 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Short Term Prediction of Parking Area states Using Real Time Data and Machine Learning Techniques
Nov 29, 2019
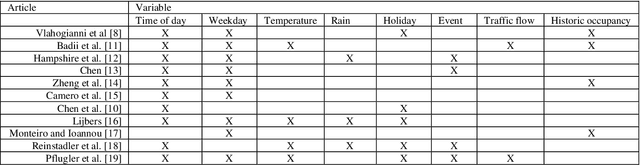
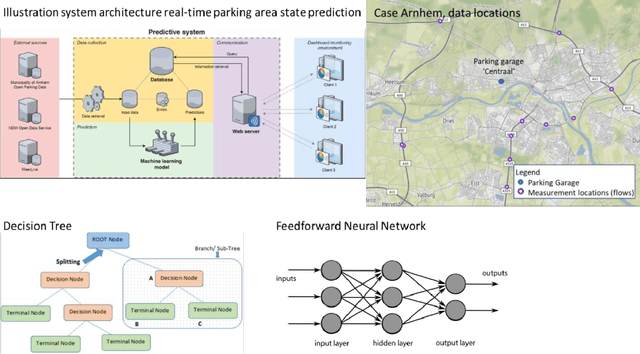
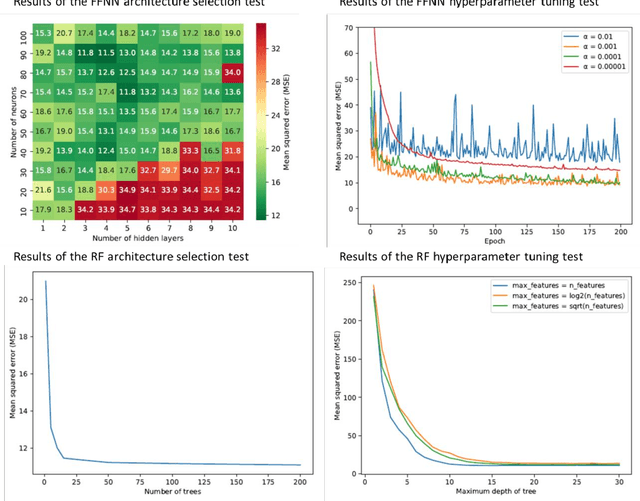
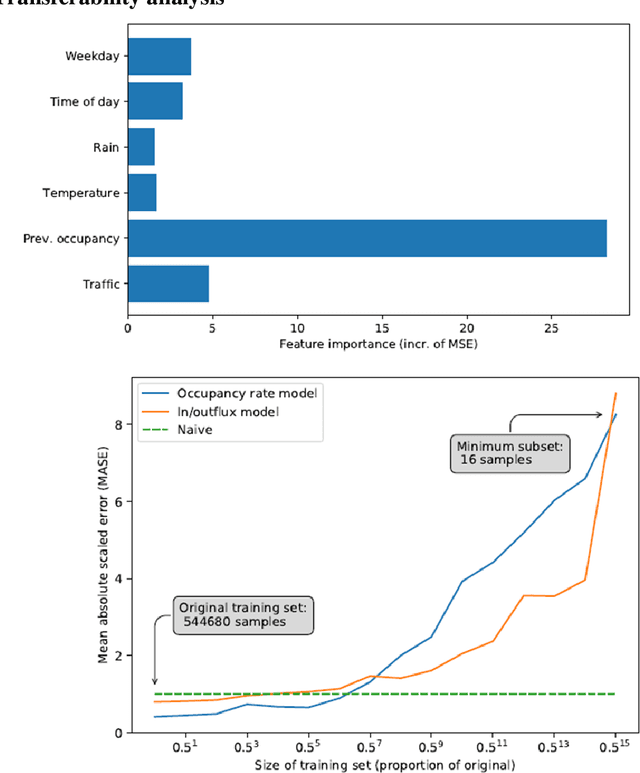
Public road authorities and private mobility service providers need information derived from the current and predicted traffic states to act upon the daily urban system and its spatial and temporal dynamics. In this research, a real-time parking area state (occupancy, in- and outflux) prediction model (up to 60 minutes ahead) has been developed using publicly available historic and real time data sources. Based on a case study in a real-life scenario in the city of Arnhem, a Neural Network-based approach outperforms a Random Forest-based one on all assessed performance measures, although the differences are small. Both are outperforming a naive seasonal random walk model. Although the performance degrades with increasing prediction horizon, the model shows a performance gain of over 150% at a prediction horizon of 60 minutes compared with the naive model. Furthermore, it is shown that predicting the in- and outflux is a far more difficult task (i.e. performance gains of 30%) which needs more training data, not based exclusively on occupancy rate. However, the performance of predicting in- and outflux is less sensitive to the prediction horizon. In addition, it is shown that real-time information of current occupancy rate is the independent variable with the highest contribution to the performance, although time, traffic flow and weather variables also deliver a significant contribution. During real-time deployment, the model performs three times better than the naive model on average. As a result, it can provide valuable information for proactive traffic management as well as mobility service providers.
Classifying Pattern and Feature Properties to Get a $Θ(n)$ Checker and Reformulation for Sliding Time-Series Constraints
Dec 03, 2019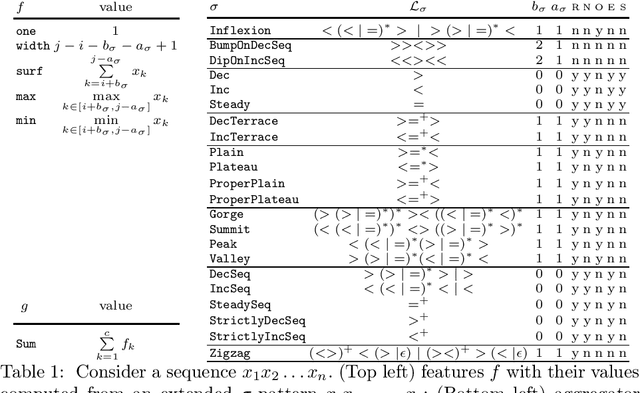

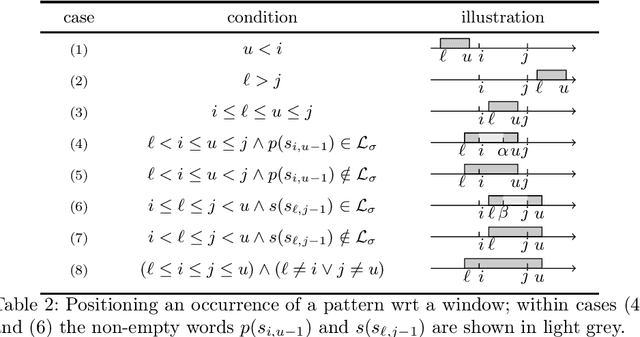
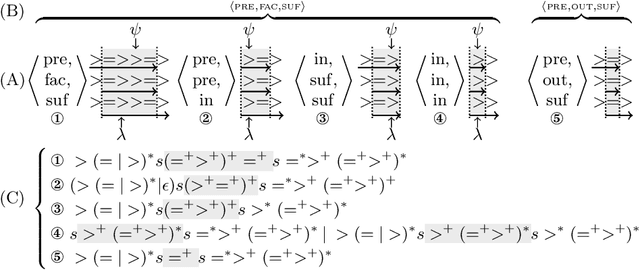
Given, a sequence $\mathcal{X}$ of $n$ variables, a time-series constraint ctr using the Sum aggregator, and a sliding time-series constraint enforcing the constraint ctr on each sliding window of $\mathcal{X}$ of $m$ consecutive variables, we describe a $\Theta(n)$ time complexity checker, as well as a $\Theta(n)$ space complexity reformulation for such sliding constraint.
Probabilistic Stability Analysis of Planar Robots with Piecewise Constant Derivative Dynamics
Sep 17, 2021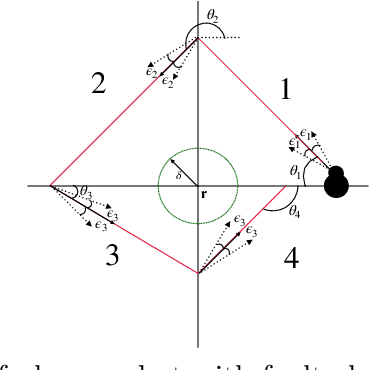
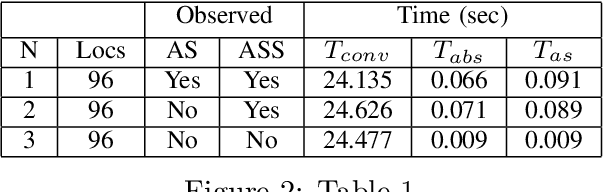
In this paper, we study the probabilistic stability analysis of a subclass of stochastic hybrid systems, called the Planar Probabilistic Piecewise Constant Derivative Systems (Planar PPCD), where the continuous dynamics is deterministic, constant rate and planar, the discrete switching between the modes is probabilistic and happens at boundary of the invariant regions, and the continuous states are not reset during switching. These aptly model piecewise linear behaviors of planar robots. Our main result is an exact algorithm for deciding absolute and almost sure stability of Planar PPCD under some mild assumptions on mutual reachability between the states and the presence of non-zero probability self-loops. Our main idea is to reduce the stability problems on planar PPCD into corresponding problems on Discrete Time Markov Chains with edge weights. Our experimental results on planar robots with faulty angle actuator demonstrate the practical feasibility of this approach.
Text to Insight: Accelerating Organic Materials Knowledge Extraction via Deep Learning
Sep 27, 2021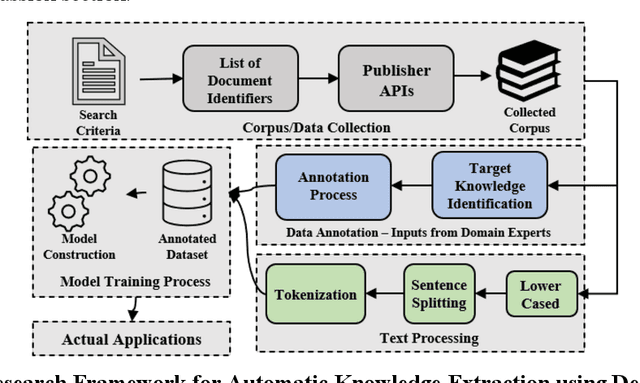

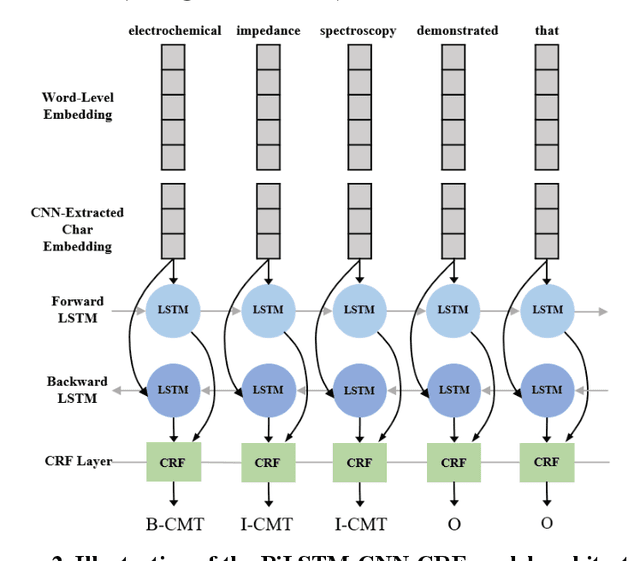
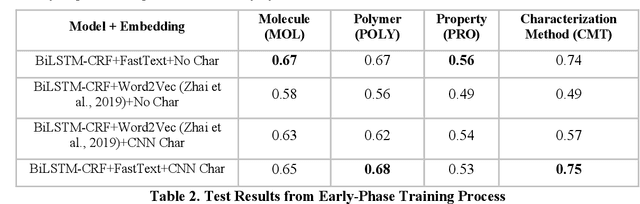
Scientific literature is one of the most significant resources for sharing knowledge. Researchers turn to scientific literature as a first step in designing an experiment. Given the extensive and growing volume of literature, the common approach of reading and manually extracting knowledge is too time consuming, creating a bottleneck in the research cycle. This challenge spans nearly every scientific domain. For the materials science, experimental data distributed across millions of publications are extremely helpful for predicting materials properties and the design of novel materials. However, only recently researchers have explored computational approaches for knowledge extraction primarily for inorganic materials. This study aims to explore knowledge extraction for organic materials. We built a research dataset composed of 855 annotated and 708,376 unannotated sentences drawn from 92,667 abstracts. We used named-entity-recognition (NER) with BiLSTM-CNN-CRF deep learning model to automatically extract key knowledge from literature. Early-phase results show a high potential for automated knowledge extraction. The paper presents our findings and a framework for supervised knowledge extraction that can be adapted to other scientific domains.
Iterative Decoding for Compositional Generalization in Transformers
Oct 08, 2021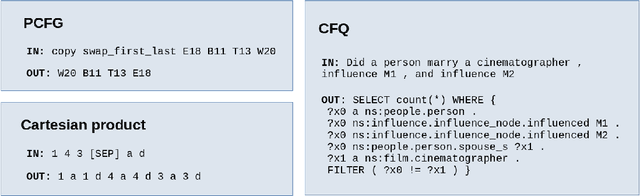
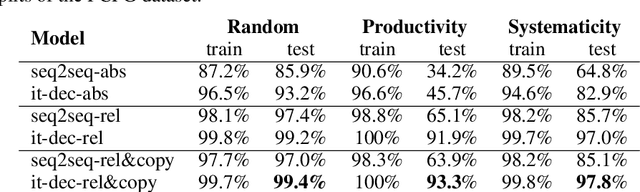
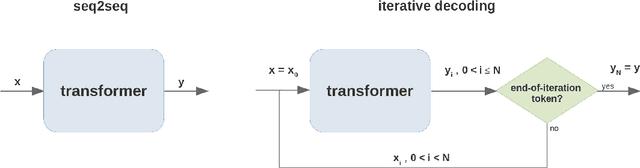
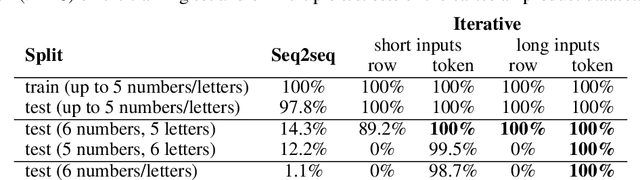
Deep learning models do well at generalizing to in-distribution data but struggle to generalize compositionally, i.e., to combine a set of learned primitives to solve more complex tasks. In particular, in sequence-to-sequence (seq2seq) learning, transformers are often unable to predict correct outputs for even marginally longer examples than those seen during training. This paper introduces iterative decoding, an alternative to seq2seq learning that (i) improves transformer compositional generalization and (ii) evidences that, in general, seq2seq transformers do not learn iterations that are not unrolled. Inspired by the idea of compositionality -- that complex tasks can be solved by composing basic primitives -- training examples are broken down into a sequence of intermediate steps that the transformer then learns iteratively. At inference time, the intermediate outputs are fed back to the transformer as intermediate inputs until an end-of-iteration token is predicted. Through numerical experiments, we show that transfomers trained via iterative decoding outperform their seq2seq counterparts on the PCFG dataset, and solve the problem of calculating Cartesian products between vectors longer than those seen during training with 100% accuracy, a task at which seq2seq models have been shown to fail. We also illustrate a limitation of iterative decoding, specifically, that it can make sorting harder to learn on the CFQ dataset.
Real-time Detection of Clustered Events in Video-imaging data with Applications to Additive Manufacturing
Apr 23, 2020
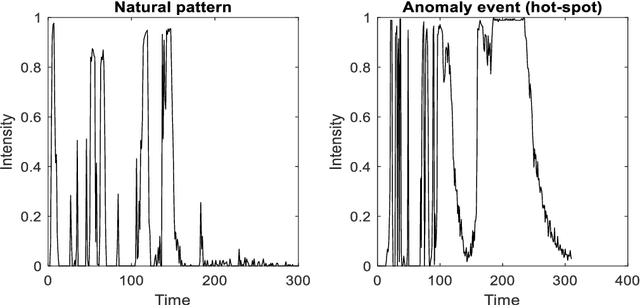

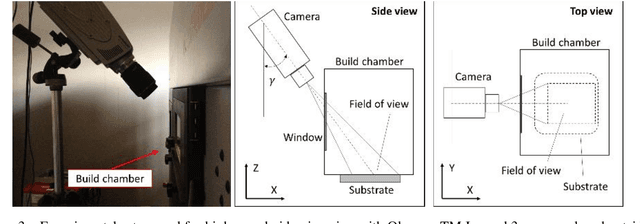
The use of video-imaging data for in-line process monitoring applications has become more and more popular in the industry. In this framework, spatio-temporal statistical process monitoring methods are needed to capture the relevant information content and signal possible out-of-control states. Video-imaging data are characterized by a spatio-temporal variability structure that depends on the underlying phenomenon, and typical out-of-control patterns are related to the events that are localized both in time and space. In this paper, we propose an integrated spatio-temporal decomposition and regression approach for anomaly detection in video-imaging data. Out-of-control events are typically sparse spatially clustered and temporally consistent. Therefore, the goal is to not only detect the anomaly as quickly as possible ("when") but also locate it ("where"). The proposed approach works by decomposing the original spatio-temporal data into random natural events, sparse spatially clustered and temporally consistent anomalous events, and random noise. Recursive estimation procedures for spatio-temporal regression are presented to enable the real-time implementation of the proposed methodology. Finally, a likelihood ratio test procedure is proposed to detect when and where the hotspot happens. The proposed approach was applied to the analysis of video-imaging data to detect and locate local over-heating phenomena ("hotspots") during the layer-wise process in a metal additive manufacturing process.
Clustering Activity-Travel Behavior Time Series using Topological Data Analysis
Jul 17, 2019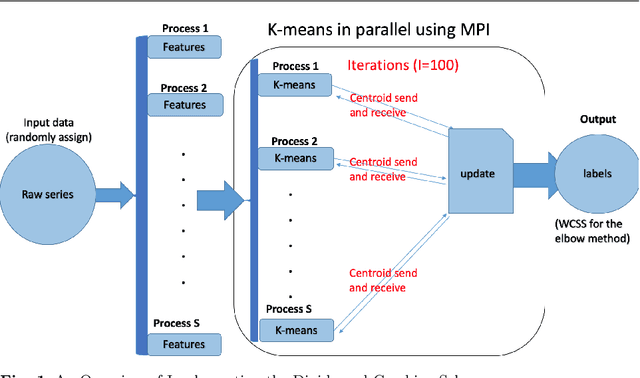
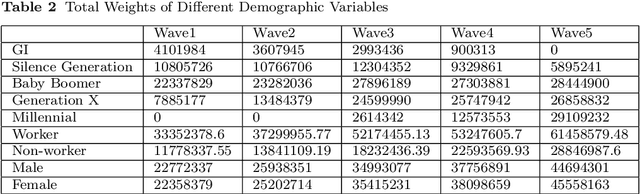
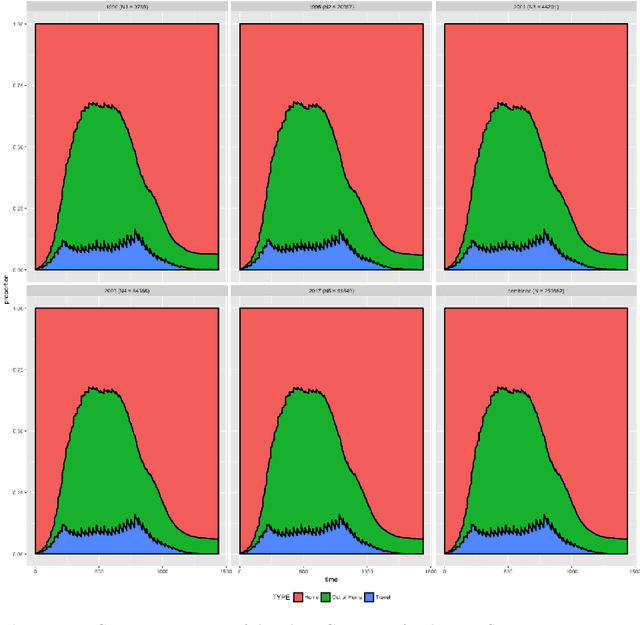
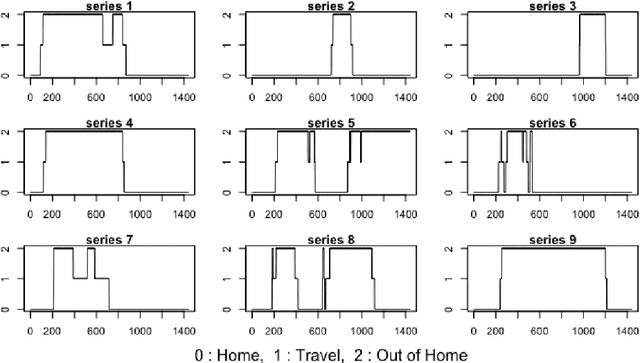
Over the last few years, traffic data has been exploding and the transportation discipline has entered the era of big data. It brings out new opportunities for doing data-driven analysis, but it also challenges traditional analytic methods. This paper proposes a new Divide and Combine based approach to do K means clustering on activity-travel behavior time series using features that are derived using tools in Time Series Analysis and Topological Data Analysis. Clustering data from five waves of the National Household Travel Survey ranging from 1990 to 2017 suggests that activity-travel patterns of individuals over the last three decades can be grouped into three clusters. Results also provide evidence in support of recent claims about differences in activity-travel patterns of different survey cohorts. The proposed method is generally applicable and is not limited only to activity-travel behavior analysis in transportation studies. Driving behavior, travel mode choice, household vehicle ownership, when being characterized as categorical time series, can all be analyzed using the proposed method.
Artificial Intelligence Algorithms for Natural Language Processing and the Semantic Web Ontology Learning
Aug 31, 2021Evolutionary clustering algorithms have considered as the most popular and widely used evolutionary algorithms for minimising optimisation and practical problems in nearly all fields. In this thesis, a new evolutionary clustering algorithm star (ECA*) is proposed. Additionally, a number of experiments were conducted to evaluate ECA* against five state-of-the-art approaches. For this, 32 heterogeneous and multi-featured datasets were used to examine their performance using internal and external clustering measures, and to measure the sensitivity of their performance towards dataset features in the form of operational framework. The results indicate that ECA* overcomes its competitive techniques in terms of the ability to find the right clusters. Based on its superior performance, exploiting and adapting ECA* on the ontology learning had a vital possibility. In the process of deriving concept hierarchies from corpora, generating formal context may lead to a time-consuming process. Therefore, formal context size reduction results in removing uninterested and erroneous pairs, taking less time to extract the concept lattice and concept hierarchies accordingly. In this premise, this work aims to propose a framework to reduce the ambiguity of the formal context of the existing framework using an adaptive version of ECA*. In turn, an experiment was conducted by applying 385 sample corpora from Wikipedia on the two frameworks to examine the reduction of formal context size, which leads to yield concept lattice and concept hierarchy. The resulting lattice of formal context was evaluated to the original one using concept lattice-invariants. Accordingly, the homomorphic between the two lattices preserves the quality of resulting concept hierarchies by 89% in contrast to the basic ones, and the reduced concept lattice inherits the structural relation of the original one.
Clustering in Recurrent Neural Networks for Micro-Segmentation using Spending Personality
Sep 20, 2021
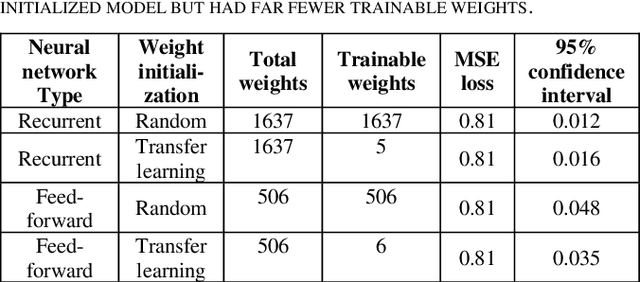
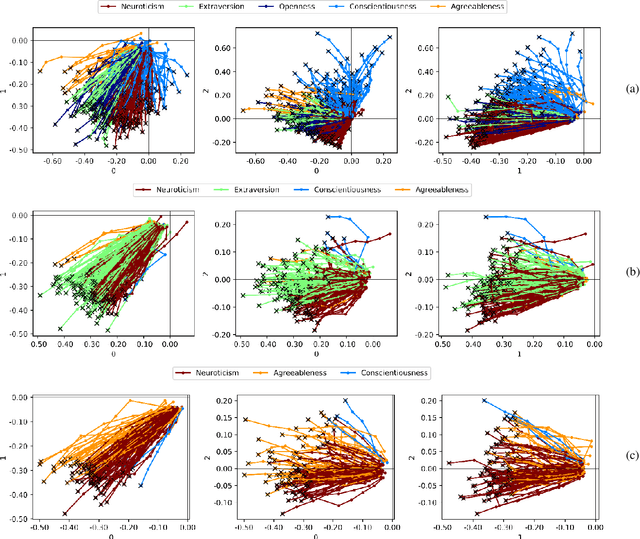
Customer segmentation has long been a productive field in banking. However, with new approaches to traditional problems come new opportunities. Fine-grained customer segments are notoriously elusive and one method of obtaining them is through feature extraction. It is possible to assign coefficients of standard personality traits to financial transaction classes aggregated over time. However, we have found that the clusters formed are not sufficiently discriminatory for micro-segmentation. In this study, we extract temporal features with continuous values from the hidden states of neural networks predicting customers' spending personality from their financial transactions. We consider both temporal and non-sequential models, using long short-term memory (LSTM) and feed-forward neural networks, respectively. We found that recurrent neural networks produce micro-segments where feed-forward networks produce only course segments. Finally, we show that classification using these extracted features performs at least as well as bespoke models on two common metrics, namely loan default rate and customer liquidity index.
A Framework for Learning Assessment through Multimodal Analysis of Reading Behaviour and Language Comprehension
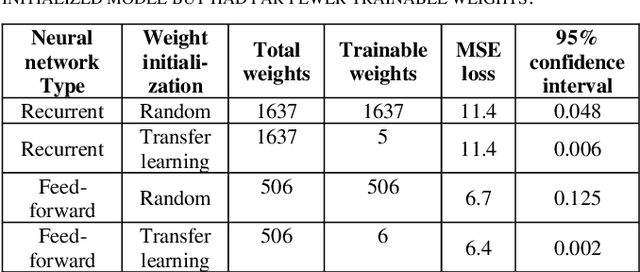
Oct 22, 2021

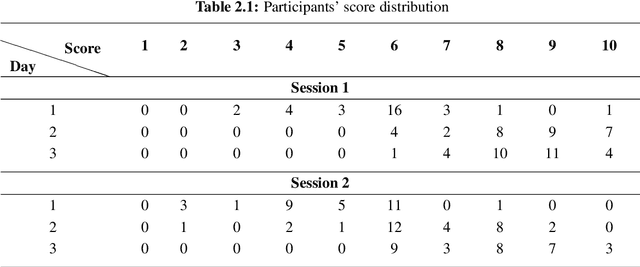
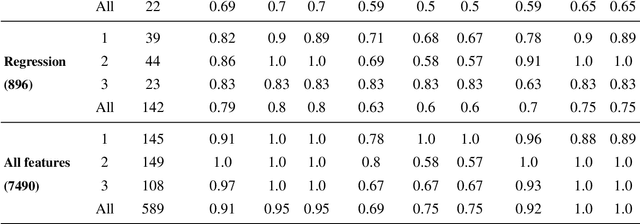
Reading comprehension, which has been defined as gaining an understanding of written text through a process of translating grapheme into meaning, is an important academic skill. Other language learning skills - writing, speaking and listening, all are connected to reading comprehension. There have been several measures proposed by researchers to automate the assessment of comprehension skills for second language (L2) learners, especially English as Second Language (ESL) and English as Foreign Language (EFL) learners. However, current methods measure particular skills without analysing the impact of reading frequency on comprehension skills. In this dissertation, we show how different skills could be measured and scored automatically. We also demonstrate, using example experiments on multiple forms of learners' responses, how frequent reading practices could impact on the variables of multimodal skills (reading pattern, writing, and oral fluency). This thesis comprises of five studies. The first and second studies are based on eye-tracking data collected from EFL readers in repeated reading (RR) sessions. The third and fourth studies are to evaluate free-text summary written by EFL readers in repeated reading sessions. The fifth and last study, described in the sixth chapter of the thesis, is to evaluate recorded oral summaries recited by EFL readers in repeated reading sessions. In a nutshell, through this dissertation, we show that multimodal skills of learners could be assessed to measure their comprehension skills as well as to measure the effect of repeated readings on these skills in the course of time, by finding significant features and by applying machine learning techniques with a combination of statistical models such as LMER.