 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Distance-aware Quantization
Aug 16, 2021
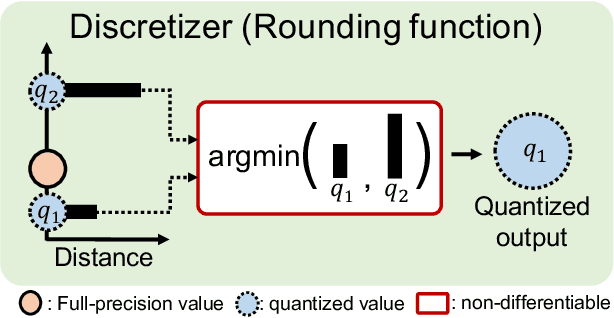
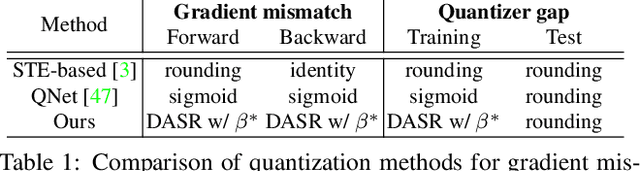
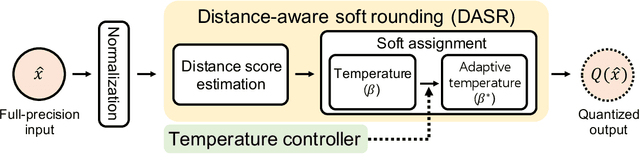

We address the problem of network quantization, that is, reducing bit-widths of weights and/or activations to lighten network architectures. Quantization methods use a rounding function to map full-precision values to the nearest quantized ones, but this operation is not differentiable. There are mainly two approaches to training quantized networks with gradient-based optimizers. First, a straight-through estimator (STE) replaces the zero derivative of the rounding with that of an identity function, which causes a gradient mismatch problem. Second, soft quantizers approximate the rounding with continuous functions at training time, and exploit the rounding for quantization at test time. This alleviates the gradient mismatch, but causes a quantizer gap problem. We alleviate both problems in a unified framework. To this end, we introduce a novel quantizer, dubbed a distance-aware quantizer (DAQ), that mainly consists of a distance-aware soft rounding (DASR) and a temperature controller. To alleviate the gradient mismatch problem, DASR approximates the discrete rounding with the kernel soft argmax, which is based on our insight that the quantization can be formulated as a distance-based assignment problem between full-precision values and quantized ones. The controller adjusts the temperature parameter in DASR adaptively according to the input, addressing the quantizer gap problem. Experimental results on standard benchmarks show that DAQ outperforms the state of the art significantly for various bit-widths without bells and whistles.
Image Shape Manipulation from a Single Augmented Training Sample
Sep 13, 2021
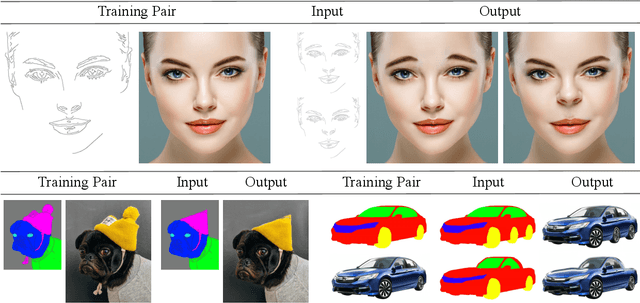


In this paper, we present DeepSIM, a generative model for conditional image manipulation based on a single image. We find that extensive augmentation is key for enabling single image training, and incorporate the use of thin-plate-spline (TPS) as an effective augmentation. Our network learns to map between a primitive representation of the image to the image itself. The choice of a primitive representation has an impact on the ease and expressiveness of the manipulations and can be automatic (e.g. edges), manual (e.g. segmentation) or hybrid such as edges on top of segmentations. At manipulation time, our generator allows for making complex image changes by modifying the primitive input representation and mapping it through the network. Our method is shown to achieve remarkable performance on image manipulation tasks.
Continuous Streaming Multi-Talker ASR with Dual-path Transducers
Sep 17, 2021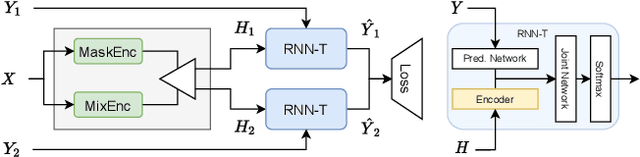

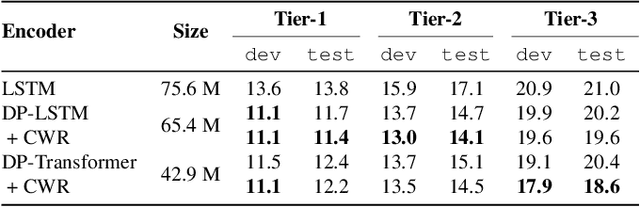
Streaming recognition of multi-talker conversations has so far been evaluated only for 2-speaker single-turn sessions. In this paper, we investigate it for multi-turn meetings containing multiple speakers using the Streaming Unmixing and Recognition Transducer (SURT) model, and show that naively extending the single-turn model to this harder setting incurs a performance penalty. As a solution, we propose the dual-path (DP) modeling strategy first used for time-domain speech separation. We experiment with LSTM and Transformer based DP models, and show that they improve word error rate (WER) performance while yielding faster convergence. We also explore training strategies such as chunk width randomization and curriculum learning for these models, and demonstrate their importance through ablation studies. Finally, we evaluate our models on the LibriCSS meeting data, where they perform competitively with offline separation-based methods.
Designing Composites with Target Effective Young's Modulus using Reinforcement Learning
Oct 07, 2021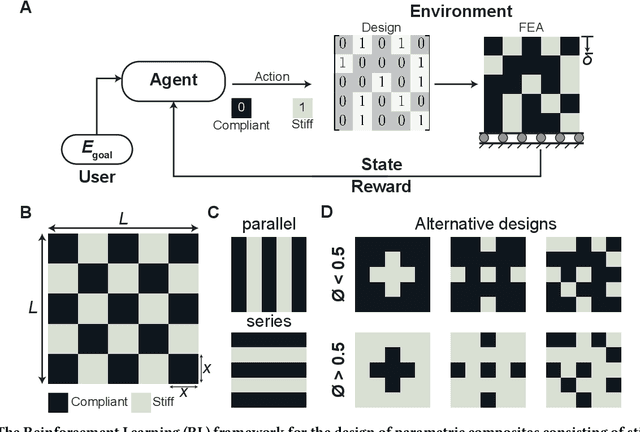
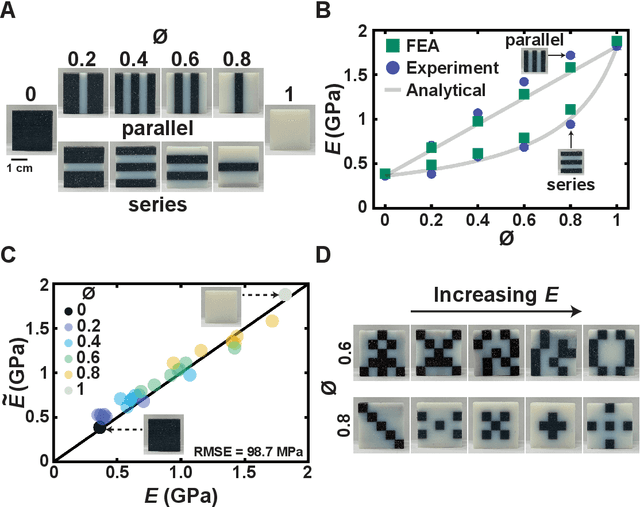

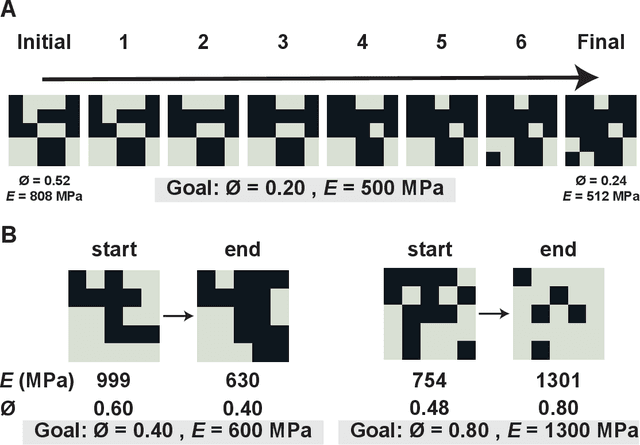
Advancements in additive manufacturing have enabled design and fabrication of materials and structures not previously realizable. In particular, the design space of composite materials and structures has vastly expanded, and the resulting size and complexity has challenged traditional design methodologies, such as brute force exploration and one factor at a time (OFAT) exploration, to find optimum or tailored designs. To address this challenge, supervised machine learning approaches have emerged to model the design space using curated training data; however, the selection of the training data is often determined by the user. In this work, we develop and utilize a Reinforcement learning (RL)-based framework for the design of composite structures which avoids the need for user-selected training data. For a 5 $\times$ 5 composite design space comprised of soft and compliant blocks of constituent material, we find that using this approach, the model can be trained using 2.78% of the total design space consists of $2^{25}$ design possibilities. Additionally, the developed RL-based framework is capable of finding designs at a success rate exceeding 90%. The success of this approach motivates future learning frameworks to utilize RL for the design of composites and other material systems.
Subgradient methods near active manifolds: saddle point avoidance, local convergence, and asymptotic normality
Aug 26, 2021
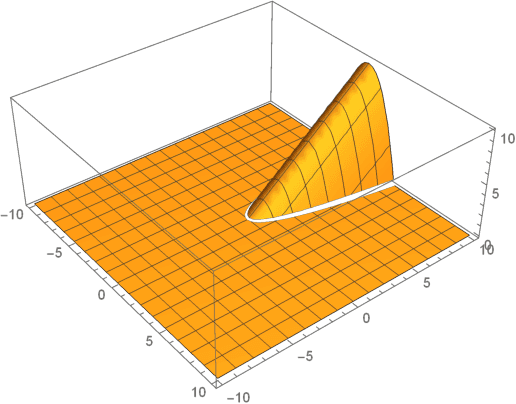
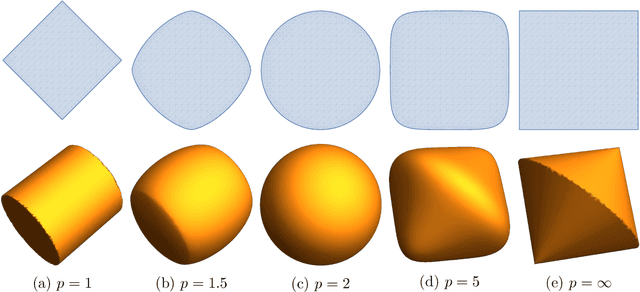
Nonsmooth optimization problems arising in practice tend to exhibit beneficial smooth substructure: their domains stratify into "active manifolds" of smooth variation, which common proximal algorithms "identify" in finite time. Identification then entails a transition to smooth dynamics, and accommodates second-order acceleration techniques. While identification is clearly useful algorithmically, empirical evidence suggests that even those algorithms that do not identify the active manifold in finite time -- notably the subgradient method -- are nonetheless affected by it. This work seeks to explain this phenomenon, asking: how do active manifolds impact the subgradient method in nonsmooth optimization? In this work, we answer this question by introducing two algorithmically useful properties -- aiming and subgradient approximation -- that fully expose the smooth substructure of the problem. We show that these properties imply that the shadow of the (stochastic) subgradient method along the active manifold is precisely an inexact Riemannian gradient method with an implicit retraction. We prove that these properties hold for a wide class of problems, including cone reducible/decomposable functions and generic semialgebraic problems. Moreover, we develop a thorough calculus, proving such properties are preserved under smooth deformations and spectral lifts. This viewpoint then leads to several algorithmic consequences that parallel results in smooth optimization, despite the nonsmoothness of the problem: local rates of convergence, asymptotic normality, and saddle point avoidance. The asymptotic normality results appear to be new even in the most classical setting of stochastic nonlinear programming. The results culminate in the following observation: the perturbed subgradient method on generic, Clarke regular semialgebraic problems, converges only to local minimizers.
Memory-Efficient CNN Accelerator Based on Interlayer Feature Map Compression
Oct 12, 2021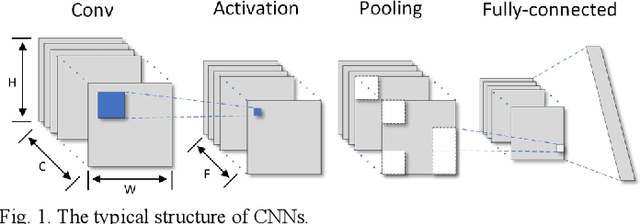
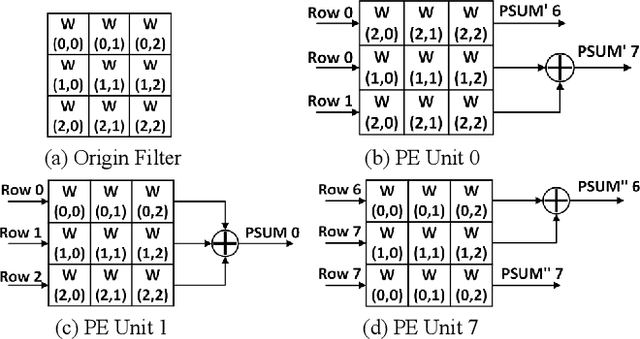
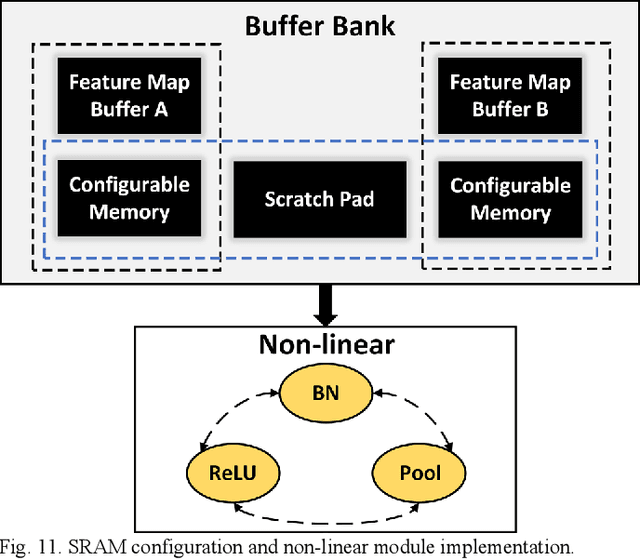
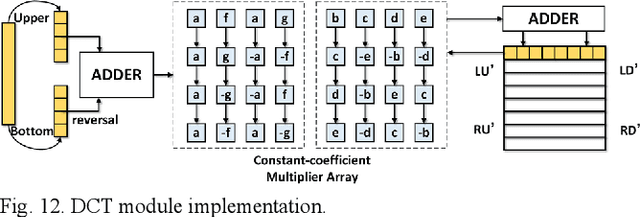
Existing deep convolutional neural networks (CNNs) generate massive interlayer feature data during network inference. To maintain real-time processing in embedded systems, large on-chip memory is required to buffer the interlayer feature maps. In this paper, we propose an efficient hardware accelerator with an interlayer feature compression technique to significantly reduce the required on-chip memory size and off-chip memory access bandwidth. The accelerator compresses interlayer feature maps through transforming the stored data into frequency domain using hardware-implemented 8x8 discrete cosine transform (DCT). The high-frequency components are removed after the DCT through quantization. Sparse matrix compression is utilized to further compress the interlayer feature maps. The on-chip memory allocation scheme is designed to support dynamic configuration of the feature map buffer size and scratch pad size according to different network-layer requirements. The hardware accelerator combines compression, decompression, and CNN acceleration into one computing stream, achieving minimal compressing and processing delay. A prototype accelerator is implemented on an FPGA platform and also synthesized in TSMC 28-nm COMS technology. It achieves 403GOPS peak throughput and 1.4x~3.3x interlayer feature map reduction by adding light hardware area overhead, making it a promising hardware accelerator for intelligent IoT devices.
WeClick: Weakly-Supervised Video Semantic Segmentation with Click Annotations
Aug 04, 2021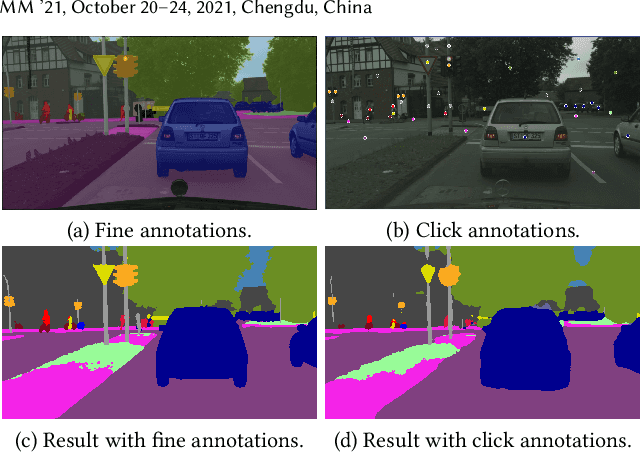
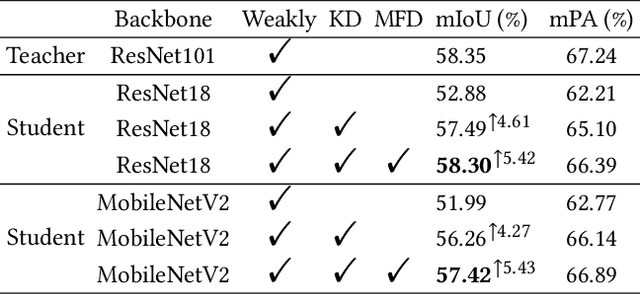
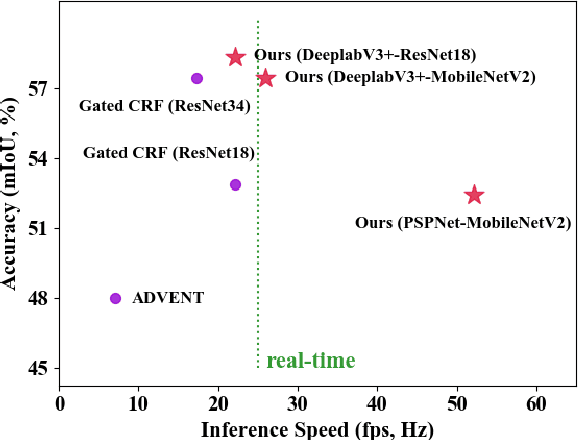
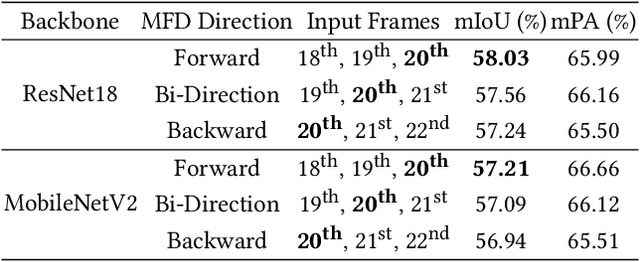
Compared with tedious per-pixel mask annotating, it is much easier to annotate data by clicks, which costs only several seconds for an image. However, applying clicks to learn video semantic segmentation model has not been explored before. In this work, we propose an effective weakly-supervised video semantic segmentation pipeline with click annotations, called WeClick, for saving laborious annotating effort by segmenting an instance of the semantic class with only a single click. Since detailed semantic information is not captured by clicks, directly training with click labels leads to poor segmentation predictions. To mitigate this problem, we design a novel memory flow knowledge distillation strategy to exploit temporal information (named memory flow) in abundant unlabeled video frames, by distilling the neighboring predictions to the target frame via estimated motion. Moreover, we adopt vanilla knowledge distillation for model compression. In this case, WeClick learns compact video semantic segmentation models with the low-cost click annotations during the training phase yet achieves real-time and accurate models during the inference period. Experimental results on Cityscapes and Camvid show that WeClick outperforms the state-of-the-art methods, increases performance by 10.24% mIoU than baseline, and achieves real-time execution.
Towards Real-Time Action Recognition on Mobile Devices Using Deep Models
Jun 17, 2019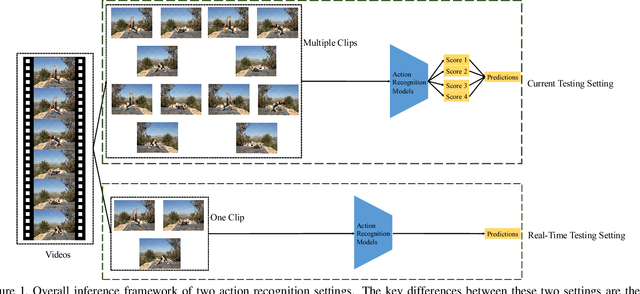
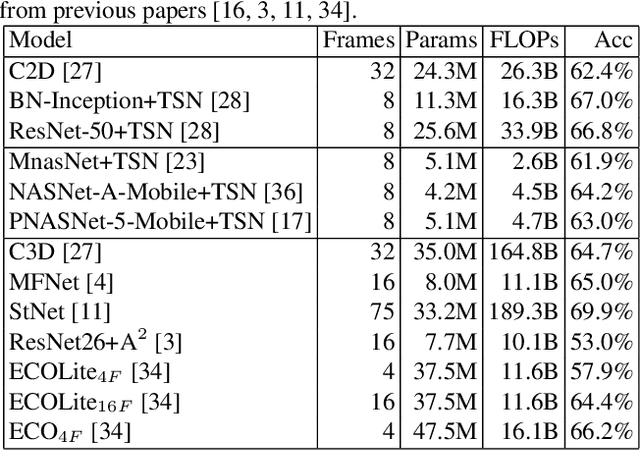
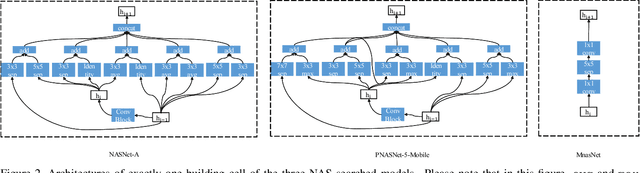
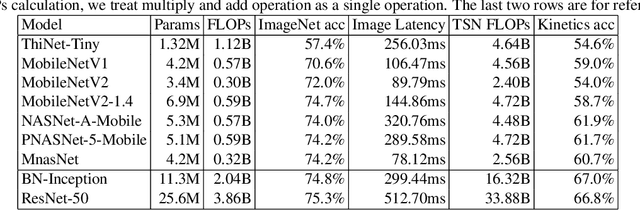
Action recognition is a vital task in computer vision, and many methods are developed to push it to the limit. However, current action recognition models have huge computational costs, which cannot be deployed to real-world tasks on mobile devices. In this paper, we first illustrate the setting of real-time action recognition, which is different from current action recognition inference settings. Under the new inference setting, we investigate state-of-the-art action recognition models on the Kinetics dataset empirically. Our results show that designing efficient real-time action recognition models is different from designing efficient ImageNet models, especially in weight initialization. We show that pre-trained weights on ImageNet improve the accuracy under the real-time action recognition setting. Finally, we use the hand gesture recognition task as a case study to evaluate our compact real-time action recognition models in real-world applications on mobile phones. Results show that our action recognition models, being 6x faster and with similar accuracy as state-of-the-art, can roughly meet the real-time requirements on mobile devices. To our best knowledge, this is the first paper that deploys current deep learning action recognition models on mobile devices.
The Optimization of the Constant Flow Parallel Micropump Using RBF Neural Network
Sep 21, 2021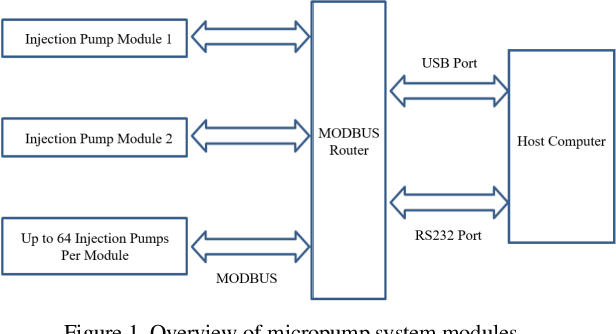
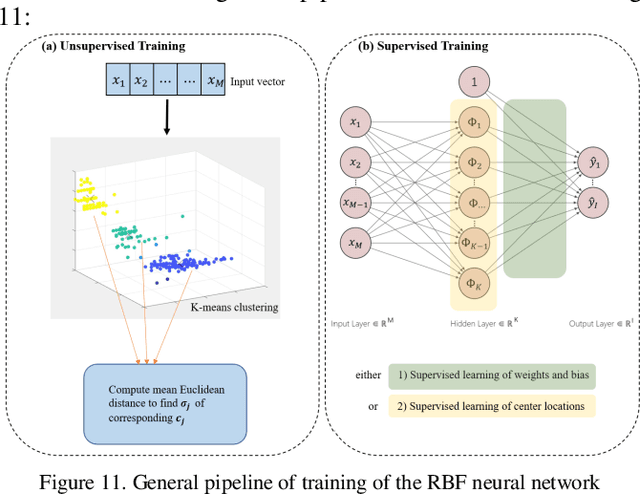
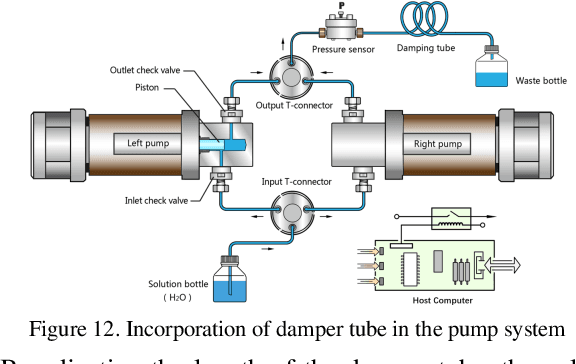
The objective of this work is to optimize the performance of a constant flow parallel mechanical displacement micropump, which has parallel pump chambers and incorporates passive check valves. The critical task is to minimize the pressure pulse caused by regurgitation, which negatively impacts the constant flow rate, during the reciprocating motion when the left and right pumps interchange their role of aspiration and transfusion. Previous works attempt to solve this issue via the mechanical design of passive check valves. In this work, the novel concept of overlap time is proposed, and the issue is solved from the aspect of control theory by implementing a RBF neural network trained by both unsupervised and supervised learning. The experimental results indicate that the pressure pulse is optimized in the range of 0.15 - 0.25 MPa, which is a significant improvement compared to the maximum pump working pressure of 40 MPa.
Unsupervised Translation of German--Lower Sorbian: Exploring Training and Novel Transfer Methods on a Low-Resource Language
Sep 24, 2021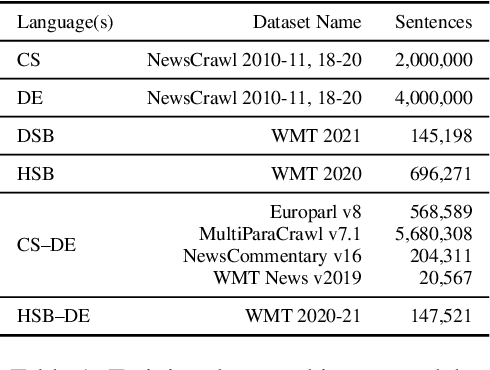
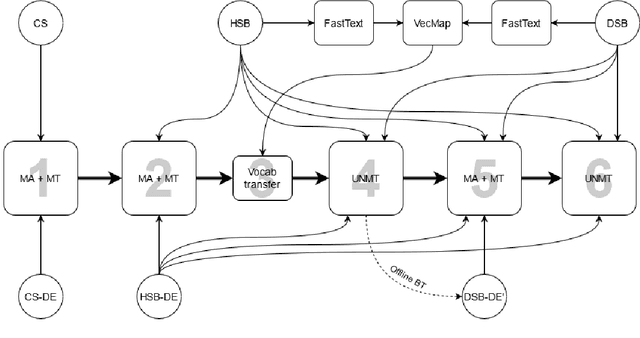
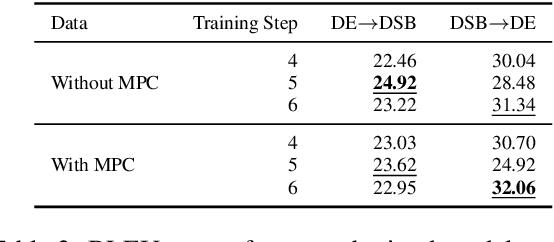
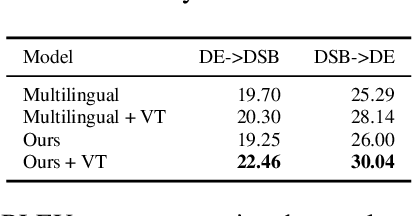
This paper describes the methods behind the systems submitted by the University of Groningen for the WMT 2021 Unsupervised Machine Translation task for German--Lower Sorbian (DE--DSB): a high-resource language to a low-resource one. Our system uses a transformer encoder-decoder architecture in which we make three changes to the standard training procedure. First, our training focuses on two languages at a time, contrasting with a wealth of research on multilingual systems. Second, we introduce a novel method for initializing the vocabulary of an unseen language, achieving improvements of 3.2 BLEU for DE$\rightarrow$DSB and 4.0 BLEU for DSB$\rightarrow$DE. Lastly, we experiment with the order in which offline and online back-translation are used to train an unsupervised system, finding that using online back-translation first works better for DE$\rightarrow$DSB by 2.76 BLEU. Our submissions ranked first (tied with another team) for DSB$\rightarrow$DE and third for DE$\rightarrow$DSB.