 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Discover, Hallucinate, and Adapt: Open Compound Domain Adaptation for Semantic Segmentation
Oct 08, 2021
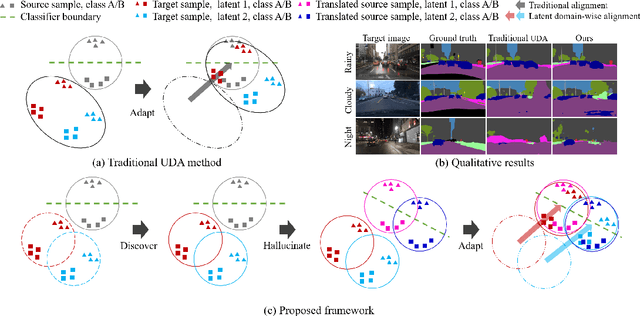
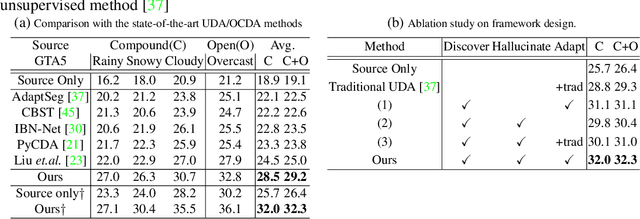
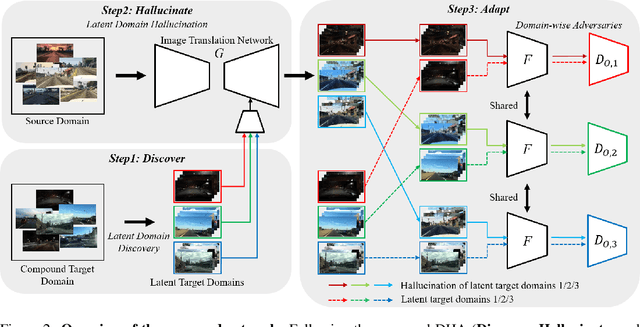
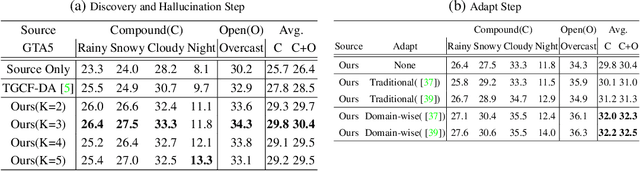
Unsupervised domain adaptation (UDA) for semantic segmentation has been attracting attention recently, as it could be beneficial for various label-scarce real-world scenarios (e.g., robot control, autonomous driving, medical imaging, etc.). Despite the significant progress in this field, current works mainly focus on a single-source single-target setting, which cannot handle more practical settings of multiple targets or even unseen targets. In this paper, we investigate open compound domain adaptation (OCDA), which deals with mixed and novel situations at the same time, for semantic segmentation. We present a novel framework based on three main design principles: discover, hallucinate, and adapt. The scheme first clusters compound target data based on style, discovering multiple latent domains (discover). Then, it hallucinates multiple latent target domains in source by using image-translation (hallucinate). This step ensures the latent domains in the source and the target to be paired. Finally, target-to-source alignment is learned separately between domains (adapt). In high-level, our solution replaces a hard OCDA problem with much easier multiple UDA problems. We evaluate our solution on standard benchmark GTA to C-driving, and achieved new state-of-the-art results.
Learning Models as Functionals of Signed-Distance Fields for Manipulation Planning
Oct 02, 2021



This work proposes an optimization-based manipulation planning framework where the objectives are learned functionals of signed-distance fields that represent objects in the scene. Most manipulation planning approaches rely on analytical models and carefully chosen abstractions/state-spaces to be effective. A central question is how models can be obtained from data that are not primarily accurate in their predictions, but, more importantly, enable efficient reasoning within a planning framework, while at the same time being closely coupled to perception spaces. We show that representing objects as signed-distance fields not only enables to learn and represent a variety of models with higher accuracy compared to point-cloud and occupancy measure representations, but also that SDF-based models are suitable for optimization-based planning. To demonstrate the versatility of our approach, we learn both kinematic and dynamic models to solve tasks that involve hanging mugs on hooks and pushing objects on a table. We can unify these quite different tasks within one framework, since SDFs are the common object representation. Video: https://youtu.be/ga8Wlkss7co
Noisy-to-Noisy Voice Conversion Framework with Denoising Model
Sep 22, 2021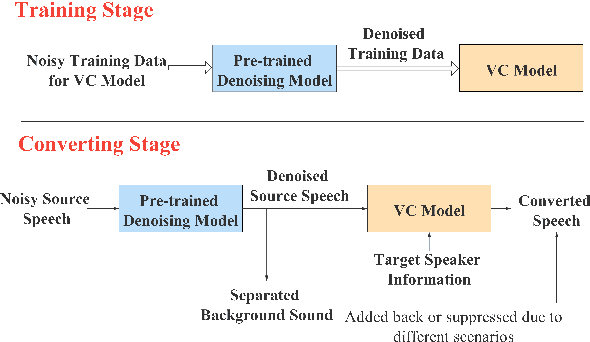
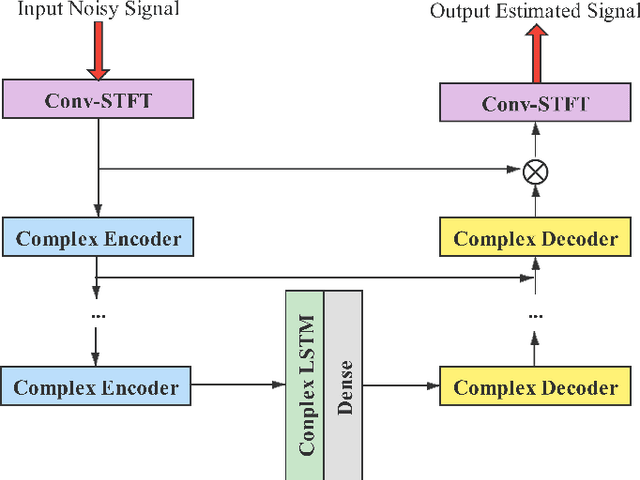
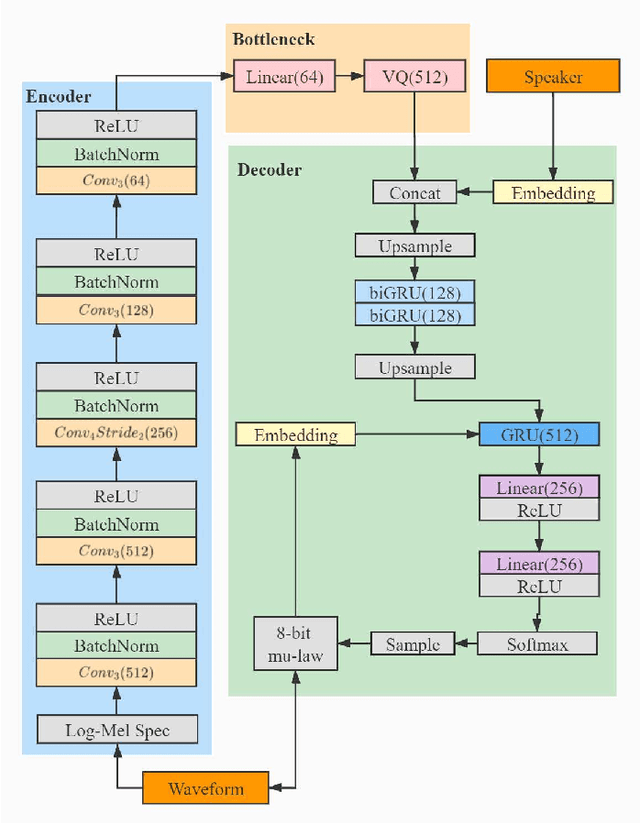
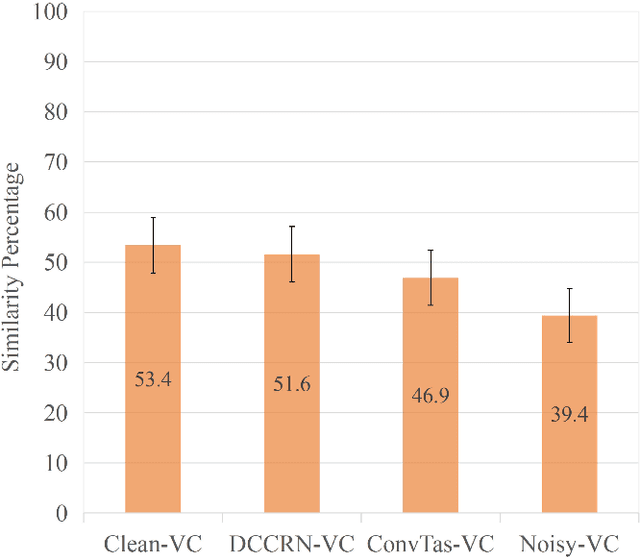
In a conventional voice conversion (VC) framework, a VC model is often trained with a clean dataset consisting of speech data carefully recorded and selected by minimizing background interference. However, collecting such a high-quality dataset is expensive and time-consuming. Leveraging crowd-sourced speech data in training is more economical. Moreover, for some real-world VC scenarios such as VC in video and VC-based data augmentation for speech recognition systems, the background sounds themselves are also informative and need to be maintained. In this paper, to explore VC with the flexibility of handling background sounds, we propose a noisy-to-noisy (N2N) VC framework composed of a denoising module and a VC module. With the proposed framework, we can convert the speaker's identity while preserving the background sounds. Both objective and subjective evaluations are conducted, and the results reveal the effectiveness of the proposed framework.
Efficient Context-Aware Network for Abdominal Multi-organ Segmentation
Sep 22, 2021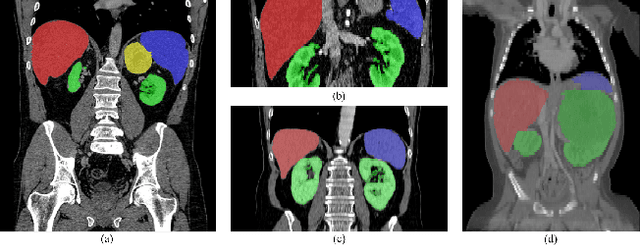
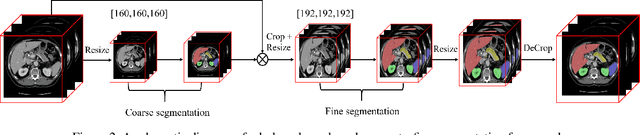
The contextual information, presented in abdominal CT scan, is relative consistent. In order to make full use of the overall 3D context, we develop a whole-volumebased coarse-to-fine framework for efficient and effective abdominal multi-organ segmentation. We propose a new efficientSegNet network, which is composed of encoder, decoder and context block. For the decoder module, anisotropic convolution with a k*k*1 intra-slice convolution and a 1*1*k inter-slice convolution, is designed to reduce the computation burden. For the context block, we propose strip pooling module to capture anisotropic and long-range contextual information, which exists in abdominal scene. Quantitative evaluation on the FLARE2021 validation cases, this method achieves the average dice similarity coefficient (DSC) of 0.895 and average normalized surface distance (NSD) of 0.775. The average running time is 9.8 s per case in inference phase, and maximum used GPU memory is 1017 MB.
An Application of CNNs to Time Sequenced One Dimensional Data in Radiation Detection
Aug 28, 2019A Convolutional Neural Network architecture was used to classify various isotopes of time-sequenced gamma-ray spectra, a typical output of a radiation detection system of a type commonly fielded for security or environmental measurement purposes. A two-dimensional surface (waterfall plot) in time-energy space is interpreted as a monochromatic image and standard image-based CNN techniques are applied. This allows for the time-sequenced aspects of features in the data to be discovered by the network, as opposed to standard algorithms which arbitrarily time bin the data to satisfy the intuition of a human spectroscopist. The CNN architecture and results are presented along with a comparison to conventional techniques. The results of this novel application of image processing techniques to radiation data will be presented along with a comparison to more conventional adaptive methods.
* 11 pages, 9 figures, presented: SPIE Defense + Commercial Sensing, 16-18 Apr 2019, Baltimore, MD, United States
Traffic Flow Forecasting with Spatial-Temporal Graph Diffusion Network
Oct 08, 2021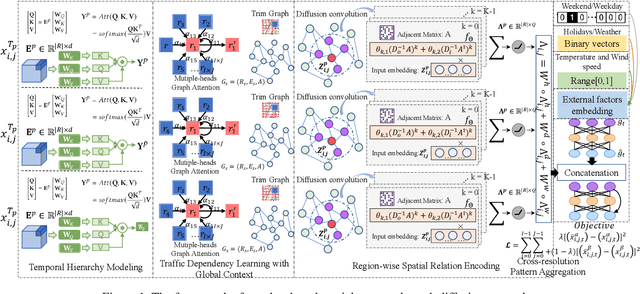
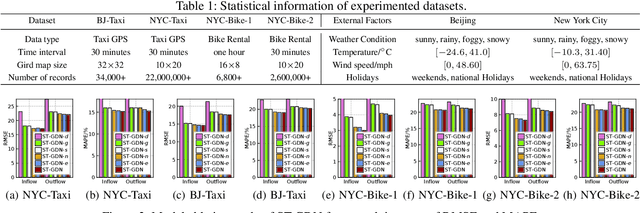
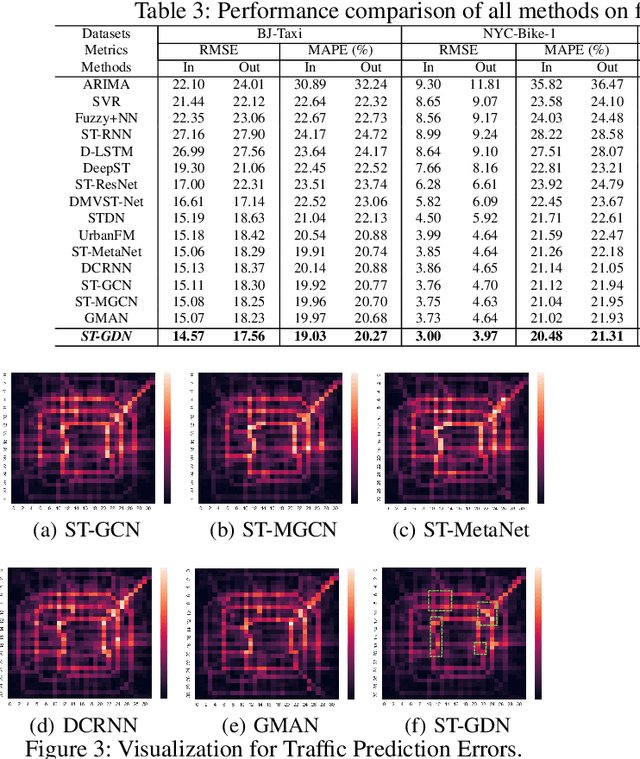
Accurate forecasting of citywide traffic flow has been playing critical role in a variety of spatial-temporal mining applications, such as intelligent traffic control and public risk assessment. While previous work has made significant efforts to learn traffic temporal dynamics and spatial dependencies, two key limitations exist in current models. First, only the neighboring spatial correlations among adjacent regions are considered in most existing methods, and the global inter-region dependency is ignored. Additionally, these methods fail to encode the complex traffic transition regularities exhibited with time-dependent and multi-resolution in nature. To tackle these challenges, we develop a new traffic prediction framework-Spatial-Temporal Graph Diffusion Network (ST-GDN). In particular, ST-GDN is a hierarchically structured graph neural architecture which learns not only the local region-wise geographical dependencies, but also the spatial semantics from a global perspective. Furthermore, a multi-scale attention network is developed to empower ST-GDN with the capability of capturing multi-level temporal dynamics. Experiments on several real-life traffic datasets demonstrate that ST-GDN outperforms different types of state-of-the-art baselines. Source codes of implementations are available at https://github.com/jill001/ST-GDN.
Minimizing LR(1) State Machines is NP-Hard
Oct 02, 2021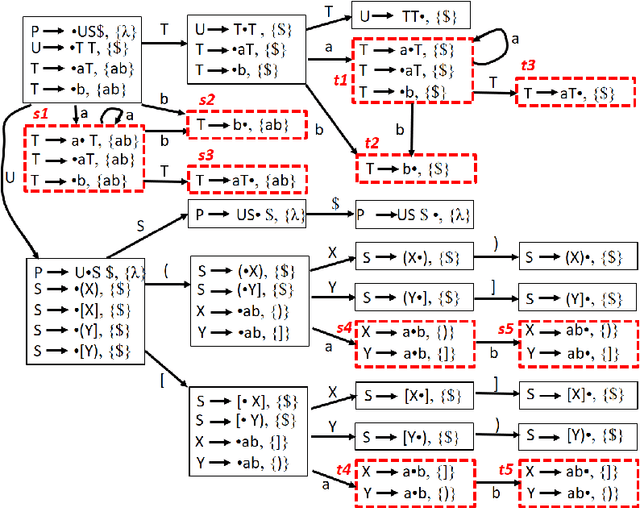
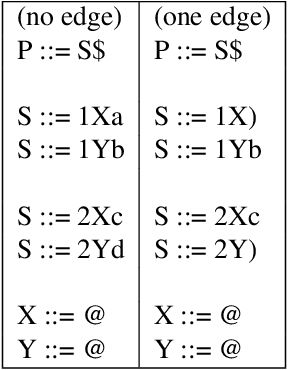
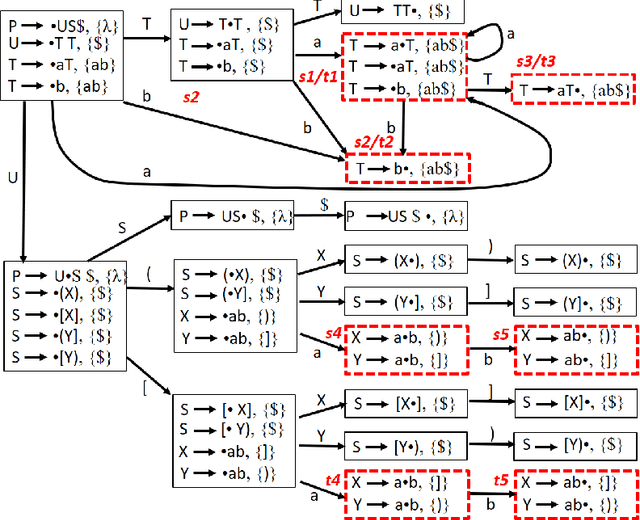
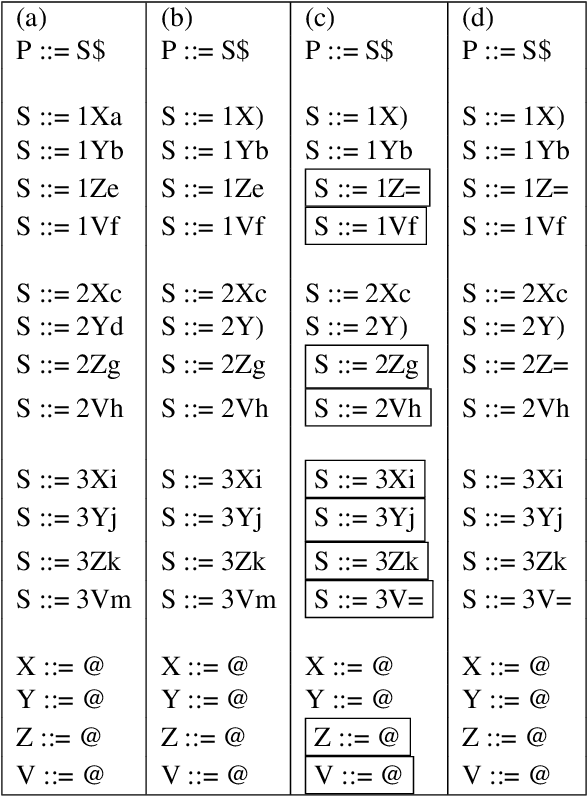
LR(1) parsing was a focus of extensive research in the past 50 years. Though most fundamental mysteries have been resolved, a few remain hidden in the dark corners. The one we bumped into is the minimization of the LR(1) state machines, which we prove is NP-hard. It is the node-coloring problem that is reduced to the minimization puzzle. The reduction makes use of two technique: indirect reduction and incremental construction. Indirect reduction means the graph to be colored is not reduced to an LR(1) state machine directly. Instead, it is reduced to a context-free grammar from which an LR(1) state machine is derived. Furthermore, by considering the nodes in the graph to be colored one at a time, the context-free grammar is incrementally extended from a template context-free grammar that is for a two-node graph. The extension is done by adding new grammar symbols and rules. A minimized LR(1) machine can be used to recover a minimum coloring of the original graph.
Fast Projection onto the Capped Simplex withApplications to Sparse Regression in Bioinformatics
Oct 19, 2021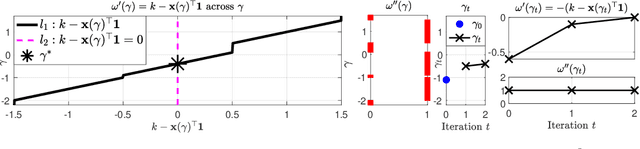
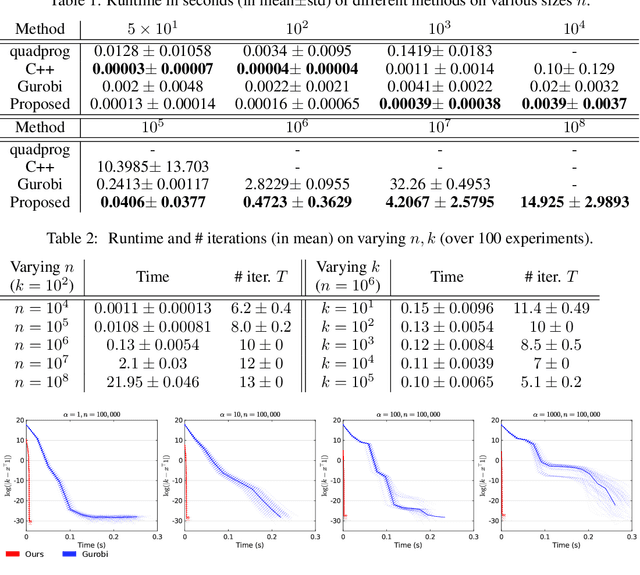
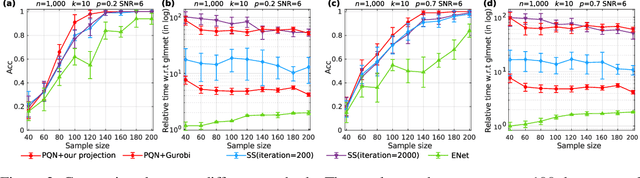
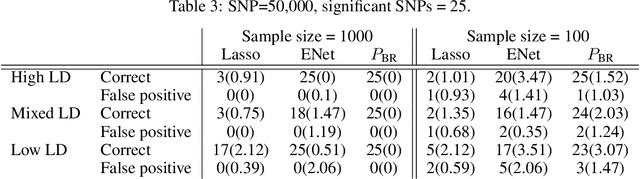
We consider the problem of projecting a vector onto the so-called k-capped simplex, which is a hyper-cube cut by a hyperplane. For an n-dimensional input vector with bounded elements, we found that a simple algorithm based on Newton's method is able to solve the projection problem to high precision with a complexity roughly about O(n), which has a much lower computational cost compared with the existing sorting-based methods proposed in the literature. We provide a theory for partial explanation and justification of the method. We demonstrate that the proposed algorithm can produce a solution of the projection problem with high precision on large scale datasets, and the algorithm is able to significantly outperform the state-of-the-art methods in terms of runtime (about 6-8 times faster than a commercial software with respect to CPU time for input vector with 1 million variables or more). We further illustrate the effectiveness of the proposed algorithm on solving sparse regression in a bioinformatics problem. Empirical results on the GWAS dataset (with 1,500,000 single-nucleotide polymorphisms) show that, when using the proposed method to accelerate the Projected Quasi-Newton (PQN) method, the accelerated PQN algorithm is able to handle huge-scale regression problem and it is more efficient (about 3-6 times faster) than the current state-of-the-art methods.
An algorithm for a fairer and better voting system
Oct 13, 2021The major finding, of this article, is an ensemble method, but more exactly, a novel, better ranked voting system (and other variations of it), that aims to solve the problem of finding the best candidate to represent the voters. We have the source code on GitHub, for making realistic simulations of elections, based on artificial intelligence for comparing different variations of the algorithm, and other already known algorithms. We have convincing evidence that our algorithm is better than Instant-Runoff Voting, Preferential Block Voting, Single Transferable Vote, and First Past The Post (if certain, natural conditions are met, to support the wisdom of the crowds). By also comparing with the best voter, we demonstrated the wisdom of the crowds, suggesting that democracy (distributed system) is a better option than dictatorship (centralized system), if those certain, natural conditions are met. Voting systems are not restricted to politics, they are ensemble methods for artificial intelligence, but the context of this article is natural intelligence. It is important to find a system that is fair (e.g. freedom of expression on the ballot exists), especially when the outcome of the voting system has social impact: some voting systems have the unfair inevitability to trend (over time) towards the same two major candidates (Duverger's law).
Score-based diffusion models for accelerated MRI
Oct 08, 2021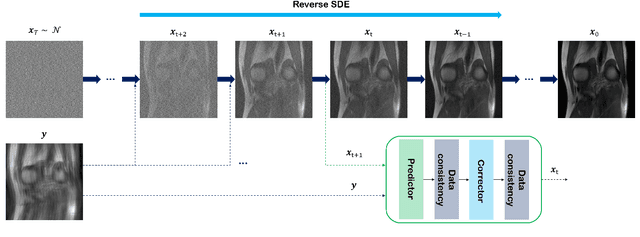
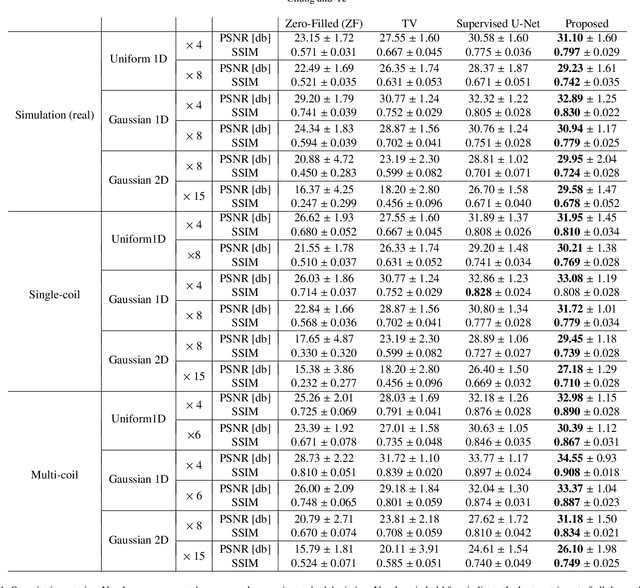
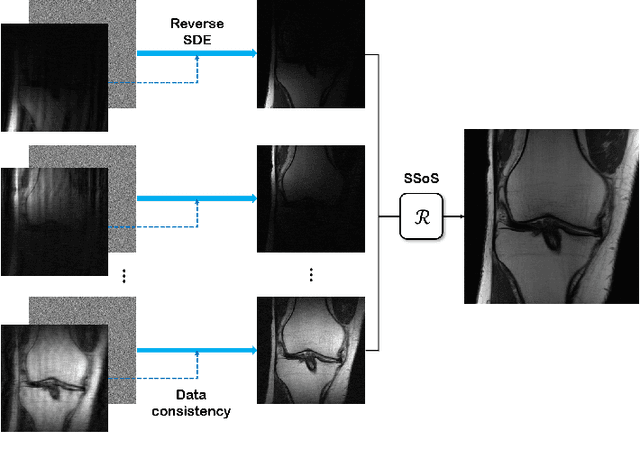
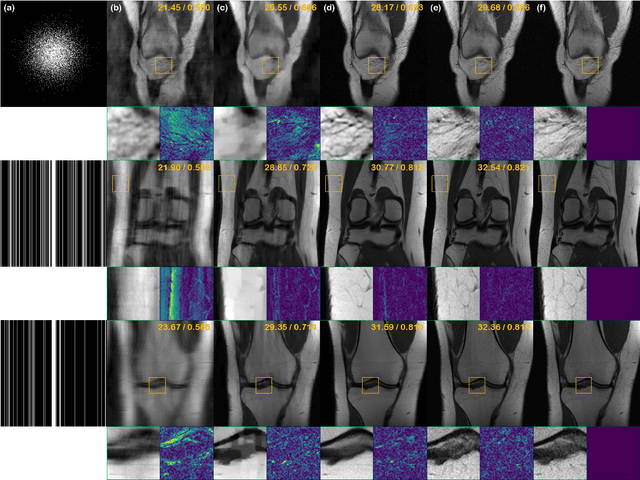
Score-based diffusion models provide a powerful way to model images using the gradient of the data distribution. Leveraging the learned score function as a prior, here we introduce a way to sample data from a conditional distribution given the measurements, such that the model can be readily used for solving inverse problems in imaging, especially for accelerated MRI. In short, we train a continuous time-dependent score function with denoising score matching. Then, at the inference stage, we iterate between numerical SDE solver and data consistency projection step to achieve reconstruction. Our model requires magnitude images only for training, and yet is able to reconstruct complex-valued data, and even extends to parallel imaging. The proposed method is agnostic to sub-sampling patterns, and can be used with any sampling schemes. Also, due to its generative nature, our approach can quantify uncertainty, which is not possible with standard regression settings. On top of all the advantages, our method also has very strong performance, even beating the models trained with full supervision. With extensive experiments, we verify the superiority of our method in terms of quality and practicality.