 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-Time Anomaly Detection With HMOF Feature
Dec 12, 2018
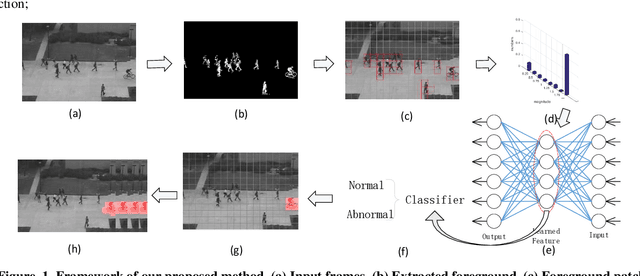
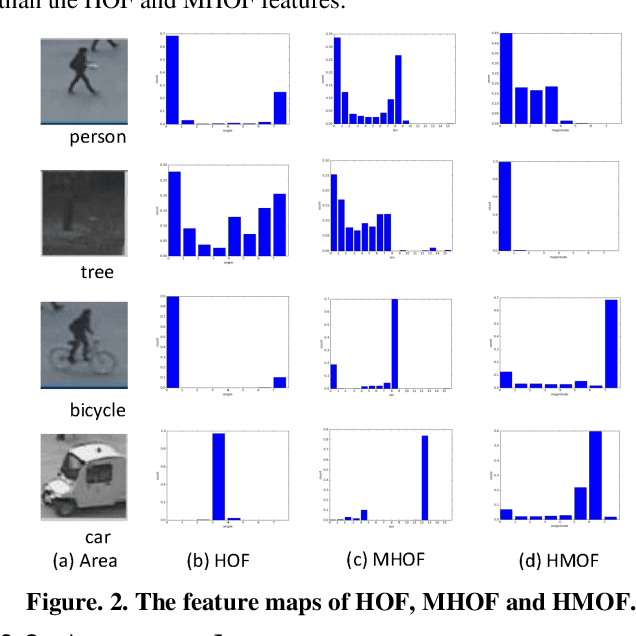
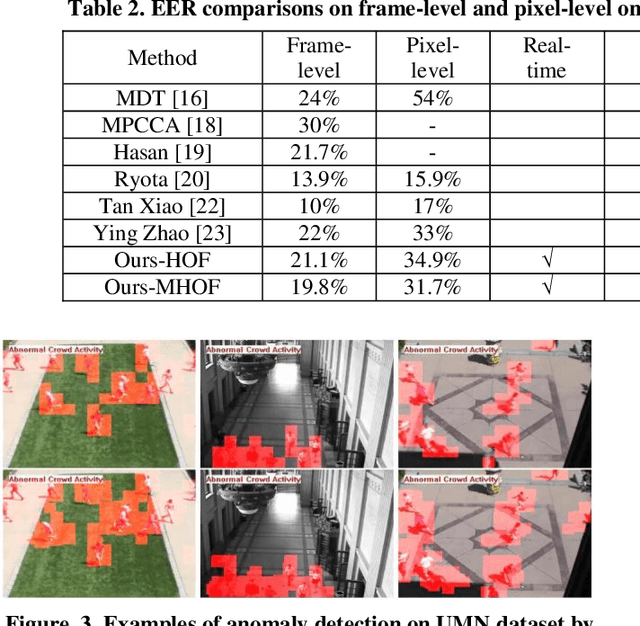

Anomaly detection is a challenging problem in intelligent video surveillance. Most existing methods are computation consuming, which cannot satisfy the real-time requirement. In this paper, we propose a real-time anomaly detection framework with low computational complexity and high efficiency. A new feature, named Histogram of Magnitude Optical Flow (HMOF), is proposed to capture the motion of video patches. Compared with existing feature descriptors, HMOF is more sensitive to motion magnitude and more efficient to distinguish anomaly information. The HMOF features are computed for foreground patches, and are reconstructed by the auto-encoder for better clustering. Then, we use Gaussian Mixture Model (GMM) Classifiers to distinguish anomalies from normal activities in videos. Experimental results show that our framework outperforms state-of-the-art methods, and can reliably detect anomalies in real-time.
Classifying Pattern and Feature Properties to Get a $Θ(n)$ Checker and Reformulation for Sliding Time-Series Constraints
Dec 03, 2019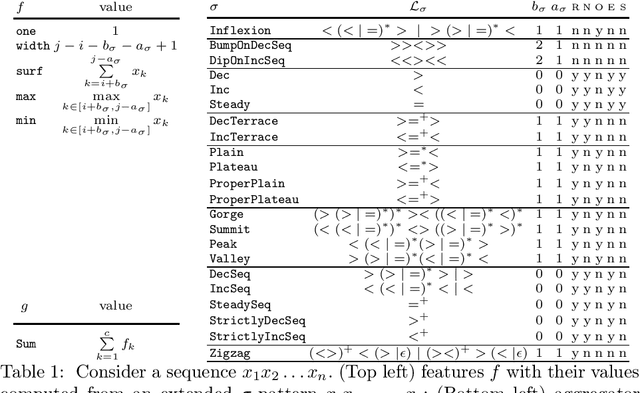

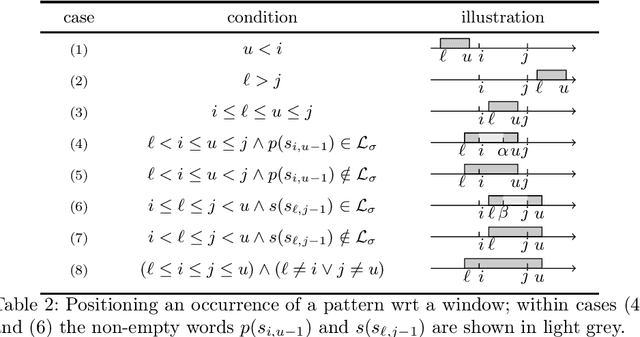
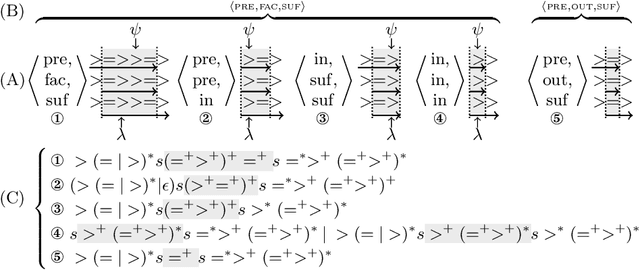
Given, a sequence $\mathcal{X}$ of $n$ variables, a time-series constraint ctr using the Sum aggregator, and a sliding time-series constraint enforcing the constraint ctr on each sliding window of $\mathcal{X}$ of $m$ consecutive variables, we describe a $\Theta(n)$ time complexity checker, as well as a $\Theta(n)$ space complexity reformulation for such sliding constraint.
Group-Node Attention for Community Evolution Prediction
Jul 09, 2021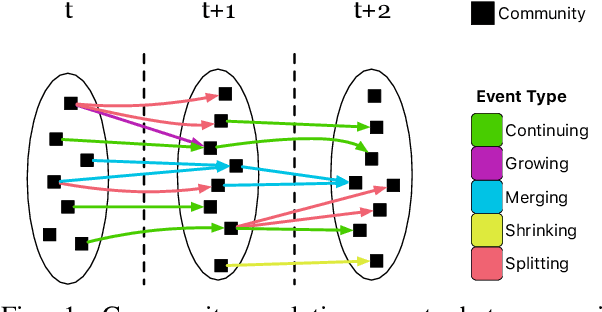
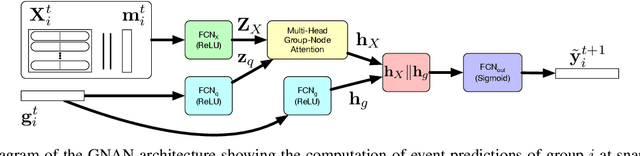
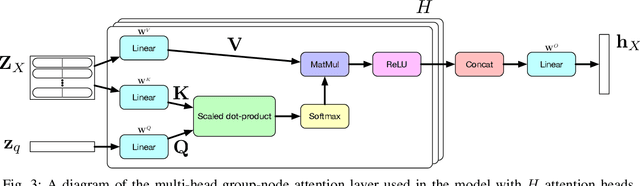
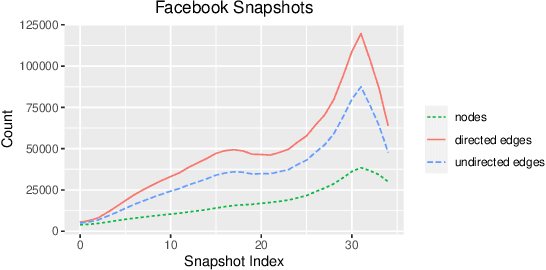
Communities in social networks evolve over time as people enter and leave the network and their activity behaviors shift. The task of predicting structural changes in communities over time is known as community evolution prediction. Existing work in this area has focused on the development of frameworks for defining events while using traditional classification methods to perform the actual prediction. We present a novel graph neural network for predicting community evolution events from structural and temporal information. The model (GNAN) includes a group-node attention component which enables support for variable-sized inputs and learned representation of groups based on member and neighbor node features. A comparative evaluation with standard baseline methods is performed and we demonstrate that our model outperforms the baselines. Additionally, we show the effects of network trends on model performance.
End-to-End Complex-Valued Multidilated Convolutional Neural Network for Joint Acoustic Echo Cancellation and Noise Suppression
Oct 11, 2021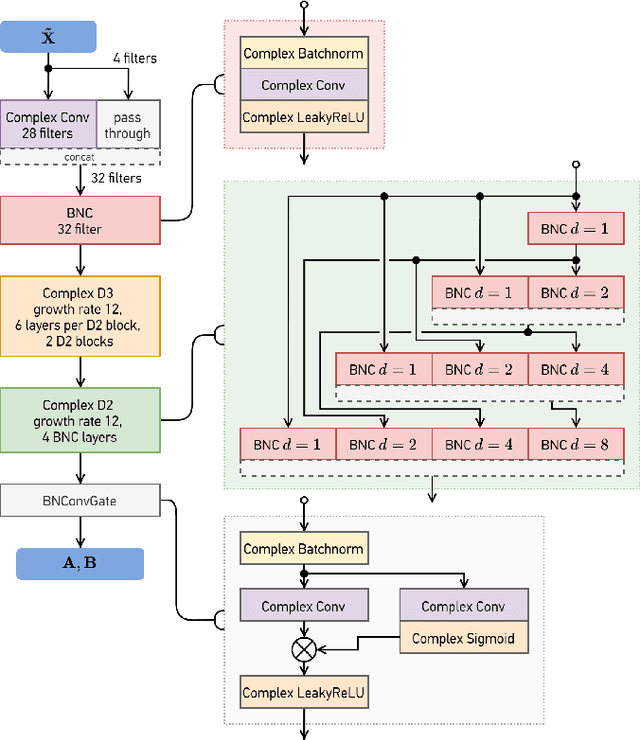
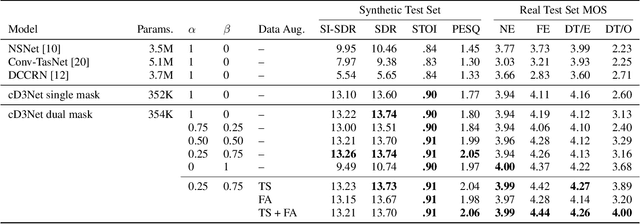
Echo and noise suppression is an integral part of a full-duplex communication system. Many recent acoustic echo cancellation (AEC) systems rely on a separate adaptive filtering module for linear echo suppression and a neural module for residual echo suppression. However, not only do adaptive filtering modules require convergence and remain susceptible to changes in acoustic environments, but this two-stage framework also often introduces unnecessary delays to the AEC system when neural modules are already capable of both linear and nonlinear echo suppression. In this paper, we exploit the offset-compensating ability of complex time-frequency masks and propose an end-to-end complex-valued neural network architecture. The building block of the proposed model is a pseudocomplex extension based on the densely-connected multidilated DenseNet (D3Net) building block, resulting in a very small network of only 354K parameters. The architecture utilized the multi-resolution nature of the D3Net building blocks to eliminate the need for pooling, allowing the network to extract features using large receptive fields without any loss of output resolution. We also propose a dual-mask technique for joint echo and noise suppression with simultaneous speech enhancement. Evaluation on both synthetic and real test sets demonstrated promising results across multiple energy-based metrics and perceptual proxies.
EchoVPR: Echo State Networks for Visual Place Recognition
Oct 11, 2021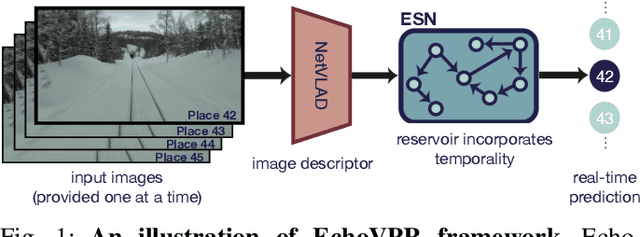

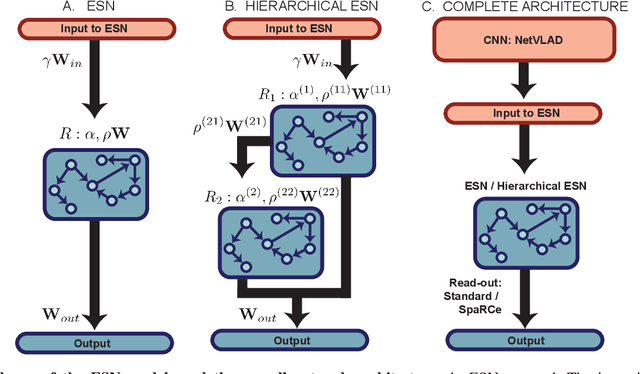
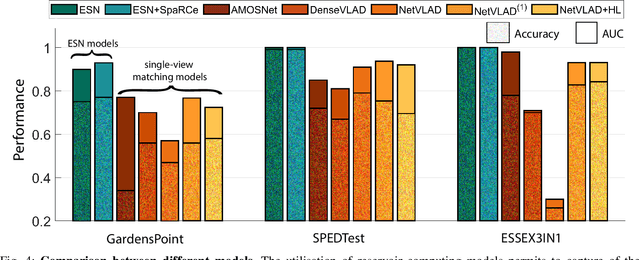
Recognising previously visited locations is an important, but unsolved, task in autonomous navigation. Current visual place recognition (VPR) benchmarks typically challenge models to recover the position of a query image (or images) from sequential datasets that include both spatial and temporal components. Recently, Echo State Network (ESN) varieties have proven particularly powerful at solving machine learning tasks that require spatio-temporal modelling. These networks are simple, yet powerful neural architectures that -- exhibiting memory over multiple time-scales and non-linear high-dimensional representations -- can discover temporal relations in the data while still maintaining linearity in the learning. In this paper, we present a series of ESNs and analyse their applicability to the VPR problem. We report that the addition of ESNs to pre-processed convolutional neural networks led to a dramatic boost in performance in comparison to non-recurrent networks in four standard benchmarks (GardensPoint, SPEDTest, ESSEX3IN1, Nordland) demonstrating that ESNs are able to capture the temporal structure inherent in VPR problems. Moreover, we show that ESNs can outperform class-leading VPR models which also exploit the sequential dynamics of the data. Finally, our results demonstrate that ESNs also improve generalisation abilities, robustness, and accuracy further supporting their suitability to VPR applications.
Neural Waveshaping Synthesis
Jul 27, 2021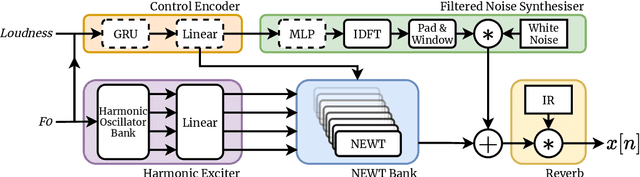
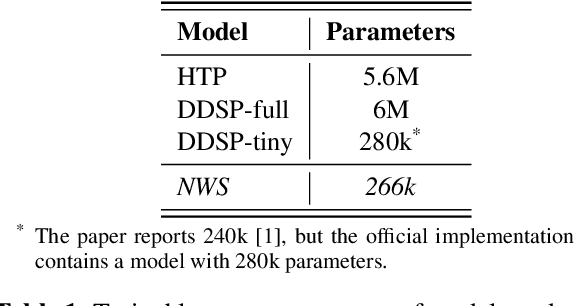
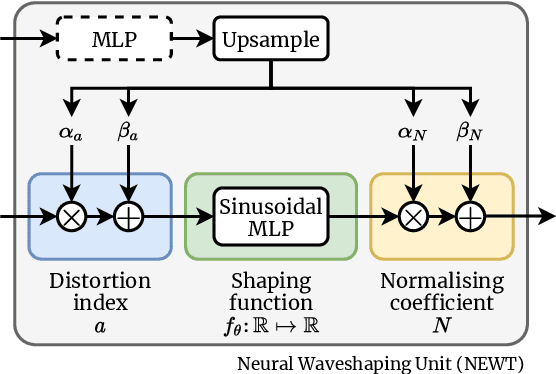
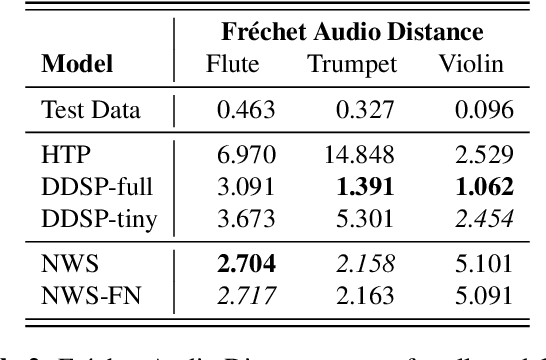
We present the Neural Waveshaping Unit (NEWT): a novel, lightweight, fully causal approach to neural audio synthesis which operates directly in the waveform domain, with an accompanying optimisation (FastNEWT) for efficient CPU inference. The NEWT uses time-distributed multilayer perceptrons with periodic activations to implicitly learn nonlinear transfer functions that encode the characteristics of a target timbre. Once trained, a NEWT can produce complex timbral evolutions by simple affine transformations of its input and output signals. We paired the NEWT with a differentiable noise synthesiser and reverb and found it capable of generating realistic musical instrument performances with only 260k total model parameters, conditioned on F0 and loudness features. We compared our method to state-of-the-art benchmarks with a multi-stimulus listening test and the Fr\'echet Audio Distance and found it performed competitively across the tested timbral domains. Our method significantly outperformed the benchmarks in terms of generation speed, and achieved real-time performance on a consumer CPU, both with and without FastNEWT, suggesting it is a viable basis for future creative sound design tools.
Machine-Learning Identification of Hemodynamics in Coronary Arteries in the Presence of Stenosis
Nov 02, 2021
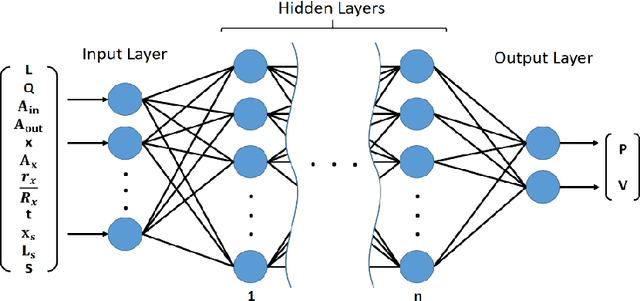
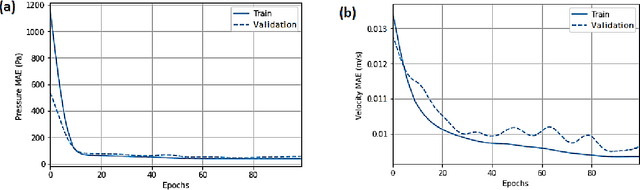
Prediction of the blood flow characteristics is of utmost importance for understanding the behavior of the blood arterial network, especially in the presence of vascular diseases such as stenosis. Computational fluid dynamics (CFD) has provided a powerful and efficient tool to determine these characteristics including the pressure and velocity fields within the network. Despite numerous studies in the field, the extremely high computational cost of CFD has led the researchers to develop new platforms including Machine Learning approaches that instead provide faster analyses at a much lower cost. In this study, we put forth a Deep Neural Network framework to predict flow behavior in a coronary arterial network with different properties in the presence of any abnormality like stenosis. To this end, an artificial neural network (ANN) model is trained using synthetic data so that it can predict the pressure and velocity within the arterial network. The data required to train the neural network were obtained from the CFD analysis of several geometries of arteries with specific features in ABAQUS software. Blood pressure drop caused by stenosis, which is one of the most important factors in the diagnosis of heart diseases, can be predicted using our proposed model knowing the geometrical and flow boundary conditions of any section of the coronary arteries. The efficiency of the model was verified using three real geometries of LAD's vessels. The proposed approach precisely predicts the hemodynamic behavior of the blood flow. The average accuracy of the pressure prediction was 98.7% and the average velocity magnitude accuracy was 93.2%. According to the results of testing the model on three patient-specific geometries, model can be considered as an alternative to finite element methods as well as other hard-to-implement and time-consuming numerical simulations.
Optimal Control via Combined Inference and Numerical Optimization
Sep 23, 2021

Derivative based optimization methods are efficient at solving optimal control problems near local optima. However, their ability to converge halts when derivative information vanishes. The inference approach to optimal control does not have strict requirements on the objective landscape. However, sampling, the primary tool for solving such problems, tends to be much slower in computation time. We propose a new method that combines second order methods with inference. We utilise the Kullback Leibler (KL) control framework to formulate an inference problem that computes the optimal controls from an adaptive distribution approximating the solution of the second order method. Our method allows for combining simple convex and non convex cost functions. This simplifies the process of cost function design and leverages the strengths of both inference and second order optimization. We compare our method to Model Predictive Path Integral (MPPI) and iterative Linear Quadratic Regulator (iLQG), outperforming both in sample efficiency and quality on manipulation and obstacle avoidance tasks.
DSEE: Dually Sparsity-embedded Efficient Tuning of Pre-trained Language Models
Oct 30, 2021
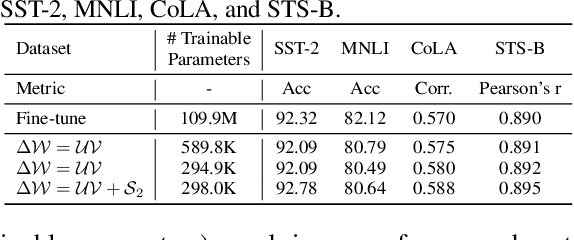
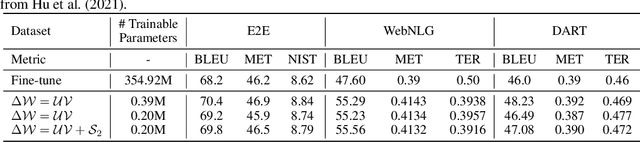
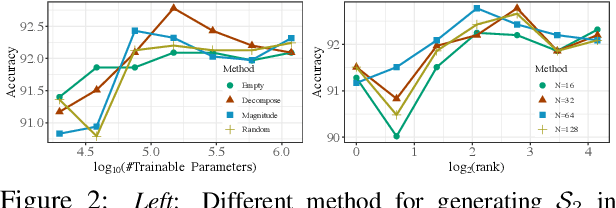
Gigantic pre-trained models have become central to natural language processing (NLP), serving as the starting point for fine-tuning towards a range of downstream tasks. However, two pain points persist for this paradigm: (a) as the pre-trained models grow bigger (e.g., 175B parameters for GPT-3), even the fine-tuning process can be time-consuming and computationally expensive; (b) the fine-tuned model has the same size as its starting point by default, which is neither sensible due to its more specialized functionality, nor practical since many fine-tuned models will be deployed in resource-constrained environments. To address these pain points, we propose a framework for resource- and parameter-efficient fine-tuning by leveraging the sparsity prior in both weight updates and the final model weights. Our proposed framework, dubbed Dually Sparsity-Embedded Efficient Tuning (DSEE), aims to achieve two key objectives: (i) parameter efficient fine-tuning - by enforcing sparsity-aware weight updates on top of the pre-trained weights; and (ii) resource-efficient inference - by encouraging a sparse weight structure towards the final fine-tuned model. We leverage sparsity in these two directions by exploiting both unstructured and structured sparse patterns in pre-trained language models via magnitude-based pruning and $\ell_1$ sparse regularization. Extensive experiments and in-depth investigations, with diverse network backbones (i.e., BERT, GPT-2, and DeBERTa) on dozens of datasets, consistently demonstrate highly impressive parameter-/training-/inference-efficiency, while maintaining competitive downstream transfer performance. For instance, our DSEE-BERT obtains about $35\%$ inference FLOPs savings with <1% trainable parameters and comparable performance to conventional fine-tuning. Codes are available in https://github.com/VITA-Group/DSEE.
NeuroCartography: Scalable Automatic Visual Summarization of Concepts in Deep Neural Networks
Aug 29, 2021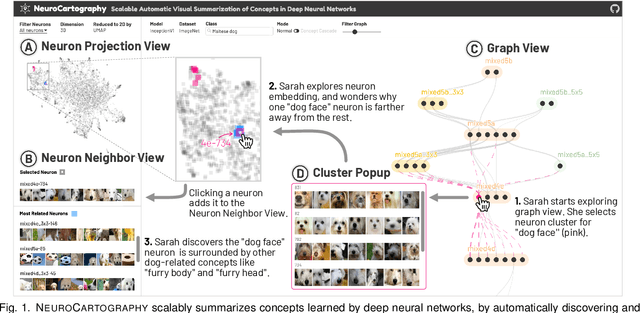


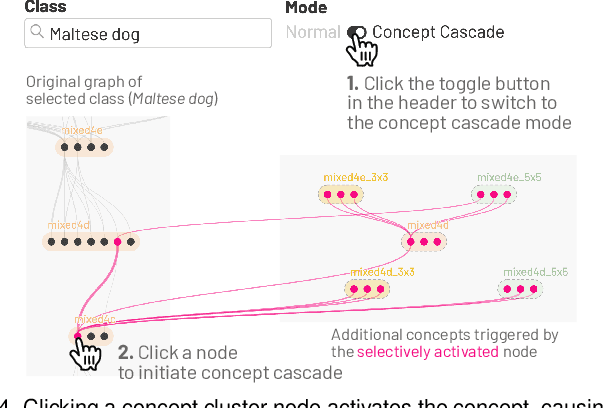
Existing research on making sense of deep neural networks often focuses on neuron-level interpretation, which may not adequately capture the bigger picture of how concepts are collectively encoded by multiple neurons. We present NeuroCartography, an interactive system that scalably summarizes and visualizes concepts learned by neural networks. It automatically discovers and groups neurons that detect the same concepts, and describes how such neuron groups interact to form higher-level concepts and the subsequent predictions. NeuroCartography introduces two scalable summarization techniques: (1) neuron clustering groups neurons based on the semantic similarity of the concepts detected by neurons (e.g., neurons detecting "dog faces" of different breeds are grouped); and (2) neuron embedding encodes the associations between related concepts based on how often they co-occur (e.g., neurons detecting "dog face" and "dog tail" are placed closer in the embedding space). Key to our scalable techniques is the ability to efficiently compute all neuron pairs' relationships, in time linear to the number of neurons instead of quadratic time. NeuroCartography scales to large data, such as the ImageNet dataset with 1.2M images. The system's tightly coordinated views integrate the scalable techniques to visualize the concepts and their relationships, projecting the concept associations to a 2D space in Neuron Projection View, and summarizing neuron clusters and their relationships in Graph View. Through a large-scale human evaluation, we demonstrate that our technique discovers neuron groups that represent coherent, human-meaningful concepts. And through usage scenarios, we describe how our approaches enable interesting and surprising discoveries, such as concept cascades of related and isolated concepts. The NeuroCartography visualization runs in modern browsers and is open-sourced.