 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Transfer Learning for Multi-source Entity Linkage via Domain Adaptation
Oct 27, 2021
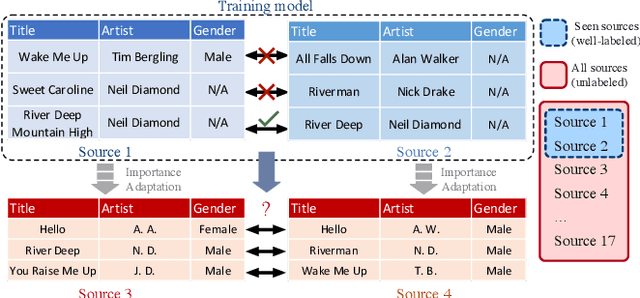

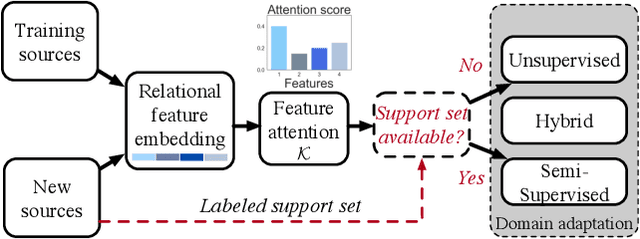
Multi-source entity linkage focuses on integrating knowledge from multiple sources by linking the records that represent the same real world entity. This is critical in high-impact applications such as data cleaning and user stitching. The state-of-the-art entity linkage pipelines mainly depend on supervised learning that requires abundant amounts of training data. However, collecting well-labeled training data becomes expensive when the data from many sources arrives incrementally over time. Moreover, the trained models can easily overfit to specific data sources, and thus fail to generalize to new sources due to significant differences in data and label distributions. To address these challenges, we present AdaMEL, a deep transfer learning framework that learns generic high-level knowledge to perform multi-source entity linkage. AdaMEL models the attribute importance that is used to match entities through an attribute-level self-attention mechanism, and leverages the massive unlabeled data from new data sources through domain adaptation to make it generic and data-source agnostic. In addition, AdaMEL is capable of incorporating an additional set of labeled data to more accurately integrate data sources with different attribute importance. Extensive experiments show that our framework achieves state-of-the-art results with 8.21% improvement on average over methods based on supervised learning. Besides, it is more stable in handling different sets of data sources in less runtime.
HDRVideo-GAN: Deep Generative HDR Video Reconstruction
Oct 22, 2021


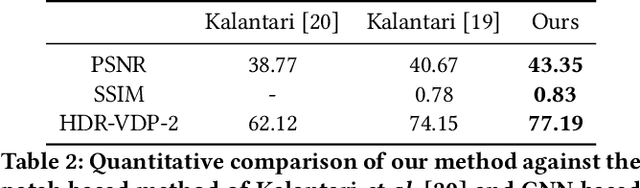
High dynamic range (HDR) videos provide a more visually realistic experience than the standard low dynamic range (LDR) videos. Despite having significant progress in HDR imaging, it is still a challenging task to capture high-quality HDR video with a conventional off-the-shelf camera. Existing approaches rely entirely on using dense optical flow between the neighboring LDR sequences to reconstruct an HDR frame. However, they lead to inconsistencies in color and exposure over time when applied to alternating exposures with noisy frames. In this paper, we propose an end-to-end GAN-based framework for HDR video reconstruction from LDR sequences with alternating exposures. We first extract clean LDR frames from noisy LDR video with alternating exposures with a denoising network trained in a self-supervised setting. Using optical flow, we then align the neighboring alternating-exposure frames to a reference frame and then reconstruct high-quality HDR frames in a complete adversarial setting. To further improve the robustness and quality of generated frames, we incorporate temporal stability-based regularization term along with content and style-based losses in the cost function during the training procedure. Experimental results demonstrate that our framework achieves state-of-the-art performance and generates superior quality HDR frames of a video over the existing methods.
Risk-Aware Learning for Scalable Voltage Optimization in Distribution Grids
Oct 04, 2021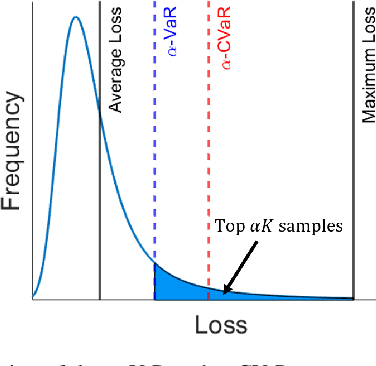
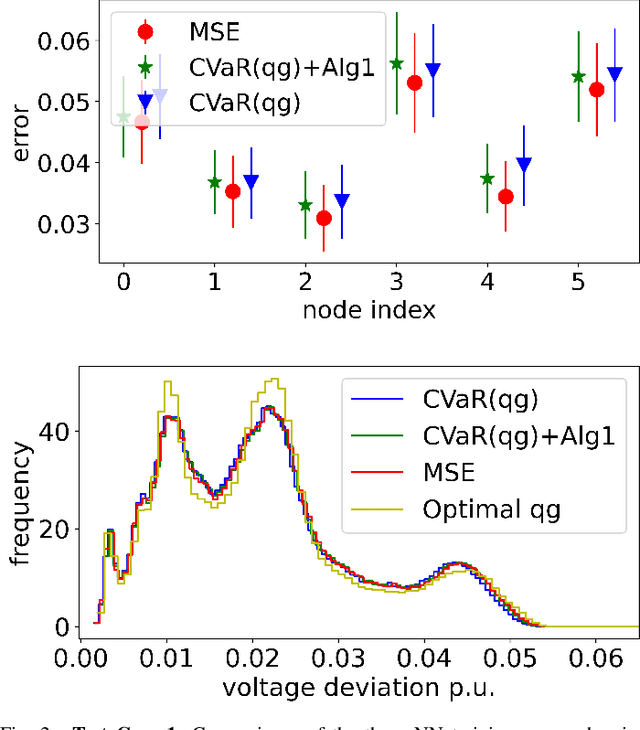
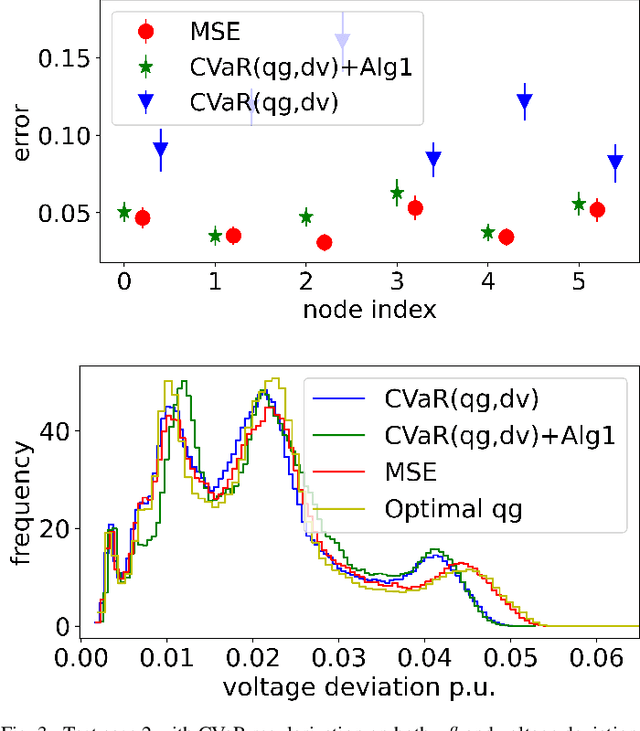
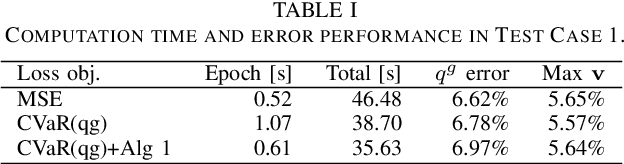
Real-time coordination of distributed energy resources (DERs) is crucial for regulating the voltage profile in distribution grids. By capitalizing on a scalable neural network (NN) architecture, machine learning tools can attain decentralized DER decisions by minimizing the average loss of prediction. This paper aims to improve these learning-enabled approaches by accounting for the potential risks associated with reactive power prediction and voltage deviation. Specifically, we advocate to measure such risks using the conditional value-at-risk (CVaR) loss based on the worst-case samples only, which could lead to the learning efficiency issue. To tackle this issue, we propose to accelerate the training process under the CVaR loss objective by selecting the mini-batches that are more likely to contain the worst-case samples of interest. Numerical tests using real-world data on the IEEE 123-bus test case have demonstrated the computation and safety improvements of the proposed risk-aware learning algorithm for decentralized DER decision making in distribution systems.
Large-Scale News Classification using BERT Language Model: Spark NLP Approach
Jul 15, 2021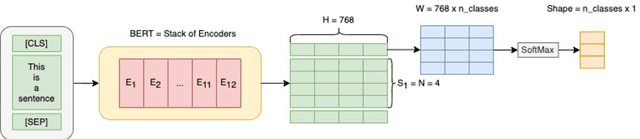

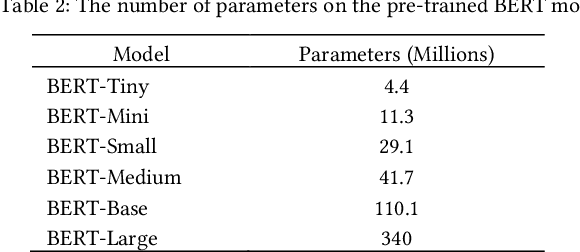

The rise of big data analytics on top of NLP increases the computational burden for text processing at scale. The problems faced in NLP are very high dimensional text, so it takes a high computation resource. The MapReduce allows parallelization of large computations and can improve the efficiency of text processing. This research aims to study the effect of big data processing on NLP tasks based on a deep learning approach. We classify a big text of news topics with fine-tuning BERT used pre-trained models. Five pre-trained models with a different number of parameters were used in this study. To measure the efficiency of this method, we compared the performance of the BERT with the pipelines from Spark NLP. The result shows that BERT without Spark NLP gives higher accuracy compared to BERT with Spark NLP. The accuracy average and training time of all models using BERT is 0.9187 and 35 minutes while using BERT with Spark NLP pipeline is 0.8444 and 9 minutes. The bigger model will take more computation resources and need a longer time to complete the tasks. However, the accuracy of BERT with Spark NLP only decreased by an average of 5.7%, while the training time was reduced significantly by 62.9% compared to BERT without Spark NLP.
Estimation of Stationary Optimal Transport Plans
Jul 25, 2021We study optimal transport problems in which finite-valued quantities of interest evolve dynamically over time in a stationary fashion. Mathematically, this is a special case of the general optimal transport problem in which the distributions under study represent stationary processes and the cost depends on a finite number of time points. In this setting, we argue that one should restrict attention to stationary couplings, also known as joinings, which have close connections with long run average cost. We introduce estimators of both optimal joinings and the optimal joining cost, and we establish their consistency under mild conditions. Under stronger mixing assumptions we establish finite-sample error rates for the same estimators that extend the best known results in the iid case. Finally, we extend the consistency and rate analysis to an entropy-penalized version of the optimal joining problem.
PicTalky: Augmentative and Alternative Communication Software for Language Developmental Disabilities
Sep 27, 2021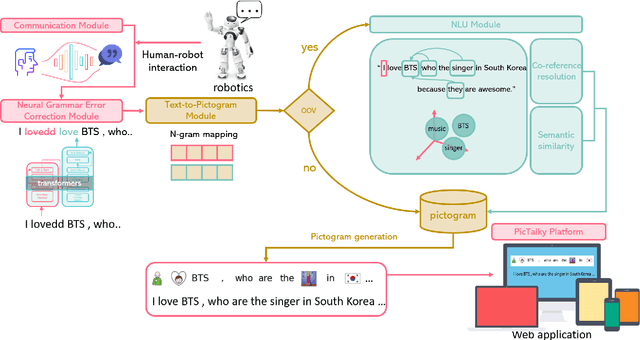

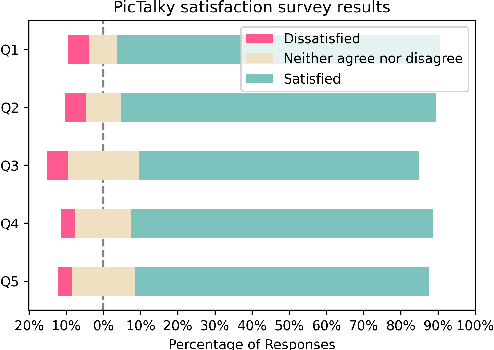
Augmentative and alternative communication (AAC) is a practical means of communication for people with language disabilities. In this study, we propose PicTalky, which is an AI-based AAC system that helps children with language developmental disabilities to improve their communication skills and language comprehension abilities. PicTalky can process both text and pictograms more accurately by connecting a series of neural-based NLP modules. Moreover, we perform quantitative and qualitative analyses on the essential features of PicTalky. It is expected that those suffering from language problems will be able to express their intentions or desires more easily and improve their quality of life by using this service. We have made the models freely available alongside a demonstration of the Web interface. Furthermore, we implemented robotics AAC for the first time by applying PicTalky to the NAO robot.
Astrocytes mediate analogous memory in a multi-layer neuron-astrocytic network
Aug 31, 2021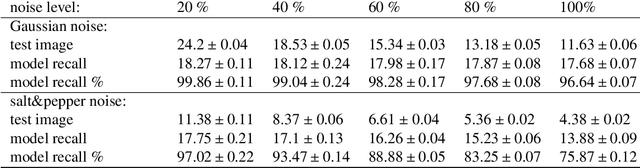
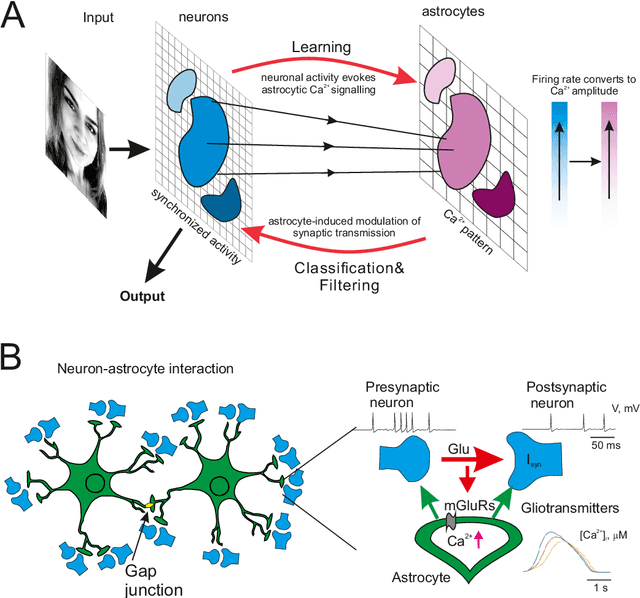


Modeling the neuronal processes underlying short-term working memory remains the focus of many theoretical studies in neuroscience. Here we propose a mathematical model of spiking neuron network (SNN) demonstrating how a piece of information can be maintained as a robust activity pattern for several seconds then completely disappear if no other stimuli come. Such short-term memory traces are preserved due to the activation of astrocytes accompanying the SNN. The astrocytes exhibit calcium transients at a time scale of seconds. These transients further modulate the efficiency of synaptic transmission and, hence, the firing rate of neighboring neurons at diverse timescales through gliotransmitter release. We show how such transients continuously encode frequencies of neuronal discharges and provide robust short-term storage of analogous information. This kind of short-term memory can keep operative information for seconds, then completely forget it to avoid overlapping with forthcoming patterns. The SNN is inter-connected with the astrocytic layer by local inter-cellular diffusive connections. The astrocytes are activated only when the neighboring neurons fire quite synchronously, e.g. when an information pattern is loaded. For illustration, we took greyscale photos of people's faces where the grey level encoded the level of applied current stimulating the neurons. The astrocyte feedback modulates (facilitates) synaptic transmission by varying the frequency of neuronal firing. We show how arbitrary patterns can be loaded, then stored for a certain interval of time, and retrieved if the appropriate clue pattern is applied to the input.
Which One is Better: Assessing Objective Metrics for Point Cloud Compression
Sep 15, 2021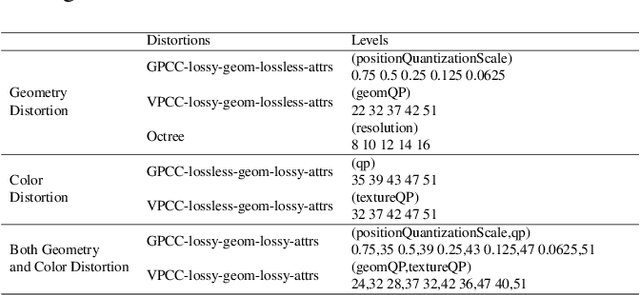

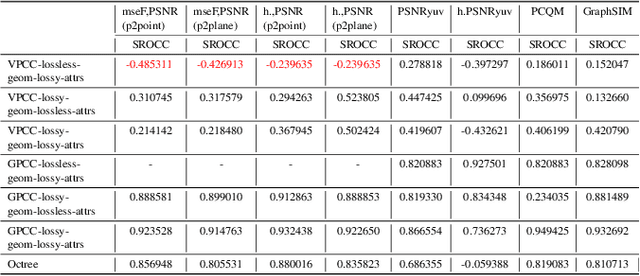
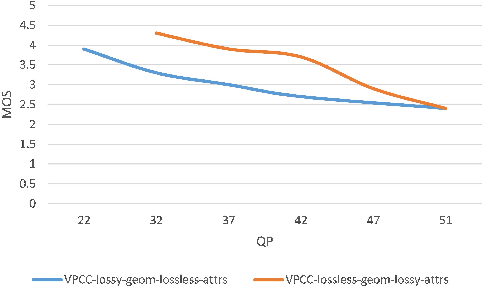
Point cloud compression (PCC) has made remarkable achievement in recent years. In the mean time, point cloud quality assessment (PCQA) also realize gratifying development. Some recently emerged metrics present robust performance on public point cloud assessment databases. However, these metrics have not been evaluated specifically for PCC to verify whether they exhibit consistent performance with the subjective perception. In this paper, we establish a new dataset for compression evaluation first, which contains 175 compressed point clouds in total, deriving from 7 compression algorithms with 5 compression levels. Then leveraging the proposed dataset, we evaluate the performance of the existing PCQA metrics in terms of different compression types. The results demonstrate some deficiencies of existing metrics in compression evaluation.
Comprehensive learning particle swarm optimization enabled modeling framework for multi-step-ahead influenza prediction
Oct 27, 2021
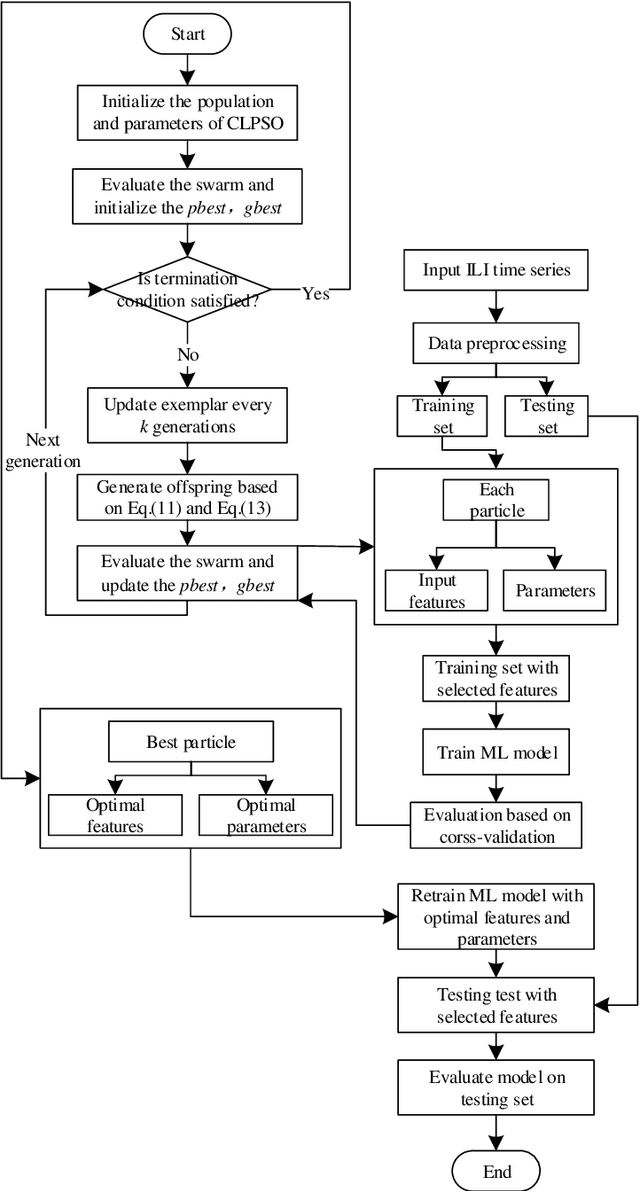
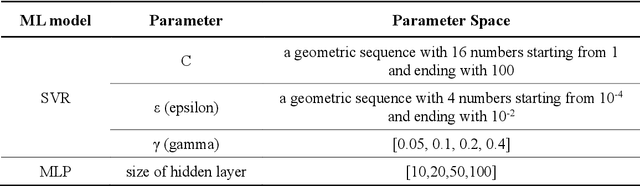
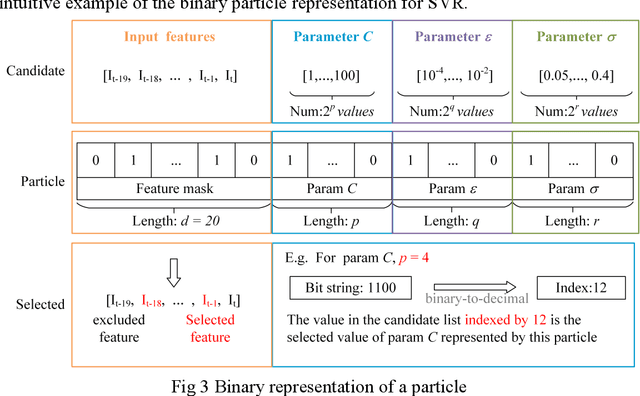
Epidemics of influenza are major public health concerns. Since influenza prediction always relies on the weekly clinical or laboratory surveillance data, typically the weekly Influenza-like illness (ILI) rate series, accurate multi-step-ahead influenza predictions using ILI series is of great importance, especially, to the potential coming influenza outbreaks. This study proposes Comprehensive Learning Particle Swarm Optimization based Machine Learning (CLPSO-ML) framework incorporating support vector regression (SVR) and multilayer perceptron (MLP) for multi-step-ahead influenza prediction. A comprehensive examination and comparison of the performance and potential of three commonly used multi-step-ahead prediction modeling strategies, including iterated strategy, direct strategy and multiple-input multiple-output (MIMO) strategy, was conducted using the weekly ILI rate series from both the Southern and Northern China. The results show that: (1) The MIMO strategy achieves the best multi-step-ahead prediction, and is potentially more adaptive for longer horizon; (2) The iterated strategy demonstrates special potentials for deriving the least time difference between the occurrence of the predicted peak value and the true peak value of an influenza outbreak; (3) For ILI in the Northern China, SVR model implemented with MIMO strategy performs best, and SVR with iterated strategy also shows remarkable performance especially during outbreak periods; while for ILI in the Southern China, both SVR and MLP models with MIMO strategy have competitive prediction performance
SubTab: Subsetting Features of Tabular Data for Self-Supervised Representation Learning
Oct 27, 2021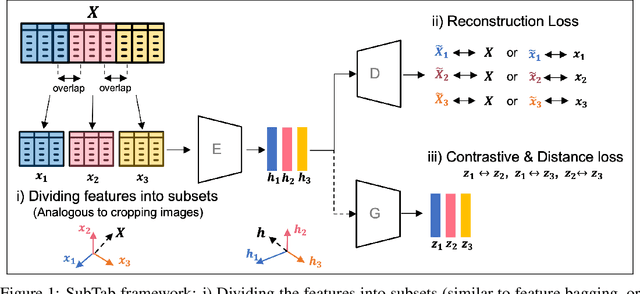
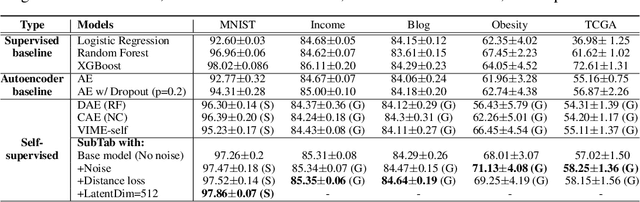
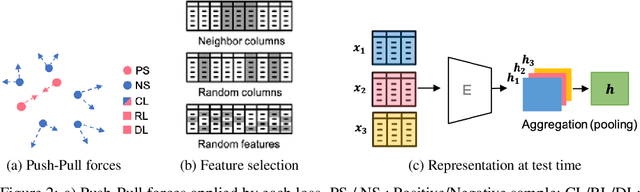
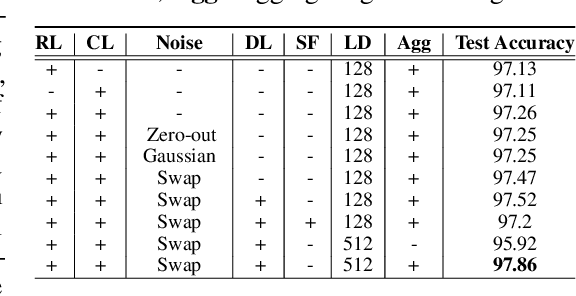
Self-supervised learning has been shown to be very effective in learning useful representations, and yet much of the success is achieved in data types such as images, audio, and text. The success is mainly enabled by taking advantage of spatial, temporal, or semantic structure in the data through augmentation. However, such structure may not exist in tabular datasets commonly used in fields such as healthcare, making it difficult to design an effective augmentation method, and hindering a similar progress in tabular data setting. In this paper, we introduce a new framework, Subsetting features of Tabular data (SubTab), that turns the task of learning from tabular data into a multi-view representation learning problem by dividing the input features to multiple subsets. We argue that reconstructing the data from the subset of its features rather than its corrupted version in an autoencoder setting can better capture its underlying latent representation. In this framework, the joint representation can be expressed as the aggregate of latent variables of the subsets at test time, which we refer to as collaborative inference. Our experiments show that the SubTab achieves the state of the art (SOTA) performance of 98.31% on MNIST in tabular setting, on par with CNN-based SOTA models, and surpasses existing baselines on three other real-world datasets by a significant margin.