 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep speech inpainting of time-frequency masks
Oct 22, 2019
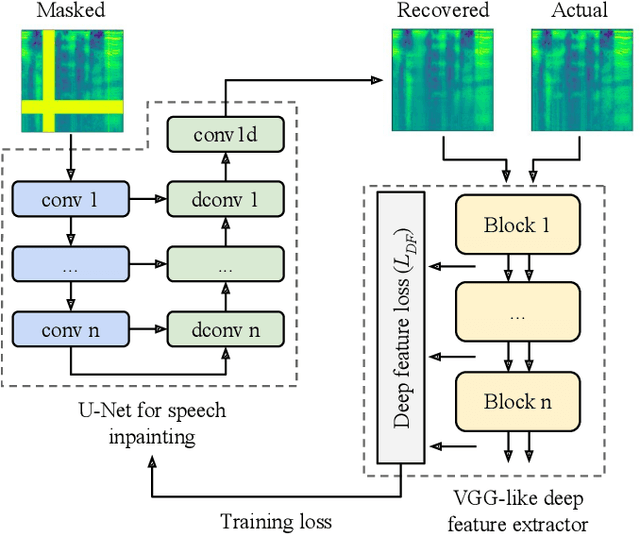
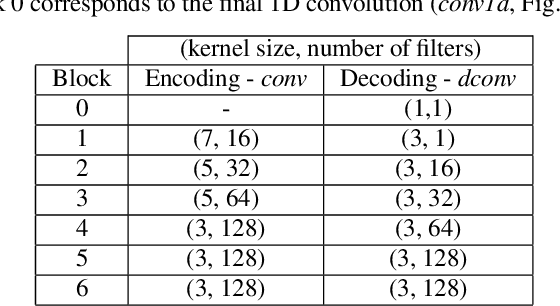
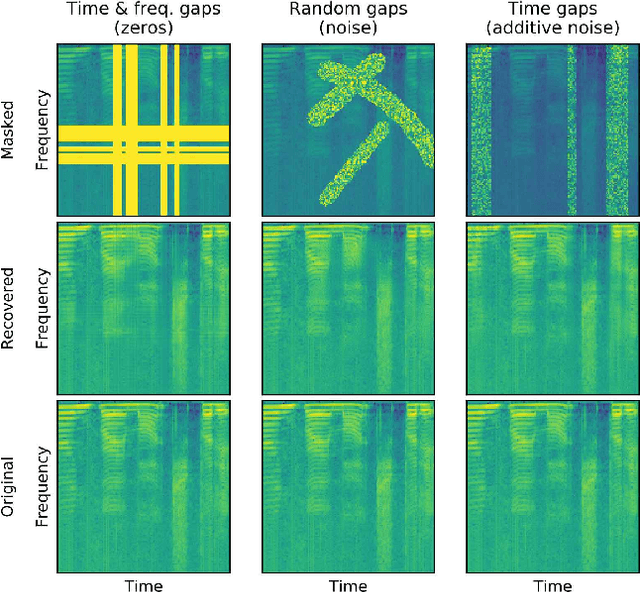
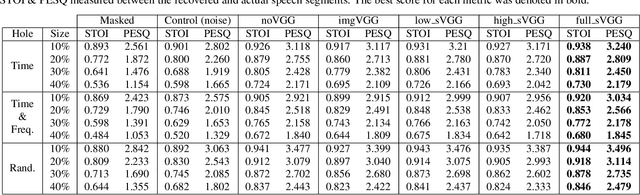
In particularly noisy environments, transient loud intrusions can completely overpower parts of the speech signal, leading to an inevitable loss of information. Recent algorithms for noise suppression often yield impressive results but tend to struggle when the signal-to-noise ratio (SNR) of the mixture is low or when parts of the signal are missing. To address these issues, here we introduce an end-to-end framework for the retrieval of missing or severely distorted parts of time-frequency representation of speech, from the short-term context, thus speech inpainting. The framework is based on a convolutional U-Net trained via deep feature losses, obtained through speechVGG, a deep speech feature extractor pre-trained on the word classification task. Our evaluation results demonstrate that the proposed framework is effective at recovering large portions of missing or distorted parts of speech. Specifically, it yields notable improvements in STOI & PESQ objective metrics, as assessed using the LibriSpeech dataset.
Graph Neural Netwrok with Interaction Pattern for Group Recommendation
Sep 21, 2021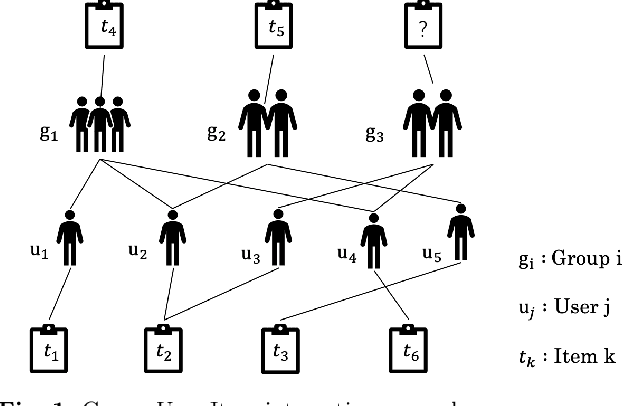

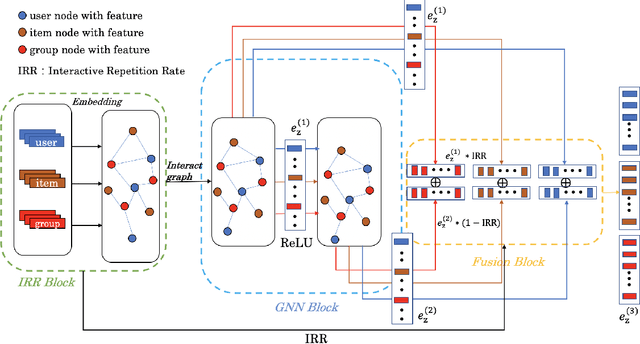
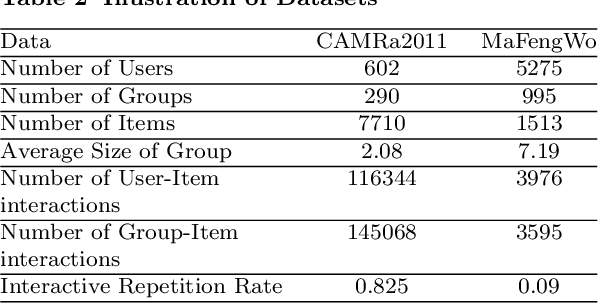
With the development of social platforms, people are more and more inclined to combine into groups to participate in some activities, so group recommendation has gradually become a problem worthy of research. For group recommendation, an important issue is how to obtain the characteristic representation of the group and the item through personal interaction history, and obtain the group's preference for the item. For this problem, we proposed the model GIP4GR (Graph Neural Network with Interaction Pattern For Group Recommendation). Specifically, our model use the graph neural network framework with powerful representation capabilities to represent the interaction between group-user-items in the topological structure of the graph, and at the same time, analyze the interaction pattern of the graph to adjust the feature output of the graph neural network, the feature representations of groups, and items are obtained to calculate the group's preference for items. We conducted a lot of experiments on two real-world datasets to illustrate the superior performance of our model.
EVARS-GPR: EVent-triggered Augmented Refitting of Gaussian Process Regression for Seasonal Data
Jul 06, 2021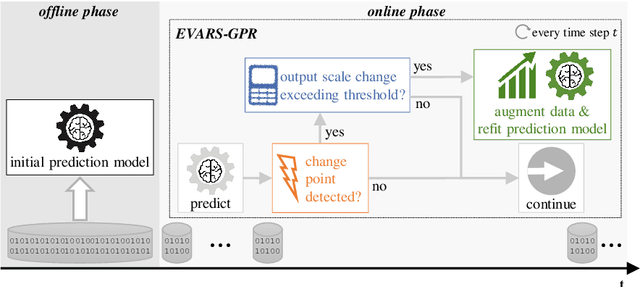
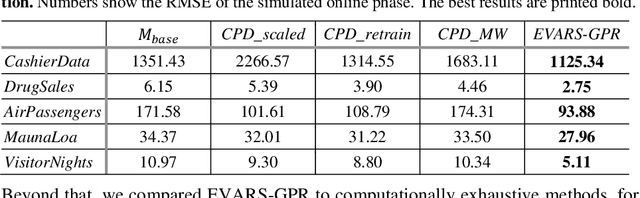
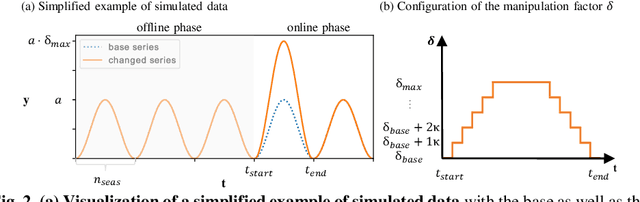
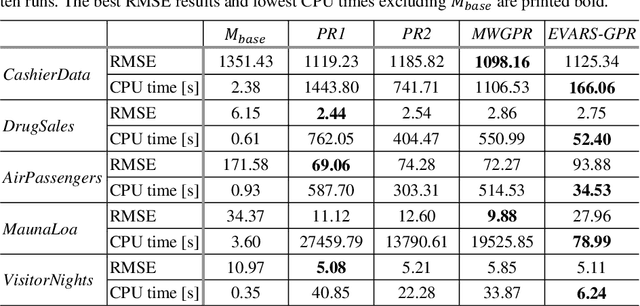
Time series forecasting is a growing domain with diverse applications. However, changes of the system behavior over time due to internal or external influences are challenging. Therefore, predictions of a previously learned fore-casting model might not be useful anymore. In this paper, we present EVent-triggered Augmented Refitting of Gaussian Process Regression for Seasonal Data (EVARS-GPR), a novel online algorithm that is able to handle sudden shifts in the target variable scale of seasonal data. For this purpose, EVARS-GPR com-bines online change point detection with a refitting of the prediction model using data augmentation for samples prior to a change point. Our experiments on sim-ulated data show that EVARS-GPR is applicable for a wide range of output scale changes. EVARS-GPR has on average a 20.8 % lower RMSE on different real-world datasets compared to methods with a similar computational resource con-sumption. Furthermore, we show that our algorithm leads to a six-fold reduction of the averaged runtime in relation to all comparison partners with a periodical refitting strategy. In summary, we present a computationally efficient online fore-casting algorithm for seasonal time series with changes of the target variable scale and demonstrate its functionality on simulated as well as real-world data. All code is publicly available on GitHub: https://github.com/grimmlab/evars-gpr.
A Reinforcement Learning Framework for Time-Dependent Causal Effects Evaluation in A/B Testing
Feb 10, 2020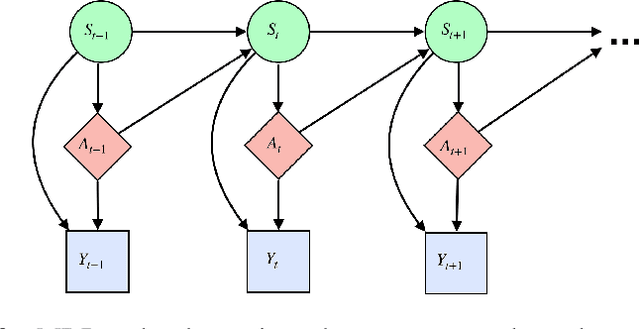
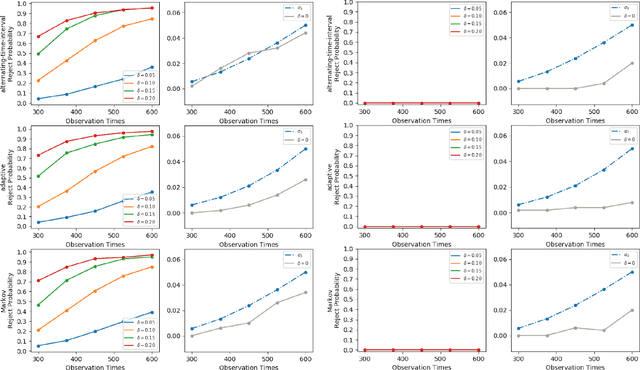
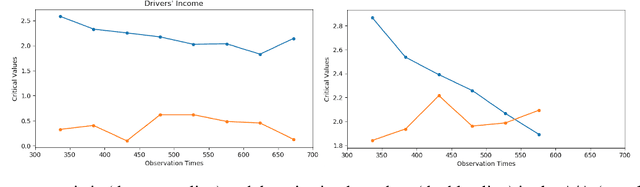
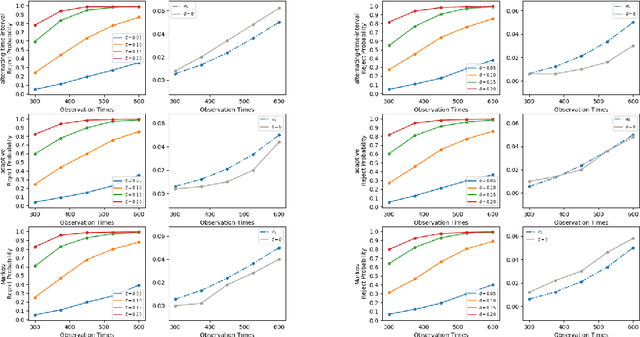
A/B testing, or online experiment is a standard business strategy to compare a new product with an old one in pharmaceutical, technological, and traditional industries. Major challenges arise in online experiments where there is only one unit that receives a sequence of treatments over time. In those experiments, the treatment at a given time impacts current outcome as well as future outcomes. The aim of this paper is to introduce a reinforcement learning framework for carrying A/B testing, while characterizing the long-term treatment effects. Our proposed testing procedure allows for sequential monitoring and online updating, so it is generally applicable to a variety of treatment designs in different industries. In addition, we systematically investigate the theoretical properties (e.g., asymptotic distribution and power) of our testing procedure. Finally, we apply our framework to both synthetic datasets and a real-world data example obtained from a ride-sharing company to illustrate its usefulness.
Predicting Solar Flares with Remote Sensing and Machine Learning
Oct 14, 2021
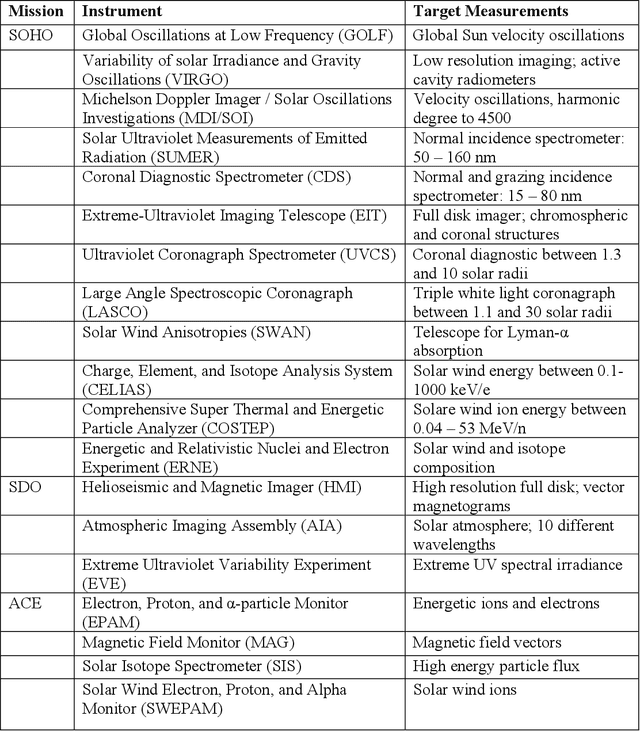
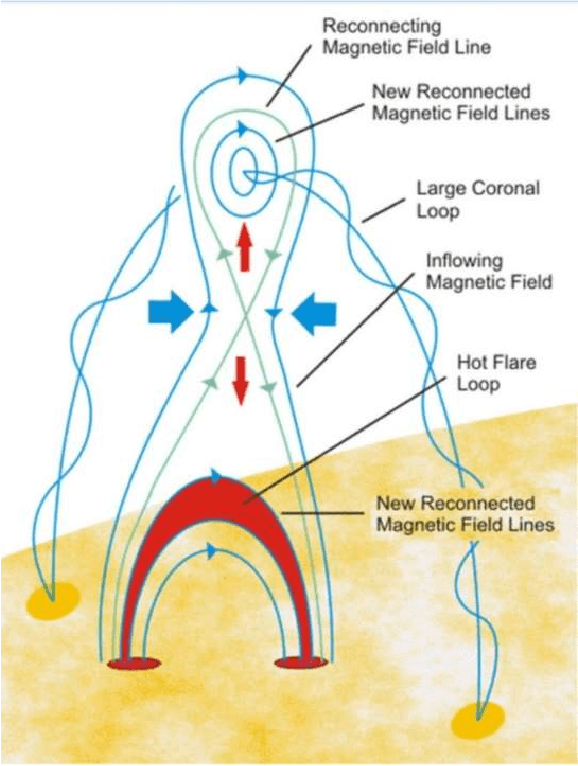

High energy solar flares and coronal mass ejections have the potential to destroy Earth's ground and satellite infrastructures, causing trillions of dollars in damage and mass human suffering. Destruction of these critical systems would disable power grids and satellites, crippling communications and transportation. This would lead to food shortages and an inability to respond to emergencies. A solution to this impending problem is proposed herein using satellites in solar orbit that continuously monitor the Sun, use artificial intelligence and machine learning to calculate the probability of massive solar explosions from this sensed data, and then signal defense mechanisms that will mitigate the threat. With modern technology there may be only safeguards that can be implemented with enough warning, which is why the best algorithm must be identified and continuously trained with existing and new data to maximize true positive rates while minimizing false negatives. This paper conducts a survey of current machine learning models using open source solar flare prediction data. The rise of edge computing allows machine learning hardware to be placed on the same satellites as the sensor arrays, saving critical time by not having to transmit remote sensing data across the vast distances of space. A system of systems approach will allow enough warning for safety measures to be put into place mitigating the risk of disaster.
The Role of Lookahead and Approximate Policy Evaluation in Policy Iteration with Linear Value Function Approximation
Sep 28, 2021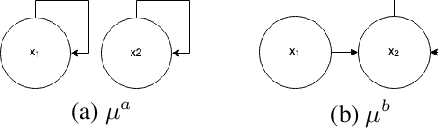
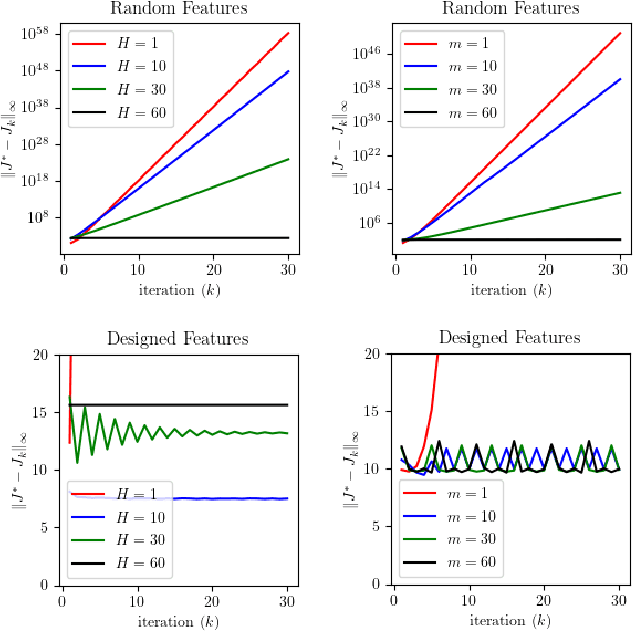
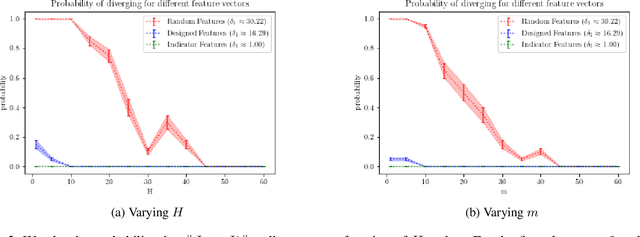
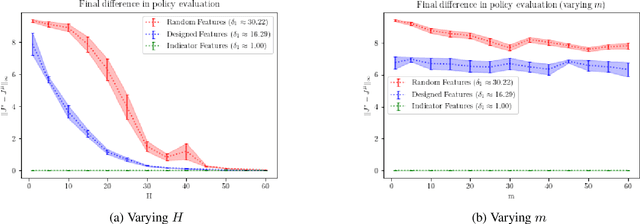
When the sizes of the state and action spaces are large, solving MDPs can be computationally prohibitive even if the probability transition matrix is known. So in practice, a number of techniques are used to approximately solve the dynamic programming problem, including lookahead, approximate policy evaluation using an m-step return, and function approximation. In a recent paper, (Efroni et al. 2019) studied the impact of lookahead on the convergence rate of approximate dynamic programming. In this paper, we show that these convergence results change dramatically when function approximation is used in conjunction with lookout and approximate policy evaluation using an m-step return. Specifically, we show that when linear function approximation is used to represent the value function, a certain minimum amount of lookahead and multi-step return is needed for the algorithm to even converge. And when this condition is met, we characterize the finite-time performance of policies obtained using such approximate policy iteration. Our results are presented for two different procedures to compute the function approximation: linear least-squares regression and gradient descent.
A Suitable Hierarchical Framework with Arbitrary Task Dimensions under Unilateral Constraints for physical Human Robot Interaction
Sep 10, 2021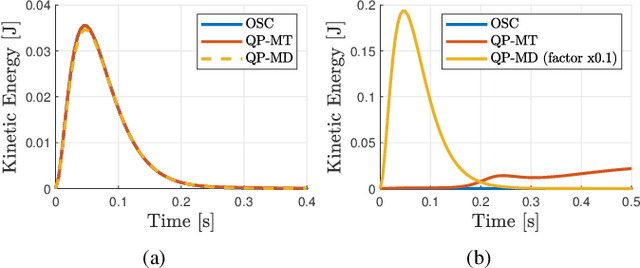
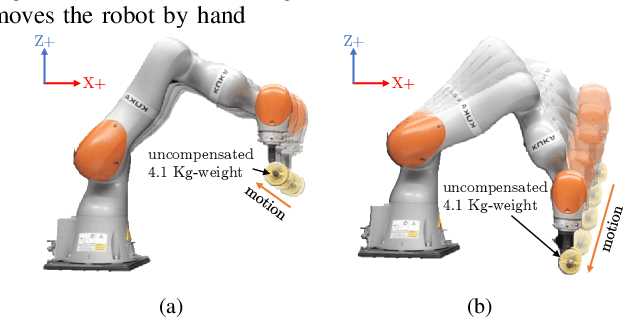
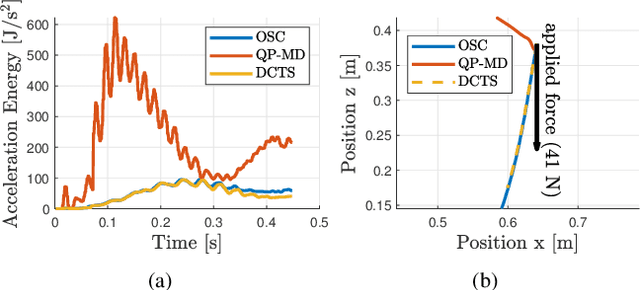
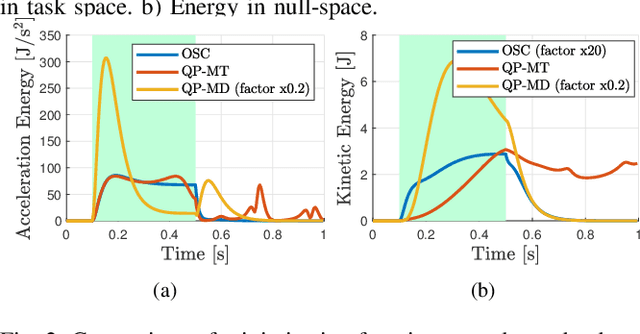
In the last years, several hierarchical frameworks have been proposed to deal with highly-redundant robotic systems. Some of that systems are expected to perform multiple tasks and physically to interact with the environment. However, none of the proposed frameworks is able to manage multiple tasks with arbitrary task dimensions, while respecting unilateral constraints at position, velocity, acceleration and force level, and at the same time, to react intuitively to external forces. This work proposes a framework that addresses this problem. The framework is tested in simulation and on a real robot. The experiments on the redundant collaborative industrial robot (KUKA LBR iiwa) demonstrate the advantage of the framework compared to state-of-the-art approaches. The framework reacts intuitively to external forces and is able to limit joint positions, velocities, accelerations and forces.
Regulating Greed Over Time
Dec 04, 2017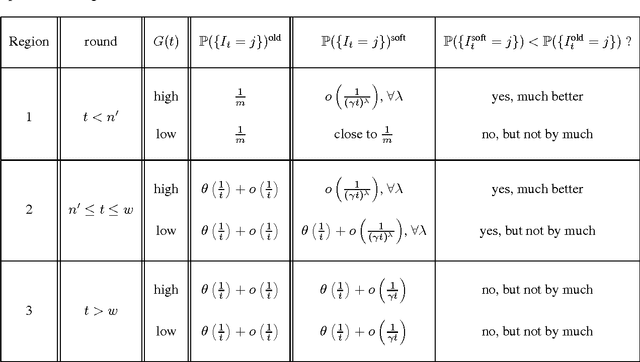
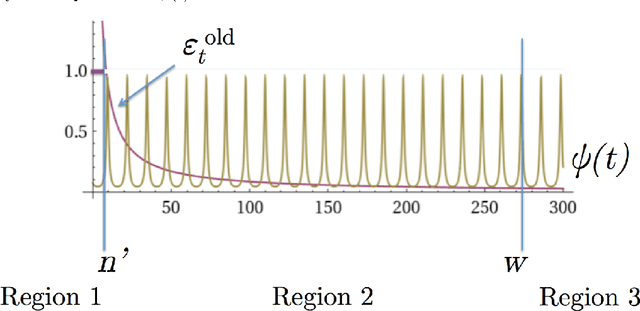
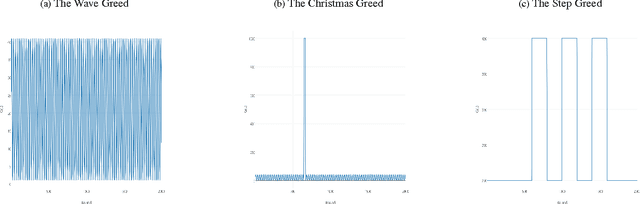
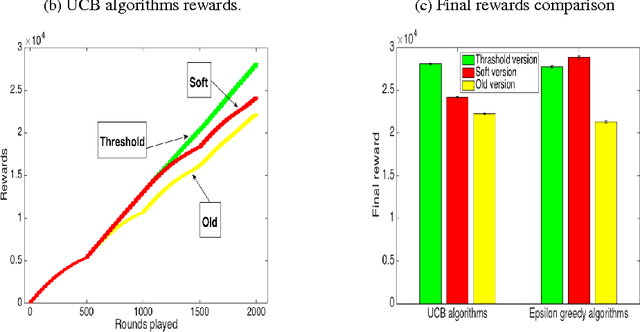
In retail, there are predictable yet dramatic time-dependent patterns in customer behavior, such as periodic changes in the number of visitors, or increases in visitors just before major holidays. The current paradigm of multi-armed bandit analysis does not take these known patterns into account. This means that for applications in retail, where prices are fixed for periods of time, current bandit algorithms will not suffice. This work provides a remedy that takes the time-dependent patterns into account, and we show how this remedy is implemented in the UCB and {\epsilon}-greedy methods and we introduce a new policy called the variable arm pool method. In the corrected methods, exploitation (greed) is regulated over time, so that more exploitation occurs during higher reward periods, and more exploration occurs in periods of low reward. In order to understand why regret is reduced with the corrected methods, we present a set of bounds that provide insight into why we would want to exploit during periods of high reward, and discuss the impact on regret. Our proposed methods perform well in experiments, and were inspired by a high-scoring entry in the Exploration and Exploitation 3 contest using data from Yahoo! Front Page. That entry heavily used time-series methods to regulate greed over time, which was substantially more effective than other contextual bandit methods.
A time resolved clustering method revealing longterm structures and their short-term internal dynamics
Dec 09, 2019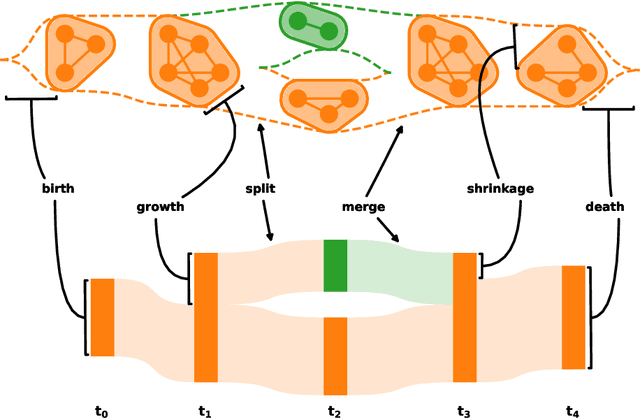
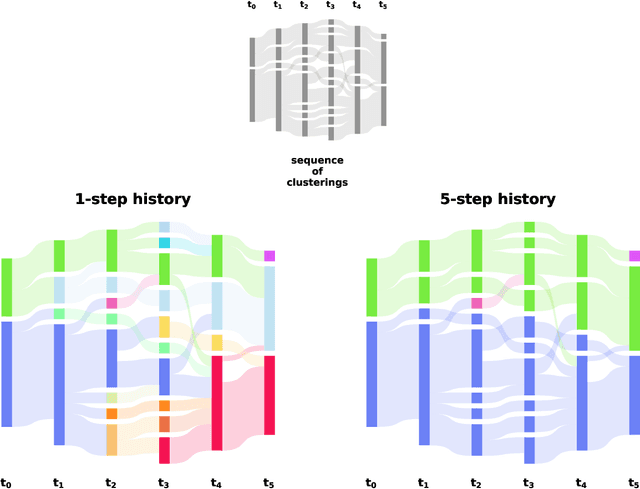
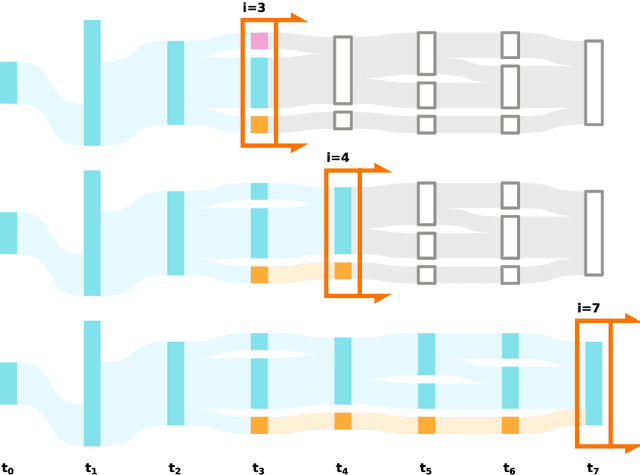
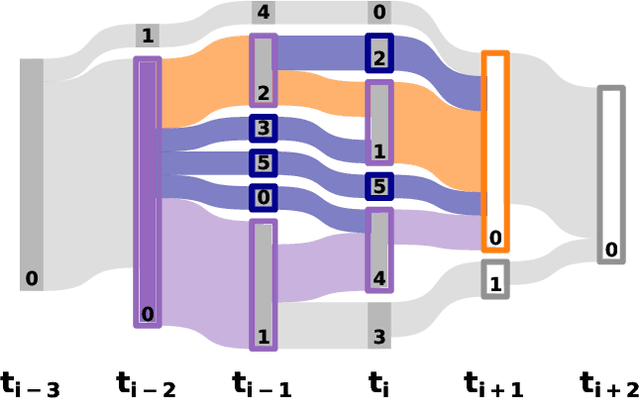
The last decades have not only been characterized by an explosive growth of data, but also an increasing appreciation of data as a valuable resource. It's value comes with the ability to extract meaningful patterns that are of economic, societal or scientific relevance. A particular challenge is to identify patterns across time, including patterns that might only become apparent when the temporal dimension is taken into account. Here, we present a novel method that aims to achieve this by detecting dynamic clusters, i.e. structural elements that can be present over prolonged durations. It is based on an adaptive identification of majority overlaps between groups at different time points and allows the accommodation of transient decompositions in otherwise persistent dynamic clusters. As such, our method enables the detection of persistent structural elements with internal dynamics and can be applied to any classifiable data, ranging from social contact networks to arbitrary sets of time stamped feature vectors. It provides a unique tool to study systems with non-trivial temporal dynamics with a broad applicability to scientific, societal and economic data.
DeepOrder: Deep Learning for Test Case Prioritization in Continuous Integration Testing
Oct 14, 2021Continuous integration testing is an important step in the modern software engineering life cycle. Test prioritization is a method that can improve the efficiency of continuous integration testing by selecting test cases that can detect faults in the early stage of each cycle. As continuous integration testing produces voluminous test execution data, test history is a commonly used artifact in test prioritization. However, existing test prioritization techniques for continuous integration either cannot handle large test history or are optimized for using a limited number of historical test cycles. We show that such a limitation can decrease fault detection effectiveness of prioritized test suites. This work introduces DeepOrder, a deep learning-based model that works on the basis of regression machine learning. DeepOrder ranks test cases based on the historical record of test executions from any number of previous test cycles. DeepOrder learns failed test cases based on multiple factors including the duration and execution status of test cases. We experimentally show that deep neural networks, as a simple regression model, can be efficiently used for test case prioritization in continuous integration testing. DeepOrder is evaluated with respect to time-effectiveness and fault detection effectiveness in comparison with an industry practice and the state of the art approaches. The results show that DeepOrder outperforms the industry practice and state-of-the-art test prioritization approaches in terms of these two metrics.