 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Deep Learning Generative Model Approach for Image Synthesis of Plant Leaves
Nov 05, 2021
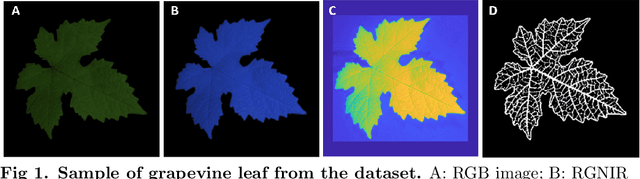
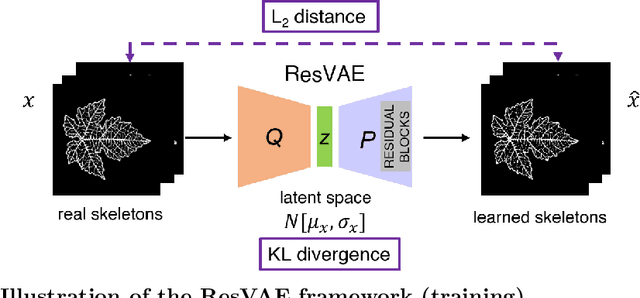
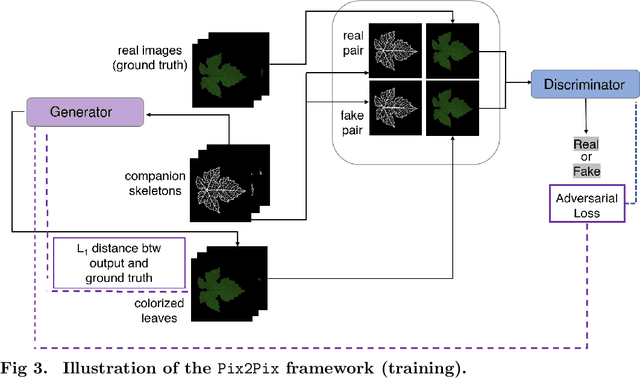
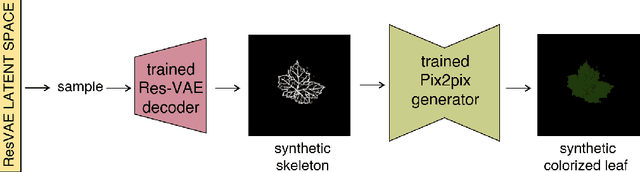
Objectives. We generate via advanced Deep Learning (DL) techniques artificial leaf images in an automatized way. We aim to dispose of a source of training samples for AI applications for modern crop management. Such applications require large amounts of data and, while leaf images are not truly scarce, image collection and annotation remains a very time--consuming process. Data scarcity can be addressed by augmentation techniques consisting in simple transformations of samples belonging to a small dataset, but the richness of the augmented data is limited: this motivates the search for alternative approaches. Methods. Pursuing an approach based on DL generative models, we propose a Leaf-to-Leaf Translation (L2L) procedure structured in two steps: first, a residual variational autoencoder architecture generates synthetic leaf skeletons (leaf profile and veins) starting from companions binarized skeletons of real images. In a second step, we perform translation via a Pix2pix framework, which uses conditional generator adversarial networks to reproduce the colorization of leaf blades, preserving the shape and the venation pattern. Results. The L2L procedure generates synthetic images of leaves with a realistic appearance. We address the performance measurement both in a qualitative and a quantitative way; for this latter evaluation, we employ a DL anomaly detection strategy which quantifies the degree of anomaly of synthetic leaves with respect to real samples. Conclusions. Generative DL approaches have the potential to be a new paradigm to provide low-cost meaningful synthetic samples for computer-aided applications. The present L2L approach represents a step towards this goal, being able to generate synthetic samples with a relevant qualitative and quantitative resemblance to real leaves.
Automatic Generation of Word Problems for Academic Education via Natural Language Processing (NLP)
Sep 30, 2021


Digital learning platforms enable students to learn on a flexible and individual schedule as well as providing instant feedback mechanisms. The field of STEM education requires students to solve numerous training exercises to grasp underlying concepts. It is apparent that there are restrictions in current online education in terms of exercise diversity and individuality. Many exercises show little variance in structure and content, hindering the adoption of abstraction capabilities by students. This thesis proposes an approach to generate diverse, context rich word problems. In addition to requiring the generated language to be grammatically correct, the nature of word problems implies additional constraints on the validity of contents. The proposed approach is proven to be effective in generating valid word problems for mathematical statistics. The experimental results present a tradeoff between generation time and exercise validity. The system can easily be parametrized to handle this tradeoff according to the requirements of specific use cases.
Time Series Anomaly Detection Using Convolutional Neural Networks and Transfer Learning
May 31, 2019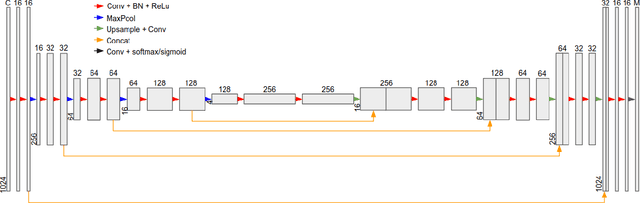
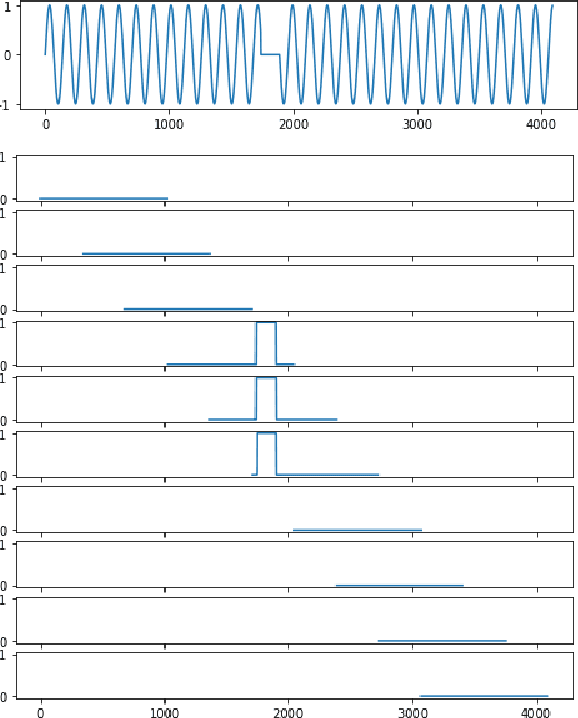
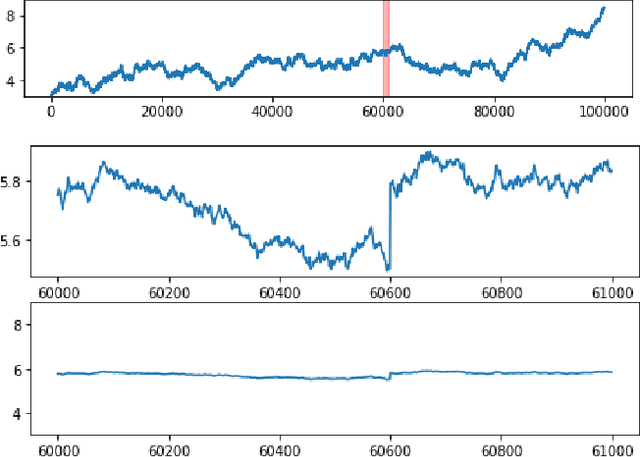
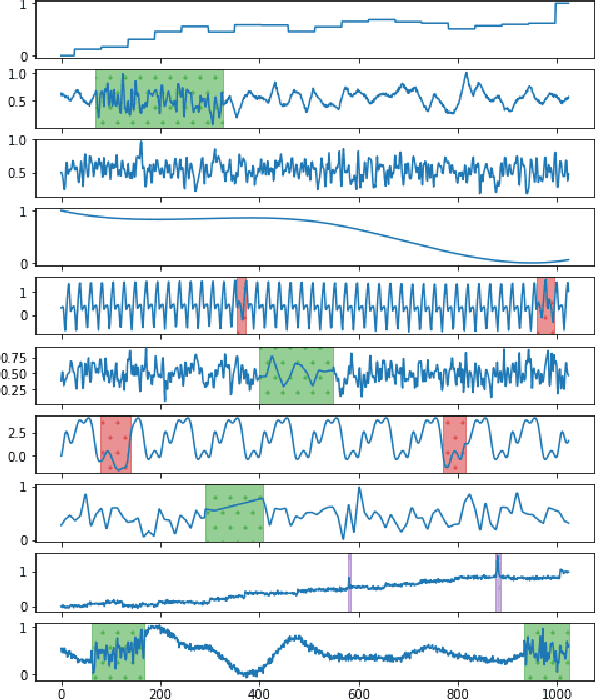
Time series anomaly detection plays a critical role in automated monitoring systems. Most previous deep learning efforts related to time series anomaly detection were based on recurrent neural networks (RNN). In this paper, we propose a time series segmentation approach based on convolutional neural networks (CNN) for anomaly detection. Moreover, we propose a transfer learning framework that pretrains a model on a large-scale synthetic univariate time series data set and then fine-tunes its weights on small-scale, univariate or multivariate data sets with previously unseen classes of anomalies. For the multivariate case, we introduce a novel network architecture. The approach was tested on multiple synthetic and real data sets successfully.
Online Ordering Platform City Distribution Based on Genetic Algorithm
Jun 22, 2021
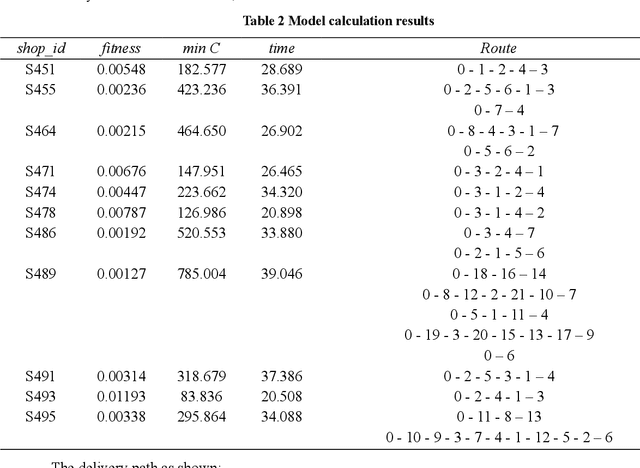
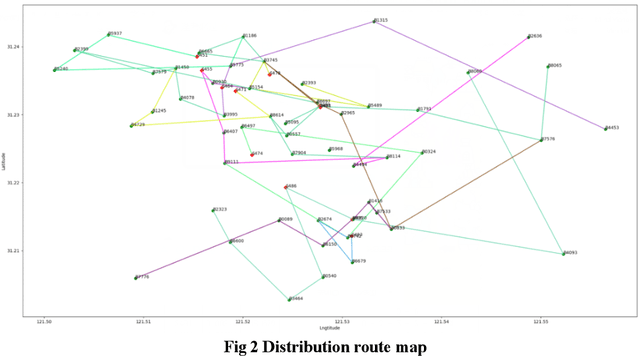
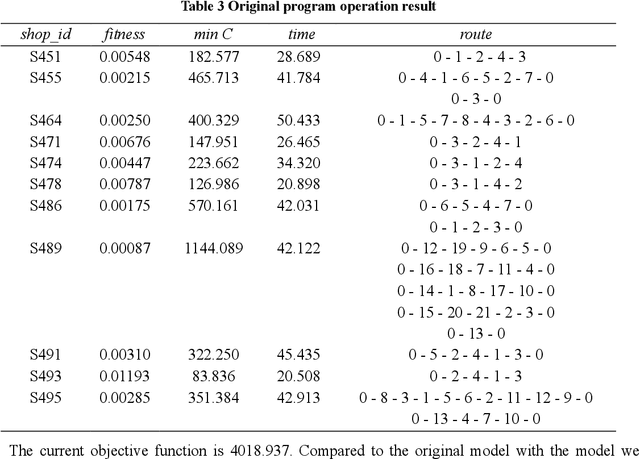
Since the rising of the takeaway ordering platform, the M platform has taken the lead in the industry with its high-quality service. The increasing order volume leads the competition between platforms to reduce the distribution cost, which increases rapidly because of the unreasonable distribution route. By analyzing platform distribution's current situation, we study the vehicle routing problem of urban distribution on the M platform and minimize the distribution cost. Considering the constraints of the customer's expected delivery time and vehicle condition, we combine the different arrival times of the vehicle routing problem model using three soft time windows and solve the problem using a genetic algorithm (GA). The results show that our model and algorithm can design the vehicle path superior to the original model in terms of distribution cost and delivery time, thus providing decision support for the M platform to save distribution cost in urban distribution in the future.
PWPAE: An Ensemble Framework for Concept Drift Adaptation in IoT Data Streams
Sep 10, 2021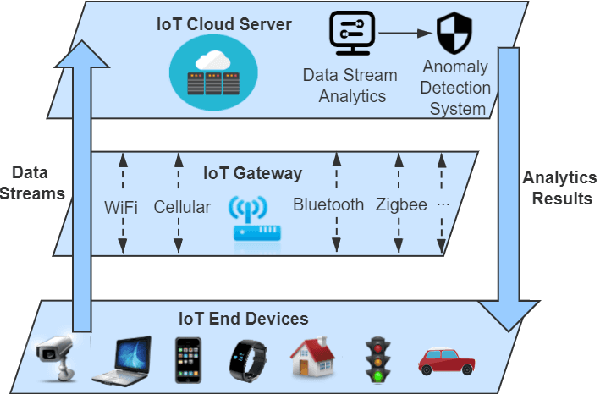
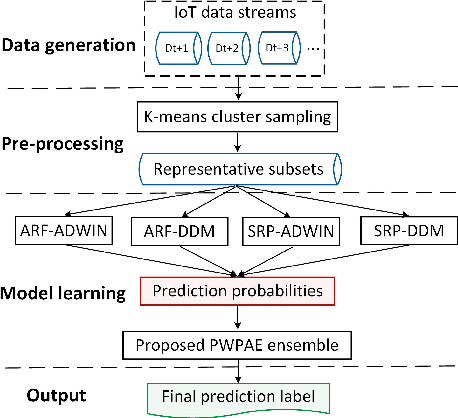
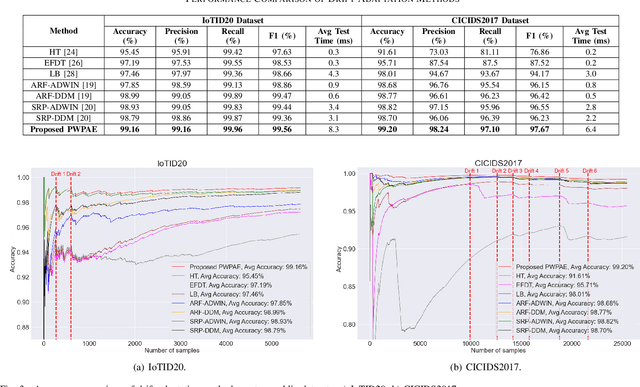
As the number of Internet of Things (IoT) devices and systems have surged, IoT data analytics techniques have been developed to detect malicious cyber-attacks and secure IoT systems; however, concept drift issues often occur in IoT data analytics, as IoT data is often dynamic data streams that change over time, causing model degradation and attack detection failure. This is because traditional data analytics models are static models that cannot adapt to data distribution changes. In this paper, we propose a Performance Weighted Probability Averaging Ensemble (PWPAE) framework for drift adaptive IoT anomaly detection through IoT data stream analytics. Experiments on two public datasets show the effectiveness of our proposed PWPAE method compared against state-of-the-art methods.
SIRe-Networks: Skip Connections over Interlaced Multi-Task Learning and Residual Connections for Structure Preserving Object Classification
Oct 06, 2021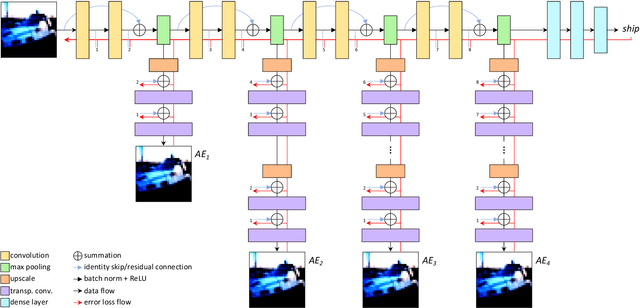
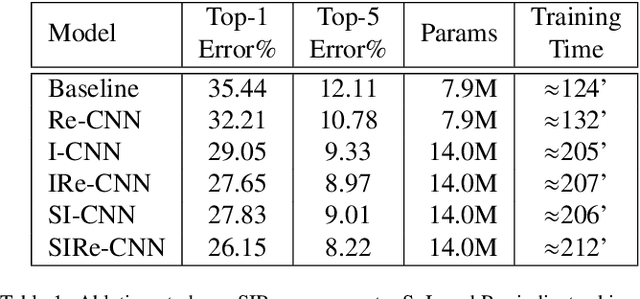

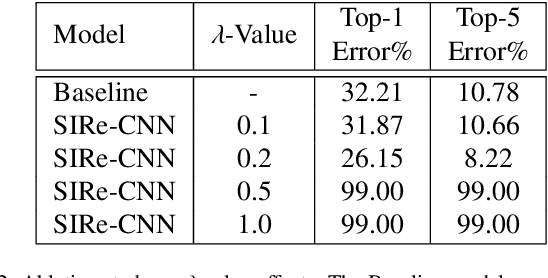
Improving existing neural network architectures can involve several design choices such as manipulating the loss functions, employing a diverse learning strategy, exploiting gradient evolution at training time, optimizing the network hyper-parameters, or increasing the architecture depth. The latter approach is a straightforward solution, since it directly enhances the representation capabilities of a network; however, the increased depth generally incurs in the well-known vanishing gradient problem. In this paper, borrowing from different methods addressing this issue, we introduce an interlaced multi-task learning strategy, defined SIRe, to reduce the vanishing gradient in relation to the object classification task. The presented methodology directly improves a convolutional neural network (CNN) by enforcing the input image structure preservation through interlaced auto-encoders, and further refines the base network architecture by means of skip and residual connections. To validate the presented methodology, a simple CNN and various implementations of famous networks are extended via the SIRe strategy and extensively tested on the CIFAR100 dataset; where the SIRe-extended architectures achieve significantly increased performances across all models, thus confirming the presented approach effectiveness.
Classification of Discrete Dynamical Systems Based on Transients
Aug 03, 2021
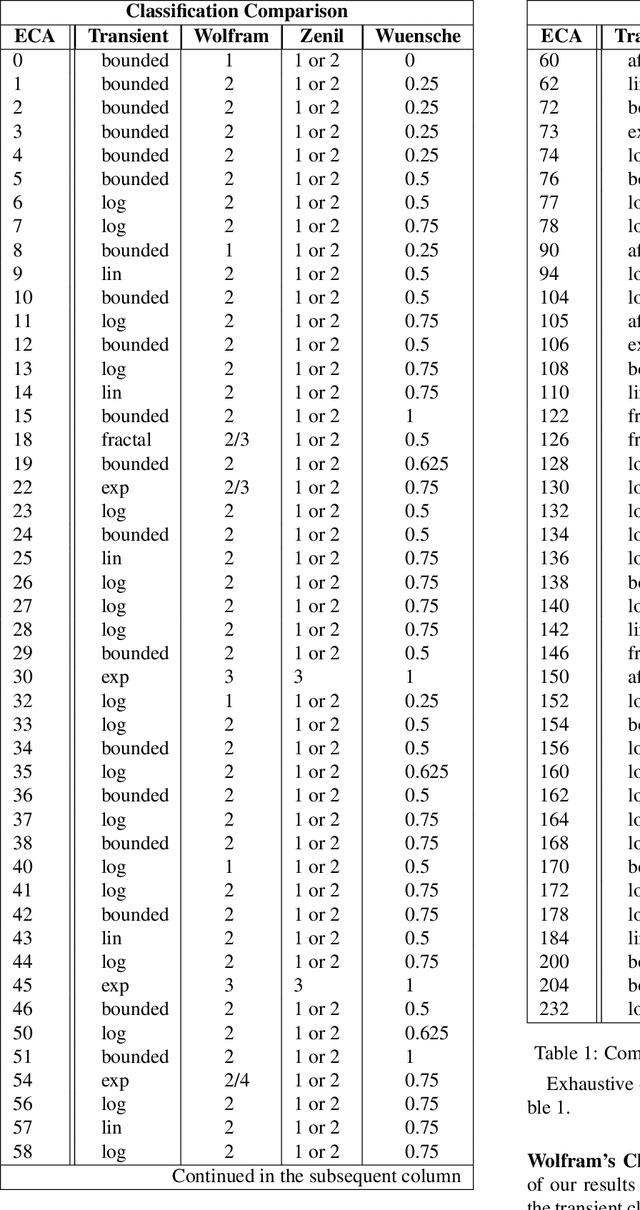
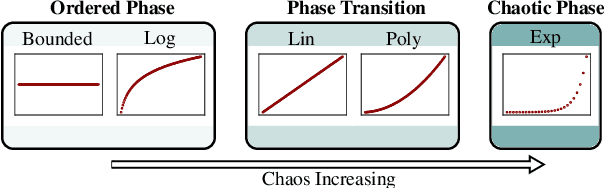
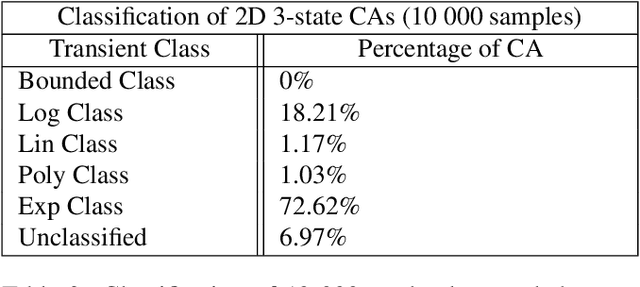
In order to develop systems capable of artificial evolution, we need to identify which systems can produce complex behavior. We present a novel classification method applicable to any class of deterministic discrete space and time dynamical systems. The method is based on classifying the asymptotic behavior of the average computation time in a given system before entering a loop. We were able to identify a critical region of behavior that corresponds to a phase transition from ordered behavior to chaos across various classes of dynamical systems. To show that our approach can be applied to many different computational systems, we demonstrate the results of classifying cellular automata, Turing machines, and random Boolean networks. Further, we use this method to classify 2D cellular automata to automatically find those with interesting, complex dynamics. We believe that our work can be used to design systems in which complex structures emerge. Also, it can be used to compare various versions of existing attempts to model open-ended evolution (Ray (1991), Ofria et al. (2004), Channon (2006)).
A life-long SLAM approach using adaptable local maps based on rasterized LIDAR images
Jul 15, 2021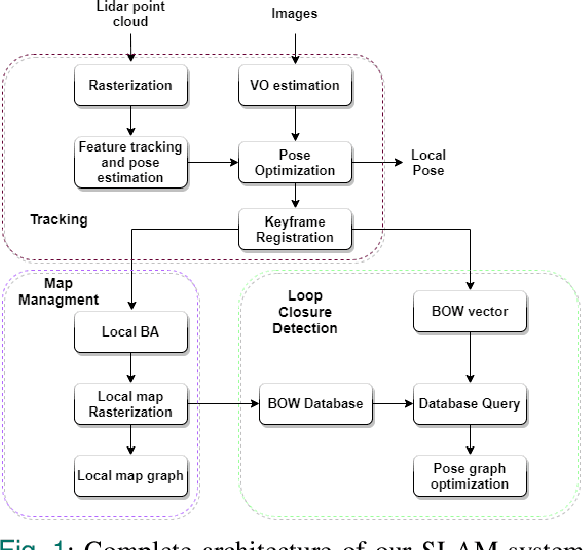
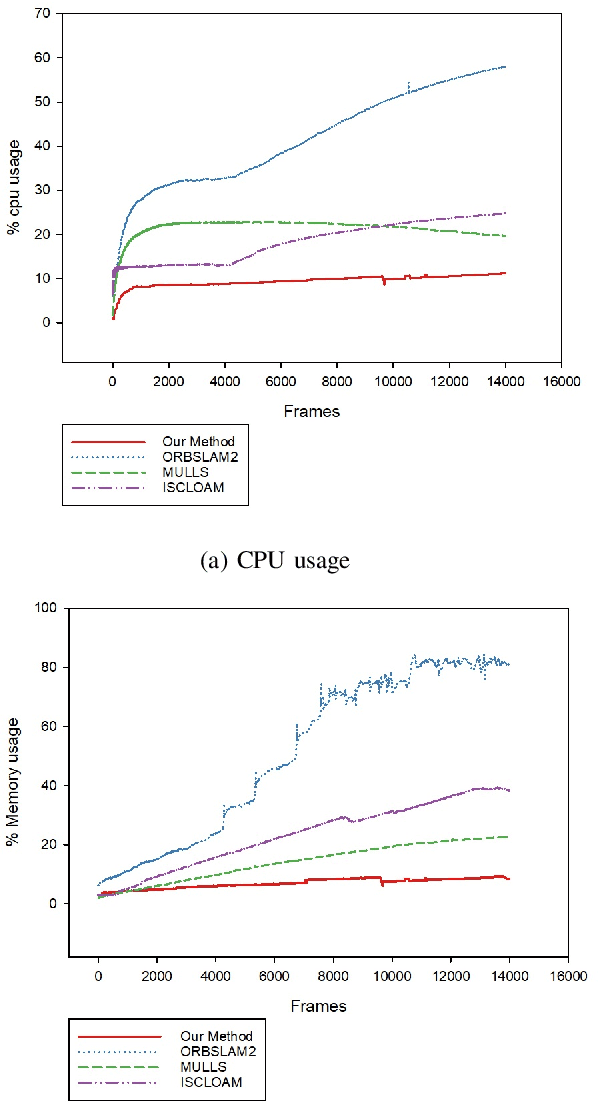
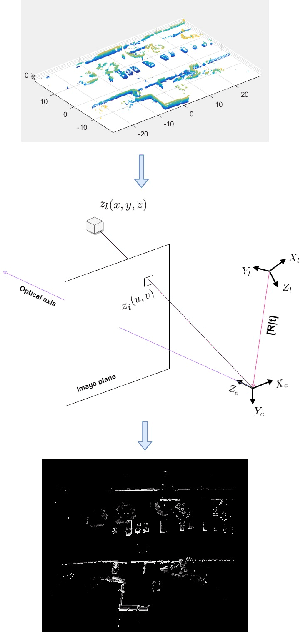
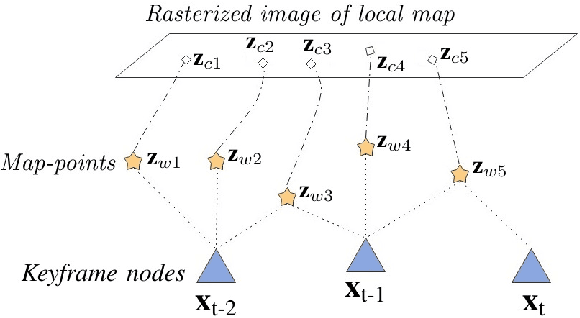
Most real-time autonomous robot applications require a robot to traverse through a dynamic space for a long time. In some cases, a robot needs to work in the same environment. Such applications give rise to the problem of a life-long SLAM system. Life-long SLAM presents two main challenges i.e. the tracking should not fail in a dynamic environment and the need for a robust and efficient mapping strategy. The system should update maps with new information; while also keeping track of older observations. But, mapping for a long time can require higher computational requirements. In this paper, we propose a solution to the problem of life-long SLAM. We represent the global map as a set of rasterized images of local maps along with a map management system responsible for updating local maps and keeping track of older values. We also present an efficient approach of using the bag of visual words method for loop closure detection and relocalization. We evaluate the performance of our system on the KITTI dataset and an indoor dataset. Our loop closure system reported recall and precision of above 90 percent. The computational cost of our system is much lower as compared to state-of-the-art methods. Our method reports lower computational requirements even for long-term operation.
TS-CHIEF: A Scalable and Accurate Forest Algorithm for Time Series Classification
Jun 25, 2019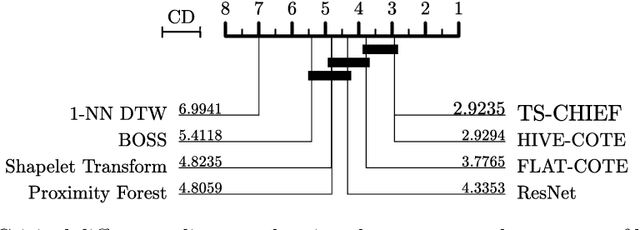
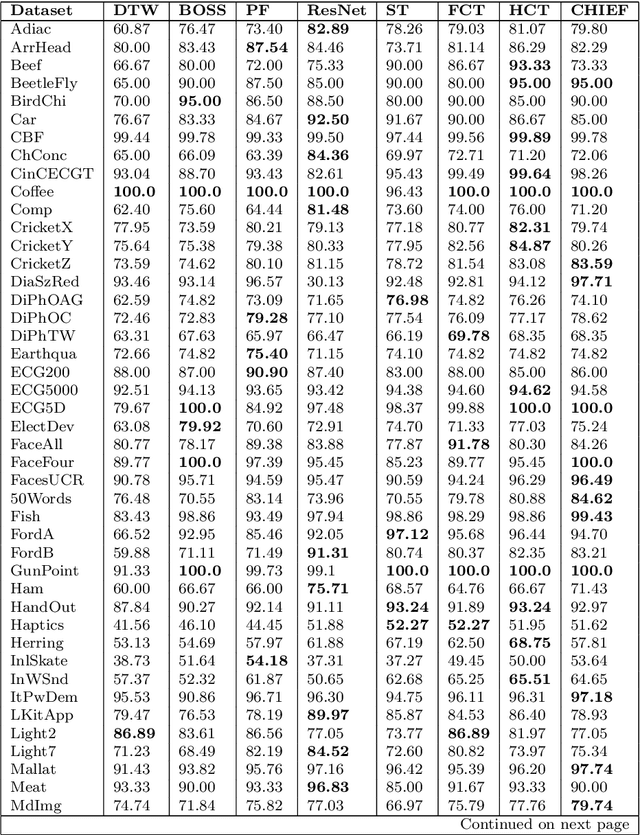
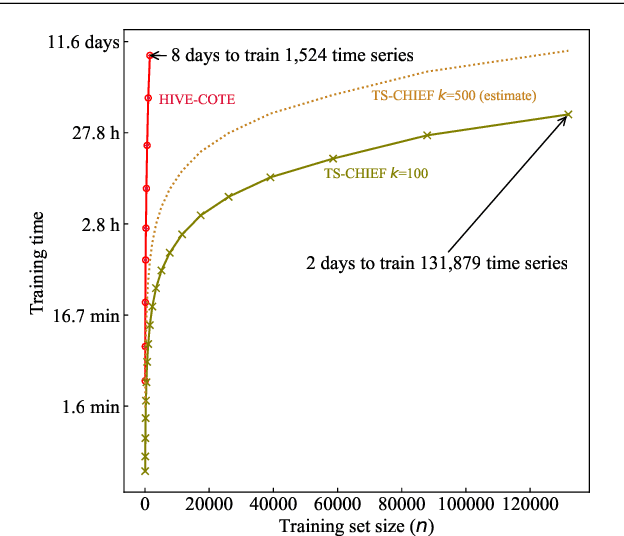
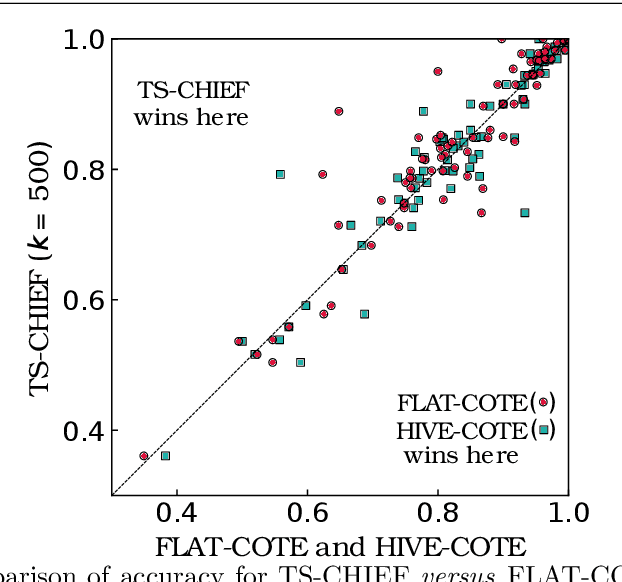
Time Series Classification (TSC) has seen enormous progress over the last two decades. HIVE-COTE (Hierarchical Vote Collective of Transformation-based Ensembles) is the current state of the art in terms of classification accuracy. HIVE-COTE recognizes that time series are a specific data type for which the traditional attribute-value representation, used predominantly in machine learning, fails to provide a relevant representation. HIVE-COTE combines multiple types of classifiers: each extracting information about a specific aspect of a time series, be it in the time domain, frequency domain or summarization of intervals within the series. However, HIVE-COTE (and its predecessor, FLAT-COTE) is often infeasible to run on even modest amounts of data. For instance, training HIVE-COTE on a dataset with only 1,500 time series can require 8 days of CPU time. It has polynomial runtime w.r.t training set size, so this problem compounds as data quantity increases. We propose a novel TSC algorithm, TS-CHIEF, which is highly competitive to HIVE-COTE in accuracy, but requires only a fraction of the runtime. TS-CHIEF constructs an ensemble classifier that integrates the most effective embeddings of time series that research has developed in the last decade. It uses tree-structured classifiers to do so efficiently. We assess TS-CHIEF on 85 datasets of the UCR archive, where it achieves state-of-the-art accuracy with scalability and efficiency. We demonstrate that TS-CHIEF can be trained on 130k time series in 2 days, a data quantity that is beyond the reach of any TSC algorithm with comparable accuracy.
Machine Learning for Malware Evolution Detection
Jul 04, 2021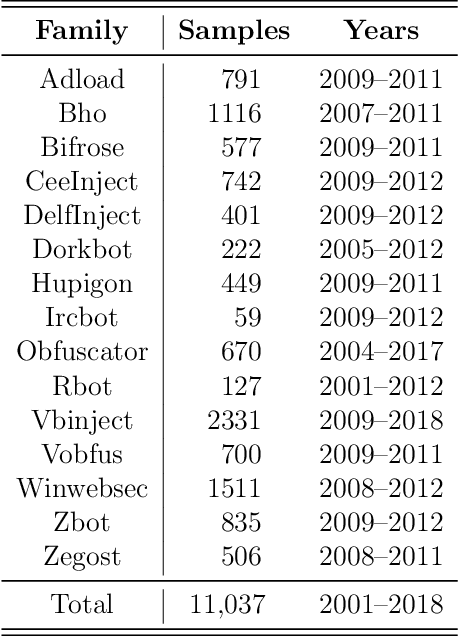
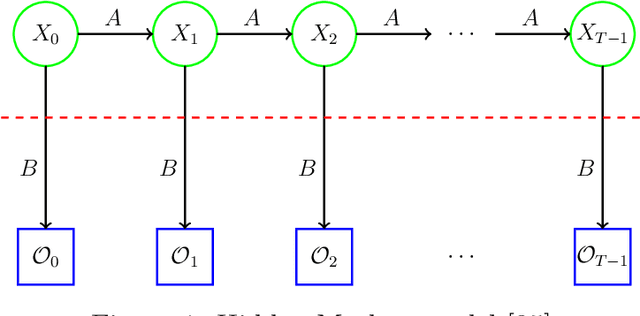
Malware evolves over time and antivirus must adapt to such evolution. Hence, it is critical to detect those points in time where malware has evolved so that appropriate countermeasures can be undertaken. In this research, we perform a variety of experiments on a significant number of malware families to determine when malware evolution is likely to have occurred. All of the evolution detection techniques that we consider are based on machine learning and can be fully automated -- in particular, no reverse engineering or other labor-intensive manual analysis is required. Specifically, we consider analysis based on hidden Markov models (HMM) and the word embedding techniques HMM2Vec and Word2Vec.