 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
AP-MTL: Attention Pruned Multi-task Learning Model for Real-time Instrument Detection and Segmentation in Robot-assisted Surgery
Mar 10, 2020
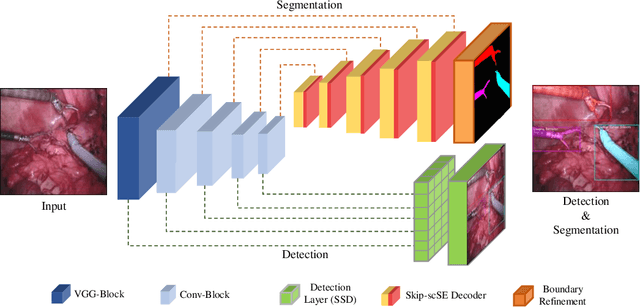
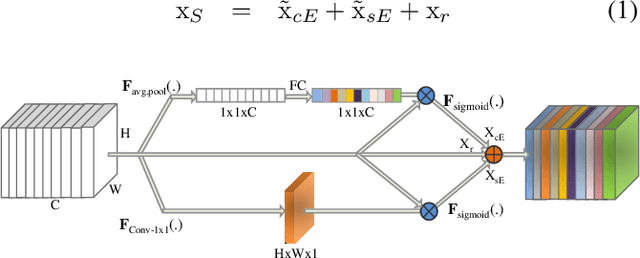
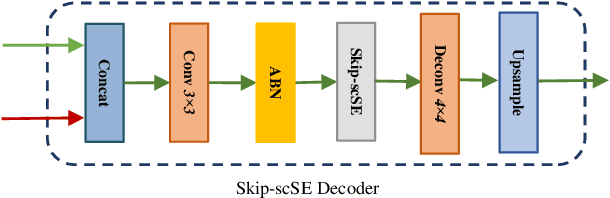
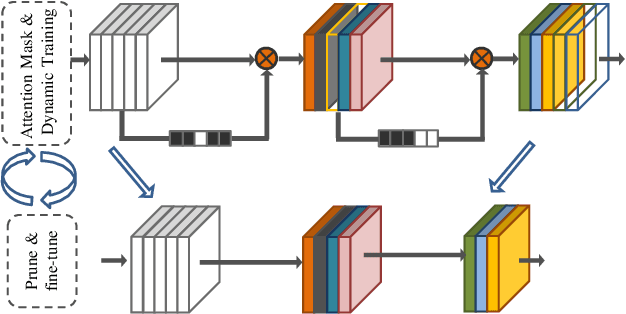
Surgical scene understanding and multi-tasking learning are crucial for image-guided robotic surgery. Training a real-time robotic system for the detection and segmentation of high-resolution images provides a challenging problem with the limited computational resource. The perception drawn can be applied in effective real-time feedback, surgical skill assessment, and human-robot collaborative surgeries to enhance surgical outcomes. For this purpose, we develop a novel end-to-end trainable real-time Multi-Task Learning (MTL) model with weight-shared encoder and task-aware detection and segmentation decoders. Optimization of multiple tasks at the same convergence point is vital and presents a complex problem. Thus, we propose an asynchronous task-aware optimization (ATO) technique to calculate task-oriented gradients and train the decoders independently. Moreover, MTL models are always computationally expensive, which hinder real-time applications. To address this challenge, we introduce a global attention dynamic pruning (GADP) by removing less significant and sparse parameters. We further design a skip squeeze and excitation (SE) module, which suppresses weak features, excites significant features and performs dynamic spatial and channel-wise feature re-calibration. Validating on the robotic instrument segmentation dataset of MICCAI endoscopic vision challenge, our model significantly outperforms state-of-the-art segmentation and detection models, including best-performed models in the challenge.
StarGANv2-VC: A Diverse, Unsupervised, Non-parallel Framework for Natural-Sounding Voice Conversion
Jul 21, 2021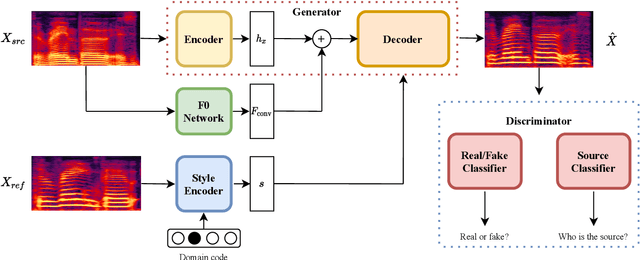
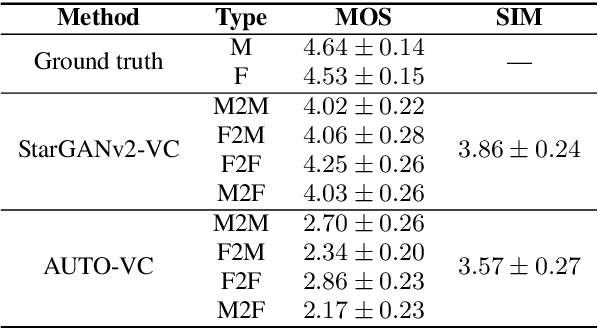
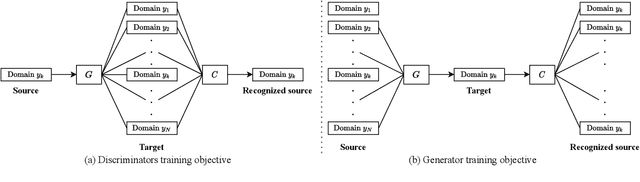
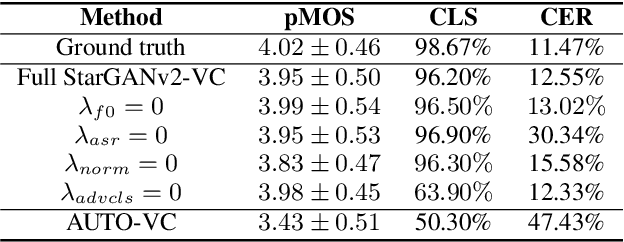
We present an unsupervised non-parallel many-to-many voice conversion (VC) method using a generative adversarial network (GAN) called StarGAN v2. Using a combination of adversarial source classifier loss and perceptual loss, our model significantly outperforms previous VC models. Although our model is trained only with 20 English speakers, it generalizes to a variety of voice conversion tasks, such as any-to-many, cross-lingual, and singing conversion. Using a style encoder, our framework can also convert plain reading speech into stylistic speech, such as emotional and falsetto speech. Subjective and objective evaluation experiments on a non-parallel many-to-many voice conversion task revealed that our model produces natural sounding voices, close to the sound quality of state-of-the-art text-to-speech (TTS) based voice conversion methods without the need for text labels. Moreover, our model is completely convolutional and with a faster-than-real-time vocoder such as Parallel WaveGAN can perform real-time voice conversion.
PTRAIL -- A python package for parallel trajectory data preprocessing
Aug 26, 2021
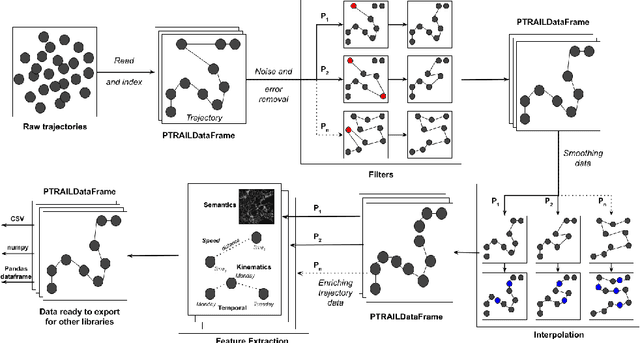

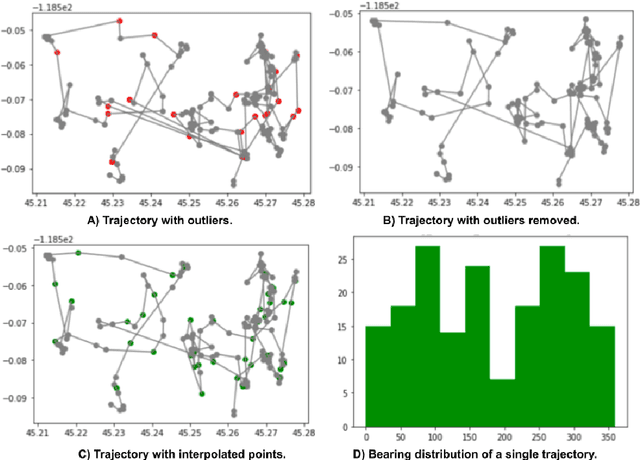
Trajectory data represent a trace of an object that changes its position in space over time. This kind of data is complex to handle and analyze, since it is generally produced in huge quantities, often prone to errors generated by the geolocation device, human mishandling, or area coverage limitation. Therefore, there is a need for software specifically tailored to preprocess trajectory data. In this work we propose PTRAIL, a python package offering several trajectory preprocessing steps, including filtering, feature extraction, and interpolation. PTRAIL uses parallel computation and vectorization, being suitable for large datasets and fast compared to other python libraries.
Memory-Efficient CNN Accelerator Based on Interlayer Feature Map Compression
Oct 12, 2021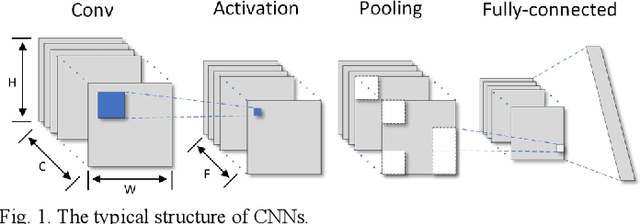
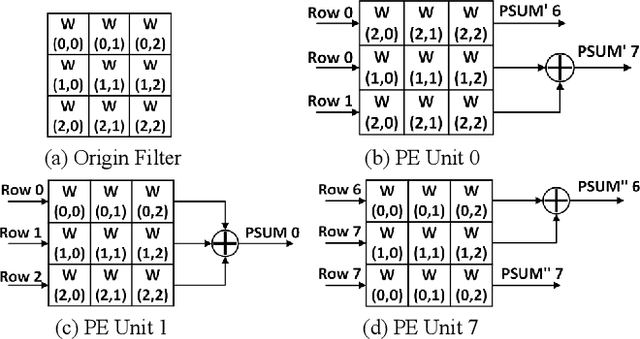
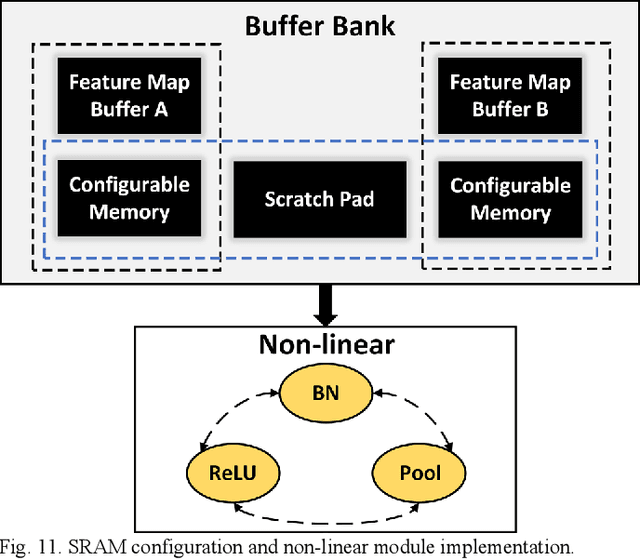
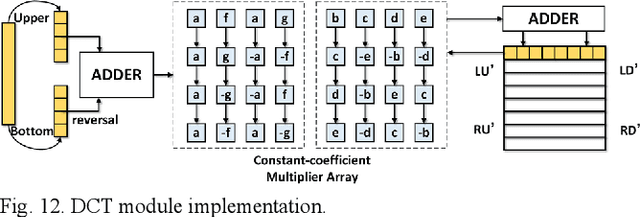
Existing deep convolutional neural networks (CNNs) generate massive interlayer feature data during network inference. To maintain real-time processing in embedded systems, large on-chip memory is required to buffer the interlayer feature maps. In this paper, we propose an efficient hardware accelerator with an interlayer feature compression technique to significantly reduce the required on-chip memory size and off-chip memory access bandwidth. The accelerator compresses interlayer feature maps through transforming the stored data into frequency domain using hardware-implemented 8x8 discrete cosine transform (DCT). The high-frequency components are removed after the DCT through quantization. Sparse matrix compression is utilized to further compress the interlayer feature maps. The on-chip memory allocation scheme is designed to support dynamic configuration of the feature map buffer size and scratch pad size according to different network-layer requirements. The hardware accelerator combines compression, decompression, and CNN acceleration into one computing stream, achieving minimal compressing and processing delay. A prototype accelerator is implemented on an FPGA platform and also synthesized in TSMC 28-nm COMS technology. It achieves 403GOPS peak throughput and 1.4x~3.3x interlayer feature map reduction by adding light hardware area overhead, making it a promising hardware accelerator for intelligent IoT devices.
Cubature Kalman Filter Based Training of Hybrid Differential Equation Recurrent Neural Network Physiological Dynamic Models
Oct 12, 2021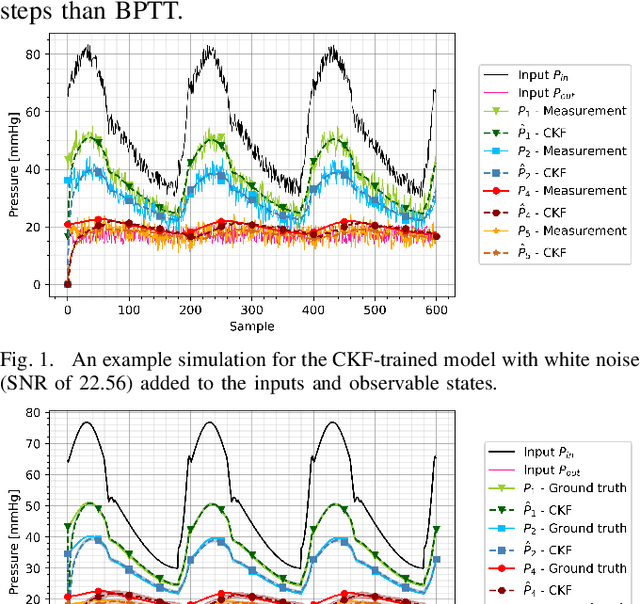
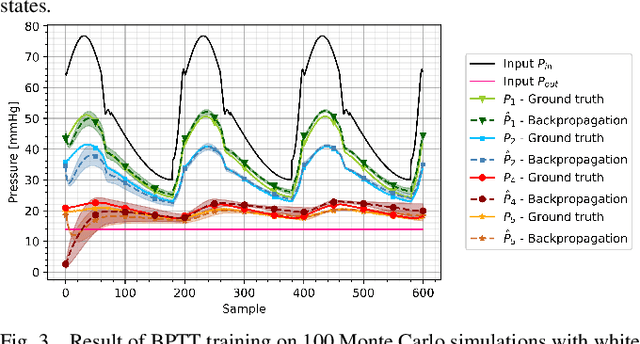
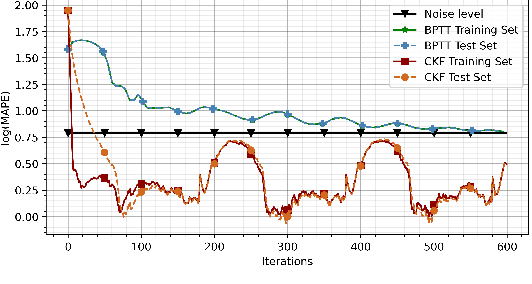
Modeling biological dynamical systems is challenging due to the interdependence of different system components, some of which are not fully understood. To fill existing gaps in our ability to mechanistically model physiological systems, we propose to combine neural networks with physics-based models. Specifically, we demonstrate how we can approximate missing ordinary differential equations (ODEs) coupled with known ODEs using Bayesian filtering techniques to train the model parameters and simultaneously estimate dynamic state variables. As a study case we leverage a well-understood model for blood circulation in the human retina and replace one of its core ODEs with a neural network approximation, representing the case where we have incomplete knowledge of the physiological state dynamics. Results demonstrate that state dynamics corresponding to the missing ODEs can be approximated well using a neural network trained using a recursive Bayesian filtering approach in a fashion coupled with the known state dynamic differential equations. This demonstrates that dynamics and impact of missing state variables can be captured through joint state estimation and model parameter estimation within a recursive Bayesian state estimation (RBSE) framework. Results also indicate that this RBSE approach to training the NN parameters yields better outcomes (measurement/state estimation accuracy) than training the neural network with backpropagation through time in the same setting.
Efficient Bayesian network structure learning via local Markov boundary search
Oct 12, 2021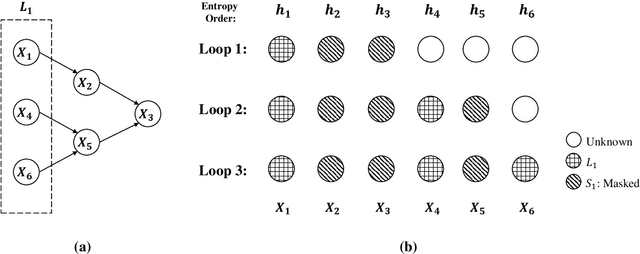
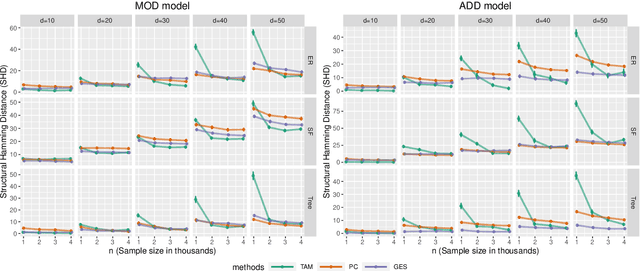
We analyze the complexity of learning directed acyclic graphical models from observational data in general settings without specific distributional assumptions. Our approach is information-theoretic and uses a local Markov boundary search procedure in order to recursively construct ancestral sets in the underlying graphical model. Perhaps surprisingly, we show that for certain graph ensembles, a simple forward greedy search algorithm (i.e. without a backward pruning phase) suffices to learn the Markov boundary of each node. This substantially improves the sample complexity, which we show is at most polynomial in the number of nodes. This is then applied to learn the entire graph under a novel identifiability condition that generalizes existing conditions from the literature. As a matter of independent interest, we establish finite-sample guarantees for the problem of recovering Markov boundaries from data. Moreover, we apply our results to the special case of polytrees, for which the assumptions simplify, and provide explicit conditions under which polytrees are identifiable and learnable in polynomial time. We further illustrate the performance of the algorithm, which is easy to implement, in a simulation study. Our approach is general, works for discrete or continuous distributions without distributional assumptions, and as such sheds light on the minimal assumptions required to efficiently learn the structure of directed graphical models from data.
Fast sensor placement by enlarging principle submatrix for large-scale linear inverse problems
Oct 07, 2021
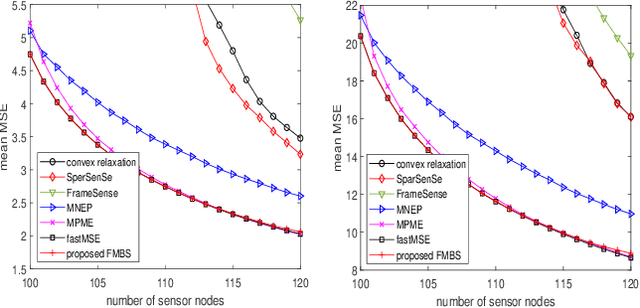
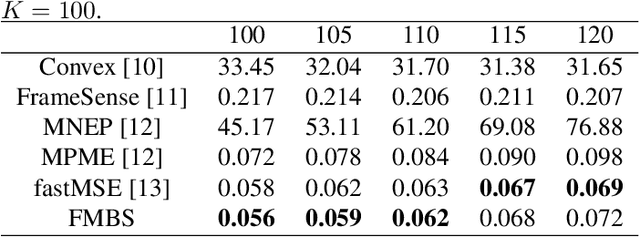
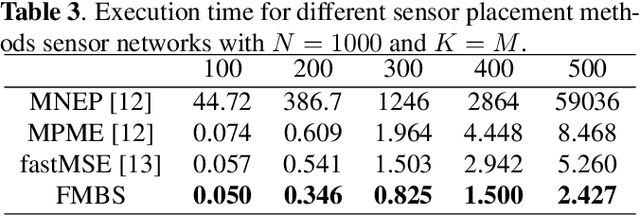
Sensor placement for linear inverse problems is the selection of locations to assign sensors so that the entire physical signal can be well recovered from partial observations. In this paper, we propose a fast sampling algorithm to place sensors. Specifically, assuming that the field signal $\mathbf{f}$ is represented by a linear model $\mathbf{f}=\pmb{\phi}\mathbf{g}$, it can be estimated from partial noisy samples via an unbiased least-squares (LS) method, whose expected mean square error (MSE) depends on chosen samples. First, we formulate an approximate MSE problem, and then prove it is equivalent to a problem related to a principle submatrix of $\pmb{\phi}\pmb{\phi}^\top$ indexed by sample set. To solve the formulated problem, we devise a fast greedy algorithm with simple matrix-vector multiplications, leveraging a matrix inverse formula. To further reduce complexity, we reuse results in the previous greedy step for warm start, so that candidates can be evaluated via lightweight vector-vector multiplications. Extensive experiments show that our proposed sensor placement method achieved the lowest sensor sampling time and the best performance compared to state-of-the-art schemes.
Training Spiking Neural Networks Using Lessons From Deep Learning
Oct 01, 2021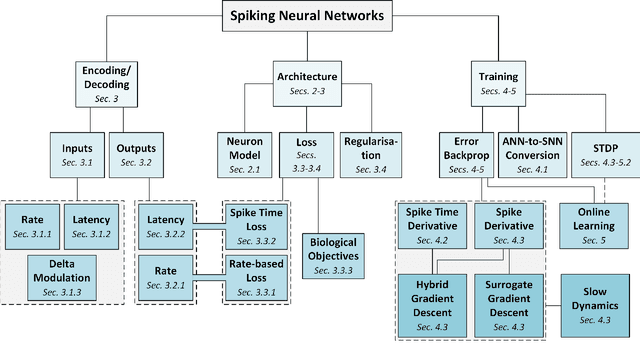

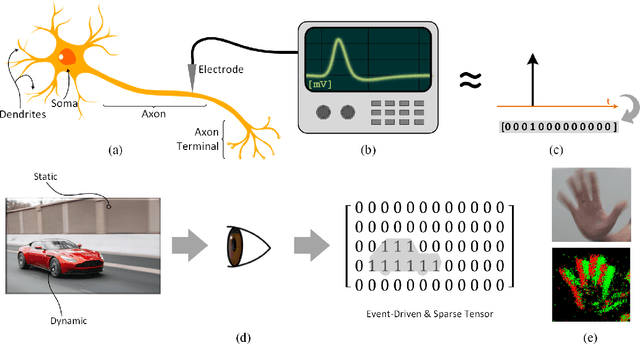

The brain is the perfect place to look for inspiration to develop more efficient neural networks. The inner workings of our synapses and neurons provide a glimpse at what the future of deep learning might look like. This paper serves as a tutorial and perspective showing how to apply the lessons learnt from several decades of research in deep learning, gradient descent, backpropagation and neuroscience to biologically plausible spiking neural neural networks. We also explore the delicate interplay between encoding data as spikes and the learning process; the challenges and solutions of applying gradient-based learning to spiking neural networks; the subtle link between temporal backpropagation and spike timing dependent plasticity, and how deep learning might move towards biologically plausible online learning. Some ideas are well accepted and commonly used amongst the neuromorphic engineering community, while others are presented or justified for the first time here. A series of companion interactive tutorials complementary to this paper using our Python package, snnTorch, are also made available: https://snntorch.readthedocs.io/en/latest/tutorials/index.html
Adaptive Fusion Affinity Graph with Noise-free Online Low-rank Representation for Natural Image Segmentation
Oct 22, 2021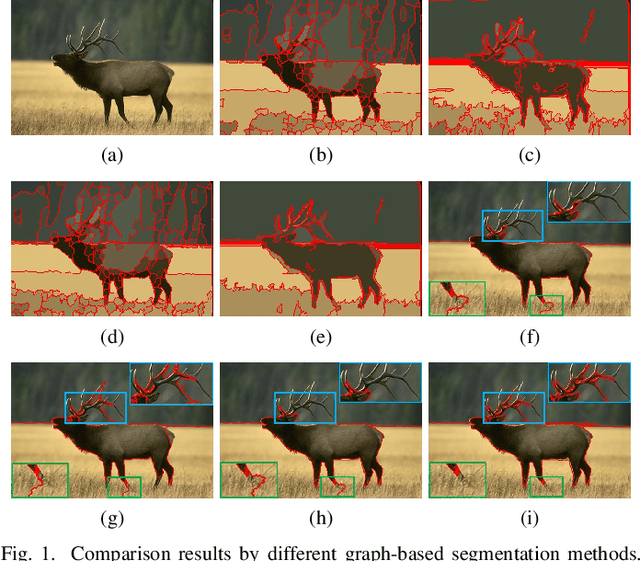



Affinity graph-based segmentation methods have become a major trend in computer vision. The performance of these methods relies on the constructed affinity graph, with particular emphasis on the neighborhood topology and pairwise affinities among superpixels. Due to the advantages of assimilating different graphs, a multi-scale fusion graph has a better performance than a single graph with single-scale. However, these methods ignore the noise from images which influences the accuracy of pairwise similarities. Multi-scale combinatorial grouping and graph fusion also generate a higher computational complexity. In this paper, we propose an adaptive fusion affinity graph (AFA-graph) with noise-free low-rank representation in an online manner for natural image segmentation. An input image is first over-segmented into superpixels at different scales and then filtered by the proposed improved kernel density estimation method. Moreover, we select global nodes of these superpixels on the basis of their subspace-preserving presentation, which reveals the feature distribution of superpixels exactly. To reduce time complexity while improving performance, a sparse representation of global nodes based on noise-free online low-rank representation is used to obtain a global graph at each scale. The global graph is finally used to update a local graph which is built upon all superpixels at each scale. Experimental results on the BSD300, BSD500, MSRC, SBD, and PASCAL VOC show the effectiveness of AFA-graph in comparison with state-of-the-art approaches.
Sequential Joint Shape and Pose Estimation of Vehicles with Application to Automatic Amodal Segmentation Labeling
Sep 20, 2021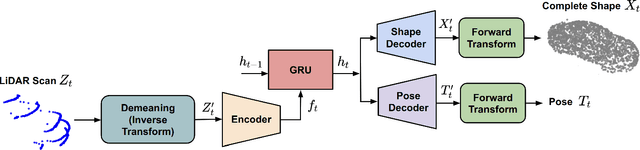

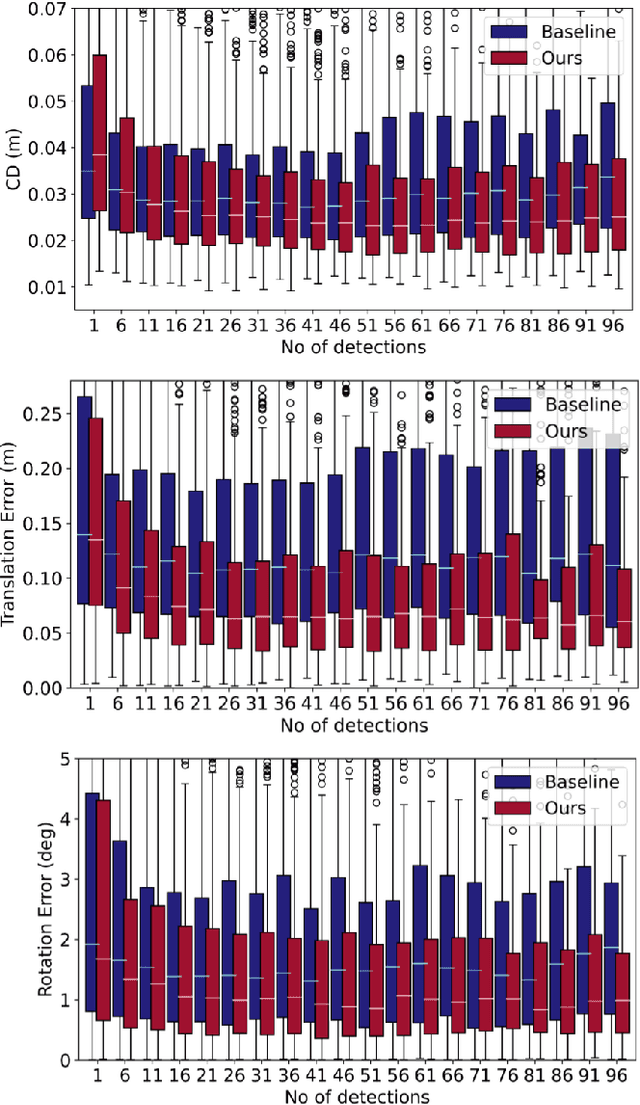

Shape and pose estimation is a critical perception problem for a self-driving car to fully understand its surrounding environment. One fundamental challenge in solving this problem is the incomplete sensor signal (e.g., LiDAR scans), especially for faraway or occluded objects. In this paper, we propose a novel algorithm to address this challenge, we explicitly leverage the sensor signal captured over consecutive time: the consecutive signals can provide more information of an object, including different viewpoints and its motion. By encoding the consecutive signal via a recurrent neural network, our algorithm not only improves shape and pose estimation, but also produces a labeling tool that can benefit other tasks in autonomous driving research. Specifically, building upon our algorithm, we propose a novel pipeline to automatically annotate high-quality labels for amodal segmentation on images, which are hard and laborious to annotate manually. Our code and data will be made publicly available.