 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
How Does Cell-Free Massive MIMO Support Multiple Federated Learning Groups?
Jul 20, 2021
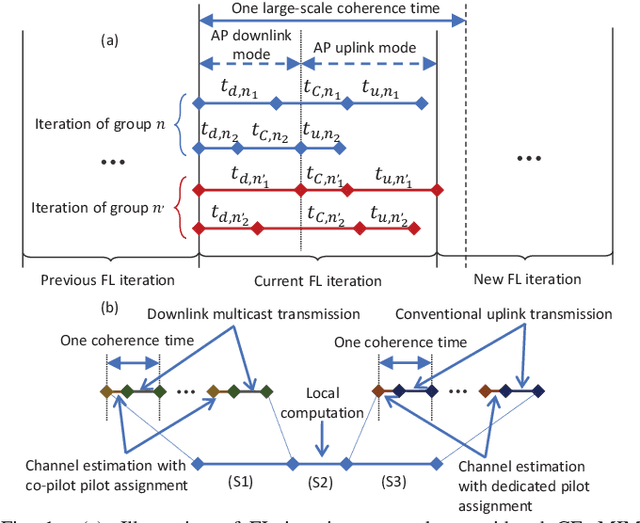
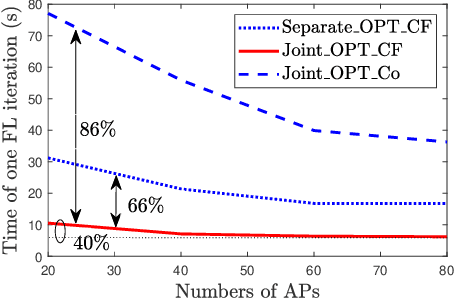
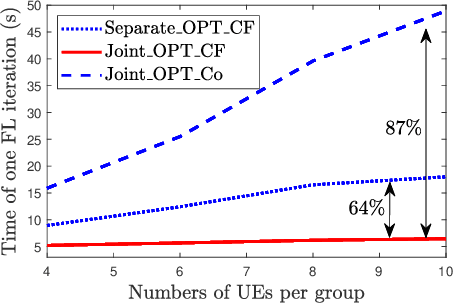
Federated learning (FL) has been considered as a promising learning framework for future machine learning systems due to its privacy preservation and communication efficiency. In beyond-5G/6G systems, it is likely to have multiple FL groups with different learning purposes. This scenario leads to a question: How does a wireless network support multiple FL groups? As an answer, we first propose to use a cell-free massive multiple-input multiple-output (MIMO) network to guarantee the stable operation of multiple FL processes by letting the iterations of these FL processes be executed together within a large-scale coherence time. We then develop a novel scheme that asynchronously executes the iterations of FL processes under multicasting downlink and conventional uplink transmission protocols. Finally, we propose a simple/low-complexity resource allocation algorithm which optimally chooses the power and computation resources to minimize the execution time of each iteration of each FL process.
Reverse engineering recurrent neural networks with Jacobian switching linear dynamical systems
Nov 01, 2021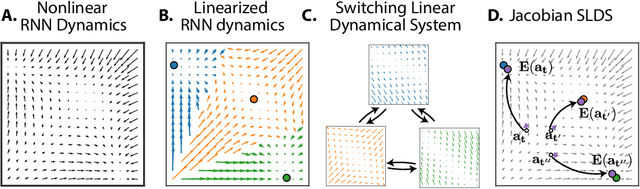
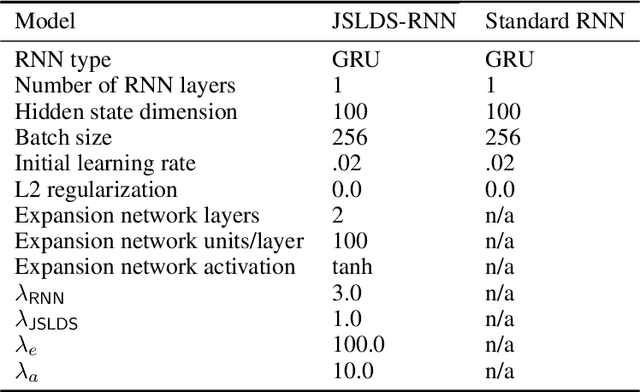
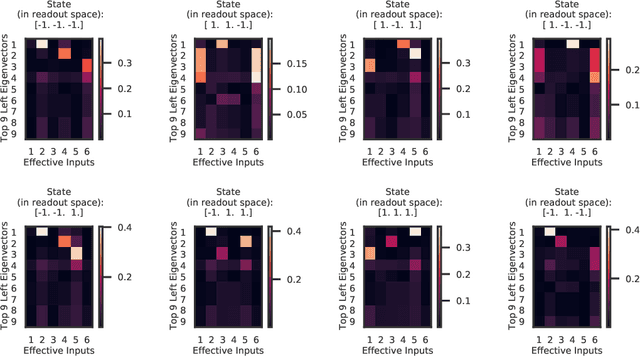
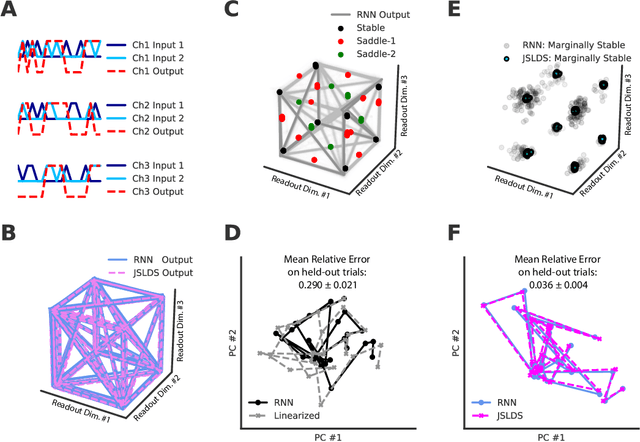
Recurrent neural networks (RNNs) are powerful models for processing time-series data, but it remains challenging to understand how they function. Improving this understanding is of substantial interest to both the machine learning and neuroscience communities. The framework of reverse engineering a trained RNN by linearizing around its fixed points has provided insight, but the approach has significant challenges. These include difficulty choosing which fixed point to expand around when studying RNN dynamics and error accumulation when reconstructing the nonlinear dynamics with the linearized dynamics. We present a new model that overcomes these limitations by co-training an RNN with a novel switching linear dynamical system (SLDS) formulation. A first-order Taylor series expansion of the co-trained RNN and an auxiliary function trained to pick out the RNN's fixed points govern the SLDS dynamics. The results are a trained SLDS variant that closely approximates the RNN, an auxiliary function that can produce a fixed point for each point in state-space, and a trained nonlinear RNN whose dynamics have been regularized such that its first-order terms perform the computation, if possible. This model removes the post-training fixed point optimization and allows us to unambiguously study the learned dynamics of the SLDS at any point in state-space. It also generalizes SLDS models to continuous manifolds of switching points while sharing parameters across switches. We validate the utility of the model on two synthetic tasks relevant to previous work reverse engineering RNNs. We then show that our model can be used as a drop-in in more complex architectures, such as LFADS, and apply this LFADS hybrid to analyze single-trial spiking activity from the motor system of a non-human primate.
Real-Time Dispatching of Large-Scale Ride-Sharing Systems: Integrating Optimization, Machine Learning, and Model Predictive Control
Mar 24, 2020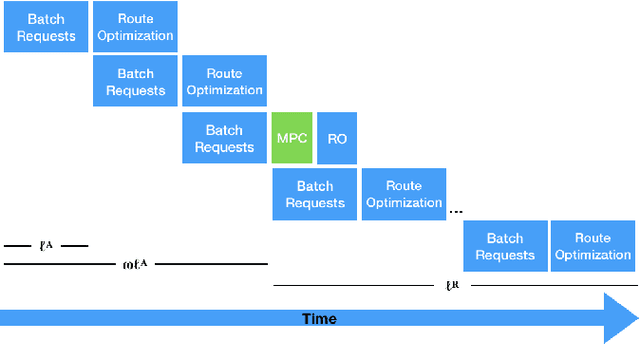
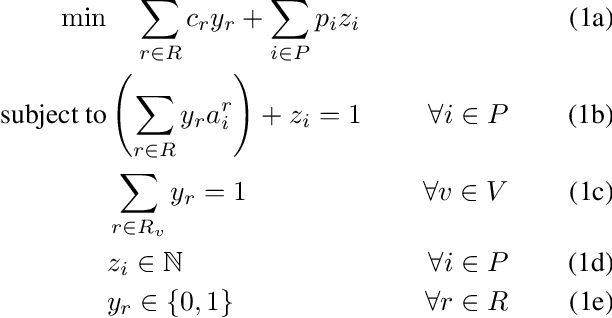
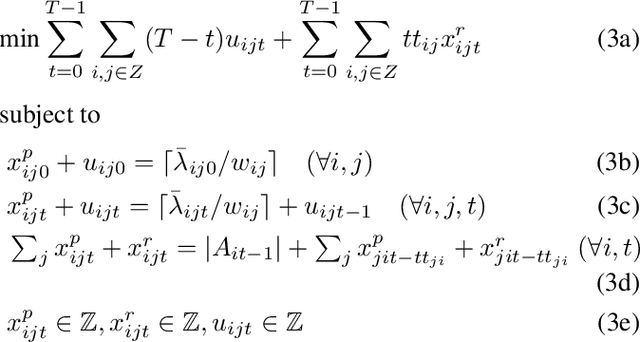
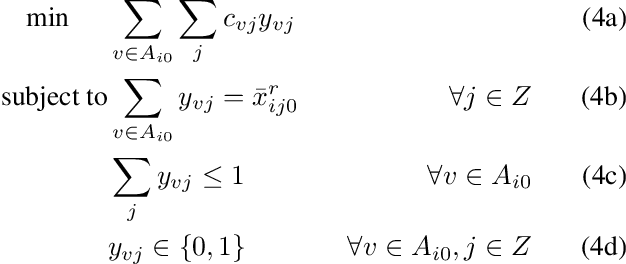
This paper considers the dispatching of large-scale real-time ride-sharing systems to address congestion issues faced by many cities. The goal is to serve all customers (service guarantees) with a small number of vehicles while minimizing waiting times under constraints on ride duration. This paper proposes an end-to-end approach that tightly integrates a state-of-the-art dispatching algorithm, a machine-learning model to predict zone-to-zone demand over time, and a model predictive control optimization to relocate idle vehicles. Experiments using historic taxi trips in New York City indicate that this integration decreases average waiting times by about 30% over all test cases and reaches close to 55% on the largest instances for high-demand zones.
Optimal Uniform OPE and Model-based Offline Reinforcement Learning in Time-Homogeneous, Reward-Free and Task-Agnostic Settings
May 21, 2021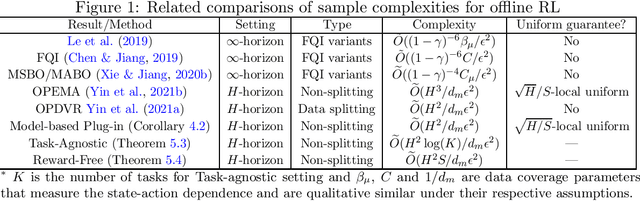
This work studies the statistical limits of uniform convergence for offline policy evaluation (OPE) problems with model-based methods (for finite horizon MDP) and provides a unified view towards optimal learning for several well-motivated offline tasks. Uniform OPE $\sup_\Pi|Q^\pi-\hat{Q}^\pi|<\epsilon$ (initiated by \citet{yin2021near}) is a stronger measure than the point-wise (fixed policy) OPE and ensures offline policy learning when $\Pi$ contains all policies (global policy class). In this paper, we establish an $\Omega(H^2 S/d_m\epsilon^2)$ lower bound (over model-based family) for the global uniform OPE, where $d_m$ is the minimal state-action probability induced by the behavior policy. Next, our main result establishes an episode complexity of $\tilde{O}(H^2/d_m\epsilon^2)$ for \emph{local} uniform convergence that applies to all \emph{near-empirically optimal} policies for the MDPs with \emph{stationary} transition. This result implies the optimal sample complexity for offline learning and separates the local uniform OPE from the global case due to the extra $S$ factor. Paramountly, the model-based method combining with our new analysis technique (singleton absorbing MDP) can be adapted to the new settings: offline task-agnostic and the offline reward-free with optimal complexity $\tilde{O}(H^2\log(K)/d_m\epsilon^2)$ ($K$ is the number of tasks) and $\tilde{O}(H^2S/d_m\epsilon^2)$ respectively, which provides a unified framework for simultaneously solving different offline RL problems.
An Application of CNNs to Time Sequenced One Dimensional Data in Radiation Detection
Aug 28, 2019A Convolutional Neural Network architecture was used to classify various isotopes of time-sequenced gamma-ray spectra, a typical output of a radiation detection system of a type commonly fielded for security or environmental measurement purposes. A two-dimensional surface (waterfall plot) in time-energy space is interpreted as a monochromatic image and standard image-based CNN techniques are applied. This allows for the time-sequenced aspects of features in the data to be discovered by the network, as opposed to standard algorithms which arbitrarily time bin the data to satisfy the intuition of a human spectroscopist. The CNN architecture and results are presented along with a comparison to conventional techniques. The results of this novel application of image processing techniques to radiation data will be presented along with a comparison to more conventional adaptive methods.
* 11 pages, 9 figures, presented: SPIE Defense + Commercial Sensing, 16-18 Apr 2019, Baltimore, MD, United States
Predicting user demographics based on interest analysis
Aug 02, 2021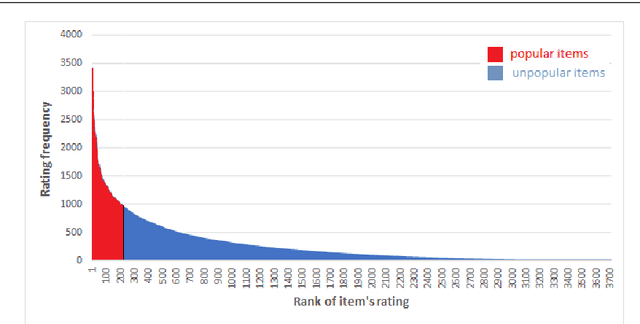
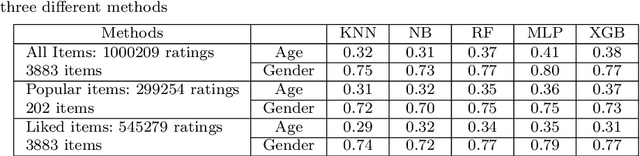
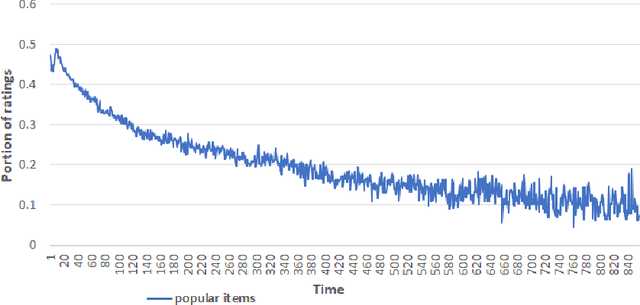
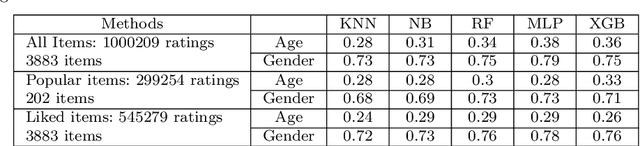
These days, due to the increasing amount of information generated on the web, most web service providers try to personalize their services. Users also interact with web-based systems in multiple ways and state their interests and preferences by rating the provided items. This paper proposes a framework to predict users' demographic based on ratings registered by users in a system. To the best of our knowledge, this is the first time that the item ratings are employed for users' demographic prediction problems, which have extensively been studied in recommendation systems and service personalization. We apply the framework to the Movielens dataset's ratings and predict users' age and gender. The experimental results show that using all ratings registered by users improves the prediction accuracy by at least 16% compared with previously studied models. Moreover, by classifying the items as popular and unpopular, we eliminate ratings that belong to 95% of items and still reach an acceptable level of accuracy. This significantly reduces update costs in a time-varying environment. Besides this classification, we propose other methods to reduce data volume while keeping the predictions accurate.
Asynchronous Tracking-by-Detection on Adaptive Time Surfaces for Event-based Object Tracking
Feb 13, 2020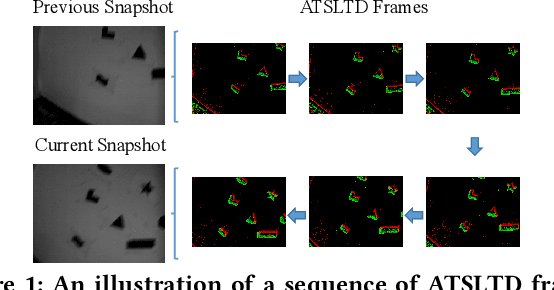


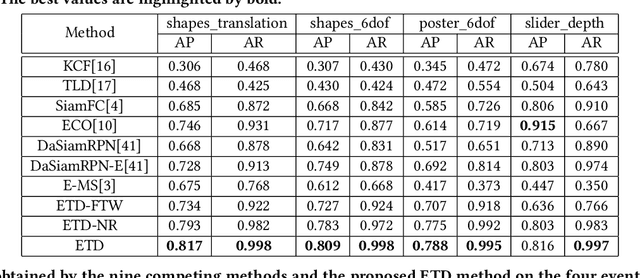
Event cameras, which are asynchronous bio-inspired vision sensors, have shown great potential in a variety of situations, such as fast motion and low illumination scenes. However, most of the event-based object tracking methods are designed for scenarios with untextured objects and uncluttered backgrounds. There are few event-based object tracking methods that support bounding box-based object tracking. The main idea behind this work is to propose an asynchronous Event-based Tracking-by-Detection (ETD) method for generic bounding box-based object tracking. To achieve this goal, we present an Adaptive Time-Surface with Linear Time Decay (ATSLTD) event-to-frame conversion algorithm, which asynchronously and effectively warps the spatio-temporal information of asynchronous retinal events to a sequence of ATSLTD frames with clear object contours. We feed the sequence of ATSLTD frames to the proposed ETD method to perform accurate and efficient object tracking, which leverages the high temporal resolution property of event cameras. We compare the proposed ETD method with seven popular object tracking methods, that are based on conventional cameras or event cameras, and two variants of ETD. The experimental results show the superiority of the proposed ETD method in handling various challenging environments.
* 9 pages, 5 figures
Nothing Wasted: Full Contribution Enforcement in Federated Edge Learning
Oct 15, 2021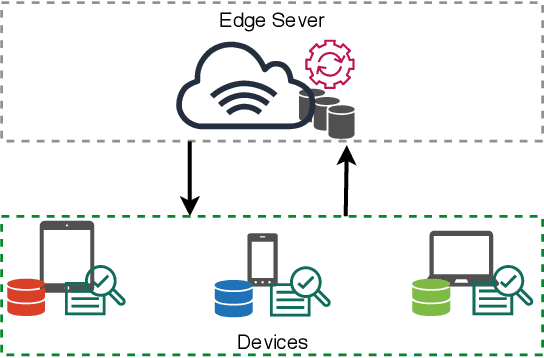

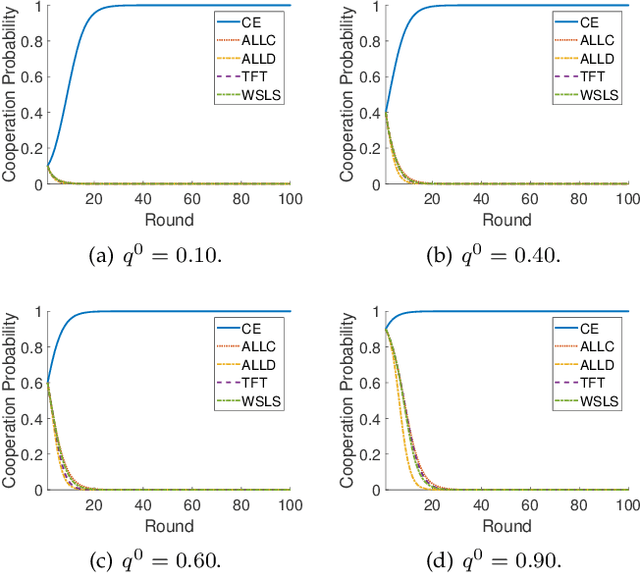
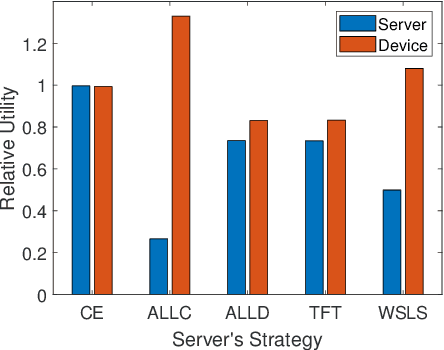
The explosive amount of data generated at the network edge makes mobile edge computing an essential technology to support real-time applications, calling for powerful data processing and analysis provided by machine learning (ML) techniques. In particular, federated edge learning (FEL) becomes prominent in securing the privacy of data owners by keeping the data locally used to train ML models. Existing studies on FEL either utilize in-process optimization or remove unqualified participants in advance. In this paper, we enhance the collaboration from all edge devices in FEL to guarantee that the ML model is trained using all available local data to accelerate the learning process. To that aim, we propose a collective extortion (CE) strategy under the imperfect-information multi-player FEL game, which is proved to be effective in helping the server efficiently elicit the full contribution of all devices without worrying about suffering from any economic loss. Technically, our proposed CE strategy extends the classical extortion strategy in controlling the proportionate share of expected utilities for a single opponent to the swiftly homogeneous control over a group of players, which further presents an attractive trait of being impartial for all participants. Moreover, the CE strategy enriches the game theory hierarchy, facilitating a wider application scope of the extortion strategy. Both theoretical analysis and experimental evaluations validate the effectiveness and fairness of our proposed scheme.
Cooperative Assistance in Robotic Surgery through Multi-Agent Reinforcement Learning
Oct 10, 2021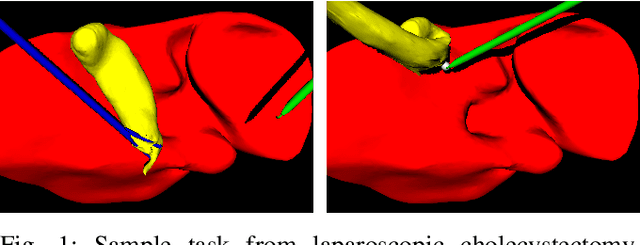

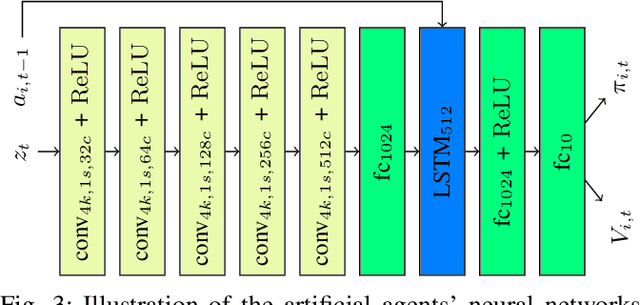
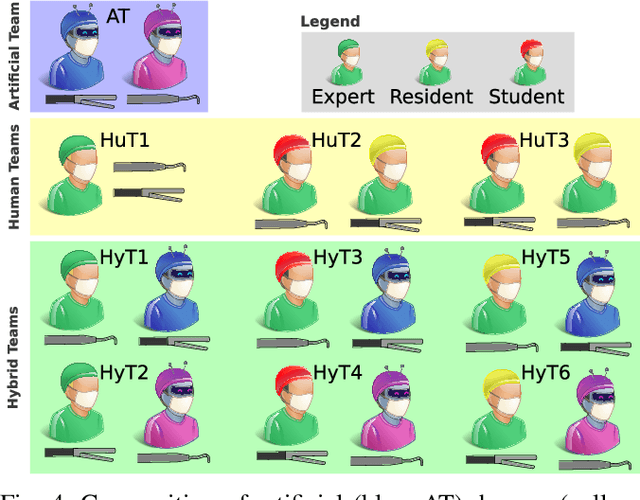
Cognitive cooperative assistance in robot-assisted surgery holds the potential to increase quality of care in minimally invasive interventions. Automation of surgical tasks promises to reduce the mental exertion and fatigue of surgeons. In this work, multi-agent reinforcement learning is demonstrated to be robust to the distribution shift introduced by pairing a learned policy with a human team member. Multi-agent policies are trained directly from images in simulation to control multiple instruments in a sub task of the minimally invasive removal of the gallbladder. These agents are evaluated individually and in cooperation with humans to demonstrate their suitability as autonomous assistants. Compared to human teams, the hybrid teams with artificial agents perform better considering completion time (44.4% to 71.2% shorter) as well as number of collisions (44.7% to 98.0% fewer). Path lengths, however, increase under control of an artificial agent (11.4% to 33.5% longer). A multi-agent formulation of the learning problem was favored over a single-agent formulation on this surgical sub task, due to the sequential learning of the two instruments. This approach may be extended to other tasks that are difficult to formulate within the standard reinforcement learning framework. Multi-agent reinforcement learning may shift the paradigm of cognitive robotic surgery towards seamless cooperation between surgeons and assistive technologies.
REFLACX, a dataset of reports and eye-tracking data for localization of abnormalities in chest x-rays
Sep 29, 2021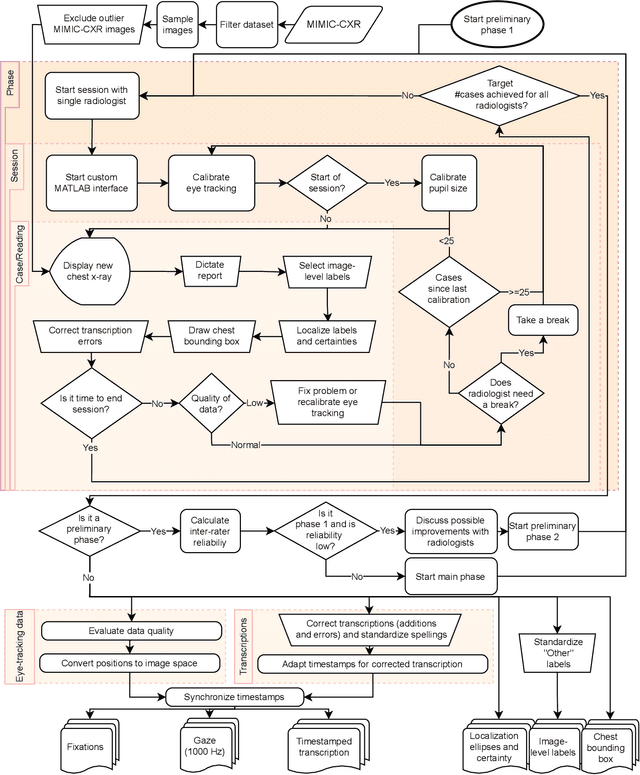
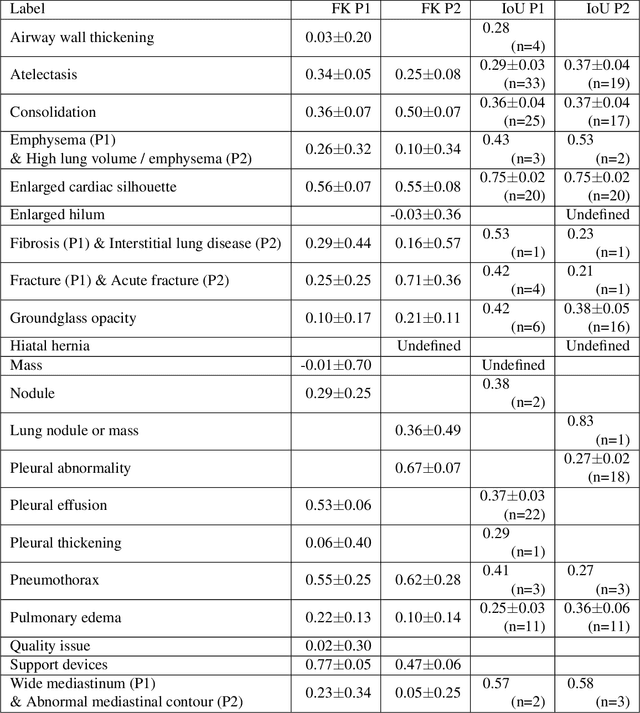
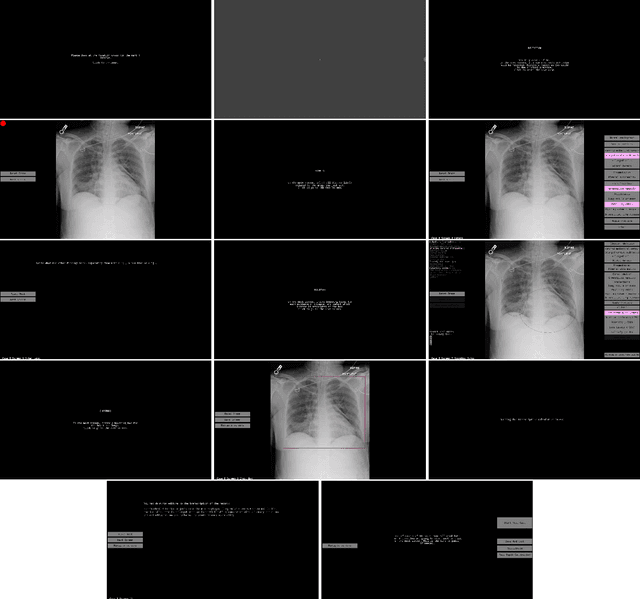
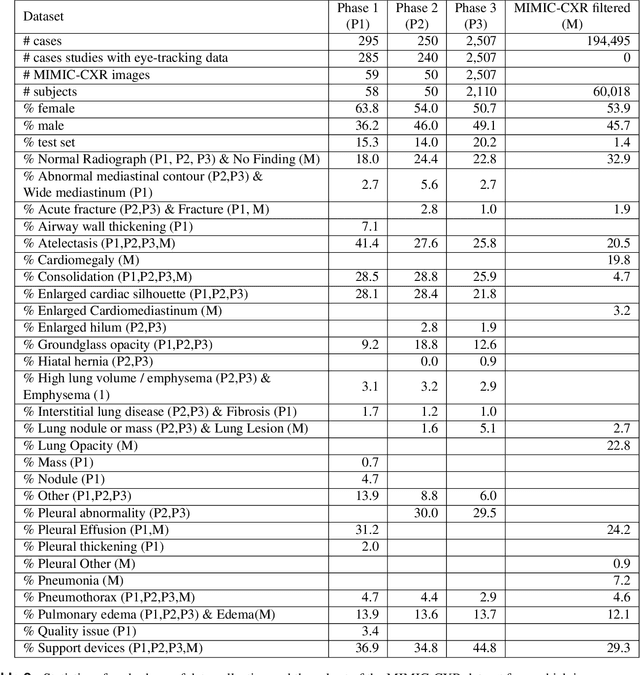
Deep learning has shown recent success in classifying anomalies in chest x-rays, but datasets are still small compared to natural image datasets. Supervision of abnormality localization has been shown to improve trained models, partially compensating for dataset sizes. However, explicitly labeling these anomalies requires an expert and is very time-consuming. We propose a method for collecting implicit localization data using an eye tracker to capture gaze locations and a microphone to capture a dictation of a report, imitating the setup of a reading room, and potentially scalable for large datasets. The resulting REFLACX (Reports and Eye-Tracking Data for Localization of Abnormalities in Chest X-rays) dataset was labeled by five radiologists and contains 3,032 synchronized sets of eye-tracking data and timestamped report transcriptions. We also provide bounding boxes around lungs and heart and validation labels consisting of ellipses localizing abnormalities and image-level labels. Furthermore, a small subset of the data contains readings from all radiologists, allowing for the calculation of inter-rater scores.