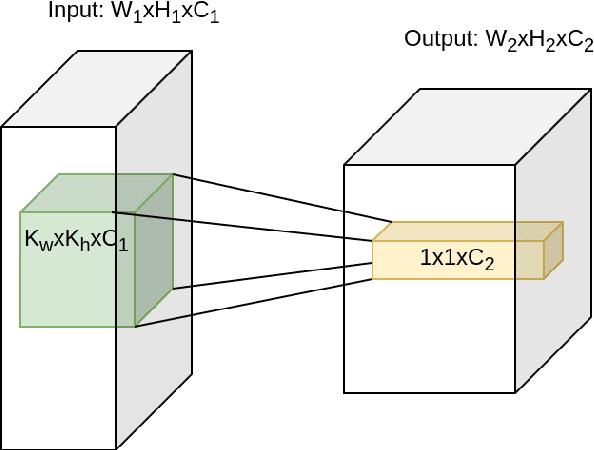
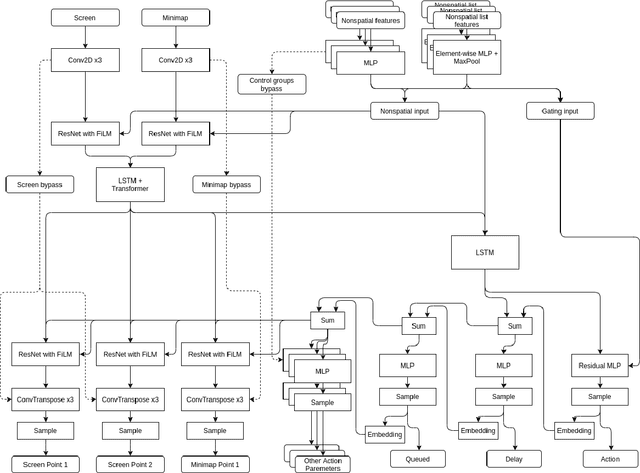
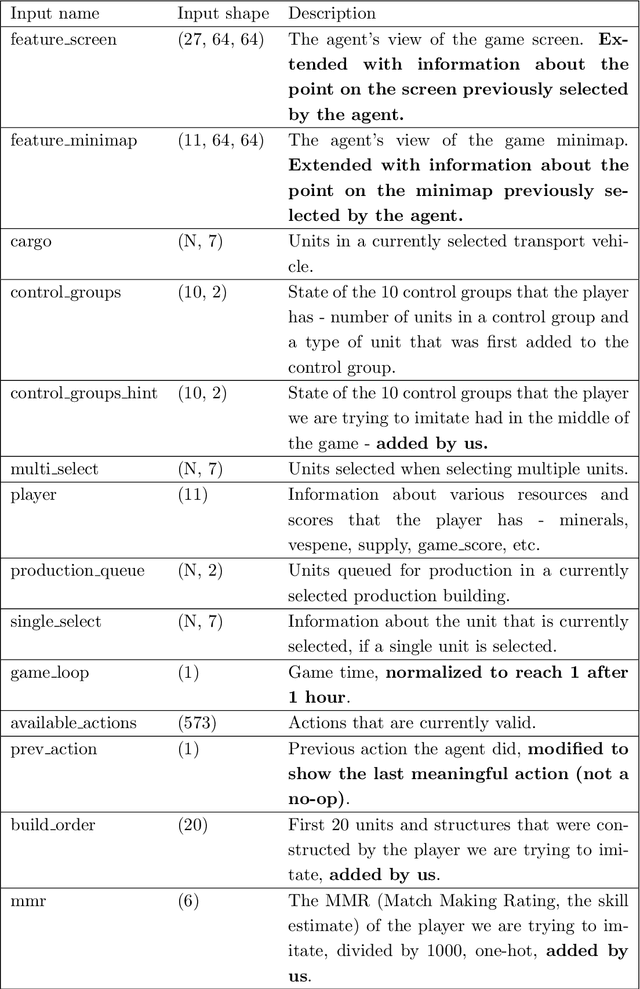
Recently, multiple approaches for creating agents for playing various complex real-time computer games such as StarCraft II or Dota 2 were proposed, however, they either embed a significant amount of expert knowledge into the agent or use a prohibitively large for most researchers amount of computational resources. We propose a neural network architecture for playing the full two-player match of StarCraft II trained with general-purpose supervised and reinforcement learning, that can be trained on a single consumer-grade PC with a single GPU. We also show that our implementation achieves a non-trivial performance when compared to the in-game scripted bots. We make no simplifying assumptions about the game except for playing on a single chosen map, and we use very little expert knowledge. In principle, our approach can be applied to any RTS game with small modifications. While our results are far behind the state-of-the-art large-scale approaches in terms of the final performance, we believe our work can serve as a solid baseline for other small-scale experiments.
DeepVecFont: Synthesizing High-quality Vector Fonts via Dual-modality Learning
Oct 13, 2021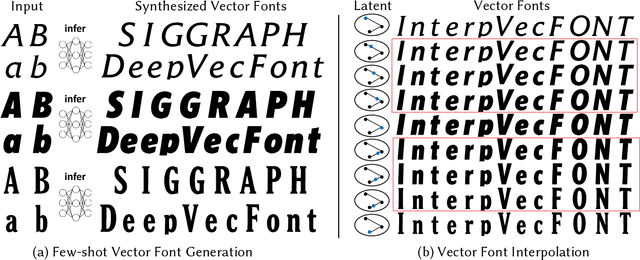
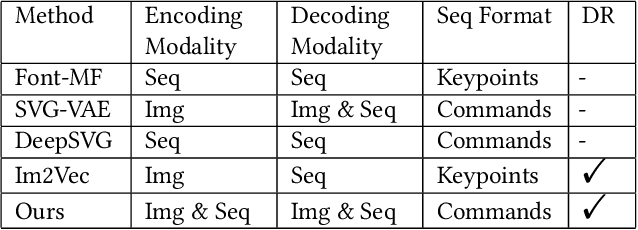
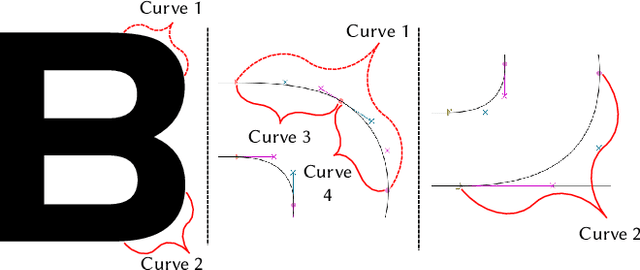
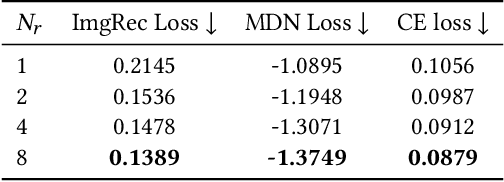
Automatic font generation based on deep learning has aroused a lot of interest in the last decade. However, only a few recently-reported approaches are capable of directly generating vector glyphs and their results are still far from satisfactory. In this paper, we propose a novel method, DeepVecFont, to effectively resolve this problem. Using our method, for the first time, visually-pleasing vector glyphs whose quality and compactness are both comparable to human-designed ones can be automatically generated. The key idea of our DeepVecFont is to adopt the techniques of image synthesis, sequence modeling and differentiable rasterization to exhaustively exploit the dual-modality information (i.e., raster images and vector outlines) of vector fonts. The highlights of this paper are threefold. First, we design a dual-modality learning strategy which utilizes both image-aspect and sequence-aspect features of fonts to synthesize vector glyphs. Second, we provide a new generative paradigm to handle unstructured data (e.g., vector glyphs) by randomly sampling plausible synthesis results to get the optimal one which is further refined under the guidance of generated structured data (e.g., glyph images). Finally, qualitative and quantitative experiments conducted on a publicly-available dataset demonstrate that our method obtains high-quality synthesis results in the applications of vector font generation and interpolation, significantly outperforming the state of the art.