 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
White blood cell subtype detection and classification
Aug 10, 2021
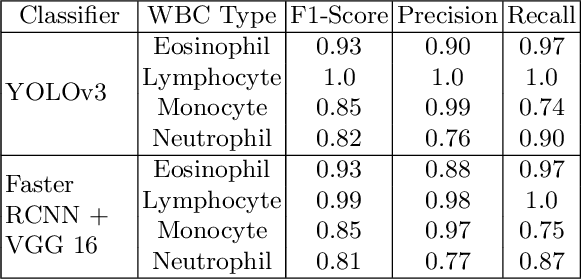
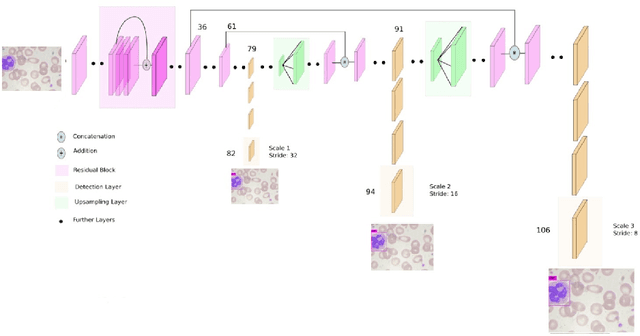
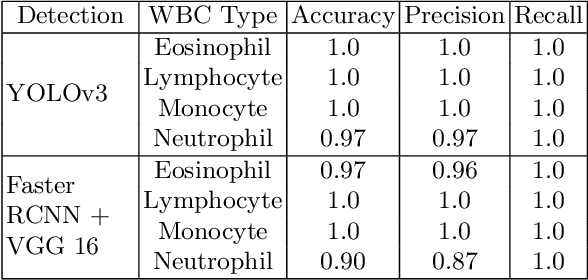
Machine learning has endless applications in the health care industry. White blood cell classification is one of the interesting and promising area of research. The classification of the white blood cells plays an important part in the medical diagnosis. In practise white blood cell classification is performed by the haematologist by taking a small smear of blood and careful examination under the microscope. The current procedures to identify the white blood cell subtype is more time taking and error-prone. The computer aided detection and diagnosis of the white blood cells tend to avoid the human error and reduce the time taken to classify the white blood cells. In the recent years several deep learning approaches have been developed in the context of classification of the white blood cells that are able to identify but are unable to localize the positions of white blood cells in the blood cell image. Following this, the present research proposes to utilize YOLOv3 object detection technique to localize and classify the white blood cells with bounding boxes. With exhaustive experimental analysis, the proposed work is found to detect the white blood cell with 99.2% accuracy and classify with 90% accuracy.
All-neural beamformer for continuous speech separation
Oct 13, 2021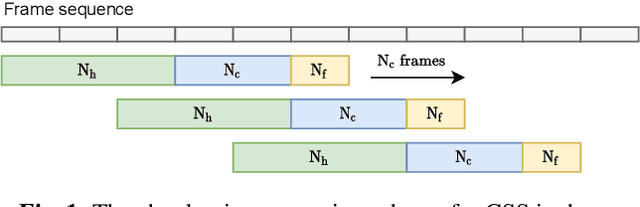
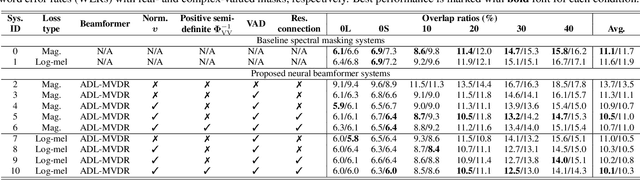

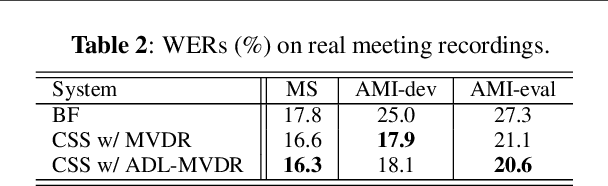
Continuous speech separation (CSS) aims to separate overlapping voices from a continuous influx of conversational audio containing an unknown number of utterances spoken by an unknown number of speakers. A common application scenario is transcribing a meeting conversation recorded by a microphone array. Prior studies explored various deep learning models for time-frequency mask estimation, followed by a minimum variance distortionless response (MVDR) filter to improve the automatic speech recognition (ASR) accuracy. The performance of these methods is fundamentally upper-bounded by MVDR's spatial selectivity. Recently, the all deep learning MVDR (ADL-MVDR) model was proposed for neural beamforming and demonstrated superior performance in a target speech extraction task using pre-segmented input. In this paper, we further adapt ADL-MVDR to the CSS task with several enhancements to enable end-to-end neural beamforming. The proposed system achieves significant word error rate reduction over a baseline spectral masking system on the LibriCSS dataset. Moreover, the proposed neural beamformer is shown to be comparable to a state-of-the-art MVDR-based system in real meeting transcription tasks, including AMI, while showing potentials to further simplify the runtime implementation and reduce the system latency with frame-wise processing.
Computational Intelligence and Deep Learning for Next-Generation Edge-Enabled Industrial IoT
Oct 28, 2021
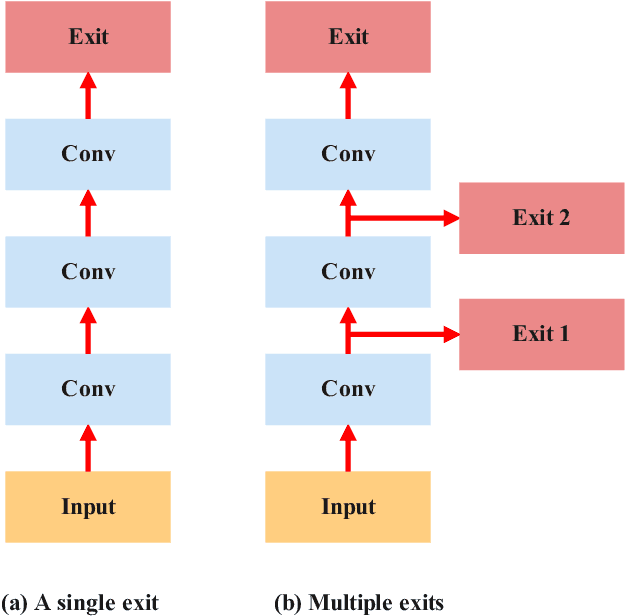
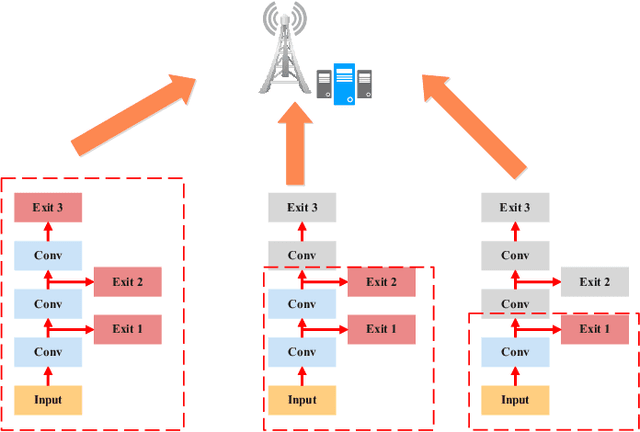
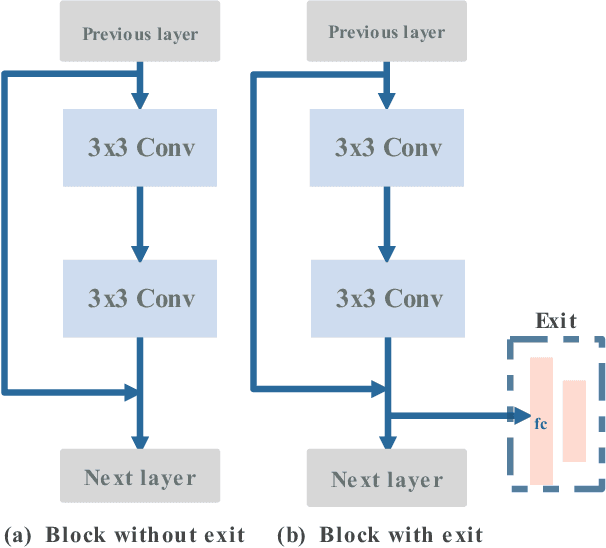
In this paper, we investigate how to deploy computational intelligence and deep learning (DL) in edge-enabled industrial IoT networks. In this system, the IoT devices can collaboratively train a shared model without compromising data privacy. However, due to limited resources in the industrial IoT networks, including computational power, bandwidth, and channel state, it is challenging for many devices to accomplish local training and upload weights to the edge server in time. To address this issue, we propose a novel multi-exit-based federated edge learning (ME-FEEL) framework, where the deep model can be divided into several sub-models with different depths and output prediction from the exit in the corresponding sub-model. In this way, the devices with insufficient computational power can choose the earlier exits and avoid training the complete model, which can help reduce computational latency and enable devices to participate into aggregation as much as possible within a latency threshold. Moreover, we propose a greedy approach-based exit selection and bandwidth allocation algorithm to maximize the total number of exits in each communication round. Simulation experiments are conducted on the classical Fashion-MNIST dataset under a non-independent and identically distributed (non-IID) setting, and it shows that the proposed strategy outperforms the conventional FL. In particular, the proposed ME-FEEL can achieve an accuracy gain up to 32.7% in the industrial IoT networks with the severely limited resources.
Fast Training of Neural Lumigraph Representations using Meta Learning
Jun 28, 2021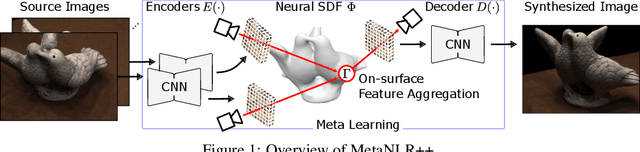


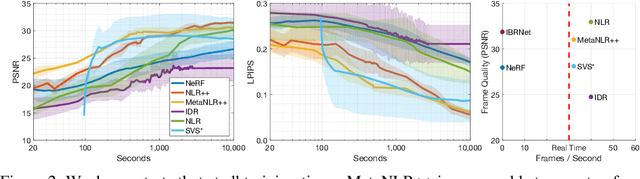
Novel view synthesis is a long-standing problem in machine learning and computer vision. Significant progress has recently been made in developing neural scene representations and rendering techniques that synthesize photorealistic images from arbitrary views. These representations, however, are extremely slow to train and often also slow to render. Inspired by neural variants of image-based rendering, we develop a new neural rendering approach with the goal of quickly learning a high-quality representation which can also be rendered in real-time. Our approach, MetaNLR++, accomplishes this by using a unique combination of a neural shape representation and 2D CNN-based image feature extraction, aggregation, and re-projection. To push representation convergence times down to minutes, we leverage meta learning to learn neural shape and image feature priors which accelerate training. The optimized shape and image features can then be extracted using traditional graphics techniques and rendered in real time. We show that MetaNLR++ achieves similar or better novel view synthesis results in a fraction of the time that competing methods require.
TS-CHIEF: A Scalable and Accurate Forest Algorithm for Time Series Classification
Jun 25, 2019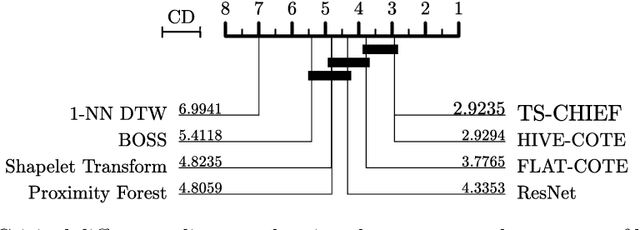
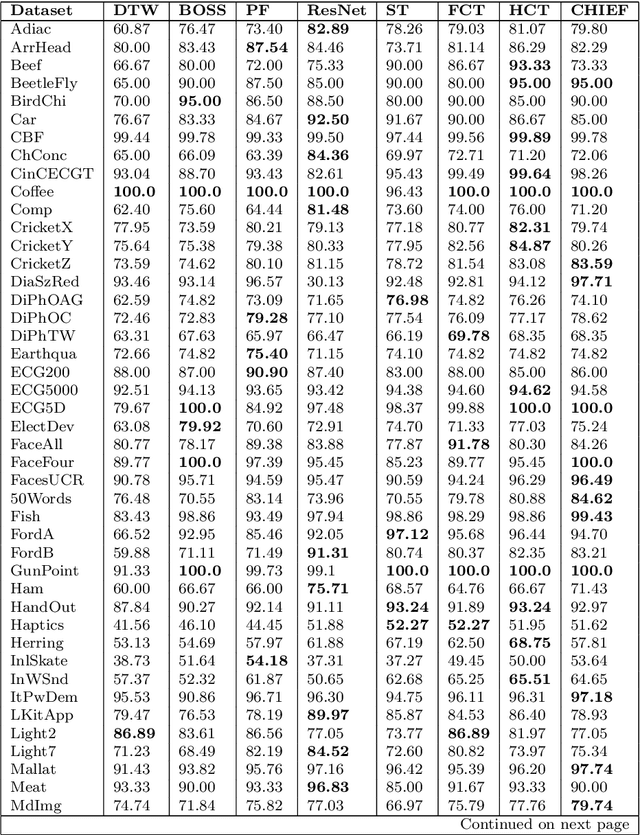
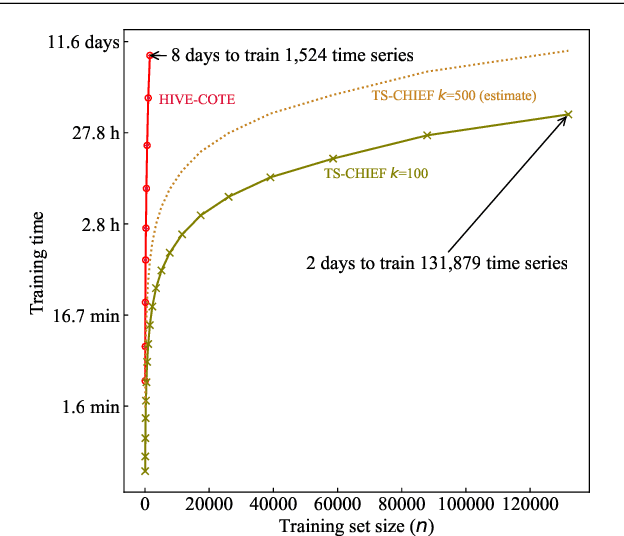
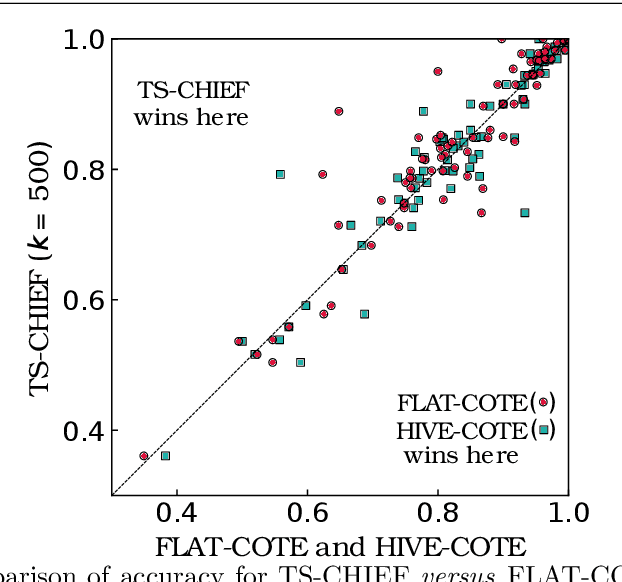
Time Series Classification (TSC) has seen enormous progress over the last two decades. HIVE-COTE (Hierarchical Vote Collective of Transformation-based Ensembles) is the current state of the art in terms of classification accuracy. HIVE-COTE recognizes that time series are a specific data type for which the traditional attribute-value representation, used predominantly in machine learning, fails to provide a relevant representation. HIVE-COTE combines multiple types of classifiers: each extracting information about a specific aspect of a time series, be it in the time domain, frequency domain or summarization of intervals within the series. However, HIVE-COTE (and its predecessor, FLAT-COTE) is often infeasible to run on even modest amounts of data. For instance, training HIVE-COTE on a dataset with only 1,500 time series can require 8 days of CPU time. It has polynomial runtime w.r.t training set size, so this problem compounds as data quantity increases. We propose a novel TSC algorithm, TS-CHIEF, which is highly competitive to HIVE-COTE in accuracy, but requires only a fraction of the runtime. TS-CHIEF constructs an ensemble classifier that integrates the most effective embeddings of time series that research has developed in the last decade. It uses tree-structured classifiers to do so efficiently. We assess TS-CHIEF on 85 datasets of the UCR archive, where it achieves state-of-the-art accuracy with scalability and efficiency. We demonstrate that TS-CHIEF can be trained on 130k time series in 2 days, a data quantity that is beyond the reach of any TSC algorithm with comparable accuracy.
Power and Performance Efficient SDN-Enabled Fog Architecture
May 30, 2021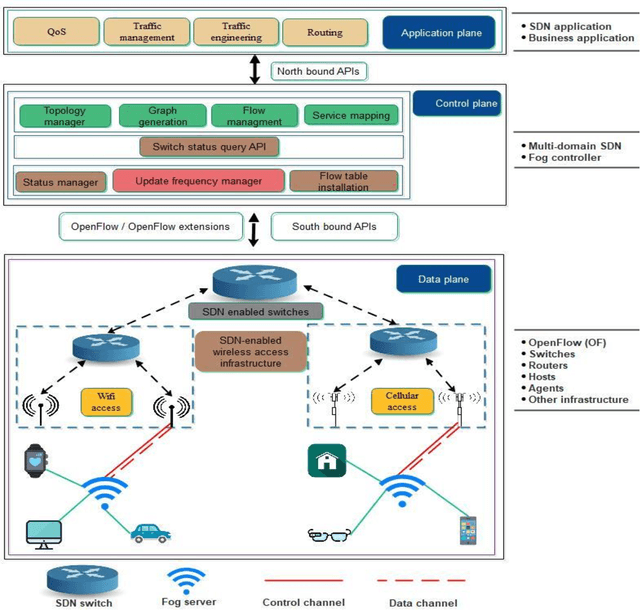
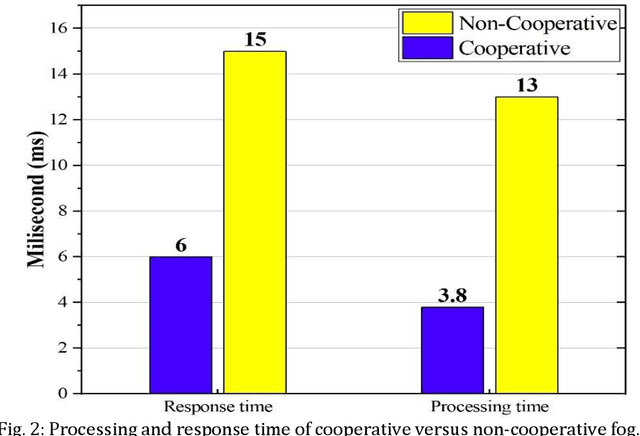
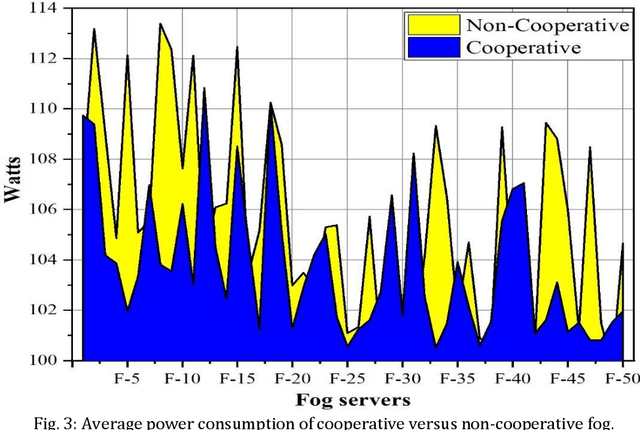
Software Defined Networks (SDNs) have dramatically simplified network management. However, enabling pure SDNs to respond in real-time while handling massive amounts of data still remains a challenging task. In contrast, fog computing has strong potential to serve large surges of data in real-time. SDN control plane enables innovation, and greatly simplifies network operations and management thereby providing a promising solution to implement energy and performance aware SDN-enabled fog computing. Besides, power efficiency and performance evaluation in SDN-enabled fog computing is an area that has not yet been fully explored by the research community. We present a novel SDN-enabled fog architecture to improve power efficacy and performance by leveraging cooperative and non-cooperative policy-based computing. Preliminary results from extensive simulation demonstrate an improvement in the power utilization as well as the overall performance (i.e., processing time, response time). Finally, we discuss several open research issues that need further investigation in the future.
Learning Optimal Conformal Classifiers
Oct 18, 2021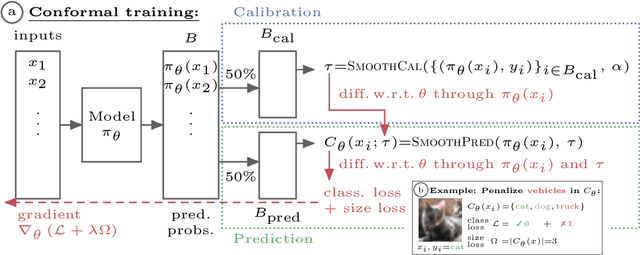
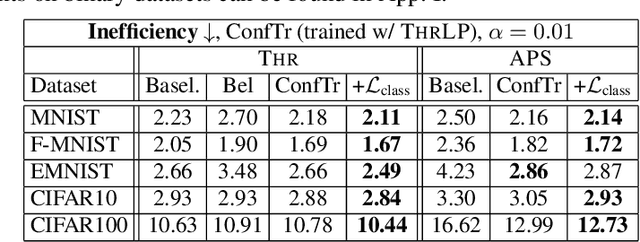

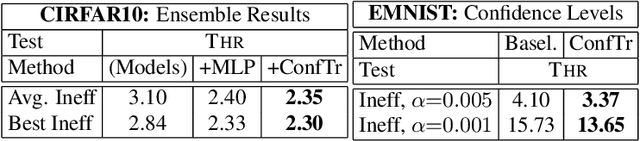
Modern deep learning based classifiers show very high accuracy on test data but this does not provide sufficient guarantees for safe deployment, especially in high-stake AI applications such as medical diagnosis. Usually, predictions are obtained without a reliable uncertainty estimate or a formal guarantee. Conformal prediction (CP) addresses these issues by using the classifier's probability estimates to predict confidence sets containing the true class with a user-specified probability. However, using CP as a separate processing step after training prevents the underlying model from adapting to the prediction of confidence sets. Thus, this paper explores strategies to differentiate through CP during training with the goal of training model with the conformal wrapper end-to-end. In our approach, conformal training (ConfTr), we specifically "simulate" conformalization on mini-batches during training. We show that CT outperforms state-of-the-art CP methods for classification by reducing the average confidence set size (inefficiency). Moreover, it allows to "shape" the confidence sets predicted at test time, which is difficult for standard CP. On experiments with several datasets, we show ConfTr can influence how inefficiency is distributed across classes, or guide the composition of confidence sets in terms of the included classes, while retaining the guarantees offered by CP.
Prediction of new outlinks for focused crawling
Nov 09, 2021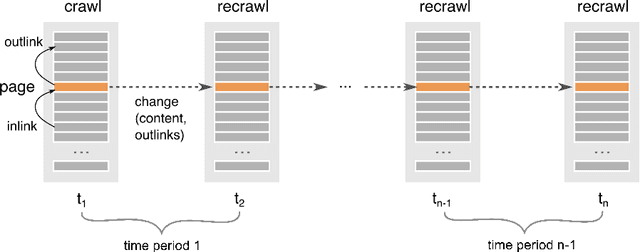
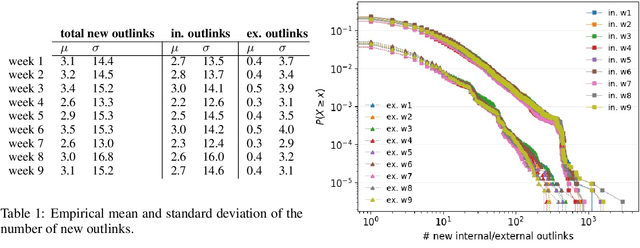


Discovering new hyperlinks enables Web crawlers to find new pages that have not yet been indexed. This is especially important for focused crawlers because they strive to provide a comprehensive analysis of specific parts of the Web, thus prioritizing discovery of new pages over discovery of changes in content. In the literature, changes in hyperlinks and content have been usually considered simultaneously. However, there is also evidence suggesting that these two types of changes are not necessarily related. Moreover, many studies about predicting changes assume that long history of a page is available, which is unattainable in practice. The aim of this work is to provide a methodology for detecting new links effectively using a short history. To this end, we use a dataset of ten crawls at intervals of one week. Our study consists of three parts. First, we obtain insight in the data by analyzing empirical properties of the number of new outlinks. We observe that these properties are, on average, stable over time, but there is a large difference between emergence of hyperlinks towards pages within and outside the domain of a target page (internal and external outlinks, respectively). Next, we provide statistical models for three targets: the link change rate, the presence of new links, and the number of new links. These models include the features used earlier in the literature, as well as new features introduced in this work. We analyze correlation between the features, and investigate their informativeness. A notable finding is that, if the history of the target page is not available, then our new features, that represent the history of related pages, are most predictive for new links in the target page. Finally, we propose ranking methods as guidelines for focused crawlers to efficiently discover new pages, which achieve excellent performance with respect to the corresponding targets.
ES-ImageNet: A Million Event-Stream Classification Dataset for Spiking Neural Networks
Oct 23, 2021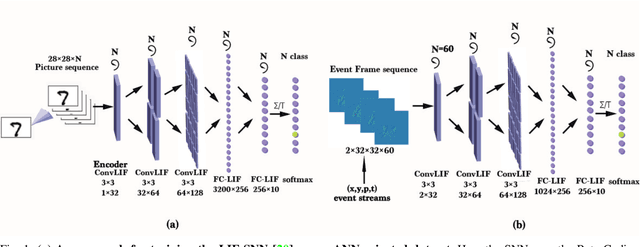
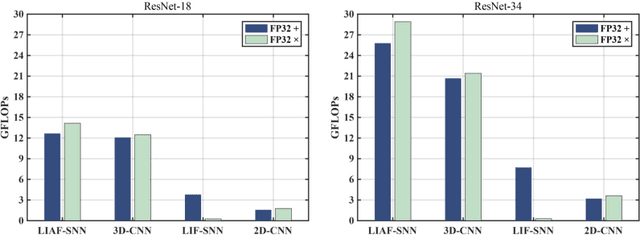
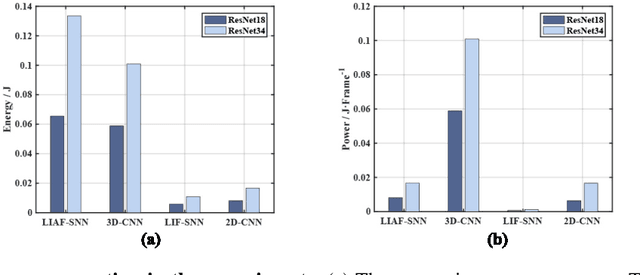
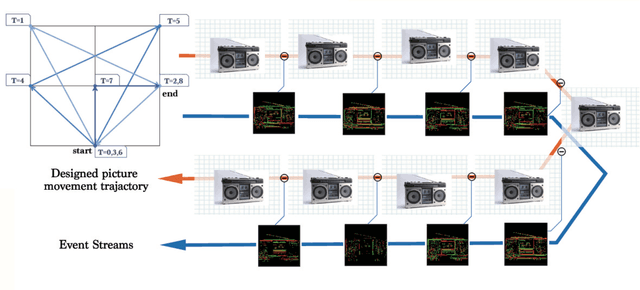
With event-driven algorithms, especially the spiking neural networks (SNNs), achieving continuous improvement in neuromorphic vision processing, a more challenging event-stream-dataset is urgently needed. However, it is well known that creating an ES-dataset is a time-consuming and costly task with neuromorphic cameras like dynamic vision sensors (DVS). In this work, we propose a fast and effective algorithm termed Omnidirectional Discrete Gradient (ODG) to convert the popular computer vision dataset ILSVRC2012 into its event-stream (ES) version, generating about 1,300,000 frame-based images into ES-samples in 1000 categories. In this way, we propose an ES-dataset called ES-ImageNet, which is dozens of times larger than other neuromorphic classification datasets at present and completely generated by the software. The ODG algorithm implements an image motion to generate local value changes with discrete gradient information in different directions, providing a low-cost and high-speed way for converting frame-based images into event streams, along with Edge-Integral to reconstruct the high-quality images from event streams. Furthermore, we analyze the statistics of the ES-ImageNet in multiple ways, and a performance benchmark of the dataset is also provided using both famous deep neural network algorithms and spiking neural network algorithms. We believe that this work shall provide a new large-scale benchmark dataset for SNNs and neuromorphic vision.
Equilibrium and non-Equilibrium regimes in the learning of Restricted Boltzmann Machines
May 28, 2021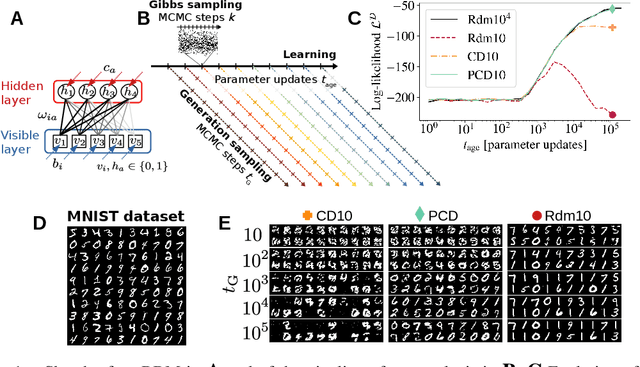
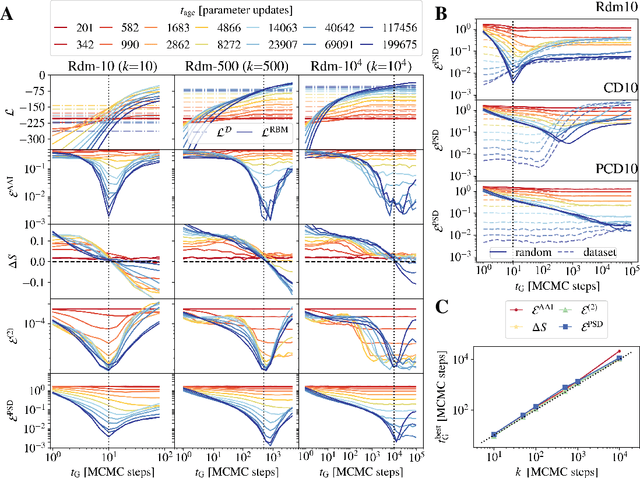
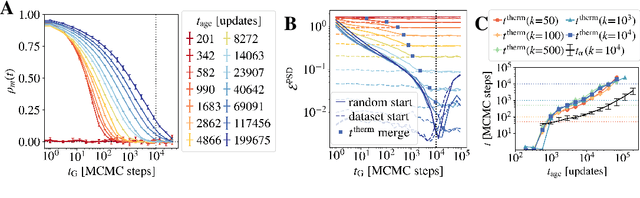
Training Restricted Boltzmann Machines (RBMs) has been challenging for a long time due to the difficulty of computing precisely the log-likelihood gradient. Over the past decades, many works have proposed more or less successful training recipes but without studying the crucial quantity of the problem: the mixing time i.e. the number of Monte Carlo iterations needed to sample new configurations from a model. In this work, we show that this mixing time plays a crucial role in the dynamics and stability of the trained model, and that RBMs operate in two well-defined regimes, namely equilibrium and out-of-equilibrium, depending on the interplay between this mixing time of the model and the number of steps, $k$, used to approximate the gradient. We further show empirically that this mixing time increases with the learning, which often implies a transition from one regime to another as soon as $k$ becomes smaller than this time. In particular, we show that using the popular $k$ (persistent) contrastive divergence approaches, with $k$ small, the dynamics of the learned model are extremely slow and often dominated by strong out-of-equilibrium effects. On the contrary, RBMs trained in equilibrium display faster dynamics, and a smooth convergence to dataset-like configurations during the sampling. Finally we discuss how to exploit in practice both regimes depending on the task one aims to fulfill: (i) short $k$s can be used to generate convincing samples in short times, (ii) large $k$ (or increasingly large) must be used to learn the correct equilibrium distribution of the RBM.