 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Neural Implicit Surfaces for Efficient and Accurate Collisions in Physically Based Simulations
Oct 03, 2021




Current trends in the computer graphics community propose leveraging the massive parallel computational power of GPUs to accelerate physically based simulations. Collision detection and solving is a fundamental part of this process. It is also the most significant bottleneck on physically based simulations and it easily becomes intractable as the number of vertices in the scene increases. Brute force approaches carry a quadratic growth in both computational time and memory footprint. While their parallelization is trivial in GPUs, their complexity discourages from using such approaches. Acceleration structures -- such as BVH -- are often applied to increase performance, achieving logarithmic computational times for individual point queries. Nonetheless, their memory footprint also grows rapidly and their parallelization in a GPU is problematic due to their branching nature. We propose using implicit surface representations learnt through deep learning for collision handling in physically based simulations. Our proposed architecture has a complexity of O(n) -- or O(1) for a single point query -- and has no parallelization issues. We will show how this permits accurate and efficient collision handling in physically based simulations, more specifically, for cloth. In our experiments, we query up to 1M points in 300 milliseconds.
BGaitR-Net: Occluded Gait Sequence reconstructionwith temporally constrained model for gait recognition
Oct 18, 2021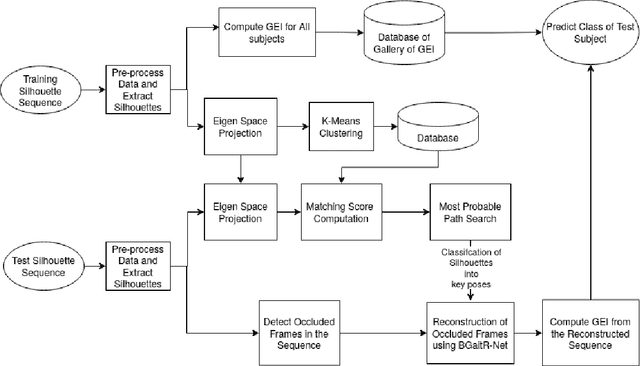
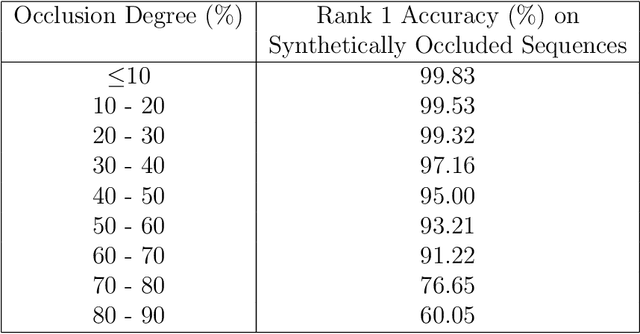

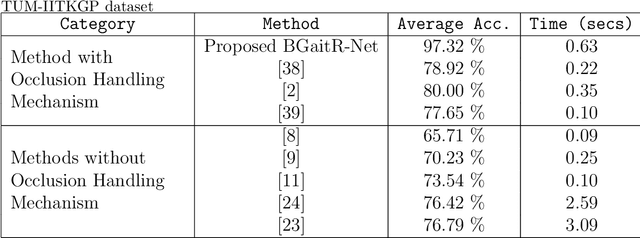
Recent advancements in computational resources and Deep Learning methodologies has significantly benefited development of intelligent vision-based surveillance applications. Gait recognition in the presence of occlusion is one of the challenging research topics in this area, and the solutions proposed by researchers to date lack in robustness and also dependent of several unrealistic constraints, which limits their practical applicability. We improve the state-of-the-art by developing novel deep learning-based algorithms to identify the occluded frames in an input sequence and next reconstruct these occluded frames by exploiting the spatio-temporal information present in the gait sequence. The multi-stage pipeline adopted in this work consists of key pose mapping, occlusion detection and reconstruction, and finally gait recognition. While the key pose mapping and occlusion detection phases are done %using Constrained KMeans Clustering and via a graph sorting algorithm, reconstruction of occluded frames is done by fusing the key pose-specific information derived in the previous step along with the spatio-temporal information contained in a gait sequence using a Bi-Directional Long Short Time Memory. This occlusion reconstruction model has been trained using synthetically occluded CASIA-B and OU-ISIR data, and the trained model is termed as Bidirectional Gait Reconstruction Network BGait-R-Net. Our LSTM-based model reconstructs occlusion and generates frames that are temporally consistent with the periodic pattern of a gait cycle, while simultaneously preserving the body structure.
A Comprehensive Study on Torchvision Pre-trained Models for Fine-grained Inter-species Classification
Oct 14, 2021



This study aims to explore different pre-trained models offered in the Torchvision package which is available in the PyTorch library. And investigate their effectiveness on fine-grained images classification. Transfer Learning is an effective method of achieving extremely good performance with insufficient training data. In many real-world situations, people cannot collect sufficient data required to train a deep neural network model efficiently. Transfer Learning models are pre-trained on a large data set, and can bring a good performance on smaller datasets with significantly lower training time. Torchvision package offers us many models to apply the Transfer Learning on smaller datasets. Therefore, researchers may need a guideline for the selection of a good model. We investigate Torchvision pre-trained models on four different data sets: 10 Monkey Species, 225 Bird Species, Fruits 360, and Oxford 102 Flowers. These data sets have images of different resolutions, class numbers, and different achievable accuracies. We also apply their usual fully-connected layer and the Spinal fully-connected layer to investigate the effectiveness of SpinalNet. The Spinal fully-connected layer brings better performance in most situations. We apply the same augmentation for different models for the same data set for a fair comparison. This paper may help future Computer Vision researchers in choosing a proper Transfer Learning model.
* Accepted
Nonuniform Sampling Rate Conversion: An Efficient Approach
May 14, 2021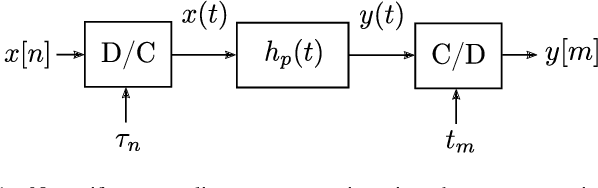
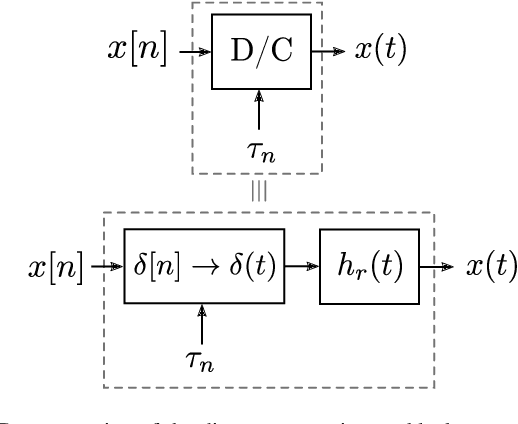
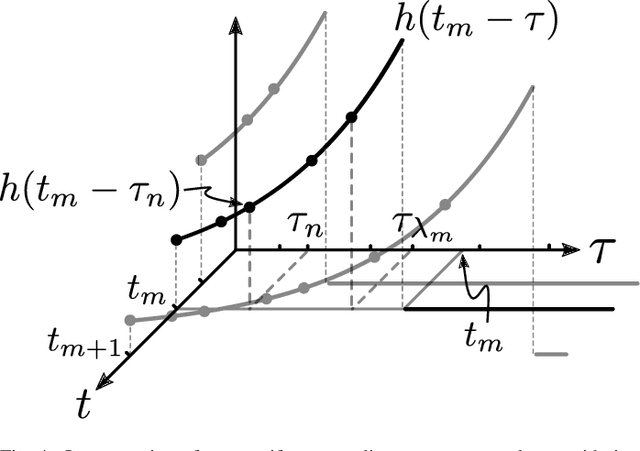
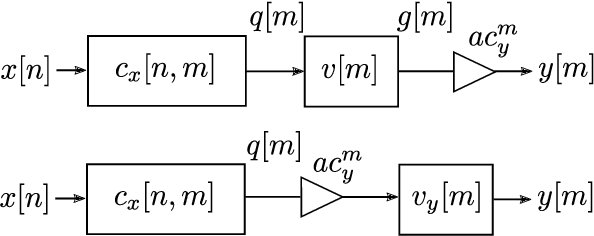
We present a discrete-time algorithm for nonuniform sampling rate conversion that presents low computational complexity and memory requirements. It generalizes arbitrary sampling rate conversion by accommodating time-varying conversion ratios, i.e., it can efficiently adapt to instantaneous changes of the input and output sampling rates. This approach is based on appropriately factorizing the time-varying discrete-time filter used for the conversion. Common filters that satisfy this factorization property are those where the underlying continuous-time filter consists of linear combinations of exponentials, e.g., those described by linear constant-coefficient differential equations. This factorization separates the computation into two parts: one consisting of a factor solely depending on the output sampling instants and the other consists of a summation -- that can be computed recursively -- whose terms depend solely on the input sampling instants and its number of terms is given by a relationship between input and output sampling instants. Thus, nonuniform sampling rates can be accommodated by updating the factors involved and adjusting the number of terms added. When the impulse response consists of exponentials, computing the factors can be done recursively in an efficient manner.
Review of Clustering-Based Recommender Systems
Sep 27, 2021Recommender systems are one of the most applied methods in machine learning and find applications in many areas, ranging from economics to the Internet of things. This article provides a general overview of modern approaches to recommender system design using clustering as a preliminary step to improve overall performance. Using clustering can address several known issues in recommendation systems, including increasing the diversity, consistency, and reliability of recommendations; the data sparsity of user-preference matrices; and changes in user preferences over time. This work will be useful for both beginners in the field of recommender systems and specialists in related fields that are interested in examining the applicability of recommender systems. This review is focused on the analysis of the scientific literature on the topics of recommender systems and clustering models that have appeared in recent years and contains a representative list of the literature for the further exploration of this topic. In the first part, a brief introduction to the so-called classic or traditional recommendation algorithms is given, along with an overview of the clustering problem.
Adaptive importance sampling for seismic fragility curve estimation
Sep 09, 2021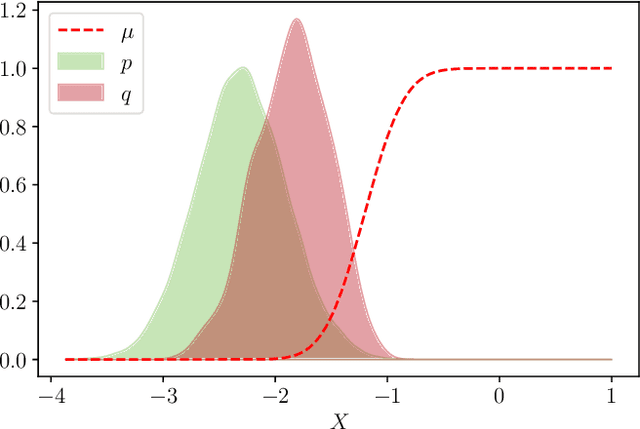
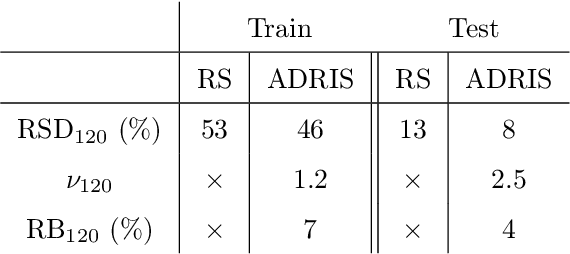
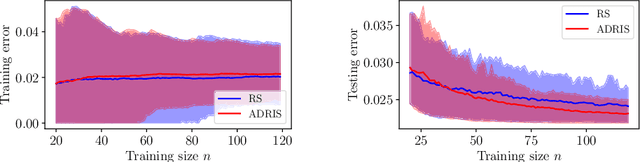
As part of Probabilistic Risk Assessment studies, it is necessary to study the fragility of mechanical and civil engineered structures when subjected to seismic loads. This risk can be measured with fragility curves, which express the probability of failure of the structure conditionally to a seismic intensity measure. The estimation of fragility curves relies on time-consuming numerical simulations, so that careful experimental design is required in order to gain the maximum information on the structure's fragility with a limited number of code evaluations. We propose and implement an active learning methodology based on adaptive importance sampling in order to reduce the variance of the training loss. The efficiency of the proposed method in terms of bias, standard deviation and prediction interval coverage are theoretically and numerically characterized.
SPAP: Simultaneous Demand Prediction and Planning for Electric Vehicle Chargers in a New City
Oct 18, 2021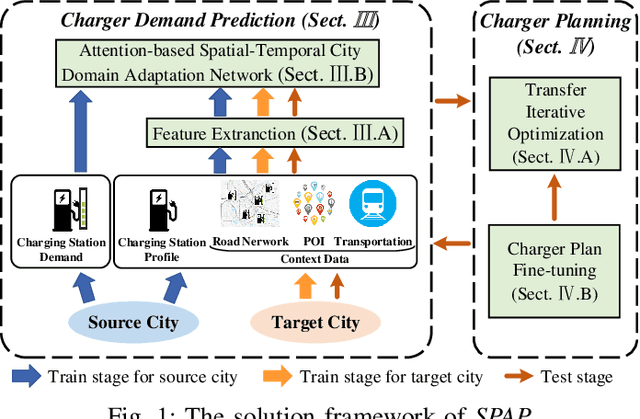
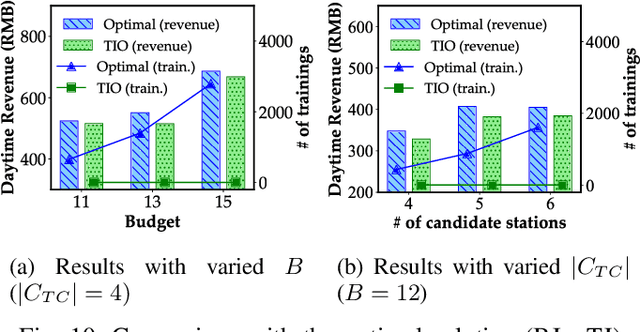
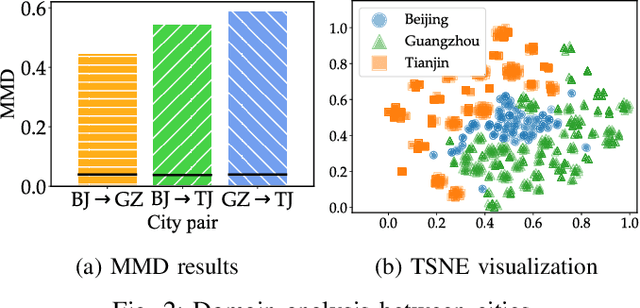
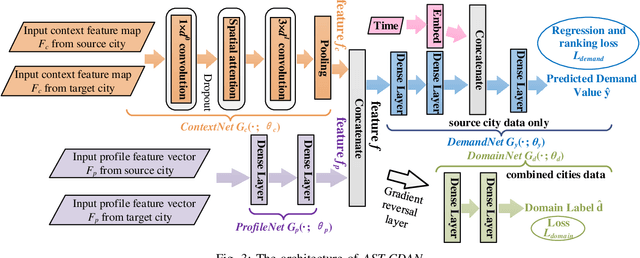
For a new city that is committed to promoting Electric Vehicles (EVs), it is significant to plan the public charging infrastructure where charging demands are high. However, it is difficult to predict charging demands before the actual deployment of EV chargers for lack of operational data, resulting in a deadlock. A direct idea is to leverage the urban transfer learning paradigm to learn the knowledge from a source city, then exploit it to predict charging demands, and meanwhile determine locations and amounts of slow/fast chargers for charging stations in the target city. However, the demand prediction and charger planning depend on each other, and it is required to re-train the prediction model to eliminate the negative transfer between cities for each varied charger plan, leading to the unacceptable time complexity. To this end, we propose the concept and an effective solution of Simultaneous Demand Prediction And Planning (SPAP): discriminative features are extracted from multi-source data, and fed into an Attention-based Spatial-Temporal City Domain Adaptation Network (AST-CDAN) for cross-city demand prediction; a novel Transfer Iterative Optimization (TIO) algorithm is designed for charger planning by iteratively utilizing AST-CDAN and a charger plan fine-tuning algorithm. Extensive experiments on real-world datasets collected from three cities in China validate the effectiveness and efficiency of SPAP. Specially, SPAP improves at most 72.5% revenue compared with the real-world charger deployment.
AI and conventional methods for UCT projection data estimation
Aug 17, 2021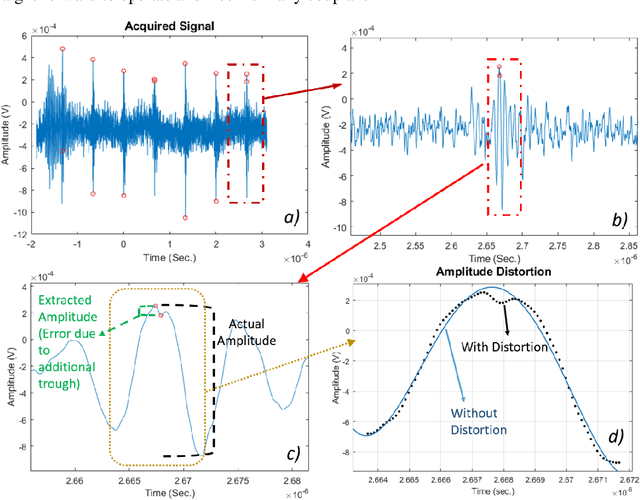
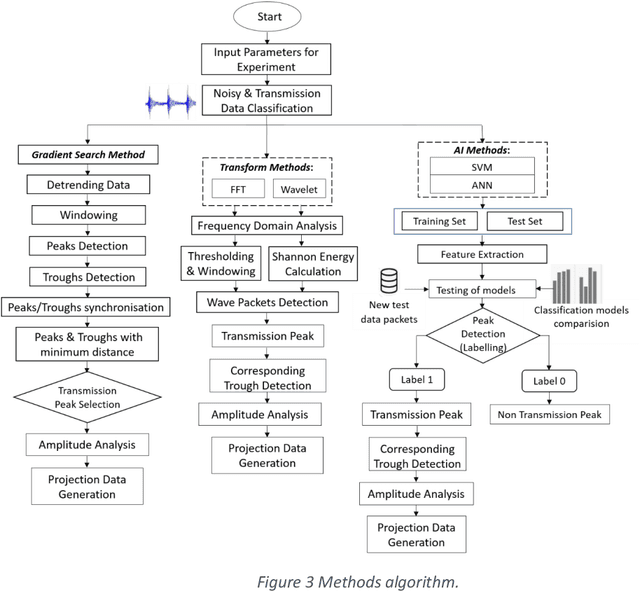
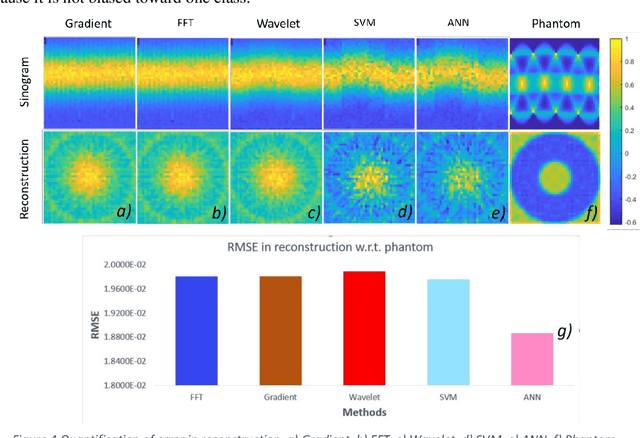
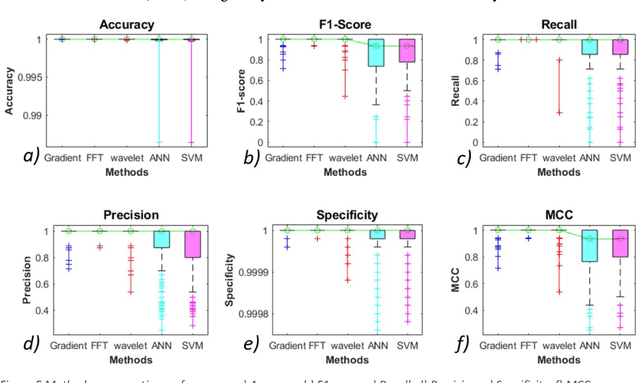
A 2D Compact ultrasound computerized tomography (UCT) system is developed. Fully automatic post processing tools involving signal and image processing are developed as well. Square of the amplitude values are used in transmission mode with natural 1.5 MHz frequency and rise time 10.4 ns and fall time 8.4 ns and duty cycle of 4.32%. Highest peak to corresponding trough values are considered as transmitting wave between transducers in direct line talk. Sensitivity analysis of methods to extract peak to corresponding trough per transducer are discussed in this paper. Total five methods are tested. These methods are taken from broad categories: (a) Conventional and (b) Artificial Intelligence (AI) based methods. Conventional methods, namely: (a) simple gradient based peak detection, (b) Fourier based, (c) wavelet transform are compared with AI based methods: (a) support vector machine (SVM), (b) artificial neural network (ANN). Classification step was performed as well to discard the signal which does not has contribution of transmission wave. It is found that conventional methods have better performance. Reconstruction error, accuracy, F-Score, recall, precision, specificity and MCC for 40 x 40 data 1600 data files are measured. Each data file contains 50,002 data point. Ten such data files are used for training the Neural Network. Each data file has 7/8 wave packets and each packet corresponds to one transmission amplitude data. Reconstruction error is found to be minimum for ANN method. Other performance indices show that FFT method is processing the UCT signal with best recovery.
Short Term Prediction of Parking Area states Using Real Time Data and Machine Learning Techniques
Nov 29, 2019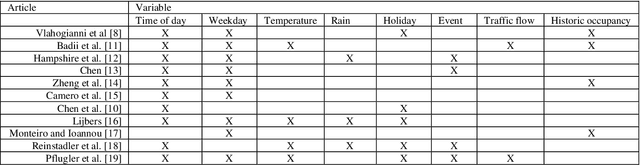
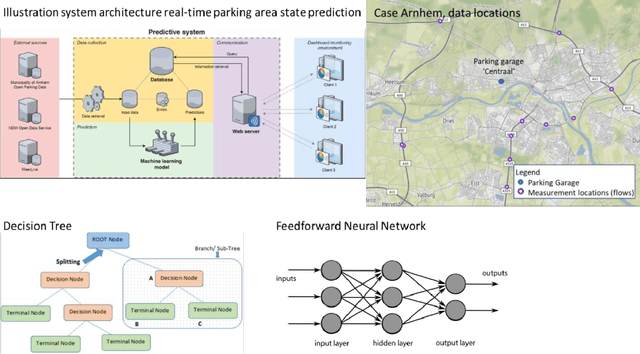
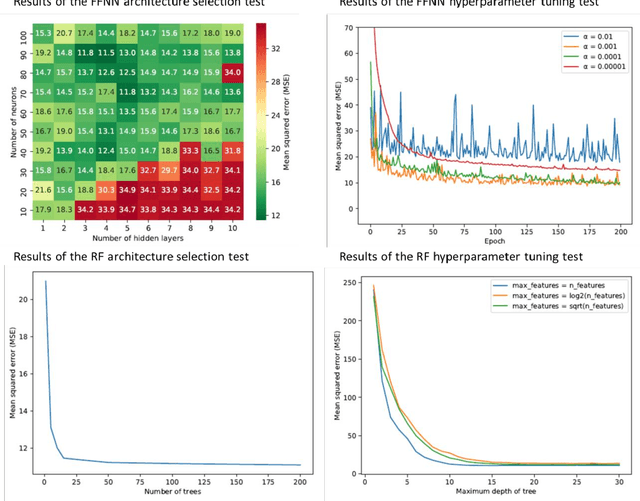
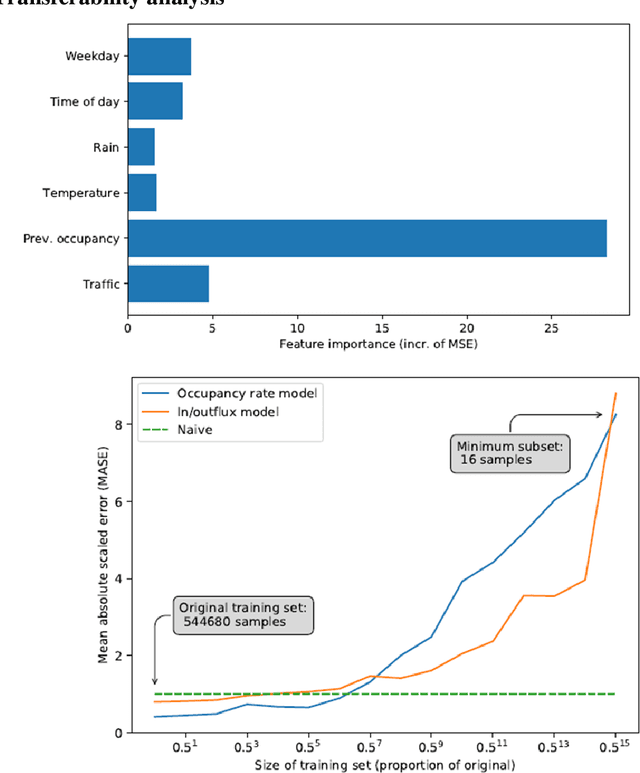
Public road authorities and private mobility service providers need information derived from the current and predicted traffic states to act upon the daily urban system and its spatial and temporal dynamics. In this research, a real-time parking area state (occupancy, in- and outflux) prediction model (up to 60 minutes ahead) has been developed using publicly available historic and real time data sources. Based on a case study in a real-life scenario in the city of Arnhem, a Neural Network-based approach outperforms a Random Forest-based one on all assessed performance measures, although the differences are small. Both are outperforming a naive seasonal random walk model. Although the performance degrades with increasing prediction horizon, the model shows a performance gain of over 150% at a prediction horizon of 60 minutes compared with the naive model. Furthermore, it is shown that predicting the in- and outflux is a far more difficult task (i.e. performance gains of 30%) which needs more training data, not based exclusively on occupancy rate. However, the performance of predicting in- and outflux is less sensitive to the prediction horizon. In addition, it is shown that real-time information of current occupancy rate is the independent variable with the highest contribution to the performance, although time, traffic flow and weather variables also deliver a significant contribution. During real-time deployment, the model performs three times better than the naive model on average. As a result, it can provide valuable information for proactive traffic management as well as mobility service providers.
Clustering Activity-Travel Behavior Time Series using Topological Data Analysis
Jul 17, 2019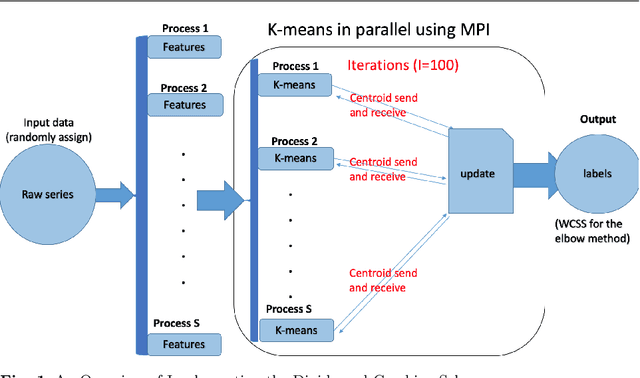
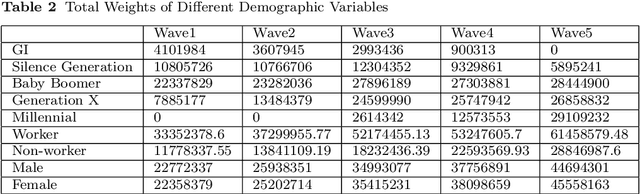
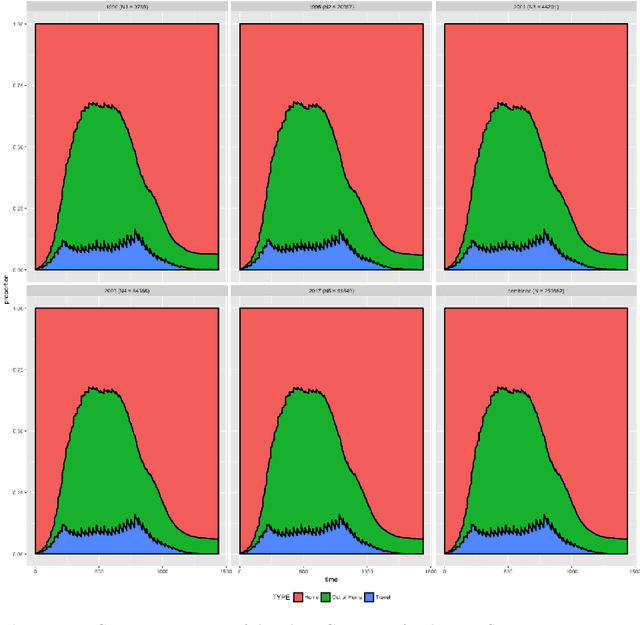
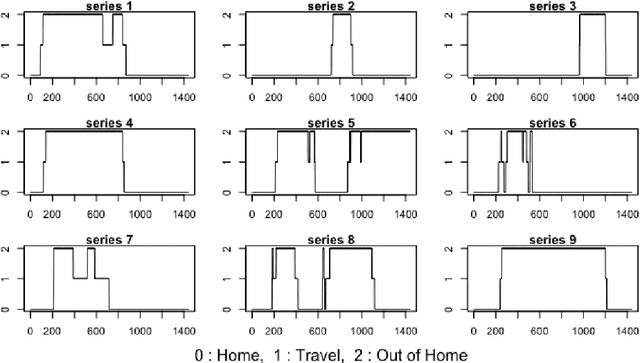
Over the last few years, traffic data has been exploding and the transportation discipline has entered the era of big data. It brings out new opportunities for doing data-driven analysis, but it also challenges traditional analytic methods. This paper proposes a new Divide and Combine based approach to do K means clustering on activity-travel behavior time series using features that are derived using tools in Time Series Analysis and Topological Data Analysis. Clustering data from five waves of the National Household Travel Survey ranging from 1990 to 2017 suggests that activity-travel patterns of individuals over the last three decades can be grouped into three clusters. Results also provide evidence in support of recent claims about differences in activity-travel patterns of different survey cohorts. The proposed method is generally applicable and is not limited only to activity-travel behavior analysis in transportation studies. Driving behavior, travel mode choice, household vehicle ownership, when being characterized as categorical time series, can all be analyzed using the proposed method.