 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Anomaly Detection in Predictive Maintenance: A New Evaluation Framework for Temporal Unsupervised Anomaly Detection Algorithms
May 26, 2021

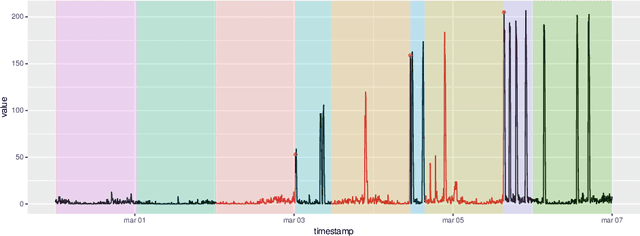
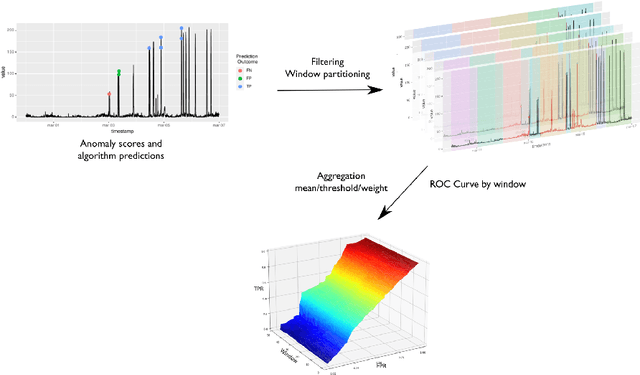

The research in anomaly detection lacks a unified definition of what represents an anomalous instance. Discrepancies in the nature itself of an anomaly lead to multiple paradigms of algorithms design and experimentation. Predictive maintenance is a special case, where the anomaly represents a failure that must be prevented. Related time-series research as outlier and novelty detection or time-series classification does not apply to the concept of an anomaly in this field, because they are not single points which have not been seen previously and may not be precisely annotated. Moreover, due to the lack of annotated anomalous data, many benchmarks are adapted from supervised scenarios. To address these issues, we generalise the concept of positive and negative instances to intervals to be able to evaluate unsupervised anomaly detection algorithms. We also preserve the imbalance scheme for evaluation through the proposal of the Preceding Window ROC, a generalisation for the calculation of ROC curves for time-series scenarios. We also adapt the mechanism from a established time-series anomaly detection benchmark to the proposed generalisations to reward early detection. Therefore, the proposal represents a flexible evaluation framework for the different scenarios. To show the usefulness of this definition, we include a case study of Big Data algorithms with a real-world time-series problem provided by the company ArcelorMittal, and compare the proposal with an evaluation method.
Comparison of Deep learning models on time series forecasting : a case study of Dissolved Oxygen Prediction
Nov 21, 2019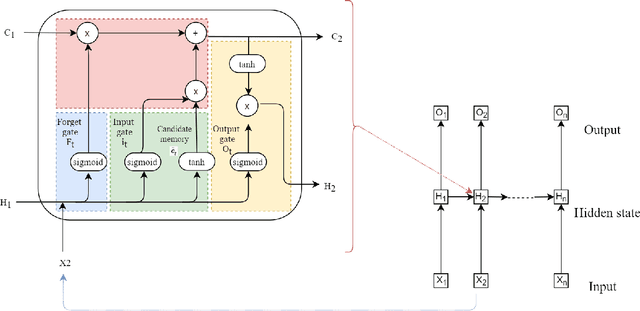
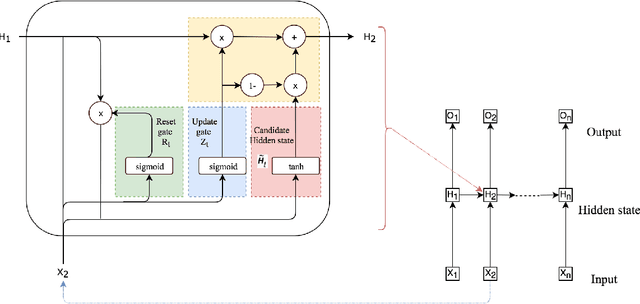
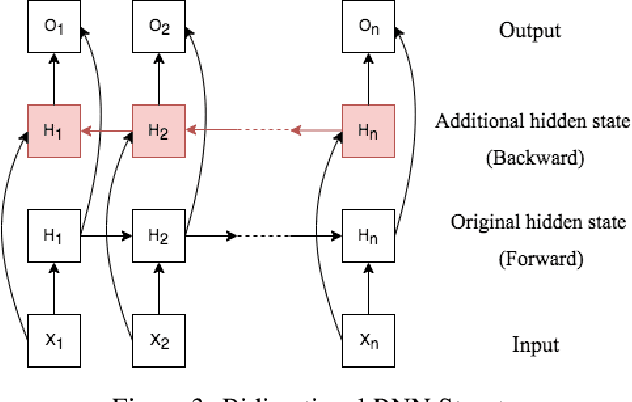
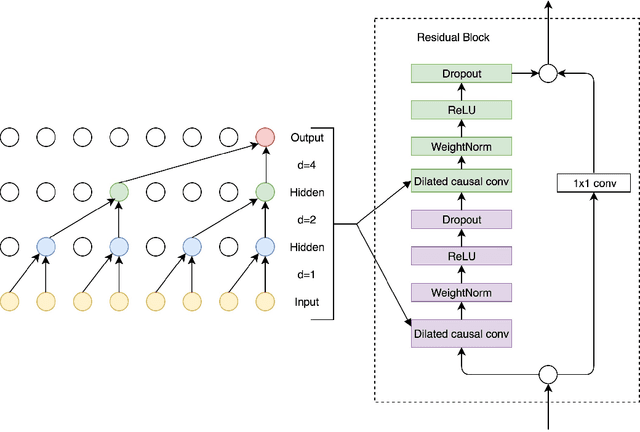
Deep learning has achieved impressive prediction performance in the field of sequence learning recently. Dissolved oxygen prediction, as a kind of time-series forecasting, is suitable for this technique. Although many researchers have developed hybrid models or variant models based on deep learning techniques, there is no comprehensive and sound comparison among the deep learning models in this field currently. Plus, most previous studies focused on one-step forecasting by using a small data set. As the convenient access to high-frequency data, this paper compares multi-step deep learning forecasting by using walk-forward validation. Specifically, we test Convolutional Neural Network (CNN), Temporal Convolutional Network (TCN), Long Short-Term Memory (LSTM), Gated Recurrent Unit (GRU), Bidirectional Recurrent Neural Network (BiRNN) based on the real-time data recorded automatically at a fixed observation point in the Yangtze River from 2012 to 2016. By comparing the average accumulated statistical metrics of root mean square error (RMSE), mean absolute error (MAE), and coefficient of determination in each time step, We find for multi-step time series forecasting, the average performance of each time step does not decrease linearly. GRU outperforms other models with significant advantages.
Detect and Perturb: Neutral Rewriting of Biased and Sensitive Text via Gradient-based Decoding
Sep 24, 2021
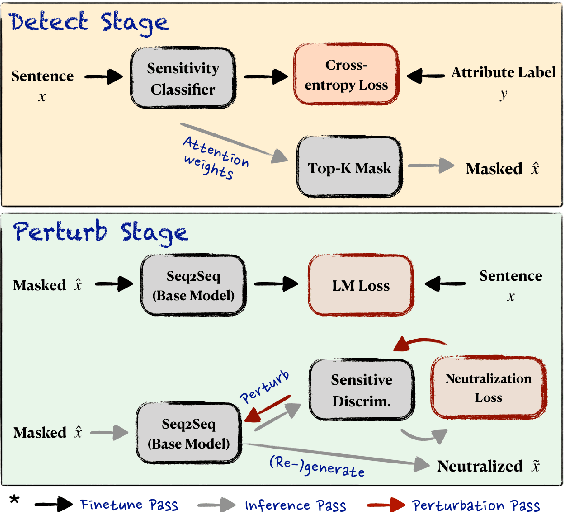
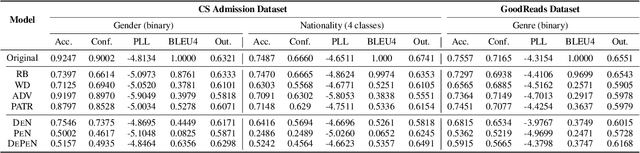
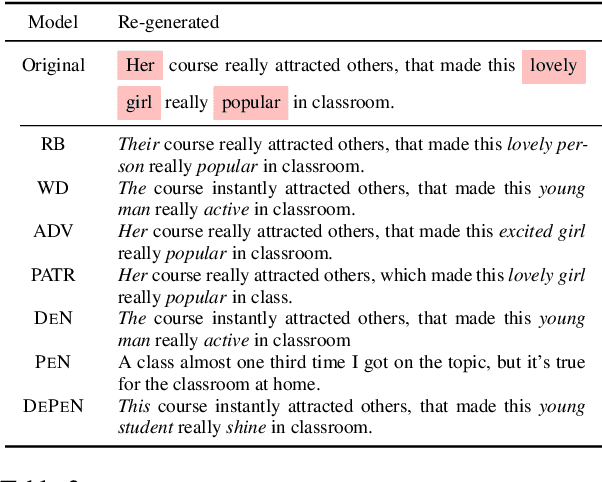
Written language carries explicit and implicit biases that can distract from meaningful signals. For example, letters of reference may describe male and female candidates differently, or their writing style may indirectly reveal demographic characteristics. At best, such biases distract from the meaningful content of the text; at worst they can lead to unfair outcomes. We investigate the challenge of re-generating input sentences to 'neutralize' sensitive attributes while maintaining the semantic meaning of the original text (e.g. is the candidate qualified?). We propose a gradient-based rewriting framework, Detect and Perturb to Neutralize (DEPEN), that first detects sensitive components and masks them for regeneration, then perturbs the generation model at decoding time under a neutralizing constraint that pushes the (predicted) distribution of sensitive attributes towards a uniform distribution. Our experiments in two different scenarios show that DEPEN can regenerate fluent alternatives that are neutral in the sensitive attribute while maintaining the semantics of other attributes.
GCNScheduler: Scheduling Distributed Computing Applications using Graph Convolutional Networks
Oct 22, 2021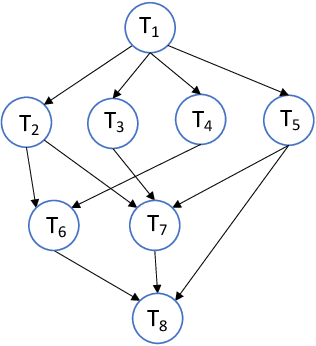
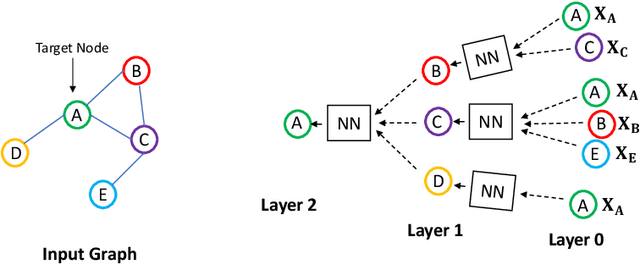

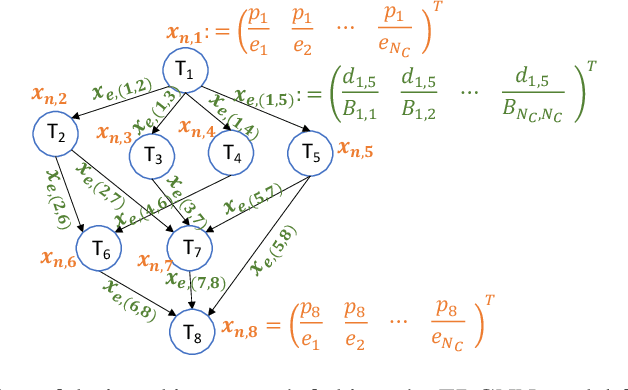
We consider the classical problem of scheduling task graphs corresponding to complex applications on distributed computing systems. A number of heuristics have been previously proposed to optimize task scheduling with respect to metrics such as makespan and throughput. However, they tend to be slow to run, particularly for larger problem instances, limiting their applicability in more dynamic systems. Motivated by the goal of solving these problems more rapidly, we propose, for the first time, a graph convolutional network-based scheduler (GCNScheduler). By carefully integrating an inter-task data dependency structure with network settings into an input graph and feeding it to an appropriate GCN, the GCNScheduler can efficiently schedule tasks of complex applications for a given objective. We evaluate our scheme with baselines through simulations. We show that not only can our scheme quickly and efficiently learn from existing scheduling schemes, but also it can easily be applied to large-scale settings where current scheduling schemes fail to handle. We show that it achieves better makespan than the classic HEFT algorithm, and almost the same throughput as throughput-oriented HEFT (TP-HEFT), while providing several orders of magnitude faster scheduling times in both cases. For example, for makespan minimization, GCNScheduler schedules 50-node task graphs in about 4 milliseconds while HEFT takes more than 1500 seconds; and for throughput maximization, GCNScheduler schedules 100-node task graphs in about 3.3 milliseconds, compared to about 6.9 seconds for TP-HEFT.
Safe, Deterministic Trajectory Planning for Unstructured and Partially Occluded Environments
Sep 30, 2021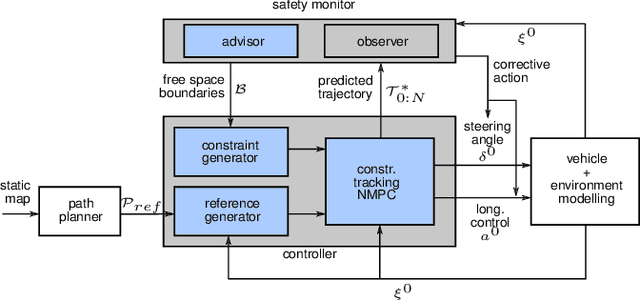

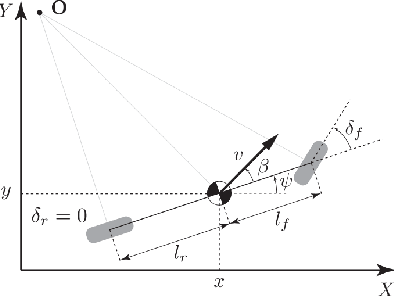
Ensuring safe behavior for automated vehicles in unregulated traffic areas poses a complex challenge for the industry. It is an open problem to provide scalable and certifiable solutions to this challenge. We derive a trajectory planner based on model predictive control which interoperates with a monitoring system for pedestrian safety based on cellular automata. The combined planner-monitor system is demonstrated on the example of a narrow indoor parking environment. The system features deterministic behavior, mitigating the immanent risk of black boxes and offering full certifiability. By using fundamental and conservative prediction models of pedestrians the monitor is able to determine a safe drivable area in the partially occluded and unstructured parking environment. The information is fed to the trajectory planner which ensures the vehicle remains in the safe drivable area at any time through constrained optimization. We show how the approach enables solving plenty of situations in tight parking garage scenarios. Even though conservative prediction models are applied, evaluations indicate a performant system for the tested low-speed navigation.
EdgeFlow: Achieving Practical Interactive Segmentation with Edge-Guided Flow
Sep 20, 2021
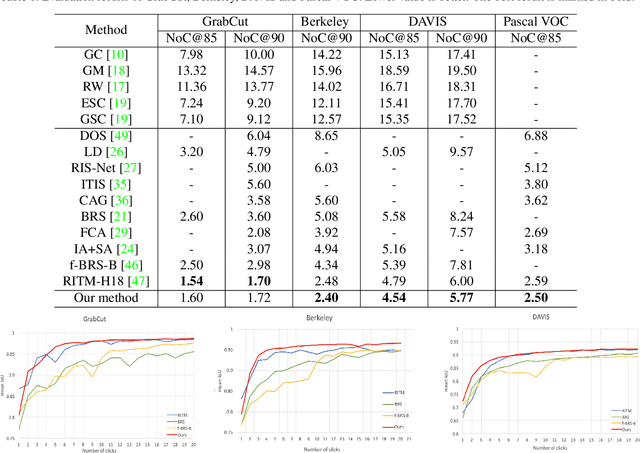
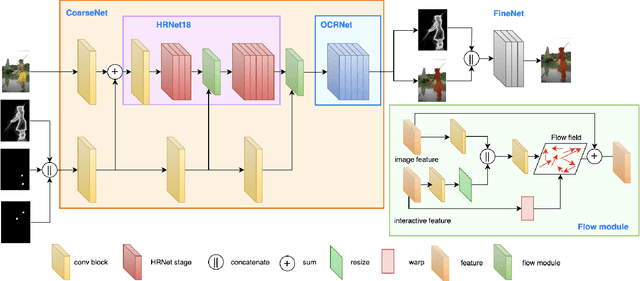

High-quality training data play a key role in image segmentation tasks. Usually, pixel-level annotations are expensive, laborious and time-consuming for the large volume of training data. To reduce labelling cost and improve segmentation quality, interactive segmentation methods have been proposed, which provide the result with just a few clicks. However, their performance does not meet the requirements of practical segmentation tasks in terms of speed and accuracy. In this work, we propose EdgeFlow, a novel architecture that fully utilizes interactive information of user clicks with edge-guided flow. Our method achieves state-of-the-art performance without any post-processing or iterative optimization scheme. Comprehensive experiments on benchmarks also demonstrate the superiority of our method. In addition, with the proposed method, we develop an efficient interactive segmentation tool for practical data annotation tasks. The source code and tool is avaliable at https://github.com/PaddlePaddle/PaddleSeg.
Towards Efficient Post-training Quantization of Pre-trained Language Models
Sep 30, 2021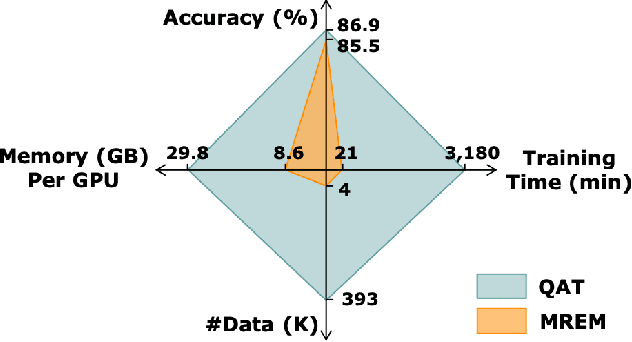
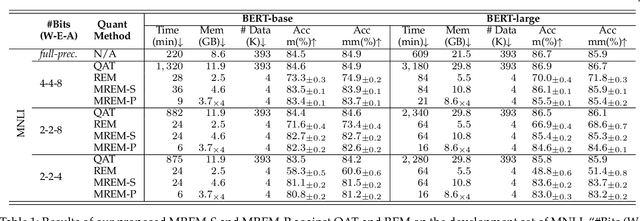
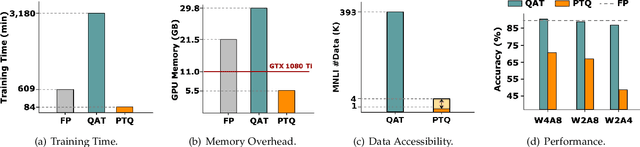
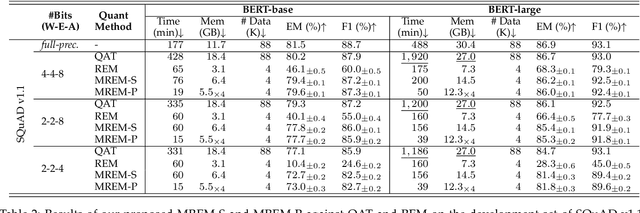
Network quantization has gained increasing attention with the rapid growth of large pre-trained language models~(PLMs). However, most existing quantization methods for PLMs follow quantization-aware training~(QAT) that requires end-to-end training with full access to the entire dataset. Therefore, they suffer from slow training, large memory overhead, and data security issues. In this paper, we study post-training quantization~(PTQ) of PLMs, and propose module-wise quantization error minimization~(MREM), an efficient solution to mitigate these issues. By partitioning the PLM into multiple modules, we minimize the reconstruction error incurred by quantization for each module. In addition, we design a new model parallel training strategy such that each module can be trained locally on separate computing devices without waiting for preceding modules, which brings nearly the theoretical training speed-up (e.g., $4\times$ on $4$ GPUs). Experiments on GLUE and SQuAD benchmarks show that our proposed PTQ solution not only performs close to QAT, but also enjoys significant reductions in training time, memory overhead, and data consumption.
On Efficiently Explaining Graph-Based Classifiers
Jun 03, 2021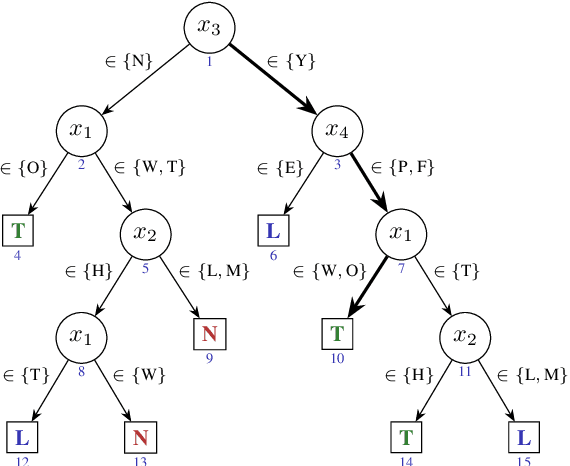
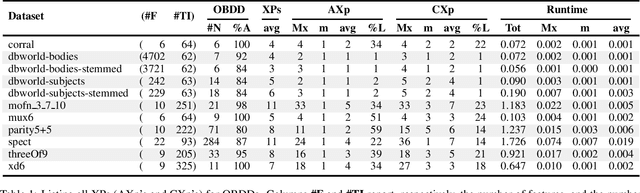
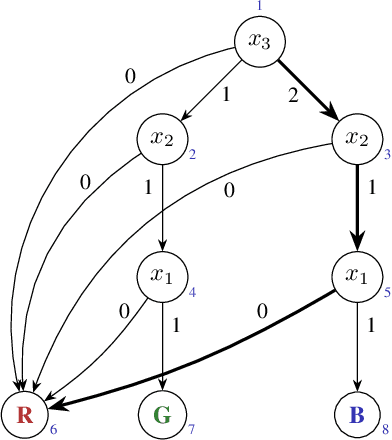
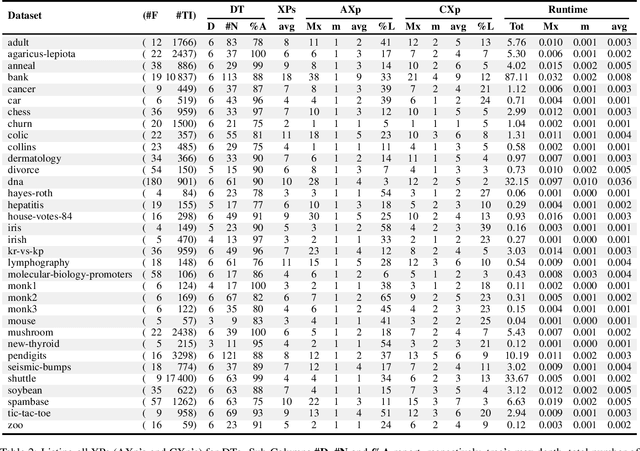
Recent work has shown that not only decision trees (DTs) may not be interpretable but also proposed a polynomial-time algorithm for computing one PI-explanation of a DT. This paper shows that for a wide range of classifiers, globally referred to as decision graphs, and which include decision trees and binary decision diagrams, but also their multi-valued variants, there exist polynomial-time algorithms for computing one PI-explanation. In addition, the paper also proposes a polynomial-time algorithm for computing one contrastive explanation. These novel algorithms build on explanation graphs (XpG's). XpG's denote a graph representation that enables both theoretical and practically efficient computation of explanations for decision graphs. Furthermore, the paper pro- poses a practically efficient solution for the enumeration of explanations, and studies the complexity of deciding whether a given feature is included in some explanation. For the concrete case of decision trees, the paper shows that the set of all contrastive explanations can be enumerated in polynomial time. Finally, the experimental results validate the practical applicability of the algorithms proposed in the paper on a wide range of publicly available benchmarks.
Deep speech inpainting of time-frequency masks
Oct 22, 2019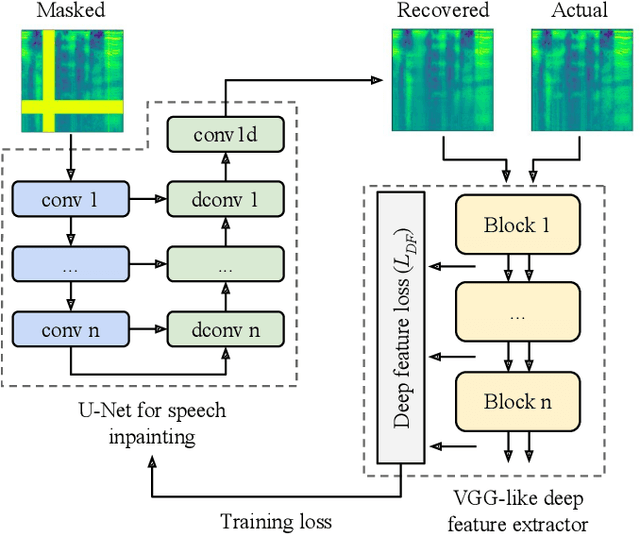
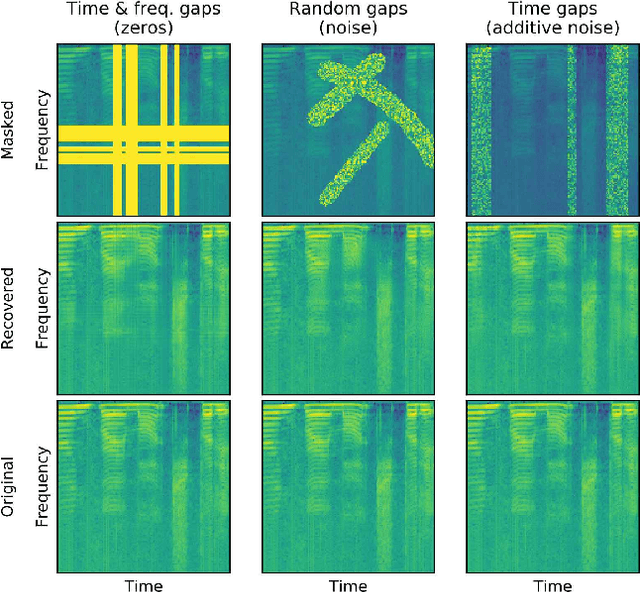
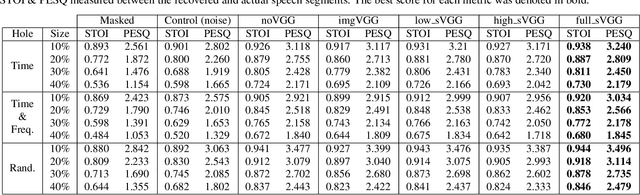
In particularly noisy environments, transient loud intrusions can completely overpower parts of the speech signal, leading to an inevitable loss of information. Recent algorithms for noise suppression often yield impressive results but tend to struggle when the signal-to-noise ratio (SNR) of the mixture is low or when parts of the signal are missing. To address these issues, here we introduce an end-to-end framework for the retrieval of missing or severely distorted parts of time-frequency representation of speech, from the short-term context, thus speech inpainting. The framework is based on a convolutional U-Net trained via deep feature losses, obtained through speechVGG, a deep speech feature extractor pre-trained on the word classification task. Our evaluation results demonstrate that the proposed framework is effective at recovering large portions of missing or distorted parts of speech. Specifically, it yields notable improvements in STOI & PESQ objective metrics, as assessed using the LibriSpeech dataset.
Integrating Deep Learning and Augmented Reality to Enhance Situational Awareness in Firefighting Environments
Jul 23, 2021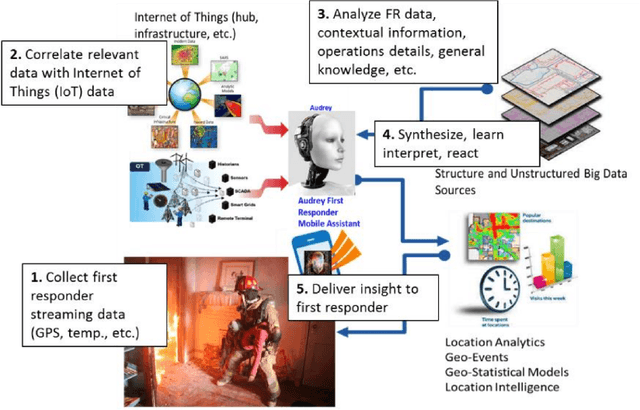
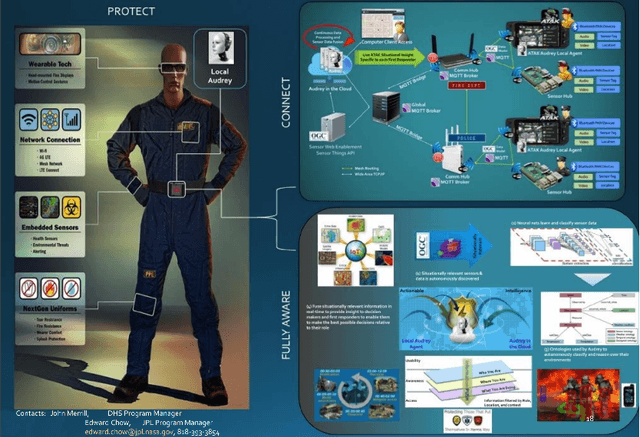
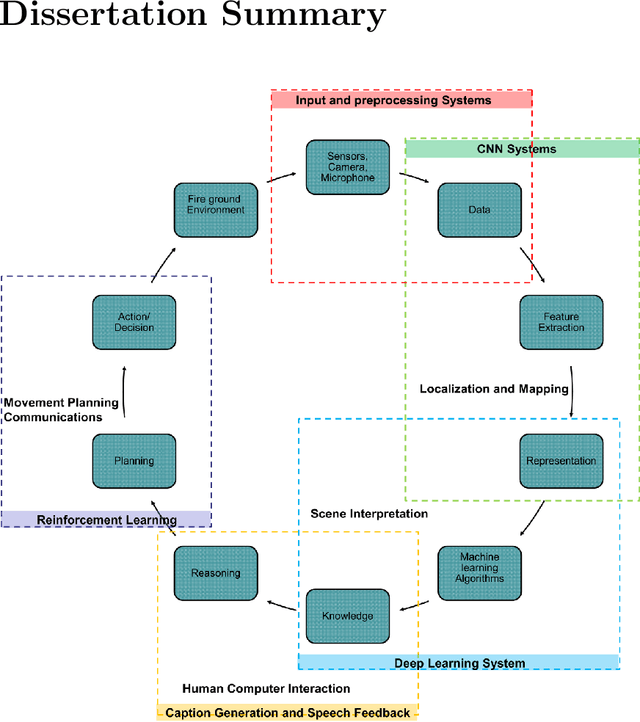
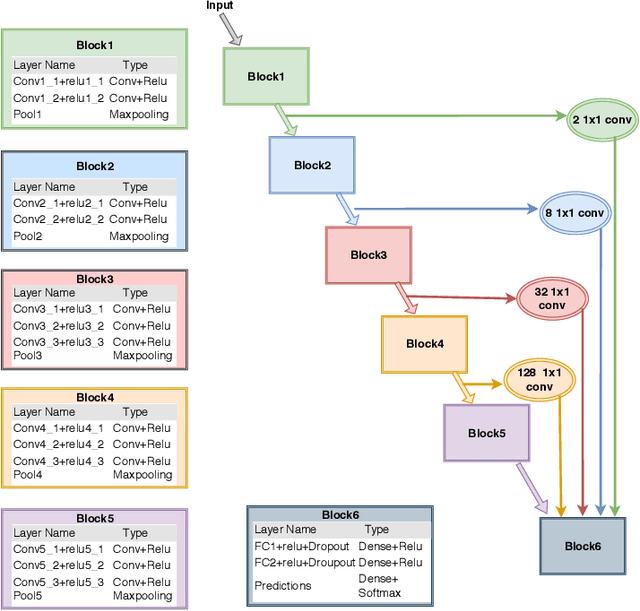
We present a new four-pronged approach to build firefighter's situational awareness for the first time in the literature. We construct a series of deep learning frameworks built on top of one another to enhance the safety, efficiency, and successful completion of rescue missions conducted by firefighters in emergency first response settings. First, we used a deep Convolutional Neural Network (CNN) system to classify and identify objects of interest from thermal imagery in real-time. Next, we extended this CNN framework for object detection, tracking, segmentation with a Mask RCNN framework, and scene description with a multimodal natural language processing(NLP) framework. Third, we built a deep Q-learning-based agent, immune to stress-induced disorientation and anxiety, capable of making clear navigation decisions based on the observed and stored facts in live-fire environments. Finally, we used a low computational unsupervised learning technique called tensor decomposition to perform meaningful feature extraction for anomaly detection in real-time. With these ad-hoc deep learning structures, we built the artificial intelligence system's backbone for firefighters' situational awareness. To bring the designed system into usage by firefighters, we designed a physical structure where the processed results are used as inputs in the creation of an augmented reality capable of advising firefighters of their location and key features around them, which are vital to the rescue operation at hand, as well as a path planning feature that acts as a virtual guide to assist disoriented first responders in getting back to safety. When combined, these four approaches present a novel approach to information understanding, transfer, and synthesis that could dramatically improve firefighter response and efficacy and reduce life loss.