 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
HUNTER: AI based Holistic Resource Management for Sustainable Cloud Computing
Oct 28, 2021

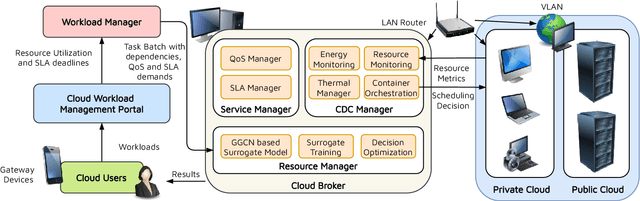
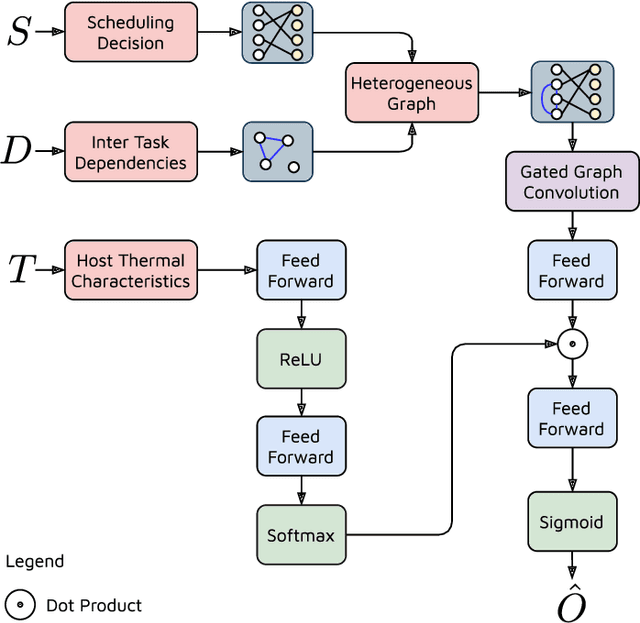
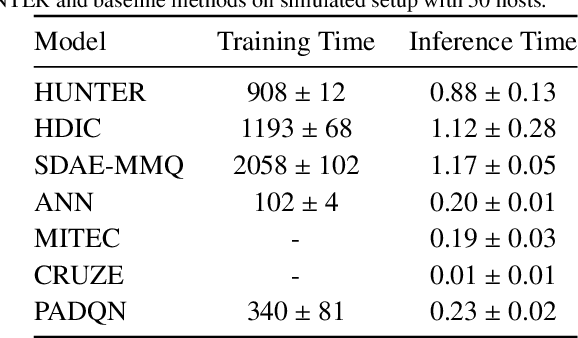
The worldwide adoption of cloud data centers (CDCs) has given rise to the ubiquitous demand for hosting application services on the cloud. Further, contemporary data-intensive industries have seen a sharp upsurge in the resource requirements of modern applications. This has led to the provisioning of an increased number of cloud servers, giving rise to higher energy consumption and, consequently, sustainability concerns. Traditional heuristics and reinforcement learning based algorithms for energy-efficient cloud resource management address the scalability and adaptability related challenges to a limited extent. Existing work often fails to capture dependencies across thermal characteristics of hosts, resource consumption of tasks and the corresponding scheduling decisions. This leads to poor scalability and an increase in the compute resource requirements, particularly in environments with non-stationary resource demands. To address these limitations, we propose an artificial intelligence (AI) based holistic resource management technique for sustainable cloud computing called HUNTER. The proposed model formulates the goal of optimizing energy efficiency in data centers as a multi-objective scheduling problem, considering three important models: energy, thermal and cooling. HUNTER utilizes a Gated Graph Convolution Network as a surrogate model for approximating the Quality of Service (QoS) for a system state and generating optimal scheduling decisions. Experiments on simulated and physical cloud environments using the CloudSim toolkit and the COSCO framework show that HUNTER outperforms state-of-the-art baselines in terms of energy consumption, SLA violation, scheduling time, cost and temperature by up to 12, 35, 43, 54 and 3 percent respectively.
ViT Cane: Visual Assistant for the Visually Impaired
Sep 26, 2021
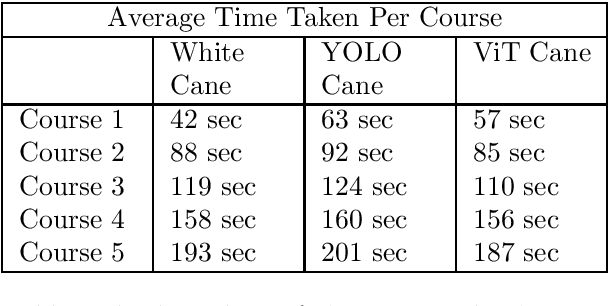
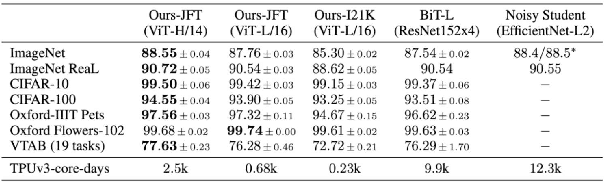
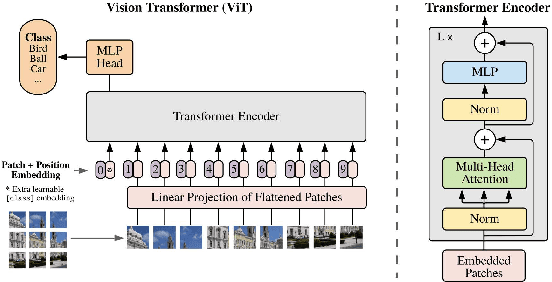
Blind and visually challenged face multiple issues with navigating the world independently. Some of these challenges include finding the shortest path to a destination and detecting obstacles from a distance. To tackle this issue, this paper proposes ViT Cane, which leverages a vision transformer model in order to detect obstacles in real-time. Our entire system consists of a Pi Camera Module v2, Raspberry Pi 4B with 8GB Ram and 4 motors. Based on tactile input using the 4 motors, the obstacle detection model is highly efficient in helping visually impaired navigate unknown terrain and is designed to be easily reproduced. The paper discusses the utility of a Visual Transformer model in comparison to other CNN based models for this specific application. Through rigorous testing, the proposed obstacle detection model has achieved higher performance on the Common Object in Context (COCO) data set than its CNN counterpart. Comprehensive field tests were conducted to verify the effectiveness of our system for holistic indoor understanding and obstacle avoidance.
Text analysis and deep learning: A network approach
Oct 08, 2021
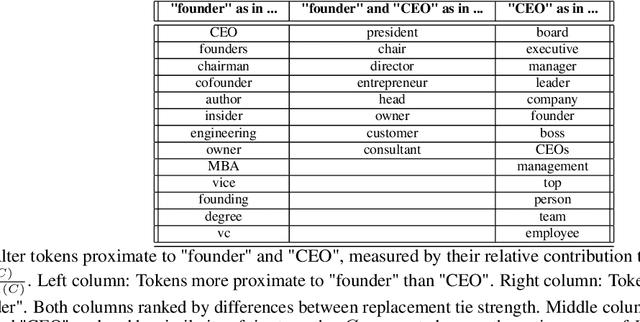
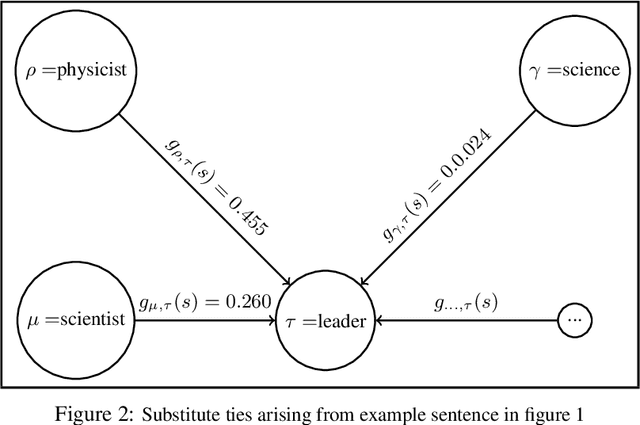
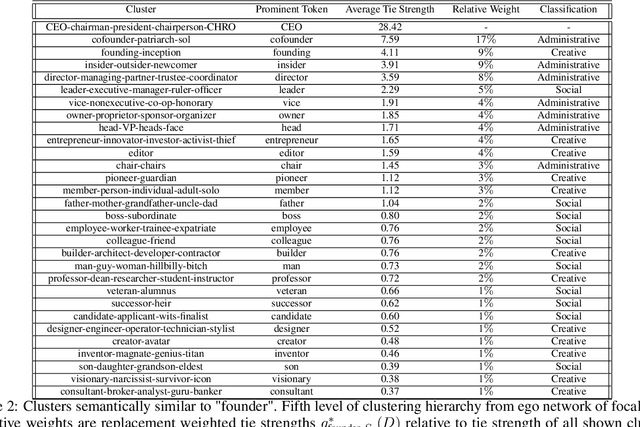
Much information available to applied researchers is contained within written language or spoken text. Deep language models such as BERT have achieved unprecedented success in many applications of computational linguistics. However, much less is known about how these models can be used to analyze existing text. We propose a novel method that combines transformer models with network analysis to form a self-referential representation of language use within a corpus of interest. Our approach produces linguistic relations strongly consistent with the underlying model as well as mathematically well-defined operations on them, while reducing the amount of discretionary choices of representation and distance measures. It represents, to the best of our knowledge, the first unsupervised method to extract semantic networks directly from deep language models. We illustrate our approach in a semantic analysis of the term "founder". Using the entire corpus of Harvard Business Review from 1980 to 2020, we find that ties in our network track the semantics of discourse over time, and across contexts, identifying and relating clusters of semantic and syntactic relations. Finally, we discuss how this method can also complement and inform analyses of the behavior of deep learning models.
Wasserstein GANs with Gradient Penalty Compute Congested Transport
Sep 01, 2021Wasserstein GANs with Gradient Penalty (WGAN-GP) are an extremely popular method for training generative models to produce high quality synthetic data. While WGAN-GP were initially developed to calculate the Wasserstein 1 distance between generated and real data, recent works (e.g. Stanczuk et al. (2021)) have provided empirical evidence that this does not occur, and have argued that WGAN-GP perform well not in spite of this issue, but because of it. In this paper we show for the first time that WGAN-GP compute the minimum of a different optimal transport problem, the so-called congested transport (Carlier et al. (2008)). Congested transport determines the cost of moving one distribution to another under a transport model that penalizes congestion. For WGAN-GP, we find that the congestion penalty has a spatially varying component determined by the sampling strategy used in Gulrajani et al. (2017) which acts like a local speed limit, making congestion cost less in some regions than others. This aspect of the congested transport problem is new in that the congestion penalty turns out to be unbounded and depend on the distributions to be transported, and so we provide the necessary mathematical proofs for this setting. We use our discovery to show that the gradients of solutions to the optimization problem in WGAN-GP determine the time averaged momentum of optimal mass flow. This is in contrast to the gradients of Kantorovich potentials for the Wasserstein 1 distance, which only determine the normalized direction of flow. This may explain, in support of Stanczuk et al. (2021), the success of WGAN-GP, since the training of the generator is based on these gradients.
An Interleaved Approach to Trait-Based Task Allocation and Scheduling
Aug 05, 2021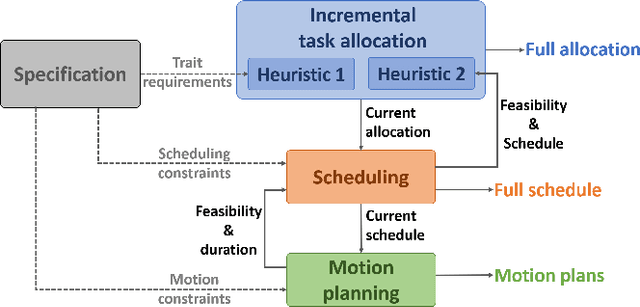
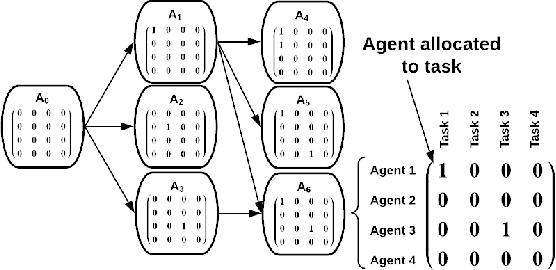
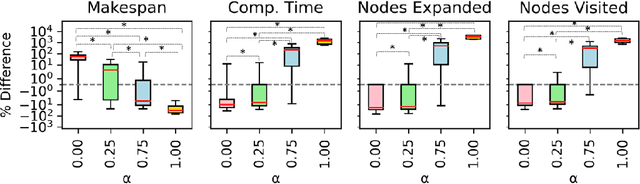
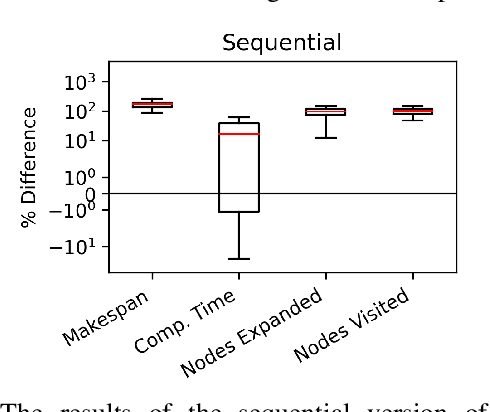
To realize effective heterogeneous multi-robot teams, researchers must leverage individual robots' relative strengths and coordinate their individual behaviors. Specifically, heterogeneous multi-robot systems must answer three important questions: \textit{who} (task allocation), \textit{when} (scheduling), and \textit{how} (motion planning). While specific variants of each of these problems are known to be NP-Hard, their interdependence only exacerbates the challenges involved in solving them together. In this paper, we present a novel framework that interleaves task allocation, scheduling, and motion planning. We introduce a search-based approach for trait-based time-extended task allocation named Incremental Task Allocation Graph Search (ITAGS). In contrast to approaches that solve the three problems in sequence, ITAGS's interleaved approach enables efficient search for allocations while simultaneously satisfying scheduling constraints and accounting for the time taken to execute motion plans. To enable effective interleaving, we develop a convex combination of two search heuristics that optimizes the satisfaction of task requirements as well as the makespan of the associated schedule. We demonstrate the efficacy of ITAGS using detailed ablation studies and comparisons against two state-of-the-art algorithms in a simulated emergency response domain.
Discover, Hallucinate, and Adapt: Open Compound Domain Adaptation for Semantic Segmentation
Oct 08, 2021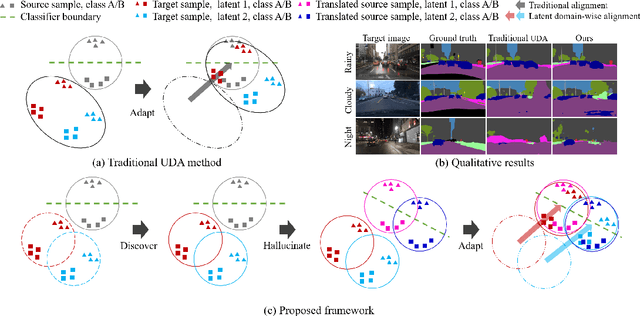
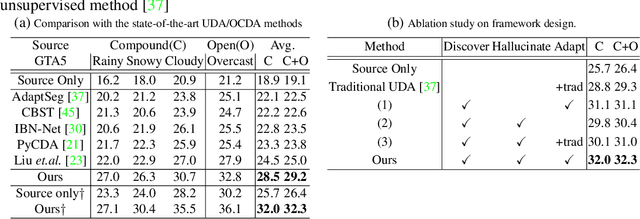
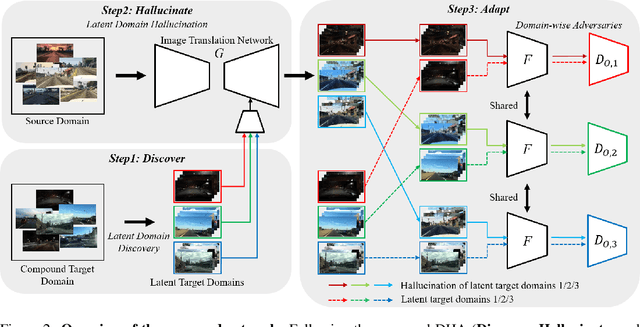
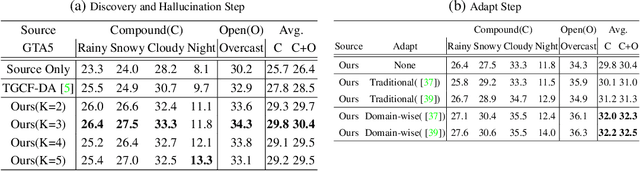
Unsupervised domain adaptation (UDA) for semantic segmentation has been attracting attention recently, as it could be beneficial for various label-scarce real-world scenarios (e.g., robot control, autonomous driving, medical imaging, etc.). Despite the significant progress in this field, current works mainly focus on a single-source single-target setting, which cannot handle more practical settings of multiple targets or even unseen targets. In this paper, we investigate open compound domain adaptation (OCDA), which deals with mixed and novel situations at the same time, for semantic segmentation. We present a novel framework based on three main design principles: discover, hallucinate, and adapt. The scheme first clusters compound target data based on style, discovering multiple latent domains (discover). Then, it hallucinates multiple latent target domains in source by using image-translation (hallucinate). This step ensures the latent domains in the source and the target to be paired. Finally, target-to-source alignment is learned separately between domains (adapt). In high-level, our solution replaces a hard OCDA problem with much easier multiple UDA problems. We evaluate our solution on standard benchmark GTA to C-driving, and achieved new state-of-the-art results.
Learning Models as Functionals of Signed-Distance Fields for Manipulation Planning
Oct 02, 2021



This work proposes an optimization-based manipulation planning framework where the objectives are learned functionals of signed-distance fields that represent objects in the scene. Most manipulation planning approaches rely on analytical models and carefully chosen abstractions/state-spaces to be effective. A central question is how models can be obtained from data that are not primarily accurate in their predictions, but, more importantly, enable efficient reasoning within a planning framework, while at the same time being closely coupled to perception spaces. We show that representing objects as signed-distance fields not only enables to learn and represent a variety of models with higher accuracy compared to point-cloud and occupancy measure representations, but also that SDF-based models are suitable for optimization-based planning. To demonstrate the versatility of our approach, we learn both kinematic and dynamic models to solve tasks that involve hanging mugs on hooks and pushing objects on a table. We can unify these quite different tasks within one framework, since SDFs are the common object representation. Video: https://youtu.be/ga8Wlkss7co
Noisy-to-Noisy Voice Conversion Framework with Denoising Model
Sep 22, 2021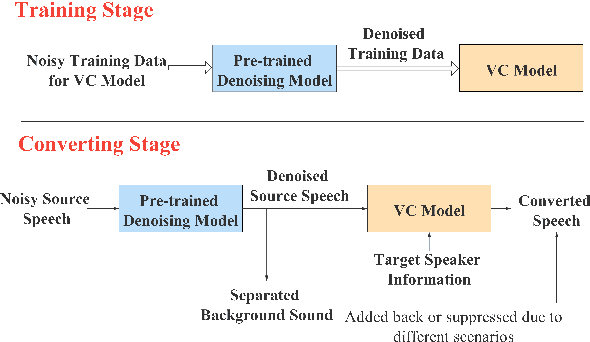
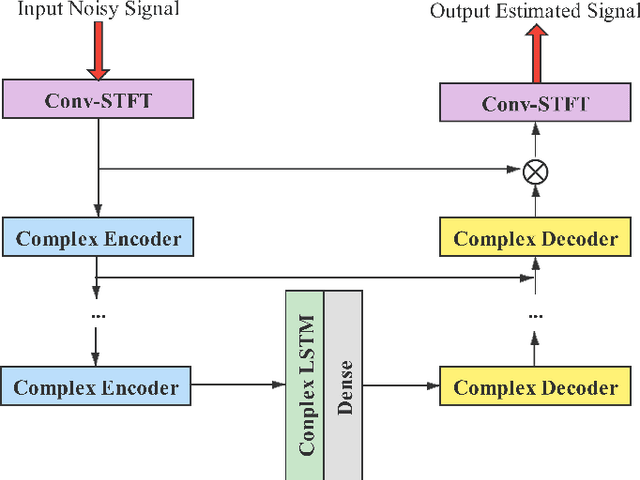
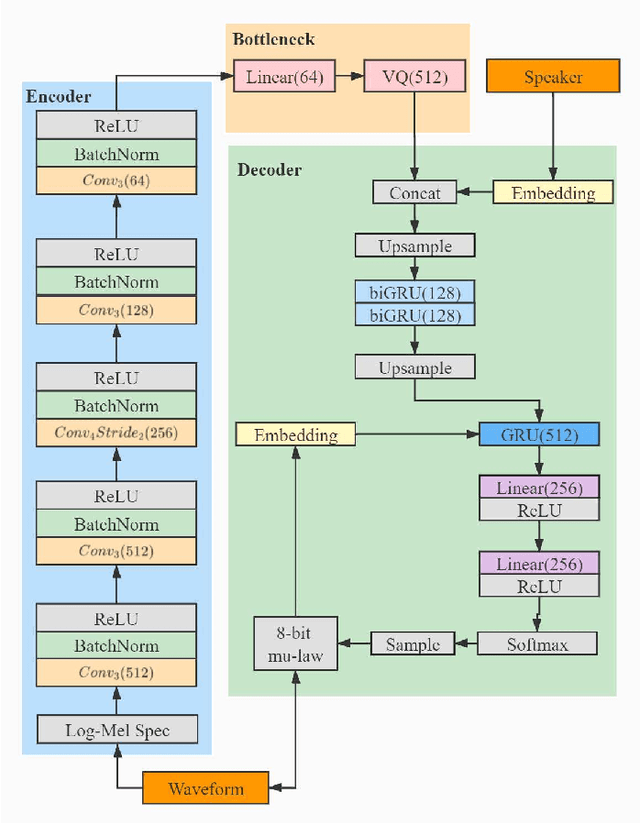
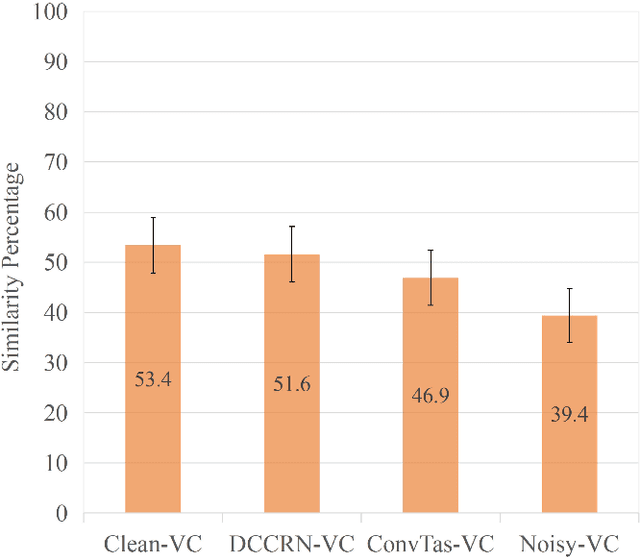
In a conventional voice conversion (VC) framework, a VC model is often trained with a clean dataset consisting of speech data carefully recorded and selected by minimizing background interference. However, collecting such a high-quality dataset is expensive and time-consuming. Leveraging crowd-sourced speech data in training is more economical. Moreover, for some real-world VC scenarios such as VC in video and VC-based data augmentation for speech recognition systems, the background sounds themselves are also informative and need to be maintained. In this paper, to explore VC with the flexibility of handling background sounds, we propose a noisy-to-noisy (N2N) VC framework composed of a denoising module and a VC module. With the proposed framework, we can convert the speaker's identity while preserving the background sounds. Both objective and subjective evaluations are conducted, and the results reveal the effectiveness of the proposed framework.
Tetra-Tagging: Word-Synchronous Parsing with Linear-Time Inference
Apr 22, 2019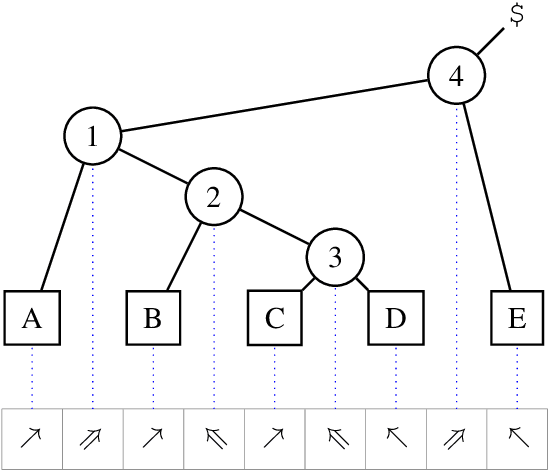

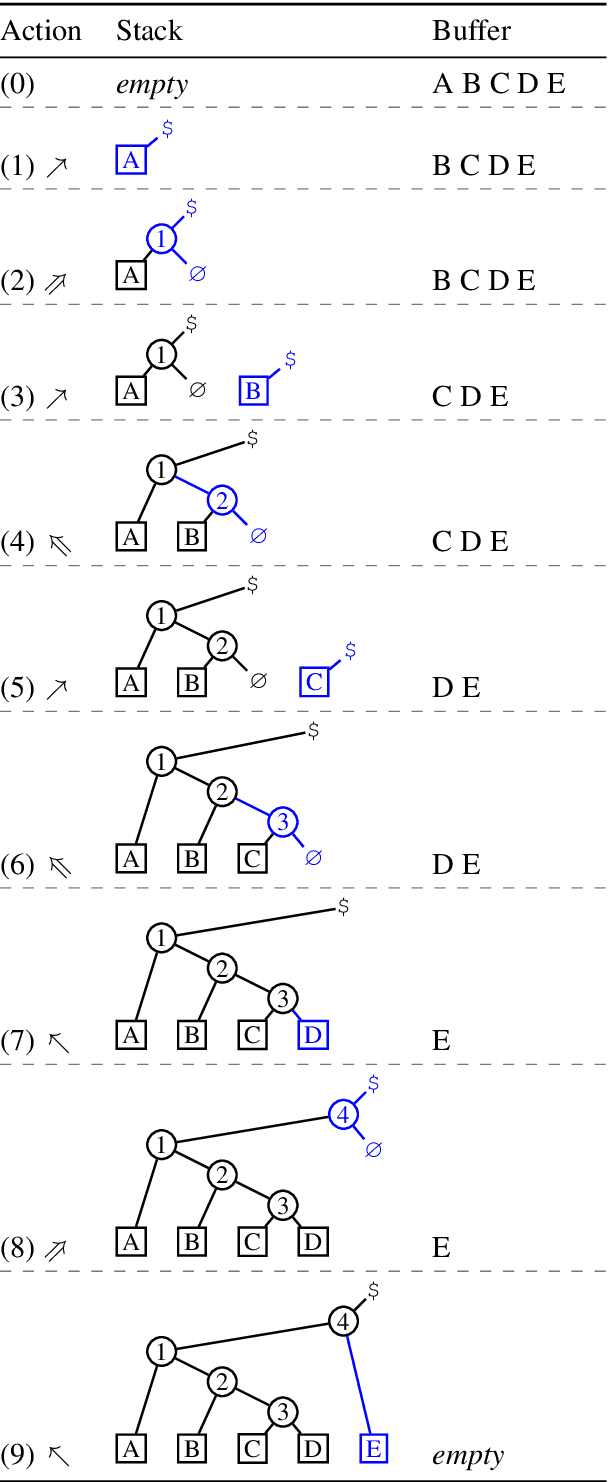
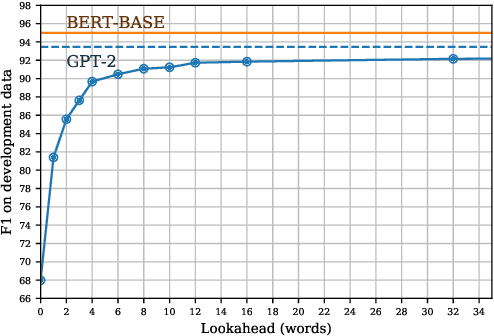
We present a constituency parsing algorithm that maps from word-aligned contextualized feature vectors to parse trees. Our algorithm proceeds strictly left-to-right, processing one word at a time by assigning it a label from a small vocabulary. We show that, with mild assumptions, our inference procedure requires constant computation time per word. Our method gets 95.4 F1 on the WSJ test set.
Efficient Context-Aware Network for Abdominal Multi-organ Segmentation
Sep 22, 2021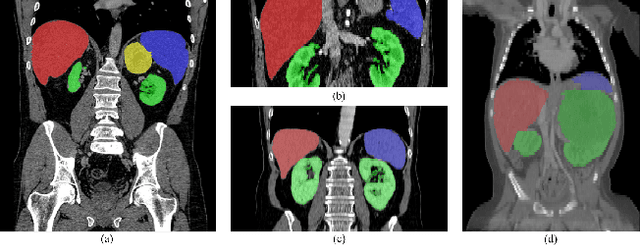
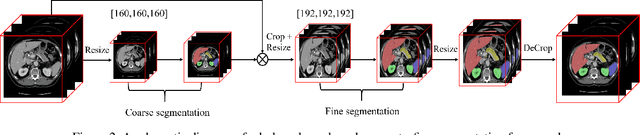
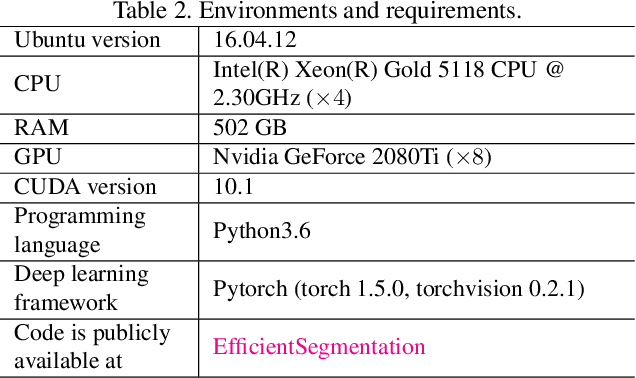
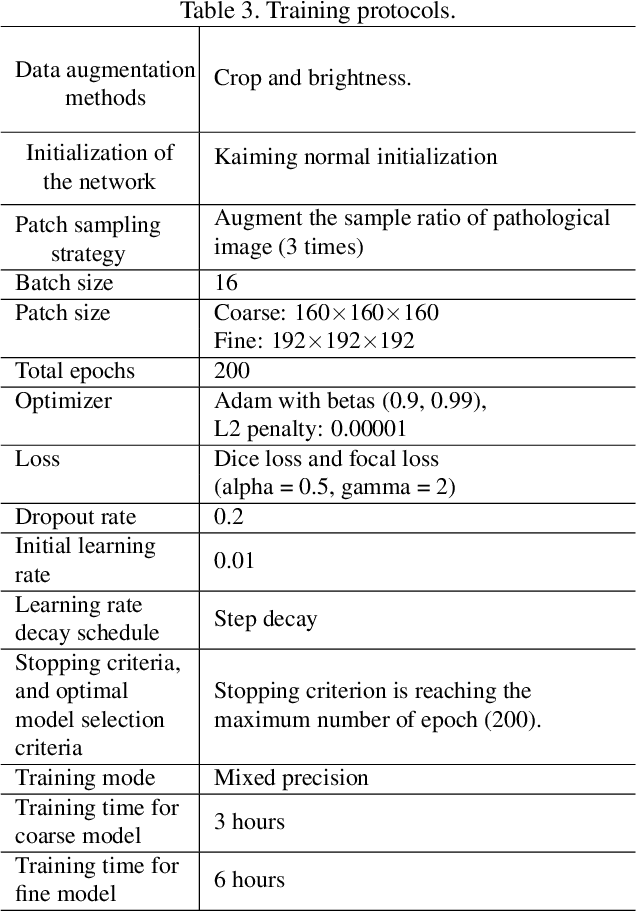
The contextual information, presented in abdominal CT scan, is relative consistent. In order to make full use of the overall 3D context, we develop a whole-volumebased coarse-to-fine framework for efficient and effective abdominal multi-organ segmentation. We propose a new efficientSegNet network, which is composed of encoder, decoder and context block. For the decoder module, anisotropic convolution with a k*k*1 intra-slice convolution and a 1*1*k inter-slice convolution, is designed to reduce the computation burden. For the context block, we propose strip pooling module to capture anisotropic and long-range contextual information, which exists in abdominal scene. Quantitative evaluation on the FLARE2021 validation cases, this method achieves the average dice similarity coefficient (DSC) of 0.895 and average normalized surface distance (NSD) of 0.775. The average running time is 9.8 s per case in inference phase, and maximum used GPU memory is 1017 MB.