 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deceptive Decision-Making Under Uncertainty
Sep 14, 2021
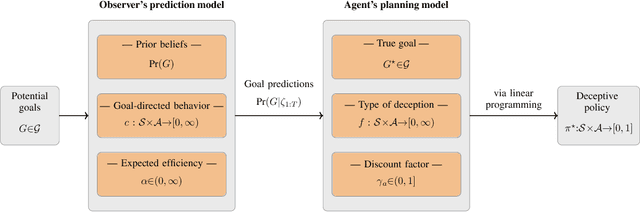
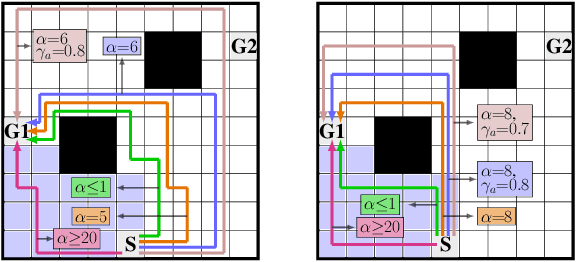
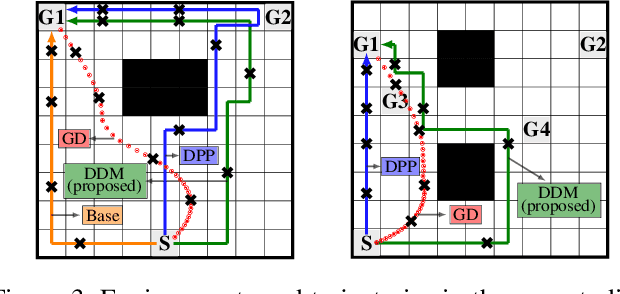
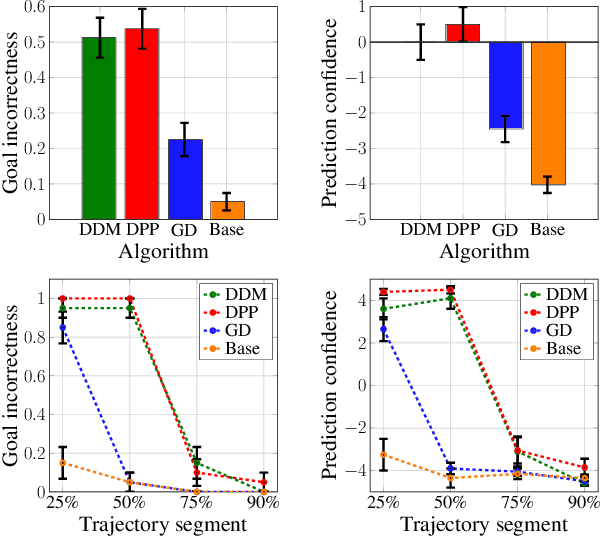
We study the design of autonomous agents that are capable of deceiving outside observers about their intentions while carrying out tasks in stochastic, complex environments. By modeling the agent's behavior as a Markov decision process, we consider a setting where the agent aims to reach one of multiple potential goals while deceiving outside observers about its true goal. We propose a novel approach to model observer predictions based on the principle of maximum entropy and to efficiently generate deceptive strategies via linear programming. The proposed approach enables the agent to exhibit a variety of tunable deceptive behaviors while ensuring the satisfaction of probabilistic constraints on the behavior. We evaluate the performance of the proposed approach via comparative user studies and present a case study on the streets of Manhattan, New York, using real travel time distributions.
Accelerating Genetic Programming using GPUs
Oct 15, 2021
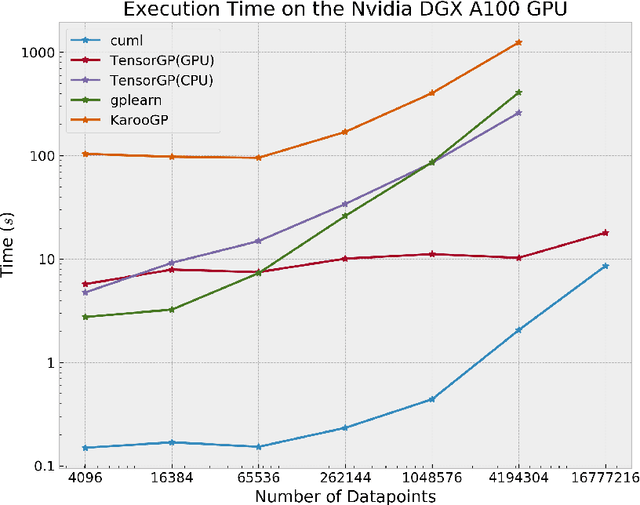
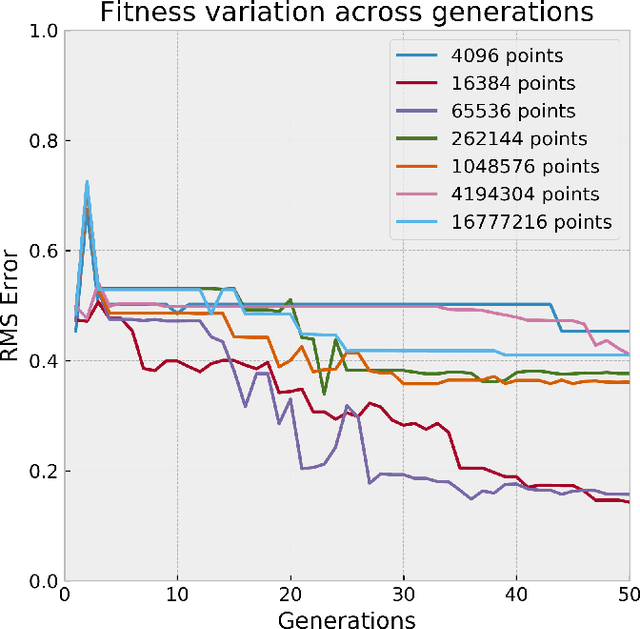
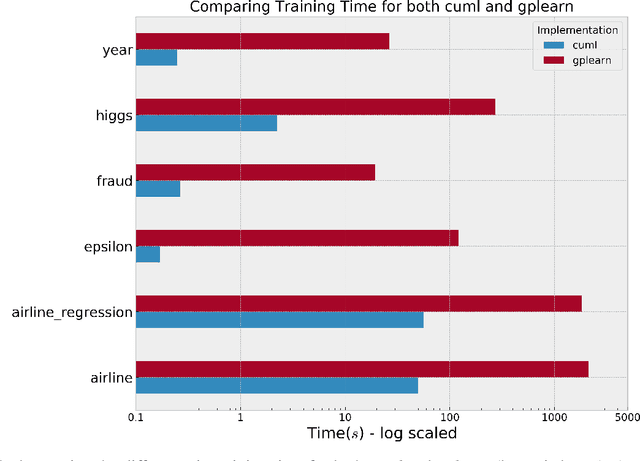
Genetic Programming (GP), an evolutionary learning technique, has multiple applications in machine learning such as curve fitting, data modelling, feature selection, classification etc. GP has several inherent parallel steps, making it an ideal candidate for GPU based parallelization. This paper describes a GPU accelerated stack-based variant of the generational GP algorithm which can be used for symbolic regression and binary classification. The selection and evaluation steps of the generational GP algorithm are parallelized using CUDA. We introduce representing candidate solution expressions as prefix lists, which enables evaluation using a fixed-length stack in GPU memory. CUDA based matrix vector operations are also used for computation of the fitness of population programs. We evaluate our algorithm on synthetic datasets for the Pagie Polynomial (ranging in size from $4096$ to $16$ million points), profiling training times of our algorithm with other standard symbolic regression libraries viz. gplearn, TensorGP and KarooGP. In addition, using $6$ large-scale regression and classification datasets usually used for comparing gradient boosting algorithms, we run performance benchmarks on our algorithm and gplearn, profiling the training time, test accuracy, and loss. On an NVIDIA DGX-A100 GPU, our algorithm outperforms all the previously listed frameworks, and in particular, achieves average speedups of $119\times$ and $40\times$ against gplearn on the synthetic and large scale datasets respectively.
Fast Uncertainty Quantification for Active Graph SLAM
Oct 04, 2021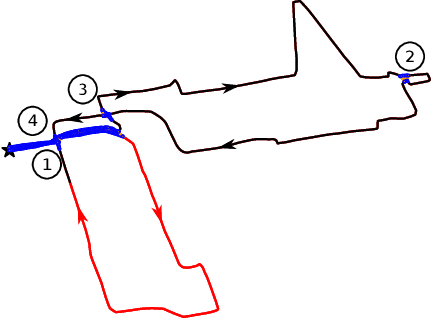
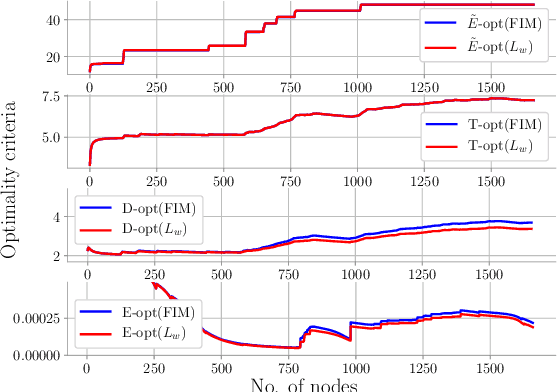
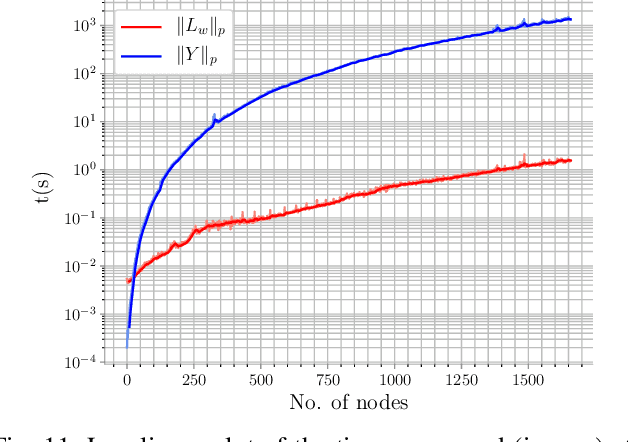
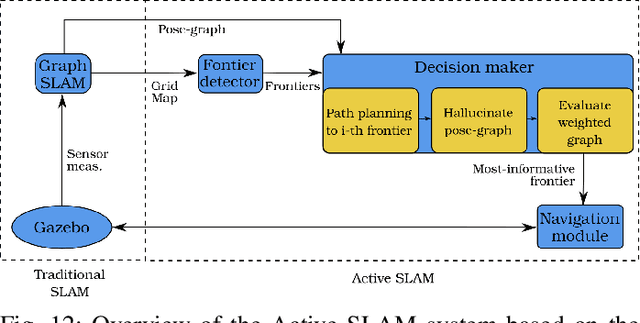
Quantifying uncertainty is a key stage in autonomous robotic exploration, since it allows to identify the most informative actions to execute. However, dealing with full Fisher Information matrices (FIM) is computationally heavy and may become intractable for online systems. In this work, we study the paradigm of Active graph SLAM formulated over $\textit{SE(n)}$, and propose a general relationship between the full FIM and the Laplacian matrix of the underlying pose-graph. Therefore, the optimal set of actions can be estimated by maximizing optimality criteria of the weighted Laplacian instead of that of the FIM. Experimental validation proves our method leads to equivalent results in a fraction of the time traditional methods require. Based on the former, we present an online Active graph SLAM system capable of selecting D-optimal actions and that outperforms other state-of-the-art methods that rely on slower computations. Also, we propose the use of such indices as stopping criterion, making our system capable of autonomously determining when the exploration strategy is no longer adding information to the graph SLAM algorithm and it should be either changed or terminated.
An AI-based Approach for Tracing Content Requirements in Financial Documents
Oct 28, 2021

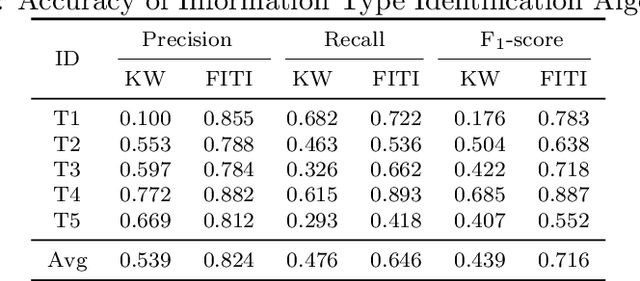
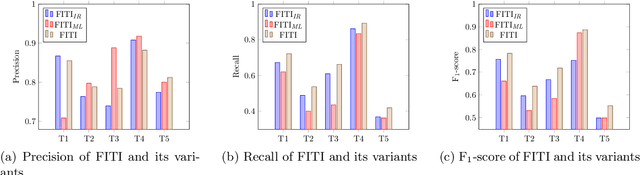
The completeness (in terms of content) of financial documents is a fundamental requirement for investment funds. To ensure completeness, financial regulators spend a huge amount of time for carefully checking every financial document based on the relevant content requirements, which prescribe the information types to be included in financial documents (e.g., the description of shares' issue conditions). Although several techniques have been proposed to automatically detect certain types of information in documents in various application domains, they provide limited support to help regulators automatically identify the text chunks related to financial information types, due to the complexity of financial documents and the diversity of the sentences characterizing an information type. In this paper, we propose FITI, an artificial intelligence (AI)-based method for tracing content requirements in financial documents. Given a new financial document, FITI selects a set of candidate sentences for efficient information type identification. Then, FITI uses a combination of rule-based and data-centric approaches, by leveraging information retrieval (IR) and machine learning (ML) techniques that analyze the words, sentences, and contexts related to an information type, to rank candidate sentences. Finally, using a list of indicator phrases related to each information type, a heuristic-based selector, which considers both the sentence ranking and the domain-specific phrases, determines a list of sentences corresponding to each information type. We evaluated FITI by assessing its effectiveness in tracing financial content requirements in 100 financial documents. Experimental results show that FITI provides accurate identification with average precision and recall values of 0.824 and 0.646, respectively. Furthermore, FITI can detect about 80% of missing information types in financial documents.
Embedding time expressions for deep temporal ordering models
Jun 19, 2019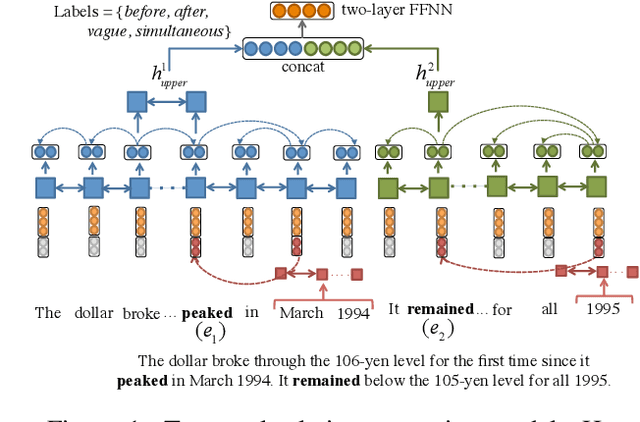
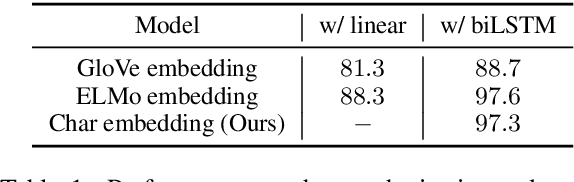
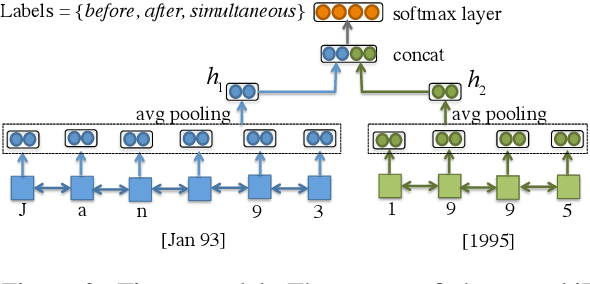
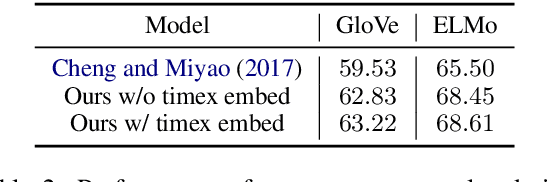
Data-driven models have demonstrated state-of-the-art performance in inferring the temporal ordering of events in text. However, these models often overlook explicit temporal signals, such as dates and time windows. Rule-based methods can be used to identify the temporal links between these time expressions (timexes), but they fail to capture timexes' interactions with events and are hard to integrate with the distributed representations of neural net models. In this paper, we introduce a framework to infuse temporal awareness into such models by learning a pre-trained model to embed timexes. We generate synthetic data consisting of pairs of timexes, then train a character LSTM to learn embeddings and classify the timexes' temporal relation. We evaluate the utility of these embeddings in the context of a strong neural model for event temporal ordering, and show a small increase in performance on the MATRES dataset and more substantial gains on an automatically collected dataset with more frequent event-timex interactions.
Robust Event Classification Using Imperfect Real-world PMU Data
Oct 19, 2021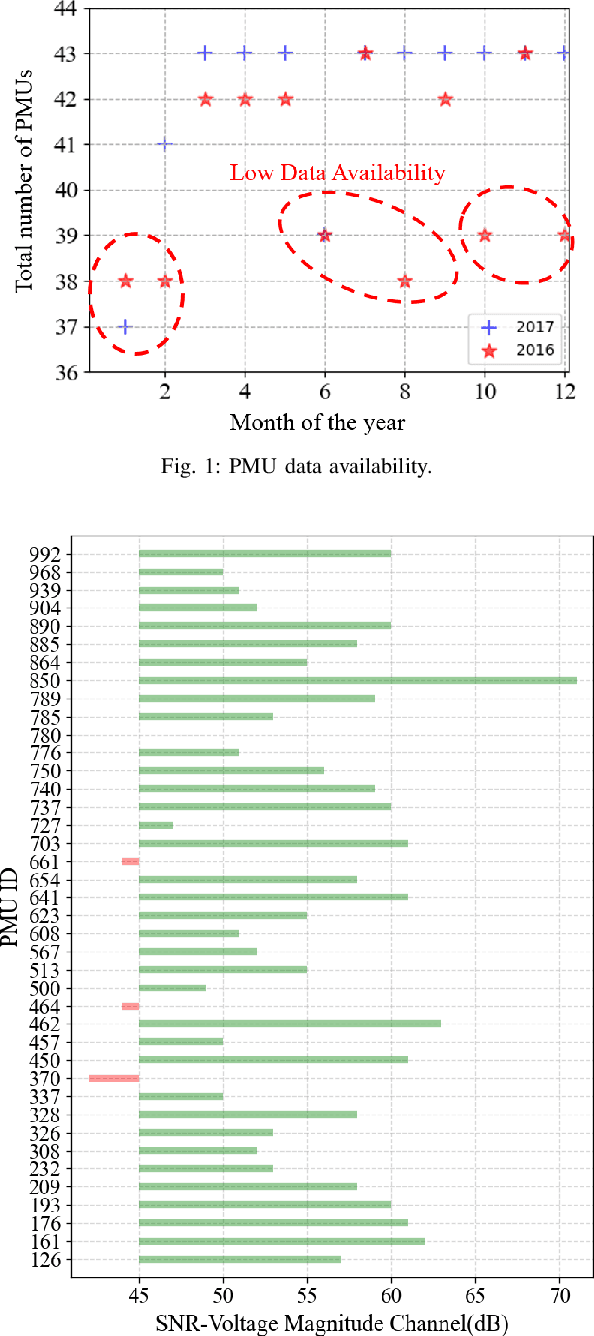
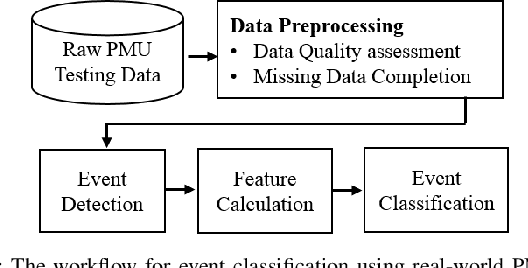
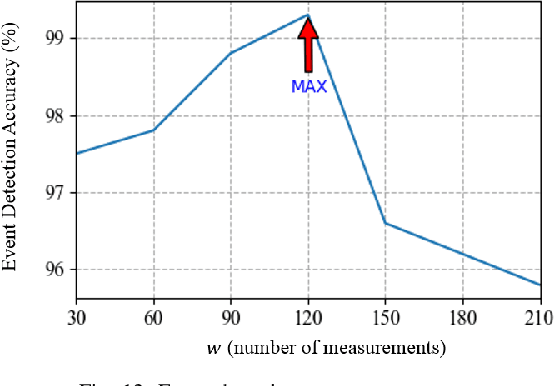
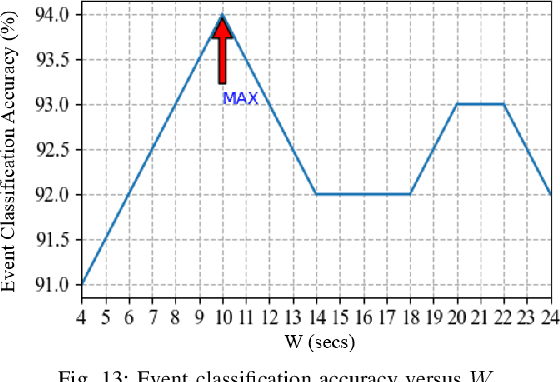
This paper studies robust event classification using imperfect real-world phasor measurement unit (PMU) data. By analyzing the real-world PMU data, we find it is challenging to directly use this dataset for event classifiers due to the low data quality observed in PMU measurements and event logs. To address these challenges, we develop a novel machine learning framework for training robust event classifiers, which consists of three main steps: data preprocessing, fine-grained event data extraction, and feature engineering. Specifically, the data preprocessing step addresses the data quality issues of PMU measurements (e.g., bad data and missing data); in the fine-grained event data extraction step, a model-free event detection method is developed to accurately localize the events from the inaccurate event timestamps in the event logs; and the feature engineering step constructs the event features based on the patterns of different event types, in order to improve the performance and the interpretability of the event classifiers. Based on the proposed framework, we develop a workflow for event classification using the real-world PMU data streaming into the system in real-time. Using the proposed framework, robust event classifiers can be efficiently trained based on many off-the-shelf lightweight machine learning models. Numerical experiments using the real-world dataset from the Western Interconnection of the U.S power transmission grid show that the event classifiers trained under the proposed framework can achieve high classification accuracy while being robust against low-quality data.
Graph Neural Netwrok with Interaction Pattern for Group Recommendation
Sep 21, 2021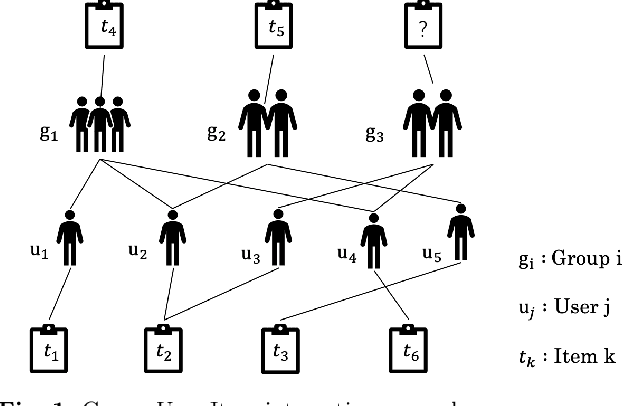

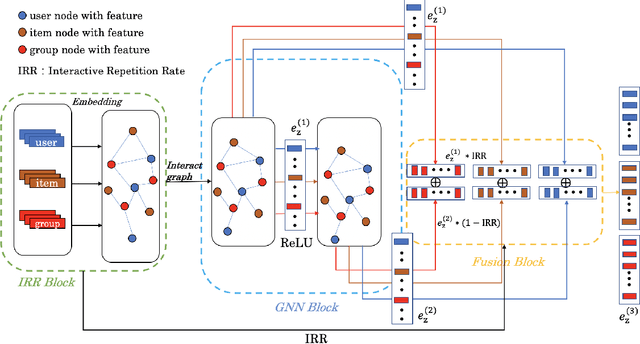
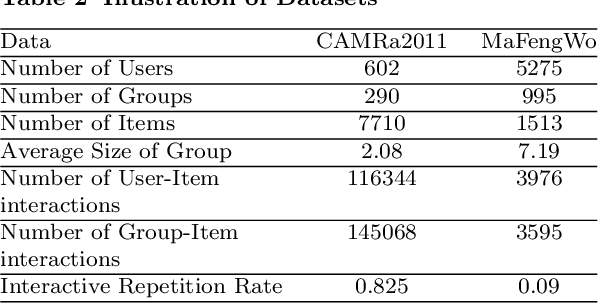
With the development of social platforms, people are more and more inclined to combine into groups to participate in some activities, so group recommendation has gradually become a problem worthy of research. For group recommendation, an important issue is how to obtain the characteristic representation of the group and the item through personal interaction history, and obtain the group's preference for the item. For this problem, we proposed the model GIP4GR (Graph Neural Network with Interaction Pattern For Group Recommendation). Specifically, our model use the graph neural network framework with powerful representation capabilities to represent the interaction between group-user-items in the topological structure of the graph, and at the same time, analyze the interaction pattern of the graph to adjust the feature output of the graph neural network, the feature representations of groups, and items are obtained to calculate the group's preference for items. We conducted a lot of experiments on two real-world datasets to illustrate the superior performance of our model.
Fully convolutional networks for structural health monitoring through multivariate time series classification
Feb 12, 2020
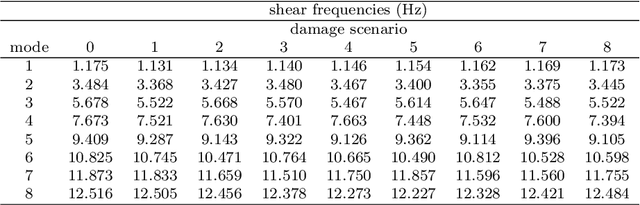
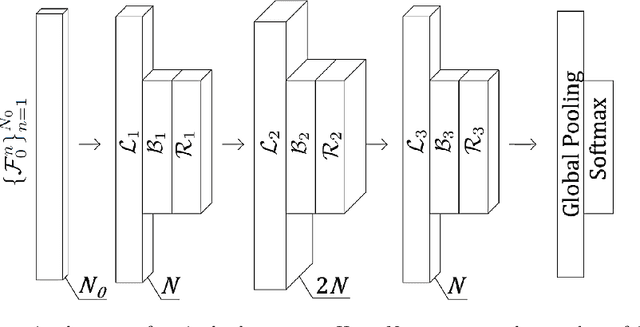

We propose a novel approach to Structural Health Monitoring (SHM), aiming at the automatic identification of damage-sensitive features from data acquired through pervasive sensor systems. Damage detection and localization are formulated as classification problems, and tackled through Fully Convolutional Networks (FCNs). A supervised training of the proposed network architecture is performed on data extracted from numerical simulations of a physics-based model (playing the role of digital twin of the structure to be monitored) accounting for different damage scenarios. By relying on this simplified model of the structure, several load conditions are considered during the training phase of the FCN, whose architecture has been designed to deal with time series of different length. The training of the neural network is done before the monitoring system starts operating, thus enabling a real time damage classification. The numerical performances of the proposed strategy are assessed on a numerical benchmark case consisting of an eight-story shear building subjected to two load types, one of which modeling random vibrations due to low-energy seismicity. Measurement noise has been added to the responses of the structure to mimic the outputs of a real monitoring system. Extremely good classification capacities are shown: among the nine possible alternatives (represented by the healthy state and by a damage at any floor), damage is correctly classified in up to 95% of cases, thus showing the strong potential of the proposed approach in view of the application to real-life cases.
A Suitable Hierarchical Framework with Arbitrary Task Dimensions under Unilateral Constraints for physical Human Robot Interaction
Sep 10, 2021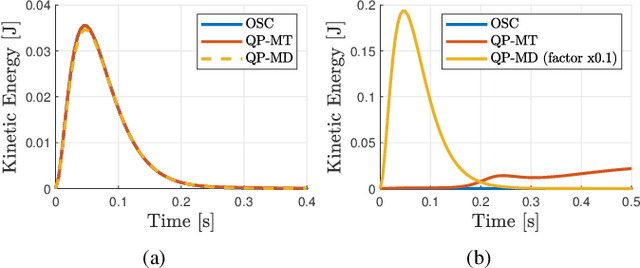
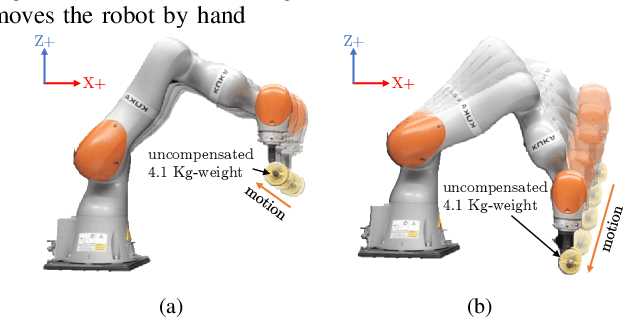
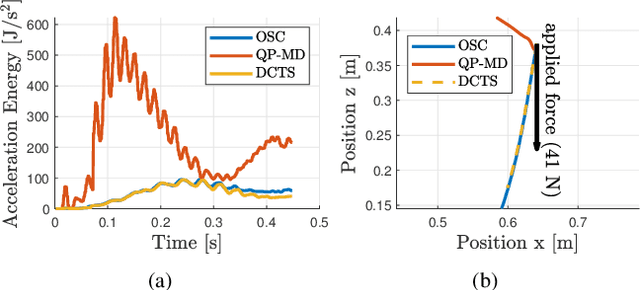
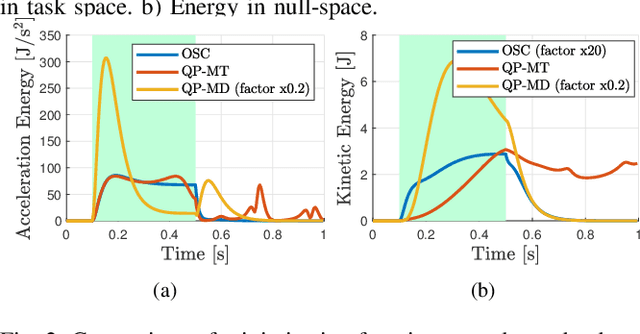
In the last years, several hierarchical frameworks have been proposed to deal with highly-redundant robotic systems. Some of that systems are expected to perform multiple tasks and physically to interact with the environment. However, none of the proposed frameworks is able to manage multiple tasks with arbitrary task dimensions, while respecting unilateral constraints at position, velocity, acceleration and force level, and at the same time, to react intuitively to external forces. This work proposes a framework that addresses this problem. The framework is tested in simulation and on a real robot. The experiments on the redundant collaborative industrial robot (KUKA LBR iiwa) demonstrate the advantage of the framework compared to state-of-the-art approaches. The framework reacts intuitively to external forces and is able to limit joint positions, velocities, accelerations and forces.
Nonuniform Sampling Rate Conversion: An Efficient Approach
May 14, 2021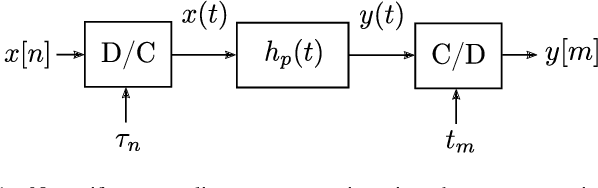
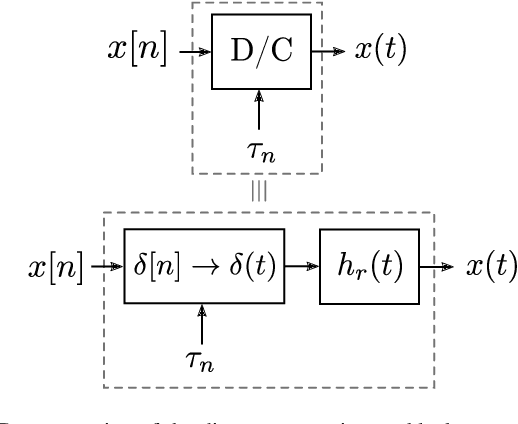
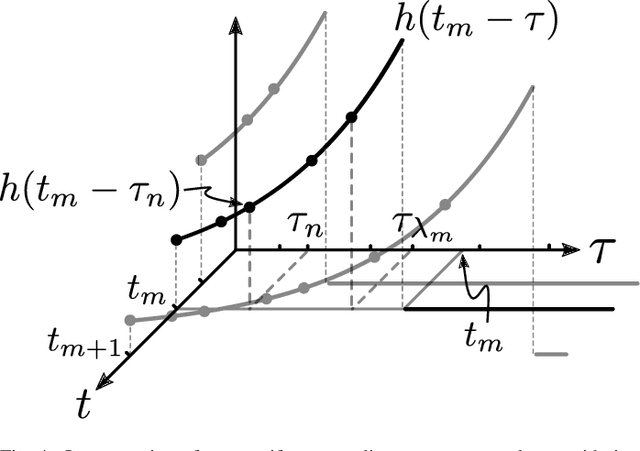
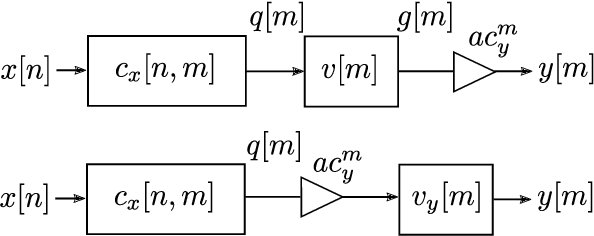
We present a discrete-time algorithm for nonuniform sampling rate conversion that presents low computational complexity and memory requirements. It generalizes arbitrary sampling rate conversion by accommodating time-varying conversion ratios, i.e., it can efficiently adapt to instantaneous changes of the input and output sampling rates. This approach is based on appropriately factorizing the time-varying discrete-time filter used for the conversion. Common filters that satisfy this factorization property are those where the underlying continuous-time filter consists of linear combinations of exponentials, e.g., those described by linear constant-coefficient differential equations. This factorization separates the computation into two parts: one consisting of a factor solely depending on the output sampling instants and the other consists of a summation -- that can be computed recursively -- whose terms depend solely on the input sampling instants and its number of terms is given by a relationship between input and output sampling instants. Thus, nonuniform sampling rates can be accommodated by updating the factors involved and adjusting the number of terms added. When the impulse response consists of exponentials, computing the factors can be done recursively in an efficient manner.