 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Model-free prediction of emergence of extreme events in a parametrically driven nonlinear dynamical system by Deep Learning
Jul 14, 2021
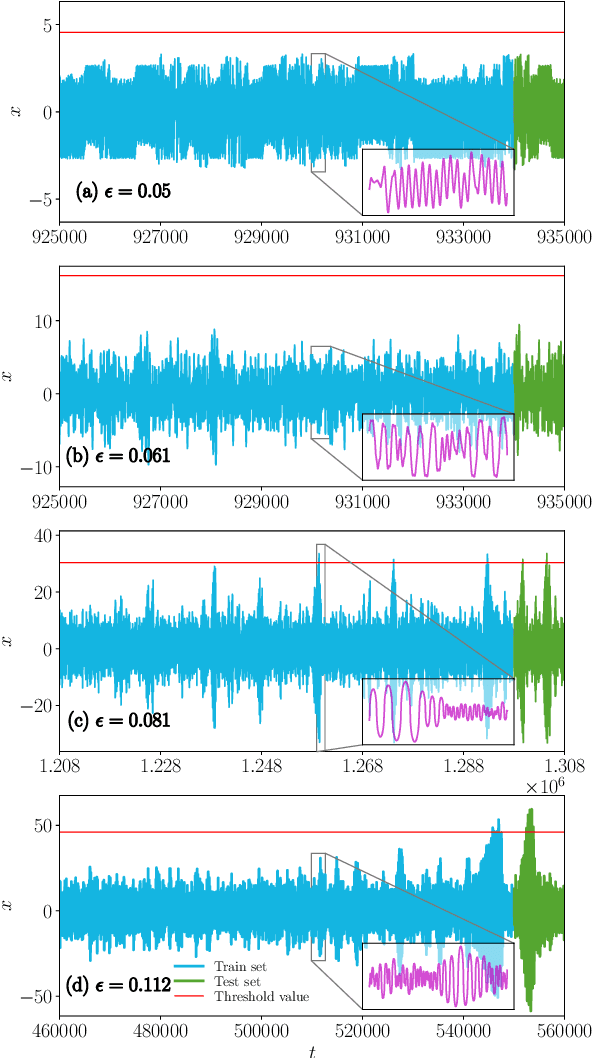
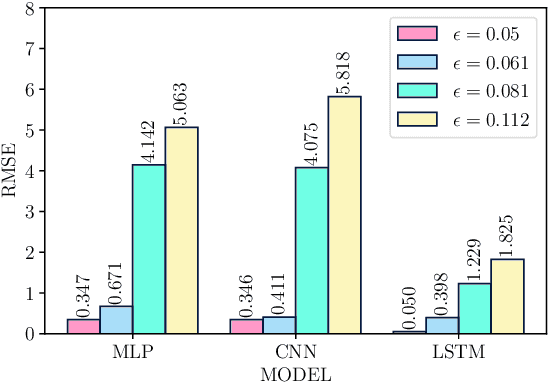
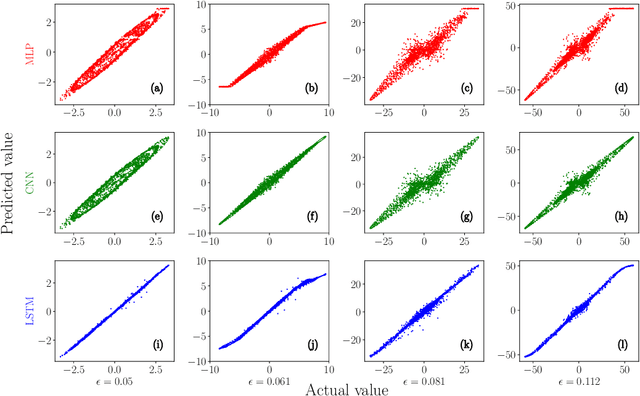
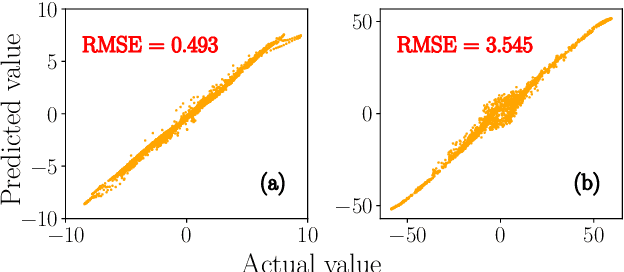
We predict the emergence of extreme events in a parametrically driven nonlinear dynamical system using three Deep Learning models, namely Multi-Layer Perceptron, Convolutional Neural Network and Long Short-Term Memory. The Deep Learning models are trained using the training set and are allowed to predict the test set data. After prediction, the time series of the actual and the predicted values are plotted one over the other in order to visualize the performance of the models. Upon evaluating the Root Mean Square Error value between predicted and the actual values of all three models, we find that the Long Short-Term Memory model can serve as the best model to forecast the chaotic time series and to predict the emergence of extreme events for the considered system.
sigmoidF1: A Smooth F1 Score Surrogate Loss for Multilabel Classification
Aug 24, 2021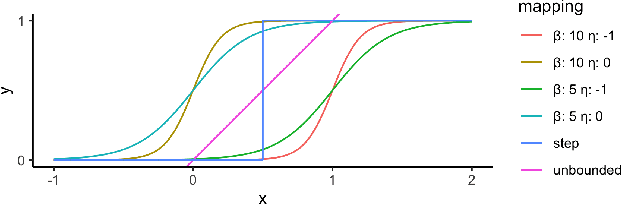

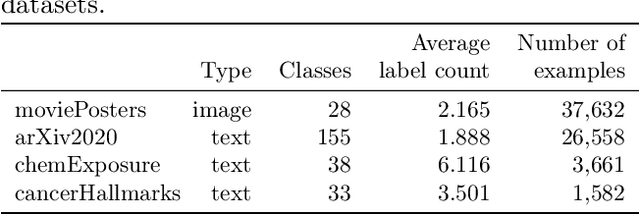
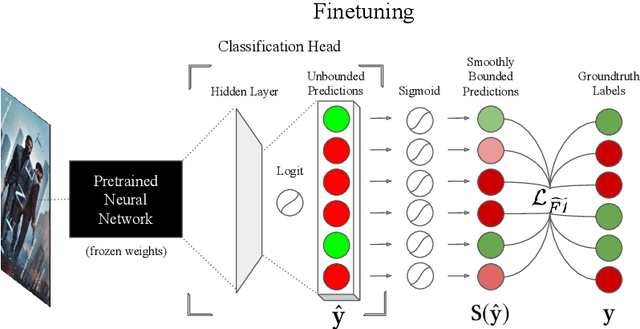
Multiclass multilabel classification refers to the task of attributing multiple labels to examples via predictions. Current models formulate a reduction of that multilabel setting into either multiple binary classifications or multiclass classification, allowing for the use of existing loss functions (sigmoid, cross-entropy, logistic, etc.). Empirically, these methods have been reported to achieve good performance on different metrics (F1 score, Recall, Precision, etc.). Theoretically though, the multilabel classification reductions does not accommodate for the prediction of varying numbers of labels per example and the underlying losses are distant estimates of the performance metrics. We propose a loss function, sigmoidF1. It is an approximation of the F1 score that (I) is smooth and tractable for stochastic gradient descent, (II) naturally approximates a multilabel metric, (III) estimates label propensities and label counts. More generally, we show that any confusion matrix metric can be formulated with a smooth surrogate. We evaluate the proposed loss function on different text and image datasets, and with a variety of metrics, to account for the complexity of multilabel classification evaluation. In our experiments, we embed the sigmoidF1 loss in a classification head that is attached to state-of-the-art efficient pretrained neural networks MobileNetV2 and DistilBERT. Our experiments show that sigmoidF1 outperforms other loss functions on four datasets and several metrics. These results show the effectiveness of using inference-time metrics as loss function at training time in general and their potential on non-trivial classification problems like multilabel classification.
Fast Density Estimation for Density-based Clustering Methods
Sep 23, 2021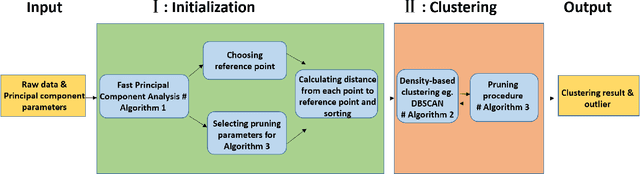
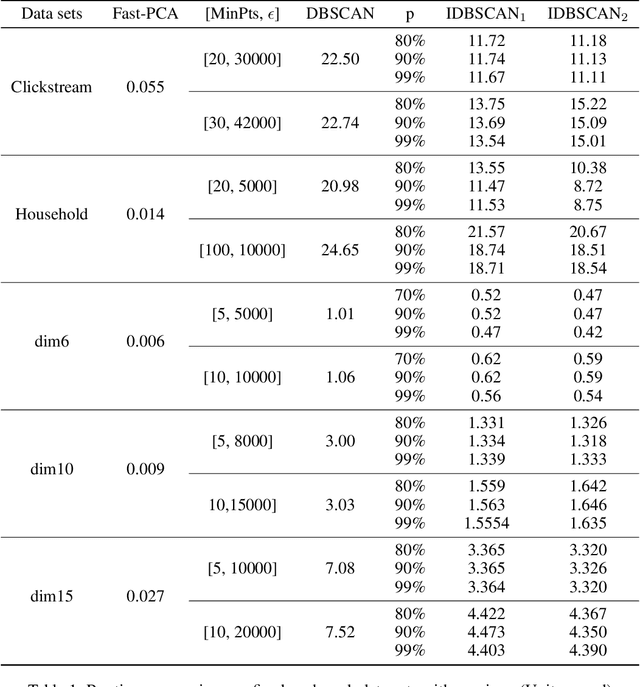

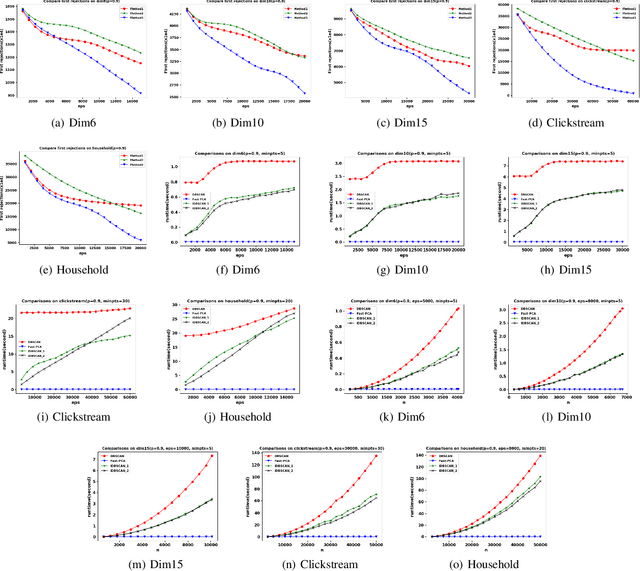
Density-based clustering algorithms are widely used for discovering clusters in pattern recognition and machine learning since they can deal with non-hyperspherical clusters and are robustness to handle outliers. However, the runtime of density-based algorithms is heavily dominated by finding neighbors and calculating the density of each point which is time-consuming. To address this issue, this paper proposes a density-based clustering framework by using the fast principal component analysis, which can be applied to density based methods to prune unnecessary distance calculations when finding neighbors and estimating densities. By applying this clustering framework to the Density Based Spatial Clustering of Applications with Noise (DBSCAN) algorithm, an improved DBSCAN (called IDBSCAN) is obtained, which preserves the advantage of DBSCAN and meanwhile, greatly reduces the computation of redundant distances. Experiments on five benchmark datasets demonstrate that the proposed IDBSCAN algorithm improves the computational efficiency significantly.
Low-Latency Immersive 6D Televisualization with Spherical Rendering
Sep 23, 2021
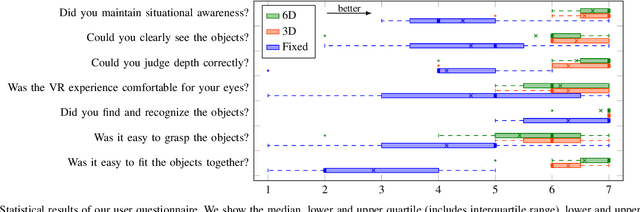


We present a method for real-time stereo scene capture and remote VR visualization that allows a human operator to freely move their head and thus intuitively control their perspective during teleoperation. The stereo camera is mounted on a 6D robotic arm, which follows the operator's head pose. Existing VR teleoperation systems either induce high latencies on head movements, leading to motion sickness, or use scene reconstruction methods to allow re-rendering of the scene from different perspectives, which cannot handle dynamic scenes effectively. Instead, we present a decoupled approach which renders captured camera images as spheres, assuming constant distance. This allows very fast re-rendering on head pose changes while keeping the resulting temporary distortions during head translations small. We present qualitative examples, quantitative results in the form of lab experiments and a small user study, showing that our method outperforms other visualization methods.
Internal Language Model Adaptation with Text-Only Data for End-to-End Speech Recognition
Oct 14, 2021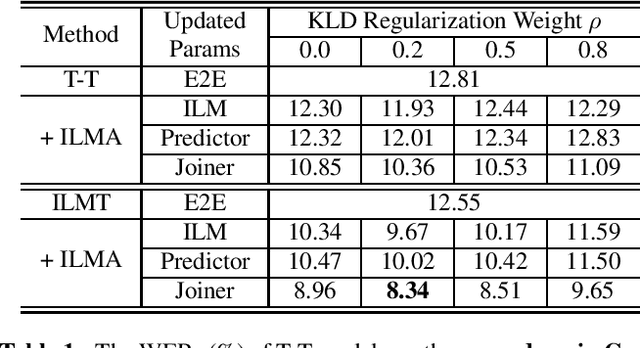
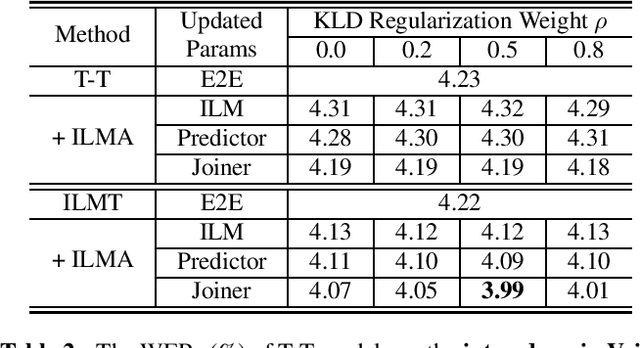
Text-only adaptation of an end-to-end (E2E) model remains a challenging task for automatic speech recognition (ASR). Language model (LM) fusion-based approaches require an additional external LM during inference, significantly increasing the computation cost. To overcome this, we propose an internal LM adaptation (ILMA) of the E2E model using text-only data. Trained with audio-transcript pairs, an E2E model implicitly learns an internal LM that characterizes the token sequence probability which is approximated by the E2E model output after zeroing out the encoder contribution. During ILMA, we fine-tune the internal LM, i.e., the E2E components excluding the encoder, to minimize a cross-entropy loss. To make ILMA effective, it is essential to train the E2E model with an internal LM loss besides the standard E2E loss. Furthermore, we propose to regularize ILMA by minimizing the Kullback-Leibler divergence between the output distributions of the adapted and unadapted internal LMs. ILMA is the most effective when we update only the last linear layer of the joint network. ILMA enables a fast text-only adaptation of the E2E model without increasing the run-time computational cost. Experimented with 30K-hour trained transformer transducer models, ILMA achieves up to 34.9% relative word error rate reduction from the unadapted baseline.
F-T-LSTM based Complex Network for Joint Acoustic Echo Cancellation and Speech Enhancement
Jun 16, 2021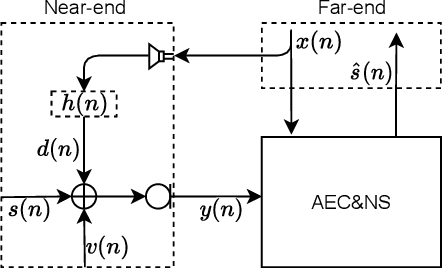
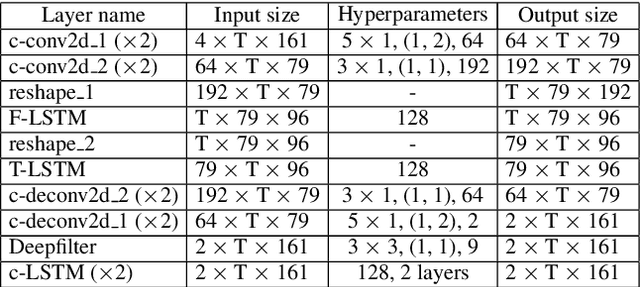
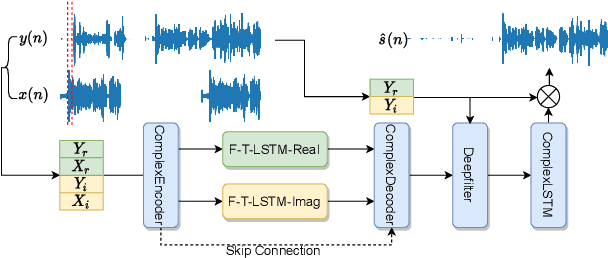
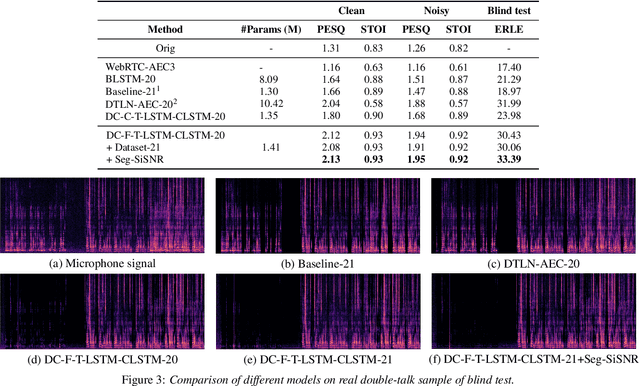
With the increasing demand for audio communication and online conference, ensuring the robustness of Acoustic Echo Cancellation (AEC) under the complicated acoustic scenario including noise, reverberation and nonlinear distortion has become a top issue. Although there have been some traditional methods that consider nonlinear distortion, they are still inefficient for echo suppression and the performance will be attenuated when noise is present. In this paper, we present a real-time AEC approach using complex neural network to better modeling the important phase information and frequency-time-LSTMs (F-T-LSTM), which scan both frequency and time axis, for better temporal modeling. Moreover, we utilize modified SI-SNR as cost function to make the model to have better echo cancellation and noise suppression (NS) performance. With only 1.4M parameters, the proposed approach outperforms the AEC-challenge baseline by 0.27 in terms of Mean Opinion Score (MOS).
Automated Multi-Process CTC Detection using Deep Learning
Sep 26, 2021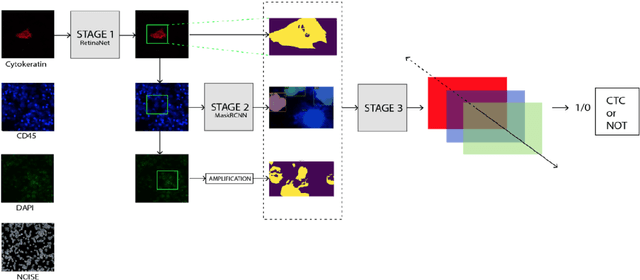
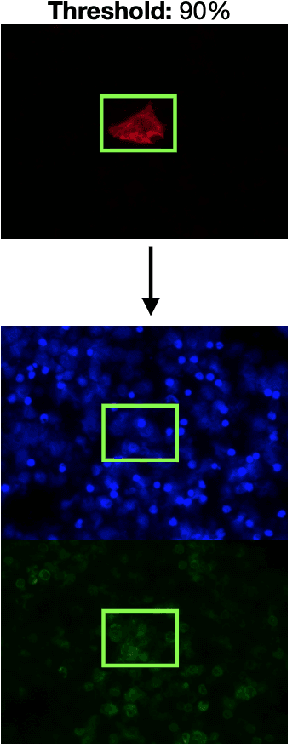
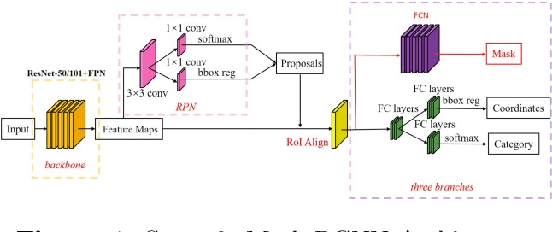
Circulating Tumor Cells (CTCs) bear great promise as biomarkers in tumor prognosis. However, the process of identification and later enumeration of CTCs require manual labor, which is error-prone and time-consuming. The recent developments in object detection via Deep Learning using Mask-RCNNs and wider availability of pre-trained models have enabled sensitive tasks with limited data of such to be tackled with unprecedented accuracy. In this report, we present a novel 3-stage detection model for automated identification of Circulating Tumor Cells in multi-channel darkfield microscopic images comprised of: RetinaNet based identification of Cytokeratin (CK) stains, Mask-RCNN based cell detection of DAPI cell nuclei and Otsu thresholding to detect CD-45s. The training dataset is composed of 46 high variance data points, with 10 Negative and 36 Positive data points. The test set is composed of 420 negative data points. The final accuracy of the pipeline is 98.81%.
Human-Computer Interaction Glow Up: Examining Operational Trust and Intention Towards Mars Autonomous Systems
Oct 28, 2021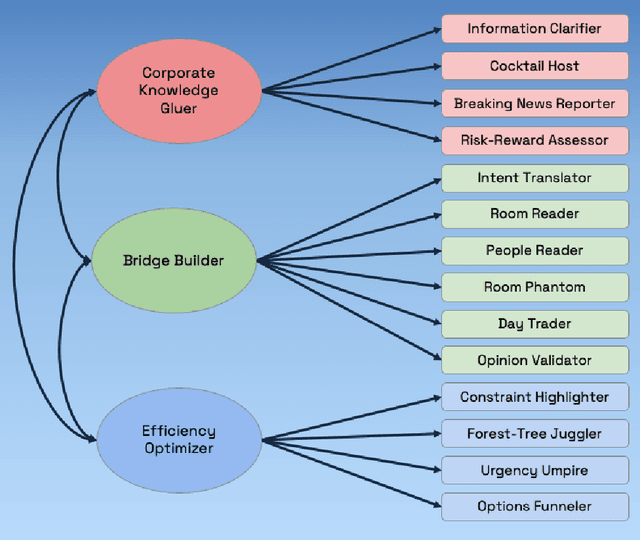
Tactful coordination on earth between hundreds of operators from diverse disciplines and backgrounds is needed to ensure that Martian rovers have a high likelihood of achieving their science goals while enduring the harsh environment of the red planet. The operations team includes many individuals, each with independent and overlapping objectives, working to decide what to execute on the Mars surface during the next planning period. The team must work together to understand each other's objectives and constraints within a fixed time period, often requiring frequent revision. This study examines the challenges faced during Mars surface operations, from high-level science objectives to formulating a valid, safe, and optimal activity plan that is ready to be radiated to the rover. Through this examination, we aim to illuminate how planning intent can be formulated and effectively communicated to future spacecrafts that will become more and more autonomous. Our findings reveal the intricate nature of human-to-human interactions that require a large array of soft skills and core competencies to communicate concurrently with science and engineering teams during plan formulation. Additionally, our findings exposed significant challenges in eliciting planning intent from operators, which will intensify in the future, as operators on the ground asynchronously co-operate the rover with the on board autonomy. Building a marvellous robot and landing it onto the Mars surface are remarkable feats -however, ensuring that scientists can get the best out of the mission is an ongoing challenge and will not cease to be a difficult task with increased autonomy.
KalmanNet: Neural Network Aided Kalman Filtering for Partially Known Dynamics
Jul 21, 2021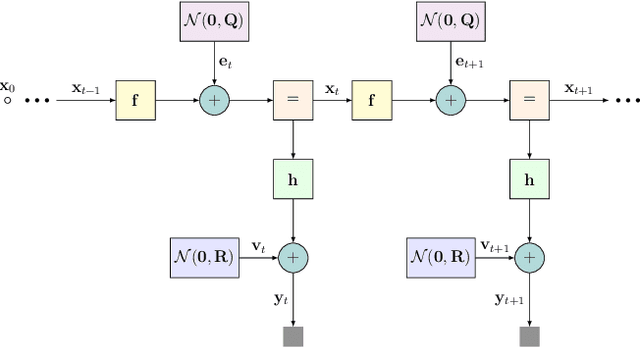
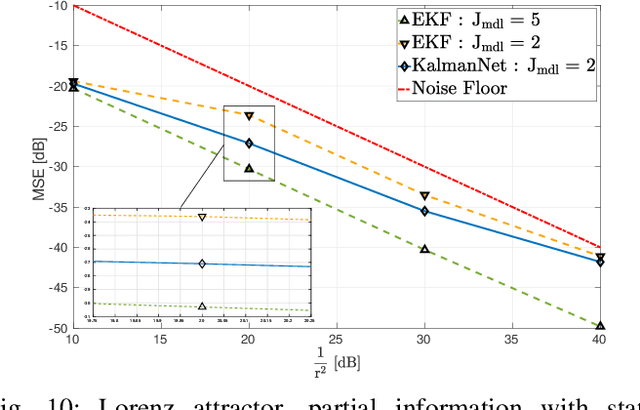
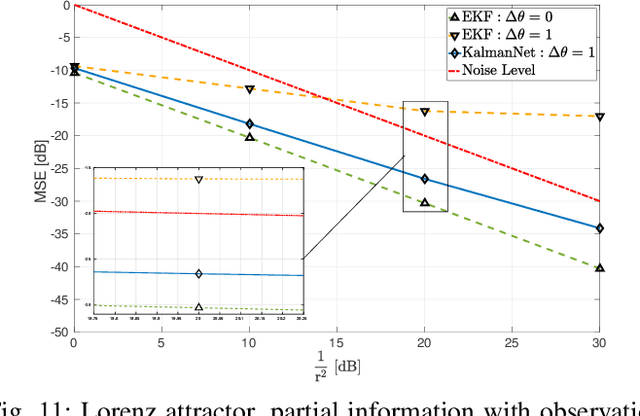
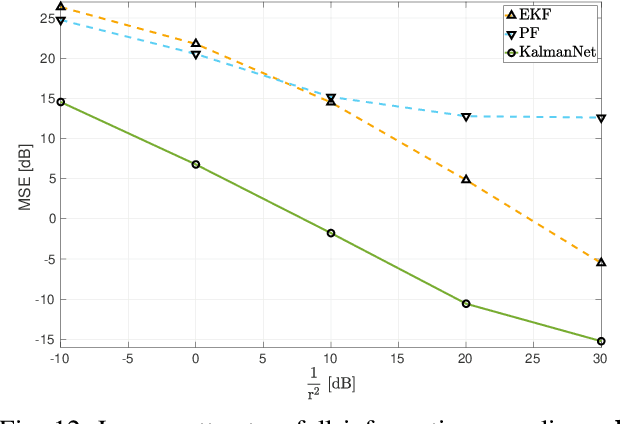
Real-time state estimation of dynamical systems is a fundamental task in signal processing and control. For systems that are well-represented by a fully known linear Gaussian state space (SS) model, the celebrated Kalman filter (KF) is a low complexity optimal solution. However, both linearity of the underlying SS model and accurate knowledge of it are often not encountered in practice. Here, we present KalmanNet, a real-time state estimator that learns from data to carry out Kalman filtering under non-linear dynamics with partial information. By incorporating the structural SS model with a dedicated recurrent neural network module in the flow of the KF, we retain data efficiency and interpretability of the classic algorithm while implicitly learning complex dynamics from data. We numerically demonstrate that KalmanNet overcomes nonlinearities and model mismatch, outperforming classic filtering methods operating with both mismatched and accurate domain knowledge.
Fair Balance: Mitigating Machine Learning Bias Against Multiple Protected Attributes With Data Balancing
Jul 17, 2021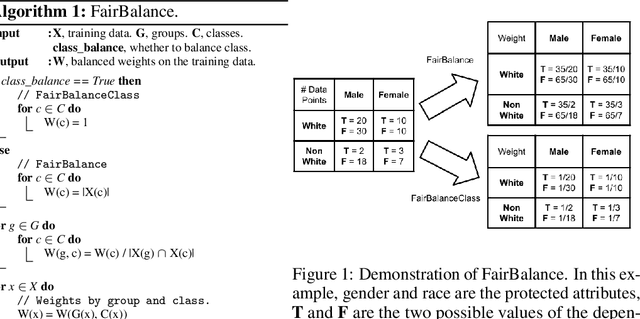

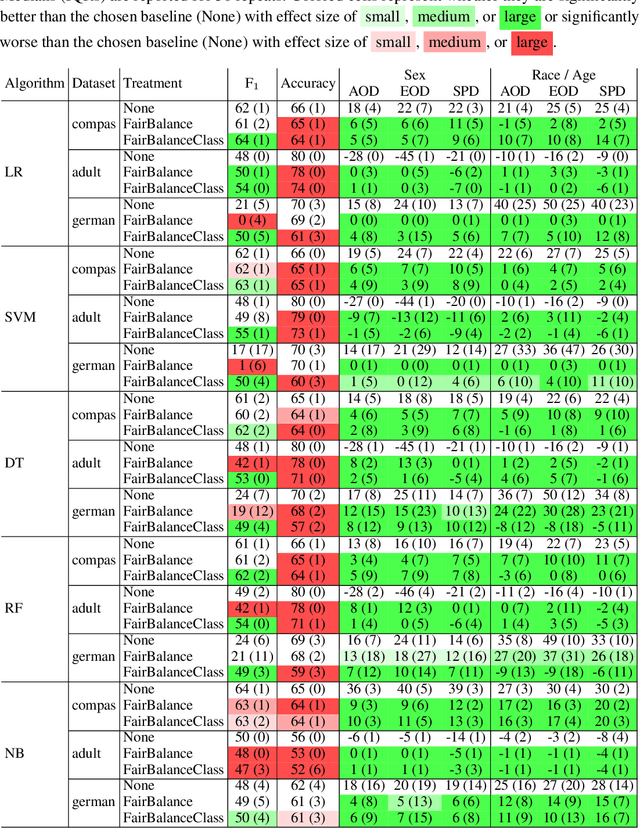
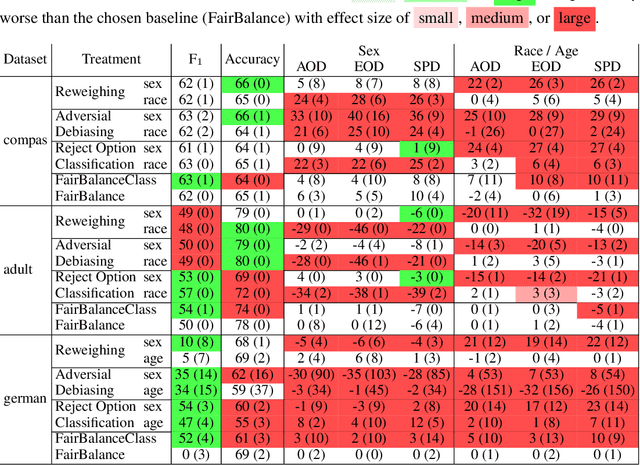
This paper aims to improve machine learning fairness on multiple protected at-tributes. Machine learning fairness has attracted increasing attention since machine learning models are increasingly used for high-stakes and high-risk decisions. Most existing solutions for machine learning fairness only target one protected attribute(e.g. sex) at a time. These solutions cannot generate a machine learning model which is fair against every protected attribute (e.g. both sex and race) at the same time. To solve this problem, we propose FairBalance in this paper to balance the distribution of training data across every protected attribute before training the machine learning models. Our results show that, under the assumption of unbiased ground truth labels, FairBalance can significantly reduce bias metrics (AOD, EOD, and SPD) on every known protected attribute without much, if not any damage to the prediction performance.