 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Modulation Layer to Increase Neural Network Robustness Against Data Quality Issues
Jul 19, 2021
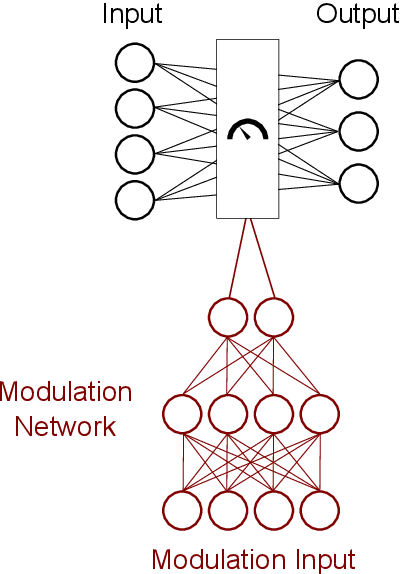
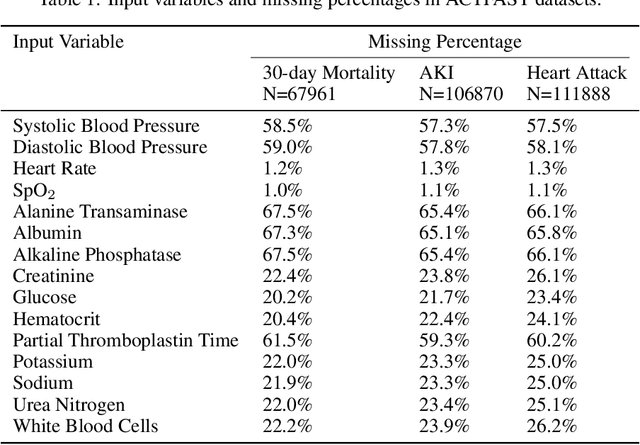
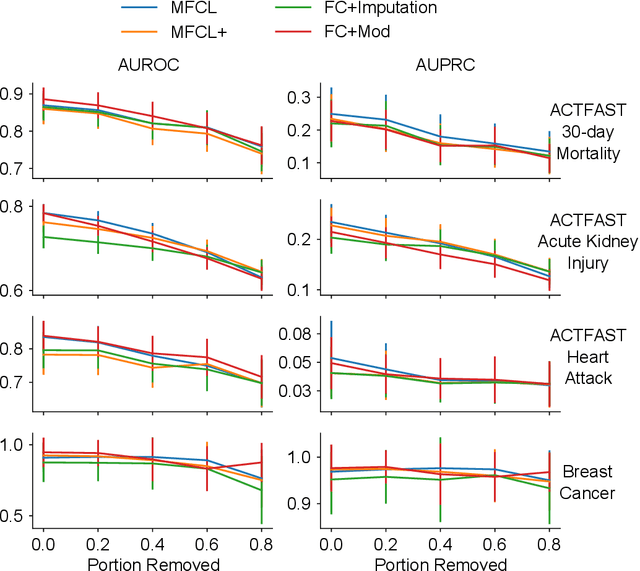
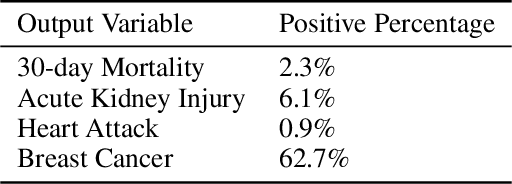
Data quality is a common problem in machine learning, especially in high-stakes settings such as healthcare. Missing data affects accuracy, calibration, and feature attribution in complex patterns. Developers often train models on carefully curated datasets to minimize missing data bias; however, this reduces the usability of such models in production environments, such as real-time healthcare records. Making machine learning models robust to missing data is therefore crucial for practical application. While some classifiers naturally handle missing data, others, such as deep neural networks, are not designed for unknown values. We propose a novel neural network modification to mitigate the impacts of missing data. The approach is inspired by neuromodulation that is performed by biological neural networks. Our proposal replaces the fixed weights of a fully-connected layer with a function of an additional input (reliability score) at each input, mimicking the ability of cortex to up- and down-weight inputs based on the presence of other data. The modulation function is jointly learned with the main task using a multi-layer perceptron. We tested our modulating fully connected layer on multiple classification, regression, and imputation problems, and it either improved performance or generated comparable performance to conventional neural network architectures concatenating reliability to the inputs. Models with modulating layers were more robust against degradation of data quality by introducing additional missingness at evaluation time. These results suggest that explicitly accounting for reduced information quality with a modulating fully connected layer can enable the deployment of artificial intelligence systems in real-time settings.
Adaptive Fusion Affinity Graph with Noise-free Online Low-rank Representation for Natural Image Segmentation
Oct 22, 2021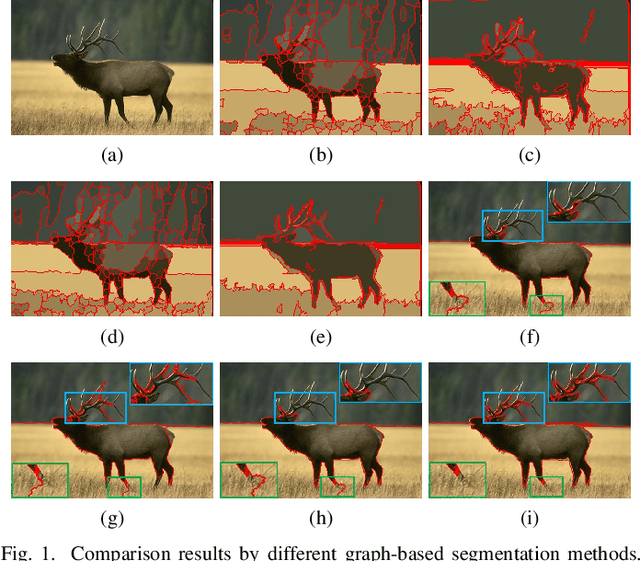



Affinity graph-based segmentation methods have become a major trend in computer vision. The performance of these methods relies on the constructed affinity graph, with particular emphasis on the neighborhood topology and pairwise affinities among superpixels. Due to the advantages of assimilating different graphs, a multi-scale fusion graph has a better performance than a single graph with single-scale. However, these methods ignore the noise from images which influences the accuracy of pairwise similarities. Multi-scale combinatorial grouping and graph fusion also generate a higher computational complexity. In this paper, we propose an adaptive fusion affinity graph (AFA-graph) with noise-free low-rank representation in an online manner for natural image segmentation. An input image is first over-segmented into superpixels at different scales and then filtered by the proposed improved kernel density estimation method. Moreover, we select global nodes of these superpixels on the basis of their subspace-preserving presentation, which reveals the feature distribution of superpixels exactly. To reduce time complexity while improving performance, a sparse representation of global nodes based on noise-free online low-rank representation is used to obtain a global graph at each scale. The global graph is finally used to update a local graph which is built upon all superpixels at each scale. Experimental results on the BSD300, BSD500, MSRC, SBD, and PASCAL VOC show the effectiveness of AFA-graph in comparison with state-of-the-art approaches.
Estimating Mean Speed-of-Sound from Sequence-Dependent Geometric Disparities
Sep 24, 2021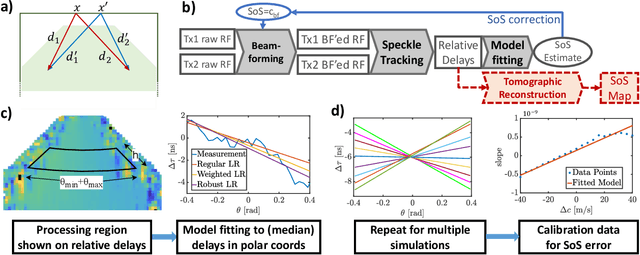
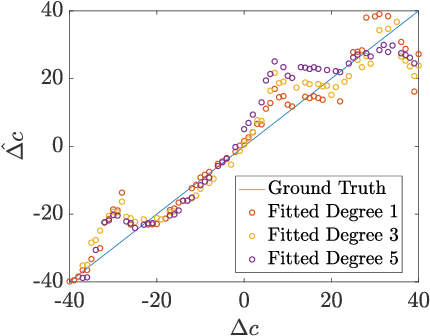
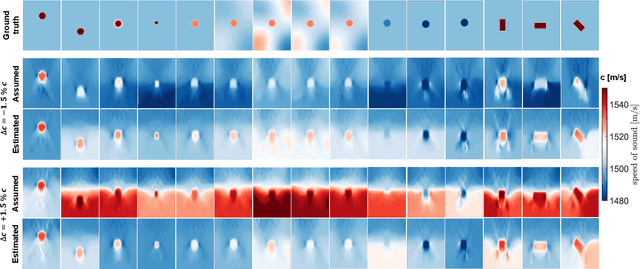
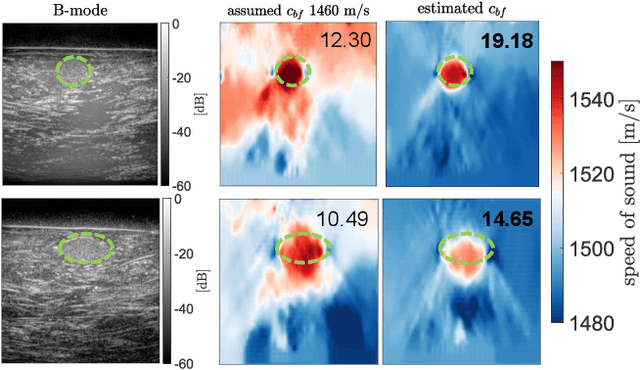
In ultrasound beamforming, focusing time delays are typically computed with a spatially constant speed-of-sound (SoS) assumption. A mismatch between beamforming and true medium SoS then leads to aberration artifacts. Other imaging techniques such as spatially-resolved SoS reconstruction using tomographic techniques also rely on a good SoS estimate for initial beamforming. In this work, we exploit spatially-varying geometric disparities in the transmit and receive paths of multiple sequences for estimating a mean medium SoS. We use images from diverging waves beamformed with an assumed SoS, and propose a model fitting method for estimating the SoS offset. We demonstrate the effectiveness of our proposed method for tomographic SoS reconstruction. With corrected beamforming SoS, the reconstruction accuracy on simulated data was improved by 63% and 29%, respectively, for an initial SoS over- and under-estimation of 1.5%. We further demonstrate our proposed method on a breast phantom, indicating substantial improvement in contrast-to-noise ratio for local SoS mapping.
Diachronic Text Mining Investigation of Therapeutic Candidates for COVID-19
Oct 26, 2021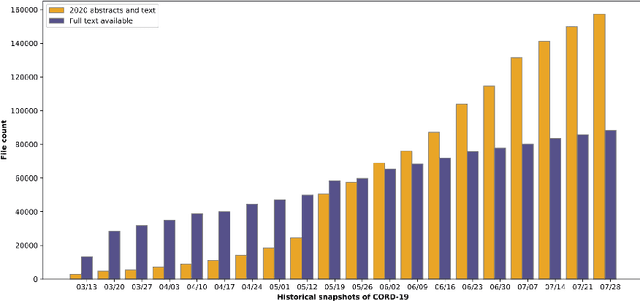
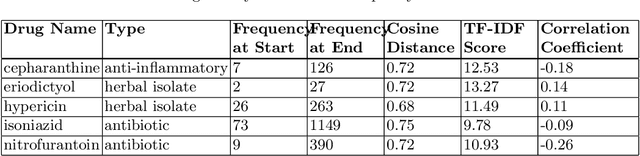
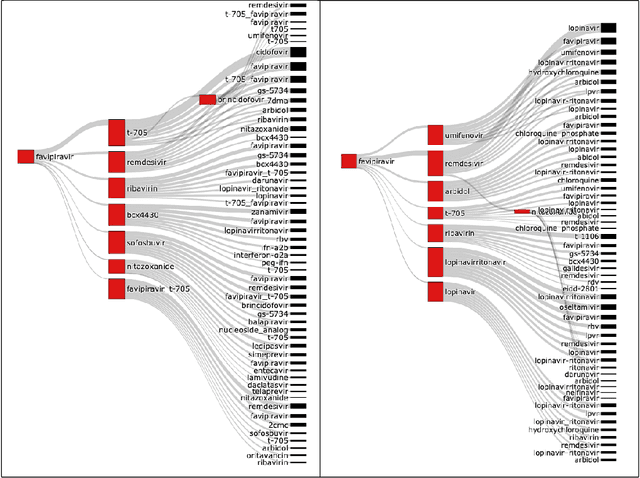

Diachronic text mining has frequently been applied to long-term linguistic surveys of word meaning and usage shifts over time. In this paper we apply short-term diachronic text mining to a rapidly growing corpus of scientific publications on COVID-19 captured in the CORD-19 dataset in order to identify co-occurrences and analyze the behavior of potential candidate treatments. We used a data set associated with a COVID-19 drug re-purposing study from Oak Ridge National Laboratory. This study identified existing candidate coronavirus treatments, including drugs and approved compounds, which had been analyzed and ranked according to their potential for blocking the ability of the SARS-COV-2 virus to invade human cells. We investigated the occurrence of these candidates in temporal instances of the CORD-19 corpus. We found that at least 25% of the identified terms occurred in temporal instances of the corpus to the extent that their frequency and contextual dynamics could be evaluated. We identified three classes of behaviors: those where frequency and contextual shifts were small and positively correlated; those where there was no correlation between frequency and contextual changes; and those where there was a negative correlation between frequency and contextual shift. We speculate that the latter two patterns are indicative that a target candidate therapeutics is undergoing active evaluation. The patterns we detected demonstrate the potential benefits of using diachronic text mining techniques with a large dynamic text corpus to track drug-repurposing activities across international clinical and laboratory settings.
Automated Design of Heuristics for the Container Relocation Problem
Jul 28, 2021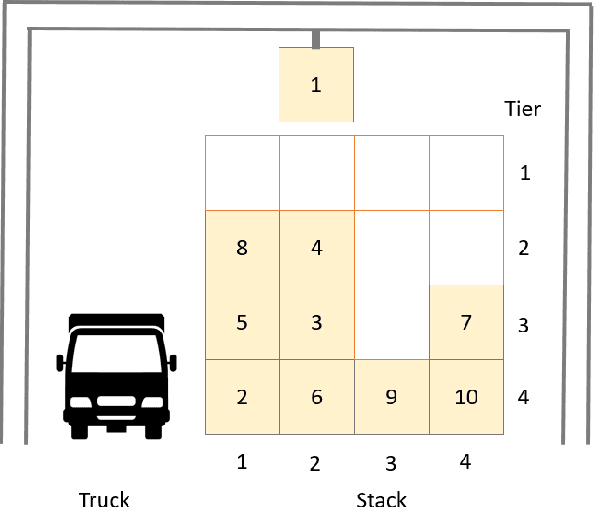
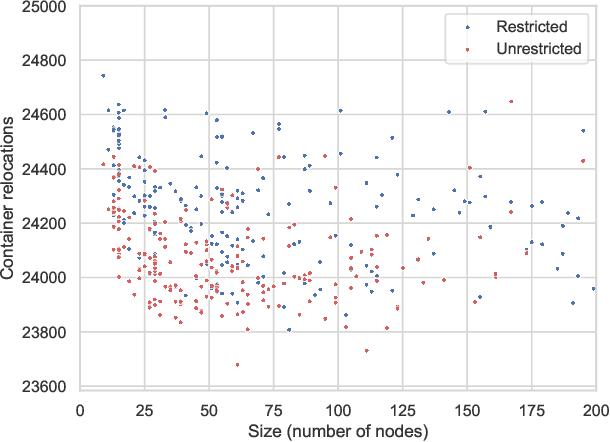
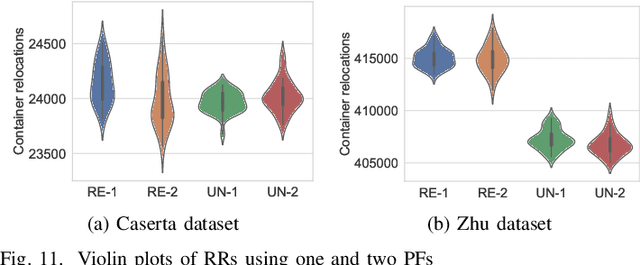
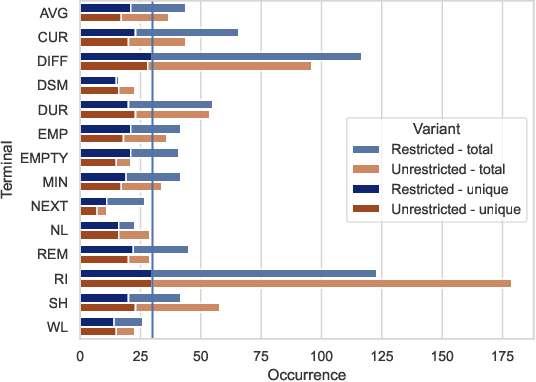
The container relocation problem is a challenging combinatorial optimisation problem tasked with finding a sequence of container relocations required to retrieve all containers by a given order. Due to the complexity of this problem, heuristic methods are often applied to obtain acceptable solutions in a small amount of time. These include relocation rules (RRs) that determine the relocation moves that need to be performed to efficiently retrieve the next container based on certain yard properties. Such rules are often designed manually by domain experts, which is a time-consuming and challenging task. This paper investigates the application of genetic programming (GP) to design effective RRs automatically. The experimental results show that GP evolved RRs outperform several existing manually designed RRs. Additional analyses of the proposed approach demonstrate that the evolved rules generalise well across a wide range of unseen problems and that their performance can be further enhanced. Therefore, the proposed method presents a viable alternative to existing manually designed RRs and opens a new research direction in the area of container relocation problems.
Comparison of Deep learning models on time series forecasting : a case study of Dissolved Oxygen Prediction
Nov 21, 2019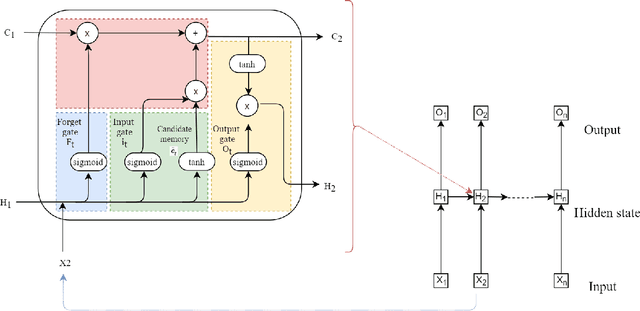
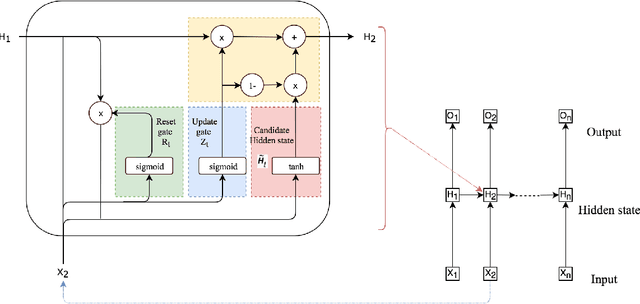
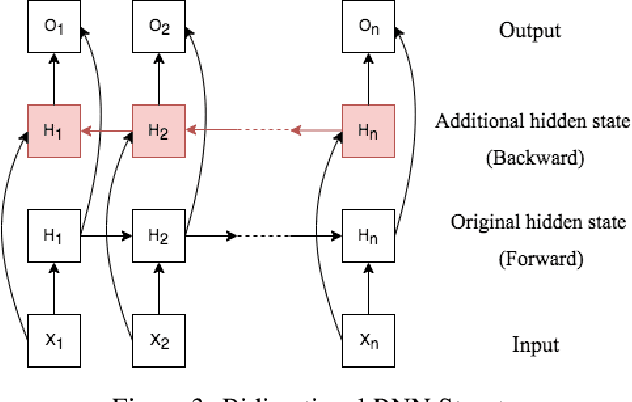
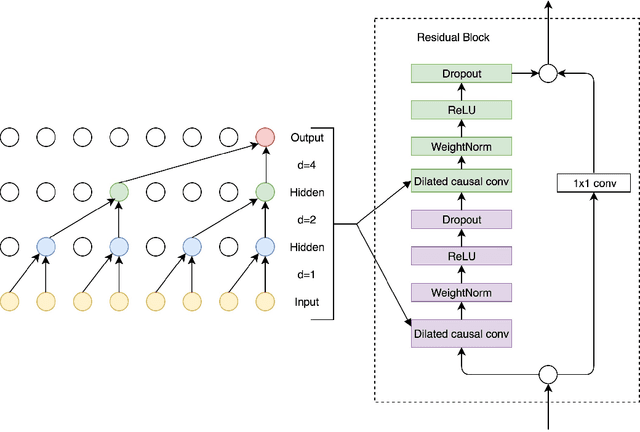
Deep learning has achieved impressive prediction performance in the field of sequence learning recently. Dissolved oxygen prediction, as a kind of time-series forecasting, is suitable for this technique. Although many researchers have developed hybrid models or variant models based on deep learning techniques, there is no comprehensive and sound comparison among the deep learning models in this field currently. Plus, most previous studies focused on one-step forecasting by using a small data set. As the convenient access to high-frequency data, this paper compares multi-step deep learning forecasting by using walk-forward validation. Specifically, we test Convolutional Neural Network (CNN), Temporal Convolutional Network (TCN), Long Short-Term Memory (LSTM), Gated Recurrent Unit (GRU), Bidirectional Recurrent Neural Network (BiRNN) based on the real-time data recorded automatically at a fixed observation point in the Yangtze River from 2012 to 2016. By comparing the average accumulated statistical metrics of root mean square error (RMSE), mean absolute error (MAE), and coefficient of determination in each time step, We find for multi-step time series forecasting, the average performance of each time step does not decrease linearly. GRU outperforms other models with significant advantages.
Mitigating Current Variation in Particle Beam Microscopy
Jun 08, 2021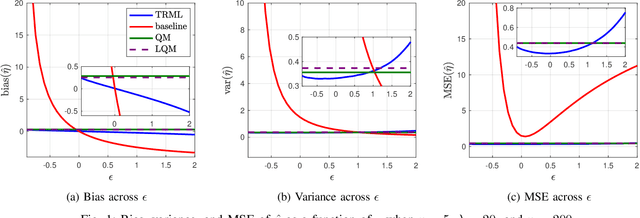
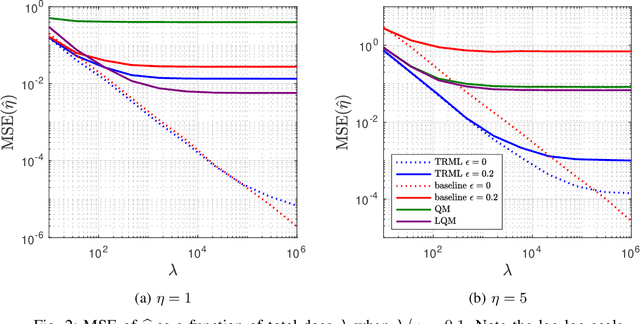
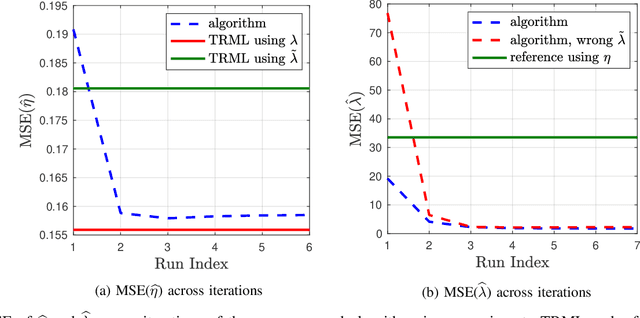

Particle beam microscopy uses a scanning beam of charged particles to create images of samples, and the quality of image reconstruction suffers when this beam current varies over time. Neither conventional reconstruction methods nor time-resolved sensing acknowledges beam current variation, although through sensitivity analysis, my project demonstrates that when the beam current variation is appreciable, time-resolved sensing has significant improvement compared to conventional methods in terms of image reconstruction quality, specifically mean-squared error (MSE). To more actively combat this unknown varying beam current's effects, my project further focuses on designing an algorithm that uses time-resolved sensing for even better image reconstruction quality in the presence of beam current variation. This algorithm works by simultaneously estimating the unknown beam current variation in addition to the underlying image, offering an alternative to more conventional methods, which exploit statistical assumptions of the image content without explicitly estimating the beam current. Using a concept of excess MSE due to beam current variation, this algorithm provides a factor of 7 improvement on average, which could lead to less expensive equipment in the future. Beyond improving the image estimation, this algorithm offers a novel estimation of the beam current, potentially providing more control in manufacturing and fabrication processes.
Graph Neural Network Guided Local Search for the Traveling Salesperson Problem
Oct 12, 2021
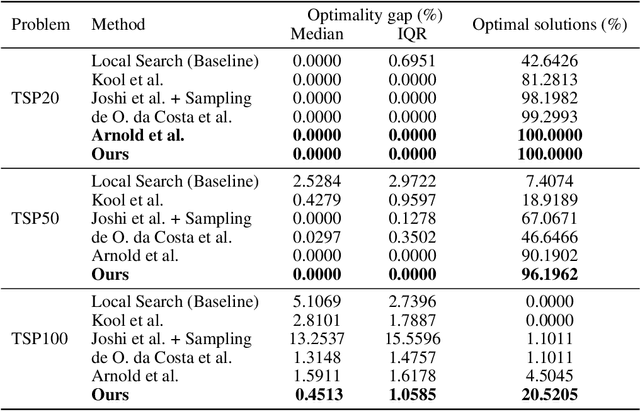

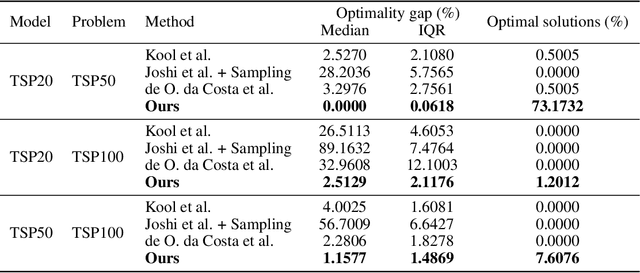
Solutions to the Traveling Salesperson Problem (TSP) have practical applications to processes in transportation, logistics, and automation, yet must be computed with minimal delay to satisfy the real-time nature of the underlying tasks. However, solving large TSP instances quickly without sacrificing solution quality remains challenging for current approximate algorithms. To close this gap, we present a hybrid data-driven approach for solving the TSP based on Graph Neural Networks (GNNs) and Guided Local Search (GLS). Our model predicts the regret of including each edge of the problem graph in the solution; GLS uses these predictions in conjunction with the original problem graph to find solutions. Our experiments demonstrate that this approach converges to optimal solutions at a faster rate than state-of-the-art learning-based approaches and non-learning GLS algorithms for the TSP, notably finding optimal solutions to 96% of the 50-node problem set, 7% more than the next best benchmark, and to 20% of the 100-node problem set, 4.5x more than the next best benchmark. When generalizing from 20-node problems to the 100-node problem set, our approach finds solutions with an average optimality gap of 2.5%, a 10x improvement over the next best learning-based benchmark.
Anomaly Detection in Predictive Maintenance: A New Evaluation Framework for Temporal Unsupervised Anomaly Detection Algorithms
May 26, 2021
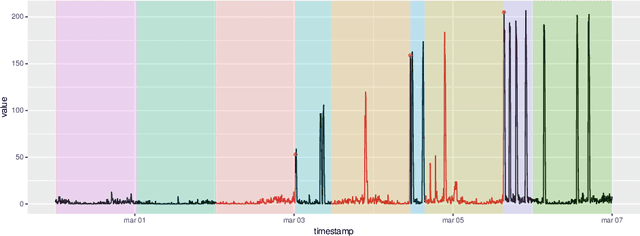
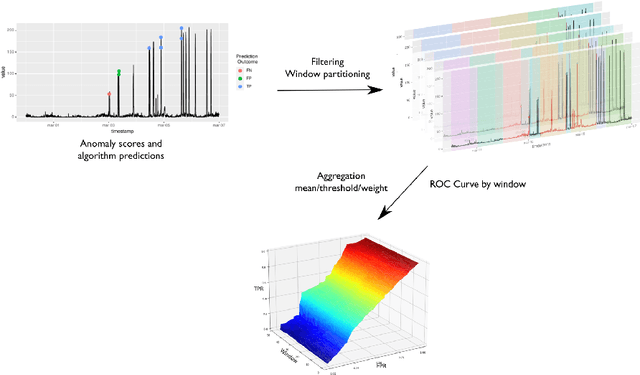

The research in anomaly detection lacks a unified definition of what represents an anomalous instance. Discrepancies in the nature itself of an anomaly lead to multiple paradigms of algorithms design and experimentation. Predictive maintenance is a special case, where the anomaly represents a failure that must be prevented. Related time-series research as outlier and novelty detection or time-series classification does not apply to the concept of an anomaly in this field, because they are not single points which have not been seen previously and may not be precisely annotated. Moreover, due to the lack of annotated anomalous data, many benchmarks are adapted from supervised scenarios. To address these issues, we generalise the concept of positive and negative instances to intervals to be able to evaluate unsupervised anomaly detection algorithms. We also preserve the imbalance scheme for evaluation through the proposal of the Preceding Window ROC, a generalisation for the calculation of ROC curves for time-series scenarios. We also adapt the mechanism from a established time-series anomaly detection benchmark to the proposed generalisations to reward early detection. Therefore, the proposal represents a flexible evaluation framework for the different scenarios. To show the usefulness of this definition, we include a case study of Big Data algorithms with a real-world time-series problem provided by the company ArcelorMittal, and compare the proposal with an evaluation method.
Recent Advances of Continual Learning in Computer Vision: An Overview
Sep 24, 2021

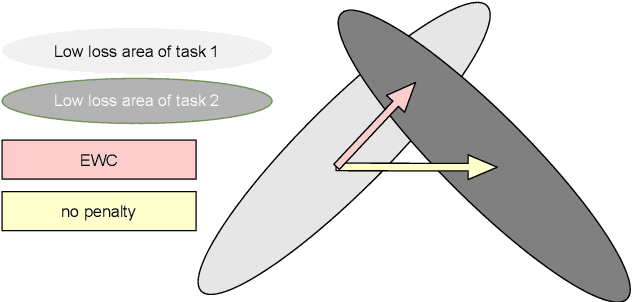
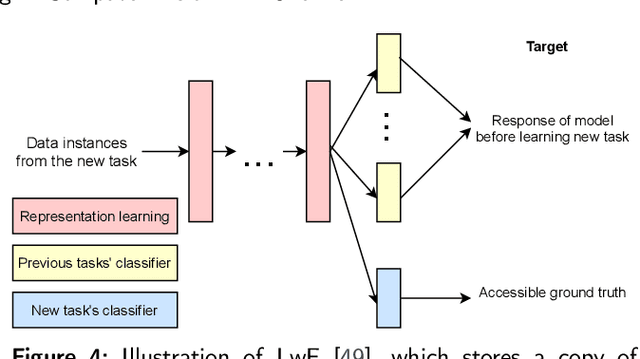
In contrast to batch learning where all training data is available at once, continual learning represents a family of methods that accumulate knowledge and learn continuously with data available in sequential order. Similar to the human learning process with the ability of learning, fusing, and accumulating new knowledge coming at different time steps, continual learning is considered to have high practical significance. Hence, continual learning has been studied in various artificial intelligence tasks. In this paper, we present a comprehensive review of the recent progress of continual learning in computer vision. In particular, the works are grouped by their representative techniques, including regularization, knowledge distillation, memory, generative replay, parameter isolation, and a combination of the above techniques. For each category of these techniques, both its characteristics and applications in computer vision are presented. At the end of this overview, several subareas, where continuous knowledge accumulation is potentially helpful while continual learning has not been well studied, are discussed.